






hello,今天我们来分享一个更加完善的单细胞轨迹分析的软件,cellrank,文章在CellRank for directed single-cell fate mapping,方法很经典,我们先来分享文献,后续介绍一下示例代码。
Abstract
计算轨迹推断能够从单细胞 RNA 测序实验中重建细胞状态动态。 然而,轨迹推断需要已知生物过程的方向,这在很大程度上限制了其在正常发育中区分系统的应用。 在这里,利用软件 CellRank用于映射单细胞在不同情况下的命运,包括方向未知的干扰,如再生或疾病。 软件的方法将轨迹推断的鲁棒性与来自 RNA 速度的方向信息相结合,这些信息来自剪接与未剪接读数的比率。 CellRank 考虑了细胞命运决定的渐进性和随机性,以及 RNA 速度向量的不确定性。 根据胰腺发育的数据,表明它可以自动检测初始、中间和终端细胞群,预测命运潜力并可视化沿各个谱系的连续基因表达趋势。 CellRank 还预测了肺损伤后再生过程中新的去分化轨迹,可以通过确认先前未知的中间细胞状态的存在进行实验跟踪。
Introduction
细胞在许多生物过程中经历状态转换,包括发育、重编程、再生、细胞周期和癌症,并且它们通常以高度异步的方式进行。单细胞 RNA 测序 (scRNA-seq) 在捕捉这些过程在单个细胞中展开时的异质性方面非常成功。然而,scRNA-seq 由于其破坏性而丢失了谱系关系——细胞不能被多次测量。目前已经提出了实验方法来缓解这个问题; scRNA-seq 可以与谱系追踪方法结合使用,这些方法使用可遗传的条形码来跟踪长时间尺度的克隆进化,代谢标记使用新生和成熟 RNA 分子之间的比率来统计连接短时间windows内观察到的基因表达谱。然而,这两种策略大多仅限于体外应用,促进了重建伪时间轨迹的计算方法的发展。这些方法基于对发育相关细胞倾向于共享相似基因表达谱的观察,并且它们已被广泛用于计算细胞沿分化轨迹的伪时间排序和研究细胞命运决定。
计算轨迹推断通常需要使用先验生物学知识来确定细胞状态变化的方向性,通常是通过指定初始细胞(大多数软件都要求指定分化起点,monocle2虽然默认有起点,但通常都是错的)。 这在很大程度上限制了此类方法在具有已知细胞层次结构的正常发育场景中的成功。 最近引入的 RNA 速度概念通过基于剪接与未剪接 mRNA 分子的比率重建状态变化轨迹的方向来缓解这个问题(大家最熟悉的RNA velocyto,python版本的scvelo)。 该方法已被推广到包括瞬时细胞群和蛋白质动力学; 然而,速度估计是嘈杂的,高维速度向量的解释主要限于低维预测,这不容易揭示远程概率命运或允许定量解释。
在这里,软件CellRank,这是一种将先前基于相似性的轨迹推理方法的稳健性与 RNA 速度给出的方向信息相结合的方法(相似性 + velocyto),以在正常或扰动条件下学习定向的概率状态变化轨迹。 CellRank 推断 scRNA-seq 数据集的初始、中间和终端细胞并计算命运概率,我们用它来揭示假定的谱系驱动因素并可视化谱系特异性基因表达趋势。对于这些计算,考虑了细胞命运决定的随机性以及速度估计的不确定性。利用CellRank 在胰腺内分泌谱系发育方面的分析能力,确定了已建立的终末和初始状态,并正确恢复谱系偏差和产生生长抑素的 delta 细胞分化的关键驱动基因。此外,将 CellRank 应用于肺再生,软件预测了一种新的去分化轨迹,并通过实验验证了以前未知的中间细胞状态的存在。表明 CellRank 优于不包含速度信息的方法。
Results
