






Model Architect SpectFormer(
(patch_embed1): Stem(
(conv): Sequential(
(0): Conv2d(3, 32, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) 特征提取
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
)
(proj): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(block1): ModuleList(
(0): Block(
(m): SpectralGatingNetwork(
(conv_input): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv_output): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): PVT2FFN(
(fc1): Linear(in_features=64, out_features=64, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
)
(act): GELU(approximate='none')
(fc2): Linear(in_features=64, out_features=64, bias=True)
)
(drop_path): Identity()
)
(1-2): 2 x Block(
(m): SpectralGatingNetwork(
(conv_input): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv_output): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): PVT2FFN(
(fc1): Linear(in_features=64, out_features=64, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
)
(act): GELU(approximate='none')
(fc2): Linear(in_features=64, out_features=64, bias=True)
)
(drop_path): DropPath()
)
)
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(patch_embed2): DownSamples(
(proj): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(block2): ModuleList(
(0-3): 4 x Block(
(m): SpectralGatingNetwork(
(conv_input): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv_output): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(norm1): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(mlp): PVT2FFN(
(fc1): Linear(in_features=128, out_features=128, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
)
(act): GELU(approximate='none')
(fc2): Linear(in_features=128, out_features=128, bias=True)
)
(drop_path): DropPath()
)
)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(patch_embed3): DownSamples(
(proj): Conv2d(128, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(block3): ModuleList(
(0-5): 6 x Block(
(m): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(proj): Linear(in_features=320, out_features=320, bias=True)
)
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): PVT2FFN(
(fc1): Linear(in_features=320, out_features=320, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(act): GELU(approximate='none')
(fc2): Linear(in_features=320, out_features=320, bias=True)
)
(drop_path): DropPath()
)
)
(norm3): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(patch_embed4): DownSamples(
(proj): Conv2d(320, 448, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((448,), eps=1e-05, elementwise_affine=True)
)
(block4): ModuleList(
(0-2): 3 x Block(
(m): Attention(
(q): Linear(in_features=448, out_features=448, bias=True)
(kv): Linear(in_features=448, out_features=896, bias=True)
(proj): Linear(in_features=448, out_features=448, bias=True)
)
(norm1): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
(norm2): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
