







集中不等式(concentration inequalities)是在概率论和统计学中用于描述随机变量(尤其是随机变量的和或函数)的集中程度的一类不等式。它们为随机变量偏离其期望值的概率提供了上界。这些不等式在很多领域都有应用,包括机器学习、统计学习理论、组合数学和随机过程等。下面介绍几种常见的集中不等式:
1.马尔可夫不等式(Markov’s Inequality)
马尔可夫不等式(Markov’s Inequality)是概率论中的一个基本不等式,用于估计随机变量大于某个正数的概率。它适用于任何非负随机变量,提供了一个简单而有用的上界。下面是马尔可夫不等式的正式陈述及其证明。
设
X
X
X是一个非负随机变量,且
a
>
0
a > 0
a>0,则:
P
(
X
≥
a
)
≤
E
[
X
]
a
P(X \geq a) \leq \frac{\mathbb{E}[X]}{a}
P(X≥a)≤aE[X]
证明
-
考虑事件 { X ≥ a } \{X \geq a\} {X≥a},引入指示函数 I { X ≥ a } I_{\{X \geq a\}} I{X≥a},其取值为:
I { X ≥ a } = { 1 , 如果 X ≥ a , 0 , 如果 X < a . I_{\{X \geq a\}} = \begin{cases} 1, & \text{如果 } X \geq a, \\ 0, & \text{如果 } X < a. \end{cases} I{X≥a}={1,0,如果 X≥a,如果 X<a. -
由于 X ≥ a ⋅ I { X ≥ a } X \geq a \cdot I_{\{X \geq a\}} X≥a⋅I{X≥a},我们有:
X ⋅ I { X ≥ a } ≥ a ⋅ I { X ≥ a } . X \cdot I_{\{X \geq a\}} \geq a \cdot I_{\{X \geq a\}}. X⋅I{X≥a}≥a⋅I{X≥a}. -
对两边取期望值,得到:
E [ X ⋅ I { X ≥ a } ] ≥ E [ a ⋅ I { X ≥ a } ] . \mathbb{E}[X \cdot I_{\{X \geq a\}}] \geq \mathbb{E}[a \cdot I_{\{X \geq a\}}]. E[X⋅I{X≥a}]≥E[a⋅I{X≥a}]. -
由于 I { X ≥ a } I_{\{X \geq a\}} I{X≥a}是指示函数,它的期望就是事件 { X ≥ a } \{X \geq a\} {X≥a}发生的概率,因此:
E [ a ⋅ I { X ≥ a } ] = a ⋅ P ( X ≥ a ) . \mathbb{E}[a \cdot I_{\{X \geq a\}}] = a \cdot P(X \geq a). E[a⋅I{X≥a}]=a⋅P(X≥a). -
因此,不等式变为:
E [ X ⋅ I { X ≥ a } ] ≥ a ⋅ P ( X ≥ a ) . \mathbb{E}[X \cdot I_{\{X \geq a\}}] \geq a \cdot P(X \geq a). E[X⋅I{X≥a}]≥a⋅P(X≥a). -
由于 X ⋅ I { X ≥ a } ≤ X X \cdot I_{\{X \geq a\}} \leq X X⋅I{X≥a}≤X,我们有:
E [ X ⋅ I { X ≥ a } ] ≤ E [ X ] . \mathbb{E}[X \cdot I_{\{X \geq a\}}] \leq \mathbb{E}[X]. E[X⋅I{X≥a}]≤E[X]. -
结合以上两点,我们得到:
E [ X ] ≥ a ⋅ P ( X ≥ a ) . \mathbb{E}[X] \geq a \cdot P(X \geq a). E[X]≥a⋅P(X≥a). -
最终,马尔可夫不等式成立:
P ( X ≥ a ) ≤ E [ X ] a . P(X \geq a) \leq \frac{\mathbb{E}[X]}{a}. P(X≥a)≤aE[X].
应用
马尔可夫不等式在各种情况下都有广泛的应用,尤其是在对随机变量进行估计和给出尾部概率上界时。它的简单形式使得它成为其他更复杂不等式(如切尔诺夫不等式和霍夫丁不等式)的基础。
例如,假设有一个随机变量
X
X
X,其期望值为10,我们想知道
X
X
X大于或等于50的概率。应用马尔可夫不等式,有:
P
(
X
≥
50
)
≤
E
[
X
]
50
=
10
50
=
0.2.
P(X \geq 50) \leq \frac{\mathbb{E}[X]}{50} = \frac{10}{50} = 0.2.
P(X≥50)≤50E[X]=5010=0.2.
