







From生物技能树 GEO数据挖掘第一节
(pipeline)(Day8-9)
文章目录
1.图表分析
2.GEO背景介绍及分析思路
3.代码分析流程
4.复杂数据分析
提示:这是GEO数据挖掘的大概内容:
理论知识
广义的基因有 6w+个,如何缩小范围到课题相关?
1.数据从哪里来
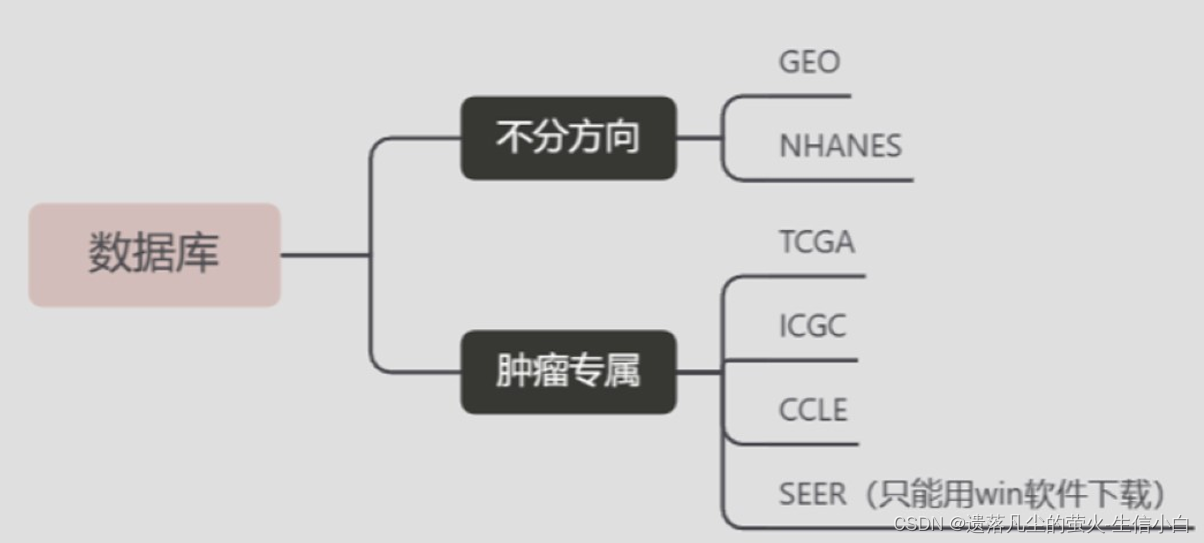
2.有什么类型的数据可挖掘
基因表达芯片
转录组
单细胞
突变(外显子)、甲基化、拷贝数差异。。。
3.如何筛选基因(分析方法)
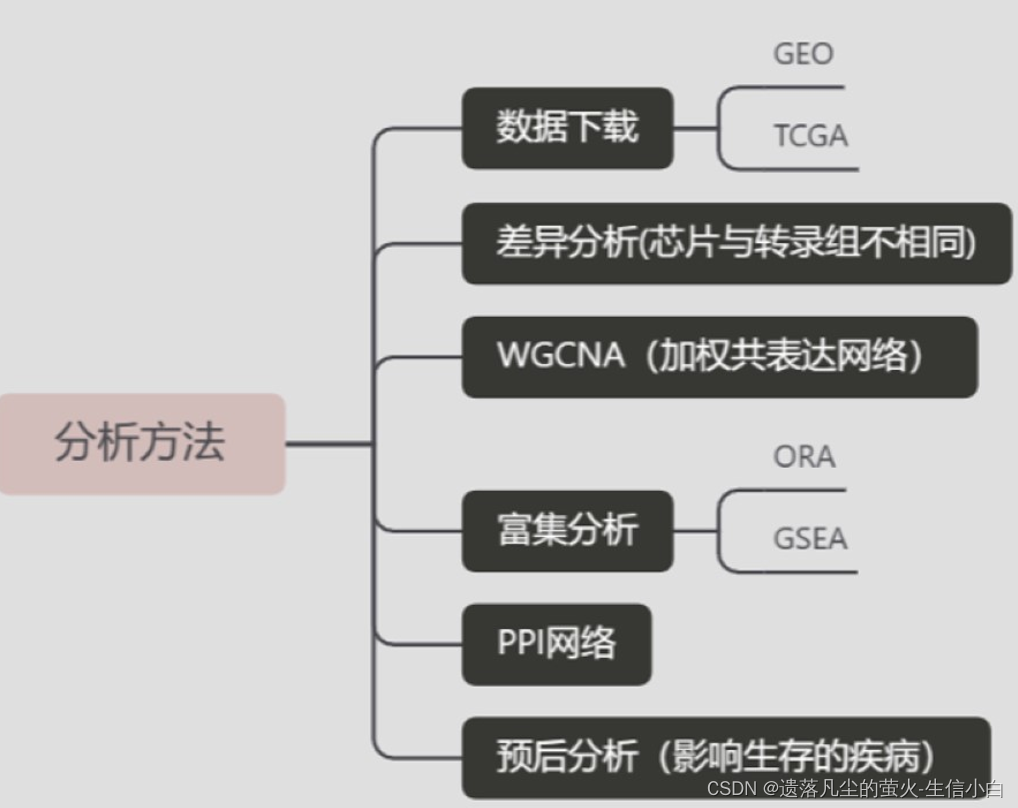
图表介绍
1.热图
- 输入数据是数值型矩阵/数据框
- 颜色的变化表示数值的大小
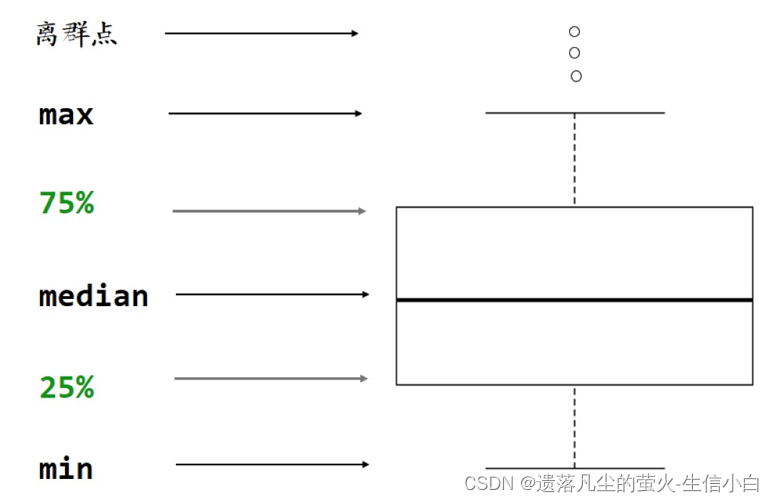
2.散点图和箱线图
- 横坐标是下标/组
- 纵坐标是表达值
- 箱线图的五条线:max、75%、median、25%、min
- 箱线图:用于单个基因在两组之间的表达差异
输入数据是一个连续型向量和一个有重复值的离散型向量
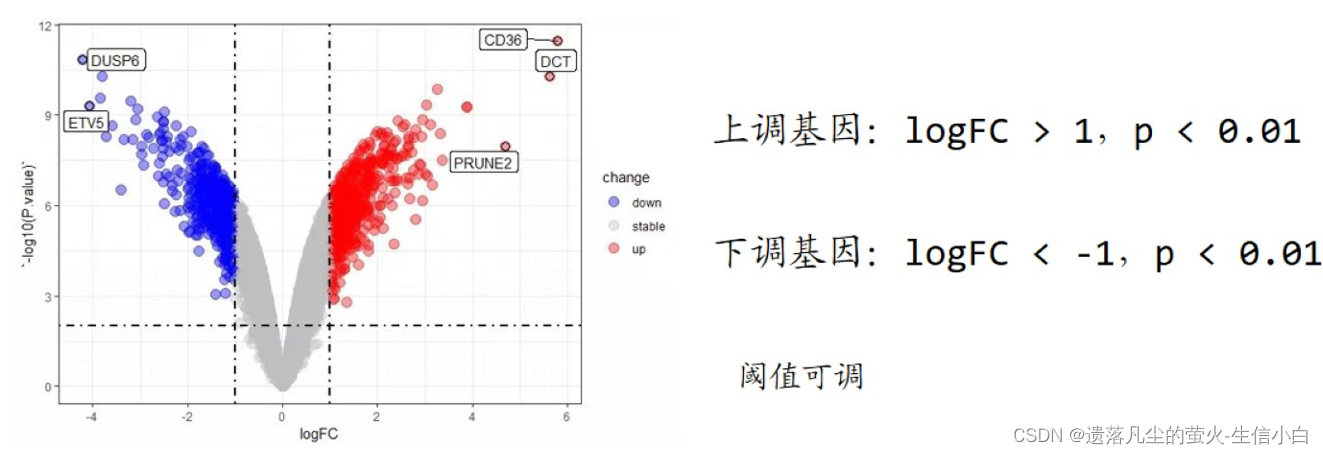
3.火山图
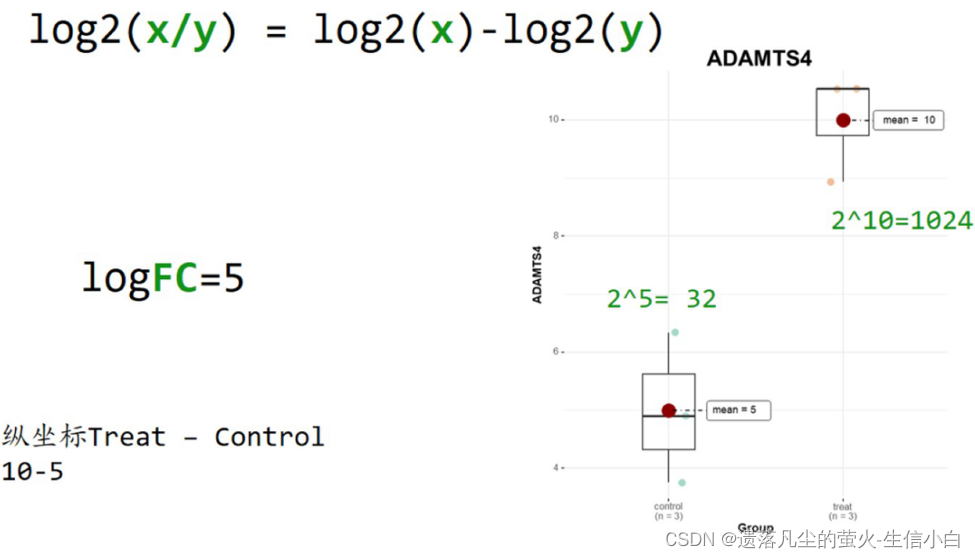
Foldchange(FC):处理组平均值/对照组平均值
log2Foldchange(logFc):Foldchange取log2
- List item
- 火山图:差异分析,用于多个基因在两组间的表达差异
- 横坐标是 logFC,纵坐标是-log10(Pvalue)
- logFC: Foldchange取log2,Foldchange为处理组表达量平均值/对照组表达量平均值,实际计算时,为先取log2,然后log2(处理组)-log2(对照组),既没有单位也没有意义,只是一个相对值的意义
- 永远都是处理组-对照组,而不是大的-小的
- logFC 如果太大:是不是没取 log?顶多在 ±12 之间
- logFC > 0,treat > control,基因表达量上升
- logFC < 0,treat < control,基因表达量下降
- 通常所说的上调、下调基因是指表达量显著上升/下降的基因(需要结合显著性p值)
- logFC 的阈值设置是自行规定的,p 值阈值一般为 0.01,常见的 logFC 阈值有:1、2、1.2、1.5、2.2、(0.585=log2(1.5):即上升1.5倍),阈值可调。
