






【2023年CVPR论文】
总链接:https://jamycheung.github.io/DELIVER.html
代码链接:https://github.com/jamycheung/DELIVER
论文链接:https://arxiv.org/pdf/2303.01480.pdf
abstract
动机
- 多模态融合能提高语义分割的鲁棒性
- 但,融合任意数量的模态有待探索
创新点
- 提出DELIVER arbitrary-modal segmentation benchmark,包含Depth,LiDAR,multiple Views,Events和RGB
- 提供四种天气情况的数据集 and五个传感器故障情况
- 提出任意夸模态分割模型CMNEXT:它包含一个自查询中心(SQ-Hub)which can 从任何模态中提取有效信息,以便后续与RGB表示进行融合
- 引入Parallel Pooling Mixer(PPX):它能高效灵活地从辅助模式中获取鉴别线索
实验效果
mIoU达到了66.30%,与单模态基线相比,增加了9.10%
Introduction
背景
- 发展:模块化传感器爆炸式发展,用于语义分割的多模态融合发展迅速,aim at 强大的场景理解,达到更高的分割精度
- 痛点:缺少融合多模态的工作,即向任意模态语义分割(AMSS)的趋势
AMSS的两个发现
- 需要提供多样化的互补信息来提高分割精度
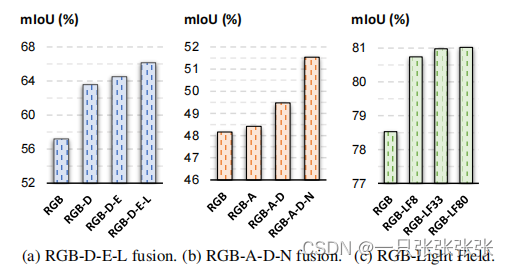
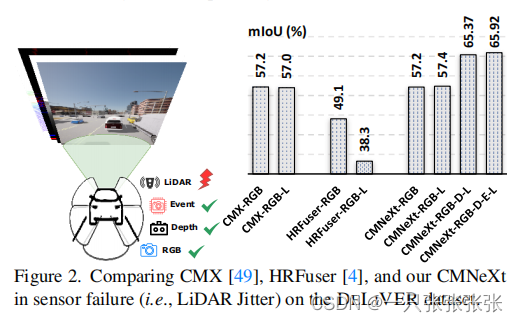
- 多种传感器的联合使用能有效地改善单个传感器故障的问题,常见的传感器故障(如激光雷达抖动)如下图所示:
本文工作
-
baseline:CARLA模拟器
-
Deliver多模态数据集:
- 包含几种模式(depth lidar views events RGB)
- 包含四种极端天气情况
- 包含五种传感器故障形式
-
CMNEXT分割模型(任意跨模态融合模型):
- 作用:
- 克服单个传感器的故障
- 提高分割的鲁棒性
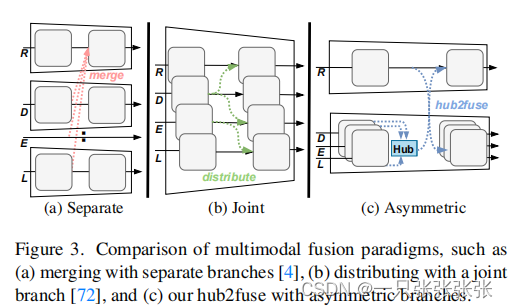
- 合并了多模态融合范式,即Hub2Fuse范式(如下图c所示)
- 不依赖于成本高昂的单独分支结构(如下图a所示)
- 也不依赖于经常丢失有价值的信息的单一联合分时结构(如下如b所示)
- 具有两个分支的非对称架构
- 一个用于RGB
- 另一个用于多种补充模式
- 作用:
-
Self-Query Hub(SQ-Hub)(用于选择信息特征)
- 目的:设计两个分支结构来获取多模态线索(其一)
- 作用:
- 在Hub2Fuse的hub步骤中从辅助模态中收集有用的互补信息,在与RGB分支融合前,从所有模态源中动态选择信息特征。
- 便于将其扩展到任意数量的模态,而增加的参数可以忽略不计(每个模态~0.01M)
-
Parallel Pooling Mixer(PPX)(用于获取识别线索)
- 目的:设计两个分支结构来获取多模态线索(其二)
- 作用:
- 为了避免系数模式难以处理的问题,利用交叉融合模块,充分利用密集和稀疏模式,将它们与PPX耦合,有效灵活地忽的最有区别性的线索。
-
实验
- 在6个数据集上取得了最先进的性能
Related Work
语义分割
- 完全卷积网络引入端到端每像素分类范式中,语义分割取得显著进展
- 范式捕获多尺度特征,附加通道和自我注意块,细化上下文鲜艳,利用边缘检索得到增强
- 视觉转换器在识别任务中的应用,出现了密集的预测转换器and语义分割转换器,以及掩模分类范式,来处理实物和分割
- transformer结构的额发展,基于MLP的、池化的、卷积的块取代注意力。
