






 本文探讨了图神经网络中的'over-smoothing'现象,介绍了其产生的原因,以及如何通过调整层数、增加表达能力、使用skip-connections等策略来避免或缓解这一问题。讲解了通过实验和实例来优化GNN模型的有效方法。
本文探讨了图神经网络中的'over-smoothing'现象,介绍了其产生的原因,以及如何通过调整层数、增加表达能力、使用skip-connections等策略来避免或缓解这一问题。讲解了通过实验和实例来优化GNN模型的有效方法。
一:'over-smoothing'问题的提出:
如下图:
按照我们以往学习‘CNN’等其他层时,我们通常会有这么一个概念,就是加入越多层,我们的神经网络的表达能力也就越强。这种观念在‘GNN’层中是不合理的,为什么这么说呢?
再解释这问题之前我们要引入一个概念--‘receptive field’(接受域)如下图:
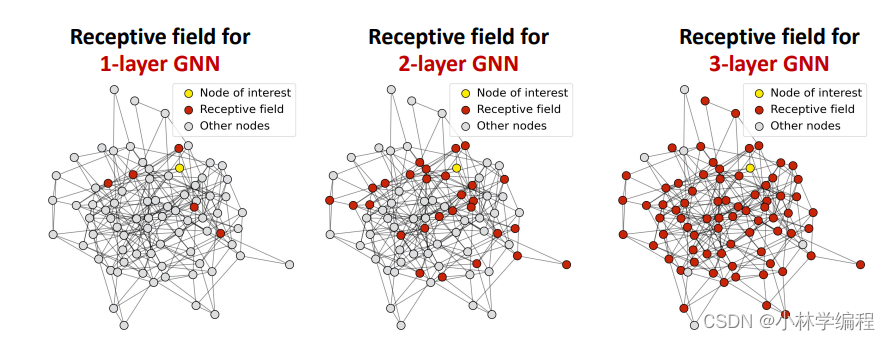
接受域简单来讲就是假如有1层GNN层,那么我们是不是就是从要嵌入节点(图中黄色节点)的一阶邻居(图中红色的点)那里拿信息?那对于有K层GNN层来讲是不是从要嵌入节点的1-k阶邻居那里拿信息?对的,接受域就是指你具体要到哪些邻居那里拿信息,那些邻居的总和就是接受域
知道了接受域的概念后我们就可以定义‘over-smoothing’问题了,如下图:
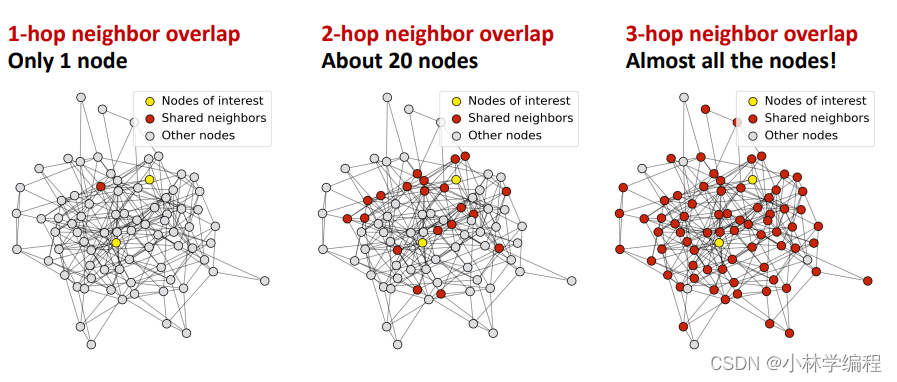
假如现在你想进行链路预测,那你就需要对一对节点进行嵌入,如果GNN层很深的话,这两个节点所共享的邻居就会非常多,导致这两个节点的嵌入非常相似(如图中的红点部分为两个节点的接受域的共享部分)(黄色节点是需要嵌入的两个节点),这就是‘over-smoothing’问题了
二:'over-smoothing'问题的产生:
所以我们可以这么归纳‘over-smoothing’问题的产生:
我们知道节点嵌入是取决于它的接收域范围的,如果两个节点的接收场高度重叠,那么他们的节点嵌入也可能十分相似,所以会有以下逻辑:我们堆叠过多的GNN层—节点具有高度重叠的接收域—节点的嵌入变得十分相似—这就是我们所说的over-smoothing问题
三:'over-smoothing'问题的解决:
lesson1:
在增添GNN层的时候要小心添加(不像是其他如CNN网络那样,过多的添加GNN层对节点精确嵌入没有好处):
(1):要分析可行的节点接收域,分析多少层GNN是好的(这可以每一层叠加完之后看训练的准确率来确定最合适的gnn层数)
(2):当我们要设计l层GNN的时候,不要轻易的让层数增加,试着使用不同的方法来怎么加精度的问题
lesson2:
我们知道层数小意味着我们神经网络的表达能力会下降,那我们如何能做到让少层数的GNN还能增强GNN的表达能力呢?