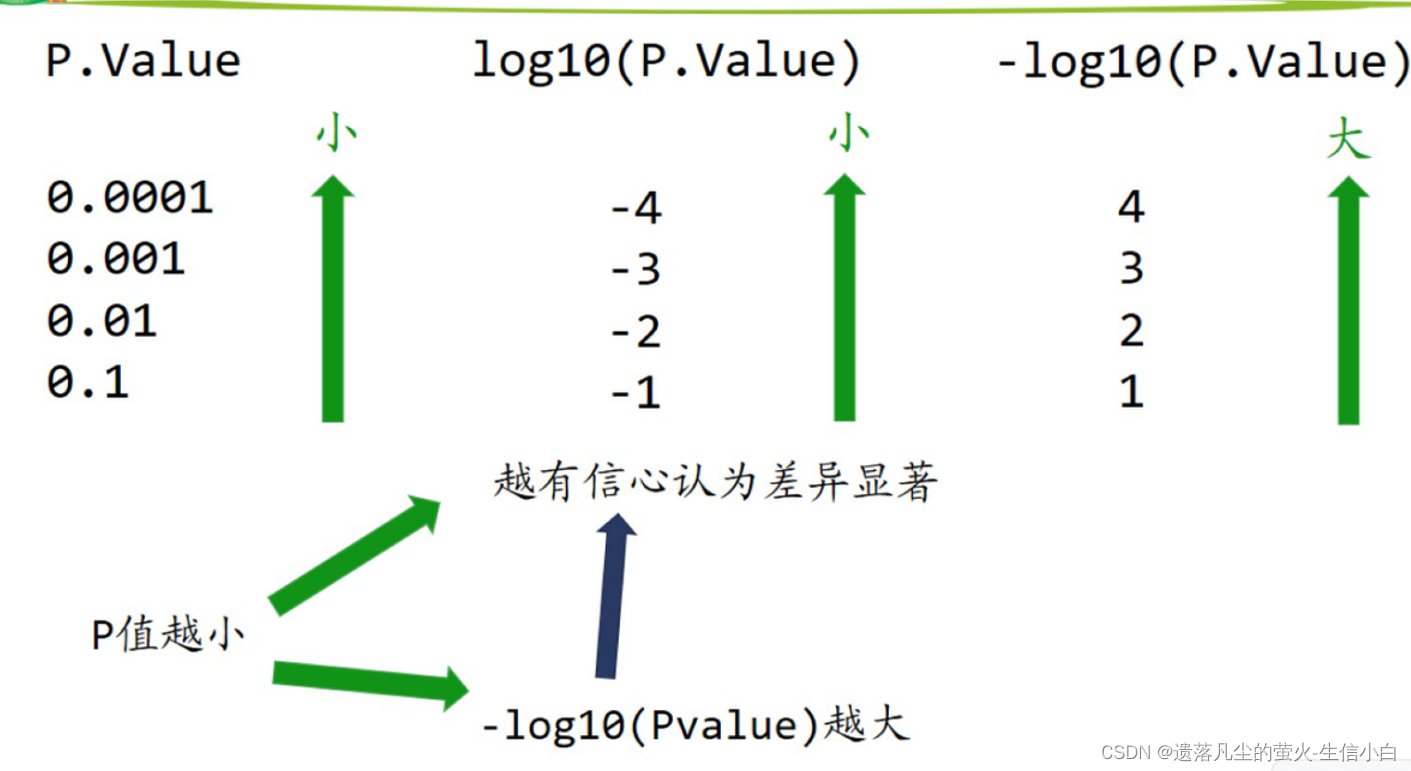
- 为什么 y 轴要取 lg?把 p 值拉到同一个数量级上,比较好画图
芯片差异分析的起点是一个取过log的表达矩阵(0-20),
如果拿到的是未log的矩阵(0-很大),需要自行log
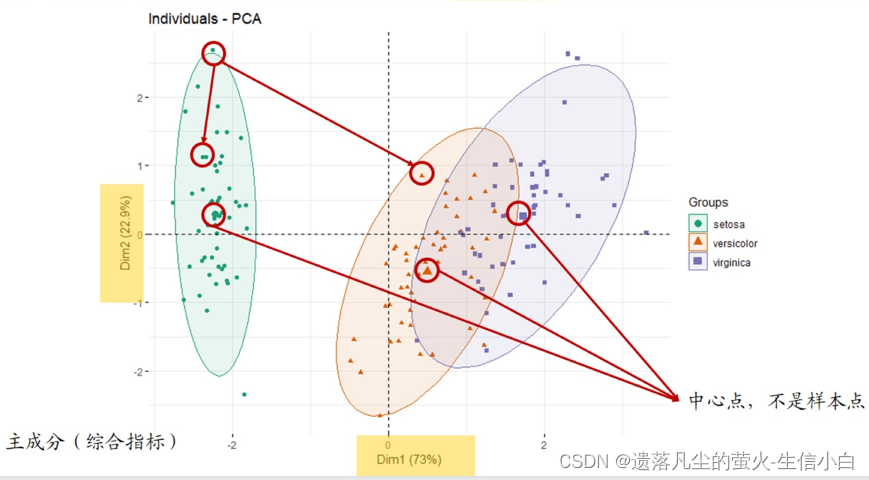
4.主成分分析图
1.主成分分析,旨在利用降维的思想,把多指标转化为少数几个综合指标(即主成分)
根据这些主成分对样本进行聚类,代表样本的点在坐标轴上距离越远,说明样本差异越大,
2. 图上的点代表样本(除中心点外),点与点之间的距离表示样本与样本的区别
3. 主成分的值没有意义,是很多个变量降维得到的一个值,dm1和dm2是维度,dm1+dm2>90%,
4. 用处:用于“预实验”简单查看组间是否有差别。同一分组是否聚成一簇(组内 重复好),中心点之间是否有距离(组间 差别大)。
GEO背景知识+表达芯片分析思路
如何查找数据,GEO数据库
添加链接描述
点进去series查找自己感兴趣的数据(主要有两种数据类型:基因表达芯片和转录组测序),点开样本查看数据分布范围,有没有全部都在0附近,如果有大量负值,数据不正常。然后查看分组信息。

1.表达数据实验设计
1.实验目的:通过基因表达量数据的差异分析和富集分析来解释生物学现象
病变组织vs健康组织
药物处理 vs 对照组(水/DMSO)
开花前vs开花后
·动物/昆虫不同发育期
·有色/无色果皮
高产/低产品种
有差异的材料→差异基因→找功能/找关联→解释差异,缩小基因范围
2.数据库介绍
1.GEO首页有一个GEO2R网页工具,它可以给相应的代码,但是没有判断数据是否正常的机制,使用默认的参数,无法得到全部的默认的基因,代码仅供参考。
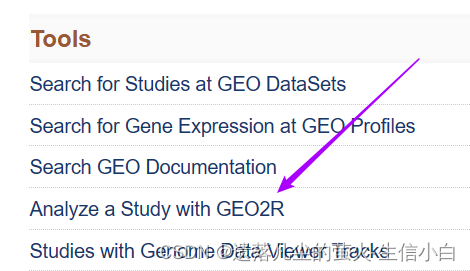
2.
3.数据库数据
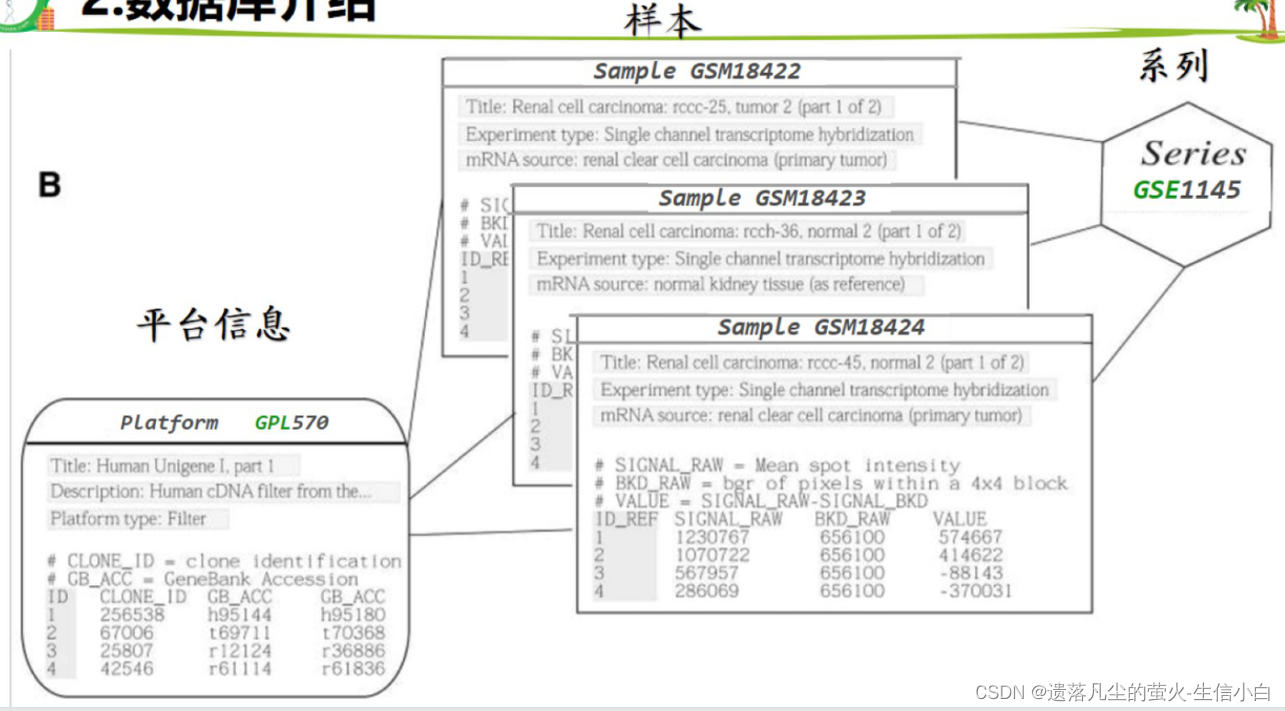
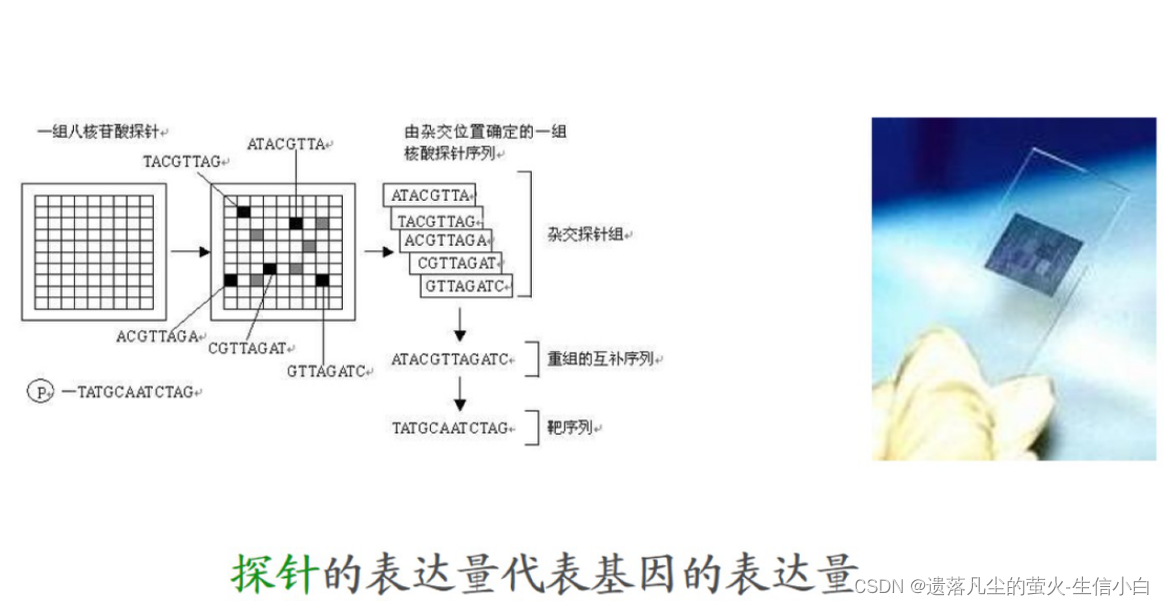
3.基因表达芯片的原理
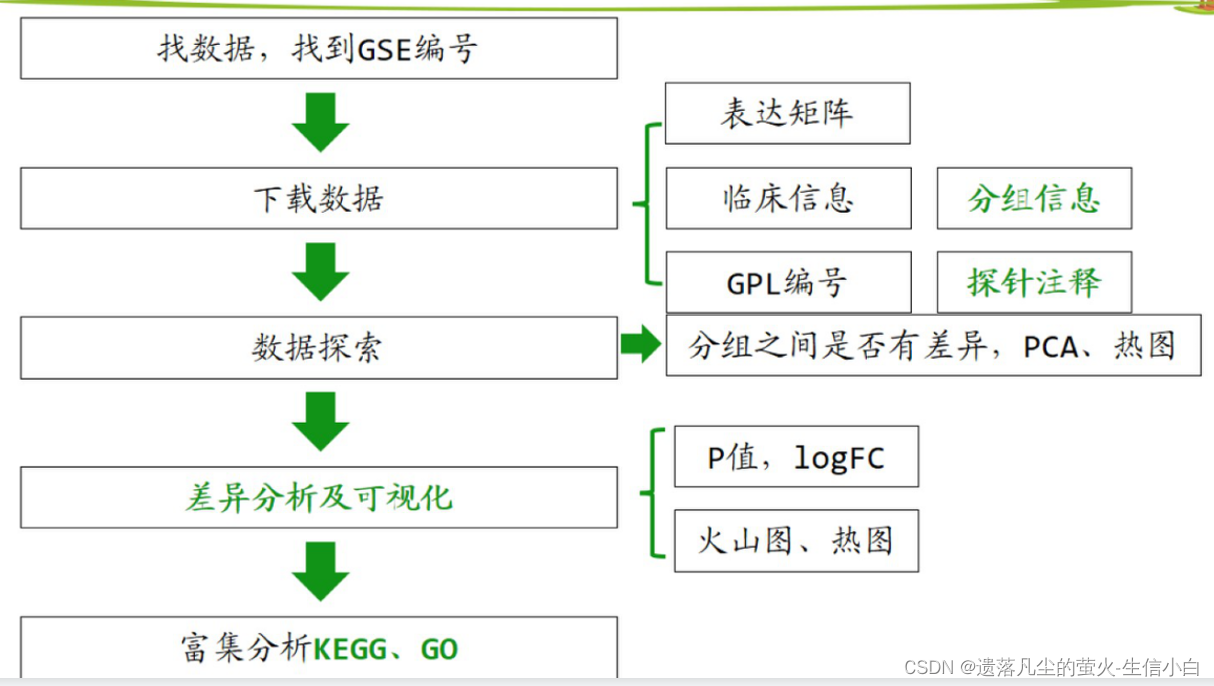
分析思路
1.找数据,找到 GSE 编号
2.下载并读取数据
3.表达矩阵
4.临床信息 → 分组信息:需要自己整理
5.GPL 编号 → 探针注释(每个探针属于哪个基因,探针与基因的对应关系)
6.数据探索:分组之间是否有差异、PCA、热图(离散基因热图)
