






SadTalker:学习逼真的3D动作系数,用于风格化的音频驱动单张图像说话人脸动画
code:
paper:
1 介绍
动机:生成说话头的方法都存在问题,耦合的2D运动场:不自然的头部动作、扭曲的表情和身份修改。显式使用3D信息:僵硬的表情和不连贯的视频等问题。
因此提出SadTalker,从音频中生成3D运动系数(头部姿态、表情),并隐式调节一种3D感知人脸渲染,用于生成说话人头部。提出了ExpNet来通过提取系数,和3D渲染人脸来学习准确的面部表情。至于头部姿态,设计了PoseVAE,通过条件VAE来合成不同风格的头部运动。最后,生成的3D运动系数被映射到所提出的人脸渲染的无监督3D关键点空间,并合成最终视频。
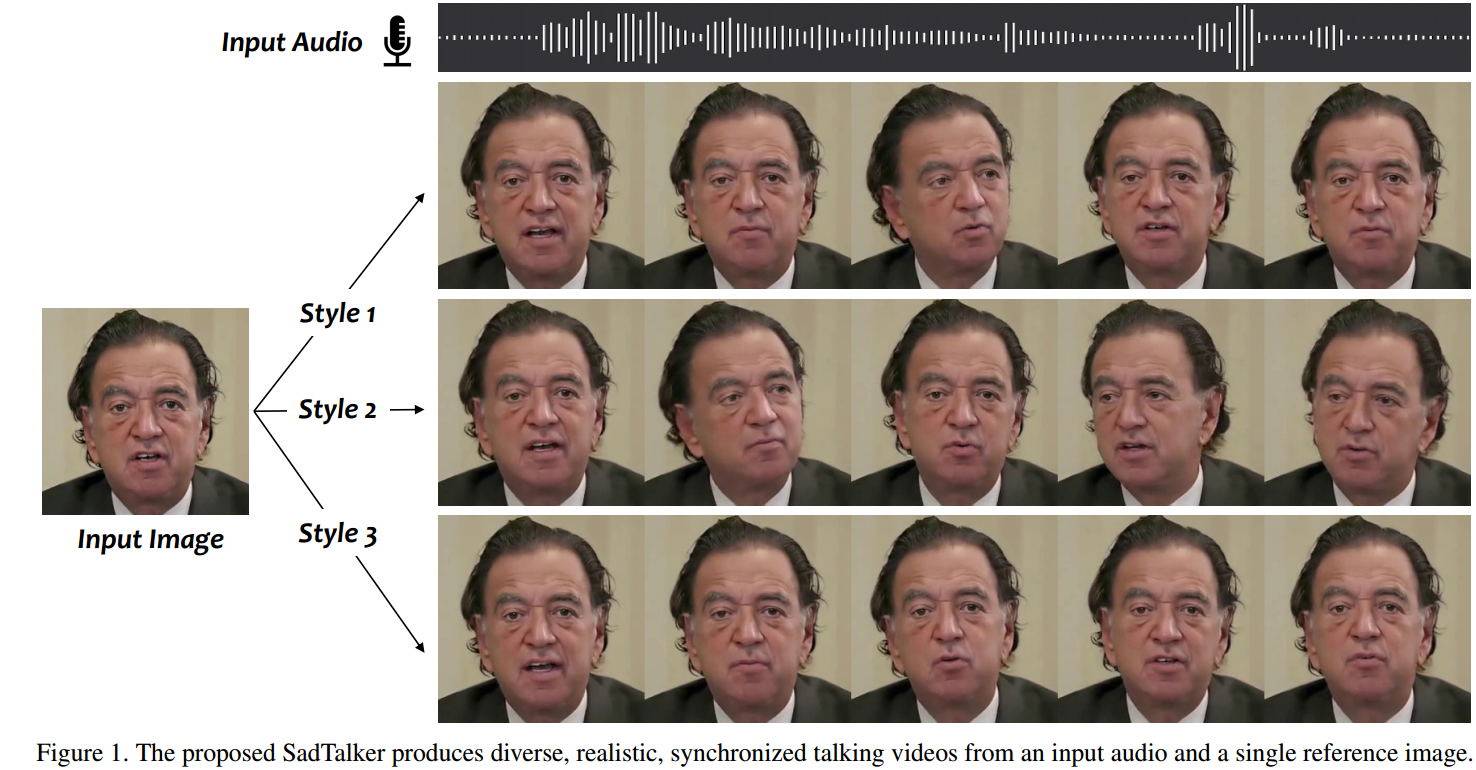 图1,SadTalker从输入音频和单个参考图像中产生多种逼真的同步谈话视频。
图1,SadTalker从输入音频和单个参考图像中产生多种逼真的同步谈话视频。
贡献:
- 提出了SadTalker,一种使用逼真3D运动系数的风格化音频驱动单张图像说话的新系统。
- 为了从音频中学习3DMM模型的逼真运动系数,分别提出了ExpNet和PoseVAE。
- 提出了一种新颖的语义解耦和3D感知人脸渲染器,用于生成逼真的说话人头部视频。
- 实验证明我们的方法在运动同步和视频质量方面达到了最先进水平。
2 背景
音频驱动的单张图像说话人脸生成。早期的研究[3, 30, 31]主要集中在通过感知鉴别器产生准确的嘴唇运动。由于真实视频包含许多不同的运动,ATVGnet [2]使用面部关键点作为中间表示来生成视频帧。MakeItTalk [52]提出了一种类似的方法,但它从输入音频信号中解耦了内容和说话人信息。由于面部关键点仍然是一个高度耦合的空间,最近也流行在解耦空间中生成说话人头部。PC-AVS [51]使用隐式潜变量代码对头部姿态和表情进行解耦。然而,它只能产生低分辨率的图像,并且需要来自另一个视频的控制信号。Audio2Head [39]和Wang等人 [40]受到视频驱动方法 [36] 的启发,用于生成说话人脸。然而,这些头部运动仍然不够生动,并且会产生具有不准确身份的扭曲面部。尽管一些先前的工作 [33, 49] 使用3DMM作为中间表示,但他们的方法仍然面临着表情不准确 [33] 和明显的伪影 [49] 的问题。