CellRank将细胞间相似性与 RNA 速度相结合来模拟细胞状态转变
CellRank 算法旨在对系统的细胞状态动态进行建模。 首先,CellRank 检测系统(就是细胞群)的初始、终端和中间细胞状态,并计算命运潜能的全局图,为每个细胞分配达到每个终端状态的概率。 根据推断的潜能,CellRank 可以绘制细胞呈现不同命运时的基因表达动态图,并且可以识别细胞命运决定的推定调节因子。 该算法使用 scRNA-seq 计数矩阵和相应的 RNA 速度向量矩阵(RNA velocyto)作为输入。 但是注意,虽然在这里使用 RNA 速度来近似细胞动力学的方向,但 CellRank 可以概括以适应任何方向性测量,这些测量给出了该过程的矢量场表示,例如metabolic labeling or real time information。
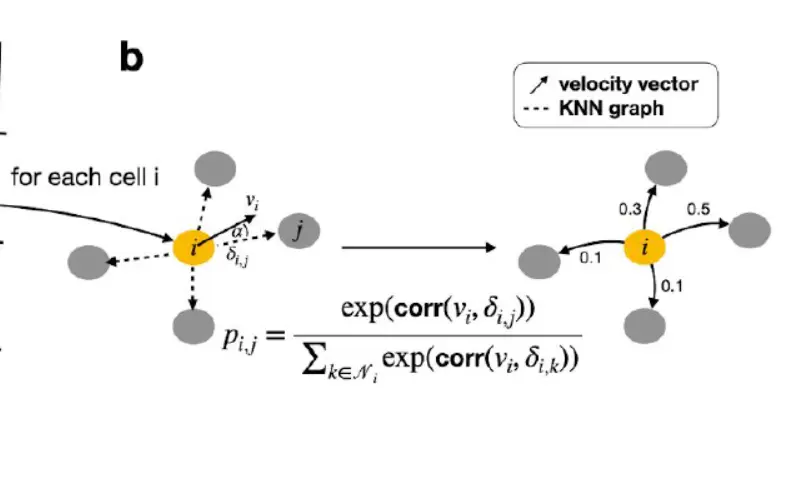
稳定地捕获轨迹的所有伪时间算法的主要假设是细胞状态随着许多过渡种群而产生逐渐的变化。 CellRank 使用相同的假设来使用马尔可夫链对状态转换进行建模,其中链中的每个状态由一个观察到的细胞轮廓给出,边缘权重表示从一个细胞转换到另一个细胞的概率。 链构建的第一步是计算表示表型流形中细胞-细胞相似性的无向 k-最近邻(KNN)图(下图)。
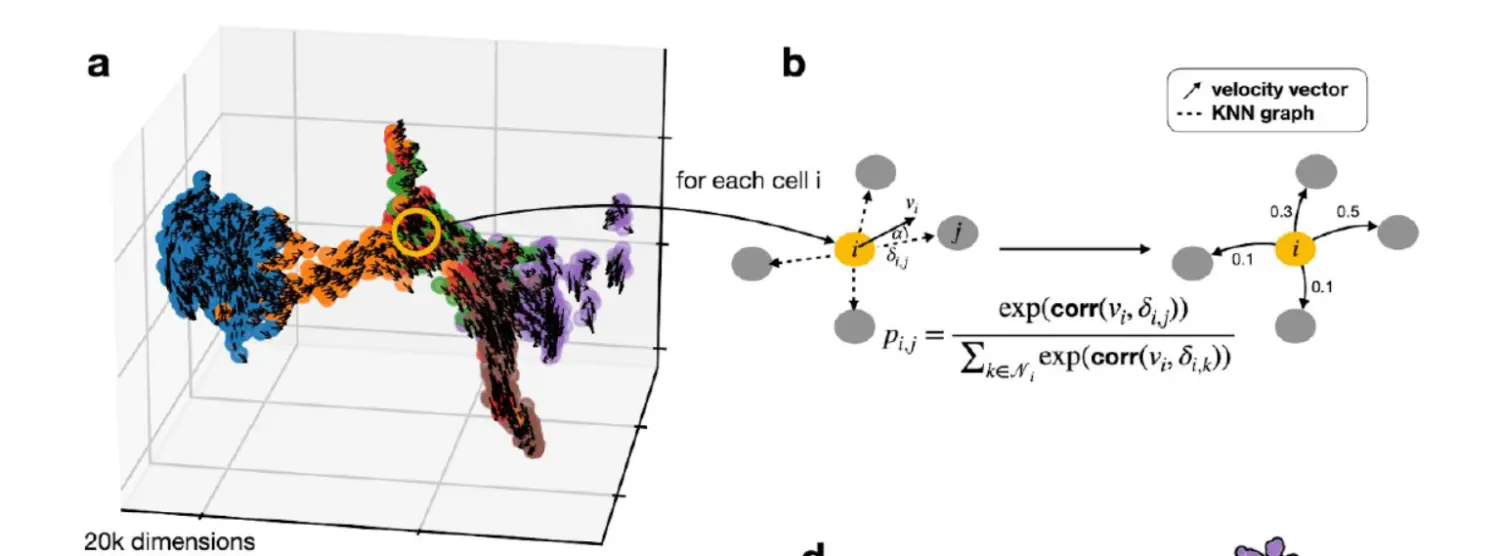

图中的每个节点代表一个观察到的细胞轮廓,边缘连接最相似的细胞。
与伪时间算法不同,我们通过使用 RNA 速度来引导马尔可夫链边缘来注入方向性。 给定细胞的 RNA 速度向量可预测哪些基因当前被上调或下调,并指向该细胞可能的未来状态。 相邻cell在速度向量方向上越多,其转移概率就越高。 我们根据细胞之间的基因表达相似性计算第二组转移概率,并通过加权平均值将其与第一组相结合。 由此产生的定向转移概率矩阵与任何低维嵌入无关,并反映了转录相似性以及由 RNA 速度给出的方向信息。
转移矩阵可能非常大、嘈杂且难以解释。 通过将单个基因表达谱总结为宏观状态来缓解这些问题,即细胞不太可能离开的regions of the phenotypic manifold(下图)。
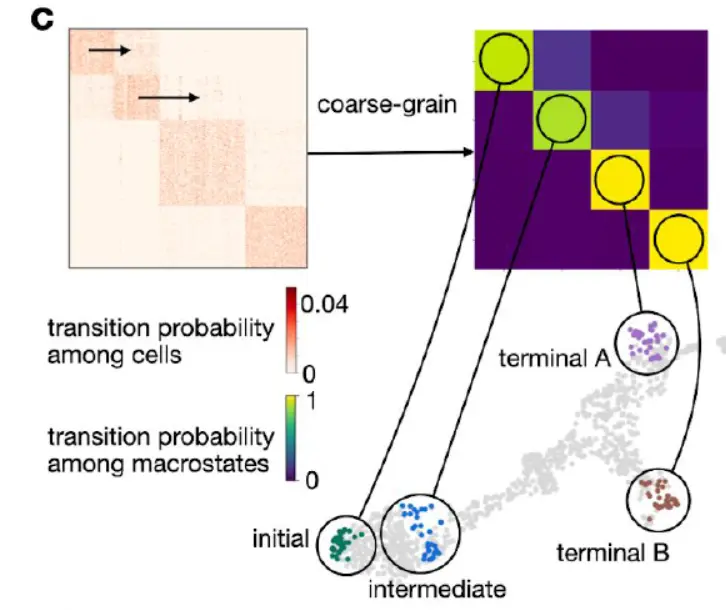
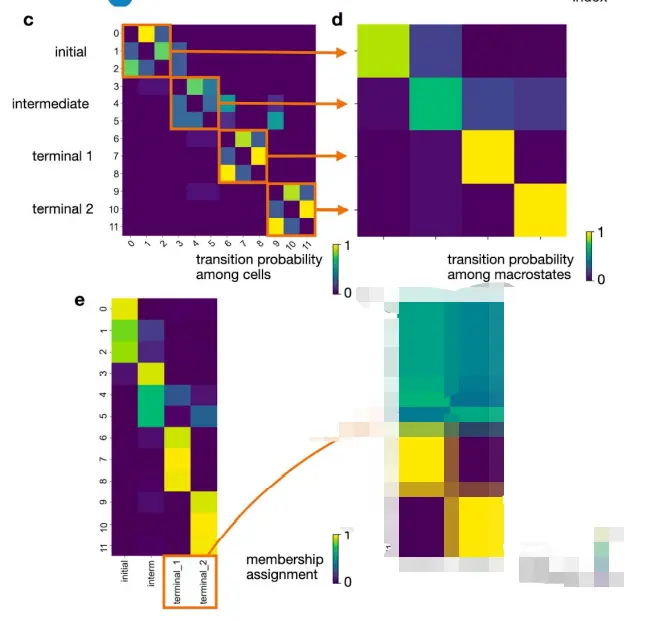
CellRank 将Markov chain的动态分解为这些宏观状态,并计算它们之间的coarse-grained转移概率。 宏观状态的数量是一个模型参数,可以使用拐点启发式或关于生物系统的先验知识(下图)来选择。
通过软分配将单个细胞分配给宏观状态。 为了计算宏观状态和诱导的coarse-grained转移概率,我们将Generalized Perron Cluster Cluster Analysis (G-PCCA) 应用于单细胞环境。
以coarse resolution查看生物系统能够根据转移概率识别populations:终端宏观状态将具有高自转移概率,初始宏观状态将具有低传入转移概率,其余宏观状态将是中间状态。 我们通过 0 和 1 之间的稳定性指数 (SI) 自动识别终端状态,表明自转移概率; SI 为 0.96 或更大的宏观状态被归类为终端。 我们通过coarse-grained平稳分布 (CGSD) 自动识别初始状态,该分布描述了coarse-grained Markov chain的长期演变。 CGSD 将较小的值分配给进程离开后不太可能重新访问的宏观状态; 这些宏观状态被归类为初始状态。 初始状态的数量是一个默认设置为 1 的参数。