7.差异分析及可视化:limma包差异分析(P值、logFC)、画图(火山图、差异基因热图)
8.富集分析:GO、KEGG
需要整理的信息
1.探针 id→ 基因名称
2.GSM 样本 ID→ 分组信息
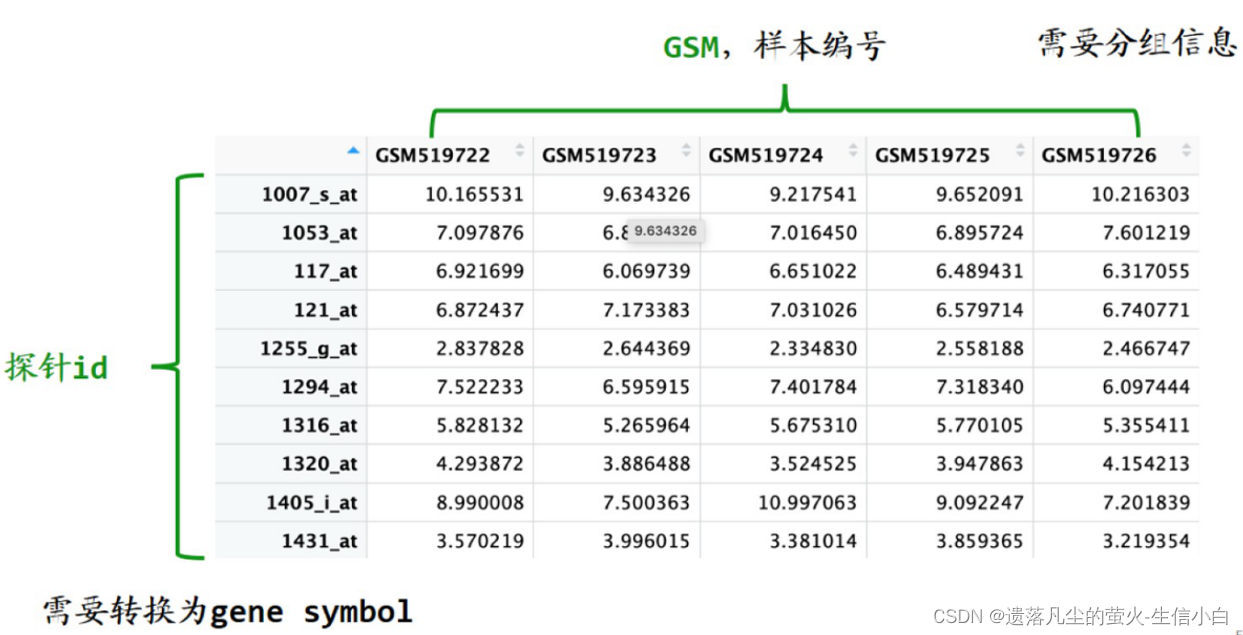
芯片差异分析所需的输入数据

代码分析流程(在pipeline文件夹)

安装 R 包
00_pre_install 全选运行安装里面的 R 包
require(pkg,character.only=T), 这个参数告诉 require() 函数,pkg 是一个字符向量。
下载数据,提取表达矩阵和临床信息
- 下载数据,大多数情况下只要在 R 中用代码下载即可
rm(list = ls())
#打破下载时间的限制,改前60秒,改后10w秒
options(timeout = 100000)
options(scipen = 20)#不要以科学计数法表示
#传统下载方式
#getGEO() 函数是 GEOquery 包提供的一个工具,用于从GEO数据库下载和导入数据集。getGEO()有则直接读取,没有的话就帮忙下载并读取,在工作目录下
library(GEOquery)
eSet = getGEO("GSE7305", destdir = '.', getGPL = F)
#destdir = '.'是指下载后放在工作目录,getGPL是指不下载GPL文件,下载的话会变得很慢,不需要它
网速太慢,下不下来怎么办?
1.从网页上下载/发链接让别人帮忙下,放在工作目录里
2.试试geoChina,只能下载2019年前的表达芯片数据
library(AnnoProbe)
eSet = geoChina("GSE7305") #选择性代替eSet = getGEO("GSE7305", destdir = '.', getGPL = F)
手动下载的方法:
1.GEO 首页-Series
- GSE:一个完整的研究,包括实验设计描述、数据描述、总结分析等
- GSM:用户提交给 GEO 的样本数据
- GPL:指用户用于测定表达量的芯片平台
2.搜索需要的疾病
3.按 array 筛选检测方法
4.点进一个 GSE
5.Series Matrix File
6.matrix.txt.gz 是表达矩阵的压缩包(至少应该是六七百 k)
#下载下来后,研究一下这个eSet
class(eSet)
## [1] "list"
#返回列表里有几个元素
length(eSet)
