






由于基于激光雷达的检测方法比基于相机的方法性能要好得多,目前最先进的方法主要是基于激光雷达的三维目标检测,即主要通过激光雷达管道进行检测,将图像信息整合到激光雷达检测管道的不同阶段,来弥补激光雷达的不足。
鉴于基于激光雷达和基于摄像机的检测系统的复杂性,将两种方式结合在一起不可避免会带来额外的计算开销和推理延迟。故如何有效地将相机和激光雷达信息融合在一起是一个挑战。此外的一大挑战是图像和点云的配准问题。
1. SuperFusion: Multilevel LiDAR-Camera Fusion
for Long-Range HD Map Generation
Hao Dong, arXiv, 2024
现有的图像点云融合方法,不论是数据级、特征级还是BEV级的融合,都还是过于简单,没有充分利用两个模态的优势。本文提出了一种多级图像-点云融合方式,在三个层次上对图像和点云进行融合。本文的方法生成了高质量的融合BEV特征来支持不同的任务,在近距离和远距离地图生成方面都大大超过了最先进的融合方法。
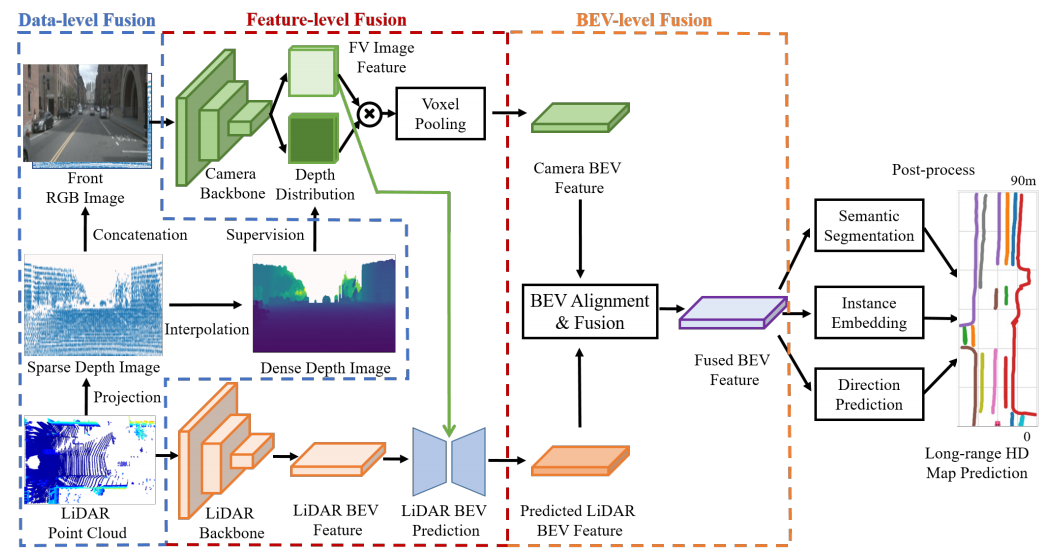
将LIDAR和相机数据进行三个层次的融合:
- 数据级融合。将LIDAR点云投影到图像平面得到稀疏深度图,将深度图与可见光图像进行数据级融合,提高图像深度估计的精度;