最后,CellRank 使用directed单细胞转移矩阵来计算命运概率,即给定细胞最终过渡到上一步中定义的每个终端群体的可能性(下图)。
通过以封闭形式求解线性系统,可以有效地为所有cell计算这些概率。 命运概率将 RNA 速度给出的短程命运预测扩展到跨越初始状态到最终状态的全局结构。 基于随机Markov chain的公式能够通过将其中的许多聚合到我们的最终命运预测中来克服单个速度向量和细胞-细胞相似性中的噪声。
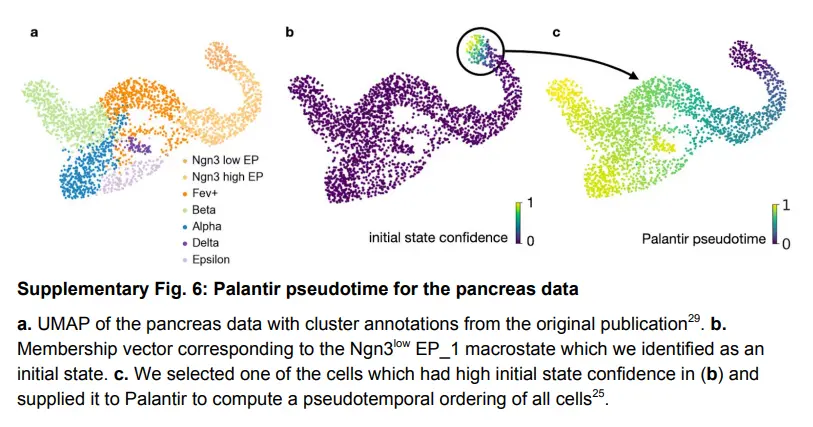
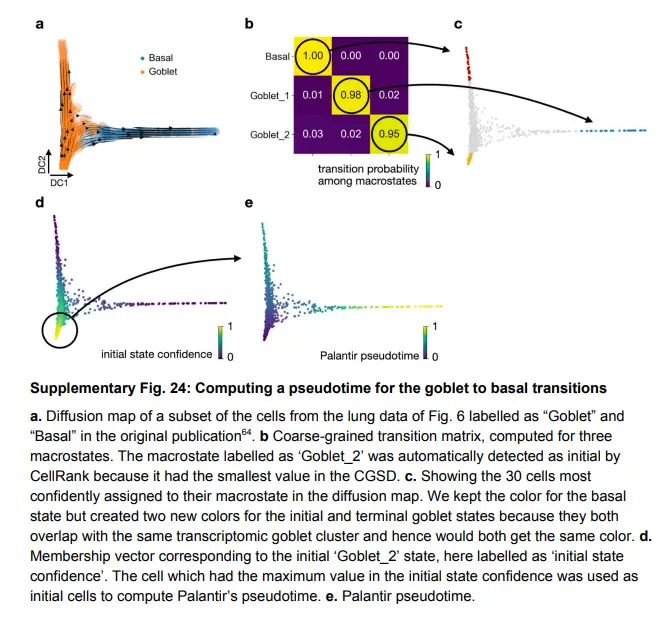
将fate probabilities估计与伪时间排序相结合,以可视化细胞沿着导致最终状态的轨迹执行的基因表达程序。伪时间从初始状态对细胞状态进行排序,而 CellRank fate probabilities表示每个细胞对每个轨迹的可信程度。通过fate probabilities 稳定地将细胞分配到轨迹,capture the effect of gradual lineage commitment,whereby cells transition from an uncommitted state (contribution to several trajectories) to a committed state (contribution to a single trajectory)。 Palantir 基于扩散分量空间中迭代优化的最短路径,默认用于伪时间排序,其中 Palantir 提供了 CellRank 计算的初始状态。通过将基因表达与fate probabilities相关联,CellRank 增强了发现推定轨迹特定调节器的能力。通过根据它们在伪时间的峰值对推定的调节器进行分类,可视化特定于其细胞轨迹的基因表达级联,同时考虑到细胞fate commitment的连续性。
宏观状态解决胰腺内分泌谱系形成的初始和终止状态
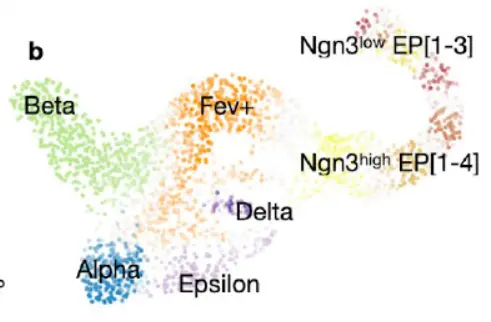
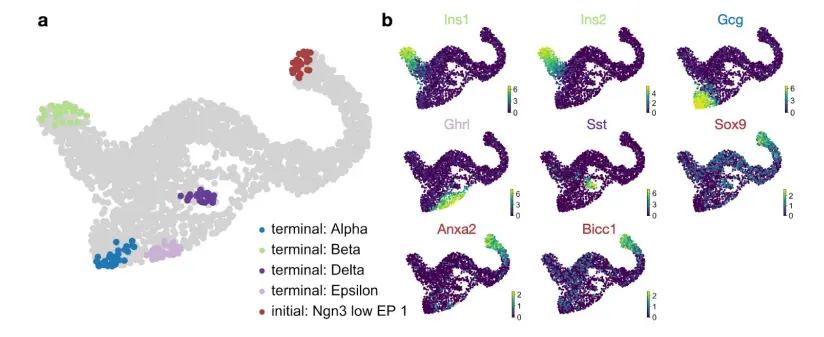
将 CellRank 应用于 E15.5 鼠胰腺发育的 scRNA-seq 数据集。 带有原始簇注释和 scVelo 投影速度的 UMAP 表示概括了主要的发展趋势(下图); 从最初的内分泌cluster祖细胞 (EP) 表达低水平的转录因子神经生成素 3(Neurog3 或 Ngn3),细胞沿着轨迹向 alpha、beta、epsilon 和 delta 细胞命运发展。
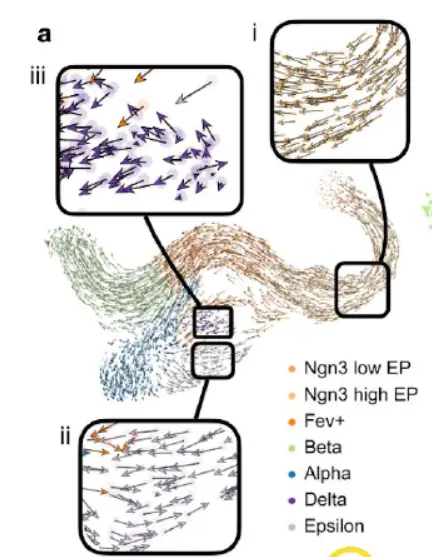
为了研究诸如谱系偏差的开始、初始和终止状态的精确位置以及任何终止状态的可能祖先等特定问题,出于三个原因,反对仅基于投影速度向量的假设。首先,向量仅投影到 2 维或 3 维,这可能会使真实速度过度正则化并导致向量场过于平滑。在 2D 或 3D 嵌入中解释细胞轨迹通常会产生误导,因为在低维中无法完全保留高维距离;这就是为什么大多数基于邻域的降维技术,如 t-SNE或 UMAP不能很好地保存全局关系。其次,投影向量的视觉解释忽略了 RNA 速度的不确定性,因此导致对推断轨迹的过度自信。第三,速度仅在本地可用,aggregates these local signals globally, computing longer range trends,计算更远距离的趋势。类似于单细胞领域达成的共识以避免在 2D 或 3D 表示中聚类细胞,理论上投影到二维或三维的速度向量不得用于解决轨迹推断的详细问题。 CellRank 克服了这些限制,并允许对全局轨迹进行建模。