音频驱动的视频肖像。我们的任务也与视觉配音相关,其目标是通过音频编辑一个肖像视频。与音频驱动的单张图像说话人脸生成不同,这个任务通常需要在特定视频上进行训练和编辑。在之前的深度视频肖像工作[19]的基础上,这些方法利用3DMM信息进行面部重建和动画。AudioDVP [45]、NVP [38]、AD-NeRF [11]学习重新演绎表情以编辑嘴形。除了嘴唇运动,例如头部运动 [23, 48]、情感表达的说话人脸 [18] 也受到关注。在这些任务中,基于3DMM的方法起着重要的作用,因为从视频片段中拟合3DMM参数是可行的。尽管这些方法在个性化视频中取得了令人满意的结果,但它们无法应用于任意照片和野外音频。
视频驱动的单张图像说话人脸生成。这个任务也被称为面部复现或面部动画,旨在将源图像的动作转移到目标人物身上。最近已经广泛探索了这个任务[14, 29, 33, 36, 37, 41, 42, 44, 47, 50]。先前的工作还学习了源图像和目标之间的共享中间动作表示,可以大致分为基于关键点[41]和无监督基于关键点的方法[14,36,42,50]、基于3DMM的方法[7,33,47]以及潜在变量动画[25, 44]。这个任务比我们的任务容易得多,因为它包含了相同领域的运动。我们的人脸渲染器也受到无监督基于关键点方法 [42] 和基于3DMM的方法 [33] 的启发,通过映射学习的系数来生成真实视频。然而,他们并没有专注于生成逼真的运动系数。
3 方法
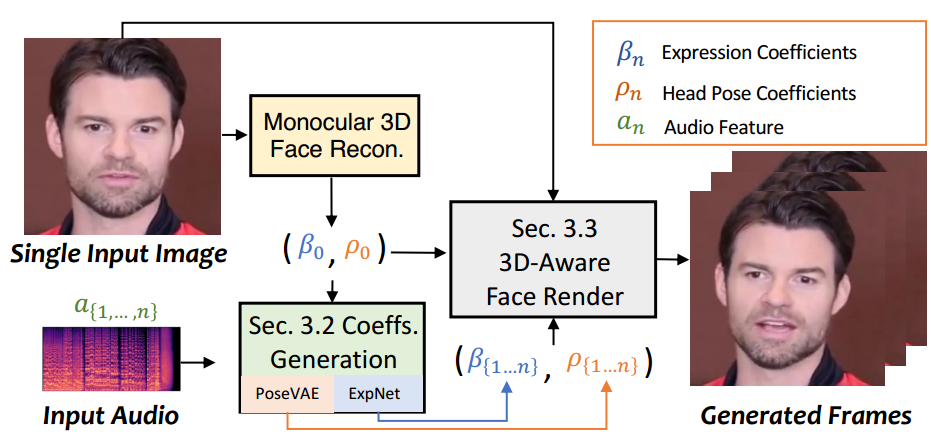
图2pipeline。使用3DMM的系数作为中间运动表示。首先从音频中生成逼真的3D运动系数(面部表情β,头部姿势ρ),然后,通过ExpNet和PoseVAE分别生成逼真的3DMM运动系数。最后,提出3D感知的人脸渲染器来生成说话人头部视频。
第3.2节介绍了音频驱动的运动系数生成方法,第3.3节介绍了基于系数驱动的图像动画。
3.1 3D面部模型的预备知识
受单张图像深度3D重建方法 [5] 启发,将预测的3D可塑模型(3DMM)的空间,视为中间表示。在3DMM中,3D面部形状S可以解耦为:
![]()
其中,![]() 是3D面部的平均形状,Uid和Uexp是LSFM可塑模型 [1] 的身份和表情的正交基。系数α ∈ R^80和β ∈ R^64分别描述了个人身份和表情。为了保持姿势差异,系数r ∈ SO(3)和t ∈ R^3表示头部旋转和平移。为了实现与身份无关的系数生成 [33],仅对运动参数{β,r,t}建模。从驱动音频中,单独学习头部姿态ρ = [r, t]和表情系数β。然后,这些运动系数用于隐式调节人脸渲染器进行最终的视频合成。
