







编者按:
在服务运营与产品组合优化的研究中,多项Logit模型(MNL)作为消费者选择行为建模的经典工具,近年来被不断拓展与创新,以适应更复杂的实际场景。本文将围绕三篇顶刊近期相关文章,探讨如何利用MNL模型及其变体,实现更高效、更精确的产品组合优化。
第一篇文章(MS, 2024)提出了基于点击的MNL模型,利用用户的点击流数据(Clickstream Data)建模消费者的考虑集生成过程,并通过多项式时间近似算法(PTAS)解决了商品组合优化的NP难问题。
第二篇文章(OR, 2023)扩展了传统MNL模型,提出了多重购买MNL模型(MP-MNL),以应对消费者一次性购买多件商品的需求场景。通过设计高效的近似算法,该研究为平台在多件购买场景下的选品决策提供了理论支持与实用工具。
第三篇文章(MSOM, 2024)则聚焦于数据内生性和未观察到的购买行为问题,提出了一种稳健的广义矩估计方法(PR),在不依赖市场份额数据的情况下,成功解决了动态优化场景下的估计问题,为复杂环境中的产品组合优化提供了新思路。
The Click-Based MNL Model: A Framework for Modeling Click Data in Assortment Optimization
Reference: Ali Aouad, Jacob Feldman, Danny Segev, Dennis J. Zhang (2024) The Click-Based MNL Model: A Framework for Modeling Click Data in Assortment Optimization. Management Science Published online in Articles in Advance 25 Nov 2024 .
原文链接: https://doi.org/10.1287/mnsc.2021.00281
Problem
在电子商务中,平台需要根据客户的行为(如点击和购买)来优化展示的商品组合以最大化收益。近年来,电商平台能够收集到丰富的用户点击流数据(clickstream data),这些数据不仅包含用户的购买行为,还记录了用户在购物过程中对商品的浏览和点击行为。点击行为反映了用户的兴趣和筛选过程,因此可以作为用户生成考虑集的信号。传统的多项Logit模型(MNL)假设消费者会在所有可选商品中进行选择,但忽略了实际中消费者常常只考虑他们点击过的商品。基于此,本研究建立了一个基于点击的MNL模型。
Method
(1)基于点击的MNL模型(Click-Based MNL Model)
假设每个物品 i ∈ [ n ] i \in [n] i∈[n]对应销售价格 r i r_i ri、基于MNL的偏好权重 w i w_i wi和考虑概率 λ i \lambda_i λi。在给定商品组合 S ⊆ [ n ] S \subseteq [n] S⊆[n]的情况下,代表性顾客分两阶段做出购买决策:
假设客户的选择过程分为两个阶段:
- 第一阶段:客户根据商品的点击概率形成一个考虑集(Consideration Set) C S ⊆ S C_S \subseteq S CS⊆S。假设顾客选择考虑集 C S C_S CS中的每个元素的可能性是相互独立的, C S C_S CS的总权重为 w ( C S ) = ∑ i ∈ C S w i w(C_S)= \sum_{i \in C_S}w_i w(CS)=∑i∈CSwi。
- 第二阶段:客户在考虑集内根据传统MNL模型进行购买决策。每个物品 i i i的被购买概率为 w i 1 + w ( C s ) \frac{w_i}{1+w(C_s)} 1+w(Cs)wi,顾客有 1 1 + w ( C s ) \frac{1}{1+w(C_s)} 1+w(Cs)1的概率选择不购买任何物品。选择物品 i i i的概率可以被建模为:
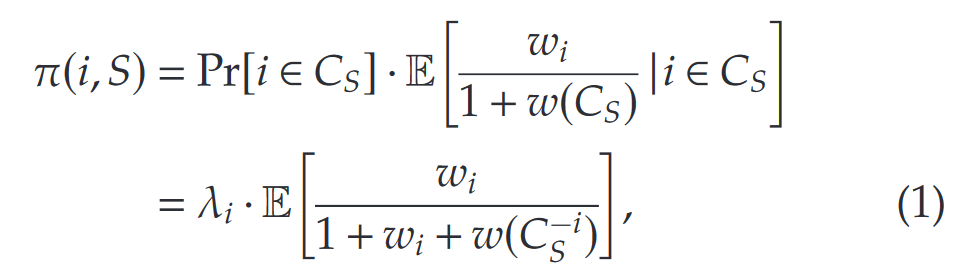
服务商需选定一个产品组合
S
⊆
[
n
]
S \subseteq [n]
S⊆[n]使得期望收益
R
(
S
)
R(S)
R(S)最大化:
R
(
S
)
=
∑
i
∈
S
r
i
π
(
i
,
S
)
R(S)=\sum_{i\in S}r_i \pi (i,S)
R(S)=i∈S∑riπ(i,S)
(2)分析与算法
基于点击的MNL模型可以看作是mixture (latent class) MNL模型的一种变体。文章首先证明了基于点击的MNL模型下的商品组合优化问题是NP难问题,随后提出了一个多项式时间近似方案(PTAS),能够在任意精度下高效逼近最优解。并开发了一种结合点击流数据和机器学习方法的参数估计方法,用于拟合模型。
