







🌟 所属专栏:机器学习(统计学习)
🐔 作者简介:rchjr——五带信管菜只因一枚
😮 前言:该系列将持续更新机器学习经典算法的相关学习笔记,欢迎和我一样的小白订阅,一起学习共同进步~
👉 文章简介:本文介绍感知机算法,将结合图片,代码等形式对感知机算法进行深入浅出的讲解,学习内容来自b站的 @深度之眼官方账号 的视频
👉1 前言
在讲解算法之前,让我们看一下下面这张图。通过肉眼和经验,我们很快便可以发现一个规律,那就是当x,y都大于0时,就属于红点;当x,y都小于0时,就属于绿点。
但是如果想要让程序知道这一规律,该怎么办呢?
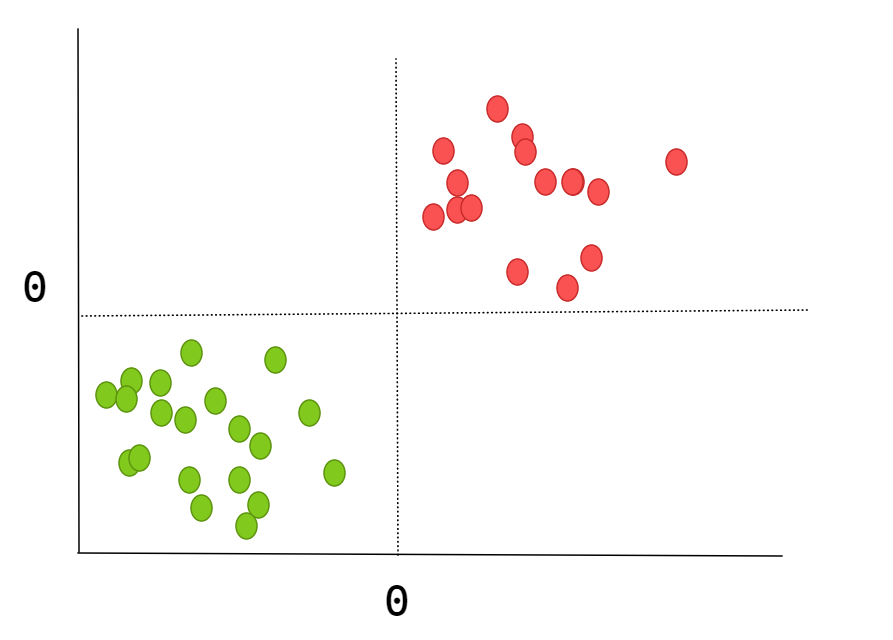
不着急,我们先来看看几条直线对这一规律的把握程度

可以发现,直线1和直线2都能很好的将红绿点进行区分;直线3基本将红绿点进行了区分,有少数红点被划到了绿点;但是直线4则根本无法对红绿点进行区分,因为它把所有的点分到了一个区域!所以我们规定,一条直线如果能够不分错一个点,那就是一条好的直线了。
所以我们就是面临两个问题:
如果不分错任何一个点就是好的直线
如何量化一条直线有多好
具体量化方法就是:把所有分错的点和直线的距离求和,求和的距离决定好坏。
💪2 感知机模型
f(x) = sign(w·x + b),其中sign(x) = 
那么其实抽象来说,就是我们给定一个点x作为f(x)的输入,那么就可以得到红点还是绿点的输出。这里无论是参数w,b还是输入x,都是向量,w·x是向量的内积。
例如,对于一个点,它可能包含以下这些特征:
x1:直径
x2:质量
x3:光滑度
......
超平面
我们把w·x+b叫做超平面。因为w,x,b都是维度不确定的向量,如果都是二维的,那么wx+b就是一条一维的直线;如果都是三维的,那么wx+b就是二维的平面,以此类推。其中w是超平面的法向量,b是超平面的截距,这个超平面将特征空间划分成两部分,位于两部分的点分别被分为正负两类。
数据集的线性可分性

很显然,感知机模型只适用于线性可分的数据集,所以它属于线性模型。
函数间距与几何间距
接下来我们具体讨论一下如何计算点到超平面的距离。
函数间距就是将x0带入超平面表达式wx0 + b得到的值,因为会有正负,所以还需要加上一个绝对值|wx0 + b|

