






论文阅读笔记(六)——用可旋转包围盒学习旋转不变检测器
论文简介
论文中文翻译:《用可旋转包围盒学习旋转不变检测器》
论文名称:《Learning a Rotation Invariant Detector with Rotatable Bounding Box》
摘要
任意旋转物体的检测是一项具有挑战性的任务,因为很难有效地分离出多角度物体并将其与背景分离。现有的方法由于使用了传统的包围盒(这是一种用于定位旋转对象的旋转变体结构)而无法定位旋转对象。本文提出了一种新的检测方法,该方法应用了新定义的可旋转包围盒。所提出的检测器(DRBox)可以有效地处理物体的方位角任意的情况。DRBox的训练迫使检测网络学习目标的正确方向角,从而实现旋转不变性。DRBox被测试在卫星图像上检测车辆、船只和飞机,与快速R-CNN和SSD相比,后者被选择作为传统的基于包围盒的方法的基准。结果表明,在给定的任务上,基于包围盒的方法比传统的基于包围盒的方法性能更好,对输入图像和目标对象的旋转具有更强的鲁棒性。此外,实验结果表明DRBox能够正确输出目标的方位角,这对于多角度目标的有效定位非常有用。代码和模型可在https://github.com/liulei01/DRBox.
正文
介绍
目标检测是计算机视觉中最具挑战性的任务之一,一直以来都备受关注。大多数现有的检测方法使用包围盒来定位图像中的对象。传统的包围盒是旋转变化的数据结构,当检测器必须处理目标对象的方向变化时,这成为一个缺点。本文讨论了如何通过引入可旋转包围盒来设计和训练旋转不变检测器。与传统的边界框(BBox)不同,它是一个旋转对象的外接矩形,羧基被定义为在其数据结构中包含方向信息。所提出的检测器(使用羧基的检测器,DRBox)非常适合于检测任意改变物体取向角度的任务。
当相机的视点移动到对象的顶部时,旋转不变属性对于检测变得重要,因此对象的方向变得任意。典型的应用是航空和卫星图像中的目标检测任务。每年有数百颗遥感卫星被发射到太空,并产生大量的图像。这些图像的目标检测非常重要,而现有的检测方法缺乏旋转不变性。在下一段中,我们首先简要概述了目标检测方法,然后讨论了最近的方法如何考虑旋转不变性。
以前的目标检测方法通常使用经济特征和推理方案来提高效率,流行的方法包括可变形零件模型(DPM) [8]、选择性搜索(SS) [24]和边缘盒[28]。随着深度学习技术的发展,深度神经网络已被应用于解决目标检测问题,基于DNN的方法获得了最先进的检测性能。在基于DNN的方法中,基于区域的检测器被广泛使用。基于区域的卷积神经网络方法(R-CNN) [10]利用扩频来生成区域建议,而卷积神经网络(CNN)是一种用于检测的多用途建议。美国有线电视新闻网的速度很慢,部分原因是每个提案都必须单独输入网络,部分原因是这是一种多阶段的管道方法。