We computed CellRank’s directed transition matrix and then coarse-grained it into 12 macrostates based on eigenvalue gap analysis(下图)。
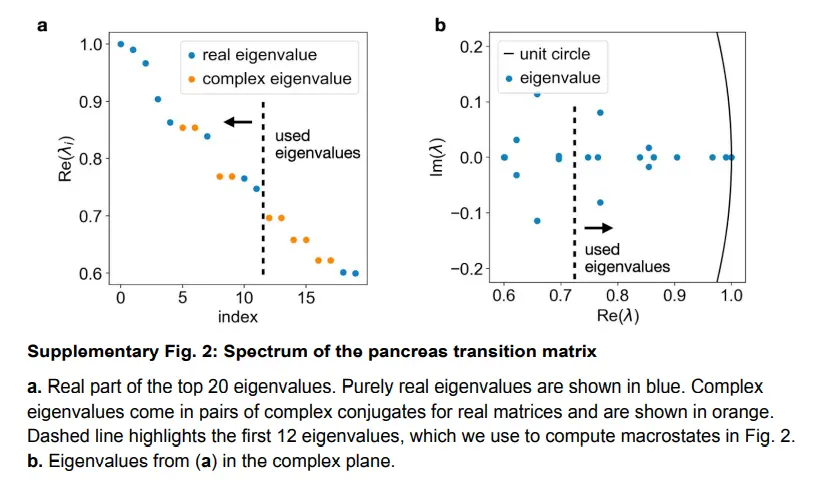
revealing a block-like structure in the transition matrix。
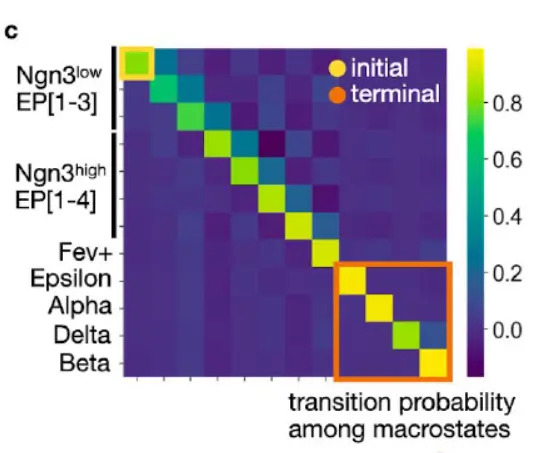
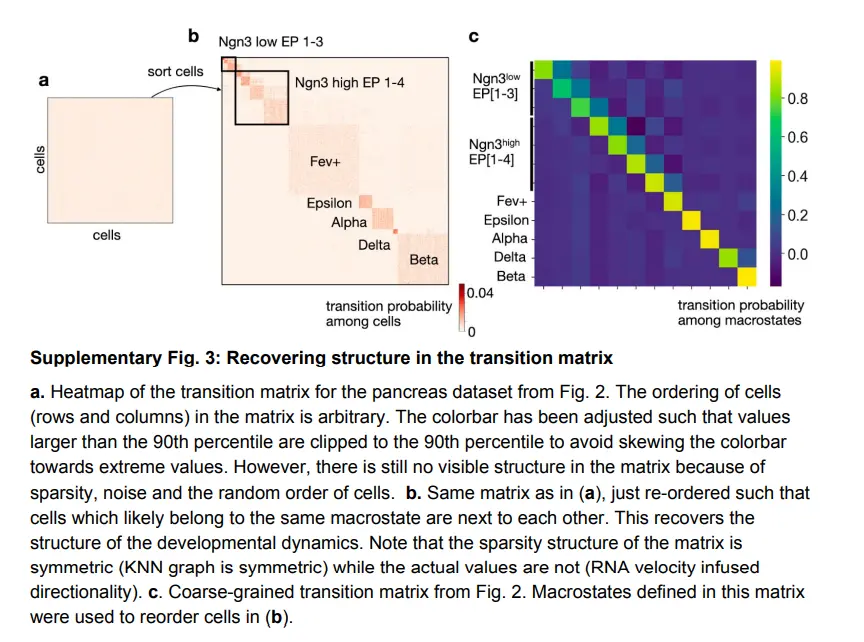
宏观状态,根据它们与潜在基因表达cluster的重叠进行注释,包括该数据集中的所有发育阶段,从初始 Ngn3l 低 EP 状态到中间 Ngn3 高 EP 和 Fev+ 状态,再到产生激素的终末α、β、ε 和δ 细胞状态。
The three most stable states according to the coarse-grained transition matrix were alpha (SI 0.97), beta (SI 1.00) and epsilon (SI 0.98) macrostates, which were accordingly labeled as terminal by CellRank, consistent with known biology。此外,恢复了一种相对稳定 (SI 0.84) 的宏观状态,它与 delta 细胞在很大程度上重叠。将 Ngn3 低 EP_1 状态确定为初始状态,因为它被分配了最小的 CGSD 值 (2 x 10 -6) 。 初始状态和终末状态的位置与众所周知的标记基因的表达一致,包括用于β的Ins1和Ins2,用于α的Gcg,用于ε的Ghrl,用于δ细胞的Sst以及用于初始状态的导管细胞标记物Sox9、Anxa2和Bicc1(下图)。
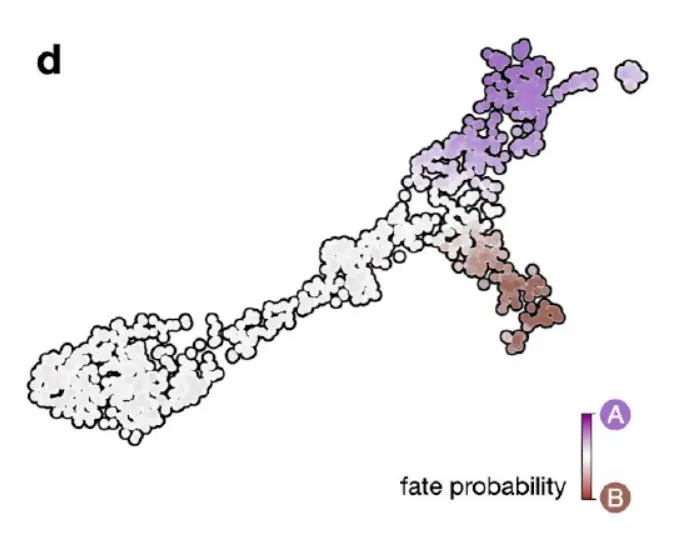
computed fate probabilities and summarized them in a fate map(下图)
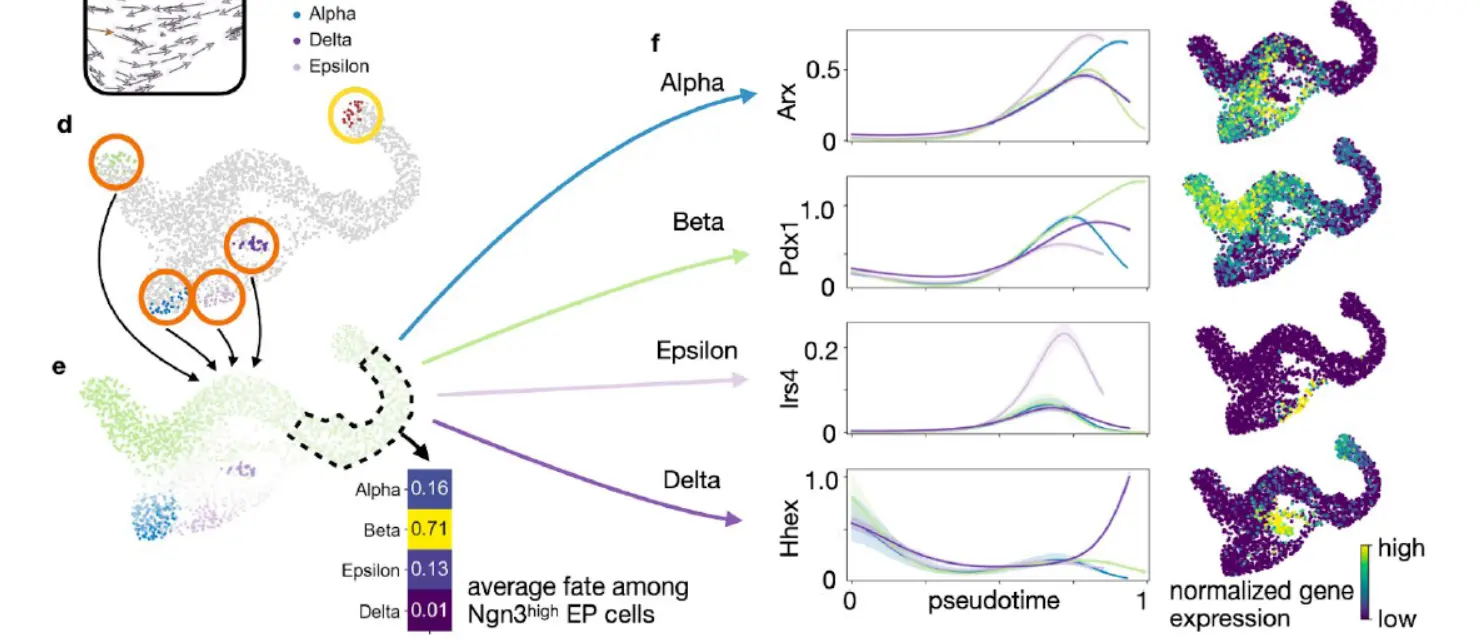
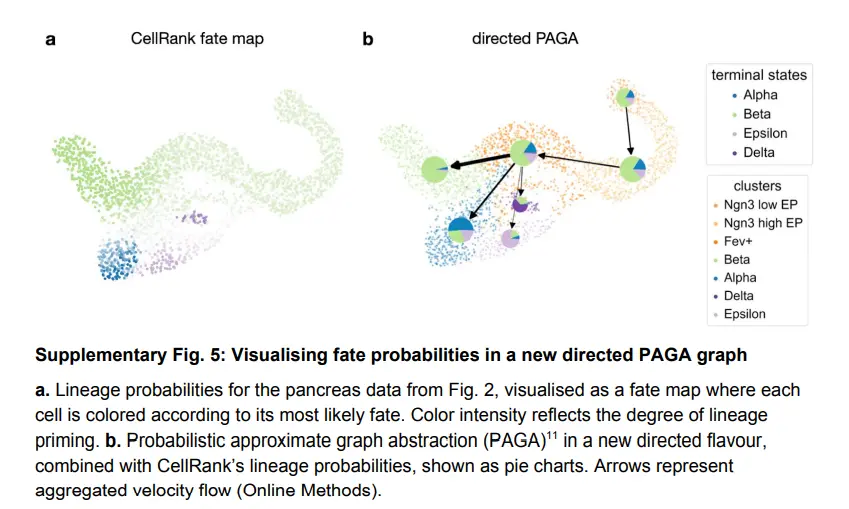
分析正确地确定了 E15.5 处 Ngn3high EP cluster中的 β 细胞命运占主导地位,这与已知生物学一致,并且还通过partition-based graph abstractionPAGA)的定向实现的饼图进行了可视化(下图)。
使用 Ngn3lowEP_1 宏观状态内的细胞作为 Palantir 的起始状态,我们在伪时间(下图)中对细胞进行排序,并覆盖主调节因子 Arx(alpha)、Pdx1(beta) 和 Hhex的表达 (delta) 和谱系相关基因 Irs4(epsilon)以显示趋势。 当接近它们相关的终端时,所有这些基因都被正确地上调。