- 特征级融合。图像和LIDAR点云经过特征提取后,在图像特征的引导下,利用交叉注意力对点云特征进行长距离预测;
- BEV级融合。将图像BEV特征和点云BEV特征对齐,生成高质量的图像-点云特征融合。

如上图所示,点云通常对地平面的有效距离很短,而相机可以看到更远的距离。
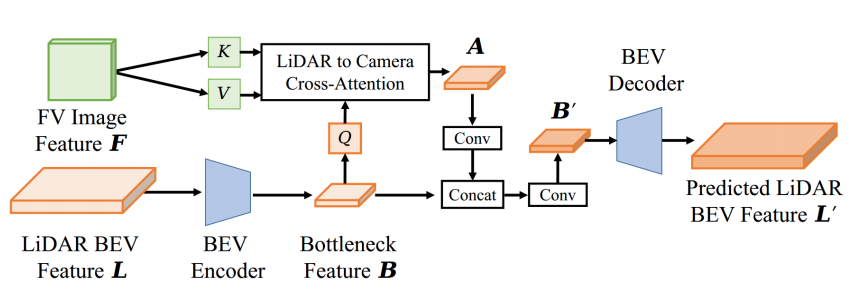
上图为图像特征引导的点云长距离预测,图像与点云的跨注意力融合结构。
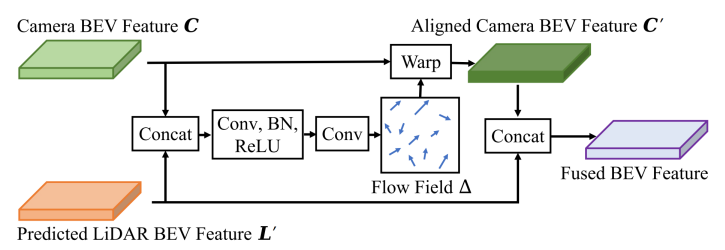
上图为BRV对齐及融合结构。
2. LIF-Seg: LiDAR and Camera Image Fusion for 3D
LiDAR Semantic Segmentation
Lin Zhao, IEEE Transactions on Multimedia, 2021
相机和激光雷达融合的两个重要问题阻碍了他们更好的性能,一是如何有效地融合两个模态;二是如何精确地对准他们,即弱时空同步问题。 对于以上问题,提出了一个由粗到精的多模态融合框架。
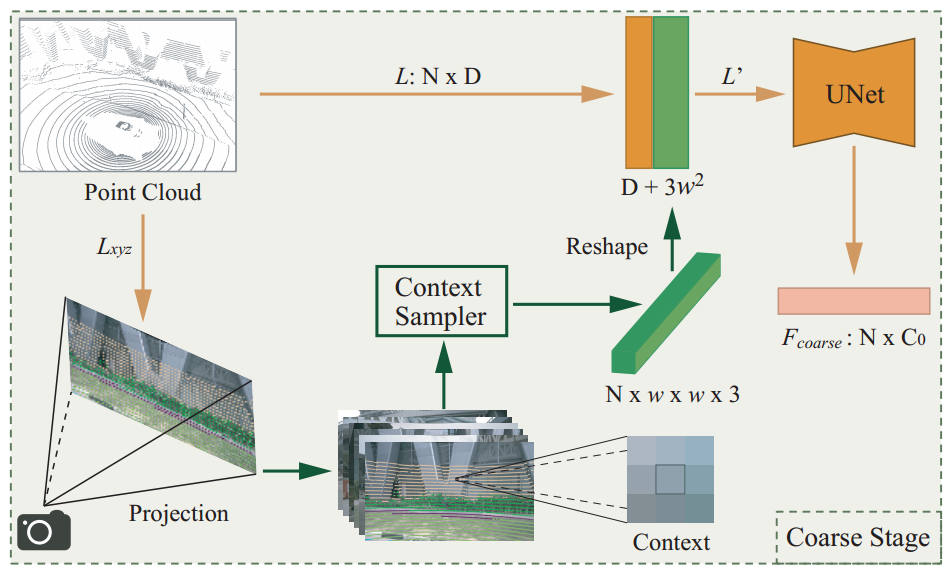
第一个粗融合阶段针对如何融合的问题,不同于以往点云图像一对一融合的方式,将LIDAR点投影到每张相机图像中,并将每个像素的3*3上下文信息加到LIDAR点的强度信息中。