(mlp): PVT2FFN(
(fc1): Linear(in_features=448, out_features=448, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(act): GELU(approximate='none')
(fc2): Linear(in_features=448, out_features=448, bias=True)
)
(drop_path): DropPath()
)
)
(norm4): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
(post_network): ModuleList(
(0): ClassBlock(
(norm1): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
(norm2): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
(attn): ClassAttention(
(kv): Linear(in_features=448, out_features=896, bias=True)
(q): Linear(in_features=448, out_features=448, bias=True)
(proj): Linear(in_features=448, out_features=448, bias=True)
)
(mlp): FFN(
(fc1): Linear(in_features=448, out_features=1792, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=1792, out_features=448, bias=True)
)
)
)
(head): Linear(in_features=448, out_features=6, bias=True)
)
---------------------------------------------------------------------------------------------------------------------------------------------------
(block1): ModuleList(
(0)Block{
SpectralGatingNetwork(Conv2d Conv2d)
LayerNorm
LayerNorm
(mlp):PVT2FFN(
Linear
DWConv(Conv2d)
GELU激活函数
Linear
)
Identity()
)
}
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
(1-2):Block{
SpectralGatingNetwork(Conv2d Conv2d)
LayerNorm
LayerNorm
(mlp):PVT2FFN(
Linear
DWConv(Conv2d)
GELU激活函数
Linear
)
DropPath(随机丢弃网络中的连接,以增强模型的泛化能力和鲁棒性)