All components of CellRank are extremely robust to parameter variation, based on sensitivity analysis for the number of macrostates, number of neighbors in the KNN graph, scVelo minimal gene counts, number of highly variable genes and number of principal components. Additionally, CellRank is robust to random subsampling of cells。
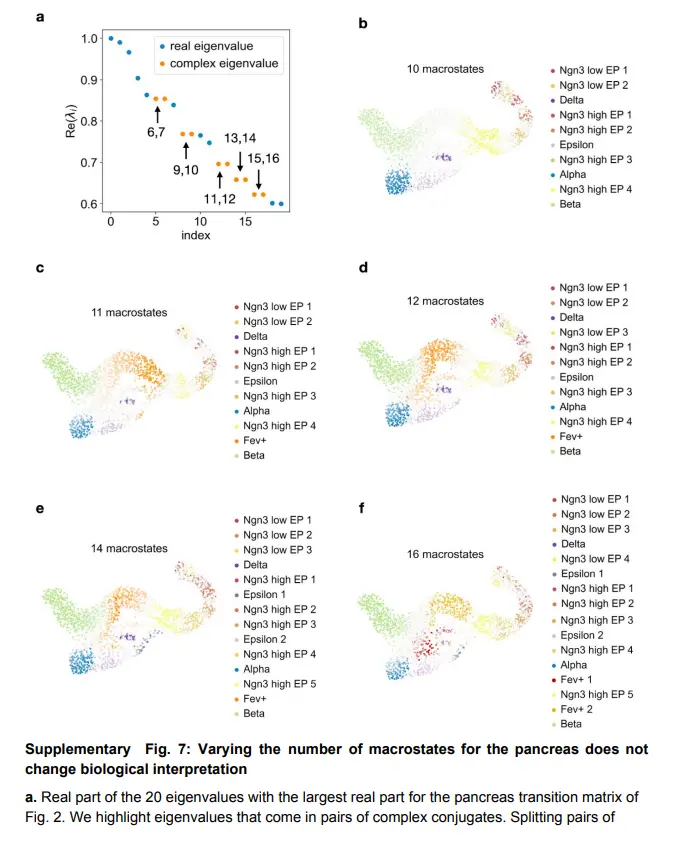
CellRank identifies putative gene programs driving delta cell differentiation
Delta 细胞突出了 CellRank 的全局方法如何克服 RNA 速度的限制。 Delta 细胞在数据中非常罕见(70 个细胞或总数的 3%),更重要的是,scVelo 的 30 个可能性最高的基因中没有已知的 delta 细胞发育驱动因素。 此外,scVelo 的剪接动力学模型未能很好地捕获与 delta 细胞发育有关的基因。 假设剪接动力学无法捕捉 delta 细胞分化,因为这些细胞出现在胰腺发育后期,因此在我们的数据中非常罕见。
δ 细胞的发展还不是很清楚。成熟的 delta 细胞可以通过 Sst 表达来识别,但未成熟的细胞更难识别。 Hhex 是唯一被广泛接受的谱系标记,Cd24a 最近与人类 delta 细胞发育有关。为了了解有关 delta 细胞发育的更多信息,关注相对稳定的 delta 宏观状态(SI 0.84)的 CellRank 命运概率,该状态并未自动归类为terminal(图 3a)。
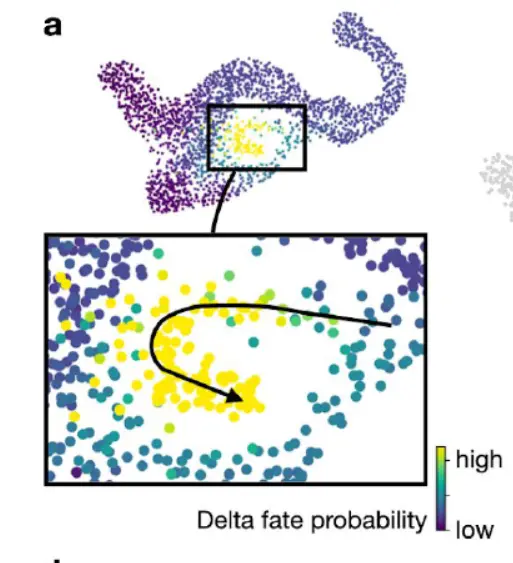
投影到 UMAP 上的速度显示了通往 delta 的多种可能路径(下图
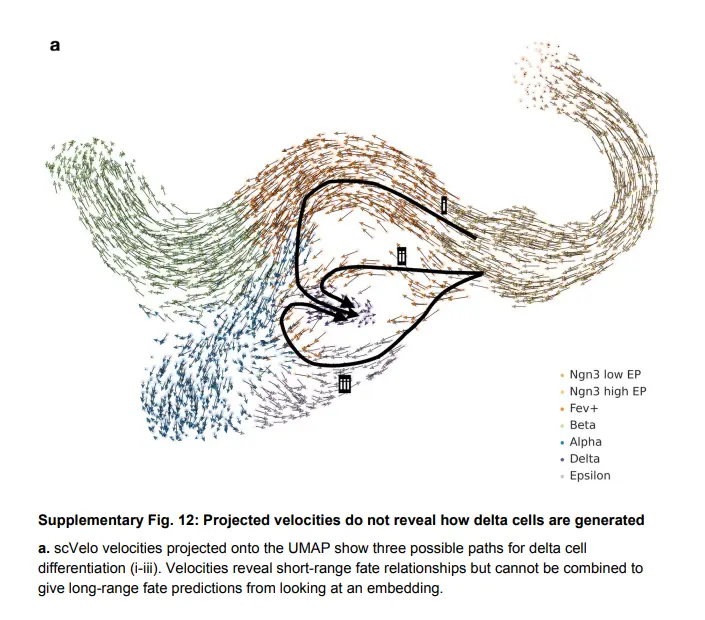
但 CellRank fate probabilities揭示了一条可能性最高的路径,通过在一项涉及 Fev+ 种群亚聚类的研究中被注释为 delta 前体的细胞(下图)
因此,虽然 RNA 速度无法捕捉 delta 细胞发育的动态,但它们可以通过 CellRank 成功恢复,因为它通过 KNN 图将速度限制在表型流形上,类似地合并细胞-细胞并对长期趋势进行建模。
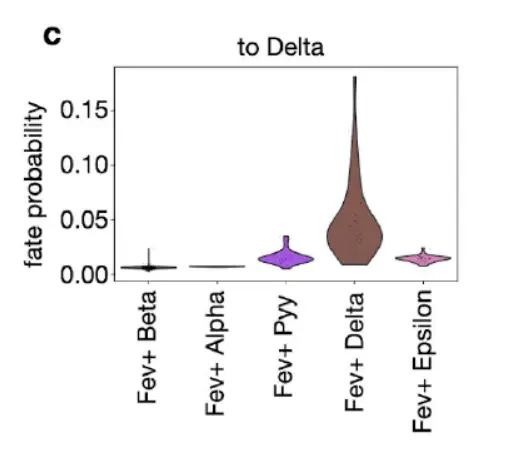
为了发现更多 delta 基因,将所有基因的表达值与 CellRank delta 命运概率相关联。具有最高相关性的 50 个基因的平滑基因表达趋势揭示了基因激活事件的级联
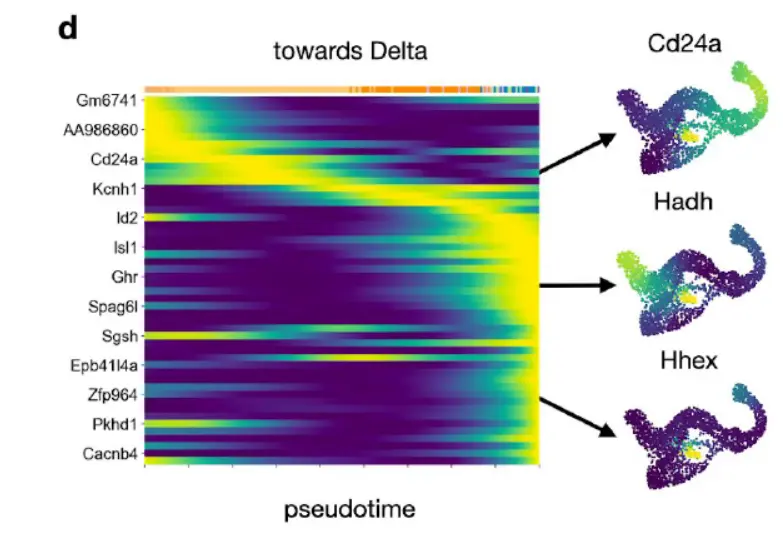
在前 50 个基因中,有 Hhex 和 Cd24,以及成熟 delta 细胞产生的激素 Sst。以前在 delta 细胞分化中没有描述作用的基因包括 Hadh(Foxa2 的靶标 46,与胰腺分化有关)、 Isl1(参与胰腺分化的转录因子)和 Pkhd1(Hnf1a/b 的靶标,参与胰腺分化的转录因子)。接下来,专注于一组瞬时上调的基因(下图)。
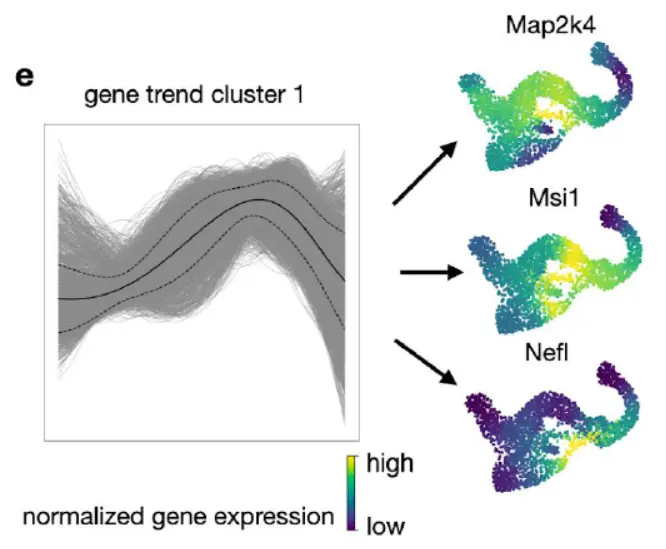