## [1] 1
#应该是1,如果有2说明是一个SuperSeries里面有两批测序结果,如果不需要合并的话最好是分开提取,分开分析
eSet = eSet[[1]] #去掉列表数据,留下里边数据,取出eSet这个列表里的唯一一个子集,并把其再赋值给eSet,所以不能重复运行。
class(eSet)
## [1] "ExpressionSet"
## attr(,"package")
## [1] "Biobase"
#ExpressionSet :数据的对象的类型
提取表达矩阵exp
exp <- exprs(eSet)
dim(exp)
#任何GEO的ExpressionSet数据都是用exprs()提取的,提取成matrix,dim() 函数用于返回一个对象的维度,这个对象可以是矩阵、数组或者数据框(data frame)。对于矩阵和数组,dim() 函数返回一个包含行数和列数的向量。
## [1] 54675 20
range(exp)#看数据范围决定是否需要log,是否有负值,异常值
## [1] 5.020951 22011.934000
exp = log2(exp+1) #需要log才log,如果不需要取log,加上#号
#如果需要去掉一个样本:
#exp = exp[,-3]
boxplot(exp,las = 2) # 看数据里有无异常样本
检查表达矩阵是否异常
正常表达矩阵
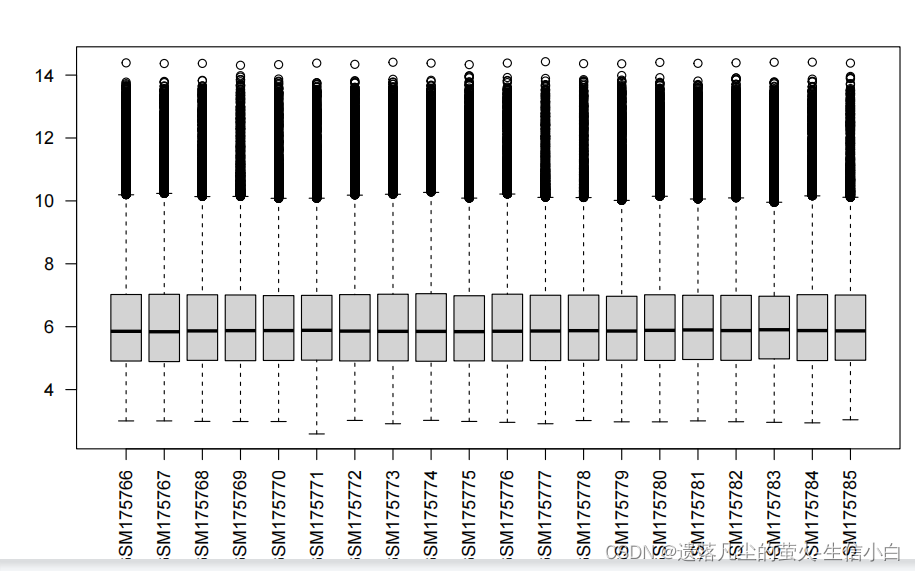
看是否有异常样本:
数值特别大,说明没取log
箱线图中位数差别特别大的:
处理异常样本:
去掉异常样本
标准化:exp = limma::(normalizeBetweenArrays(exp))
关于表达矩阵里的负值:
1.取过log,有少量的负值:正常
2.没取过log,有负值:不正常,错误数据
3.有一半负值,中位数为0:是不正常的标准化的数据
4.2和3情况一般弃用,非要用的话就处理原始数据
提取临床信息
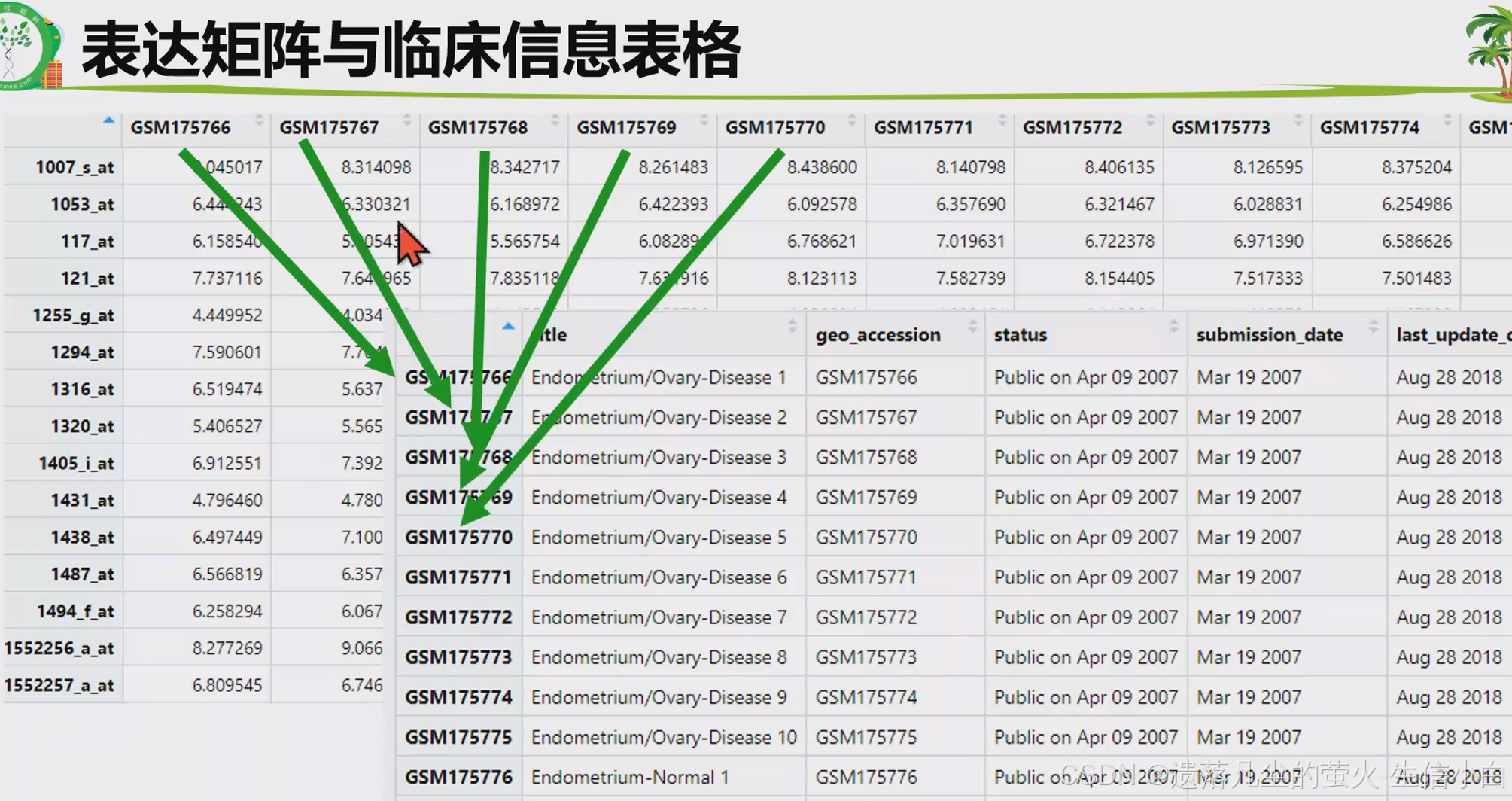
pd <- pData(eSet) # 提取临床信息,表达矩阵的行与临床信息的列相对应
#如果需要从多个分组里取出其中两个,多分组在这里加筛选样本的代码,只需要在临床信息里更改
```c
例如一个多分组:该代码适用于所有的多分组筛选二分组
library(stringr)
k1 = str_detect(pd$title,"Hep3B,control");table(k1)
k2 = str_detect(pd$title,"Hep3B,control");table(k2)