LayerNorm
DownSamples(Conv2d LayerNorm )
)
}
---------------------------------------------------------------------------------------------------------------------------------------------------
(0-3)block: ModuleList(
Block{
SpectralGatingNetwork(Conv2d Conv2d)
LayerNorm
LayerNorm
(mlp):PVT2FFN(
Linear
DWConv(Conv2d)
GELU激活函数
Linear
)
DropPath
LayerNorm(对输入数据进行归一化处理)
DownSamples(Conv2d LayerNorm )
)
)
---------------------------------------------------------------------------------------------------------------------------------------------------
(0-5)block: ModuleList(
Block{
Attention( (q): Linear (kv): Linear (proj): Linear)
LayerNorm
LayerNorm
(mlp):PVT2FFN(
Linear
DWConv(Conv2d)
GELU激活函数
Linear
)
DropPath
LayerNorm
DownSamples(Conv2d LayerNorm )
)
)
---------------------------------------------------------------------------------------------------------------------------------------------------
(0-2)block: ModuleList(
Block{
Attention( (q): Linear (kv): Linear (proj): Linear)
LayerNorm
LayerNorm
(mlp):PVT2FFN(
Linear
DWConv(Conv2d)
GELU激活函数
Linear
)
DropPath
)
)
LayerNorm
---------------------------------------------------------------------------------------------------------------------------------------------------
post_network: ModuleList(
(0): ClassBlock(
LayerNorm
LayerNorm
ClassAttention(
(q): Linear (kv): Linear (proj): Linear
)
FFN(
Linear
GELU激活函数
Linear
)
(head): Linear
)