N为激光雷达点云的个数,D为一个点云携带的信息的维度,如xyz轴位置+反射率r,D=4。w*w为上下文信息的尺寸,w*w*3代表每一个上下文信息像素的3个RGB颜色通道。
将融合了上下文信息的点云和原点云拼接,将拼接后的LIDAR点送入U-Net分割子网络,得到LIDAR点的粗特征。
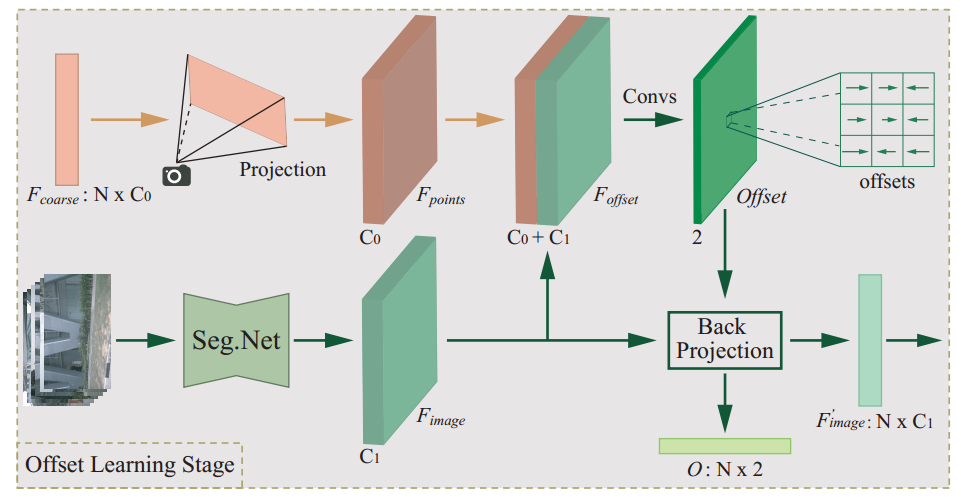
针对弱时空同步问题,设计了一种偏移矫正方法,对粗特征和图像的语义特征进行对齐。具体而言,首先使用图像分割子网络提取图像的语义特征Fimage,将上一步得到的点云粗特征投影到图像平面中形成与图像特征大小相同的伪图像特征映射Fpoints,将其与Fimage拼接,以预测点云投影点与相应图像像素之间的偏移量,用预测的偏移量对点云投影点位置进行矫正。
下图为偏移矫正的可视化效果,红点为矫正前点云在图像平面上的投影,蓝点为矫正后的投影。

3. PointAugmenting: Cross-Modal Augmentation for 3D Object Detection
Chunwei Wang, CVPR, 2021
本文提出了一种新的跨模态三维目标检测算法-点增强算法,该方法使用预训练好的二维模型提取的相应的点向CNN特征对点云进行装饰,然后在装饰好的点云上进行三维目标检测。与高度抽象的语义分割分数来装饰点云相比,该方法能够适应物体外形的变化,取得了显著的改进。