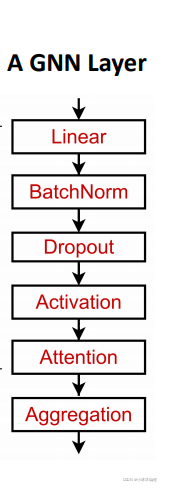
solution1:在一层GNN层中增加表达能力,我们可以通过聚合和转换,让一层GNN层本身变成深度
的一个神经网络(比如增加linear层,dropout层,激活层,attention层,Bantch Norm层等)如图中的几种层:
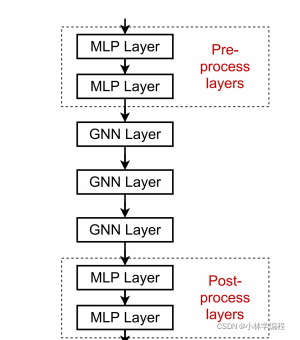
solution2:(常用)我们可以添加不传递消息的图层(比如linear层等),这里意味着,我们不必全是GNN层在神经网络模型的构建中如下图:你可以把它们看作预处理(preprocess)层和后处理(postprocess)层,来增加神经网络的表达能力,这也意味着我们将经典的神经网络也结合了进来。
lesson3:
如果我需要解决的问题就是需要很多GNN层,那该怎么办呢?
solution:添加一些跳过链接的概念(skip connection)这可以理解为在最后添加早些时候(层数较少时候的嵌入)输入到下面深层次的嵌入中如下图左边部分(我们可以添加红色的链接,这样做可以跳过1层或多层GNN层,比如从第一层跳到第三层而这里的数据不需要经过第二层),所以会出现这种情况,(下图中中间部分)相当于把输入复制成了两份,一份通过正常的GNN层顺序更新,另一份走的是skip connection,最后把这两种数据结合起来。这样可以有效的提升最后的表达能力(因为输出混合了多层的输入)
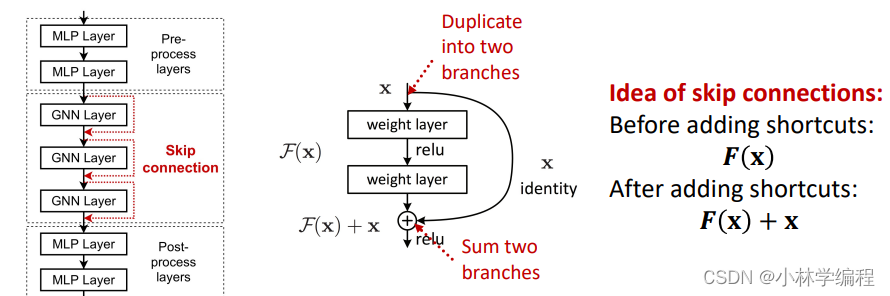
那为什么skip connection有用呢?
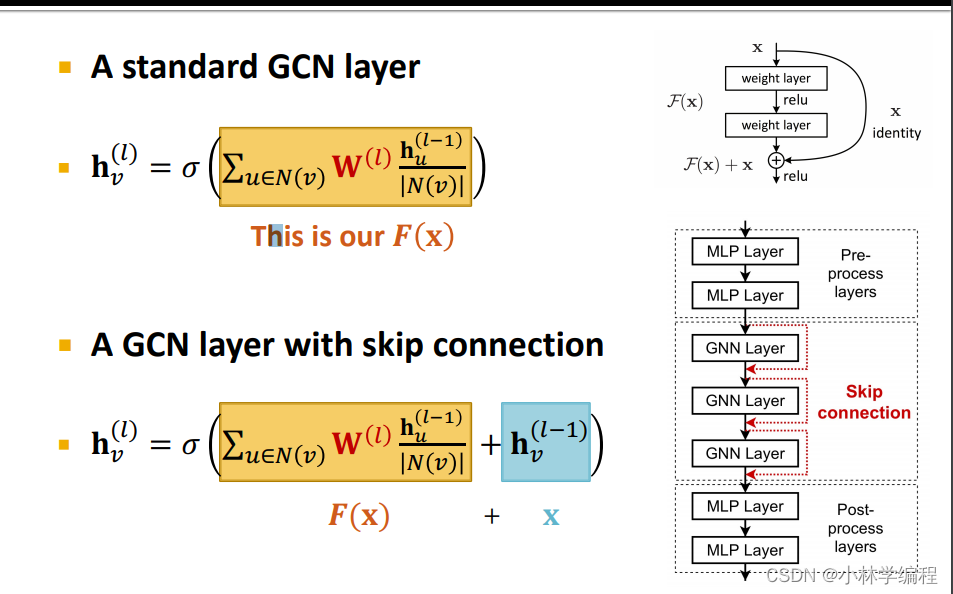
(拿普通的GCN层为例)就可以简单理解为走正常GNN层更新的得到的最终节点的嵌入(如下图黄色部分)会参考之前层更新后的节点嵌入(如下图蓝色部分),使得减轻‘over-smoothing’的问题。
四:参考视频:
1:属于视频的7.3部分内容:
 https://www.bilibili.com/video/BV1RZ4y1c7Co?p=28&spm_id_from=pageDriver
https://www.bilibili.com/video/BV1RZ4y1c7Co?p=28&spm_id_from=pageDriver

















 2860
2860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











