







1.代码下载地址GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
2.准备自己的数据集
这里数据集我以SAR数据集为例
具体的下载链接如下所示:
链接:https://pan.baidu.com/s/1cIiaOT2hbnQsa8e93cHQrg
提取码:yyds
3.数据集路径调整
将数据集存放在yolov9的文件夹下面
4.新建data.yaml文件
train: E:\liqiang\yolov9-main\data\SSDD\train\images # 训练集绝对路径 进入到训练集存放图片的文件夹里面,按ctrl+L复制过来即可 val: E:\liqiang\yolov9-main\data\SSDD\val\images # 验证集绝对路径 进入到验证集存放图片的文件夹里面,按ctrl+L复制过来即可 # test: D:\needed\air-filter\train\images nc: 1 # class数 names: ['ship'] # 模型类别名train的路径是训练集下面的images路径
val的路径是验证集下面的images路径
其他的根据自己的数据集进行调整

5.修改yolov9.yaml文件
把nc改为数据集类别即可
6.训练
报错1:
训练如果出现AttributeError: 'list' object has no attribute 'view'报错时,使用tain_dual.py进行训练,不要使用train.py进行训练
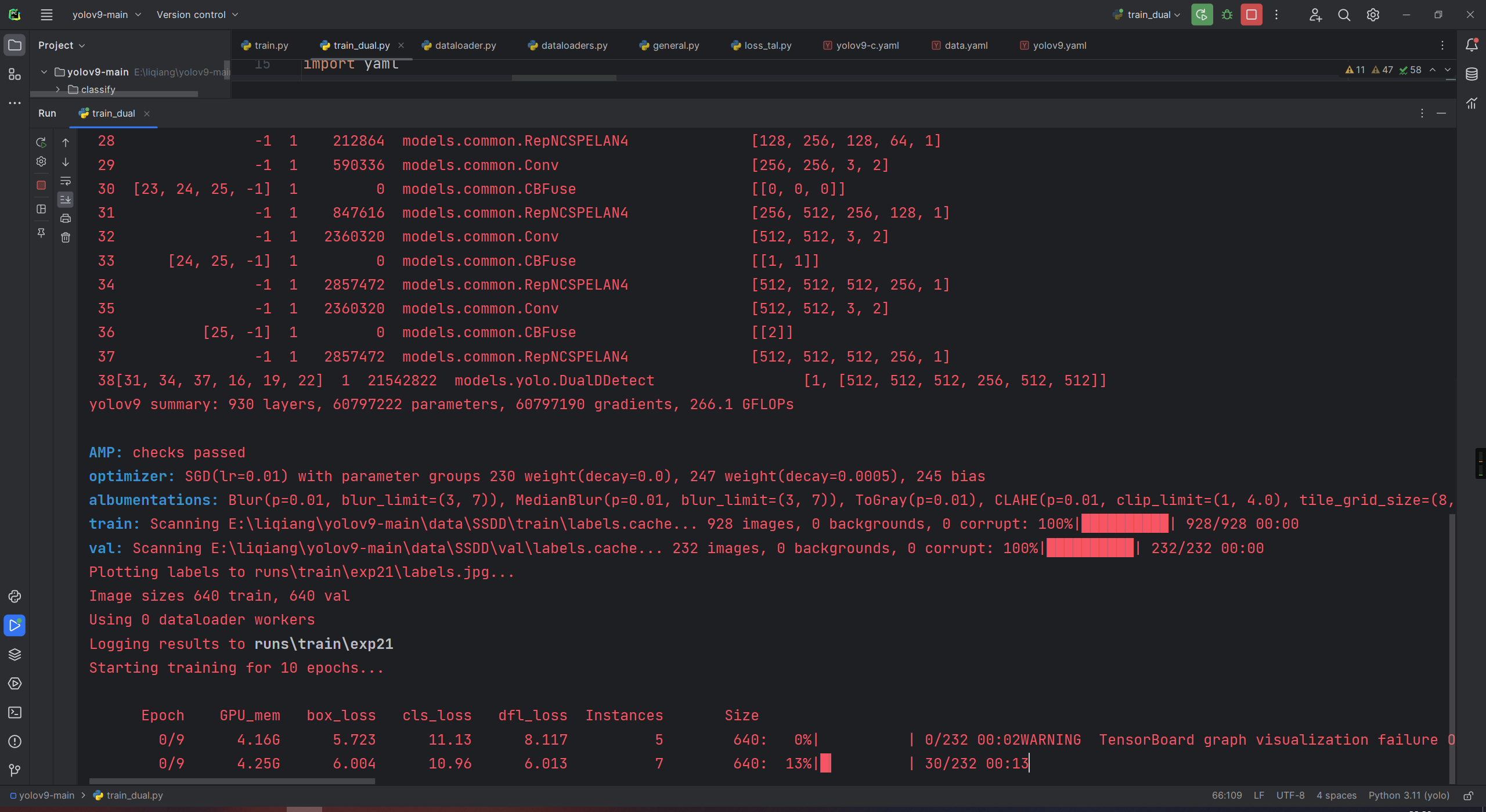
AMP: checks passed
optimizer: SGD(lr=0.01) with parameter groups 230 weight(decay=0.0), 247 weight(decay=0.0005), 245 bias
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
train: Scanning E:\liqiang\yolov9-main\data\SSDD\train\labels.cache... 928 images, 0 backgrounds, 0 corrupt: 100%|██████████| 928/928 00:00
val: Scanning E:\liqiang\yolov9-main\data\SSDD\val\labels.cache... 232 images, 0 backgrounds, 0 corrupt: 100%|██████████| 232/232 00:00
Plotting labels to runs\train\exp10\labels.jpg...
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs\train\exp10
Starting training for 10 epochs...Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
0%| | 0/232 00:01
Traceback (most recent call last):
File "E:\liqiang\yolov9-main\train.py", line 634, in <module>
main(opt)
File "E:\liqiang\yolov9-main\train.py", line 528, in main
train(opt.hyp, opt, device, callbacks)
File "E:\liqiang\yolov9-main\train.py", line 304, in train
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\liqiang\yolov9-main\utils\loss_tal.py", line 168, in __call__
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\liqiang\yolov9-main\utils\loss_tal.py", line 168, in <listcomp>
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
^^^^^^^
AttributeError: 'list' object has no attribute 'view'