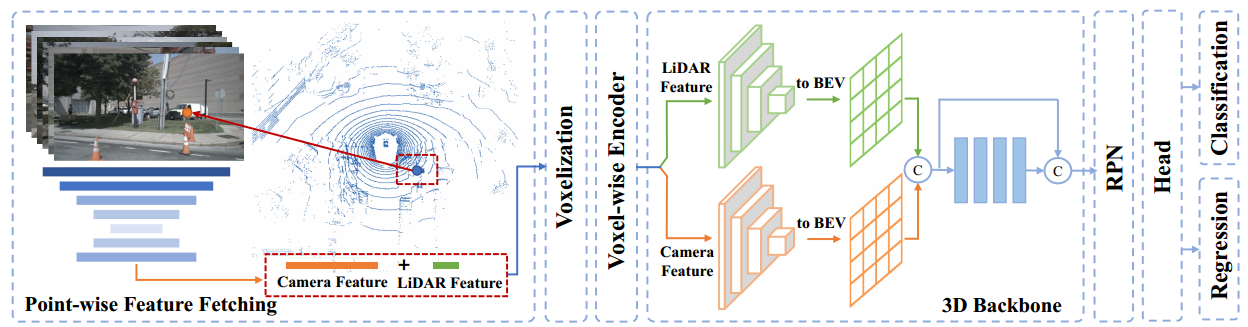
下图是网络的框架结构,包括两个阶段:首先逐点特征提取,将LIDAR点投影到图像平面上,然后添加提取的逐点CNN特征;其次是3D检测,使用额外的三维稀疏卷积扩展CenterPoint,用于提取相机特征,并在BEV平面上融合图像与点云特征。
4. SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection
Yichen Xie, ICCV, 2023
观察到现有的图像-点云融合方法要么是找到密集的候选,要么产生密集的场景表示,如BEV、体积和点表示。然而考虑到对象通常只占场景的一小部分,寻找密集的候选对象并生成密集的表示是嘈杂和低效的。本文提出了一种新的多模态三维目标检测方法,只使用稀疏候选和稀疏表示,采用稀疏+稀疏---稀疏的策略。
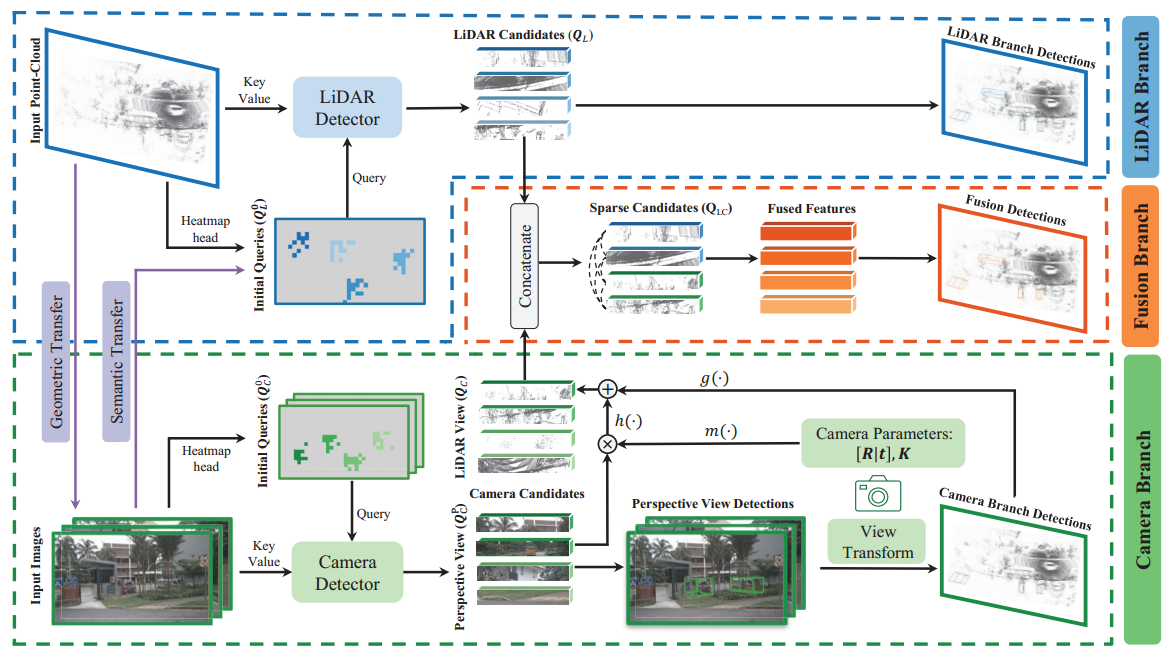
具体来说,在两个并行分支对图像和点云进行Query初始化和特征提取,将query和提取的特征通过交叉注意力交互,生成更新后的query作为各模态的候选对象,即实例特征,然后将图像分支的实例特征投影到LIDAR三维空间中。由于实例级特征是同一场景中相同对象的稀疏表示,可以通过一种柔和的方式将他们用轻量级注意力模块融合在一起。
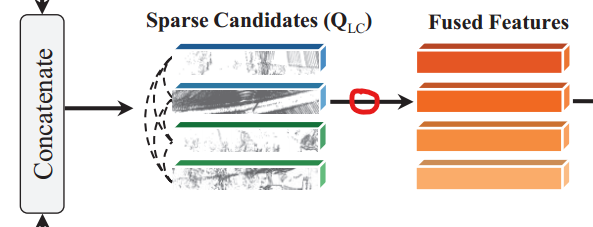