后续的方法需要花很大的努力来逐步集成检测管道。空间金字塔汇集网络(SPPnets) [13]通过共享计算加速R-CNN。引入空间金字塔池来消除固定大小的输入约束,整个图像只需通过一次网。Fast R-CNN [9]采用了几项创新来提高检测的效果和效率,包括RoI层的使用、多任务损失和截断的SVD。美国有线电视新闻网应用地区提案网络生成提案[19],而不是使用党卫军生成地区提案检测步骤被集成到一个统一的网络中,从而在当时获得最佳的检测结果。多尺度、多纵横比的锚盒在fast R-CNN中是至关重要的,它定位候选对象的位置。在快速网络中,网络可以被划分为一个完全卷积的子网,它独立于建议并共享计算,而每个建议的子网不共享计算。值得注意的是,每个建议的子网是低效的,基于区域的完全卷积网络(R-FCN)是在[6]中提出的,通过使用FCN在整个图像上共享几乎所有的计算来解决这个问题。通过添加一个分支来预测目标的遮罩,遮罩可以同时检测目标并生成目标的分割遮罩[12]。还有另一种基于数字线的目标检测方法,不依赖于区域建议,例如您只看一次检测器(YOLO) [18]和单次多盒检测器(SSD) [16]。我们称YOLO和固态硬盘为基于盒子的方法,因为它们根据一定的规则生成几个盒子来检测图像中的对象。这些盒子被称为优先盒子,对象应该位于某个优先盒子中或附近。固态硬盘试图使用从卷积网络计算的金字塔特征层次,但是没有重用金字塔特征层次中的更高分辨率的地图。特征金字塔网络(FPN) [15]通过引入横向连接更好地利用金字塔特征层级,横向连接将具有粗分辨率的高级语义特征图和具有细分辨率的低级语义特征图合并。
许多最近的基于机器学习的方法已经被用于遥感目标检测。许多机器学习方法提取候选对象特征,例如方向梯度直方图(HOG) [23,4],纹理[3],词袋(BoW) [22],区域协方差描述符(RCD) [1],和兴趣点[25],然后是某些分类器,例如稀疏表示分类器(SRC) [4,3]和支持向量机(SVM) [1]。随着深度学习技术的发展,数字神经网络已经成功地应用于解决遥感图像中的目标检测问题。基于美国有线电视新闻网对卫星图像中车辆检测的开创性研究在[2]中进行了介绍,随后是许多关注不同类型地理空间对象检测问题的方法[14,20,21,5,26,17]。作为另一种有效的特征提取工具,深玻尔兹曼机也被用作地理空间目标检测问题中的特征提取器[11,7]。
为了使该方法对平面内的对象旋转不敏感,需要做出一些努力来调整方向,或者尝试提取旋转不敏感的特征。例如,为了处理地理空间对象的旋转变化问题,引入了旋转不变正则项,该正则项强制样本和它们的旋转版本共享相似的特征[5]。与这些试图消除旋转对特征水平的影响的方法不同,我们更喜欢使旋转信息对特征提取有用,使得检测结果涉及对象的角度信息。因此,检测结果是可旋转的,而检测器的性能是旋转不变的。