报错2:
AttributeError: 'FreeTypeFont' object has no attribute 'getsize'

解决:
pip install Pillow==9.5 -i https://pypi.douban.com/simple/训练命令:
python .\train_dual.py --cfg E:\liqiang\yolov9-main\models\detect\yolov9.yaml --data E:\liqiang\yolov9-main\data\data.yaml --device 0 --batch-size 4 --epoch 10 --hyp E:\liqiang\yolov9-main\data\hyps\hyp.scratch-high.yamlyolov9.yaml绝对路径复制

data.yaml绝对路径复制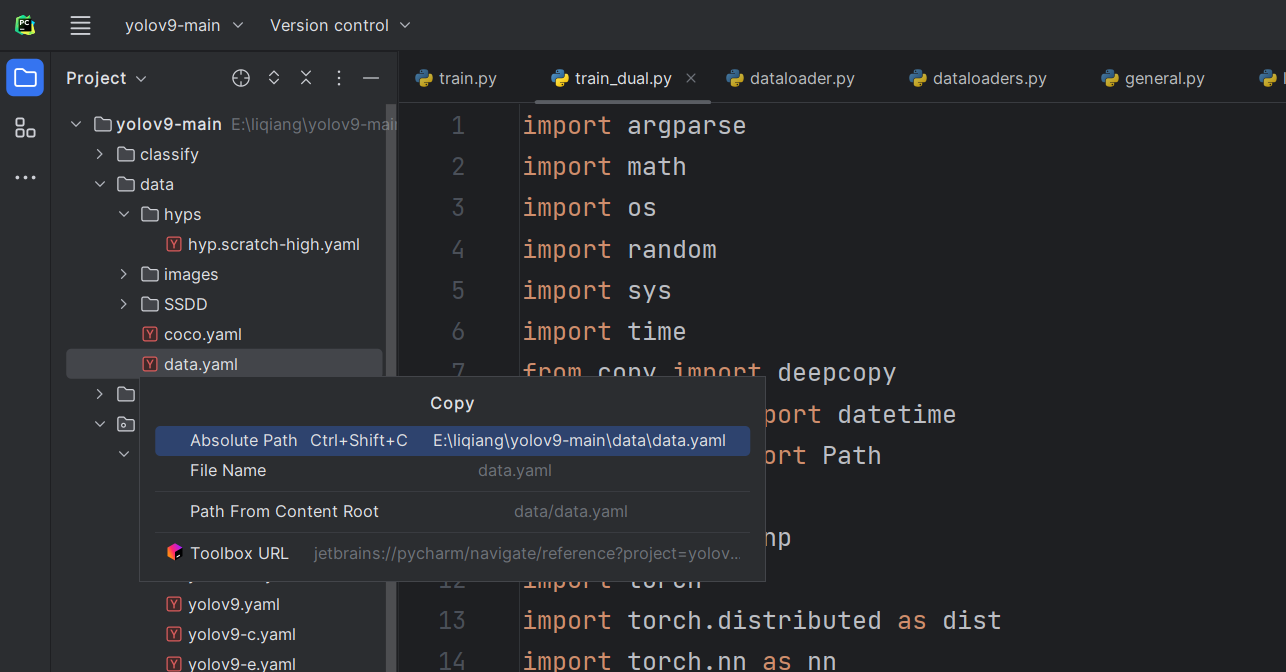
hyps绝对路径复制

7.推理
python detect.py --weights E:\liqiang\yolov9-main\runs\train\exp11\weights\best.pt --source E:\liqiang\yolov9-main\data\images\000002.jpg报错:AttributeError: 'list' object has no attribute 'device'