将两个模态的稀疏候选投影到同一空间中后,将二者通过以下公式拼接:
![]()
其中fL和fC是可学习的投影。之后使用了一个新颖的自注意块来融合这两种模式(文章图中没有画出)。自注意力虽然简单,但该操作的想法是新颖的:特定于模态的检测器对各自输入的有利方面进行编码,而自注意块能够以有效的方式聚合和保存来自两种模态的信息。该步的输出用于边界框的最终分类与回归。
每种单模态探测器的缺点可能导致在融合阶段产生负迁移。例如,点云检测器可能由于缺乏详细的语义信息而难以区分站立的人和树干,而图像检测器由于缺乏准确的深度信息而难以在3D空间中定位物体。为了缓解负迁移问题,本文引入了一种新的跨模态信息传递方法,旨在弥补每种模态的不足。该方法应用于两个模态的输入之前的并行检测分支。如下图所示。
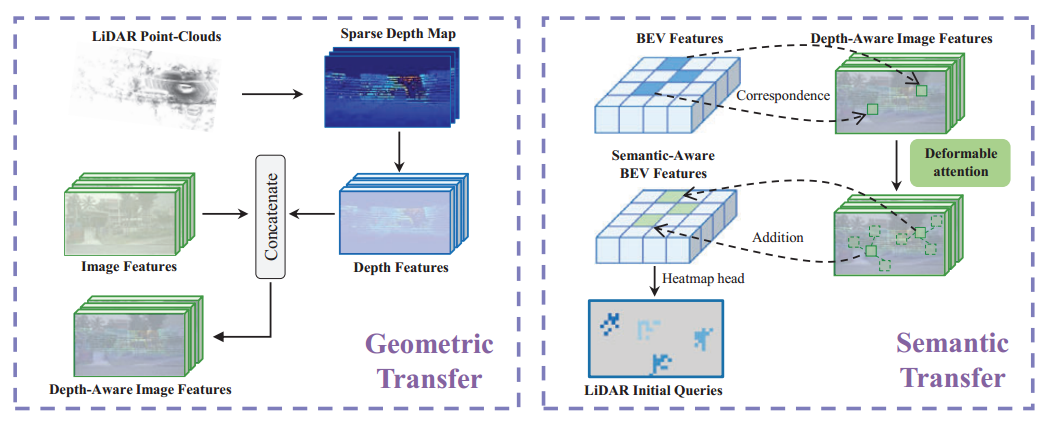
在特征提取和初始化query之前,通过上图的跨模态信息转移实现模态间信息互补,防止出现负迁移情况。
5. IS-FUSION: Instance-Scene Collaborative Fusion for Multimodal 3D Object Detection
Junbo Yin, CVPR, 2024
