







 本文介绍了如何查找和处理GEO与ArrayExpress数据库中的基因注释信息。针对原始数据,可以通过R包处理,而对于已处理的数据,可以从adf.txt文件中获取注释信息,利用R进行合并。在Bioconductor网站上可以找到对应的注释平台资源。
本文介绍了如何查找和处理GEO与ArrayExpress数据库中的基因注释信息。针对原始数据,可以通过R包处理,而对于已处理的数据,可以从adf.txt文件中获取注释信息,利用R进行合并。在Bioconductor网站上可以找到对应的注释平台资源。
1、首先我们要知道这两个数据库里面的芯片数据分为两大类,一类是原始数据,只有压缩包,压缩包里面是每个样本的信息,另一类是已经处理过的数据,是整理好的矩阵。
2.我们以GEO的GSE16778为例子
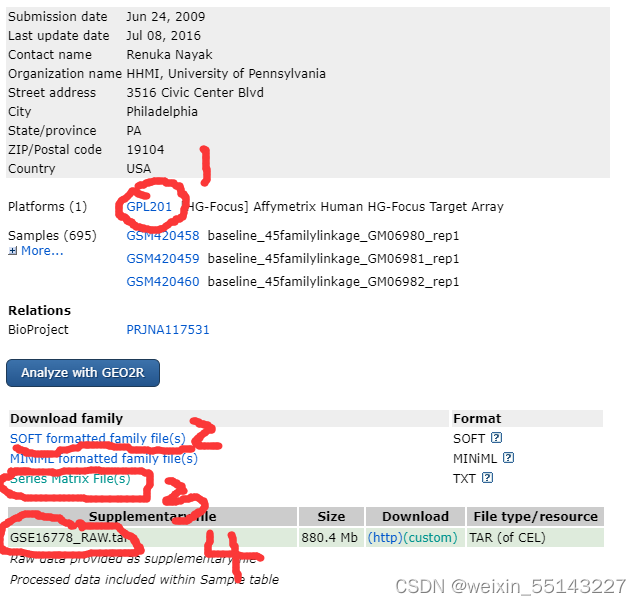
打开GEO网页,在搜索框输入GSE16778,可见下面的页面。1是注释平台信息,2里面也有注释平台信息,3是处理好的矩阵,但是若矩阵的大小小于1M,这就表明里面没有处理好的数据,这时你就需要下载4,也就是原始文件,用R进行合并处理。在网站上面的注释平台文件一般都比较大,我们可以利用R的包,下载相关的注释包,这个网上的教程都有很多了,就不在这里举例了。
3.关于arryexpress数据的注释包,有部分是与GEO数据库相同的,因为在该数据库里面有一部分的数据是来源于GEO.我这里主要讲述不在GEO数据库的部分。
针对原始数据,在网上已经有大佬分享了教程,在进行数据预处理的过程中就进行了基因注释。
对于已经处理好的数据的处理,打开adf.txt文件,搜索annotation,查看注释平台信息;可在网页用ctrl+F搜索,或者直接利用adf文件进行注释,用R提取相关列,再用merge函数合并
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4449
4449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