解决:
将general.py中的:
if isinstance(prediction, (list, tuple)): # YOLO model in validation model, output = (inference_out, loss_out) prediction = prediction[0] # select only inference output device = prediction.device
替换为:
if isinstance(prediction, (list, tuple)):
processed_predictions = []
for pred_tensor in prediction:
processed_tensor = pred_tensor[0]
processed_predictions.append(processed_tensor)
prediction = processed_predictions[0]
device = prediction.device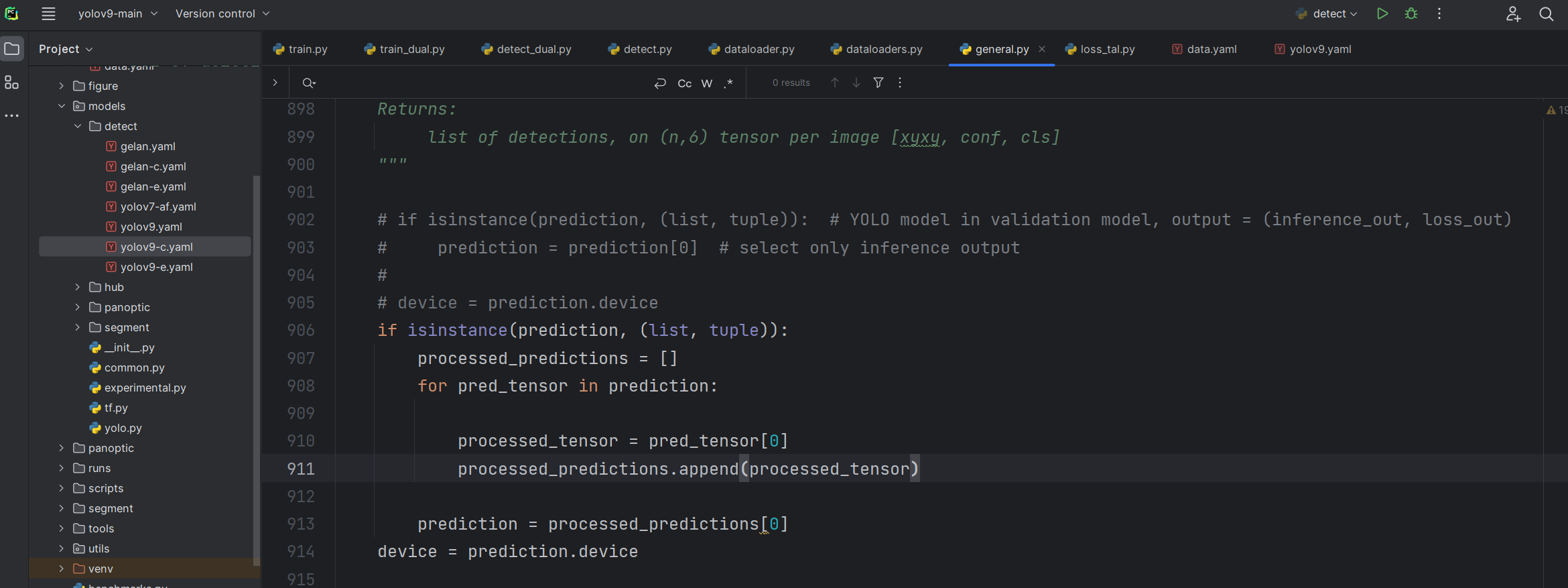
结果如下:

















 2160
2160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