是3D面部的平均形状,Uid和Uexp是LSFM可塑模型 [1] 的身份和表情的正交基。系数α ∈ R^80和β ∈ R^64分别描述了个人身份和表情。为了保持姿势差异,系数r ∈ SO(3)和t ∈ R^3表示头部旋转和平移。为了实现与身份无关的系数生成 [33],仅对运动参数{β,r,t}建模。从驱动音频中,单独学习头部姿态ρ = [r, t]和表情系数β。然后,这些运动系数用于隐式调节人脸渲染器进行最终的视频合成。
3.2 通过音频生成运动系数
如上所述,3D运动系数包含了头部姿态和表情,其中头部姿态是全局运动,表情相对局部。为此,如果同时学习所有内容会导致网络中的巨大不确定性,因为头部姿态与音频的关系相对较弱,而嘴唇运动则高度相关。我们使用提出的PoseVAE和ExpNet分别生成头部姿态和表情的运动,具体如下介绍。
ExpNet
由于两个原因,从音频中学习生成准确的表情系数是非常困难的:1)对于不同的身份来说,音频到表情并不是一对一的映射任务。2)表情系数中存在一些与音频无关的运动,会影响预测的准确性。
我们设计了ExpNet来减少这些不确定性。至于身份问题,通过第一帧的表情系数 β0 将表情运动与特定的人物连接起来。为了在自然说话时减少其他面部组件的运动权重,使用仅包含嘴唇运动的系数作为系数目标,通过预训练网络Wav2Lip [30] 和深度3D重建 [5]。然后,可以通过渲染图像上的额外关键点损失来利用其他次要面部运动(例如眨眼)。
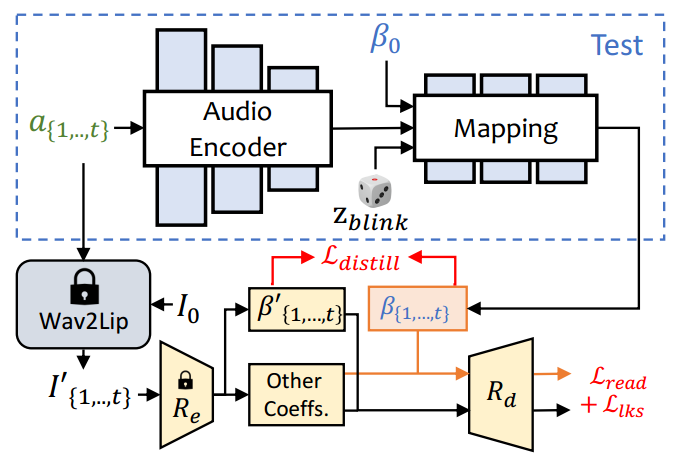
图3. ExpNet的结构。引入了一个单目3D面部重建模型[5](Re和Rd)来学习逼真的表情系数。Re是一个预训练的3DMM系数估计器,Rd是一个可微分的3D人脸渲染器,没有可学习参数。使用参考表情β0来减少身份的不确定性,并使用预训练的Wav2Lip [30]生成的帧![]() 和第一帧I0作为目标表情系数,因为它们只包含与嘴唇相关的运动。
和第一帧I0作为目标表情系数,因为它们只包含与嘴唇相关的运动。
如图3所示,从音频窗口![]() 生成t帧的表情系数,其中每帧的音频特征是一个0.2秒的mel频谱图。在训练过程中,首先设计了基于ResNet的音频编码器ΦA [12, 30],将音频特征嵌入到潜空间中。然后,添加一个线性层作为映射网络ΦM来解码表情系数。同时还在生成过程中添加了来自参考图像的参考表情β0,以减少身份的不确定性。由于在训练中使用仅包含嘴唇运动的系数作为真实值,所以又添加了一个闪烁控制信号zblink∈[0, 1]和相应的眼睛关键点损失,以生成可控的眨眼动作。网络写为:
生成t帧的表情系数,其中每帧的音频特征是一个0.2秒的mel频谱图。在训练过程中,首先设计了基于ResNet的音频编码器ΦA [12, 30],将音频特征嵌入到潜空间中。然后,添加一个线性层作为映射网络ΦM来解码表情系数。同时还在生成过程中添加了来自参考图像的参考表情β0,以减少身份的不确定性。由于在训练中使用仅包含嘴唇运动的系数作为真实值,所以又添加了一个闪烁控制信号zblink∈[0, 1]和相应的眼睛关键点损失,以生成可控的眨眼动作。网络写为:
![]()
对于损失函数,首先使用![]() 来评估唇部运动系数
来评估唇部运动系数![]() 与生成的β{1,...,t}之间的差异。只使用wav2lip的第一帧I0生成唇同步视频,这减少了姿势变异和除嘴唇运动外的其他面部表情的影响。还使用可微分的3D人脸渲染器Rd在显式面部运动空间中计算额外的感知损失。如图3所示,计算眼睛关键点损失Llks来衡量眨眼的范围和整体表情准确性。还使用预训练的唇读网络Φreader作为临时唇读损失Lread,以保持感知的唇部质量[9, 30]。
与生成的β{1,...,t}之间的差异。只使用wav2lip的第一帧I0生成唇同步视频,这减少了姿势变异和除嘴唇运动外的其他面部表情的影响。还使用可微分的3D人脸渲染器Rd在显式面部运动空间中计算额外的感知损失。如图3所示,计算眼睛关键点损失Llks来衡量眨眼的范围和整体表情准确性。还使用预训练的唇读网络Φreader作为临时唇读损失Lread,以保持感知的唇部质量[9, 30]。
PoseVAE
如图4所示,设计了一个基于VAE [21]的模型,用于学习真实且具有身份感知的风格化头部运动 ρ ∈ R^6。在训练中,PoseVAE在固定的n帧上使用编码器-解码器结构进行训练。编码器和解码器都是两层MLP,输入包含连续的t帧头部姿态,并将其嵌入到一个高斯分布中。
解码器中,网络被训练生成从采样分布中得到的t帧姿态。与直接生成姿态不同,PoseVAE学习了第一帧条件姿态ρ0的残差,这使得我们的方法能够在测试时,在第一帧的条件下生成更长、更稳定和连续的头部运动。此外,根据CVAE [6],我们添加了相应的音频特征![]() 和风格身份 Zstyle 作为节奏感知和身份风格的条件。
和风格身份 Zstyle 作为节奏感知和身份风格的条件。