周等人提出了一个与我们的方法具有相似性质的网络[27]。ORN用于分类图像,同时提取整个图像的方向角。然而,ORN不能作为检测网络直接应用,它需要检测每个对象的局部方向。在我们的方法中,角度估计与大量的先验框相关联,因此对象的旋转可以通过相应的先验框来实现,而其他先验框对于其他对象仍然可用。此外,我们的方法有效地将目标提案与其背景像素分离,因此角度估计可以集中在目标上而不受背景的干扰。
下一节将解释为什么在旋转不变检测方面,可旋转包围盒(RBox)比BBox更好。在第3节中,我们讨论了羧基如何取代BBox,形成新设计的检测方法DRBox。DRBox在船舶、飞机和车辆的遥感图像检测中得到了验证,与传统的基于BBox的方法相比显示出明显的优势。
可旋转边界框
大多数目标检测方法使用包围盒来定位图像中的目标对象。BBox是由四个变量参数化的矩形:中心点位置(两个变量)、宽度和高度。BBox在定位不同方向角的物体时会遇到困难。在这种情况下,BBox无法提供对象的确切大小,并且很难区分密集的对象。表1列出了BBox的三个主要缺点及其对应的例子。如该表所示,由于旋转,遥感图像中的船只目标与不同大小和纵横比的物体对齐。因此,BBox的宽度和高度与旋转目标的大小无关。另一个明显的缺点是对象和背景之间的区别。在给定的例子中,当船只的方向角接近45度时,BBox内部大约60%的区域属于背景像素。当目标对象分布密集时,这种情况会变得更加困难,在这种情况下,对象很难被立方体分开。
在本文中,定义了羧基以克服上述困难。羧基是一个矩形,用一个角度参数来定义它的方向。一个羧基需要五个参数去精细定位、尺寸和方向。与Box相比,Box更紧密地围绕目标对象的轮廓,因此克服了表中列出的所有缺点。表1详细比较了羧基丁苯橡胶和双羧基丁苯橡胶。因此,我们建议在旋转物体的检测上,羧基丁酸是一个更好的选择。

给定两个盒子,对于检测算法来说,重要是评估它们的距离,该距离用于在训练期间选择正样本,并抑制检测中的重复预测。BBox最常用的标准是交集-并集(IoU),它也可以被羧基使用。两个羧基之间的欠条定义如下:
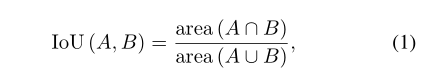
羧基之间的布尔计算比BBox更复杂,因为两个羧基的交点可以是不超过八条边的任何多边形。羧基的另一个标准是角度相关的IoU (ArIoU),定义如下:
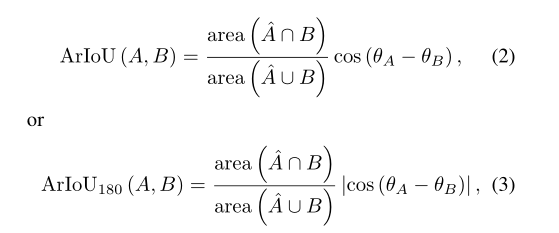
IoU和ArIoU的用法不同。ArIoU用于训练,因此它可以强制检测器学习直角,而IoU用于非最大抑制(NMS),因此可以有效地去除角度不准确的预测。
