







 本文详细介绍如何使用R语言中的pheatmap包绘制高质量的聚类热图。内容涵盖数据准备、包加载、基本热图绘制、热图参数调整、个性化设置及保存等步骤。
本文详细介绍如何使用R语言中的pheatmap包绘制高质量的聚类热图。内容涵盖数据准备、包加载、基本热图绘制、热图参数调整、个性化设置及保存等步骤。
-
一、前言
1 热图介绍
通常,热图是对所获得的数据或其他因素进行归一化处理后,用颜色的变化来直观表示不同样本间的变化情况。本质上其是由一个个用预设颜色表示数值大小的小方格组成的数据矩阵,并通过对因子或样本的聚类,观察不同样品数据间的相似性。
2 热图绘制方式
常用的绘图软件:origin,excel,Tbtools,GraphPadPrism
R语言绘制聚类热图的R包:pheatmap,heatmap,corrplot,complexHeatmap
其中,pheatmap是R语言中使用最广泛的用于绘制聚类热图的绘图包。使用该绘图包可以帮助我们快速生成包含聚类结果的热图。
二、用pheatmap包绘制聚类热图
1 数据准备
数据输入格式(csv格式):
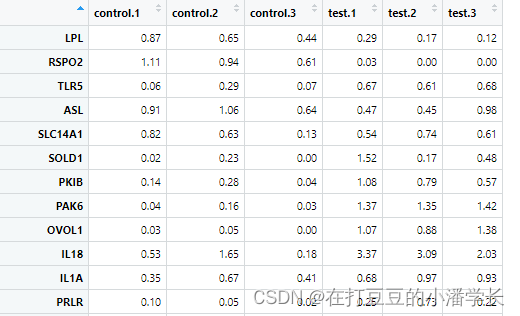
2 R包加载及数据导入
#下载包#
install.packages("pheatmap")
install.packages("RColorBrewer")
#加载包#
library("pheatmap")
library("RColorBrewer")
#加载绘图数据#
data<-read.table(file='C:/Rdata/jc/pheatmap.csv',header=TRUE,row.names= 1,sep=',')
head(data) #查看数据 
#data=log2(data[,1:6]+1) #对基因表达量数据处理
#data <- as.matrix(data) #转变为matrix格式矩阵
#head(data)3 热图绘制
3.1基础热图及标准化
pheatmap(data) #基础热图绘制 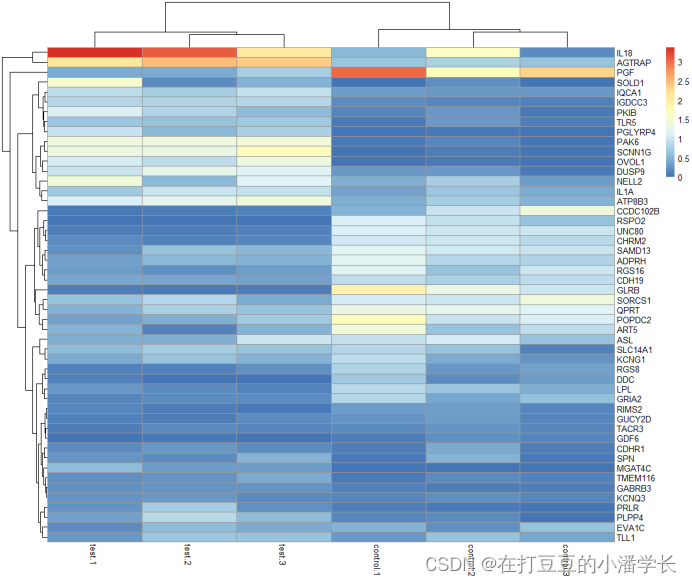
图1 数据未均一化的热图
3.2进行归一化绘图
3.2.1热图绘制准备——均一化
绘制热图通常需对数据进行归一化操作,以使差别较大的因子处于同一个数量级,从而便于观察不同因子在不同样本之间的变化规律。一般来说,一个因子在不同样本间的分布会在热图的行方向上进行展示,所以为了展示一个因子在不同样本间的分布,均一化处理会按 “row”进行。
pheatmap(data, scale='row') #标准化的方法,row是按照进行标准化(归一化),column是按照列进行标准化,none为不进行标准化 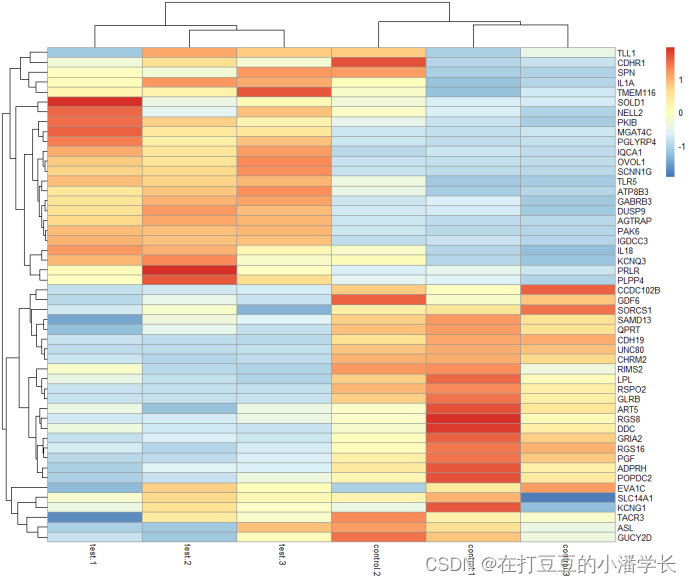
图2经过归一化处理的热图
3.3 热图聚类方式及聚类树调整
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为“euclidean”,也可为 "correlation"即按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
clust 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