因此,
X
X
X大于或等于50的概率最多为0.2。
2.矩母函数
矩母函数(moment generating function, MGF)是概率论和统计学中的一个重要工具,用于描述随机变量的分布性质。矩母函数提供了一种方便的方法来推导随机变量的矩和分析随机变量的集中现象。
定义
对于一个随机变量 X X X,其矩母函数 M X ( t ) M_X(t) MX(t)定义为:
M X ( t ) = E [ e t X ] M_X(t) = \mathbb{E}[e^{tX}] MX(t)=E[etX]
其中 t t t是一个实数参数, E [ ⋅ ] \mathbb{E}[\cdot] E[⋅]表示期望值运算。
性质
- 存在性:如果矩母函数在某个邻域内存在(即有限),则随机变量的所有矩都存在。
- 生成矩:通过矩母函数,可以生成随机变量
X
X
X的矩。具体来说,
X
X
X的
n
n
n阶矩
E
[
X
n
]
\mathbb{E}[X^n]
E[Xn]可以通过矩母函数的
n
n
n阶导数在
t
=
0
t = 0
t=0处的值得到:
E [ X n ] = d n M X ( t ) d t n ∣ t = 0 \mathbb{E}[X^n] = \frac{d^n M_X(t)}{dt^n} \bigg|_{t=0} E[Xn]=dtndnMX(t) t=0 - 独立性:对于独立随机变量
X
X
X和
Y
Y
Y,其和的矩母函数等于各自矩母函数的乘积:
M X + Y ( t ) = M X ( t ) ⋅ M Y ( t ) M_{X+Y}(t) = M_X(t) \cdot M_Y(t) MX+Y(t)=MX(t)⋅MY(t)
举例
-
常数随机变量:如果 X = c X = c X=c是一个常数,则其矩母函数为:
M X ( t ) = E [ e t X ] = e t c M_X(t) = \mathbb{E}[e^{tX}] = e^{tc} MX(t)=E[etX]=etc -
正态分布:设 X ∼ N ( μ , σ 2 ) X \sim N(\mu, \sigma^2) X∼N(μ,σ2),则其矩母函数为:
M X ( t ) = E [ e t X ] = exp ( t μ + 1 2 t 2 σ 2 ) M_X(t) = \mathbb{E}[e^{tX}] = \exp\left(t\mu + \frac{1}{2}t^2\sigma^2\right) MX(t)=E[etX]=exp(tμ+21t2σ2)
草稿纸简单推导一下(字丑见谅…):

-
伯努利分布:设 X X X是参数为 p p p的伯努利随机变量,即 P ( X = 1 ) = p P(X=1) = p P(X=1)=p和 P ( X = 0 ) = 1 − p P(X=0) = 1-p P(X=0)=1−p,则其矩母函数为:
M X ( t ) = E [ e t X ] = p e t + ( 1 − p ) M_X(t) = \mathbb{E}[e^{tX}] = pe^t + (1-p) MX(t)=E[etX]=pet+(1−p)
应用
矩母函数在许多概率论和统计学问题中都有重要应用,特别是在以下方面:
- 推导集中不等式:如切尔诺夫界等集中不等式的证明通常依赖于矩母函数。
- 求解概率分布的矩:通过矩母函数的导数,可以方便地求解随机变量的矩。
- 分析随机变量的性质:矩母函数提供了随机变量分布的另一种表示形式,有助于分析其性质和行为。
对于第三点,这里多说一句:
- 矩母函数编码了随机变量的所有矩信息,因此它本质上提供了关于随机变量分布的完整信息。通过矩母函数可以导出随机变量的各种特性和分布形状。
矩母函数与切尔诺夫界
切尔诺夫界的证明通常依赖于矩母函数。以下是一个简要的证明思路:
- 构造矩母函数:对于独立随机变量 X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn,考虑它们的和 S n = ∑ i = 1 n X i S_n = \sum_{i=1}^n X_i Sn=∑i=1nXi的矩母函数 M S n ( t ) M_{S_n}(t) MSn(t)。
- 利用独立性:由于独立性,
S
n
S_n
Sn的矩母函数等于每个
X
i
X_i
Xi的矩母函数的乘积:
M S n ( t ) = E [ e t S n ] = ∏ i = 1 n E [ e t X i ] = ∏ i = 1 n M X i ( t ) M_{S_n}(t) = \mathbb{E}[e^{tS_n}] = \prod_{i=1}^n \mathbb{E}[e^{tX_i}] = \prod_{i=1}^n M_{X_i}(t) MSn(t)=E[etSn]=i=1∏nE[etXi]=i=1∏nMXi(t) - 应用切尔诺夫界:通过选择适当的参数 t t t,并利用矩母函数的上界,得到随机变量和偏离其期望值的概率的上界。
通过矩母函数,切尔诺夫界的证明可以简化为对矩母函数的优化问题,从而得出强有力的集中不等式。这在分析随机过程和评估算法性能时非常有用。
3.切尔诺夫不等式(Chernoff Bound)
切尔诺夫不等式(Chernoff Inequality)是一种强有力的集中不等式,用于估计独立随机变量的和偏离其期望值的概率。它通常用于分析独立二项随机变量和泊松随机变量的尾部概率。切尔诺夫不等式的两个常见形式是针对上尾和下尾概率的估计。
切尔诺夫不等式(上尾)
设
X
1
,
X
2
,
…
,
X
n
X_1, X_2, \ldots, X_n
X1,X2,…,Xn是独立的伯努利随机变量,且每个
X
i
X_i
Xi满足
P
(
X
i
=
1
)
=
p
i
P(X_i = 1) = p_i
P(Xi=1)=pi,定义
S
n
=
∑
i
=
1
n
X
i
S_n = \sum_{i=1}^n X_i
Sn=∑i=1nXi,则对于任意
0
<
δ
<
1
0 < \delta < 1
0<δ<1,有:
P
(
S
n
≥
(
1
+
δ
)
μ
)
≤
exp
(
−
δ
2
μ
2
+
δ
)
,
P(S_n \geq (1 + \delta)\mu) \leq \exp\left(-\frac{\delta^2 \mu}{2 + \delta}\right),
P(Sn≥(1+δ)μ)≤exp(−2+δδ2μ),
其中
μ
=
E
[
S
n
]
=
∑
i
=
1
n
p
i
\mu = \mathbb{E}[S_n] = \sum_{i=1}^n p_i
μ=E[Sn]=∑i=1npi。
切尔诺夫不等式(下尾)
同样的设定,对于任意
0
<
δ
<
1
0 < \delta < 1
0<δ<1,有:
P
(
S
n
≤
(
1
−
δ
)
μ
)
≤
exp
(
−
δ
2
μ
2
)
.
