







From 生物技能树
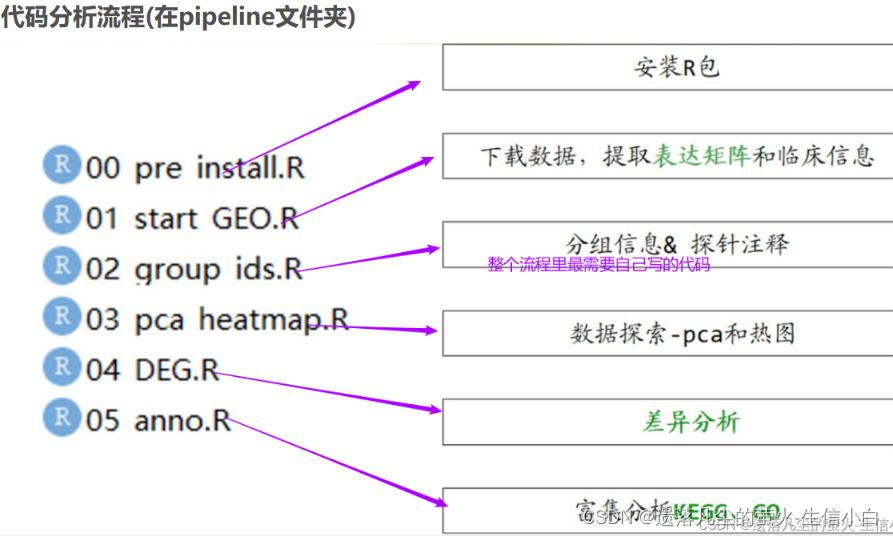
1.安装R包
options("repos"="https://mirrors.ustc.edu.cn/CRAN/")
if(!require("BiocManager")) install.packages("BiocManager",update = F,ask = F)
options(BioC_mirror="https://mirrors.ustc.edu.cn/bioc/")
cran_packages <- c('tidyr',
'tibble',
'dplyr',
'stringr',
'ggplot2',
'ggpubr',
'factoextra',
'FactoMineR',
'devtools',
'cowplot',
'patchwork',
'basetheme',
'paletteer',
'AnnoProbe',
'ggthemes',
'VennDiagram')
Biocductor_packages <- c('GEOquery',
'hgu133plus2.db',
'ggnewscale',
"limma",
"impute",
"GSEABase",
"GSVA",
"clusterProfiler",
"org.Hs.eg.db",
"preprocessCore",
"enrichplot")
for (pkg in cran_packages){
if (! require(pkg,character.only=T,quietly = T) ) {
install.packages(pkg,ask = F,update = F)
require(pkg,character.only=T)
}
}
for (pkg in Biocductor_packages){
if (! require(pkg,character.only=T,quietly = T) ) {
BiocManager::install(pkg,ask = F,update = F)
require(pkg,character.only=T)
}
}
#前面的所有提示和报错都先不要管。主要看这里
for (pkg in c(Biocductor_packages,cran_packages)){
require(pkg,character.only=T)
}
#没有任何提示就是成功了,如果有warning xx包不存在,用library检查一下。
#library报错,就单独安装。
if(!require(tinyarray))install.packages("https://cran.r-project.org/src/contrib/Archive/tinyarray/tinyarray_2.3.3.tar.gz",repos = NULL)
library(tinyarray)
2.下载数据,提取表达矩阵和临床信息
需要改代码
rm(list = ls())
#打破下载时间的限制,改前60秒,改后10w秒
options(timeout = 100000)
options(scipen = 20)#不要以科学计数法表示
#传统下载方式
library(GEOquery)
eSet = getGEO("GSE7305", destdir = '.', getGPL = F)
#网速太慢,下不下来怎么办
#1.从网页上下载/发链接让别人帮忙下,放在工作目录里
#2.试试geoChina,只能下载2019年前的表达芯片数据
#library(AnnoProbe)
#eSet = geoChina("GSE7305") #选择性代替第8行
#研究一下这个eSet
class(eSet)
length(eSet)
eSet = eSet[[1]]
class(eSet)
#(1)提取表达矩阵exp
exp <- exprs(eSet)
dim(exp)
range(exp)#看数据范围决定是否需要log,是否有负值,异常值
exp = log2(exp+1) #需要log才log
boxplot(exp,las = 2) #看是否有异常样本
#(2)提取临床信息
pd <- pData(eSet)
#(3)让exp列名与pd的行名顺序完全一致
p = identical(rownames(pd),colnames(exp));p
if(!p) {
s = intersect(rownames(pd),colnames(exp))
exp = exp[,s]
pd = pd[s,]
}
#(4)提取芯片平台编号,后面要根据它来找探针注释
gpl_number <- eSet@annotation;gpl_number
save(pd,exp,gpl_number,file = "step1output.Rdata")
# 原始数据处理的代码,按需学习
# https://mp.weixin.qq.com/s/0g8XkhXM3PndtPd-BUiVgw
3.分组信息&探针注释
需要改代码
# Group(实验分组)和ids(探针注释)
rm(list = ls())
load(file = "step1output.Rdata")
# 1.Group----
library(stringr)
# 标准流程代码是二分组,多分组数据的分析后面另讲
# 生成Group向量的三种常规方法,三选一,选谁就把第几个逻辑值写成T,另外两个为F。如果三种办法都不适用,可以继续往后写else if
if(F){
# 第一种方法,有现成的可以用来分组的列
}else if(F){
# 第二种方法,眼睛数,自己生成
Group = rep(c("Disease","Normal"),each = 10)