旋转不变检测
在这一节中,我们将羧基应用于检测,这意味着检测器不仅必须学习位置和大小,还必须学习目标对象的角度。一旦达到这个目的,网络就可以意识到物体之间方位差异的存在,而不是被旋转所迷惑。结果,检测器的性能变得旋转不变。
模型
网络结构:DRBox使用卷积结构进行检测,如图1所示。输入图像通过多层卷积网络产生检测结果。最后一个卷积层用于预测,其他卷积层用于特征提取。预测层包括K组通道,其中K是每个位置中先前通道的数量。先验二元羧酸是一系列预定义的二元羧酸。对于每一个先验羧基值,预测层输出一个置信度预测向量和一个5维向量,置信度预测向量指示它是目标对象还是背景,5维向量是预测羧基值和相应的预定义先验羧基值之间的参数偏移。解码过程是必要的,以将偏移转换为准确的预测羧基。最后,对预测的羧基进行置信度排序,并通过NMS消除重复预测。
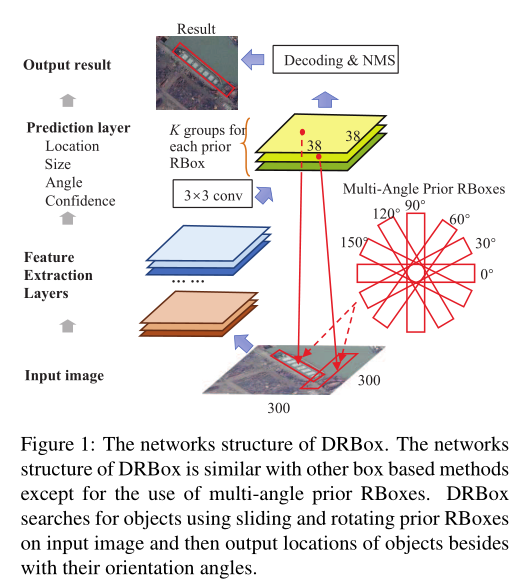
多角度先验羧基在DRBox中起着重要的作用。卷积结构确保先前的盒子可以移动到不同的位置来搜索目标对象。在每个位置上,先前的边界框以一系列角度旋转,以生成多角度预测,这是DRBox和其他基于边界框的方法之间的关键区别。检测中使用的纵横比根据对象类型是固定的,这减少了先前框的总数。通过多角度先验贝叶斯策略,训练网络将检测任务作为一系列子任务来处理。每个子任务集中在一个狭窄的角度范围内,因此降低了由物体旋转引起的难度。
训练
DRBox的训练从SSD训练程序[16]扩展到涉及角度估计。在训练过程中,每个地面实况转播车根据各自的优先顺序被分配了几个优先转播车。ArIoU是一个非交换函数,这意味着ArIoU(A,B)与ArIoU(B,A)不同。当ArIoU(P,G) > 0.5时,先前的真值赋给一个基本真值。分配后,匹配的先验二元羧酸被视为正样本,并负责产生位置和角度回归的损失。ArIoU的使用有助于训练过程选择具有适当角度的先验羧基作为正样本,因此可以在训练过程中粗略地学习对象的角度信息。在匹配步骤之后,大多数先前的羧基是负的。我们应用硬阴性挖掘来减少阴性样本的数量。
DRBox的目标损失函数是在SSD目标损失函数的基础上增加角度相关项而得到的。总体目标损失函数如下:
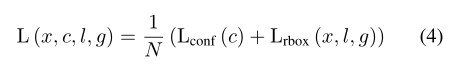
其中N是匹配的先前羧基的数目。置信损失Lconf©是所有选定的正样本和负样本的两类软最大损失,其中c是二维置信向量。羧基回归损失Lrbox(x,l,g)类似于固态硬盘和更快的R-CNN,其中我们计算预测羧基l和地面真实羧基g之间的平滑L1损失: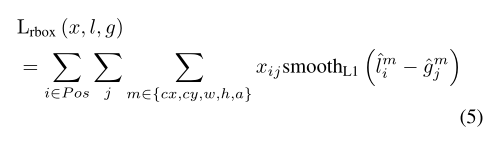