P(S_n \leq (1 - \delta)\mu) \leq \exp\left(-\frac{\delta^2 \mu}{2}\right).
P(Sn≤(1−δ)μ)≤exp(−2δ2μ).
一般形式的切尔诺夫不等式
设
X
1
,
X
2
,
…
,
X
n
X_1, X_2, \ldots, X_n
X1,X2,…,Xn是独立同分布的随机变量,且取值范围为
[
0
,
1
]
[0,1]
[0,1],定义
S
n
=
∑
i
=
1
n
X
i
S_n = \sum_{i=1}^n X_i
Sn=∑i=1nXi,则对于任意
t
>
0
t > 0
t>0,有:
P
(
S
n
≥
E
[
S
n
]
+
t
)
≤
exp
(
−
2
t
2
n
)
.
P(S_n \geq \mathbb{E}[S_n] + t) \leq \exp\left(-\frac{2t^2}{n}\right).
P(Sn≥E[Sn]+t)≤exp(−n2t2).
类似地,对于下尾,有:
P
(
S
n
≤
E
[
S
n
]
−
t
)
≤
exp
(
−
2
t
2
n
)
.
P(S_n \leq \mathbb{E}[S_n] - t) \leq \exp\left(-\frac{2t^2}{n}\right).
P(Sn≤E[Sn]−t)≤exp(−n2t2).
证明思想(简要)
切尔诺夫不等式的证明通常基于矩母函数(moment generating function)和鞅(martingale)的方法。以下是一个简要的证明思路:
-
矩母函数法:
- 定义矩母函数 M X ( t ) = E [ exp ( t X ) ] M_X(t) = \mathbb{E}[\exp(tX)] MX(t)=E[exp(tX)]。
- 利用独立性和随机变量的特性,构造矩母函数的上界。
- 通过选择合适的参数 t t t,优化上界以得到所需的不等式。
-
鞅法:
- 构造鞅序列并应用阿兹马尔-海涅不等式(Azuma-Hoeffding Inequality)。
- 使用鞅的性质和差值的界限来推导出尾部概率的不等式。
切尔诺夫不等式的强大之处在于它不仅适用于独立同分布的随机变量,还可以扩展到一些更复杂的情况。它在计算机科学、统计学、机器学习和组合优化中具有广泛的应用,用于分析算法性能和随机过程的行为。
切尔诺夫界的推导步骤(矩母函数法)
为了更详细地说明如何通过选择适当的参数 t t t并利用矩母函数的上界来得到随机变量和偏离其期望值的概率的上界,我们需要详细了解切尔诺夫界的推导过程。这个过程主要涉及构造随机变量和的矩母函数,并利用该函数来推导其偏离期望值的概率界限。
假设 X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn是独立随机变量,每个 X i X_i Xi的取值范围为 [ a i , b i ] [a_i, b_i] [ai,bi],定义 S n = ∑ i = 1 n X i S_n = \sum_{i=1}^n X_i Sn=∑i=1nXi,其期望值为 μ = E [ S n ] \mu = \mathbb{E}[S_n] μ=E[Sn]。我们希望估计 S n S_n Sn偏离其期望值的概率。
1. 构造矩母函数
首先,我们构造 S n S_n Sn的矩母函数 M S n ( t ) M_{S_n}(t) MSn(t):
M S n ( t ) = E [ e t S n ] M_{S_n}(t) = \mathbb{E}[e^{t S_n}] MSn(t)=E[etSn]
由于 X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn是独立的,我们有:
M S n ( t ) = E [ e t ∑ i = 1 n X i ] = ∏ i = 1 n E [ e t X i ] = ∏ i = 1 n M X i ( t ) M_{S_n}(t) = \mathbb{E}[e^{t \sum_{i=1}^n X_i}] = \prod_{i=1}^n \mathbb{E}[e^{t X_i}] = \prod_{i=1}^n M_{X_i}(t) MSn(t)=E[et∑i=1nXi]=i=1∏nE[etXi]=i=1∏nMXi(t)
2. 利用独立性和上界
对每个 X i X_i Xi,我们可以利用 e t X i e^{t X_i} etXi的期望值来构造矩母函数的上界。假设 X i X_i Xi的期望值为 E [ X i ] \mathbb{E}[X_i] E[Xi],我们有:
M X i ( t ) = E [ e t X i ] M_{X_i}(t) = \mathbb{E}[e^{t X_i}] MXi(t)=E[etXi]
根据鞅性质或其他方法,我们可以找到 M X i ( t ) M_{X_i}(t) MXi(t)的上界。假设对于每个 i i i,我们有 M X i ( t ) ≤ exp ( g ( t , X i ) ) M_{X_i}(t) \leq \exp(g(t, X_i)) MXi(t)≤exp(g(t,Xi)),其中 g ( t , X i ) g(t, X_i) g(t,Xi)是某个函数。
3. 选择合适的参数 t t t
为了估计 S n S_n Sn大于某个值 a a a的概率,我们可以应用马尔可夫不等式:
P ( S n ≥ a ) = P ( e t S n ≥ e t a ) ≤ E [ e t S n ] e t a = M S n ( t ) e t a P(S_n \geq a) = P(e^{t S_n} \geq e^{t a}) \leq \frac{\mathbb{E}[e^{t S_n}]}{e^{t a}} = \frac{M_{S_n}(t)}{e^{t a}} P(Sn≥a)=P(etSn≥eta)≤etaE[etSn]=etaMSn(t)
然后,我们利用 M S n ( t ) M_{S_n}(t) MSn(t)的上界:
M S n ( t ) ≤ exp ( ∑ i = 1 n g ( t , X i ) ) M_{S_n}(t) \leq \exp\left(\sum_{i=1}^n g(t, X_i)\right) MSn(t)≤exp(i=1∑ng(t,Xi))
结合以上不等式,我们有:
P ( S n ≥ a ) ≤ exp ( ∑ i = 1 n g ( t , X i ) ) e t a = exp ( ∑ i = 1 n g ( t , X i ) − t a ) P(S_n \geq a) \leq \frac{\exp\left(\sum_{i=1}^n g(t, X_i)\right)}{e^{t a}} = \exp\left(\sum_{i=1}^n g(t, X_i) - t a\right) P(Sn≥a)≤etaexp(∑i=1ng(t,Xi))=exp(i=1∑ng(t,Xi)−ta)
通过选择适当的 t t t使得上界最小化,可以得到最紧的概率界限。
4. 优化参数 t t t
我们选择 t t t使得 ∑ i = 1 n g ( t , X i ) − t a \sum_{i=1}^n g(t, X_i) - t a ∑i=1ng(t,Xi)−ta最小化。通常,我们需要解以下优化问题:
d d t ( ∑ i = 1 n g ( t , X i ) − t a ) = 0 \frac{d}{dt}\left(\sum_{i=1}^n g(t, X_i) - t a\right) = 0 dtd(i=1∑ng(t,Xi)−ta)=0
通过求导并解方程,我们可以找到最优的 t t t,从而得到最紧的上界。
切尔诺夫界示例
具体来看,对于独立的伯努利随机变量 X i X_i Xi,取值范围为 [ 0 , 1 ] [0, 1] [0,1],设 X i X_i Xi的期望为 p i p_i pi,则我们有:
M X i ( t ) = E [ e t X i ] = p i e t + ( 1 − p i ) M_{X_i}(t) = \mathbb{E}[e^{t X_i}] = p_i e^t + (1 - p_i) MXi(t)=E[etXi]=piet+(1−pi)
为了方便起见,我们可以对 M X i ( t ) M_{X_i}(t) MXi(t)进行上界估计,假设 X i X_i Xi是均值为 p i p_i pi的伯努利随机变量,我们有:
M X i ( t ) ≤ exp ( p i ( e t − 1 ) ) M_{X_i}(t) \leq \exp\left(p_i (e^t - 1)\right) MXi(t)≤exp(pi(et−1))
结合所有的 X i X_i Xi,我们有:
M S n ( t ) ≤ exp ( ∑ i = 1 n p i ( e t − 1 ) ) = exp ( μ ( e t − 1 ) ) M_{S_n}(t) \leq \exp\left(\sum_{i=1}^n p_i (e^t - 1)\right) = \exp\left(\mu (e^t - 1)\right) MSn(t)≤exp(i=1∑npi(et−1))=exp(μ(et−1))
然后,我们应用马尔可夫不等式并优化 t t t:
P ( S n ≥ ( 1 + δ ) μ ) ≤ inf t > 0 exp ( μ ( e t − 1 ) − t ( 1 + δ ) μ ) P(S_n \geq (1 + \delta)\mu) \leq \inf_{t > 0} \exp\left(\mu (e^t - 1) - t (1 + \delta)\mu\right) P(Sn≥(1+δ)μ)≤t>0infexp(μ(et−1)−t(1+δ)μ)
通过求解最优 t t t值,最终可以得到切尔诺夫界:
P ( S n ≥ ( 1 + δ ) μ ) ≤ exp ( − δ 2 μ 2 + δ ) P(S_n \geq (1 + \delta)\mu) \leq \exp \left( -\frac{\delta^2 \mu}{2 + \delta} \right) P(Sn≥(1+δ)μ)≤exp(−2+δδ2μ)
注意,这个求导过程还涉及到不等式放缩[2]、[1]:
[1]https://www.bilibili.com/read/cv16313012/
[2]https://blog.csdn.net/m0_46496488/article/details/130734452

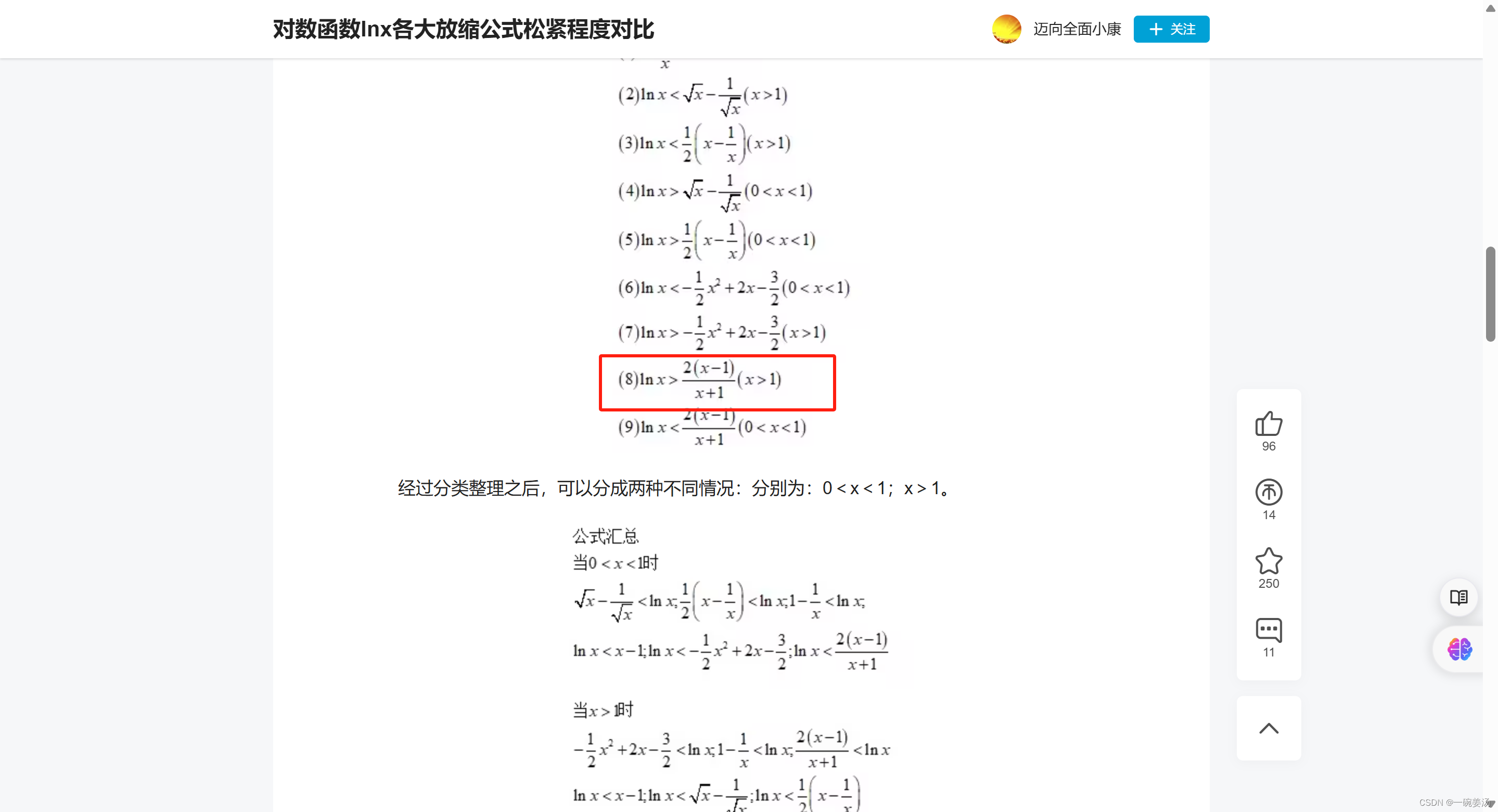
这个过程展示了如何通过选择合适的 t t t并利用矩母函数的上界,来推导随机变量和偏离其期望值的概率上界。
4.霍夫丁不等式(Hoeffding’s Inequality)