KL散度 LKL 用于衡量生成的运动分布。均方损失 LMSE 和对抗损失 LGAN 用于确保生成的质量。
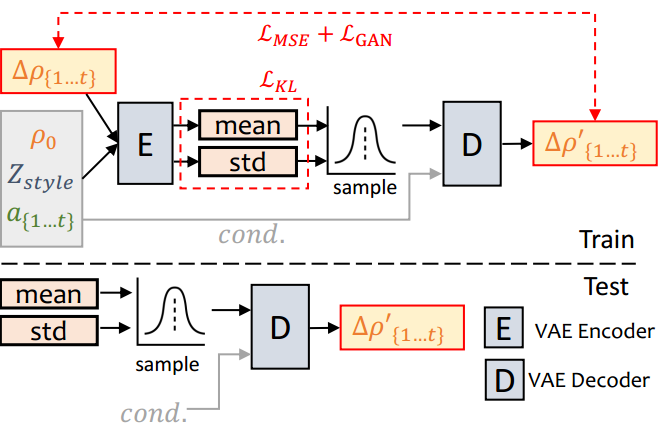
图4. PoseVAE的流程。通过条件VAE结构学习输入头部姿态ρ0的残差。给定条件:第一帧ρ0,风格身份Zstyle和音频剪辑![]() ,学习残差头部姿态
,学习残差头部姿态![]() 的分布。训练完成后,通过姿势解码器和条件(cond:)生成风格化的结果。
的分布。训练完成后,通过姿势解码器和条件(cond:)生成风格化的结果。
3.3 3D感知人脸渲染器
在生成逼真的3D运动系数之后,通过一个3D感知图像动画器来渲染最终的视频。face-vid2vid [42]中可以隐式地从单张图像中学习到3D信息,但是需要一个真实的视频作为驱动信号。我们的人脸渲染器通过3DMM系数使其可驱动。如图5所示,我们提出了mappingNet来学习明确的3DMM运动系数(头部姿态和表情)与隐式无监督的3D关键点之间的关系。mappingNet由几个1D卷积层构成。使用时间窗口内的临时系数进行平滑,类似于PIRenderer [33]。不同的是,我们发现PIRenderer中的面部对齐运动系数会极大地影响音频驱动视频生成的运动自然性,并在第4.4节中进行了实验证明。只使用表情和头部姿态的系数。
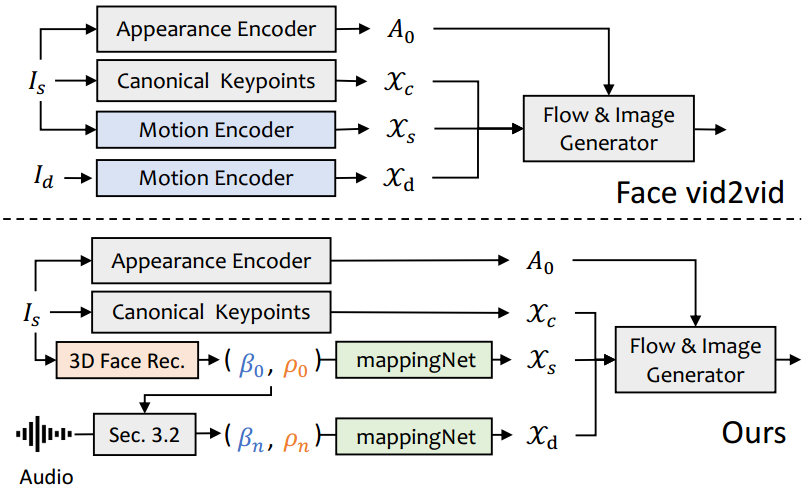
图5。FaceRender及其与facevid2vid的比较[42]。给定源图像Is和驱动图像Id, facevid2vid在无监督的三维关键点空间Xc、Xs和Xd中生成运动。然后,通过外观A0和关键点生成图像。由于我们没有驾驶图像,我们使用显式解纠缠3DMM系数作为代理,并将其映射到无监督的3D关键点空间。
训练包含两个步骤。首先按照原始论文中的方式,以自监督的方式训练face-vid2vid。第二步,冻结外观编码器、规范化关键点估计器和图像生成器的所有参数进行微调。然后以重构风格的方式,在真实视频的3DMM系数上训练mappingnet。用L1损失在无监督关键点的域中提供监督,并按照他们的原始实现生成最终的生成视频。
4 实验
4.1. 实现细节和评估指标