# rep函数的其他用法?相间、两组的数量不同?
}else if(T){
# 第三种方法,使用字符串处理的函数获取分组
k = str_detect(pd$title,"Normal");table(k)
Group = ifelse(k,"Normal","Disease")
}
# 需要把Group转换成因子,并设置参考水平,指定levels,对照组在前,处理组在后
Group = factor(Group,levels = c("Normal","Disease"))
Group
#2.探针注释的获取-----------------
#捷径
library(tinyarray)
find_anno(gpl_number) #辅助写出找注释的代码
library(hgu133plus2.db);ids <- toTable(hgu133plus2SYMBOL)
#这是从28行运行结果里复制下来的代码👆
#如果能打出代码就不需要再管其他方法。
#如果使用复制下来的AnnoProbe::idmap('xxx')代码发现报错了,请注意尝试不同的type参数
#如果显示no annotation avliable in Bioconductor and AnnoProbe则要去GEO网页上看GPL表格里找啦。
#四种方法,方法1里找不到就从方法2找,以此类推。
#捷径里面包含了全部的R包、一部分表格、一部分自主注释
#方法1 BioconductorR包(最常用,已全部收入find_anno里面,不用看啦)
if(F){
gpl_number #看看编号是多少
#http://www.bio-info-trainee.com/1399.html #在这里搜索,找到对应的R包
library(hgu133plus2.db)
ls("package:hgu133plus2.db") #列出R包里都有啥
ids <- toTable(hgu133plus2SYMBOL) #把R包里的注释表格变成数据框
}
# 方法2 读取GPL网页的表格文件,按列取子集
##https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL570
# 方法3 官网下载注释文件并读取
# 方法4 自主注释,了解一下
#https://mp.weixin.qq.com/s/mrtjpN8yDKUdCSvSUuUwcA
save(exp,Group,ids,file = "step2output.Rdata")
4.数据探索-PCA和热图
不需要更改
rm(list = ls())
load(file = "step2output.Rdata")
#输入数据:exp和Group
#Principal Component Analysis
#http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/112-pca-principal-component-analysis-essentials
# 1.PCA 图----
dat=as.data.frame(t(exp))
library(FactoMineR)
library(factoextra)
dat.pca <- PCA(dat, graph = FALSE)
fviz_pca_ind(dat.pca,
geom.ind = "point", # show points only (nbut not "text")
col.ind = Group, # color by groups
palette = c("#00AFBB", "#E7B800"),
addEllipses = TRUE, # Concentration ellipses
legend.title = "Groups"
)
# 2.top 1000 sd 热图----
g = names(tail(sort(apply(exp,1,sd)),1000)) #day7-apply的思考题
n = exp[g,]
library(pheatmap)
annotation_col = data.frame(row.names = colnames(n),
Group = Group)
pheatmap(n,
show_colnames =F,
show_rownames = F,
annotation_col=annotation_col,
scale = "row", #按行标准化,只保留行内差别,不保留行间差别,会把数据范围缩放到大概-5~5之间
breaks = seq(-3,3,length.out = 100) #设置色带分布范围为-3~3之间,超出此范围的数字显示极限颜色
)
# 关于scale的进一步学习:zz.scale.R
5.差异分析
无需更改
rm(list = ls())
load(file = "step2output.Rdata")
#差异分析
library(limma)
design = model.matrix(~Group)
fit = lmFit(exp,design)
fit = eBayes(fit)
deg = topTable(fit,coef = 2,number = Inf)
#为deg数据框添加几列
#1.加probe_id列,把行名变成一列
library(dplyr)
deg = mutate(deg,probe_id = rownames(deg))
#2.加上探针注释
ids = distinct(ids,symbol,.keep_all = T)
#其他去重方式在zz.去重方式.R
deg = inner_join(deg,ids,by="probe_id")
nrow(deg) #如果行数为0就是你找的探针注释是错的。
#3.加change列,标记上下调基因
logFC_t = 1
p_t = 0.05
#思考,如何使用padj而非p值