现有的很多方法将图像和点云先放到一个统一的空间即BEV上执行特征融合和对齐,然而这种方法忽略了前景实例和背景区域的固有差异。例如,与在自然图像中观察到的不同,BEV中表示的对象实例通常表现出更小的尺寸,这使得它占用的网格数远远小于背景区域占用的数量。因此,这种方法很难捕获对象周围的上下文信息。
虽然有一些方法旨在进行对象级编码,但忽略了实例特征和场景间的潜在协作。本文提出了一种新的多模态检测框架IS-Fusion,来解决以上挑战。
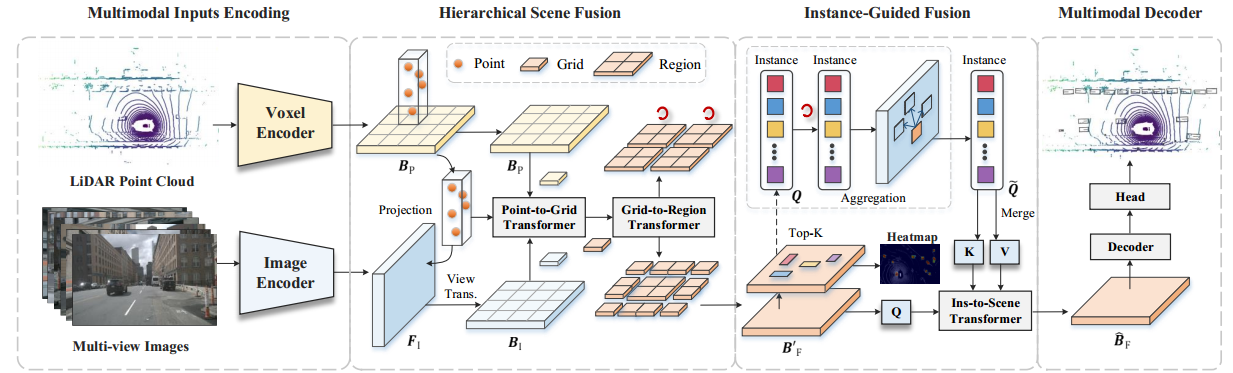
上图是本文方法的整体结构。首先分别用VoxelNet和SwinTransformer实例化点云和图像,获得了点云BEV特征Bp和图像透视图特征Fi,其中Bp是通过对三维体素特征的高度维度进行压缩得到的。
整体网络的编码器由两个模块组成,即HSF(多层次场景融合模块)和IGF(实例引导融合模块)。网络的解码器基于Transformer设计,包括几个注意力层和一个前馈网络作为检测头。在训练过程中,使用匈牙利算法来匹配预测框和真值边界框。同时,使用Focal Loss和F1 Loss进行分类和三维边界框回归。
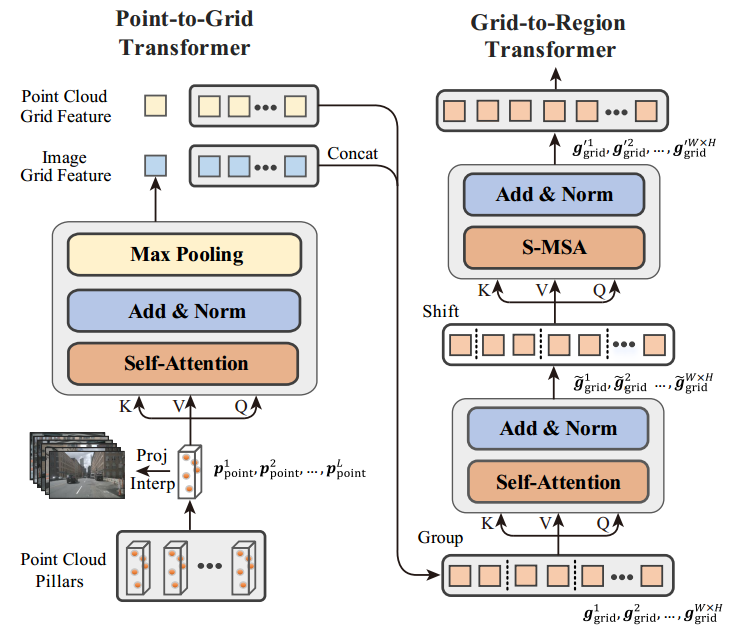
上图是HSF模块示意图。HSF模块由点到网格Transformer(P2G)和网格到区域Transformer(G2R)组成。其中,P2G考虑了每个BEV网格中的点/像素间相关性,G2R进一步挖掘了网格间和区域间的多模态场景上下文。