- 问题:PGB图像不能提供足够的纹理,如低光照和快速移动的场景。
多模态语义分割
- 概念:通过从补充模态中获取互补特征,如深度,热量,偏振,事件,lidar和光流来获取互补特征。
- 已有工作:
- CMX,通过多级跨模态交互处理RGB-X分割
- 附加的多模态融合方法,涉及目标检测,医疗和材料分割以及flow估计
- 缺点:
- 大多集中在融合互补的线索上,没有充分考虑在某些模态故障的情况下的多模态学习。
CMNeXt: Proposed Framework
为实现任意模态分割,CMNEXT框架通过在Hub2Fuse凡是中使用双分支结构来构建。
CMNeXt Architecture
结构图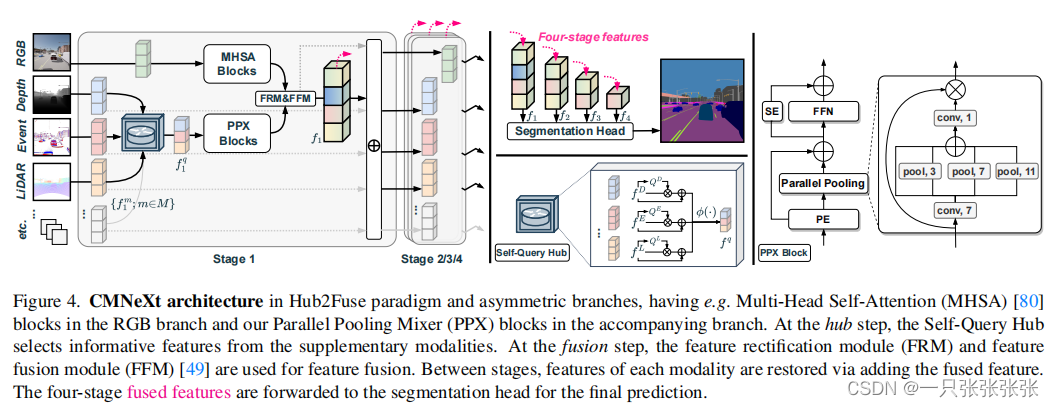
- 在RGB分支中有multi-head自我注意(MHSA)块,在伴随的分支中有我们的并行池混合器(PPX)块。
- 在hub步骤中,SQ-Hub从补充模式中选择信息性特征。
- 在融合步骤中,使用特征校流模块(FRM)和特征融合模块(FFM)进行特征融合。
- 在各个阶段之间,通过添加融合的特征来恢复每个模态的特征。
- 将四阶段融合的特征转发到分割head进行最终预测。
结构说明
encoder-decoder architecture
- encoder是一个双分支和四级编码器
双分支
- 一个是RGB(对于语义分割必不可少)
- 另一个是其他模式的次要分支
四级结构(four-stage)
- 遵循先前的CNN/Transformer模型来提取金字塔特征
预处理
- 为了模态表示的一致性,我们对激光、雷达和事件数据进行imge-like的预处理。
MHSH模块
- 逐步处理RGB数据
PPX模块
- 处理激光,雷达和事件数据
经过four stages处理后,得到
- M+1组four-stage特征图 f l m ∈ { f 1 m , f 2 m , f 3 m , f 4 m } , m ∈ [ 1 , M + 1 ] \boldsymbol{f}_{l}^{m} \in\left\{\boldsymbol{f}_{1}^{m}, \boldsymbol{f}_{2}^{m}, \boldsymbol{f}_{3}^{m}, \boldsymbol{f}_{4}^{m}\right\}, m \in[1, M+1] flm∈{f1m,f2m,f3m,f4m},m∈[1,M+1]
- 在第lth stage,每个分支的block number是bl∈{4、8、16、32},步幅为sl∈{4、8、16、32},通道尺寸为Cl∈{64、128、320、512}。
Hub2Fuse 和 SQ-Hub
- 在每个stage中,M+1个特征用Hub2Fuse中进行处理
- 在hub stage中,通过SQ-Hub,M个特征图将被合并在一个特征fq中
融合步骤
- 在融合步骤中,合并后的特征fq将通过跨模态特征校正模块(FRM)和特征融合模块(FFM)与RGB特征进一步融合,称为f。
- 这两个模块能够更好地实现多模态特征融合和交互,在RGB与稀疏特征融合时是至关重要的
- 在stage之间,通过添加融合特征f将分别恢复M+1特征图。
分割预测
- encoder后,将四级特征fl∈{f1、f2、f3、f4}转发到decoder中进行分割预测。我们使用MLP解码器作为分割head。
Self-Query Hub
- 功能:在与RGB特性融合之前选择补充模式的信息特征
- 计算m个分数掩码Qm:给定M个补充特征
{ f m ∣ m ∈ [ 1 , M ] , f m ∈ H × W × C } \left\{\boldsymbol{f}^{m} \mid m \in[1, M], \boldsymbol{f}^{m} \in H \times W \times C\right\} {fm∣m∈[1,M],fm∈H×W×C}