(a)NP难证明
通过属于Karp’s 21个NP难问题之一的集合划分问题进行规约,证明基于点击的MNL问题是NP难的,困难主要来源于该MNL选择模型中的的基本概率结构。
(b)多项式时间近似算法
算法首先通过对商品的点击概率、偏好权重和价格进行离散化,将这些参数简化为离散的指数形式,从而减少可能的参数值范围。随后,算法通过枚举生成一组统计量向量,这些向量描述了最优商品组合在不同类别上的收益贡献和影响系数。在处理点击概率较低的商品时,算法将问题转化为一个最小化背包问题,通过动态规划在满足收益约束的前提下最小化商品之间的替代效应;而对于点击概率较高的商品,算法通过贪心策略逐步选择收益最高的商品,直到满足收益贡献要求。最后将低点击商品和高点击商品的优化结果合并,生成最终的商品组合,并通过条件期望法进一步转化为确定性解。整个算法在多项式时间内完成,能够在保证近似精度的同时高效优化期望收益。
Main Result
使用阿里巴巴的真实数据集(包括点击和购买记录)进行建模和实验,比较了三种模型的表现:传统的MNL模型、基于点击的MNL模型以及潜在类别MNL模型(Latent Class MNL),结果表明,基于点击的MNL模型在预测准确性上优于传统MNL,并且与更复杂的潜在类别模型表现相当。
Why recommend?
1、点击流数据(Clickstream Data)是现代电商平台的重要数据来源,包含了客户的浏览、点击和购买行为。如何有效利用这些数据来改进商品组合优化,是一个尚未充分研究的领域,作者基于这一数据提出了基于点击的MNL模型。
2、提出的PTAS算法在理论上有良好的性能保证,并且在大规模数据集上的运行时间也在可接受范围内。
3、使用阿里巴巴真实数据进行数值实验。实验表明,相比传统的MNL模型,基于点击的MNL模型在某些场景下能显著提升预测准确性,并能更好地捕捉客户行为。
Assortment Optimization Under the Multi-Purchase Multinomial Logit Choice Model
Reference: Yicheng Bai, Jacob Feldman, Danny Segev, Huseyin Topaloglu, Laura Wagner (2023) Assortment Optimization Under the Multi-Purchase Multinomial Logit Choice Model. Operations Research 72(6):2631-2664.
原文链接:https://pubsonline.informs.org/doi/full/10.1287/opre.2023.2463
Problem
在传统的多项Logit(Multinomial Logit, MNL)模型中,我们假设消费者到来时至多只会从候选集合 S 中选购 一件 商品。比如,在机票或一次性消费场景中,这种假设相对合理。但在实际的零售业或电子商务平台上,顾客常常同时买走多件互为替代的产品,比如一次下单买好几件衣服、几瓶饮料或多个美妆小样等。若继续沿用“只买一件”的 MNL 假设,往往无法准确捕捉这些多重购买带来的需求相关性,也会影响最终的选品及收益。
为此,论文作者提出了 “多重购买 MNL (MP-MNL)” 模型,将消费者的“最大购买件数”记作一个随机变量 M,并在随机效用最大化的基础上,允许消费者 一次性 选择多于一件商品。在此模型下,如何在给定的 n 个产品中,找出子集 S⊆{1,2,…,n}来 最大化预期收益,成为本文要解决的核心优化问题。
Method
在传统单一购买(MNL)模型的基础上,作者提出了「多重购买 MNL(Multi-Purchase MNL,以下简称 MP-MNL)」模型,并围绕该模型的最优选品问题设计了多项近似算法。其核心步骤可大体分为以下几个方面:
1. 多重购买模型的构建
- 最大购买数量 M
每位顾客首先从一个已知的离散分布中抽取随机变量 M,代表其最多愿意同时购买多少件商品。当 M=0 时,顾客不买任何商品;当 M>0时,顾客可在效用较高的商品中最多选择 M 个。
- 随机效用与对数几何结构
与经典 MNL 相同,每件产品的效用由一个确定性部分(可转化为“权重” wi)加上 Gumbel 随机噪声组成,从而保留了对数形式的可加性。
- 多件购买决策规则
若顾客抽到 M=m,则在所有效用高于“不买”选项的商品中选择优先级最高的 m 个。若可选商品数不足 m,则把全部效用超过“不买”的商品都买下。