pd = pd[k1|k2,] #组合
#现编一个三分组
#pdKaTeX parse error: Expected 'EOF', got '#' at position 61: …es = c(6,6,8)) #̲假如需要从多个分组里面取两个分…group,“group1|group2”);table(k)
#pd = pd[k,]
让exp列名与pd的行名顺序完全一致
```c
p = identical(rownames(pd),colnames(exp));p
## [1] TRUE
#identical判断行名和列名是否完全一致,完全相同返回T,不完全相同返回F,则运行以下代码
if(!p) {
s = intersect(rownames(pd),colnames(exp))
exp = exp[,s]
pd = pd[s,]
}
#s为pd里的行名和exp里的列名取交集,再使新的exp和pd变成按s顺序取子集,使他们的顺序完全一致
提取芯片平台编号,后面要根据它来找探针注释
gpl_number <- eSet@annotation;gpl_number
## [1] "GPL570"
#对象里的元素提取时用@还是$根据前面的符号,是什么就用什么
save(pd,exp,gpl_number,file = "step1output.Rdata")
#完成第一步,保存一下成Rdata
每次写完代码之后一定要全选运行一下,保证代码正确且只运行了一次
附:原始数据处理的代码,按需学习:
添加链接描述
Group(实验分组)和ids(探针注释)
# Group(实验分组)和ids(探针注释)
rm(list = ls())
load(file = "step1output.Rdata")
实验分组的设置
# 1.Group----
library(stringr)
# 标准流程代码是二分组,多分组数据的分析后面另讲
# 生成Group向量的三种常规方法,三选一,选谁就把第几个逻辑值写成T,另外两个为F。如果三种办法都不适用,可以继续往后写else if,示例只执行第三个方法代码
if(F){
# 第一种方法,有现成的可以用来分组的列
}else if(F){
# 第二种方法,眼睛数,自己生成
Group = rep(c("Disease","Normal"),each = 10)
# rep函数的其他用法?相间、两组的数量不同?
}else if(T){
# 第三种方法,使用字符串处理的函数获取分组
k = str_detect(pd$title,"Normal");table(k)