数据集:VoxCeleb [26]数据集来训练,包含1251个主体的超过10万个视频。按照之前的图像动画方法[36]对原始视频进行裁剪,调整为256×256。预处理之后,数据用于训练FaceRender。由于VoxCeleb中一些视频和音频不对齐,我们选择了46个主体的1890个对齐视频和音频来训练我们的PoseVAE和ExpNet。输入音频下采样到16kHz,并使用与Wav2lip [30]相同的设置转换为mel频谱图。测试:使用了HDTF数据集中346个视频的第一个8秒视频(总共约70,000帧),因为它包含了高分辨率和野外环境的说话人头部视频。这些视频也按照[36]进行了裁剪和处理,并调整大小为256×256进行评估。使用每个视频的第一帧作为参考图像来生成视频。
实现细节:ExpNet、PoseVAE和FaceRender都是分别训练的,在所有实验中使用Adam优化器 [20]。训练完成后,我们的方法可以以端到端的方式进行推断,无需手动干预。所有的3DMM参数都是通过预训练的深度3D人脸重建方法 [5] 提取的。
在8个A100 GPU上进行所有实验。ExpNet、PoseVAE和FaceRender的学习率分别为2e−5、1e−4和2e−4。对于时间考虑,ExpNet使用连续的5帧进行学习。PoseVAE通过连续32帧进行学习。FaceRender中的帧是逐帧生成的,使用连续5帧的系数以保持稳定性。
评估指标:
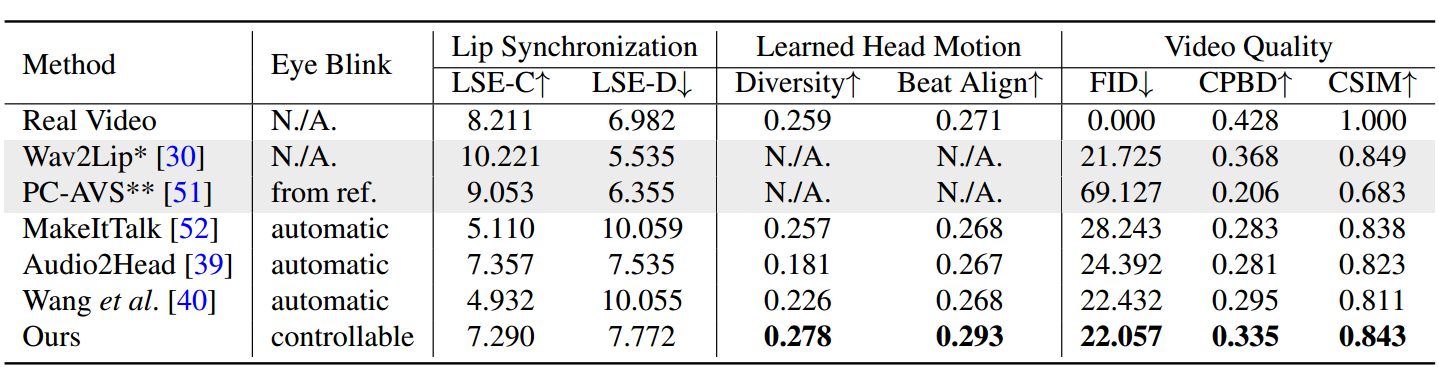
表1。与HDTF数据集上最先进方法的比较。我们评估了Wav2Lip[30]和PC-AVS[51]在一次性设置。Wav2Lip*实现了最好的视频质量,因为它只动画唇区域,而其他区域是相同的原始帧。PC-AVS**使用固定参考姿态进行评估,在某些样本中失败。
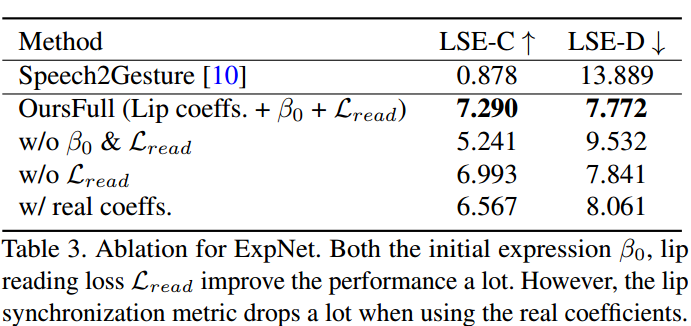
表3。ExpNet的消融。无论是初始表达β0,唇读损失Lread,都大大提高了性能。然而,当使用实系数时,唇同步度量下降了很多。
4.2. 与其他先进方法的比较
包括面部视频生成方法(MakeItTalk [52]、Audio2Head [39]和Wang等人 [40])以及音频到表情生成方法(Wav2Lip [30]、PC-AVS [51])。评估是直接在它们公开可用的检查点上进行的。如表1所示,所提出的方法在整体视频质量和头部姿态多样性方面表现更好,并且在唇同步度量方面与其他完全的说话人头部生成方法相当。我们认为这些唇同步度量指标对音频过于敏感,可能会给不自然的唇部运动打出更高的分数。然而,我们的方法达到了与真实视频类似的分数,这证明了我们的优势。