其中xij∑{ 1,0}是用于将第I个先验羧基与第j个地面真羧基匹配的指标,l和g定义如下,分别是l和g中的参数与其对应的先验羧基p的偏移量: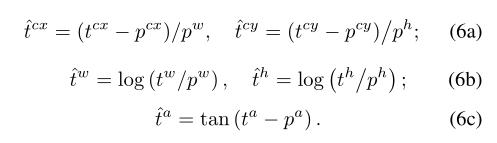
等式6a、6b和6c分别是位置回归项、尺寸回归项和角度回归项。角度回归项应用正切函数来适应角度参数的周期性。角度回归项的最小化确保了在训练中学习到正确的角度。
补充细节
金字塔输入:DRBox采用金字塔输入策略,将原始图像重新缩放到不同的分辨率,并分成重叠的300 × 300个子图像。DRBox网络应用于每个子图像,并且该网络仅检测具有适当大小的目标。对整幅图像的检测结果进行非最大值抑制,不仅抑制子图像内的重复预测,还抑制不同子图像的交叉重叠区域。金字塔输入策略有助于检测网络在大对象和小对象之间共享特征。此外,本文使用的卫星图像往往非常大,因此子图像之间的分割过程和非最大抑制有助于在非常大的图像中检测对象。
卷积架构:DRBox使用截断VGG网进行检测。移除层conv4 3之后的所有全连接层、卷积层和汇集层。然后,在层conv4 3之后添加一个3 × 3卷积层。DRBox的感受野是108像素108像素,所以任何大于这个范围的目标都检测不到。此外,图层conv4 3的特征图为38 × 38,因此可能会错过距离小于8个像素的目标。
优先羧基设置:在本文中,三个DRBox网络分别被训练用于车辆检测、船只检测和飞机检测。比例和输入分辨率设置共同确保了先前的区域充分覆盖对象的尺寸,从而可以有效地捕获不同尺寸的对象。在舰船检测中,很难区分目标的头部和尾部。在这种情况下,地面真值和多角度先验真值的角度从0度到180度不等。具体来说,利用大小为20 × 8、40 × 14、60 × 17、80 × 20、100×25像素和角度为0:30:150度的先验模糊度来检测舰船目标;使用大小为25 × 9像素、角度为0:30:330度的先验模糊度来检测车辆对象;飞机物体是用50 × 50,70 × 70像素大小和0:30:330度角度的现有雷达散射截面来探测的。对于船只、车辆和飞机检测,每幅图像的先验框总数分别为43320、17328和34656。
NVIDIA GTX 1080Ti和英特尔酷睿i7上的DRBox达到70-80 fps。输入金字塔策略产生的时间成本不超过4/3倍。考虑到子图像之间1/3的重叠,DRBox达到每秒1600 × 1600像素的处理速度。固态硬盘和更快的R-CNN的速度在我们的数据集上分别为70帧/秒和20帧/秒,使用相同的卷积网络架构。
实验和结果
数据集