霍夫丁不等式(Hoeffding’s Inequality)是概率论中的一种重要集中不等式,它提供了独立随机变量和偏离其期望值的概率的上界。霍夫丁不等式特别适用于处理取值范围有限的独立随机变量,广泛应用于统计学和机器学习中。
设 X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn是独立随机变量,每个 X i X_i Xi的取值范围为 [ a i , b i ] [a_i, b_i] [ai,bi]。定义 S n = X 1 + X 2 + ⋯ + X n S_n = X_1 + X_2 + \cdots + X_n Sn=X1+X2+⋯+Xn,则对于任意的 ϵ > 0 \epsilon > 0 ϵ>0,有:
P ( S n − E [ S n ] ≥ t ) ≤ exp ( − 2 t 2 ∑ i = 1 n ( b i − a i ) 2 ) P(S_n - \mathbb{E}[S_n] \geq t) \leq \exp \left( -\frac{2t^2}{\sum_{i=1}^n (b_i - a_i)^2} \right) P(Sn−E[Sn]≥t)≤exp(−∑i=1n(bi−ai)22t2)
类似地,对于下尾,我们有:
P ( S n − E [ S n ] ≤ − t ) ≤ exp ( − 2 t 2 ∑ i = 1 n ( b i − a i ) 2 ) P(S_n - \mathbb{E}[S_n] \leq -t) \leq \exp \left( -\frac{2t^2}{\sum_{i=1}^n (b_i - a_i)^2} \right) P(Sn−E[Sn]≤−t)≤exp(−∑i=1n(bi−ai)22t2)
结合这两个不等式,可以得到:
P ( ∣ S n − E [ S n ] ∣ ≥ t ) ≤ 2 exp ( − 2 t 2 ∑ i = 1 n ( b i − a i ) 2 ) P(|S_n - \mathbb{E}[S_n]| \geq t) \leq 2 \exp \left( -\frac{2t^2}{\sum_{i=1}^n (b_i - a_i)^2} \right) P(∣Sn−E[Sn]∣≥t)≤2exp(−∑i=1n(bi−ai)22t2)
证明过程
Hoeffding引理及其证明
Hoeffding’s Lemma: 设
X
X
X是一个取值范围在
[
a
,
b
]
[a, b]
[a,b]之间的随机变量,且
E
[
X
]
=
μ
\mathbb{E}[X] = \mu
E[X]=μ。对于任意的
λ
∈
R
\lambda \in \mathbb{R}
λ∈R,有:
E
[
e
λ
(
X
−
μ
)
]
≤
exp
(
λ
2
(
b
−
a
)
2
8
)
\mathbb{E}[e^{\lambda (X - \mu)}] \leq \exp\left( \frac{\lambda^2 (b - a)^2}{8} \right)
E[eλ(X−μ)]≤exp(8λ2(b−a)2)
Hoeffding’s Lemma 是一个概率论中的重要不等式,用于估计独立随机变量和其期望值之间的偏差。下面是 Hoeffding’s Lemma 的详细证明推导。
证明:
-
定义中心化变量:
令 Y = X − μ Y = X - \mu Y=X−μ,则 Y Y Y的取值范围在 [ a − μ , b − μ ] [a - \mu, b - \mu] [a−μ,b−μ]之间,且 E [ Y ] = 0 \mathbb{E}[Y] = 0 E[Y]=0。 -
界定 Y Y Y的范围:
由于 X ∈ [ a , b ] X \in [a, b] X∈[a,b],所以 Y ∈ [ a − μ , b − μ ] Y \in [a - \mu, b - \mu] Y∈[a−μ,b−μ]。令 c = a − μ c = a - \mu c=a−μ, d = b − μ d = b - \mu d=b−μ,则 Y ∈ [ c , d ] Y \in [c, d] Y∈[c,d]。 -
考虑凸函数的性质:
我们考虑函数 f ( y ) = e λ y f(y) = e^{\lambda y} f(y)=eλy是一个凸函数。根据 Jensen 不等式,对于随机变量 Y Y Y和凸函数 f f f,有:
E [ f ( Y ) ] ≤ f ( E [ Y ] ) \mathbb{E}[f(Y)] \leq f(\mathbb{E}[Y]) E[f(Y)]≤f(E[Y])
由于 E [ Y ] = 0 \mathbb{E}[Y] = 0 E[Y]=0,所以 f ( E [ Y ] ) = f ( 0 ) = e 0 = 1 f(\mathbb{E}[Y]) = f(0) = e^0 = 1 f(E[Y])=f(0)=e0=1。
二次函数上界逼近(quadratic upper bound approximation)
二次函数上界逼近(quadratic upper bound approximation)是一种用来近似或上界复杂函数的方法,特别适用于凸函数。具体来说,它利用二次函数来提供一个比目标函数更宽松但较易处理的上界。这种方法在概率论和统计学中非常常见,例如在推导 Hoeffding’s Lemma 时,我们使用它来找到 e λ Y e^{\lambda Y} eλY的上界。