---------------------------------------------------------------------------------------------------------------------------------------------------
CNN 主要由卷积层(Convolutional Layer)、池化层(Pooling Layer)、全连接层(Fully Connected Layer)等组成,它们共同构成了网络的架构
卷积神经网络(CNN)由输入层、卷积层、激活函数、池化层、全连接层组成,即
- INPUT(输入层)
- CONV(卷积层)
- RELU(激活函数)
- POOL(池化层)
- FC(全连接层)
- 卷积(nn.Conv2d)
1.1卷积的定义与功能
nn.Conv2d 功能:对多个二维信号进行二维卷积
定义:
- 卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加;
- 卷积核:又称为滤波器,过滤器,可认为是某种模式,某种特征;
- 卷积维度:一般情况下,卷积核在几个维度上滑动,就是几维卷积
功能:
卷积过程类似于用一个模板去图像上寻找与他相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取;

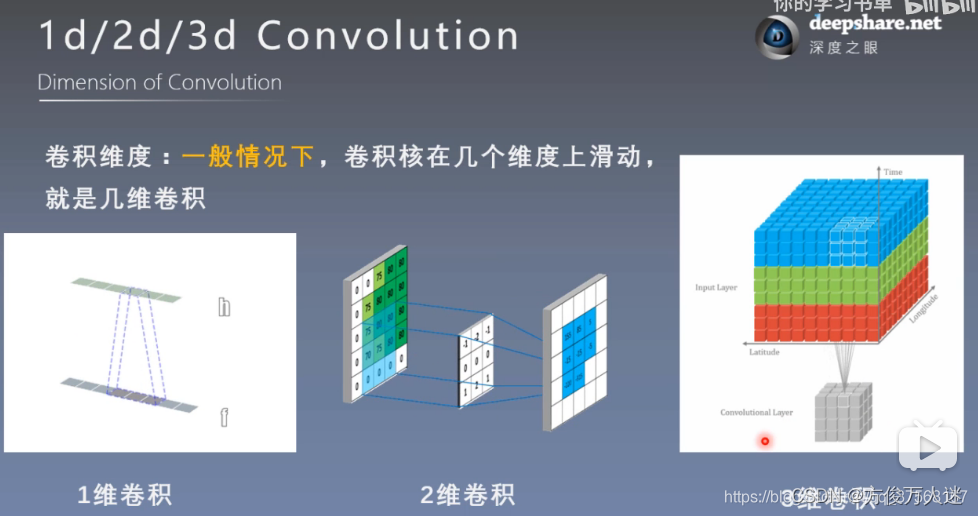
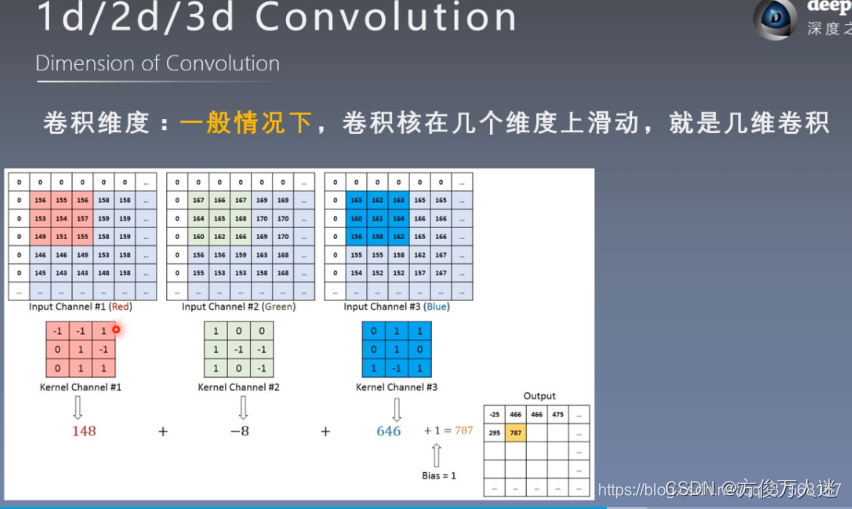
过程:卷积核(类似于一个模板)在图像上划动相应位置上乘加,从而实现特征提取

主要参数(包含默认值):
in_channels:输入通道数
out_channels:输出通道数,等价于卷积核个数
kernel_size:卷积核尺寸
stride=1:步长
padding=0:填充个数
dilation=1:空调卷积大小
groups=1:分组卷积设置
bias=True:偏置
padding_mode='zeros': 填充模式

-
- Padding、Stride
Eg:input: 5x5 kernel:3x3 stride:3 padding:2
Output : (input+padding*2-stride)/stride + 1
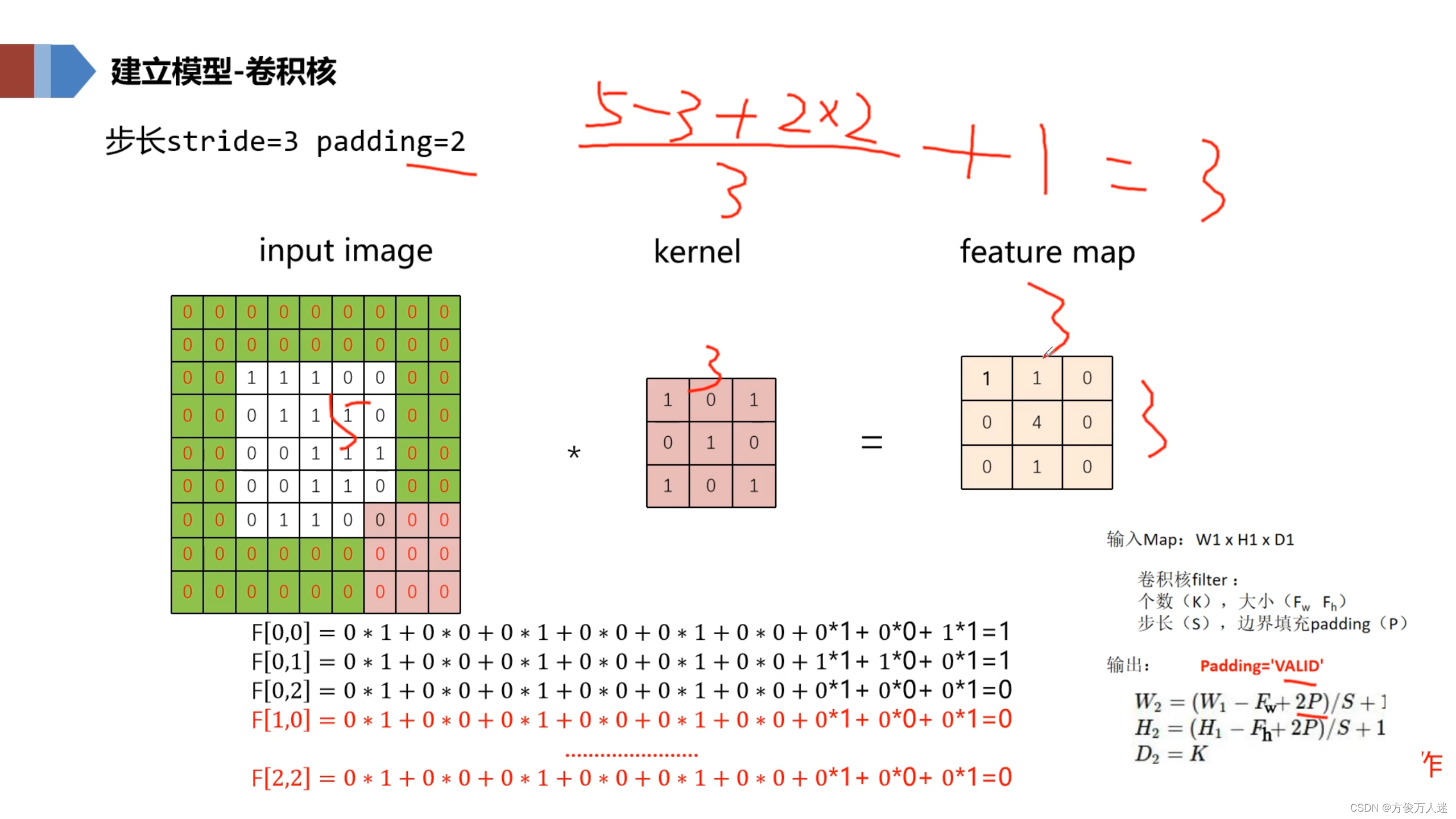
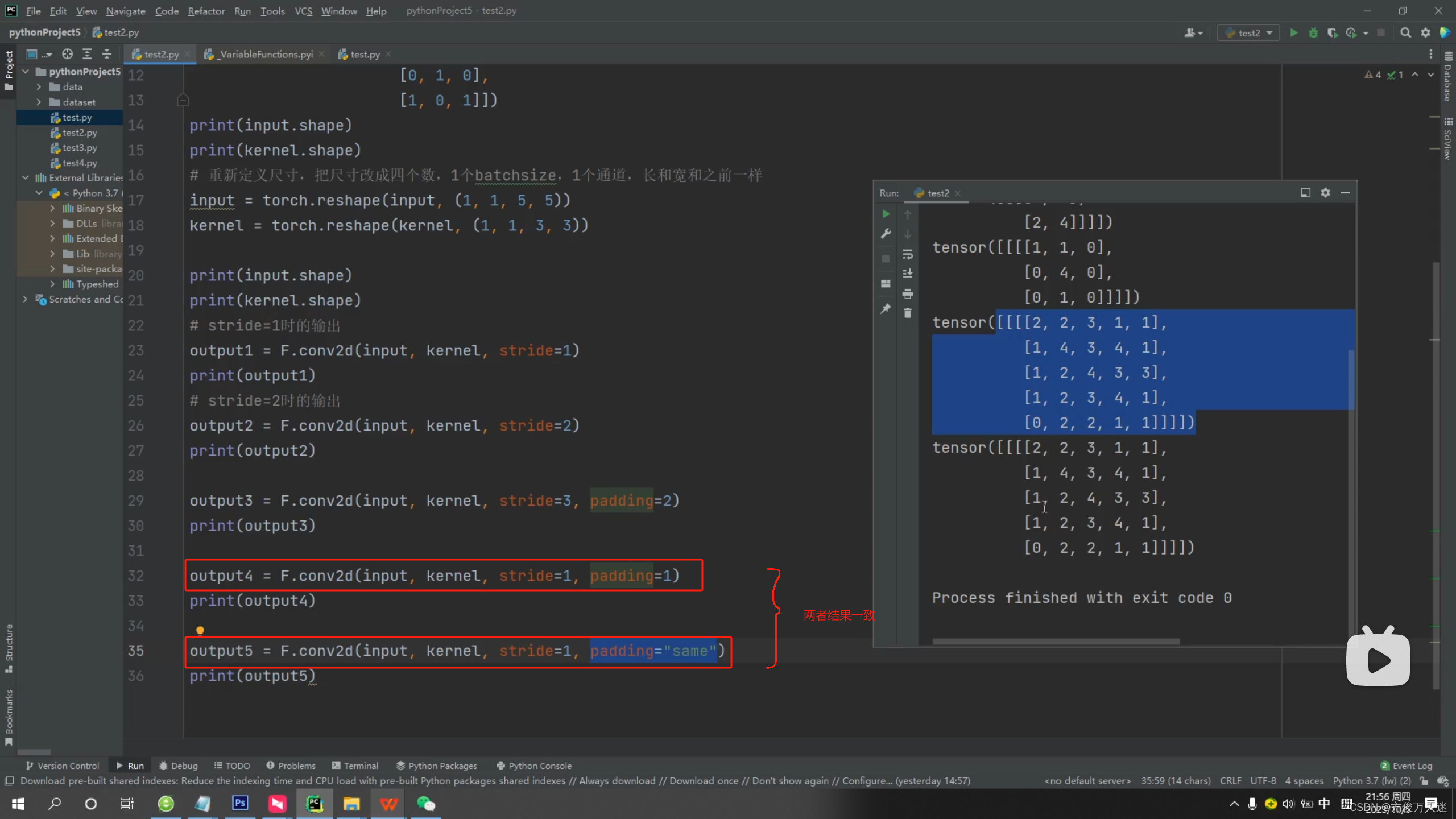
2. 池化层 Pooling Layer

2.1 最大池化 nn.MaxPool2d
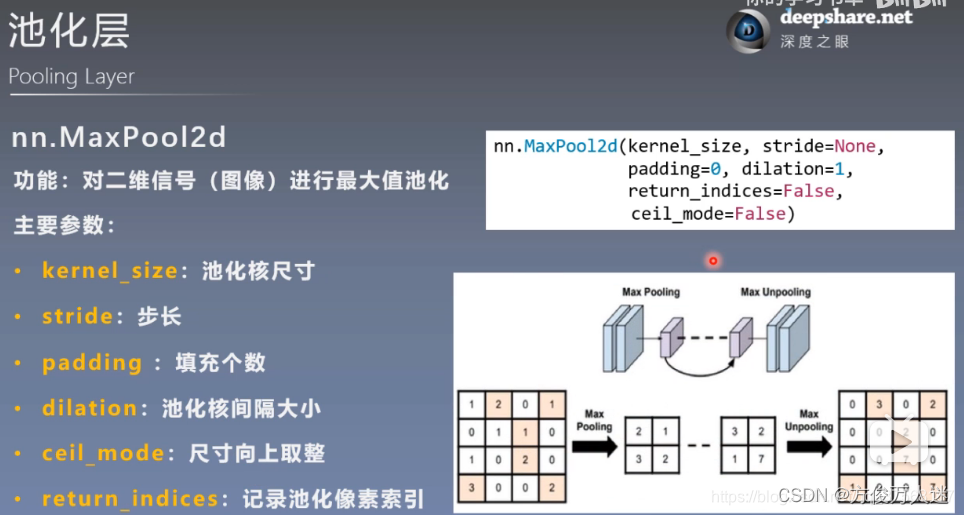
2.2 平均值池化 nn.AvgPool2d
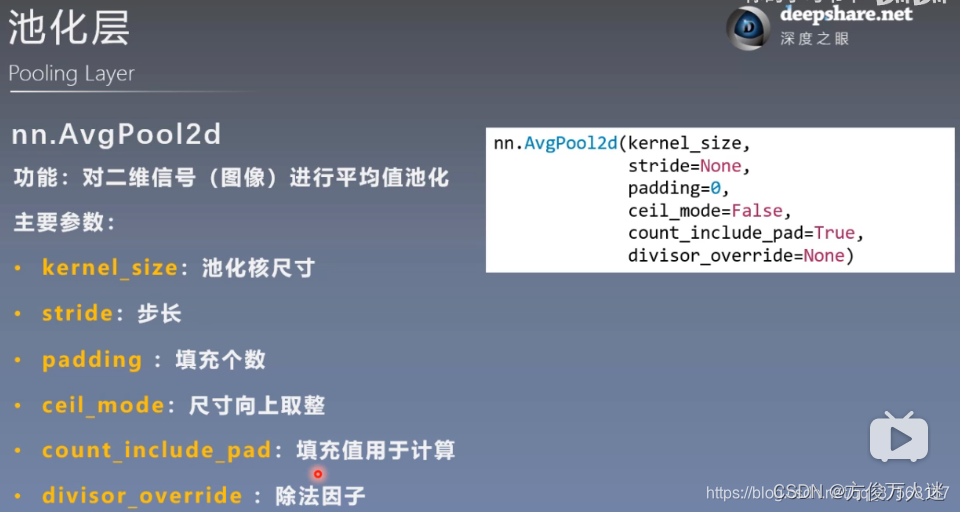
2.3 最大池化上采样 nn.MaxUnpool2d
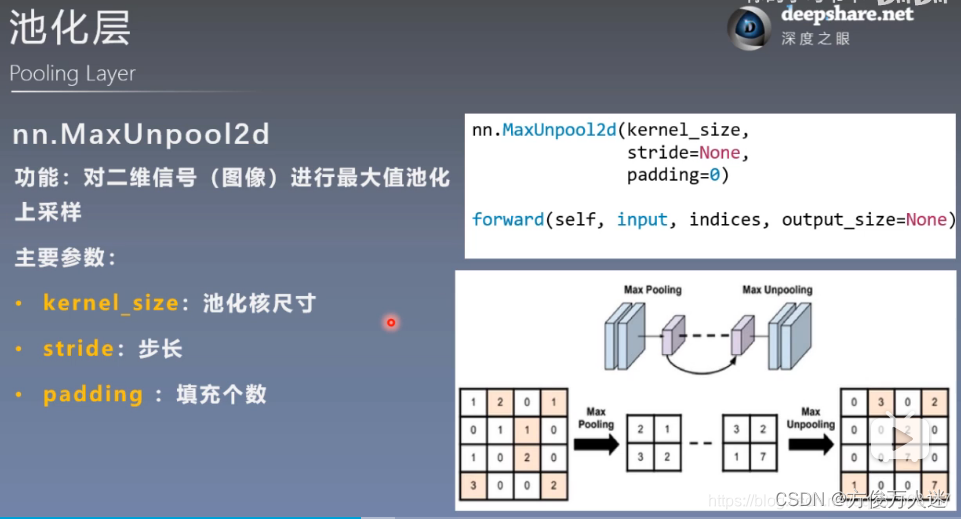
池化层:通过池化操作可以保留图像中重要特征的同时减少噪声和不重要的细节。如最大池化操作会选择每个池化窗口中的最大值作为输出,从而保留突出的特征。
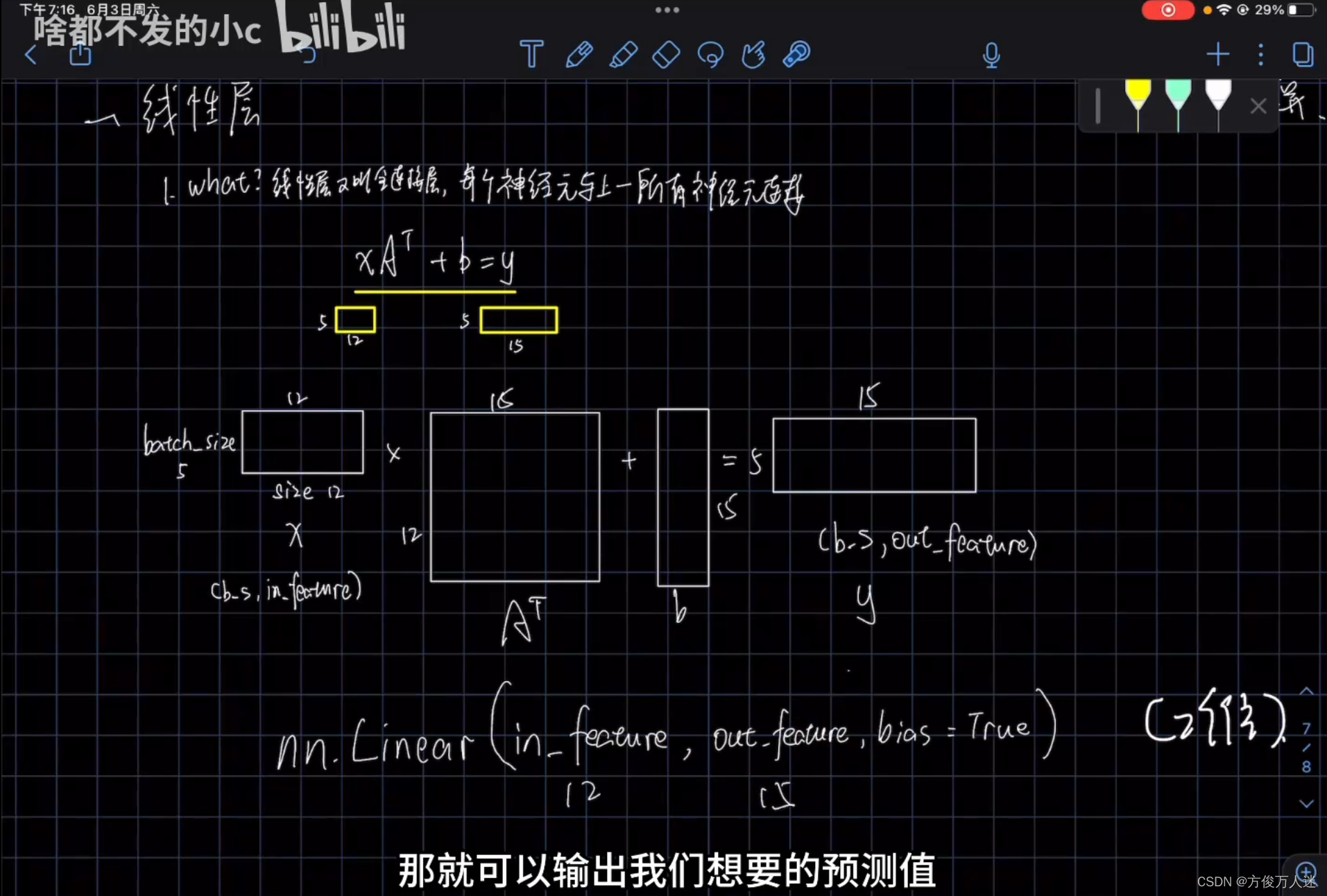
3. 线性层 (全连接层)
线性层又称全连接层,其每个神经元与上一层所有神经元相连实现对前一层的线性组合,线性变换.