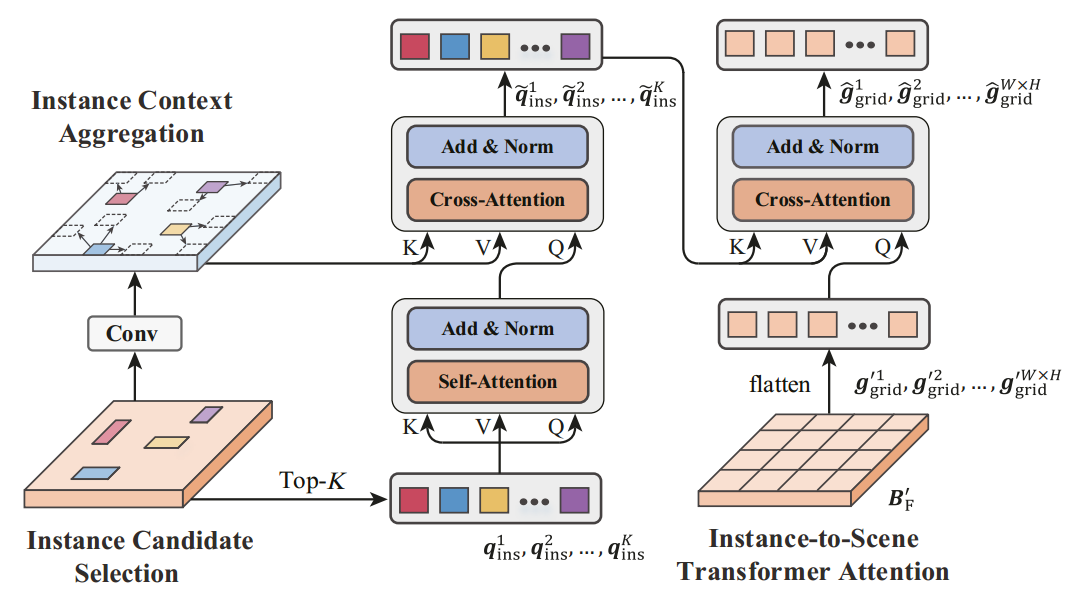
上图是IGF模块示意图。IGF模块的基本思想是挖掘每个对象周围的上下文信息(如车辆旁边的车道),同时将必要的实例级信息集成到场景特征中。例如,如果一个物体在场景特征中被错误地归类为背景的一部分,我们可以通过与所有相关实例进行比较来纠正这一错误。
- 该模块实质上就是三个注意力块,分别是实例-实例的自注意、实例-上下文的跨注意和实例-场景的多头跨注意。
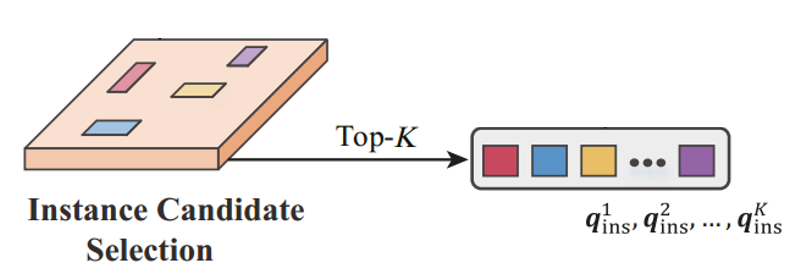
如上图所示。具体来说,首先从由HSF得到的场景特征中选择top K个最显著的实例特征。本文借鉴了Centerbased 3d object detection and tracking(CVPR, 2021)的方法,在场景特征B'F上应用关键点检测头来预测实例的中心度。在训练过程中,为每个实例定义一个二维高斯分布为目标,峰值位置由地面真值三维中心的BEV投影决定,并利用Focal Loss来优化该预测头。在推理过程中,保留具有最高中心度分数的top K个对象来表示相应的实例。同时,一个额外的线性层被用来嵌入每个实例,得到 {q1ins, q2ins, . . . , qKins}。
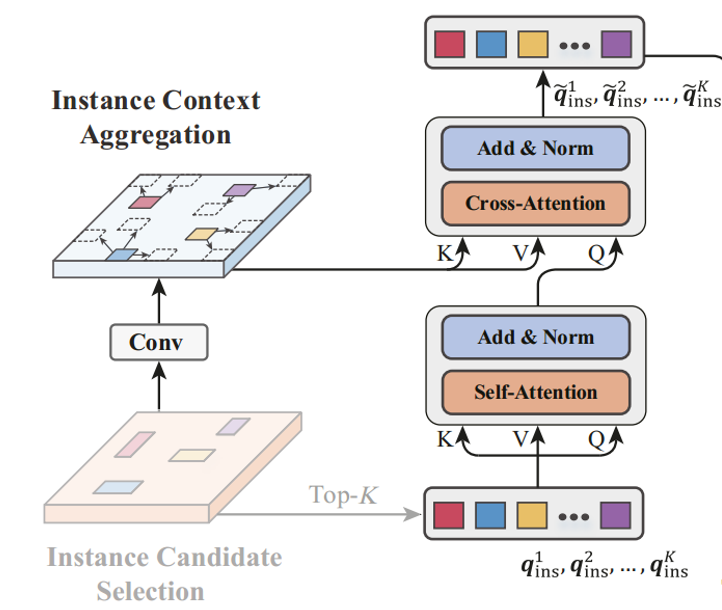