我们将我们的方法应用于卫星图像的目标检测。我们还没有找到关于这个问题的任何开源数据集,所以我们使用GoogleEarth图像构建了一个。数据集包括三类对象:车辆、船只和飞机。这些车辆来自中国北京的市区。船只聚集在长江、珠江和东海之外的码头和港口附近。这些飞机是从中国和美国的15个机场的图像中收集的。该数据集最近包括约12000辆汽车、3000艘船只和2000架飞机,并仍在扩展中。约2000辆车、1000艘船和500架飞机作为测试数据集,其他用于训练。
图像中的每个对象都用一个羧基标记,羧基不仅指示对象的位置和大小,还指示对象的角度。开发了一个Matlab工具,用羧基标签标记数据。
基准
在本节中,我们将DRBox的性能与使用BBox的检测器进行比较。SSD和fast R-CNN被用作基于BBox的方法的基准。所有检测器使用相同的卷积结构和相同的训练数据论证策略。SSD中使用的优先框和fast R-CNN中使用的锚框针对数据集进行了优化。所有其他超参数也针对数据集进行了优化。
检测结果
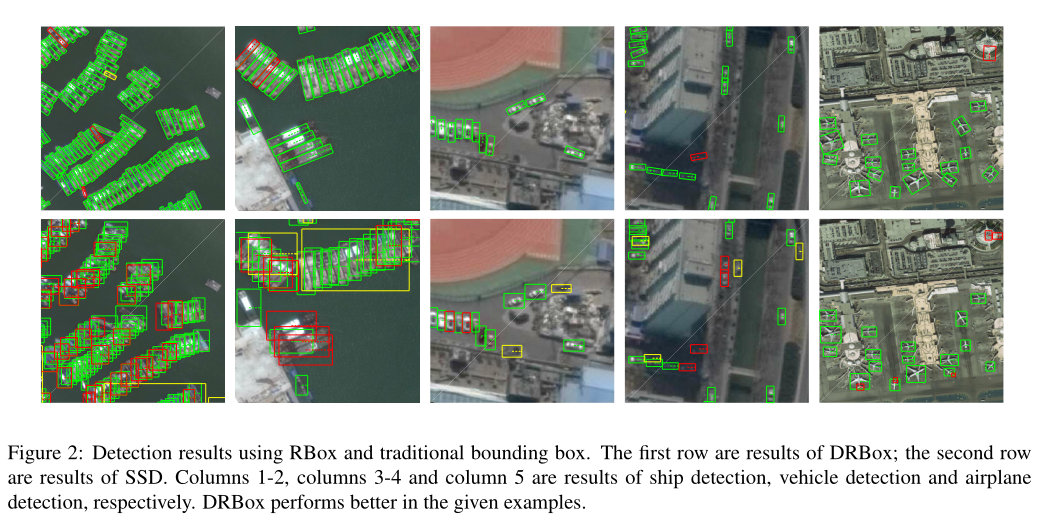
图2显示了使用RfID(DrBox)和BBox (SSD)检测到的船只、车辆和飞机。与IoU > 0.5的地面真实边界框匹配的预测边界框以绿色绘制,而假阳性预测和假阴性预测分别以黄色和红色绘制。我们的方法在给定的场景中更好。DRBox成功检测到港口区域和开阔水域的大部分船只,而SSD几乎无法检测到附近的船只。对车辆和飞机的检测结果也表明,固态硬盘比DRBox产生更多的误报警和误解雇。
DRBox的更多结果见图3。港口区域的船舶检测比开放水域更具挑战性,而DRBox在这两种情况下都能很好地工作。由于车辆体积小,背景复杂,很难检测到。在我们的数据集中,每辆车长约20像素,宽约9像素。幸运的是,我们发现DRBox成功地找到了隐藏在高楼阴影中的车辆,或者停得非常近的车辆。我们还发现DRBox不仅可以输出车辆的位置,还可以预测每辆车的头部方向,这对于人类来说甚至是一项具有挑战性的任务。汽车在道路上的估计方向与交通总是保持在道路右侧的先验知识相匹配。成功检测到不同尺寸的飞机,包括一架正在维修的飞机。
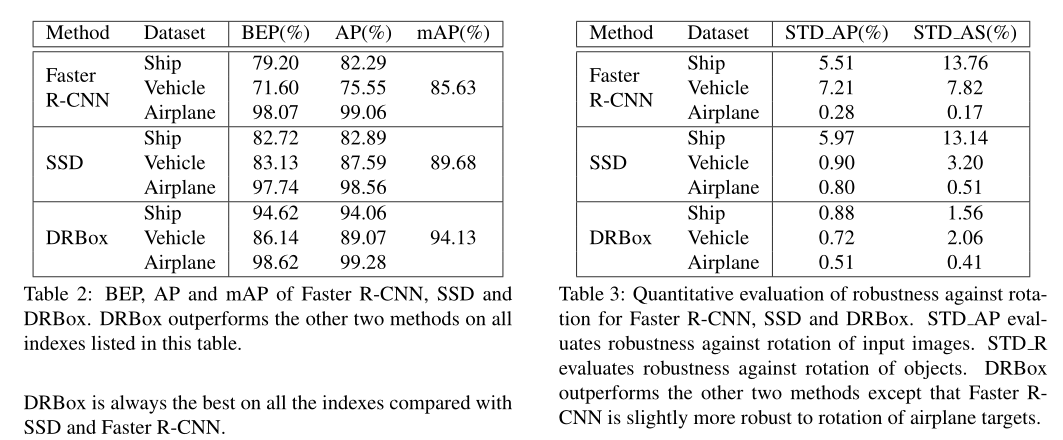
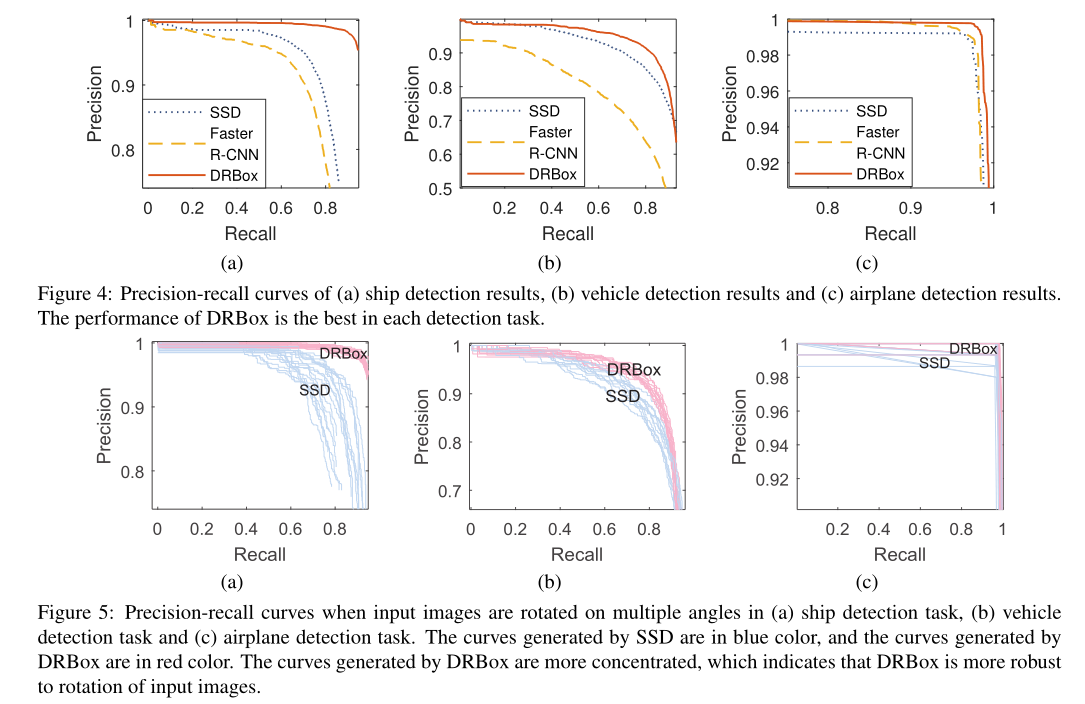
图4显示了DRBox、SSD和fast R-CNN的精度-召回率(P-R)曲线。召回率评估在图像中找到更多目标的能力,而精确度评估仅预测正确对象的质量,而不是包含许多错误警报。SSD和fast R-CNN的P-R曲线始终低于DRBox的P-R曲线。DRBox在这次测试中表现最好。我们在表2中进一步显示了每种方法的盈亏平衡点、平均精度和平均精度。BEP是P-R曲线上精度等于召回率的点,AP是P-R曲线下方的区域,mAP是所有物体检测任务中APs的平均值。相比SSD和fast R-CNN,DRBox在所有指标上始终是最好的。
