







论文地址:https://arxiv.org/abs/2306.05422
项目主页:Tracking Everything Everywhere All at Once
目录
概括:像素级跟踪的文章, 发表在ICCV2023, 可以非常好的应对遮挡等情形, 其根本的方法在于将2D点投影到一个伪3D(quasi-3D)空间, 然后再映射回去, 就可以在其他帧中得到稳定跟踪。
0. Abstract
传统的光流或者粒子视频跟踪方法都是用有限的时间窗口去解决的, 所以他们并不能很好的应对长时遮挡, 也不能保持估计的轨迹的全局连续性.
该文提出提出了一个完整的, 全局的连续性的运动表示方:OmniMotion,使用 quasi-3D 规范体积来表征视频,通过局部空间和规范空间之间的双射(bijection)对每个像素进行追踪。这种表征能够保证全局一致性,即使在物体被遮挡的情况下也能进行运动追踪,并对相机和物体运动的任何组合进行建模。
1. Method
生成密集和远程轨迹,有三个关键挑战:(1)在长序列中保持准确的轨迹,(2)通过遮挡跟踪点,(3)保持空间和时间的一致性。
而本文提出的方法:1)为整个视频中的所有点产生全局一致的全长运动轨迹。2)可以通过遮挡跟踪点。3)可以通过相机和场景运动的任何组合处理野外视频。
OmniMotion 保留了投影到每个像素的所有场景点的信息,以及它们的相对深度顺序,这让画面中的点即使暂时被遮挡,也能对其进行追踪。将一整个视频序列作为输入, 同时还输入噪声运动估计(例如光流估计), 然后解出一个完整、全局的运动轨迹。然后,添加了一个优化过程,使其可以用任何帧中的任何像素查询表征,以在整个视频中产生平滑、准确的运动轨迹。该方法可以识别画面中的点何时被遮挡,甚至可以穿过遮挡追踪点。
如何解决遮挡问题? 为了获得准确、一致的轨迹,需要一个全局运动表示,即对场景中所有点的轨迹进行编码的数据结构。
遮挡,只是在2D的图像平面下遮挡了, 但是在3D信息中是可以恢复出来的。可以将场景给投影到某个3D空间, 这个空间可以尽可能描述像素完整的运动。比如,第t1帧的某个像素x1,投影到这个3D空间变为x′,然后在第t2帧再将这个x′投射到2D平面, 就得到了对应的点x2。这个3D不需要真正的进行3D重建(因为真正的3D重建是需要知道相机的内参和外参, 内参包括图像中心的坐标, 相机的焦距等, 外参需要知道相机的朝向等, 是比较复杂的), 因此将该空间称为quasi-3D。
OmniMotion 表征
传统的运动估计方法(例如成对光流),当物体被遮挡时会失去对物体的追踪。为了在遮挡的情况下也能提供准确、一致的运动轨迹,该研究提出全局运动表征 OmniMotion。该研究试图在没有显式动态 3D 重建的情况下准确追踪真实世界的运动。OmniMotion 表征将视频中的场景表示为规范的 3D 体积,通过局部规范双射(local-canonical bijection)映射成每个帧中的局部体积。局部规范双射被参数化为神经网络,并在不分离两者的情况下捕获相机和场景运动。基于此种方法,视频可以被视为来自固定静态相机局部体积的渲染结果。
由于 OmniMotion 没有明确区分相机和场景运动,所以形成的表征不是物理上准确的 3D 场景重建。因此,该研究称其为 quasi-3D 表征。OmniMotion 保留了投影到每个像素的所有场景点的信息,以及它们的相对深度顺序,这让画面中的点即使暂时被遮挡,也能对其进行追踪。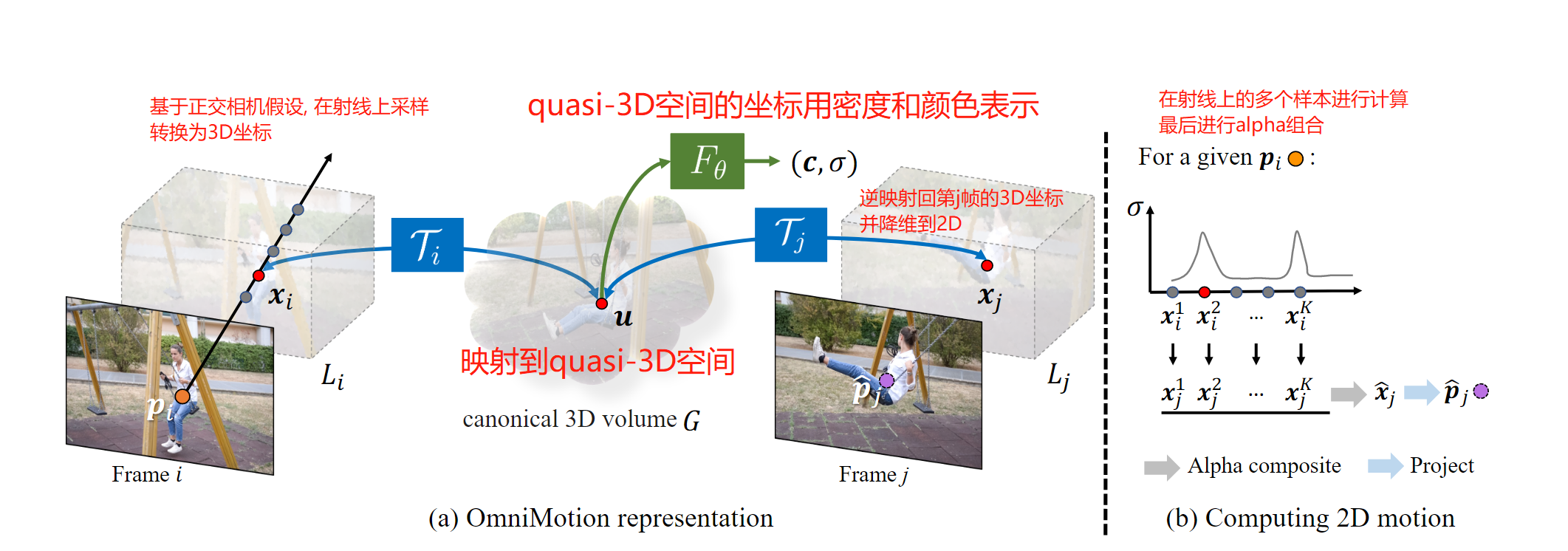