如上图所示。进行实例上下文聚合。该模块被设计为计算实例-实例和实例-上下文的交互。在典型的驾驶场景中,经常观察到行人成对成对出现,车辆在车道上共同出现,因此研究实例间的相关性至关重要。因此,首先在选定的top K个实例上使用了自关注。
此外,我们的目标是挖掘每个实例的语义上下文,这要通过比较每个实例q'ins和多模态特征B'F中的相应部分实现的。具体来说,只关注实例周围的一小组相邻位置以节省计算量,采用以下公式计算:
![]()
即先对特征B'F进行一个3*3的卷积以对齐特征和实例之间的特征空间,然后将二者进行一个可变注意力的计算,![]() 就是加入了上下文信息,enrich后的实例特征。
就是加入了上下文信息,enrich后的实例特征。
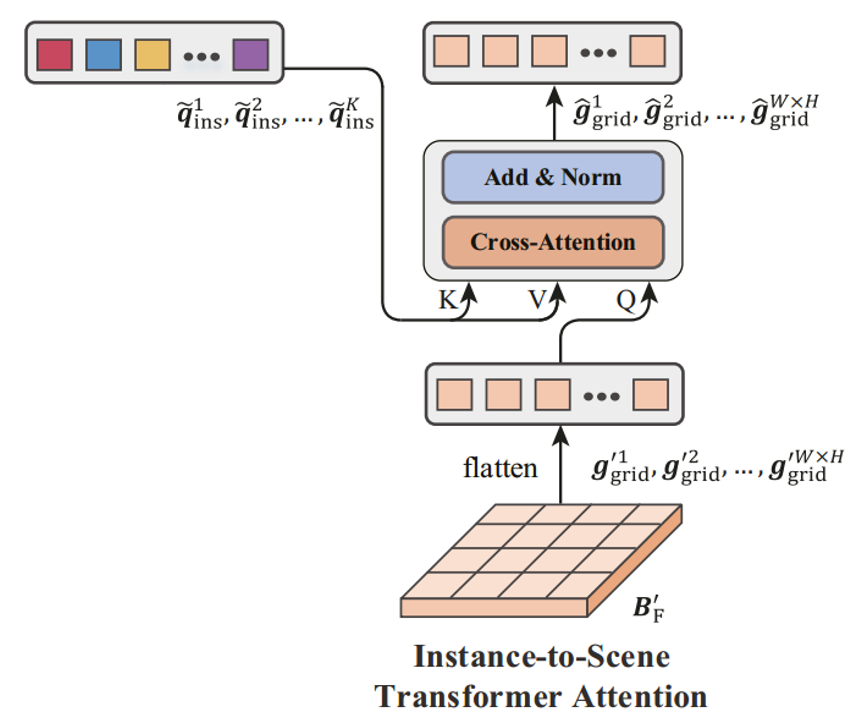
最后,对实例和场景间进行注意力交互。首先将场景特征扁平化为一组网格特征,使用每一个网格特征作为Q、实例特征作为K、V来关注实例特征,进行一个多头交叉注意力的计算。在所有网格单元上完成计算后,将重新排列得到的网格特征![]() 返回到BEV特征B'F,该特征将在最后的解码阶段使用,以产生最终的三维预测。
返回到BEV特征B'F,该特征将在最后的解码阶段使用,以产生最终的三维预测。

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









