






BA
1、针孔相机模型

2、非线性优化
slam经典问题;sfm问题的转化;后验=似然*先验;最大似然估计;以单次观测为例子计算条件概率密度函数,高维高斯分布;对于批量观测数据将z u拆开转化为slam经典问题,取负对数转为最小二乘问题。


3、非线性最小二乘



4、李群李代数

RANSAC聚类算法
随机抽样一致算法(RANdom SAmple Consensus,RANSAC),采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。RANSAC算法假设数据中包含正确数据和异常数据。正确数据记为内点(inliers),异常数据记为外点(outliers)。该算法核心思想是随机性和假设性,随机性是根据正确数据出现概率去随机选取抽样数据,根据大数定律,随机性模拟可以近似得到正确结果。假设性是假设选取出的抽样数据都是正确数据,然后用这些正确数据通过问题满足的模型,去计算其他点,然后对这次结果进行一个评分。
原理思路:
(1)要得到一个直线模型,需要两个点唯一确定一个直线方程。所以第一步随机选择两个点。
(2)通过这两个点,可以计算出这两个点所表示的模型方程y=ax+b。
(3)将所有的数据点套到这个模型中计算误差。
(4)找到所有满足误差阈值的点。
(5)然后我们再重复(1)~(4)这个过程,直到达到一定迭代次数后,选出那个被支持的最多的模型,作为问题的解。如下图所示:
RANSAC的优点是它能鲁棒的估计模型参数。例如,它能从包含大量局外点的数据集中估计出高精度的参数。
RANSAC的缺点是它计算参数的迭代次数没有上限;如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。RANSAC只有一定的概率得到可信的模型,概率与迭代次数成正比。RANSAC的另一个缺点是它要求设置跟问题相关的阀值。
RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。
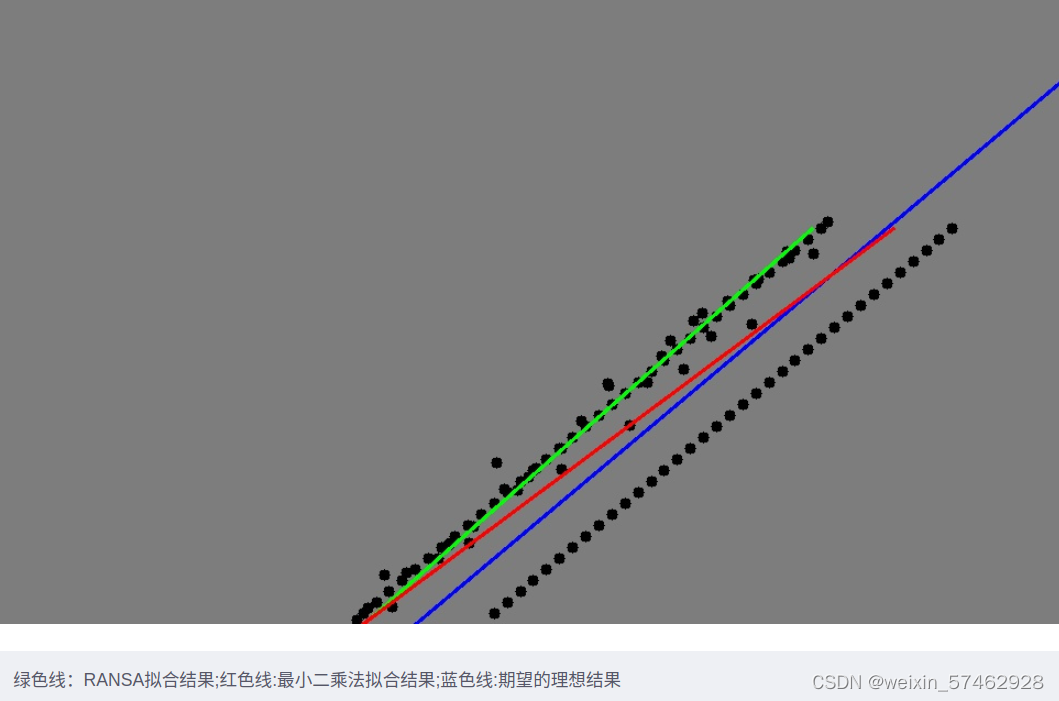