考虑凸函数 f ( y ) = e λ y f(y) = e^{\lambda y} f(y)=eλy。由于 e λ y e^{\lambda y} eλy是凸函数,所以可以用二次函数来逼近它。具体来说,对于任意的实数 y y y,我们有:
e λ y ≤ exp ( λ y + λ 2 y 2 2 ) e^{\lambda y} \leq \exp\left(\lambda y + \frac{\lambda^2 y^2}{2}\right) eλy≤exp(λy+2λ2y2)
这一不等式表明,指数函数 e λ y e^{\lambda y} eλy可以被 λ y + λ 2 y 2 2 \lambda y + \frac{\lambda^2 y^2}{2} λy+2λ2y2所支配,并且由于 exp ( λ y + λ 2 y 2 2 ) \exp\left(\lambda y + \frac{\lambda^2 y^2}{2}\right) exp(λy+2λ2y2)是 e λ y e^{\lambda y} eλy的一个上界。
推导过程
-
函数和二次逼近:
考虑函数 f ( y ) = e λ y f(y) = e^{\lambda y} f(y)=eλy在 y = 0 y = 0 y=0处的二阶泰勒展开:
e λ y ≈ 1 + λ y + λ 2 y 2 2 e^{\lambda y} \approx 1 + \lambda y + \frac{\lambda^2 y^2}{2} eλy≈1+λy+2λ2y2 -
严格凸性:
由于 e λ y e^{\lambda y} eλy是严格凸函数,这意味着在 y = 0 y = 0 y=0处的二阶泰勒展开的前两项加上一个非负的额外项会形成一个严格的上界:
e λ y ≤ exp ( λ y + λ 2 y 2 2 ) e^{\lambda y} \leq \exp\left(\lambda y + \frac{\lambda^2 y^2}{2}\right) eλy≤exp(λy+2λ2y2) -
应用 Jensen 不等式:
对于任意随机变量 Y Y Y,利用 Jensen 不等式,我们可以对期望进行上界:
E [ e λ Y ] ≤ E [ exp ( λ Y + λ 2 Y 2 2 ) ] ≤ exp ( E [ λ Y + λ 2 Y 2 2 ] ) \mathbb{E}[e^{\lambda Y}] \leq \mathbb{E}\left[\exp\left(\lambda Y + \frac{\lambda^2 Y^2}{2}\right)\right]\leq \exp\left(\mathbb{E}\left[\lambda Y + \frac{\lambda^2 Y^2}{2}\right]\right) E[eλY]≤E[exp(λY+2λ2Y2)]≤exp(E[λY+2λ2Y2]) -
期望值估计:
最终,我们考虑 Y Y Y的取值范围及其方差,通过上面的二次逼近不等式,我们可以得到:
E [ e λ Y ] ≤ exp ( λ 2 ( b − a ) 2 8 ) \mathbb{E}[e^{\lambda Y}] \leq \exp\left(\frac{\lambda^2 (b - a)^2}{8}\right) E[eλY]≤exp(8λ2(b−a)2)
二次函数上界逼近的核心思想是利用简单的二次函数形式来严格上界复杂的指数函数。这样做的好处在于二次函数的解析形式更加简单,易于处理和计算,从而使得证明和推导变得更加简洁。
这样,我们完成了 Hoeffding’s Lemma 的证明推导。
矩母函数的上界推导过程
-
定义矩母函数:
对于随机变量 X i X_i Xi,其矩母函数 M X i ( t ) M_{X_i}(t) MXi(t)定义为:
M X i ( t ) = E [ e t X i ] M_{X_i}(t) = \mathbb{E}[e^{tX_i}] MXi(t)=E[etXi]
-
使用鞅的性质:
考虑随机变量 X i X_i Xi 的偏差 ( X i − E [ X i ] ) (X_i - \mathbb{E}[X_i]) (Xi−E[Xi]),我们定义鞅差序列:
Y i = X i − E [ X i ] Y_i = X_i - \mathbb{E}[X_i] Yi=Xi−E[Xi]
注意到 Y i Y_i Yi的期望为零:
E [ Y i ] = 0 \mathbb{E}[Y_i] = 0 E[Yi]=0
-
鞅的矩母函数:
利用鞅的性质,我们考虑 e t Y i e^{t Y_i} etYi的期望。首先,我们有:
E [ e t X i ] = E [ e t ( Y i + E [ X i ] ) ] = e t E [ X i ] E [ e t Y i ] \mathbb{E}[e^{t X_i}] = \mathbb{E}[e^{t (Y_i + \mathbb{E}[X_i])}] = e^{t \mathbb{E}[X_i]} \mathbb{E}[e^{t Y_i}] E[etXi]=E[et(Yi+E[Xi])]=etE[Xi]E[etYi]
-
应用霍夫丁引理(Hoeffding’s Lemma):
对于随机变量 Y i Y_i Yi的取值范围 [ − a , b ] [-a, b] [−a,b],霍夫丁引理告诉我们:
E [ e t Y i ] ≤ exp ( t 2 ( b − ( − a ) ) 2 8 ) \mathbb{E}[e^{t Y_i}] \leq \exp\left(\frac{t^2 (b - (-a))^2}{8}\right) E[etYi]≤exp(8t2(b−(−a))2)
在这里,由于 X i X_i Xi的取值范围为 [ 0 , c i ] [0, c_i] [0,ci],即 Y i Y_i Yi的取值范围为 [ − a , b ] [-a, b] [−a,b]的情况变为 [ − c i , 0 ] [-c_i, 0] [−ci,0]或 [ 0 , c i ] [0, c_i] [0,ci]。所以:
E [ e t Y i ] ≤ exp ( t 2 c i 2 8 ) \mathbb{E}[e^{t Y_i}] \leq \exp\left(\frac{t^2 c_i^2}{8}\right) E[etYi]≤exp(8t2ci2)
-
结合结果:
回到原矩母函数 M X i ( t ) M_{X_i}(t) MXi(t)的计算:
E [ e t X i ] = e t E [ X i ] E [ e t Y i ] ≤ e t E [ X i ] exp ( t 2 c i 2 8 ) \mathbb{E}[e^{t X_i}] = e^{t \mathbb{E}[X_i]} \mathbb{E}[e^{t Y_i}] \leq e^{t \mathbb{E}[X_i]} \exp\left(\frac{t^2 c_i^2}{8}\right) E[etXi]=etE[Xi]E[etYi]≤etE[Xi]exp(8t2ci2)
因此,得到了 X i X_i Xi 的矩母函数的上界:
E [ e t X i ] ≤ exp ( t E [ X i ] + t 2 c i 2 8 ) \mathbb{E}[e^{t X_i}] \leq \exp\left(t \mathbb{E}[X_i] + \frac{t^2 c_i^2}{8}\right) E[etXi]≤exp(tE[Xi]+8t2ci2)
这个上界在推导霍夫丁不等式和其他集中不等式时非常有用。
利用单个变量的矩母函数
假设 X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn是独立的随机变量,且每个 X i X_i Xi的取值范围为 [ a i , b i ] [a_i, b_i] [ai,bi]。定义 S n = X 1 + X 2 + ⋯ + X n S_n = X_1 + X_2 + \cdots + X_n Sn=X1+X2+⋯+Xn,其期望值为 E [ S n ] \mathbb{E}[S_n] E[Sn]。
为了简化推导,我们可以对每个 X i X_i Xi进行重平移,使其取值范围为 [ 0 , b i − a i ] [0, b_i - a_i] [0,bi−ai]。这不会影响最终的不等式,因为我们只关心偏离期望值的概率。因此,假设每个 X i X_i Xi的取值范围为 [ 0 , c i ] [0, c_i] [0,ci],其中 c i = b i − a i c_i = b_i - a_i ci=bi−ai。
定义 S n = ∑ i = 1 n X i S_n = \sum_{i=1}^n X_i Sn=∑i=1nXi,为了估计 S n S_n Sn偏离其期望值的概率,我们使用切尔诺夫界。首先,我们计算矩母函数 E [ e t S n ] \mathbb{E}[e^{t S_n}] E[etSn]:
E [ e t S n ] = E [ e t ∑ i = 1 n X i ] = ∏ i = 1 n E [ e t X i ] \mathbb{E}[e^{t S_n}] = \mathbb{E}\left[e^{t \sum_{i=1}^n X_i}\right] = \prod_{i=1}^n \mathbb{E}[e^{t X_i}] E[etSn]=E[et∑i=1nXi]=i=1∏nE[etXi]
由于 X i X_i Xi是独立的。
对每个 X i X_i Xi,考虑其矩母函数 E [ e t X i ] \mathbb{E}[e^{t X_i}] E[etXi]。由于 X i X_i Xi的取值范围为 [ 0 , c i ] [0, c_i] [0,ci],根据矩母函数的上界推导过程结论,我们有:
E [ e t X i ] ≤ exp ( t E [ X i ] + t 2 c i 2 8 ) \mathbb{E}[e^{t X_i}] \leq \exp\left(t \mathbb{E}[X_i] + \frac{t^2 c_i^2}{8}\right) E[etXi]≤exp(tE[Xi]+8t2ci2)
总和的矩母函数
将以上结果应用到所有的 X i X_i Xi,我们有:
E [ e t S n ] ≤ ∏ i = 1 n exp ( t E [ X i ] + t 2 c i 2 8 ) = exp ( t ∑ i = 1 n E [ X i ] + t 2 ∑ i = 1 n c i 2 8 ) \mathbb{E}[e^{t S_n}] \leq \prod_{i=1}^n \exp\left(t \mathbb{E}[X_i] + \frac{t^2 c_i^2}{8}\right) = \exp\left(t \sum_{i=1}^n \mathbb{E}[X_i] + \frac{t^2 \sum_{i=1}^n c_i^2}{8}\right) E[etSn]≤i=1∏nexp(tE[Xi]+8t2ci2)=exp(ti=1∑nE[Xi]+8t2∑i=1nci2)