当根据它们与 delta 命运的相关性进行排序时,我们将 Map2k4、Msi1 和 Nefl 确定为新的候选regulators。 Msi1 受 Rfx4调控,它是 Rfx6 的旁系同源物,在结构上与 Rfx3 55 相关,两者都参与内分泌分化。
Propagating uncertainty rectifies noise in RNA velocity
CellRank 在 delta 细胞命运方面的成功部分是由于它能够正确解释嘈杂的 RNA 速度向量中的不确定性。原始 velocyto 和广义 scVelo 模型都根据拼接与未拼接的计数比率计算速度向量。然而,这些计数受到许多生物和技术噪声来源的影响,例如环境 RNA、稀疏性、双峰、爆裂动力学和低捕获效率。特别是未剪接的 RNA 在细胞中更为罕见,并且检测率低。分子计数的不确定性转化为 RNA 速度向量的不确定性,可以在 scVelo 中估计(下图)。
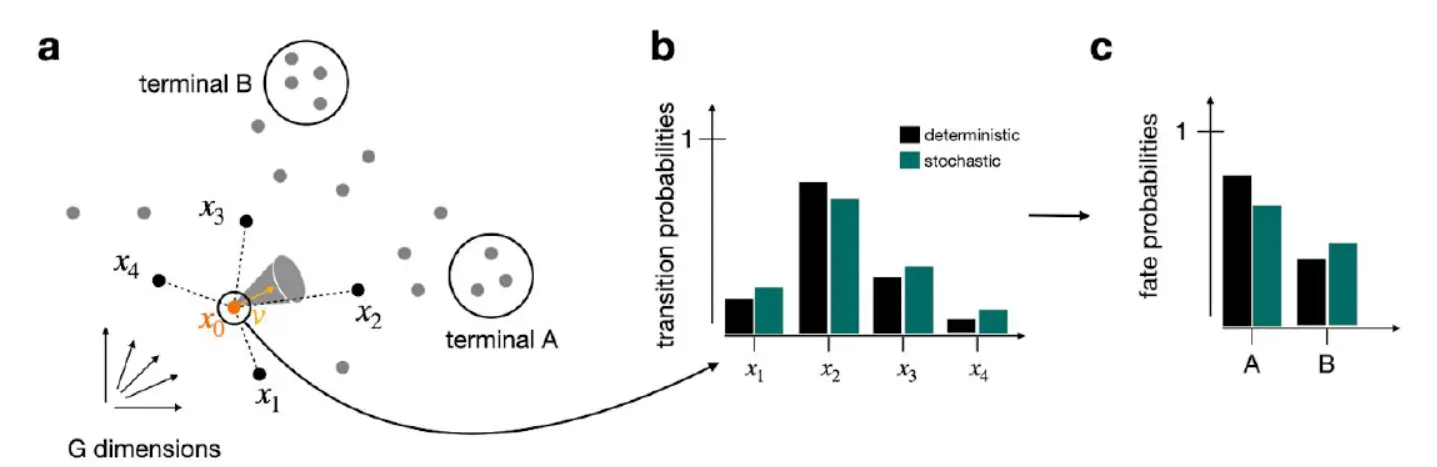
CellRank 通过传播速度向量上的估计分布来解释这些不确定性来源。默认情况下,它使用解析近似计算向最近邻的转移概率的预期值,给定速度向量的分布。解析近似非常有效,确保即使对于大型数据集,也可以处理不确定性。Alternatively, CellRank has an option for far slower, more accurate computation of fate probabilities via Monte Carlo (MC) sampling (Online methods). We confirm that this gives similar results to our analytical approximation 。
我们使用完整的胰腺数据集来研究不确定性传播的影响(下图)。
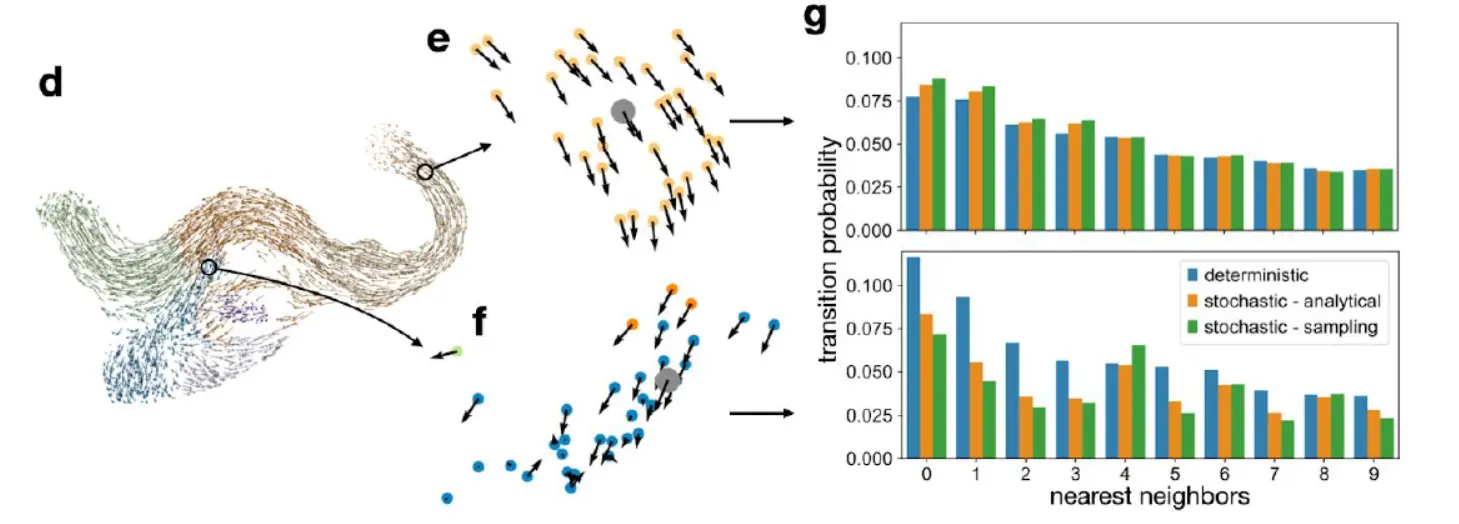
选择了两类细胞,一个来自相邻细胞的速度矢量趋于一致的低噪声区域,另一个来自高噪声区域 区域。 为了计算向最近邻的转移概率,使用了一种不会传播不确定性的确定性方法,以及分析近似和 MC 采样。 确定性和随机转换概率之间的差异在高噪声区域最大,突出表明不确定性传播会自动降低向噪声区域中单个速度向量不太可信的cell的转换。 总体而言,这导致推断fate probabilities的稳健性增加。
CellRank outperforms competing similarity-based methods
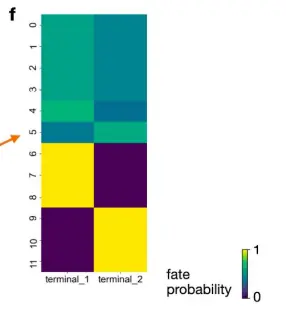
为了评估包含速度信息的影响,我们将 CellRank 与其他提供细胞轨迹分析的方法进行了比较:Palantir、STEMNET和 FateID对胰腺数据。只有 CellRank 正确识别了初始状态和终止状态(下图)。
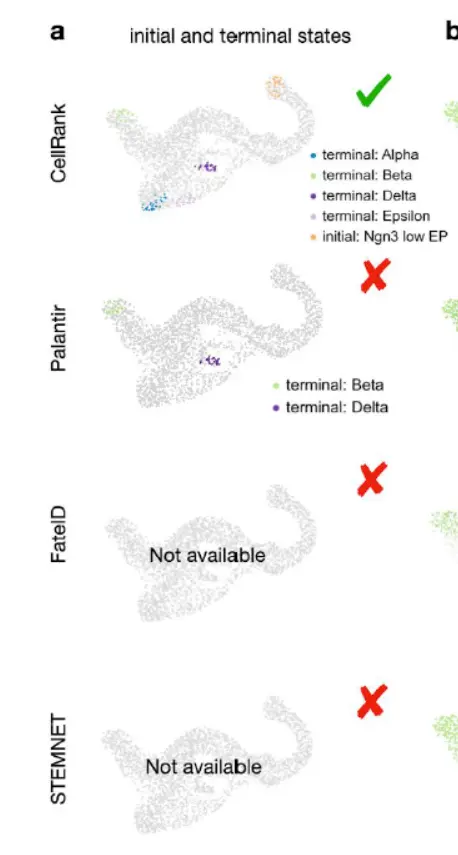
Palantir 需要提供初始状态,并且只能识别 4 个终止状态中的 2 个,而 STEMNET 和 FateID 无法确定初始状态或终止状态。接下来,为所有方法提供了 CellRank 终端状态并测试了细胞命运概率,发现只有 CellRank 和 Palantir 正确地将 beta 识别为 Ngn3high EP 细胞中的主要命运
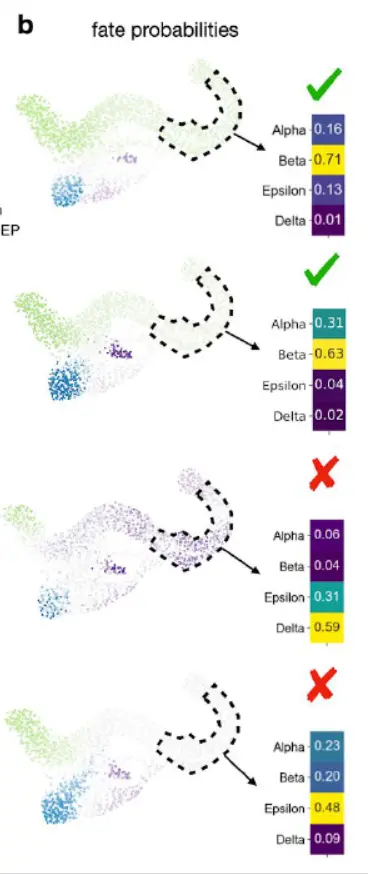
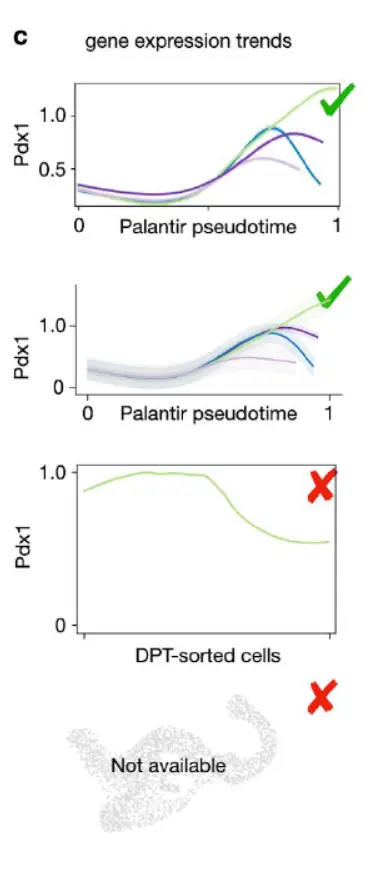