RANSAC可以对局外点进行剔除,这一点是比较好的,但它也并不是完美的,当它对于拟合两条平近似平行直线分布的点时,拟合出来的结果并不是最好的,甚至可以说拟合的结果是不对的。因为最终的正确结果有可能并不是经过所给的数据点的,如下图所示
AFK-MC2
马尔科夫链蒙特卡洛方法
蒙特卡罗法(Monte Carlo method),也称为统计模拟方法(statistical simulation method),是通过从概率模型的随机抽样进行近似数值计算的方法。
马尔可夫链蒙特卡罗法(Markov Chain Monte Carlo,MCMC),则是以马尔可夫链(Markovchain)为概率模型的蒙特卡罗法。马尔可夫链蒙特卡罗法构建一个马尔可夫链,使其平稳分布就是要进行抽样的分布,首先基于该马尔可夫链进行随机游走,产生样本的序列,之后使用该平稳分布的样本进行近似的数值计算。
使用场景
当所求解的问题是某种随机事件出现的概率,或者是某个随机变量的期望值时,通过某种"实验"(或者说"计算机实验"的方法),以事件出现的频率作为随机事件的概率(落在圆内的概率等),或者得到这个随机变量的某些数字特征(积分值,净利润等),并将其作为问题的解。
比如说我要求某个参量,直接求解遇到了困难,那我就构造一个合适的概率模型,对这个模型进行大量的采样和统计实验,使它的某些统计参量正好是待求问题的解,那么,只需要把这个参量的值统计出来,那么问题的解就得到了估计值。
蒙特卡罗法的核心是随机抽样
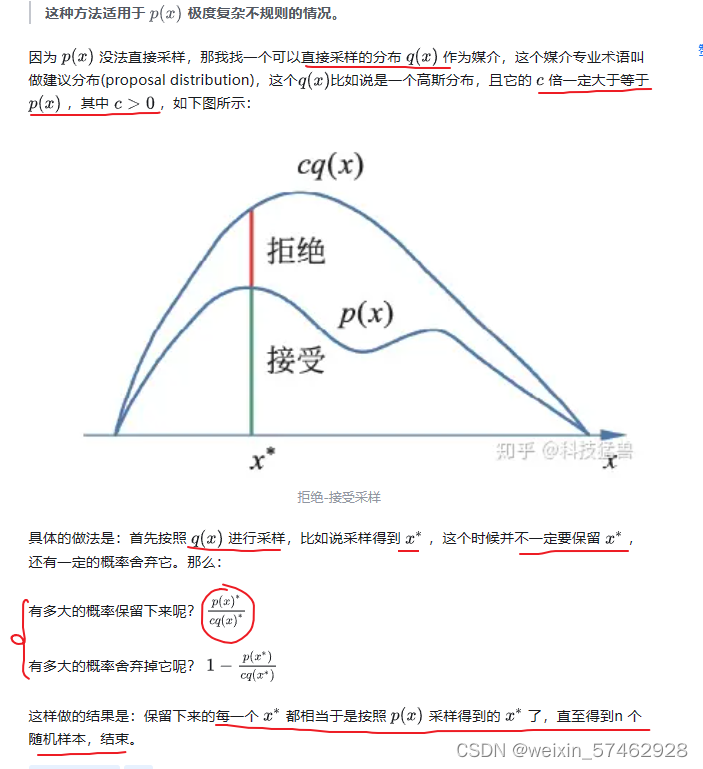
随机抽样方法1:拒绝-接受采样(acceptance probability)

def:马尔科夫链


- 不可约:每个状态都能去到。
- 非周期:返回时间公约数是1。
- 正常返:离开此状态有限步一定能回来。迟早会回来。
- 零常返:离开此状态能回来,但需要无穷多步。
- 非常返:离开此状态有限步不一定回得来。
- 遍历定理:不可约,非周期,正常返 ->有唯一的平稳分布。
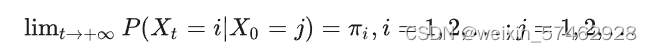
结论:每个时刻在这个马尔可夫链上进行随机游走一次,就可以得到一个样本。根据遍历定理,当时间趋于无穷时,样本的分布趋近平稳分布,样本的函数均值趋近函数的数学期望。

