






本文章主要了解vit-patch16-224模型,更多详情请直接在huggingface中了解。
链接:google/vit-base-patch16-224 · Hugging Face
要实现ViT大模型,请看博客:ViT大模型浅要实现-CSDN博客
vit模型架构:
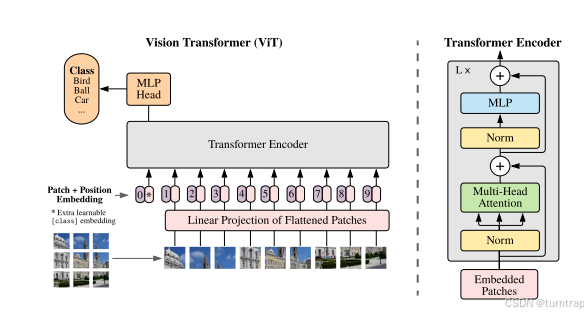
一、VIT-patch16-224模型整体配置:
Vision Transformer (ViT) 模型在分辨率为 224x224 的 ImageNet-21k(1400 万张图像,21843 个类别)上进行了预训练,并在分辨率为 224x224 的 ImageNet 2012(100 万张图像,1000 个类别)上进行了微调。
{
"_name_or_path": "google/vit-base-patch16-224",
"architectures": [
"ViTForImageClassification"
],
"attention_probs_dropout_prob": 0.0,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_size": 768,
"id2label": { },#1000个类别
"image_size": 224,
"initializer_range": 0.02,
"intermediate_size": 3072,
"label2id": { },
"layer_norm_eps": 1e-12,
"model_type": "vit",
"num_attention_heads": 12,
"num_channels": 3,
"num_hidden_layers": 12,
"patch_size": 16,
"qkv_bias": true,
"transformers_version": "4.13.0.dev0"
}
#一个224*224的图片,被分成一个个16*16的patch,则一共有(224//16)*(224//16)个patch,每个patch可以当作一个元素。
二、模型各部分组成:
2.1 图片嵌入处理ViTImageProcessor:
该部分需要找到配置文件preprocessor_config.json:
{
"do_normalize": true,
"do_resize": true,
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"size": 224
}
该部分主要调用ViTImageProcessor类的preprocess函数,在该函数内,需要进行重塑形状(do_resize)、重新缩放(do_rescale),归一化(do_normalize)。
在重塑形状时,需要将所有像素点放大到0-255区间内,之后采用双线性插值对图片尺寸进行修改,应该返回一个[batch_size,3,224,224]的images张量。
之后对图像重新缩放,缩放因子为1/255,将元素点缩小到0-1之间。
最后进行归一化,mean和std均由配置文件给出,利用image = ((image.T - mean) / std).T进行归一化。(image通道数如果在最后面,则直接使用image = (image - mean) / std即可)。
2.2 ViTPatchEmbeddings:
在该层中,主要需要利用一个卷积层将输入通道由3变为hidden_size,同时设置卷积核为16,步长为16,填充为0:
self.projection = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=patch_size)由卷积计算公式可得:
H_out=(H_in+2*p-K)//S+1=(224-16)//16+1=14
W_out=(W_in+2*p-K)//S+1=(224-16)//16+1=14
故经过卷积图像变为[batch_size,hidden_sie,14,14],之后压缩后两维,将第一维和第二维交换位置得到该部分的输出:[batch_size,196,hidden_size]
2.3 ViTEmbeddings:
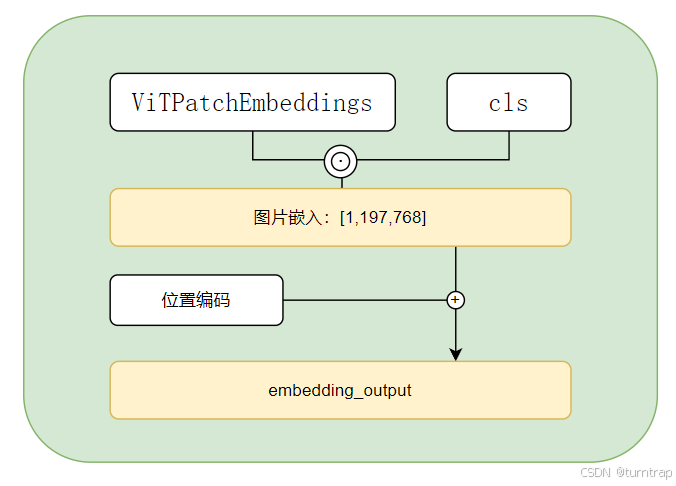
该模块主要是为了将图像编码与标志cls编码拼接,之后与位置编码相加得到后续transformers模块的输出。
图像编码由ViTPatchEmbeddings层得到,标志cls编码是一个可学习参数,二者在第一维拼接得到[batch_size,196+1,hidden_size],位置编码也是一个一维可学习参数,这时候需要注意:
如果输入图像尺寸为224,patch大小为16,则直接将位置编码与之前的拼接结果相加即可,但如果尺寸或者patch大小有改变,则不能直接相加,需要对位置编码进行双三次插值:
patch_pos_embed = nn.functional.interpolate(
patch_pos_embed,
scale_factor=(h0 / math.sqrt(num_positions), w0 / math.sqrt(num_positions)),
mode="bicubic",
align_corners=False,
)这里的patch_pos_embed是经过处理的图像的位置编码,形状为[1,768,14,14], num_positions=196,h0和w0是新的应该得到的尺寸大小,最后应该将原本的位置编码[1,197,768]变为[1,768,14,14],再变为[1,768,h0,w0],再变为[1, h0*w0+1,768],之后才能相加。
2.4 ViTForImageClassification:
该部分是模型主体,主要由一个ViT模块和一个全连接输出层组成,全连接输出层为nn.Linear(config.hidden_size, config.num_labels),ViT模块和transformers的Encoder模块基本相似。
ViT模块由ViTEmbeddings、ViTEncoder、ViTPooler组成,ViTEmbeddings在2.3介绍过,这里介绍后两个。
ViTEncoder:
ViTEncoder由12层ViTLayer组成,每个ViTLayer包括一个多头自注意力层、一个中间层、一个输出层。下图是一个ViTLayer:
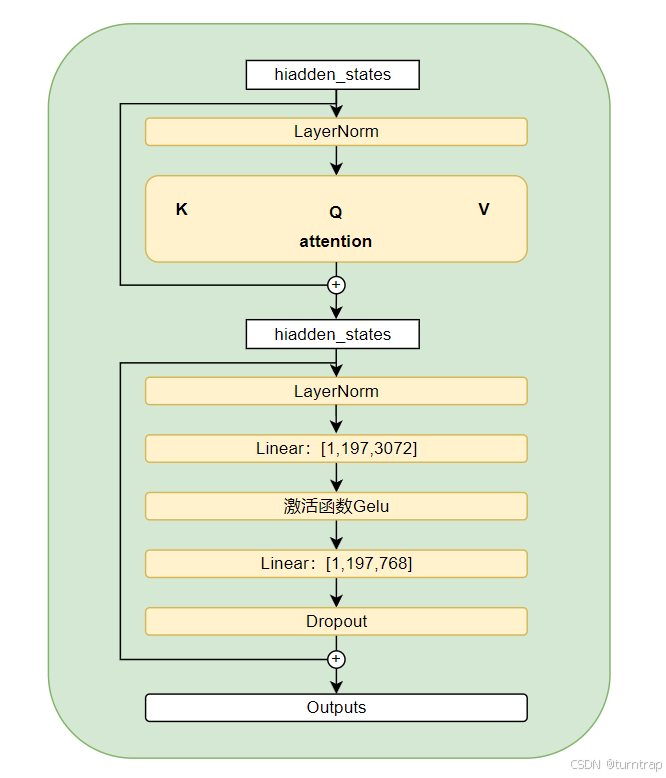
多头自注意力层如下:
class ViTSdpaSelfAttention(ViTSelfAttention):
def __init__(self, config: ViTConfig) -> None:
super().__init__(config)
self.attention_probs_dropout_prob = config.attention_probs_dropout_prob
def forward(
self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
# 变为【batch_size,heads,seq,head_dim】
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
context_layer = torch.nn.functional.scaled_dot_product_attention(
query_layer,
key_layer,
value_layer,
head_mask,
self.attention_probs_dropout_prob if self.training else 0.0,
is_causal=False,
scale=None,
)
# 变为原来的形状“【batch_size,seq,hidden_dim】
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
return context_layer, None其中self.query、self.key、self.value均为线性层,transpose_for_scores方法负责将hidden_states的形状由[batch_size,seq,hidden_dim]调整为[batch_size,heads,seq,head_dim]。在计算得到注意力分数之后在将context_layer形状调整为[batch_size,seq,hidden_size]输出
中间层主要包括一个将最后一维由hissen_size变为intermediate_size的线性层,之后经过"gelu"激活后返回。输出层包括一个将最后一维由intermediate_size变为hidden_size的线性层,之后经过dropout后返回。
得到ViTEncoder的输出后,图像形状为[batch_size,197,768],此时经过一个归一化层,之后输入池化层,池化层包括一个不做形状变化的线性层和一个tanh激活函数。最后池化层输出、归一化层输出,以及可能存在的每一个ViTLayer的输出和注意力矩阵返回。
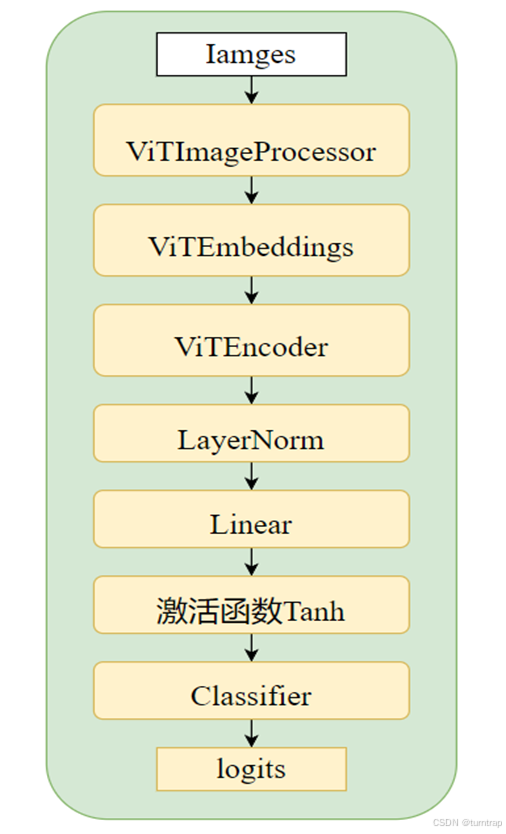
之后取归一化层输出作为全连接输出层的输入,得到分类结果,通过判断分类数量选择CrossEntropyLoss()作为损失函数,将损失loss、分类结果logits、以及可能存在的每一个ViTLayer的输出和注意力矩阵返回,后续当将数据输入model后,可调用output.logits获取分类结果。

















 3737
3737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