 图6展示了不同方法的视觉结果。这里,我们提供了唇部参考来可视化我们方法的唇同步效果。从图中可以看出,我们的方法在视觉质量上与原始目标视频非常相似,并且具有我们预期的不同头部姿态。与其他方法相比,Wav2Lip [30]产生了模糊的半张脸。PC-AVS [51]和Audio2Head [39]在身份保持方面存在困难。Audio2Head只能生成正面说话的脸部。此外,MakeItTalk [52]和Audio2Head [39]由于2D变形而产生了扭曲的人脸视频。我们在补充材料中提供了视频比较,以展示更清晰的对比结果。
图6展示了不同方法的视觉结果。这里,我们提供了唇部参考来可视化我们方法的唇同步效果。从图中可以看出,我们的方法在视觉质量上与原始目标视频非常相似,并且具有我们预期的不同头部姿态。与其他方法相比,Wav2Lip [30]产生了模糊的半张脸。PC-AVS [51]和Audio2Head [39]在身份保持方面存在困难。Audio2Head只能生成正面说话的脸部。此外,MakeItTalk [52]和Audio2Head [39]由于2D变形而产生了扭曲的人脸视频。我们在补充材料中提供了视频比较,以展示更清晰的对比结果。
4.4. 消融研究
ExpNet的消融研究:对于ExpNet,我们主要通过唇同步度量评估每个组件的必要性。由于之前没有解耦的方法,我们考虑了一个基线(Speech2Gesture [10],这是一个将音频转换为关键点的生成网络)来共同学习头部姿态和表情系数。如表3和图7所示,同时学习所有运动系数很难生成可信的说话人头部视频。然后,我们考虑了提出的ExpNet的变体,包括初始表情β0、唇读损失Lread以及仅使用嘴唇系数的必要性。图8显示了视觉比较结果,我们没有使用初始表情β0时,预期会出现巨大的身份变化。此外,如果我们使用真实系数替代我们使用的仅嘴唇系数,唇同步性能会大幅下降。

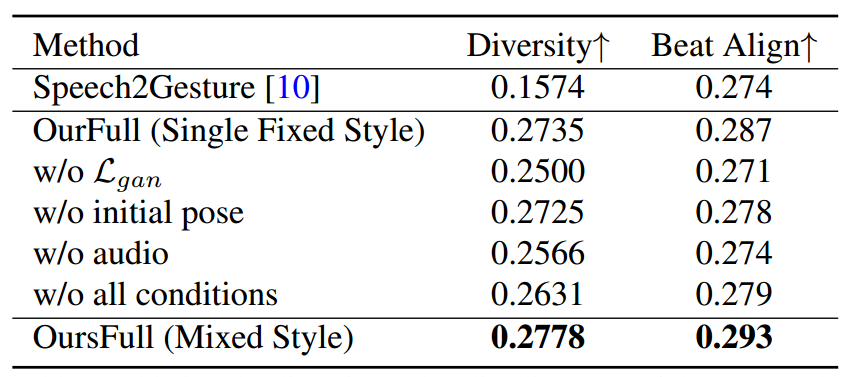
PoseVAE的消融研究:我们从运动多样性和音频节奏对齐方面评估了提出的PoseVAE。如表4所示,基线方法Speech2Gesture [10]在姿态评估中表现较差。至于我们的变体,由于我们的方法包含多个身份风格标签,为了更好地评估其他组件,我们首先考虑对我们的完整方法的一个固定独热风格进行消融研究(OurFull, Single Fixed Style)。我们设置的每个条件在运动多样性和节奏对齐方面都有益于整体运动质量。我们进一步报告了混合风格的完整方法的结果,该方法使用随机选择的身份标签作为风格,并展示了更好的多样性表现。由于姿态差异很难在图中显示出来,请参考我们的补充材料以进行更好的比较。