马尔科夫链蒙特卡罗方法总论



VIO
视觉里程计分为特征点法和直接法
特征点匹配
特征点由关键点和描述子两部分组成,有许多人为判断为关键点的方法,例如SIFT,SURF,FAST,ORB。
Harris角点
Harris⾓点检测算法是⽤于检测图像中⾓点的⼀种⽅法。其原理基于⾓点在不同⽅向上像素灰度变化较
⼤的特点。通过计算局部区域的灰度变化来检测⾓点。
算法原理
- 计算图像像素的梯度:使⽤Sobel算⼦计算图像在x和y⽅向上的梯度。
- 计算结构矩阵:在每个像素点上构建⼀个结构矩阵,包括对梯度的加权和(Ix^2、 Iy^2和IxIy)。
- 计算⾓点响应函数:对结构矩阵进⾏特征值分解,得到特征值λ1和λ2,计算⾓点响应函数R=det(M)-k(trace(M))^2,其中k为经验常数。
- 选取⾓点:根据⾓点响应函数的⼤⼩,筛选局部极⼤值作为⾓点。
SIFT
SIFT算法原理
1.检测尺度空间极值
2.关键点的精确定位
3.关键点主方向分配
4.关键点的特征描述
ORB
由关键点和描述子两部分组成,提取ORB特征分如下两步:
- FAST角点提取,找出角点,同时计算特征点主方向,为后续旋转不变性做基础。
- BRIEF描述子,对特征点的周围区域进行描述。
FAST
- 在图像中选取像素p,假设它的亮度为Ip
2)设置一个阈值T,比如Ip的20%。
3)以像素p为中心,选取半径为3的圆上的16个像素点。
4)假设圆上连续12个点的值大于Ip+T,或者小于lp-T,该像素点就可以认为
是特征点。
5)对每一个像素重复以上的操作。
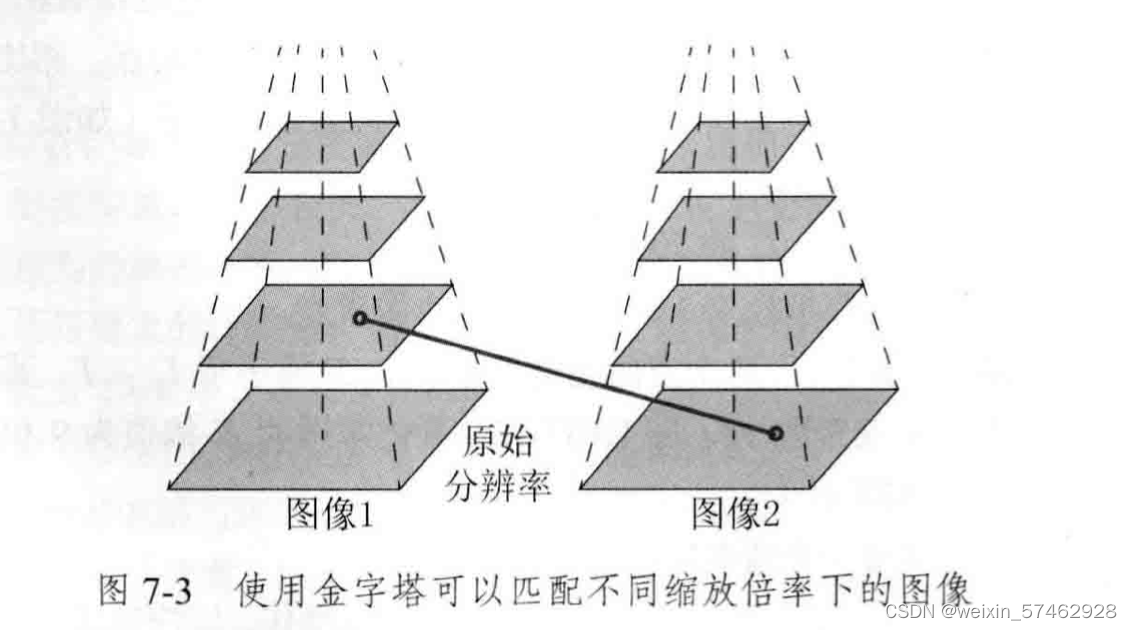
但是以上没有方向信息,尺度信息,针对以上,旋转不变性用灰度质心法解决,尺度不变性用金字塔解决。
针对尺度->建立图像金字塔