Group = ifelse(k,"Normal","Disease")
}
# **第一种方法**,有现成的可以用来分组的列
> pd$title
[1] "Endometrium/Ovary-Disease 1" "Endometrium/Ovary-Disease 2"
[3] "Endometrium/Ovary-Disease 3" "Endometrium/Ovary-Disease 4"
[5] "Endometrium/Ovary-Disease 5" "Endometrium/Ovary-Disease 6"
[7] "Endometrium/Ovary-Disease 7" "Endometrium/Ovary-Disease 8"
[9] "Endometrium/Ovary-Disease 9" "Endometrium/Ovary-Disease 10"
[11] "Endometrium-Normal 1" "Endometrium-Normal 2"
[13] "Endometrium-Normal 3" "Endometrium-Normal 4"
[15] "Endometrium-Normal 5" "Endometrium-Normal 6"
[17] "Endometrium-Normal 7" "Endometrium-Normal 8"
[19] "Endometrium-Normal 9" "Endometrium-Normal 10"
#如果这一列只有"Disease","Normal"这俩单词,不需要做任何改动,可直接运行下边代码,但是它除了这俩单词还有一些额外的信息
Group = pd$title
# **第二种方法**,眼睛数,自己生成
Group = rep(c("Disease","Normal"),each = 10)
> rep(c("Disease","Normal"),each = 10)
[1] "Disease" "Disease" "Disease" "Disease" "Disease" "Disease" "Disease" "Disease"
[9] "Disease" "Disease" "Normal" "Normal" "Normal" "Normal" "Normal" "Normal"
[17] "Normal" "Normal" "Normal" "Normal"
>
#rep用法: # rep函数的其他用法?相间、两组的数量不同?