对于基因表达,CellRank 和 Palantir 正确预测了关键谱系驱动因素的趋势,而 FateID 未能预测沿 beta 谱系 39,40 的 Pdx1 和 Pax4 的(瞬时)上调以及沿 alpha 谱系的 Arx 上调,而 STEMNET 确实如此不可视化表达趋势。
轨迹分析预测肺再生的新去分化轨迹
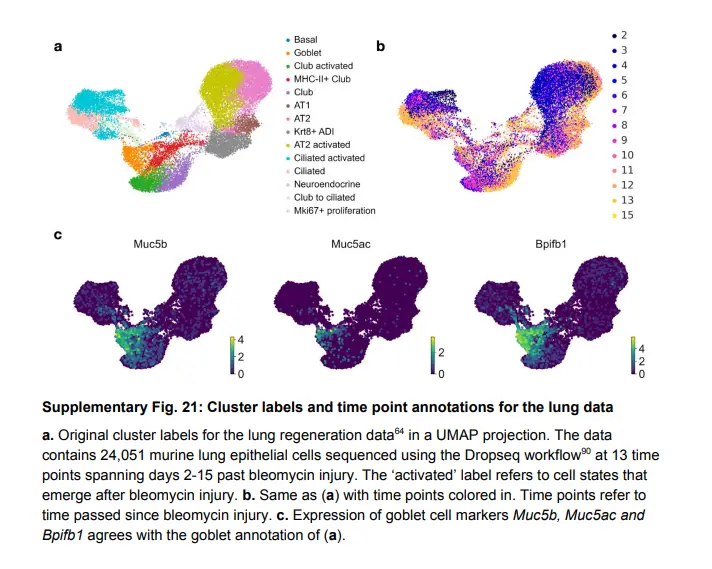
为了证明 CellRank 超越发育的泛化能力,将其应用于应对急性损伤的鼠肺再生。 scRNA-seq 数据集包含 24,051 个肺气道和肺泡上皮细胞,在博莱霉素损伤后第 2-15 天的 13 个时间点测序(下图)。
当体内平衡受到干扰和组织环境发生变化时,上皮细胞类型之间的高度可塑性已被观察到,包括损伤诱导的分化细胞类型在肺和其他器官中重编程为真正的长寿干细胞。在当前的气道细胞谱系模型中,多能基底细胞产生棒状细胞,进而产生分泌杯状细胞和纤毛细胞。有趣的是,已经表明,基底干细胞消融后,腔内分泌细胞可以去分化转化为功能齐全的基础干细胞。在这里,应用 CellRank 来公正地发现气道细胞之间的unexpected再生轨迹。
随后计算了 scVelo 速度并应用 CellRank 来识别九种宏观状态。
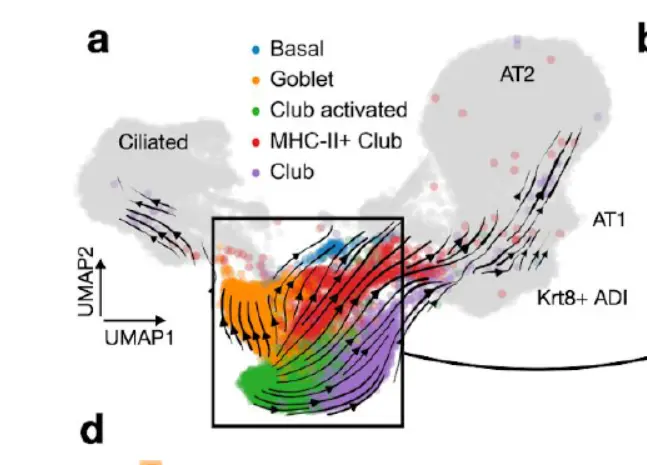
将分析重点放在气道细胞上,在纤毛细胞中确定了三种宏观状态,一种在基底细胞中,一种在杯状细胞中。 与谱系追踪实验一致,观察到club细胞产生纤毛细胞的可能性很高。 通过特定粘蛋白基因(例如 Muc5b 和 Muc5ac )以及参与先天免疫的分泌蛋白(例如 Bpifb1)的表达,将杯状细胞宏观状态与棒状细胞区分开来。 对基底和杯状状态的轨迹分析显示,令人惊讶的是,杯状细胞可能会向 Krt5+/Trp63+ 基底细胞去分化(下图)。
我们单独计算了基底细胞和杯状细胞的diffusion map以研究更高分辨率的轨迹(下图)。
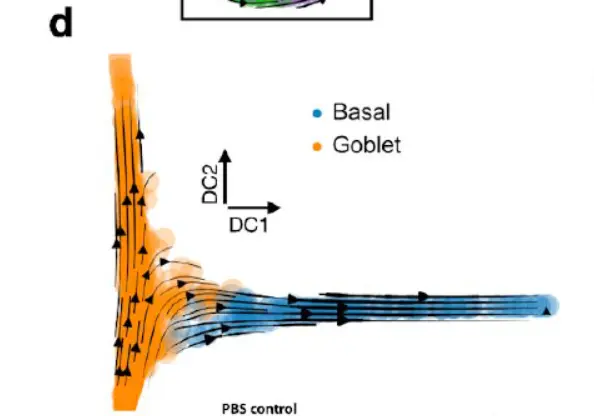
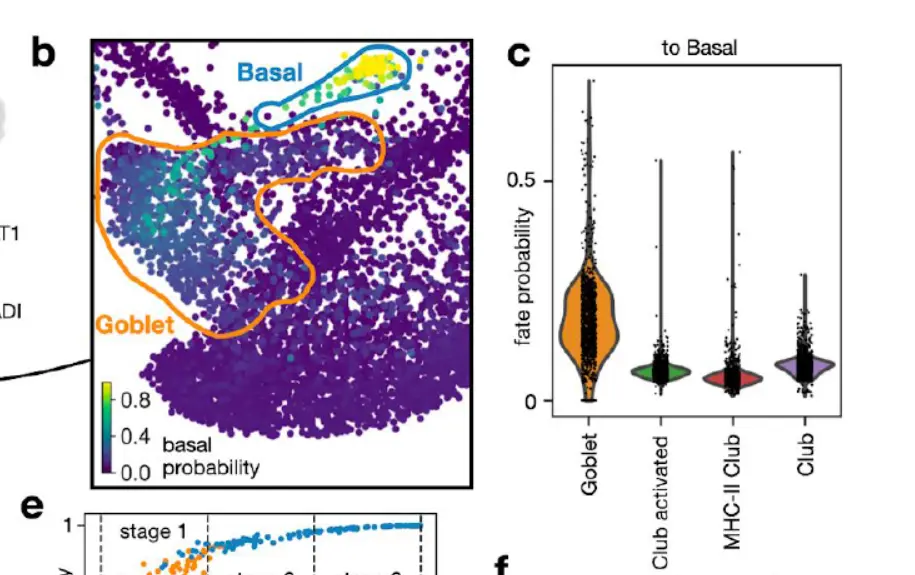
使用 CellRank 和 CGSD,确定了过渡中的早期细胞,我们从中使用 Palantir 计算了伪时间(下图)。
将伪时间与过渡到基础命运的概率相结合,以定义数据子集中去分化轨迹内的阶段
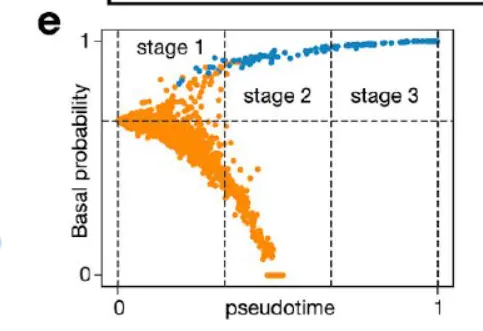
将具有至少 66% 概率达到基础状态的细胞分成三个相等的伪时间区间。 阶段 1 由杯状细胞组成,特征是杯状标记 Bpifb1 的高表达。 第 2 阶段包括一组中间细胞,它们表达 Bpifb1 和基础标记 Krt5。 第 3 阶段由末端基底细胞组成,其特征在于基底标记 Krt5 和 Trp63,并且不表达 Bpifb1。
新型杯状细胞去分化模型预测。损伤后,第 2 阶段细胞的频率应该增加。为了验证该预测,我们在博来霉素处理后第 10 天和第 21 天以及未处理动物中通过小鼠气道上皮细胞的免疫荧光评估了 Bpifb1、Krt5 和 Trp63 表达。在对照和治疗小鼠中都发现了来自第 1 阶段(杯状)和第 3 阶段(基础)的细胞。然而,仅在治疗后 10 天的小鼠中发现了中间阶段 2 细胞。此外,还发现了三重阳性细胞,但它们仅在损伤后出现。杯状细胞增生,即气道中粘液分泌细胞数量的增加,是几种慢性炎症的突出特征。 CellRank 分析发现的对基底干细胞的新去分化轨迹是出乎意料的,这表明在对损伤的再生反应的消退阶段产生多能干细胞的途径。