针对旋转->灰度质心法
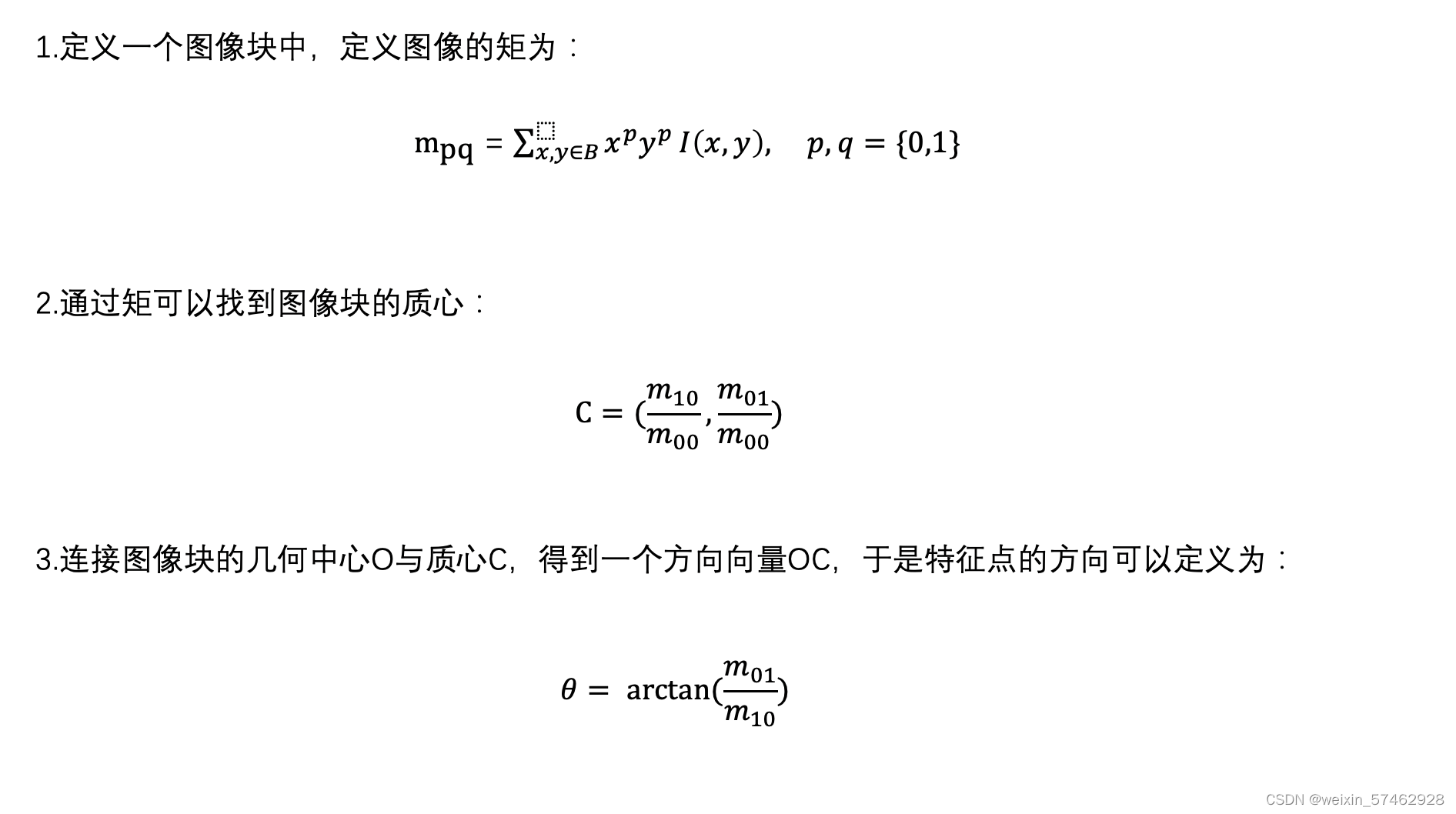
基于以上的改进,称为Oriented FAST
BRIEF
在提取Oriented FAST关键点后,我们对每个点计算其描述子。ORB使用改进的BRIEF特征描述。
BRIEF是一种二进制描述子,其描述响亮通常由很多个0和1组成,这里的0和1编码了关键点附近两个随机像素(比如p和q)的大小关系:如果p比q大,则取1,反之就取0。
如果我们取128对这样的点,那我们最后就会得到128维由0、1组成的向量。
BRIEF的优点:使用随机点的比较,速度非常快,而且由于使用二进制表达,存储起来也非常方便,适用于实时的图像匹配。
原始的BRIEF 描述子不具有旋转不变性,因此在图像发生旋转时容易丢失。而ORB在FAST特征点提取阶段计算了关键点的方向,所以可以利用方向信息,计算旋转后的“steer BRIEF”特征使得ORB描述子具有较好的旋转不变性。