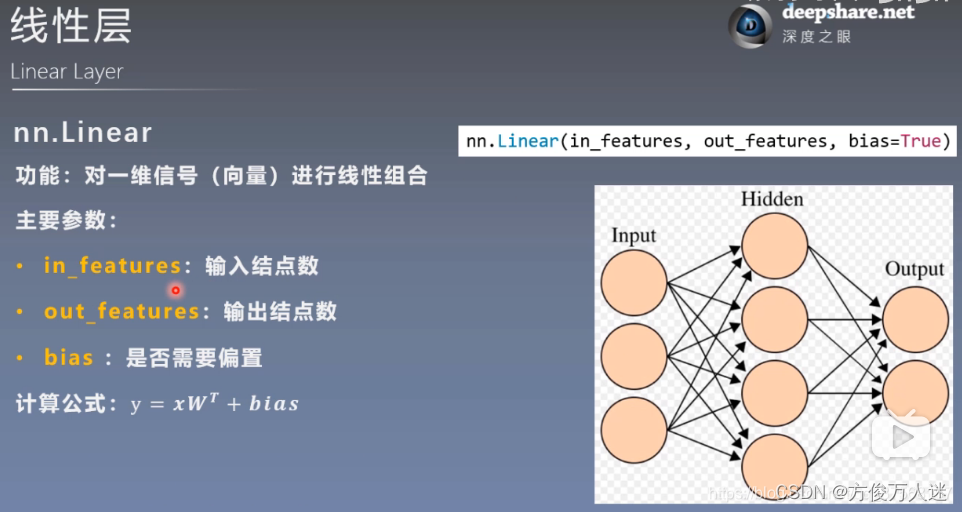
In_features(输入结点数):比如说形状为[N, M]的张量,其中N表示样本数量,M表示每个样本的特征维度,则输入结点数为M,线性层的输入结点数决定了权重矩阵的列数,即每个输入特征与权重之间的连接数量。这些连接用于将输入特征与线性层的权重进行相乘,生成线性变换后的输出特征。输入结点数也决定了线性层的输入维度,进而影响了输出维度和模型的表达能力
线性层(Linear Layer)通常位于卷积层之后,也称为全连接层(Fully Connected Layer)。线性层负责将卷积层或者池化层提取到的特征进行展平,并通过矩阵乘法和偏置项的加法进行线性变换,最终输出网络的预测结果
Out_features: y=x*WT+bias
4. 归一化
归一化作用:
- 加速收敛速度: 归一化可以将输入特征缩放到相对较小的范围内,使得优化算法(如梯度下降)更容易找到全局最优解或局部最优解,从而加速模型的收敛速度。
- 减少梯度消失/爆炸问题: 在深度神经网络中,反向传播过程中可能出现梯度消失或梯度爆炸的情况,导致训练困难。归一化可以使得网络层之间的梯度更加稳定,减少梯度消失或梯度爆炸的发生。
- 提高模型泛化能力: 归一化可以减少特征之间的相关性,降低模型对特定特征的依赖程度,从而提高模型的泛化能力,使得模型在未见过的数据上表现更好。
- 抑制过拟合: 归一化可以起到一定的正则化作用,有助于抑制模型的过拟合,提高模型的泛化能力。
- 处理梯度消失/爆炸问题: 在 RNNs 或深度 CNNs 等网络中,由于层次较多,容易出现梯度消失或梯度爆炸的情况。归一化能够在一定程度上缓解这些问题,使得网络更容易训练。
- 批量归一化和层归一化
- 对全连接层进行批量归一化
- 对卷积网络进行批量归一化
3.对序列性网络进行批量归一化
5. 激活函数层 Activation Layer
(常用的激活函数包括 Sigmoid、Tanh、ReLU(Rectified Linear Unit)、Leaky ReLU、ELU(Exponential Linear Unit)等。每种激活函数都有其独特的特性和适用场景,具体选择取决于问题的性质和实验的结果)
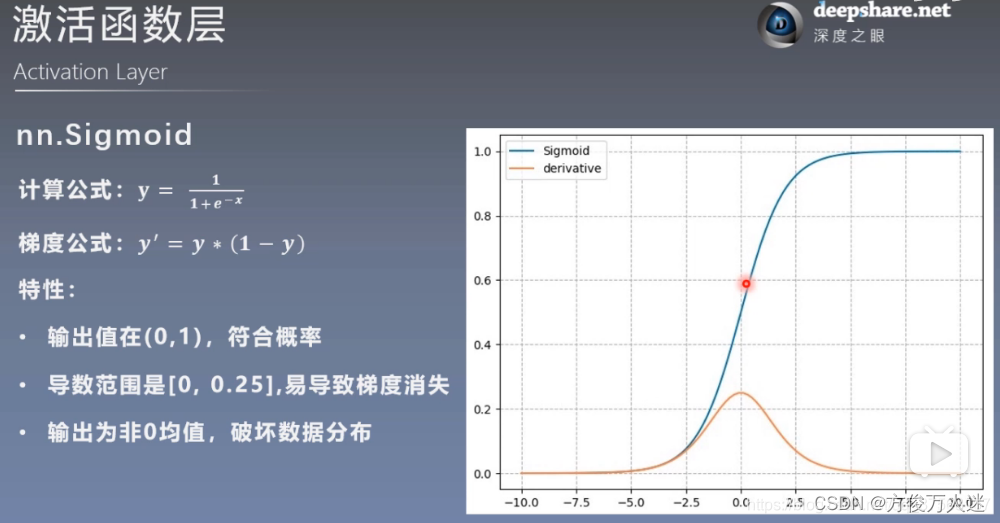 |
5.1 nn.Sigmoid
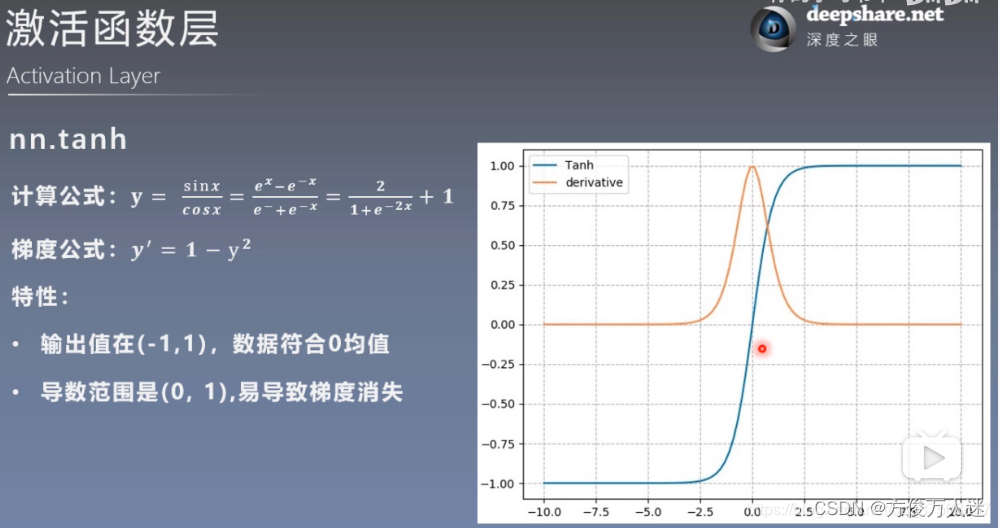
5.2 nn.tanh
5.3 nn.ReLu
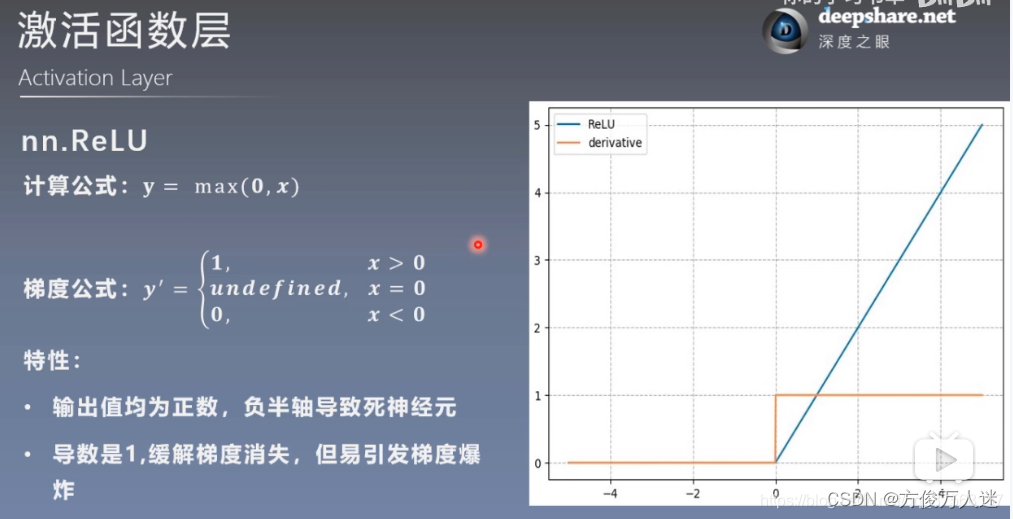
5.4 其他激活函数
5.5激活函数的作用
- 引入非线性特性:线性变换(如全连接层或卷积层)只能表示线性关系,而激活函数能够引入非线性特性,从而使神经网络能够表示更复杂的函数。