采用self query模块计算每个特征fm的信息分数掩码Qm∈H×W,公式如下:
f ^ m = D W − Conv 3 × 3 ( C , C ) ( f m ) , Q m = Sigmoid ( Conv ( C , 1 ) ( f ^ m ) ) , \begin{aligned} \hat{\boldsymbol{f}}^{m} & =\mathrm{DW}-\operatorname{Conv}_{3 \times 3}(C, C)\left(\boldsymbol{f}^{m}\right), \\ Q^{m} & =\operatorname{Sigmoid}\left(\operatorname{Conv}(C, 1)\left(\hat{\boldsymbol{f}}^{m}\right)\right), \end{aligned} f^mQm=DW−Conv3×3(C,C)(fm),=Sigmoid(Conv(C,1)(f^m)),- 说明:DW-Conv3×3(Cin,Cout)(·)表示一个内核大小为3×3的Depth-Wise的卷积层
- 对M个特征{fm|m∈[1,M]}进行交叉模态比较
- 用最高的分数的{fm|m∈[1,M]}中的patch pm(也就是M个modalities中最有效地patch)填补融合特征图fq中的每个patch pq。公式如下:
f q = { p q ∣ p q ∈ H × W } = ϕ ( { f m + Q m ⋅ f ^ m ∣ m ∈ [ 1 , M ] } ) = ϕ ( { p m ∣ p m ∈ H × W , m ∈ [ 1 , M ] } ) , \begin{aligned} \boldsymbol{f}^{q} & =\left\{p^{q} \mid p^{q} \in H \times W\right\} \\ & =\phi\left(\left\{\boldsymbol{f}^{m}+Q^{m} \cdot \hat{\boldsymbol{f}}^{m} \mid m \in[1, M]\right\}\right) \\ & =\phi\left(\left\{p^{m} \mid p^{m} \in H \times W, m \in[1, M]\right\}\right), \end{aligned} fq={pq∣pq∈H×W}=ϕ({fm+Qm⋅f^m∣m∈[1,M]})=ϕ({pm∣pm∈H×W,m∈[1,M]}),- 说明: ϕ \phi ϕ是一个从{fm+Qm·fˆm|m∈[1,M]}中选择最大pm的操作。
- 合并后的特征fq被转发到并行池混合器(PPX)
Parallel Pooling Mixer
- 作用:有效和灵活地从上述SQ-Hub中的任意模态补充中获取鉴别线索。
- 思路:
- 给定来自SQ-Hub的合并特征图fq∈H×W×C,应用7×7DW-Conv层来聚合局部信息。
- 这三个并行池化层用于捕获多尺度模态特征,它将与剩余的模态特征求和,并通过1×1卷积混合。
- 然后,利用s型函数计算加权的注意力。
- 公式:
f ^ q = D W − Conv 7 × 7 ( C , C ) ( f q ) f ^ q : = ∑ k ∈ { 3 , 7 , 11 } Pool k × k ( f ^ q ) + f ^ q , w = Sigmoid ( Conv 1 × 1 ( C , C ) ( f ^ q ) ) , f w = w ⋅ f q + f q \begin{array}{l} \hat{\boldsymbol{f}}^{q}=\mathrm{DW}-\operatorname{Conv}_{7 \times 