k1 = (deg$P.Value < p_t)&(deg$logFC < -logFC_t)
k2 = (deg$P.Value < p_t)&(deg$logFC > logFC_t)
deg = mutate(deg,change = ifelse(k1,"down",ifelse(k2,"up","stable")))
table(deg$change)
#火山图
library(ggplot2)
ggplot(data = deg, aes(x = logFC, y = -log10(P.Value))) +
geom_point(alpha=0.4, size=3.5, aes(color=change)) +
scale_color_manual(values=c("blue", "grey","red"))+
geom_vline(xintercept=c(-logFC_t,logFC_t),lty=4,col="black",linewidth=0.8) +
geom_hline(yintercept = -log10(p_t),lty=4,col="black",linewidth=0.8) +
theme_bw()
# 差异基因热图----
# 表达矩阵行名替换为基因名
exp = exp[deg$probe_id,]
rownames(exp) = deg$symbol
diff_gene = deg$symbol[deg$change !="stable"]
n = exp[diff_gene,]
library(pheatmap)
annotation_col = data.frame(group = Group)
rownames(annotation_col) = colnames(n)
pheatmap(n,show_colnames =F,
show_rownames = F,
scale = "row",
#cluster_cols = F,
annotation_col=annotation_col,
breaks = seq(-3,3,length.out = 100)
)
#4.加ENTREZID列,用于富集分析(symbol转entrezid,然后inner_join)
library(clusterProfiler)
library(org.Hs.eg.db)
s2e = bitr(deg$symbol,
fromType = "SYMBOL",
toType = "ENTREZID",
OrgDb = org.Hs.eg.db)#人类,注意物种
#一部分基因没匹配上是正常的。<30%的失败都没事。
#其他物种http://bioconductor.org/packages/release/BiocViews.html#___OrgDb
nrow(deg)
deg = inner_join(deg,s2e,by=c("symbol"="SYMBOL"))
#多了几行少了几行都正常,SYMBOL与ENTREZID不是一对一的。
nrow(deg)
save(exp,Group,deg,logFC_t,p_t,file = "step4output.Rdata")
6.富集分析KEGG、GO
有时需要更改
rm(list = ls())
load(file = 'step4output.Rdata')
library(clusterProfiler)
library(ggthemes)
library(org.Hs.eg.db)
library(dplyr)
library(ggplot2)
library(stringr)
library(enrichplot)
#(1)输入数据
gene_diff = deg$ENTREZID[deg$change != "stable"]
#(2)富集
ekk <- enrichKEGG(gene = gene_diff,organism = 'hsa')
ekk <- setReadable(ekk,OrgDb = org.Hs.eg.db,keyType = "ENTREZID")
ego <- enrichGO(gene = gene_diff,OrgDb= org.Hs.eg.db,
ont = "ALL",readable = TRUE)
#setReadable和readable = TRUE都是把富集结果表格里的基因名称转为symbol
class(ekk)
#(3)可视化
barplot(ego, split = "ONTOLOGY") +
facet_grid(ONTOLOGY ~ ., space = "free_y",scales = "free_y")
barplot(ekk)
#或者是dotplot
# 更多资料---
# GSEA:https://www.yuque.com/docs/share/a67a180f-dd2b-4f6f-96c2-68a4b86fe862?#
# Y叔的书:http://yulab-smu.top/clusterProfiler-book/index.html
# GOplot:https://mp.weixin.qq.com/s/LonwdDhDn8iFUfxqSJ2Wew
# 网上的资料和宝藏无穷无尽,学好R语言慢慢发掘~
示例数据(只展示了01和02里的更改,其余代码不用改)
二分组(GSE45422)
rm(list = ls())
#打破下载时间的限制,改前60秒,改后10w秒
options(timeout = 100000)
options(scipen = 20)#不要以科学计数法表示
#传统下载方式
library(GEOquery)
#eSet = getGEO("GSE45422", destdir = '.', getGPL = F)
#网速太慢,下不下来怎么办
#1.从网页上下载/发链接让别人帮忙下,放在工作目录里