- 解决非线性可分问题:许多实际问题都是非线性可分的,即用线性模型无法很好地拟合的问题。激活函数的非线性变换可以帮助神经网络学习并拟合这些非线性关系。
- 增强模型的表达能力:通过引入非线性变换,激活函数可以增强神经网络的表达能力,使其能够学习到更复杂的特征和模式。
- 一些激活函数具有抑制过拟合的作用抑制过拟合:一些激活函数具有抑制过拟合的作用,例如 Dropout 和 Batch Normalization 等激活函数,它们可以在训练过程中降低模型的复杂度,从而提高模型的泛化能力。
6. 正则化
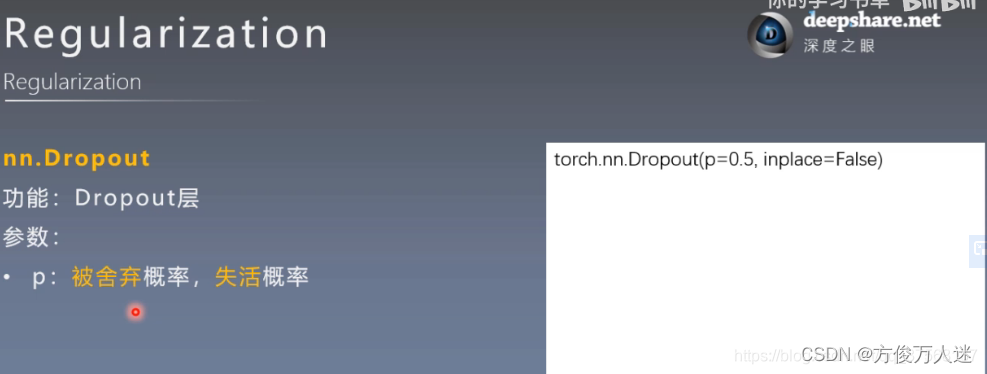
torch.nn.Dropout(p=0.5, inplace=False)
功能: 随机性失活
参数:
p:被舍弃的概率,失活概率,默认0.5
nn.Dropout
功能:Dropout层
参数:
P:
被舍弃概率,失活概率
采样:
下采样和池化应该是包含关系,池化属于下采样,而下采样不局限于池化,如果卷积 stride=2,此时也可以把这种卷积叫做下采样
上采样(Upsampling):
上采样是指增加信号或图像的采样率或分辨率,从而使其变得更大。它通过插值或填充新的数据点来增加采样点的数量。
在图像处理中,上采样可以用于放大图像,增加图像的尺寸或分辨率。一种常见的上采样方法是使用插值技术(如双线性插值、三次样条插值等)来估算新像素的值。
在神经网络中,上采样也经常用于进行反卷积操作,例如转置卷积(Transposed Convolution),以便从低分辨率特征图中恢复高分辨率特征图,用于图像分割、超分辨率重建等任务。
下采样(Downsampling):
下采样是指减少信号或图像的采样率或分辨率,从而使其变得更小。它通过跳过或合并数据点来减少采样点的数量。
在图像处理中,下采样可以用于缩小图像,减少图像的尺寸或分辨率。常见的下采样方法包括平均池化(Average Pooling)和最大池化(Max Pooling),它们通过在图像区域上取平均值或最大值来降低分辨率。
在神经网络中,下采样也经常用于卷积层中的步幅(stride)操作,或者池化层(Pooling Layer),用于缩小特征图的尺寸并提取更高级别的特征。
- 一些常用的函数
x = x.view(b_s, nq, self.h, self.d_k),
这一步首先使用 view 方法对x张量进行形状变换。具体地,将x张量重塑为一个四维张量,其中 b_s 是批大小(batch size),nq 是查询数量(number of queries),self.h 是头数(number of heads),self.d_k 是查询的深度(depth of queries)