2. 选品(Assortment)优化问题
- 目标是给定商品集合,每个商品具有一定收益(价格)ri 和偏好权重 wi,希望从中选出子集使得顾客的期望购买收益最大化。难点是当 M 的分布较一般时,顾客可能同时买多件,对应商品的选择概率会相互影响,从而导致问题复杂度上升。尤其当有额外的线性/组合约束时,问题在多购买场景下会变得 NP-hard 难以精确求解。
3. 近似算法思路(PTAS 框架)
作者在不同场景下设计了多种「多项式时间近似方案(PTAS)」,主要利用以下关键技巧:
- 猜测与分层
- 当顾客最多只买少量商品时,可先猜测最有可能被购买的商品集合,再对剩余商品做“总权重”或“总收益”上的动态规划或枚举,以在多项式时间内逼近最优解。
- 若不受限,则将商品按其偏好权重从小到大分成若干层,并在每层内采用“收入降序”的选品方式,通过逐层枚举与合并的方式,限制可行解空间,并保证逼近度。
- 选择概率的稳定性与估计
- 通过对商品权重进行适度“向下取整”,可证明每件商品的选择概率不会有太大偏离,从而在算法中使用简化或抽样估计时,误差能被控制在可接受范围内。
- 在求解最终组合的过程中,可使用抽样或小规模迭代更新来近似计算大规模集合下的期望收益,获得 (1−ε)的近似结果。
- “Knapsack”式求解
- 将问题转换为类似于“背包问题”的形式:对一些关键商品或关键层进行排列组合,满足一定的约束后,求解最优或近似最优子集。
- 在此过程中,结合 DP 技术与上述猜测策略,可显著缩小搜索空间并快速找到近似最优解。
Main Result
首先,作者在合成的 MP-MNL 数据上,以传统混合 MNL(Mixed-MNL)进行拟合,然后用该模型来做选品。结果显示:对多数测试情形,混合 MNL 对多件购买数据的预测误差可达 20%-30%,造成在选品决策上产生 10%-20% 的收益损失;说明如果真实顾客很多都买 2 件或 3 件,那么仍假设每人只买 1 件会明显“低估”了一些被多次加入购物车的产品需求。
其次,针对不同规模 n、不同最大购买数 、不同分布的 M,作者测试了以下方法:PTAS-论文里提出的多项式时间近似解;Greedy-每次挑选能带来最大边际收益的商品,直到选满或无改进;单一购买 MNL 最优解-将问题简化为普通 MNL 的选品算法。实验结论为:
- PTAS 在几乎所有情况下表现最好:收益通常比贪心或单一购买方案高 1%-5% 之间,有时极端能达 5%以上;
- 当最大购买量增加,单一购买假设的准确度下降更快,而 PTAS 相对依旧稳定;
- 选品差异:从实验剖析来看,PTAS 会选择一些“价格稍低但权重高”的商品以捕捉多购需求,而单一购买则往往倾向“单价更高但权重相对小”的几款商品。
最终,通过对最终的选品做对比分析,作者发现当平均购买件数较高时,下列策略往往带来增益:
- 补充若干低单价但高偏好权重的产品,因为在多重购买场景里,消费者在买了 1-2 件较贵的产品后,如果还可以多买几件,就会倾向于把某些高权重(他们本身喜欢度高)、但价格不贵的产品也顺手加入购物车;
- 单一购买模型忽视了这种“多件并购”效应,导致只挑选了若干高价产品,无法得到额外的小件销量;
- 数值实验充分验证了此思路:选品里多保留一些小而精的商品,能吸引消费者把购物车进一步填满,产生更多的边际收入。
Why recommend?
- 问题具有实践意义
随着电商平台“跨品类凑单”、“多件打折”等营销手段的流行,消费者一次下单购买多件互为替代(或部分替代)的商品是一种常见现象,旧有的单一购买假设难以准确预测。
- 模型创新与可操作性并存
MP-MNL 模型的提出很好地兼容了传统 MNL 的结构,可与随机效用最大化理论相衔接;同时论文给出了递归形式的选择概率计算公式,使其具有明确的可实施性。
- 在选品决策上提供理论与算法新思路
作者不仅证明了 MP-MNL 模型下选品问题的复杂度,还通过设计近似算法(PTAS)给出实用的多项式时间方法,可以应用到真实零售商、平台的选品流程中。
Assortment Optimization with Multi-Item Basket Purchase Under Multivariate MNL Model
Reference: Anran Li, Kalyan Talluri , Müge Tekin (2024) Estimating Demand with Unobserved No-Purchases on Revenue-Managed Data. Manufacturing & Service Operations Management 27(1):161-180.
