






1.导读
Title: Activating More Pixels in Image Super-Resolution Transformer
Paper: https://arxiv.org/pdf/2205.04437.pdf
Code: https://github.com/XPixelGroup/HAT
CVPR 2023中提出了一种名为Hybrid Attention Transformer (HAT)的方法,旨在通过结合深度学习技术和注意力机制来改进图像超分辨率任务。该方法将通道注意力和基于窗口的自注意力机制相结合,充分利用它们在利用全局统计信息和强大的局部拟合能力方面的互补优势。此外,作者还引入了一个重叠的交叉注意力模块,用于增强相邻窗口特征之间的交互作用,以更好地聚合跨窗口信息。
文中通过 LAM 的分析,LAM 能够显示出哪些输入像素对于重建贡献最大,如下图

发现:通过HAT,在图像超分辨率任务中,能够激活更多像素进行重建,在图中几乎可以映射整个图像,并且能够恢复正确和清晰的纹理。这对我们们在处理小目标任务时,有所启发,相比于大目标检测,小目标之所以难以检测或者有较好的检测效果是因为,其输入特征少,有效利用到的输入像素不够。
通过激活更多有效的像素,HAT方法在小目标检测任务中取得了显著的提升。这意味着HAT方法能够更好地利用输入图像的信息,从而改善目标检测的准确性和性能。此外,在训练阶段采用了预训练策略,进一步挖掘模型的潜力以实现更好的性能。通过以上改进,HAT方法为小目标检测任务带来了显著的进展和涨点。
2.HAB
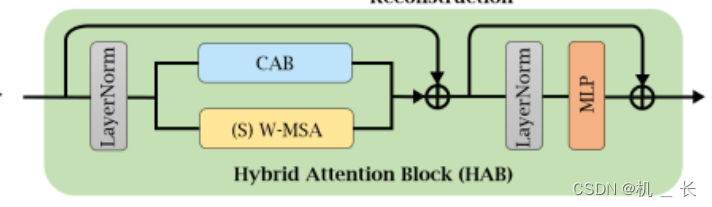
HAB 用于结合不同类型的注意力机制来激活更多的像素,以实现更好的重建效果。该模块由两个关键组成部分组成:窗口自注意力机制(Window-based Self-Attention)和通道注意力机制(Channel Attention)。
在 HAB 模块中,首先将输入特征进行归一化处理,然后利用窗口自注意力机制对特征进行处理。窗口自注意力机制将输入特征划分为局部窗口,并在每个窗口内计算自注意力。这样可以捕捉到局部区域的关联信息。接下来,通过通道注意力机制,全局信息被引入,用于计算通道注意力权重。通道注意力机制能够利用全局信息对特征进行加权,从而激活更多的像素。
HAB 模块的输出是窗口自注意力机制和通道注意力机制的加权和,并通过残差连接与输入特征相加。这种设计使得网络能够同时利用局部和全局信息,从而实现更好的重建效果。
3.YOLOv8结合HAB的有效涨点改进
以下是基于yolov8配置文件进行的一些改进。
# Ultralytics YOLO 🚀, AGPL-3.0 license # YOLOv8 object detection model with P2-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect # Parameters nc: 80 # number of classes scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n' # [depth, width, max_channels] n: [0.33, 0.25, 1024] s: [0.33, 0.50, 1024] m: [0.67, 0.75, 768] l: [1.00, 1.00, 512] x: [1.00, 1.25, 512] # YOLOv8.0 backbone backbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 0. -320 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 1. -160 - [-1, 3, C2f, [128, True]] # 2. -160 - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 3. -80 - [-1, 6, C2f, [256, True]] # 4. -80 - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 5. -40 - [-1, 6, C2f, [512, True]] # 6. -40 - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 7. -20 - [-1, 3, C2f, [1024, True]] # 8. -20 - [-1, 1, SPPF, [1024, 5]] # 9. -20 # YOLOv8.0-p2 head head: - [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 10. -40 - [[-1, 6], 1, Concat, [1]] # cat backbone P4 # 11. -40 - [-1, 3, C2f, [512]] # 12 # 12. -40 - [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 13. -80 - [[-1, 4], 1, Concat, [1]] # cat backbone P3 # 14. -80 - [-1, 3, C2f, [256]] # 15 (P3/8-small) # 15. -80 - [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 16. -160 - [[-1, 2], 1, Concat, [1]] # cat backbone P2 # 17. -160 - [-1, 3, C2f, [128]] # 18 (P2/4-xsmall) # 18. -160 - [-1, 1, HAT, []] # 24 # 19. -160 - [-1, 1, Conv, [128, 3, 2]] # 20. -80 - [[-1, 15], 1, Concat, [1]] # cat head P3 # 21. -80 - [-1, 3, C2f, [256]] # 21 (P3/8-small) # 22. -80 - [-1, 1, HAT, []] # 24 # 23. -160 - [-1, 1, Conv, [256, 3, 2]] # 24. -40 - [[-1, 12], 1, Concat, [1]] # cat head P4 # 25. -40 - [-1, 3, C2f, [512]] # 24 (P4/16-medium) # 26. -40 - [-1, 1, HAT, []] # 24 # 27. -40 - [-1, 1, Conv, [512, 3, 2]] # 28. -20 - [[-1, 9], 1, Concat, [1]] # cat head P5 # 29. -20 - [-1, 3, C2f, [1024]] # 27 (P5/32-large) # 30. -20 - [-1, 1, HAT, []] # 24 # 31. -20 - [[19, 23, 27, 31], 1, Detect, [nc]] # Detect(P2, P3, P4, P5)
其中改进部分有两处,并都用不同颜色进行标记
1 .引入P2小目标检测层,即再更大的特征图上进行输出结果,使得YOLOv8能够更有效地检测小目标物体。小目标通常在图像中占据较少的像素,因此更容易被忽略或误判。通过专门的P2层,YOLOv8能够更敏锐地检测和定位小目标,提高了小目标检测的准确性。
2.在输出的检测头上均将HAT模块加入,经过实验对比放于最后效果最好,因为此处局部高级语义,感受野也是最大的
4.结果展示
改进前:

改进后:

有效涨点!!!
5.代码运行中需要额外安装的第三方包,及其安装
1. pip install einops -i https://mirrors.aliyun.com/pypi/simple
2. pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
3. pip install basicsr==1.4.2 -i https://mirrors.aliyun.com/pypi/simple
注:更多源码,关注加私信















 1935
1935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