#2.试试geoChina,只能下载2019年前的表达芯片数据
library(AnnoProbe)
eSet = geoChina("GSE45422") #选择性代替第8行
#研究一下这个eSet
class(eSet)
length(eSet)
eSet = eSet[[1]]
class(eSet)
#(1)提取表达矩阵exp
exp <- exprs(eSet)
dim(exp)
range(exp)#看数据范围决定是否需要log,是否有负值,异常值
exp = log2(exp+1) #需要log才log
boxplot(exp,las = 2) #看是否有异常样本
#(2)提取临床信息
pd <- pData(eSet)
#(3)让exp列名与pd的行名顺序完全一致
p = identical(rownames(pd),colnames(exp));p
if(!p) {
s = intersect(rownames(pd),colnames(exp))
exp = exp[,s]
pd = pd[s,]
}
#(4)提取芯片平台编号,后面要根据它来找探针注释
gpl_number <- eSet@annotation;gpl_number
save(pd,exp,gpl_number,file = "step1output.Rdata")
# 原始数据处理的代码,按需学习
# https://mp.weixin.qq.com/s/0g8XkhXM3PndtPd-BUiVgw
# Group(实验分组)和ids(探针注释)
rm(list = ls())
load(file = "step1output.Rdata")
# 1.Group----
library(stringr)
# 标准流程代码是二分组,多分组数据的分析后面另讲
# 生成Group向量的三种常规方法,三选一,选谁就把第几个逻辑值写成T,另外两个为F。如果三种办法都不适用,可以继续往后写else if
if(F){
# 第一种方法,有现成的可以用来分组的列
}else if(F){
# 第二种方法,眼睛数,自己生成
Group = rep(c("untreated","treated"),each = 10)
# rep函数的其他用法?相间、两组的数量不同?
}else if(T){
# 第三种方法,使用字符串处理的函数获取分组
k = str_detect(pd$title,"untreated");table(k)
Group = ifelse(k,"untreated","treated")
}
data.frame(pd$title,Group) #用pd的title列和group生成一个数据框放在一起,检查一下分组对不对
# 需要把Group转换成因子,并设置参考水平,指定levels,对照组在前,处理组在后
Group = factor(Group,levels = c("untreated","treated"))
Group
levels(Group) #单独提取levels,查看Group向量里都有哪些取值,这就叫因子的水平,顺序对照组在前,处理组在后
#2.探针注释的获取-----------------
#捷径
library(tinyarray)
find_anno(gpl_number) #辅助写出找注释的代码
ids <- AnnoProbe::idmap('GPL4133', type = 'pipe')
#library(hgu133plus2.db);ids <- toTable(hgu133plus2SYMBOL)
#这是从28行运行结果里复制下来的代码👆
#如果能打出代码就不需要再管其他方法。
#如果使用复制下来的AnnoProbe::idmap('xxx')代码发现报错了,请注意尝试不同的type参数
#如果显示no annotation avliable in Bioconductor and AnnoProbe则要去GEO网页上看GPL表格里找啦。
#四种方法,方法1里找不到就从方法2找,以此类推。
#捷径里面包含了全部的R包、一部分表格、一部分自主注释
#方法1 BioconductorR包(最常用,已全部收入find_anno里面,不用看啦)
if(F){
gpl_number #看看编号是多少
#http://www.bio-info-trainee.com/1399.html #在这里搜索,找到对应的R包
library(hgu133plus2.db)
ls("package:hgu133plus2.db") #列出R包里都有啥
ids <- toTable(hgu133plus2SYMBOL) #把R包里的注释表格变成数据框
}
# 方法2 读取GPL网页的表格文件,按列取子集
##https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL570
# 方法3 官网下载注释文件并读取
# 方法4 自主注释,了解一下
#https://mp.weixin.qq.com/s/mrtjpN8yDKUdCSvSUuUwcA
save(exp,Group,ids,file = "step2output.Rdata")
从多分组数据里选出二分组(GSE11775)
rm(list = ls())
#打破下载时间的限制,改前60秒,改后10w秒
options(timeout = 100000)
options(scipen = 20)#不要以科学计数法表示
#传统下载方式
library(GEOquery)
#eSet = getGEO("GSE11775", destdir = '.', getGPL = F)
#网速太慢,下不下来怎么办
#1.从网页上下载/发链接让别人帮忙下,放在工作目录里
#2.试试geoChina,只能下载2019年前的表达芯片数据
library(AnnoProbe)