图2:方法概述。(a)OmniMotion表示由规范三维体积G和一组双射Ti组成,这些双射Ti在每一帧的局部体积Li和规范体积G之间映射。帧i中的任何局部3D位置xi都可以通过Ti映射到其相应的规范位置u,然后通过逆映射T - 1 j映射回另一帧j作为xj。G中的每个位置u都与颜色c和密度σ相关联,使用基于坐标的MLP Fθ计算。(b)为了计算从帧i映射到j的给定查询点pi对应的二维位置,我们向Li发射一条射线,并对一组点 xi 进行采样,然后将这些点首先映射到正则空间以获得它们的密度,然后映射到帧j以计算它们对应的局部三维位置xj。
然后对这些点xj进行alpha合成和投影,得到二维对应的位置pj。
1.1 标准3D量的组成
用规范体积 G 来表示视频的内容,它作为观察到的场景的三维地图集。在G上定义一个基于坐标的网络Fθ,将G中的3D坐标 u 映射到密度 σ 和颜色 c . 其中密度可以告诉我们表面(surface)在这个3D空间中的位置,从而在多个帧上跟踪表面, 颜色可以在训练过程中计算光度损失(photometric loss)。
1.2 3D双射
需要定义一个从本地坐标(也就是视频或图像坐标)到quasi-3D空间的一个映射, 以及逆映射, 这样可以再映射回别的时间索引的帧找到对应点。然而, 实际上该工作是将本地的2D坐标给提升到3D的, 然后从提升后的本地3D坐标投影到quasi-3D空间. 映射和逆映射的过程是:![]()
其中i,j是帧索引, 因此, 定义的映射是和时间有关的. 中间产物 u=Ti(xi)应该是与时间无关的。实现时, 映射是用可逆神经网络(INN)做的。
1.3 计算运动
在2D图像上的一个像素pi, 首先提升到3D, 变成pi′。方法是在一个射线上进行采样。然后用3D双射投影到第 j 帧对应的3D点, 最后再降维回2D。
由于已经将相机的运动包含在映射T内了, 因此可以直接将相机建模成固定的正交相机。也就是说, 既然物体的大小不再随着深度的变化而变化, 那么2D像素点 (xi,yi)不论深度如何, 它的RGB值一直不变, 因此射线可以这样定义:
![]()
在这个射线上采集K个样本, 就相当于在这个固定正交相机拍摄的3D场景中进行深度采样。
然后这些样本用映射Ti投影到quasi-3D空间, 然后再用之前说的映射Fθ转换成密度和颜色的量(σ,c), 即, 对于第k个样本:
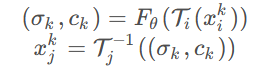
随后, 根据第 j 帧的这K个对应样本, 得到第 j 帧的估计:
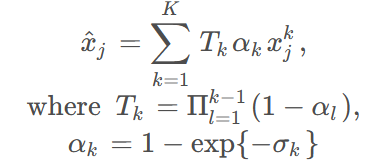
以上的过程叫做alpha compositing, 是NeRF中一个常用的技巧. 意义是, 密度实际上表达了3D空间中存在物体的可能性,1−exp{−σk}就是一种对概率的衡量。对于是否采纳第k个样本, 重要性为 Tk αk,Tk的含义是在这之前的样本的联合可信程度, 也就是说, 之前有一个样本已经比较可信了, 那么这个样本就可以更少的采纳。
2. Optimization
优化过程以输入视频序列和噪声对应预测集合(来自现有方法)作为指导,并为整个视频生成完整的,全局一致的运动估计。
Collecting input motion data:
用RAFT来计算输入对对应。首先穷举地计算所有成对光流。应用周期一致性和外观一致性检查来过滤掉虚假的对应。将这些有噪声的、不完整的成对运动整合成完整的、精确的远程运动。
损失函数:
由三部分构成, 一个是位置误差, 也就是坐标误差。一个是颜色误差, 这就是前面c的作用。一个是因为要保证平稳性而加入的罚项。其中1, 3项采用1范数, 第二项采用2范数。
Flow loss:flow loss的平均绝对误差(MAE)
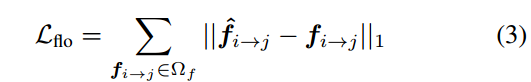
photometric loss:光度损失,预测与真值的的均方误差(MSE)
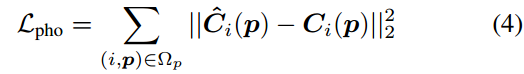
smooth loss:意义是保证前一帧和后一帧的差距尽量小。
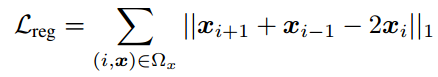
最终的loss是这三项的线性组合.
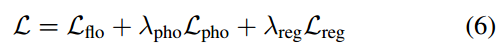
利用单规范体积G的双射、光一致性和基于坐标的网络Mθ和Fθ提供的自然时空平滑性,来调和不一致的两两流,并填补对应图中的缺失内容。
Balancing supervision via hard mining:
穷举的成对流输入最大化了优化阶段可用的有用运动信息。然而这种方法,可能导致动态区域中运动样本的不平衡收集。刚性背景区域通常具有许多可靠的成对对应关系,而快速移动和变形的前景对象在过滤后通常具有更少的可靠对应关系,特别是在远距离帧之间。这种不平衡会导致网络完全关注主要的(简单的)背景运动,而忽略了代表一小部分监督信号的具有挑战性的运动对象。
提出了一个策略用于在训练期间挖掘难示例。通过计算预测流与输入流之间的欧几里得距离来周期性地缓存流预测并计算误差映射。在优化过程中引导采样,使高误差区域的采样频率更高。
Training:
network:映射网络Mθ由六个仿射耦合层组成。在计算比例和平移之前,我们对每一层的输入坐标应用具有4个频率的位置编码。我们使用一个单独的2层MLP,通道数为256,实现为GaborNet ,以计算每帧i的潜在代码ψi。这个MLP的输入是时间ti。潜在代码ψi的维度是128。规范表示Fθ也被实现为GaborNet,但是有3层,通道数为512。
Representation:将所有像素坐标pi归一化到[-1, 1]范围,并设定近和远深度范围为0和2,为每帧定义一个局部3D空间为[-1, 1]^2 ×[0, 2]。虽然我们的方法可以在规范空间G中任意位置放置内容,但我们初始化由Mθ给出的映射规范位置大致在单位球内,以确保对密度/颜色网络Fθ的输入条件良好。为了在训练过程中提高数值稳定性,我们在将它们传递给Fθ之前,对规范3D坐标u应用mip-NeRF 360 中的收缩操作。
与Adam一起对每个视频序列进行了20万次迭代训练。在每个训练批次中,从8对图像中采样256个对应点,总共得到1024个对应点。
3. Evaluation
3.1 Benchmarks
dataset:在以下来自TAP-Vid的数据集上进行评估:1) DAVIS,真实数据集,包含来自DAVIS 2017验证集的30个视频,片段范围从34-104帧,每个视频平均有21.7个点轨迹标注。2) Kinetics,真实数据集,包含来自Kinetics-700-2020验证集的1189个视频,每个视频有250帧,平均每个视频有26.3个点轨迹标注。3) RGBStacking,合成数据集,包含50个视频,每个视频有250帧和30个轨迹。排除了主要用于训练的合成Kubric数据集。