设 μ = E [ S n ] = ∑ i = 1 n E [ X i ] \mu = \mathbb{E}[S_n] = \sum_{i=1}^n \mathbb{E}[X_i] μ=E[Sn]=∑i=1nE[Xi]和 v = ∑ i = 1 n c i 2 v = \sum_{i=1}^n c_i^2 v=∑i=1nci2,则:
E [ e t S n ] ≤ exp ( t μ + t 2 v 8 ) \mathbb{E}[e^{t S_n}] \leq \exp\left(t \mu + \frac{t^2 v}{8}\right) E[etSn]≤exp(tμ+8t2v)
应用马尔可夫不等式
现在,我们应用马尔可夫不等式来估计 S n S_n Sn偏离其期望值的概率:
P ( S n ≥ μ + t ) = P ( e λ S n ≥ e λ ( μ + t ) ) ≤ E [ e λ S n ] e λ ( μ + t ) P(S_n \geq \mu + t) = P(e^{\lambda S_n} \geq e^{\lambda (\mu + t)}) \leq \frac{\mathbb{E}[e^{\lambda S_n}]}{e^{\lambda (\mu + t)}} P(Sn≥μ+t)=P(eλSn≥eλ(μ+t))≤eλ(μ+t)E[eλSn]
将矩母函数的上界代入:
P ( S n ≥ μ + t ) ≤ exp ( λ μ + λ 2 v 8 ) e λ ( μ + t ) = exp ( λ μ + λ 2 v 8 − λ μ − λ t ) = exp ( − λ t + λ 2 v 8 ) P(S_n \geq \mu + t) \leq \frac{\exp\left(\lambda \mu + \frac{\lambda^2 v}{8}\right)}{e^{\lambda (\mu + t)}} = \exp\left(\lambda \mu + \frac{\lambda^2 v}{8} - \lambda \mu - \lambda t\right) = \exp\left(- \lambda t + \frac{\lambda^2 v}{8}\right) P(Sn≥μ+t)≤eλ(μ+t)exp(λμ+8λ2v)=exp(λμ+8λ2v−λμ−λt)=exp(−λt+8λ2v)
优化参数 λ \lambda λ
选择 λ \lambda λ使得上界最小化。为此,我们令:
− λ t + λ 2 v 8 -\lambda t + \frac{\lambda^2 v}{8} −λt+8λ2v
取导数并设导数为零以找到最优 λ \lambda λ:
d d λ ( − λ t + λ 2 v 8 ) = − t + λ v 4 = 0 \frac{d}{d\lambda} \left( -\lambda t + \frac{\lambda^2 v}{8} \right) = -t + \frac{\lambda v}{4} = 0 dλd(−λt+8λ2v)=−t+4λv=0
解得:
λ = 4 t v \lambda = \frac{4t}{v} λ=v4t
将这个 λ \lambda λ代入上界:
P ( S n ≥ μ + t ) ≤ exp ( − 4 t 2 v + 16 t 2 8 v ) = exp ( − 2 t 2 v ) P(S_n \geq \mu + t) \leq \exp\left(- \frac{4t^2}{v} + \frac{16t^2}{8v}\right) = \exp\left(- \frac{2t^2}{v}\right) P(Sn≥μ+t)≤exp(−v4t2+8v16t2)=exp(−v2t2)
下界形式
类似地,对于 S n ≤ μ − t S_n \leq \mu - t Sn≤μ−t的情况,我们可以得到:
P ( S n ≤ μ − t ) ≤ exp ( − 2 t 2 v ) P(S_n \leq \mu - t) \leq \exp\left(- \frac{2t^2}{v}\right) P(Sn≤μ−t)≤exp(−v2t2)
结合形式
综合上面两个结果,我们得到霍夫丁不等式:
P ( ∣ S n − μ ∣ ≥ t ) ≤ 2 exp ( − 2 t 2 ∑ i = 1 n ( b i − a i ) 2 ) P(|S_n - \mu| \geq t) \leq 2 \exp\left(- \frac{2t^2}{\sum_{i=1}^n (b_i - a_i)^2}\right) P(∣Sn−μ∣≥t)≤2exp(−∑i=1n(bi−ai)22t2)
结论
霍夫丁不等式为独立随机变量的和偏离其期望值的概率提供了一个强有力的上界,广泛应用于统计学和机器学习等领域。

















 7872
7872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