eSet = geoChina("GSE11775") #选择性代替第8行
#研究一下这个eSet
class(eSet)
length(eSet)
eSet = eSet[[1]]
class(eSet)
#(1)提取表达矩阵exp
exp <- exprs(eSet)
dim(exp)
range(exp)#看数据范围决定是否需要log,是否有负值,异常值
#exp = log2(exp+1) #需要log才log,不能运行两遍。
boxplot(exp,las = 2) #看是否有异常样本
# exp = limma::(normalizeBetweenArrays(exp)) 把少量异常样本标准化
#(2)提取临床信息
pd <- pData(eSet)
# 多分组在这里加筛选样本的代码
library(stringr)
k1 = str_detect(pd$title,"Treg Foxp3-deficient");table(k1)
k2 = str_detect(pd$title,"Foxp3 sufficient");table(k2)
pd = pd[k1|k2,]
也可以合并如下:
# k = str_detect(pd$title, "Treg Foxp3-deficient|Foxp3 sufficient");table(k)
# pd = pd[k,]
#(3)让exp列名与pd的行名顺序完全一致
p = identical(rownames(pd),colnames(exp));p
if(!p) {
s = intersect(rownames(pd),colnames(exp))
exp = exp[,s]
pd = pd[s,]
}
#(4)提取芯片平台编号,后面要根据它来找探针注释
gpl_number <- eSet@annotation;gpl_number
save(pd,exp,gpl_number,file = "step1output.Rdata")
# 原始数据处理的代码,按需学习
# https://mp.weixin.qq.com/s/0g8XkhXM3PndtPd-BUiVgw
# Group(实验分组)和ids(探针注释)
rm(list = ls())
load(file = "step1output.Rdata")
# 1.Group----
library(stringr)
# 标准流程代码是二分组,多分组数据的分析后面另讲
# 生成Group向量的三种常规方法,三选一,选谁就把第几个逻辑值写成T,另外两个为F。如果三种办法都不适用,可以继续往后写else if
if(F){
# 第一种方法,有现成的可以用来分组的列
}else if(F){
# 第二种方法,眼睛数,自己生成
Group = rep(c("sufficient","deficient"),each = 10)
# rep函数的其他用法?相间、两组的数量不同?
}else if(T){
# 第三种方法,使用字符串处理的函数获取分组
k = str_detect(pd$title,"sufficient");table(k)
Group = ifelse(k,"sufficient","deficient")
}
data.frame(pd$title,Group) #检测一下分组是否正确
# 需要把Group转换成因子,并设置参考水平,指定levels,对照组在前,处理组在后
Group = factor(Group,levels = c("sufficient","deficient"))
Group
#2.探针注释的获取-----------------
#捷径
library(tinyarray)
find_anno(gpl_number) #辅助写出找注释的代码
ids <- AnnoProbe::idmap('GPL1261')
#library(mouse430a2.db);ids <- toTable(mouse430a2SYMBOL)
#library(hgu133plus2.db);ids <- toTable(hgu133plus2SYMBOL)
#这是从28行运行结果里复制下来的代码👆
#如果能打出代码就不需要再管其他方法。
#如果使用复制下来的AnnoProbe::idmap('xxx')代码发现报错了,请注意尝试不同的type参数
#如果显示no annotation avliable in Bioconductor and AnnoProbe则要去GEO网页上看GPL表格里找啦。
#四种方法,方法1里找不到就从方法2找,以此类推。
#捷径里面包含了全部的R包、一部分表格、一部分自主注释
#方法1 BioconductorR包(最常用,已全部收入find_anno里面,不用看啦)
if(F){
gpl_number #看看编号是多少
#http://www.bio-info-trainee.com/1399.html #在这里搜索,找到对应的R包
library(hgu133plus2.db)
ls("package:hgu133plus2.db") #列出R包里都有啥
ids <- toTable(hgu133plus2SYMBOL) #把R包里的注释表格变成数据框
}
# 方法2 读取GPL网页的表格文件,按列取子集
##https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL570
# 方法3 官网下载注释文件并读取
# 方法4 自主注释,了解一下
#https://mp.weixin.qq.com/s/mrtjpN8yDKUdCSvSUuUwcA
save(exp,Group,ids,file = "step2output.Rdata")

















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