评估指标:按照TAP-Vid基准测试的要求,报告预测轨迹的位置和遮挡准确性。我们还引入了一种新的衡量时间连贯性的指标。评估指标包括:
-
的准确性
-
Average Jaccard (AJ) :在与
-
Occlusion Accuracy (OA):评估每一帧的可见性/遮挡预测的准确性。
-
Temporal Coherence (TC):通过测量真实轨迹和预测轨迹的加速度之间的L2距离来评估轨迹的时间连贯性。
3.2 Baselines
将OmniMotion与各种类型的密集对应方法进行比较:
RAFT:双帧流动方法。考虑两种使用RAFT在测试时生成多帧轨迹的方式:1)将连续帧间的RAFT预测链成更长的轨迹,称之为RAFT-C;2)直接计算任何(非相邻)查询和目标帧之间的RAFT流动(RAFT-D)。在使用RAFT-D生成轨迹时,总是使用前一个流预测作为当前帧的初始化。
PIPs:可以处理遮挡的多帧点轨迹估计方法。默认情况下,该方法使用8帧的时间窗口,更长的轨迹必须通过链接生成。使用了PIPs的官方实现来执行链接。
Flow-Walk:使用多尺度对比随机漫步来通过鼓励跨时间的周期一致性来学习时空对应关系。类似于RAFT,我们报告链式和直接对应计算,分别为FlowWalk-C和Flow-Walk-D。
TAP-Net:使用代价体积来预测查询点在单个目标帧中的位置,以及一个标量遮挡logit。
Deformable Sprites:是一种基于层的视频分解方法。使用每个视频的测试时优化。然而,它不直接产生帧到帧的对应关系,因为从每一帧到规范纹理图像的映射是不可逆的。需要在纹理图像空间中进行最近邻搜索来找到对应关系。
PIPs、TAP-Net和Deformable Sprites可以直接预测遮挡,但RAFT和Flow-Walk不能。因此,我们遵循先前的工作:Tap-vid: A benchmark for tracking any point in a video、Rethinking self-supervised correspondence learning: A video frame-level similarity perspective,并使用周期一致性检查,阈值为48个像素,为这些方法产生遮挡预测。首先将查询点映射到目标帧中的对应3D位置,然后检查该3D位置在目标帧中的透射率。
3.3 Comparisons
定量比较
与 TAP-Vid 基准进行比较,结果如表 1 所示。在不同的数据集上,他们的方法始终能实现最佳的位置准确性、遮挡准确性和时序一致性。可以很好地处理来自 RAFT 和 TAP-Net 的不同的成对对应输入,并且在这两种基准方法上提供了一致的改进。
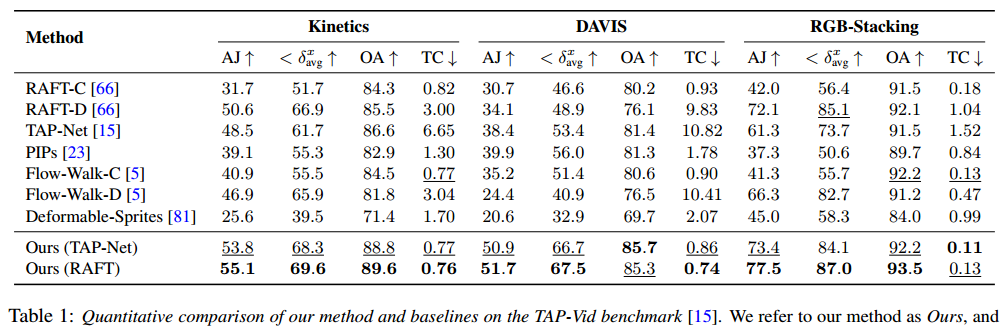
提出了两个变体:Ours (TAP-Net)和Ours (RAFT),分别使用TAP-Net和RAFT的输入成对对应进行优化。Ours和Deformable Sprites都通过对每个单独视频的测试时间优化来估计全局运动,而所有其他方法都以前馈方式估计局部运动。
比较:
- 与直接在查询和目标帧(如非相邻的)对之间进行操作的方法,如RAFT-D、TAP-Net和Flow-Walk-D相比,方法由于其全局一致的表示,显著提高了时间连贯性。