暴力匹配
使用汉明距离
如何匹配?
最直白的方法就是通过暴力匹配,例如用第一张图片的第一个关键点的描述子与第二张图片所有关键点的描述子进行匹配。分别计算两个描述子的汉明距离,计算不同位数的个数,不同的越少越好。
但是利用暴力匹配运算量非常庞大,特别是想要匹配一帧和一个地图的时候。这不符合SLAM要求的实时性。
所以我们可以利用FLANN的策略来加速匹配。
对极几何
- 当相机为单目时,2D-2D,使用对极几何
- 当相机为双目、RGB-D时,3D-3D,使用ICP
- 一组3D,一组2D,采用PnP
对极约束
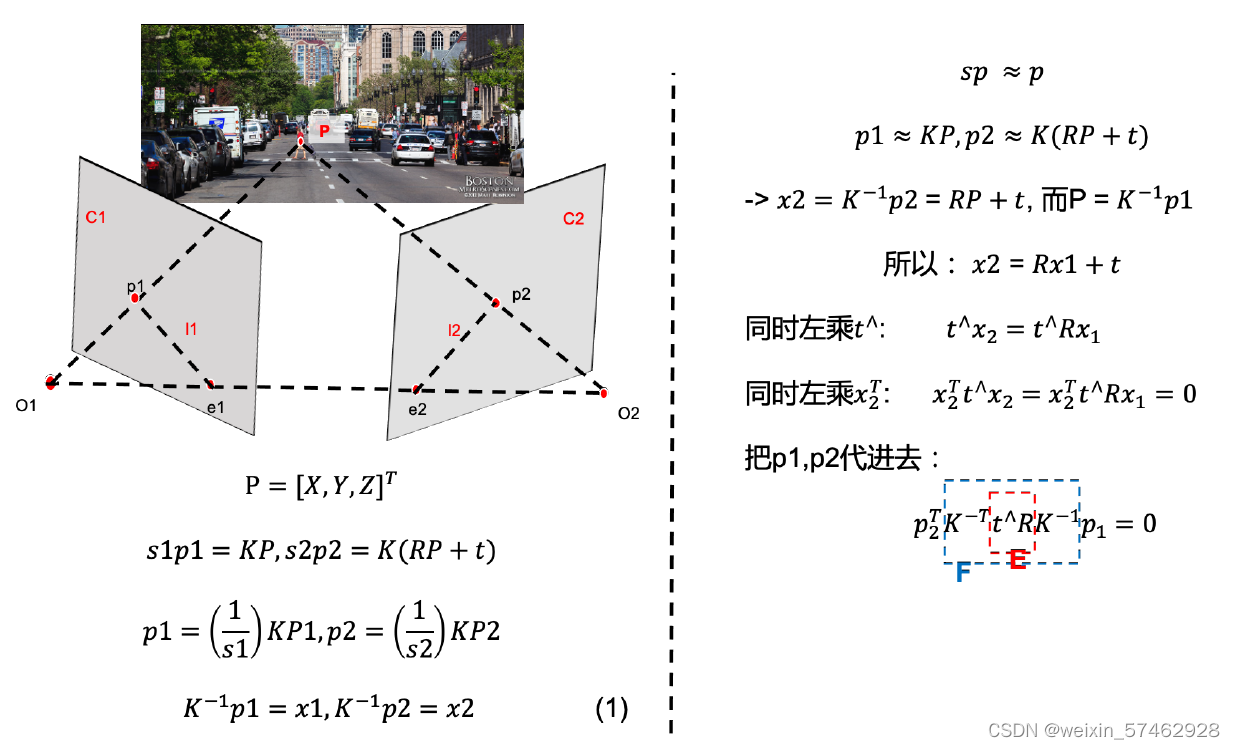
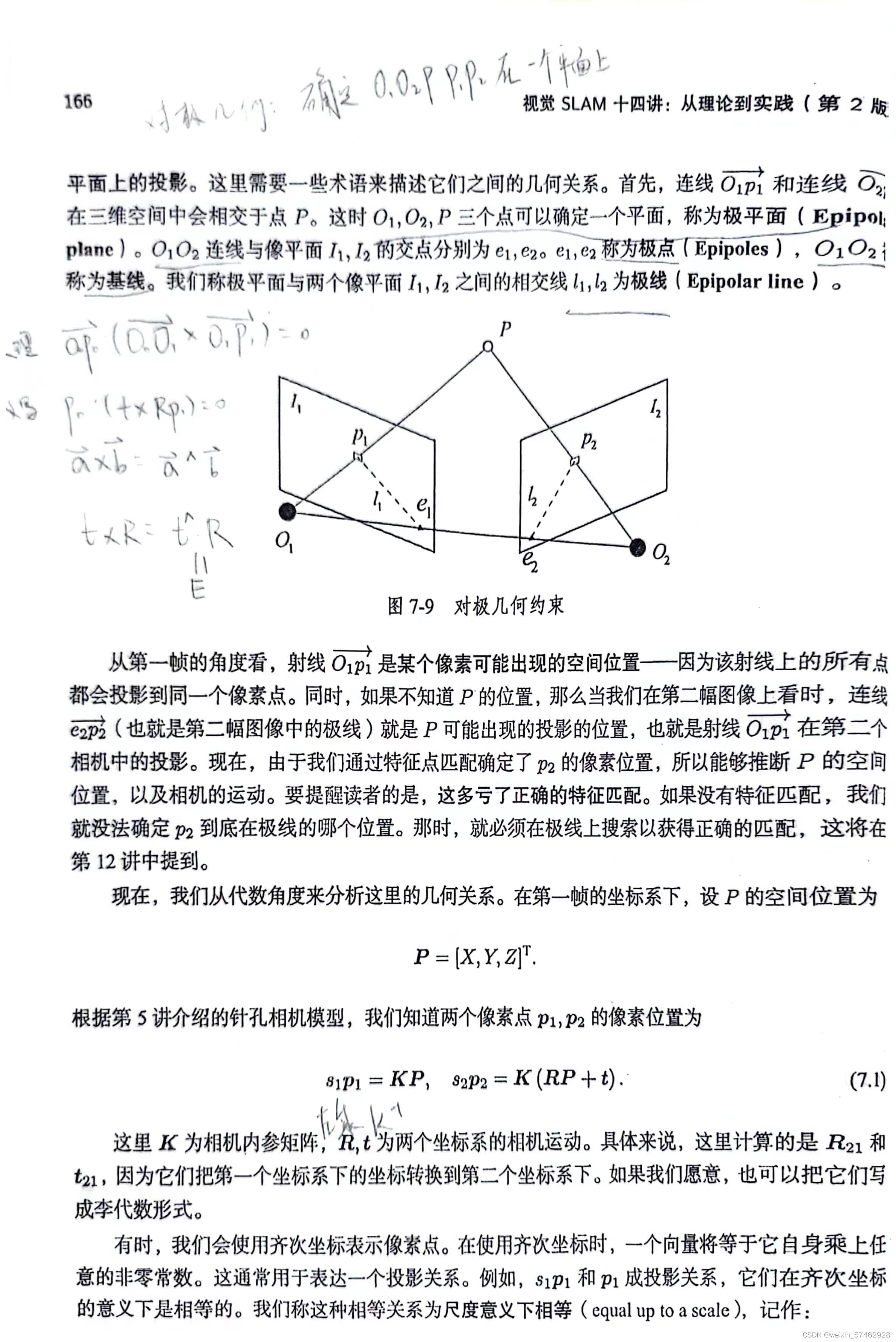