Face Render的消融研究:我们从两个方面对提出的人脸渲染器进行了消融研究。一方面,我们展示了与PIRenderer [33]相比的重建质量,因为两种方法都使用3DMM作为中间表示。如图9的第一行所示,由于稀疏无监督关键点的映射,提出的人脸渲染器显示出更好的表情重建质量。准确的表情映射也是实现唇同步的关键。此外,我们评估了PIRenderer [33]中使用的额外对齐系数引起的姿态不自然性。如图9的第二行所示,我们绘制了具有相同头部姿态和表情系数的生成视频的关键点轨迹图。使用固定或可学习的裁剪系数(作为我们poseVAE中的一部分姿态系数)将生成面部对齐的视频,这在自然视频中是奇怪的。我们去除它,并直接使用头部姿态和表情作为调制参数,得到更真实的结果。

图9。面部渲染的消融研究。在第一行中,我们直接将我们的方法与PIRenderer[33]进行人脸动画的比较,我们的方法显示出更好的表情建模。第二行是由相同运动系数生成的面部地标的轨迹图。使用额外的面部对齐系数作为运动系数的一部分[33]将产生不现实的对齐头部视频。
5 结论
局限性:由于3DMM无法对眼睛和牙齿的变化建模,Face Render中的mappingNet在某些情况下也难以合成逼真的牙齿。如图10所示,通过使用盲目人脸修复网络 [43] 可以改善这个限制。我们的工作的另一个局限性是我们只关注唇部运动和眨眼,而不考虑其他面部表情,例如情感和凝视方向。因此,生成的视频具有固定的情感,这也降低了生成内容的真实性。
本文提出了一种新的风格化音频驱动说话人头部视频生成系统。我们使用3DMM的运动系数作为中间表示,并学习它们之间的关系。为了从音频中生成逼真的3D系数,我们提出了ExpNet和PoseVAE来实现逼真的表情和多样的头部姿态。为了建模3DMM运动系数与真实视频之间的关系,我们提出了受图像动画方法 [42] 启发的新颖的3D感知人脸渲染器。实验结果证明了我们整个框架的优越性。由于我们可以预测逼真的3D面部系数,我们的方法也可以直接应用于其他领域,例如个性化的2D视觉配音 [45]、2D卡通动画 [52]、3D人脸动画 [8, 46] 和基于NeRF的4D说话人生成 [15]。

















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