7}(C, C)\left(\boldsymbol{f}^{q}\right) \\ \hat{\boldsymbol{f}}^{q}:=\sum_{k \in\{3,7,11\}} \operatorname{Pool}_{k \times k}\left(\hat{\boldsymbol{f}}^{q}\right)+\hat{\boldsymbol{f}}^{q}, \\ \boldsymbol{w}=\operatorname{Sigmoid}\left(\operatorname{Conv}_{1 \times 1}(C, C)\left(\hat{\boldsymbol{f}}^{q}\right)\right), \\ \boldsymbol{f}^{w}=\boldsymbol{w} \cdot \boldsymbol{f}^{q}+\boldsymbol{f}^{q} \\ \end{array} f^q=DW−Conv7×7(C,C)(fq)f^q:=∑k∈{3,7,11}Poolk×k(f^q)+f^q,w=Sigmoid(Conv1×1(C,C)(f^q)),fw=w⋅fq+fq - Squeeze-and-Excitation(SE)模块
- 作用:进一步在SQ-Hub的跨模态补充通道中加入更多的空间整体知识。
- 因此,加权特征fw被传递给前馈网络(FFN)和SE模块,以增强信道信息。公式如下:
f ^ w = FFN ( C , C ) ( f w ) + SE ( f w ) \hat{\boldsymbol{f}}^{w}=\operatorname{FFN}(C, C)\left(\boldsymbol{f}^{w}\right)+\operatorname{SE}\left(\boldsymbol{f}^{w}\right) f^w=FFN(C,C)(fw)+SE(fw)
- PPX块后,使用FRM&FFM模块[49]将fˆw与RGB特征融合,形成最终融合特征fl∈{f1、f2、f3、f4}
- 总结:PPX包括两个进展:
- (1)并行池化层,在注意部分有效加权;
- (2)特征混合部分的通道增强。
- PPX块的这两个特征分别有助于突出空间和通道上的跨模态融合特征。
The DELIVER Multimodal Dataset
Sensor settings and modalities
- 如下图所示,我们努力创建了一个基于CARLA模拟器的大规模多模态分割数据集
- 提供深度、激光雷达、视图、事件、RGB数据
- deliver提供了同一空间视点的六个相互正交的视图(即前、后、左、右、上、下),即,一个完整的数据帧以全景立体图的格式编码。
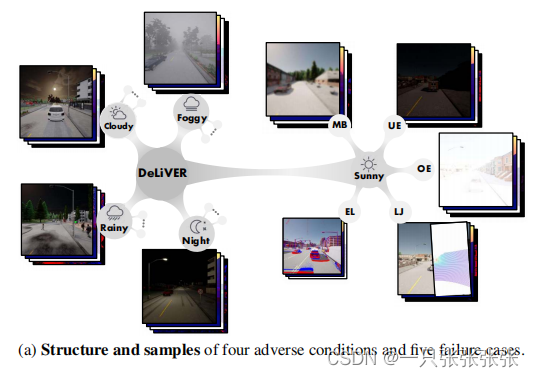
Adverse conditions and corner cases
- 提供了两种情况,包括四种环境条件和五种部分传感器故障情况(如上图所示)。
- 对于环境条件,我们考虑多云、有雾、夜间和多雨的天气条件,而不是晴天。环境条件将导致太阳的位置和照明的变化,大气漫反射、降水和阴影的场景,给强大的感知带来挑战。
- 对于传感器故障的情况,我们考虑运动模糊(MB)、过度曝光(OE)、和常见的曝光不足(UE)。
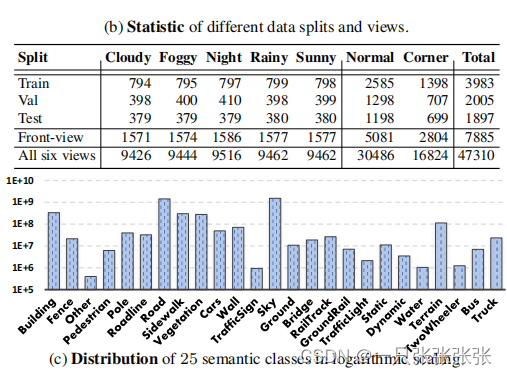
Statistics and annotations
- 包括6个视图,交付共计47,310帧(如下图所示),尺寸为1042×1042。
- 7885个前视图样本分别被分为3983/2005/1897个用于训练/验证/测试,
- 每种样本包含两种类型的注释(即语义和实例分割标签)。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