!!!

本质矩阵
- 考虑一对匹配点,进行归一化处理得到坐标
- 根据配对点的像素位置求出E或者F
- x2ex1 = 0
- 将其乘开得到8个方程组成的线性方程组
- 将E或者F用SVD分解恢复出相机的运动R,t


单应矩阵

https://blog.csdn.net/liubing8609/article/details/85340015
三角测量(三角化)
在使用了对极约束后对相机的运动进行了约束估计后,为了使单目相机有深度信息,需要用三角测量来提供该点的空间信息。
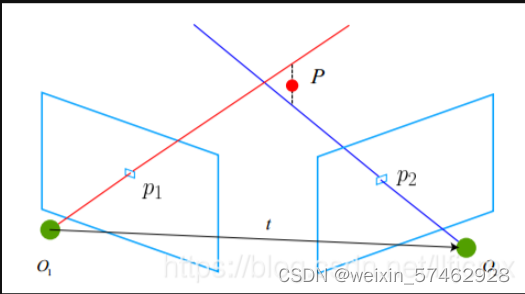
设x1,x2为两特征点的归一化坐标,理论上通过三个点可以相交于P点,但是存在噪声等误差,P会有偏差,解决办法是沿着O1p1射线的方向,通过最小二乘法来求解距离最近的点作为估计的相交点。
三角测量由平移得到,要提高三角化的精度,有两种方法,一种是提高特征点的提取精度,即像素分辨率,但会提高计算成本;一种是增大平移量,但会导致图像的外观发生改变,例如出现了被挡住的箱子等,使得特征提取困难。这种问题称为视差。
3D-2D:PnP
如果两张图像中的一张特征点的3D位置已知,则最少需要三个点对和一个点对来进行额外点验证,因此在使用双目相机和RGB-D相机时,可以直接使用PnP来估计相机运动。有很多种方法:P3P、DLT、EPnP、BA
直接线性变换(DLT)
本质是:建立3D空间点与2D特征点的映射关系,解线性方程组
说明:归一化坐标x与像素坐标差一个内参矩阵K