原文链接:https://doi.org/10.1287/msom.2021.0291
Problem
目前,产品组合存在三大挑战:
- 无法观测未购买行为: 无法得知有多少顾客考虑了产品但最终没有购买 (no-purchase)。
- 数据内生性: 企业会根据历史销售数据动态调整价格和产品组合,导致数据不再独立同分布,这种内生性使得传统估计方法(如最大似然估计MLE)失效。
- 缺乏市场份额数据:尤其在时尚零售等行业,市场份额数据定义模糊或不可获得。
本文提出了一种新的矩估计方法来解决这三大挑战。
Method
基础模型设定:
假设顾客到达过程为泊松过程(Poisson Process),可能存在异质性,顾客选择遵循MNL模型:
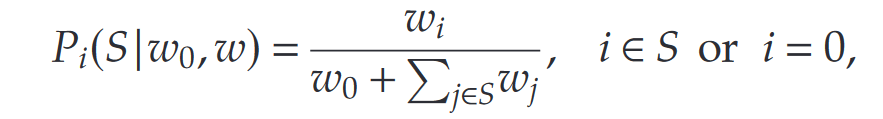
其中 w i w_i wi表示产品 i i i的权重, w 0 w_0 w0表示未购买选项的权重。
问题目标是联合估计消费者到达率 λ k \lambda_k λk、各产品权重 w i w_i wi和未购买权重 w 0 w_0 w0。
本文提出了一种稳健的两阶段广义矩估计(Generalized Method-of-Moments, GMM)方法,称为Policy-Robust Estimation (PR),主要步骤包括:
-
估计产品权重 w i w_i wi:
假设产品权重 w i w_i wi只与已观察到的销售数据相关。基于条件销售数据,通过最大化对数似然函数估计 w i w_i wi。对数似然函数为:
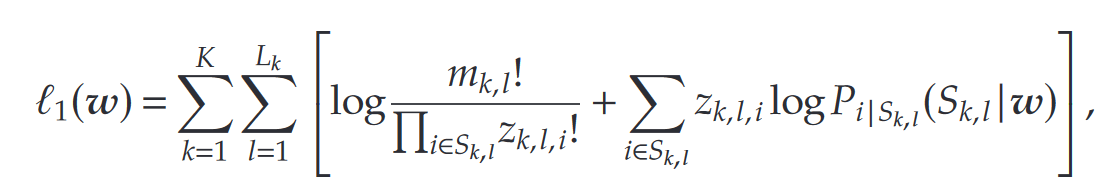
其中 z k , l , i z_{k,l,i} zk,l,i为第 k k k个实例中再时间窗口 l l l内产品 i i i的销售量。
-
估计未购买权重 w 0 w_0 w0和顾客到达率 λ k \lambda_k λk:
固定第一阶段估计的产品权重,构建一个新的矩条件(moment condition),估计未购买选项的权重(no-purchase weight)和顾客到达率。
该估计方法的优势为:不需要市场份额数据;不需要工具变量来处理内生性;在企业动态优化产品组合或价格的情况下依然稳健。
Main Result
作者进行了两组数值实验:
- 蒙特卡洛模拟(Monte Carlo Simulations):
- 在随机生成产品组合的场景下,PR方法性能与现有方法相当。在企业动态优化产品组合的场景下,PR方法明显优于不使用市场份额的现有方法,且接近甚至优于使用市场份额的先进方法(如Abdallah and Vulcano (2021)、Cho et al. (2024))。
- 真实数据验证(Real-world Data):
- 基于欧洲一家时尚零售商的大型数据集(存在库存缺货和降价促销),PR方法在没有市场份额数据的情况下,依然表现出稳健的估计效果。PR方法在预测准确性上与其他方法相比表现优异,尤其是在内生性显著的场景下。
Why recommend?
在许多行业中,企业会根据销售数据动态调整价格或产品集合(如库存不足时减少产品种类)这种调整可能导致销售数据与企业的优化决策相关,从而引入内生性问题。文章提出了一种新的矩条件,能够在不依赖工具变量(Instrumental Variables, IVs)的情况下解决内生性问题。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