> rep(c("Disease","Normal"),each = 10)
[1] "Disease" "Disease" "Disease" "Disease" "Disease" "Disease" "Disease" "Disease"
[9] "Disease" "Disease" "Normal" "Normal" "Normal" "Normal" "Normal" "Normal"
[17] "Normal" "Normal" "Normal" "Normal"
> rep(c("Disease","Normal"),times = c(8,9))
[1] "Disease" "Disease" "Disease" "Disease" "Disease" "Disease" "Disease" "Disease"
[9] "Normal" "Normal" "Normal" "Normal" "Normal" "Normal" "Normal" "Normal"
[17] "Normal"
> rep(c("Disease","Normal"),times = 10)
[1] "Disease" "Normal" "Disease" "Normal" "Disease" "Normal" "Disease" "Normal"
[9] "Disease" "Normal" "Disease" "Normal" "Disease" "Normal" "Disease" "Normal"
[17] "Disease" "Normal" "Disease" "Normal"
# **第三种方法**,匹配关键词,使用字符串处理的函数获取分组,比较万能
k = str_detect(pd$title,"Normal");table(k) #按Normal这个关键词对pd$title中进行检测,有的话就是T,没有就是F
Group = ifelse(k,"Normal","Disease") #根据T还是F赋值group
#替换成功
> ifelse(k,"Normal","Disease")
[1] "Disease" "Disease" "Disease" "Disease" "Disease" "Disease" "Disease" "Disease"
[9] "Disease" "Disease" "Normal" "Normal" "Normal" "Normal" "Normal" "Normal"
[17] "Normal" "Normal" "Normal" "Normal"
#检查,#用pd的title列和group生成一个数据框放在一起,检查一下分组对不对
> data.frame(pd$title,Group)
pd.title Group
1 Endometrium/Ovary-Disease 1 Disease
2 Endometrium/Ovary-Disease 2 Disease
3 Endometrium/Ovary-Disease 3 Disease
4 Endometrium/Ovary-Disease 4 Disease
5 Endometrium/Ovary-Disease 5 Disease
6 Endometrium/Ovary-Disease 6 Disease
7 Endometrium/Ovary-Disease 7 Disease
8 Endometrium/Ovary-Disease 8 Disease
9 Endometrium/Ovary-Disease 9 Disease
10 Endometrium/Ovary-Disease 10 Disease
11 Endometrium-Normal 1 Normal
12 Endometrium-Normal 2 Normal
13 Endometrium-Normal 3 Normal
14 Endometrium-Normal 4 Normal
15 Endometrium-Normal 5 Normal
16 Endometrium-Normal 6 Normal
17 Endometrium-Normal 7 Normal
18 Endometrium-Normal 8 Normal
19 Endometrium-Normal 9 Normal
20 Endometrium-Normal 10 Normal

需要把Group转换成因子,因子非常适合组织有重复值的向量,并设置参考水平,自行指定levels,对照组在前,处理组在后
Group的默认排序是按照首字母排序,但是为了避免错误,我们不按照默认排序,指定levels,对照组在前,处理组在后


Group = factor(Group,levels = c("Normal","Disease"))
Group
##[1] Disease Disease Disease Disease Disease Disease Disease Disease Disease Disease