Discussion
上述已经证明 CellRank 将基因表达相似性与 RNA 速度相结合,以稳健地估计细胞在发育和再生过程中的定向轨迹。 应用于胰腺发育,CellRank 正确恢复了初始和终止状态、命运潜能和基因表达趋势,优于不使用 RNA 速度信息的分析方法,同时只需几秒钟即可计算终止状态,几分钟即可计算 10 万个细胞的命运潜能 .
尽管自动识别了 alpha、beta 和 epsilon 状态,但 delta 宏状态需要手动分配其终止状态。 可以认为未达到终端分配的截止点,因为该数据集中的 delta 细胞很少见,并且速度无法正确检测到它们的调节。 为了克服这个问题,可以扩展 CellRank 模型以包括表观遗传信息,例如染色质可及性。 许多调节过程是在表观遗传水平上启动的,只有在延迟后才能在转录上可见,或者根本不可见。 将此类信息包含在 CellRank 模型中,可能是通过向马尔可夫链引入有限的内存,因此可以提高其适用性。
对于 delta 细胞发育,上述展示了如何将一个谱系内的基因表达趋势聚类并与细胞分化相关联来识别推定的驱动基因。 或者,可以通过对用于拟合这些趋势的广义加性模型的参数进行统计测试来直接识别驱动因素。 这样的模型已经存在并且可以从 CellRank 将细胞分配到谱系的分化轨迹中受益。
RNA 速度向量是基因调控当前状态的噪声估计。 CellRank 通过传播它们的分布来处理不确定的速度向量。 上述展示了这种校正如何随着局部噪声水平自动缩放并增加稳健性。 当前的一个限制是需要通过计算局部邻域中速度矢量的矩来近似速度矢量的分布。
CellRank 是一种定量分析高维 RNA 速度诱导矢量场的方法。 虽然其他方法已经开始解决这个问题,但他们要么忽略了细胞命运决定和速度不确定性的随机性,要么专注于轨迹重建以外的问题。 最初的速度模型提出了一种寻找初始和终止状态的想法,该想法基于在时间上向前或向后模拟马尔可夫过程,但是,它们的实现依赖于 2D t-SNE 嵌入,由于采样而计算成本高,忽略了不确定性 在速度向量中,并且不允许分离成单独的初始状态和终止状态。 CellRank 通过一种无模拟、独立于任何低维嵌入、考虑速度不确定性并能够识别单个初始和终端状态的原则性方法克服了这些问题。
与之前基于马尔可夫链的方法相比,Cellrank的方法基于有向非对称转移矩阵。 这意味着无法直接对转换矩阵进行特征分解以了解聚合动力学,因为非对称转换矩阵的特征向量通常很复杂并且不允许物理解释。 为了克服这一点,一种可能性是恢复到计算成本高昂的基于模拟的方法。 在 CellRank 中,采用了一种基于真实 Schur 分解的更有原则的方法,这是将特征分解推广到非对角化矩阵。 实现的当前限制是它使用无导数方法来解决由此产生的约束优化问题,随着宏状态数量的增加,这可能会在计算上变得昂贵。
基于相似性的方法已经取得了巨大的成功,但它们的应用大多仅限于正常开发,因为过程的起始细胞和方向通常是确定的。 在这里,通过发现肺损伤后基底细胞去分化轨迹的新型高脚杯,展示了 CellRank 如何推广到正常发育之外。 数据集由 13 个时间点组成; 然而,尚不清楚如何将时间信息纳入转移概率的估计。 通过只允许与实验时间一致的转换,包含这些信息可以帮助规范模型。 此外,在可用的情况下,可以包括谱系追踪信息以进一步规范模型以遵守克隆动态 。
下一篇我们分享示例代码
生活很好,有你更好

















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