x = x.permute(0,2,1,3)
使用 permute 方法对张量的维度进行置换。这里的参数 (0, 2, 1, 3) 指定了维度的新顺序。具体来说,原始的张量维度顺序是 (b_s, nq, self.h, self.d_k),经过置换后,变为 (b_s, self.h, nq, self.d_k)。换句话说,原来在第二维的x数量现在在第三维,原来在第三维的头数现在在第二维
综合起来,这行代码的作用是将原始的查询张量重塑为一个四维张量,并将查询数量和头数的维度进行置换,以满足后续计算操作的需求
- 关于类调用
class SimplifiedScaledDotProductAttention(nn.Module):
def __init__(self, d_model, h,dropout=.1):
def init_weights(self):
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
if __name__ == '__main__':
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
#会默认调用def __init__( ):,然后把参数传递到这个函数里面去
如果这个函数里面有self. init_weights(self)、forward(self, queries, keys, values, attention_mask=None, attention_weights=None):,则也会同时执行这两个函数
如果print(ssa),则由于类没有定义自定义的 __str__ 方法,因此打印 ssa 实例对象时,会默认输出类名以及对象的内存地址,要想让 print(se) 输出更有意义的信息,你可以在 SKAttention 类中自定义 __str__ 方法,返回你希望打印的字符串信息。例如:
def __str__(self):
return "SKAttention module with channel={}, reduction={}".format(self.channel, self.reduction)
如果再往ssa里传参数, output=ssa(input,input,input),则#会默认调用类中的forward( ):,然后把参数传递到这个函数里面去
而如果想要类中的init_weights(self):执行的话,要么就是在其他函数中调用了这个函数,然后被顺带执行,要么就得专门得去调用这个方法才能被执行,而不会通过实例化被默认执行















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