旋转鲁棒性的比较
方法对旋转的鲁棒性包括两个方面:对输入图像旋转的鲁棒性和对对象旋转的鲁棒性。对输入图像旋转的鲁棒性意味着当输入图像任意旋转时,检测方法应该输出相同的结果。我们定义STD AP来量化这种能力。STD AP是输入图像角度变化时AP的标准差。STD AP是通过将测试图像旋转每10度来估计的,然后分别计算检测结果的AP值和AP的标准偏差。对对象旋转的鲁棒性意味着当同一对象的方向改变时,应该总是能够成功地检测到该对象。我们将性病定义为量化这种能力。STD AS是对象在不同方向角下的平均得分的标准差,它是通过将测试数据集中的对象根据它们的角度分成不同的组,然后分别计算每组的平均得分(softmax阈值)以及所有组的标准差来估计的。这两种鲁棒性评价方法是相互关联的,不同的是,STD AP偏向于对背景旋转的鲁棒性,而STD AS偏向于对物体旋转的鲁棒性。较小的标准差和标准差值表明该检测方法对旋转的鲁棒性更强。
DRBox、SSD和fast R-CNN的STD AP和STD AS值如表3所示。所有这三种方法对飞机检测中的旋转都是鲁棒的。然而,更快的R-CNN对船只和车辆检测的旋转相对不鲁棒,SSD对船只检测的旋转不鲁棒。DRBox在所有任务中保持高分。
图5和图6展示了DRBox和固态硬盘之间的进一步比较。图5显示了相同输入图像但旋转到不同位置的公关召回角度,其中DRBox和SSD的结果分别以浅红色和浅蓝色绘制。DRBox生成的曲线更加集中,这表明DRBox比SSD对输入图像的旋转更加鲁棒。
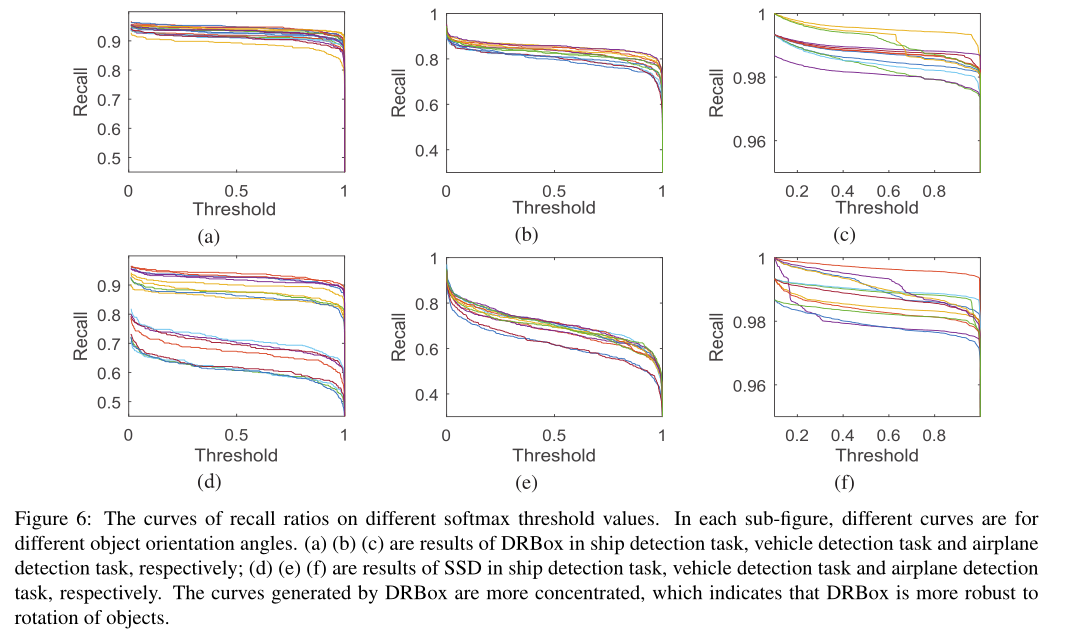
我们分别计算了不同角度范围内目标的召回率。图6显示了结果。每个角度范围对应于一条曲线,该曲线显示了软最大阈值和召回率之间的关系。DRBox的性能在每个角度范围内大致保持不变,而SSD的性能在对象角度变化时表现出很强的不稳定性。
结论
对旋转的鲁棒性在任意方向物体的检测任务中非常重要。现有的检测算法使用包围盒来定位对象,这是一种旋转变体结构。在本文中,我们将传统的包围盒替换为盒子,并使用这种新的结构重建基于深层CNN的检测框架。这种被称为DRBox的检测器是旋转不变的,因为它能够估计物体的方向角。DRBox在卫星图像的目标检测上优于fast R-CNN和SSD。
DRBox被设计为一种基于盒子的方法,然而它也可以应用于基于提议的检测框架,例如FCN研究中心或美国有线电视新闻网研究中心。使用羧基训练加强网络学习输入图像的多尺度局部方向信息。我们期待这一有趣的特性被用于其他方位敏感的任务。


















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