如果特征点大于6对,采用RANSAC方式,找到最小二乘解
BA:最小重投影误差
将三维空间点的坐标从世界坐标系投影到像素坐标系中:
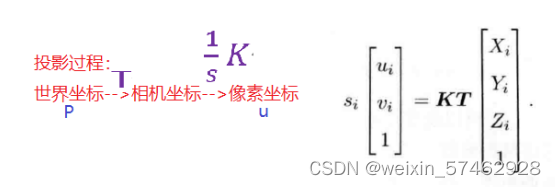
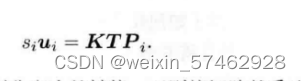
最小化位姿:将u提出与剩下的相减,得到误差函数,将其求和最小化,得到函数取最小值时的位姿
课后习题
1.ORB、SIFT、SURF原理和区别
ORB=改进的FAST+BRIEF描述子;
SIFT=图像金字塔、确定极值点精确位置、确定极值点方向、构建描述子
SURF=构造Hessian矩阵,计算特征值、构造高斯金字塔、定位特征点、确定特征点主方向、构造特征描述子
ORB在计算速度上远快于其他,实时性高选ORB。
2.OpenCV统计提取1000个特征点时机器的时间
#include<iostream>
#include <opencv2/opencv.hpp>
#include<opencv2/core/core.hpp>
#include<opencv2/features2d/features2d.hpp>
#include<opencv2/highgui/highgui.hpp>
#include<chrono>
using namespace std;
using namespace cv;
int main(int argc , char ** argv){
if (argc!=2)
{
cout<< "pls print feature_extraction img1"<< endl;
}
//读取图像
Mat img1=imread(argv[1],CV_LOAD_IMAGE_COLOR);
//初始化
vector<KeyPoint> keypoint_1 ;
chrono::steady_clock::time_point ORB_t1=chrono::steady_clock::now();
Ptr<ORB> orb = ORB::create(1000,2.0f,8,31,0,2,ORB::HARRIS_SCORE,31,20);
chrono::steady_clock::time_point ORB_t2=chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>>(ORB_t2-ORB_t1);
cout << "time_cost= "<< time_used.count() <<" seconds" <<endl;
//ORB检测特征点
orb->detect(img1 , keypoint_1);
//特征点数量
cout << "keypoint1 = "<< keypoint_1.size()<< endl;
Mat out ;
drawKeypoints(img1, keypoint_1 ,out,Scalar::all(-1),DrawMatchesFlags::DEFAULT);
imshow("ORB特征点",out);
waitKey(0);
return 0;
}
3.ORB均匀化
第1步:根据总的图像金字塔层数和待提取的特征点总数,计算每一层图像金字塔中需要提取的特征点数量。
第2步:划分格子,ORB-SLAM2 中格子固定尺寸为 30 x 30 pixels。
第3步:对每个格子提取 FAST 角点,如果初始的 FAST 阈值没有检测到角点,就降低 FAST 阈值。这样可以在弱纹理区域也能提取到更多的角点。如果降低一次阈值后,还是提取不到角点,则不再这个格子里提取。这样可以避免提取到质量特别差的角点。
第4步:使用四叉树来均匀的选取 FAST 角点,基于四叉树,均匀的选取N_a个FAST点
4.FLANN的加速匹配手段
FLANN主要采用三种算法:k-d树、k-means树、层次聚类树
在面对大数据集时它的性能要好于BFMatcher。匹配问题实际上就是一个特征向量求相似度问题。对于最简单的办法,就是逐个匹配对计算距离。明显这种遍历的方式是效率极低的,对于大数据情况下不适用。因此经典kd-tree的搜索回溯的搜索办法在这里派上了用场,减少了不必要的计算过程,提高了效率,但是对于多维数据而言,其效果往往不升反降。在经典kd-tree算法上提出了随机kd-tree算法,随即选出方差较大的维度,建立kd-tree,再进行搜索回溯。还有一种分级k-means tree,与之前不同的是先通过k-means算法(之后回环检测时会用到)来进行先数据聚类,然后再进行kd-tree的建立。这些方法相交于传统的直接匹配法优势都比较大。
加速匹配的方法:预排序图像检索;GPU加速,可以使得匹配速度提高十多倍;再后来就是用FPGA加速,其匹配速度能提升10倍;再后来的VF-SIFT(very fast SIFT)算法,其核心思想是从SIFT特征中提取4个特征角,根据特征角区间的不同,避免了大量不必要的搜索,这样据说是普通搜索的1250倍














 1931
1931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