##[11] Normal Normal Normal Normal Normal Normal Normal Normal Normal Normal
##Levels: Normal Disease
#levels(Group)
##[1] "Normal" "Disease"
##单独提取levels,查看Group向量里都有哪些取值,这就叫因子的水平,顺序对照组在前,处理组在后
探针注释的获取
原理:探针与基因的对应关系表格,一个数据框
需要把probe_id和基因symbol对应起来:基因组注释
注释来源:
1.Biocoductor的注释包:添加链接描述
2.GPL页面的表格文件解析:找探针和symbol这两列,但不是所有文件都可以通过GPL页面找到这两列
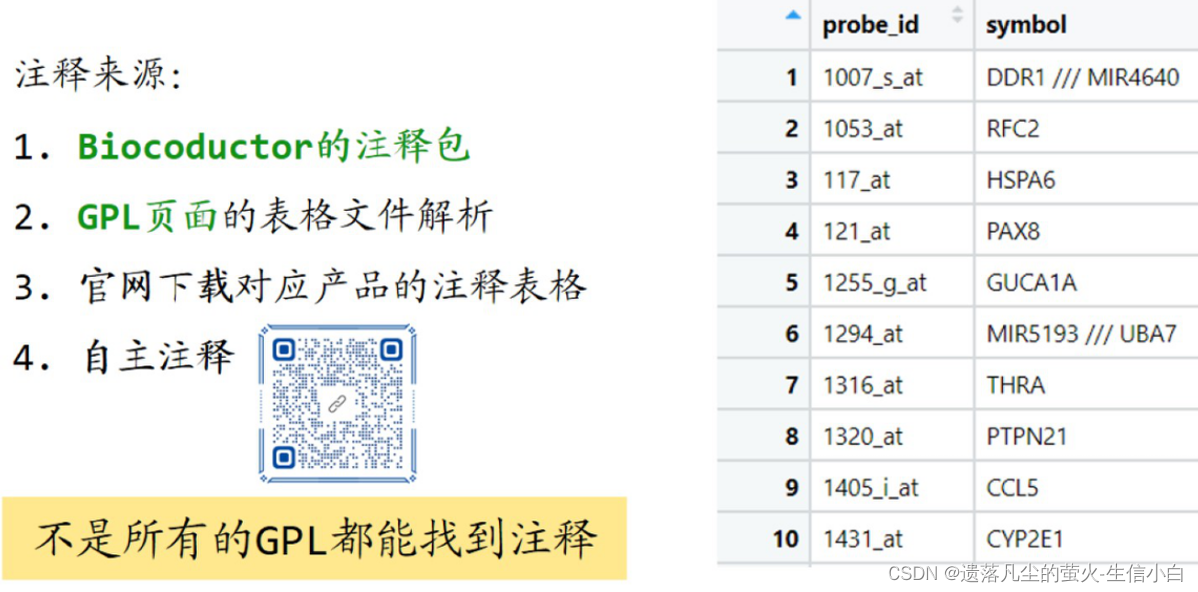
#2.探针注释的获取(运行的时候不同数据代码也要改动)
#捷径
library(tinyarray)
find_anno(gpl_number) #辅助写出找注释的代码
#读取并按列取子集的例子:GPL6887
#获取表格下载链接
#https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL6887&targ=self&form=text&view=data
get_gpl_txt(gpl_number)
#读取表格
#三种方式:
a = data.table::fread("GPL6887.txt",data.table = F)
#a = rio::import("GPL6887.txt")
#a = read.delim("GPL6887.txt",check.names = F,skip = 33)
colnames(a)
ids = a[,c("ID","Symbol")]
View(ids)
#要改列名,后面的代码适应这两个列名
colnames(ids) = c("probe_id","symbol")
View(ids)
#library(hgu133plus2.db);ids <- toTable(hgu133plus2SYMBOL)
#这是从find_anno(gpl_number)行运行结果里复制下来的代码👆
#如果能打出代码就不需要再管其他方法。
#如果使用复制下来的AnnoProbe::idmap('xxx')代码发现报错了,请注意尝试不同的type参数
#如果显示no annotation avliable in Bioconductor and AnnoProbe则要去GEO网页上看GPL表格里找啦。
#四种方法,方法1里找不到就从方法2找,以此类推。
#捷径里面包含了全部的R包、一部分表格、一部分自主注释
#方法1 BioconductorR包(最常用,已全部收入find_anno里面,不用看啦)
if(F){
gpl_number #看看编号是多少
#http://www.bio-info-trainee.com/1399.html #在这里搜索,找到对应的R包
library(hgu133plus2.db)
ls("package:hgu133plus2.db") #列出R包里都有啥
ids <- toTable(hgu133plus2SYMBOL) #把R包里的注释表格变成数据框
}
# 方法2 读取GPL网页的表格文件,按列取子集
##https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL570
# 方法3 官网下载注释文件并读取
# 方法4 自主注释,了解一下
#[添加链接描述](https://mp.weixin.qq.com/s/mrtjpN8yDKUdCSvSUuUwcA)
save(exp,Group,ids,file = "step2output.Rdata")
运行 find_anno(gpl_number) 代码会出现的报错:
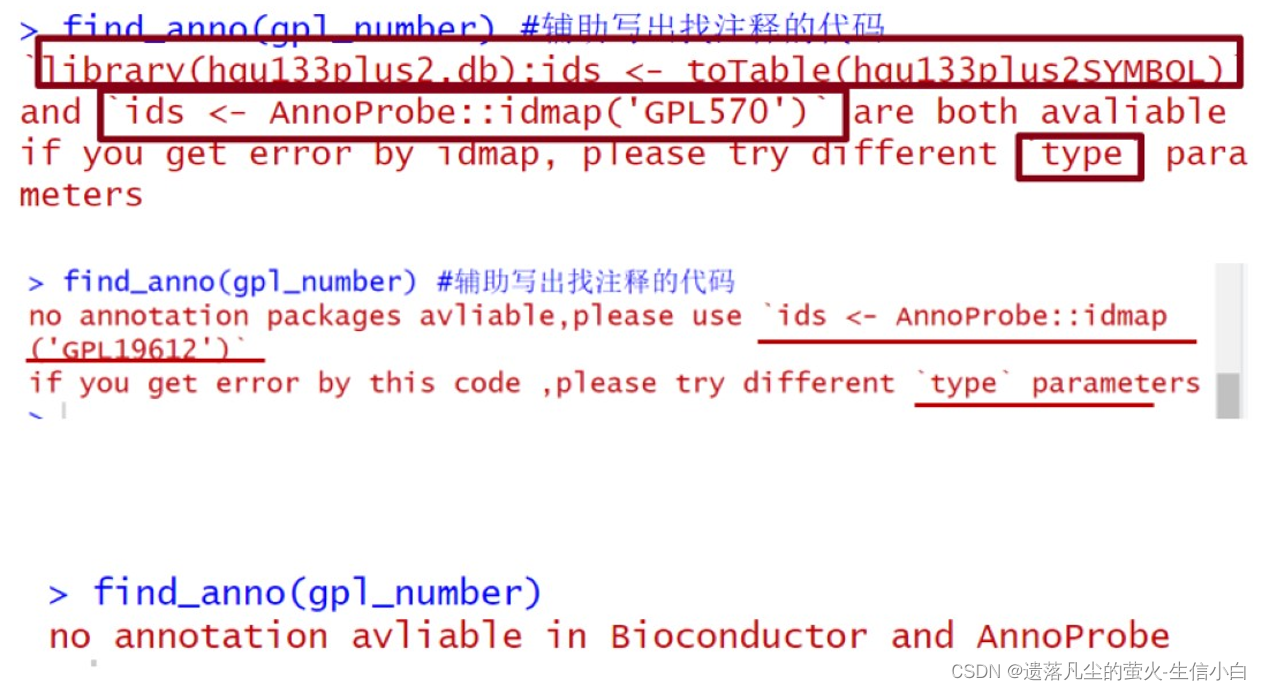
解决办法:
方法一:
find_anno(gpl_number)
library(hgu133plus2.db);ids <- toTable(hgu133plus2SYMBOL)
方法二:
find_anno(gpl_number)
ids <- AnnoProbe::idmap('GPL570')
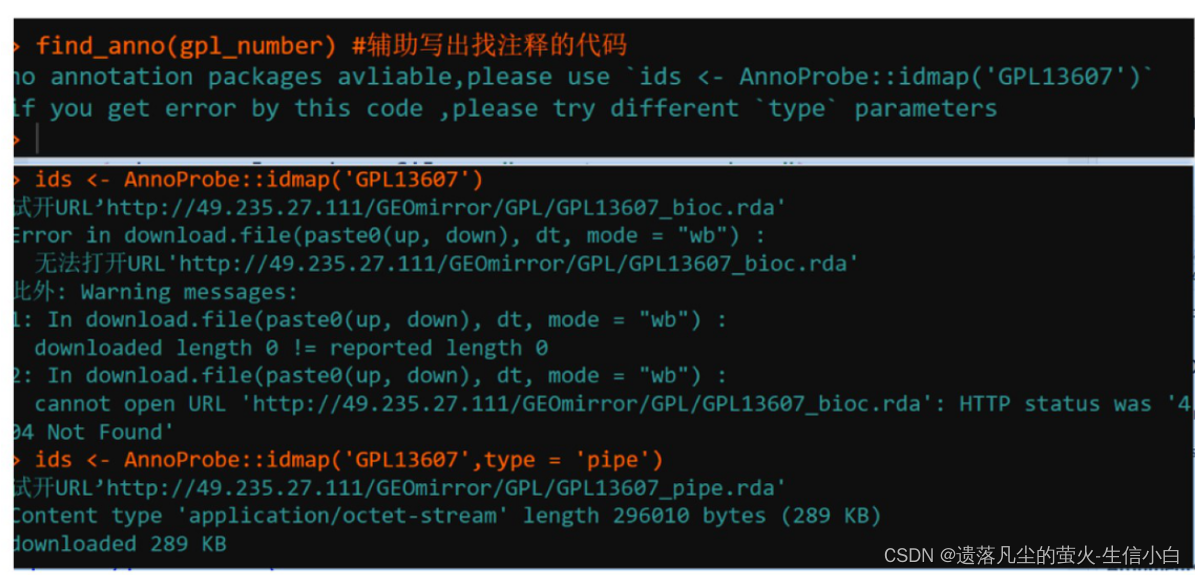
如果还是报错:
?AnnoProbe::idmap #查看帮助文档,尝试type的三个参数,一个一个尝试
查看ids,要求ids只能有两列,第一列探针id,第二列symbol,并且列名都要是小写的列名
如果列名是大写的,就更改一下
colnames(ids) = c("probe_id","symbol")

















 7888
7888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