- 与流链接方法如RAFT-C、PIPs和Flow-Walk-C相比,我们的方法有更好的跟踪性能,尤其是在较长的视频上。链接方法会随着时间的推移积累错误,并且对遮挡不具有鲁棒性。虽然PIPs考虑了更广的时间窗口(8帧)以便更好地处理遮挡,但如果一个点在整个时间窗口之外持续被遮挡,它就无法跟踪该点。相反,OmniMotion可以跟踪经过扩展遮挡的点。
- 我们的方法也优于测试时优化方法Deformable Sprites。Deformable Sprites使用预定义的两层或三层并固定排序来分解视频,并将背景建模为一个带有每帧单应性的2D图集,这限制了其适应具有复杂摄像头和场景运动的视频的能力。
定性比较
如图 3 所示,新方法在(长时间)遮挡事件中显示出了出色的识别和追踪的能力,同时在遮挡期间为点提供合理的位置,并处理很大的摄像机运动视差。

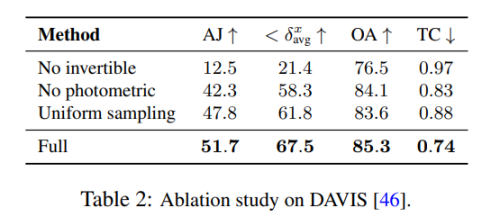
3.4 消融实验与分析
消融实验
No invertible是一个模型变体,它用本地和规范帧之间的单独的前向和后向映射网络替换我们的可逆映射网络Mθ(即,没有我们提出的双射的严格周期一致性保证)。虽然我们为这个消融添加了一个周期一致性损失,但它仍然无法构造一个有意义的规范空间,只能表示静态背景的简单运动。
No photometric:是一个省略了光度损失Lpho的版本;降低的性能表明了精炼运动估计的光度一致性的重要性。
Uniform sampling:用均匀采样策略替换了我们的硬挖掘采样策略,我们发现这导致了无法捕捉快速运动的问题。
分析
模型生成的伪深度图,以展示学习到的深度排序。这些图并不对应于物理深度。仅使用光度和光流信号,确定不同表面之间的相对顺序,这对于在遮挡中进行追踪至关重要。

4. limitation
在处理快速且高度非刚性的运动以及细长结构时会遇到困难。在这些情况下,成对的对应方法可能无法提供足够可靠的对应关系,以计算精确的全局运动。
此外,由于底层优化问题的高度非凸性质,我们的优化过程对于某些困难视频的初始化可能敏感。这可能导致次优的局部极小值,例如,在规范空间中出现错误的表面排序或重复的对象,有时很难通过优化来纠正这些问题。
最后,目前的方法在计算上可能比较昂贵。首先,流集合过程需要计算所有配对流的详尽计算,这与序列长度的平方成正比。可以通过探索更有效率的替代详尽匹配的方法来改进这个过程的可扩展性,例如,借鉴结构从运动和SLAM文献中的灵感,使用词汇树或基于关键帧的匹配。其次,与其他使用神经隐式表示的方法类似,我们的方法涉及一个相对较长的优化过程。该领域的最新研究可能有助于加速这个过程,并进一步扩展到处理更长的序列。
总结:
提出了一种新的测试时优化方法,用于估计整个视频的完整和全局一致的运动。引入了一种新的视频运动表示法,称为OmniMotion,其中包括一个准3D规范体积和每帧的局部规范双射。OmniMotion可以处理具有不同摄像机设置和场景动态的常规视频,并通过遮挡产生准确且平滑的长距离运动。该方法在定性和定量方面都比先前的最先进的方法取得了显著的改进。
参考:[论文阅读笔记26]Tracking Everything Everywhere All at Once_wjpwjpwjp0831的博客-CSDN博客

















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