但是我们会发现用函数间距存在的问题:对于在超平面上的点x1,wx1+b=0,如果两边同时放大或者缩小,对结果是不会有改变的,例如2(wx1+b)=0,那么模型就会认为可以随意放大缩小。那么对于不在超平面上的点x2,wx2+b=5,同时缩小二分之一的话,0.5(wx2+b) = 0.5*5,这样距离就变小了。因此,模型为了让距离之和尽可能的小,就会去缩小参数,但是事实上超平面却没有发生改变。
几何间距则是在函数间距的基础上除以w的内积,即1/||w||(|wx+b|),这样无论怎样放大缩小都没有用,模型就会寻找别的办法减小距离和。
综上,我们采用几何间距作为特征空间中点到超平面的距离。
💁3 感知机的学习算法——原始形式
接下来我们看看感知机是通过什么算法得到一个好的线性模型,可以做二分类问题的。
如何判断模型预测正确还是失败
我们知道,对于预测错误的点来说,其原来的真实值yi与模型的预测值wxi+b的积的负数一定是大于0的。因此我们可以借助这么一个式子来判断模型预测的是正确的还是错误的。
式子> 0
例如,我们假设红点的yi为1,绿点的yi为-1。如果模型预测绿点失败了,那么得到的wxi+b就会大于0,然后-yi也大于0,因此对于上面的式子也大于0。
如何计算预测失败的点到超平面S的距离
根据上面对几何间距的描述我们知道一个点到超平面的距离是1/||w||(|wx+b|),然后我们又知道一定是大于0的。因此预测失败的点到超平面的距离就可以修改为-1/||w||yi(wxi+b),这里我们用代替了|wx+b|,因为 恒大于0,就可以去掉|wx+b|的绝对值,其他地方不变。
恒大于0,就可以去掉|wx+b|的绝对值,其他地方不变。
因此,所有预测失败的点到超平面的距离之和就是
 ,其中n表示预测失败的点的个数。
,其中n表示预测失败的点的个数。
同时相信看过我的概述文章的朋友已经发现了,这个距离之和其实就是一个损失函数L(w, b)。
求模型的计算过程
现在,我们就可以根据数据集来一步步求得那个最佳的分类模型了。
首先,我们任取一个超平面wx + b,里面的参数w和b都是随机取的。
采用梯度下降法极小化损失函数L(w, b) =
 。有人可能会问这个损失函数和上面的不一样啊,少除了一个模长啊。这里原视频给出的原因是感知机是误分类驱动的,即只要能让模型预测的误差越小越好,所以除不除那个模长都无所谓,因为只要让模型迭代到后面,那么效果都是一样的,这样做还可以减少计算量。你可以理解为条条大路通罗马,除不除到最后都可以实现误分类最少的目的。
。有人可能会问这个损失函数和上面的不一样啊,少除了一个模长啊。这里原视频给出的原因是感知机是误分类驱动的,即只要能让模型预测的误差越小越好,所以除不除那个模长都无所谓,因为只要让模型迭代到后面,那么效果都是一样的,这样做还可以减少计算量。你可以理解为条条大路通罗马,除不除到最后都可以实现误分类最少的目的。
那么什么是梯度下降法呢?这里我简单提一下,感兴趣的朋友最好去搜一下其他大神的专门讲解。首先,我们的最终目的是要找到参数w和b使得损失函数的值最小对吧?这就好比一个函数,我们要找到它的最小值所在的位置。其次,梯度指的是:
在单变量的函数中,梯度是函数的微分,是函数在某个点上切线的斜率
在多变量函数中,梯度是一个向量,而向量是有方向的,所以梯度的方向就指出了函数在给定点的上升最快的方向
这里只用一个参数为例

得到更新后的参数w,b
💻4 代码实现感知机
😃1导入数据集
这里采用鸢(yuan)尾花数据集,一共150个样本点,每个样本点有4个特征值,分别是花萼长度、花萼宽度、花瓣长度、花瓣宽度,标签类别有3类,0,1,2,对应山鸢尾、变色鸢尾和维吉尼亚鸢尾。
# coding: utf-8
# 作者(@Author): Messimeimei
# 创建时间(@Created_time): 2023/3/3 10:53
"""感知机模型代码实现"""
from sklearn import datasets
import pandas as pd
import numpy as np
import matplotlib as plot
mydata = datasets.load_iris() # 加载鸢尾花数据集
df = pd.DataFrame(mydata.data, columns=mydata.feature_names) # 利用pandas构建数据集
df['label'] = mydata.target # 添加标签列
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label'] # 去掉单位cm
print(df)
打印数据集
😃2 修改数据
因为感知机只能做2分类,所以这里我们选择两个特征值训练,标签的值也只有2个。
data = np.array(df.iloc[:100, [2, 3, -1]]) #取100个样本,后两个特征值训练
# print(data)
x = data[:, :-1] #取出特征值
y = data[:, -1] #取出标签
y = np.array([1 if i == 1 else -1 for i in y])
for i in range(len(x)):
print(x[i], y[i])
😃3 构造感知机
class PerceptronModel(object):
def __init__(self):
self.w = np.ones(len(data[0]) - 1, dtype=np.float32) # 参数w有2个特征值,而data[0]中有3列,其中一列是标签,所以减1
self.b = 0 # 偏执
self.lrate = 0.1 # 梯度下降用的学习率
def sign(self, x, w, b):
"""sign函数,即 f(x) = wx + b"""
y = np.dot(x, w) + b # np.dot是求内积的意思
return y
def gradient_descent(self, x_train, y_label):
"""梯度下降法"""
flag = False # 模型是否全部预测正确
while not flag:
wrong_num = 0 # 计算预测错误的样本数
for i in range(len(x_train)):
x = x_train[i] # 取出样本点的特征值
y = y_label[i] # 取出样本点对应的标签
# 如果判断错误(文章中提到了判断的式子)就进行梯度更新
if -y * self.sign(x, self.w, self.b) > 0:
self.w = self.w + self.lrate * np.dot(y, x) # 更新w
self.b = self.b + self.lrate * y # 更新b
print(f"参数w:{self.w}, 参数b:{self.b}")
wrong_num += 1 # 误分类数加1
# 预测错误数为0,说明模型全部预测正确,结束梯度更新
if wrong_num == 0:
flag = True
return self.w, self.b # 返回参数和偏置
perceptron = PerceptronModel()
perceptron.gradient_descent(x, y)
更新过程
😃4 完整代码
# coding: utf-8
# 作者(@Author): Messimeimei
# 创建时间(@Created_time): 2023/3/3 10:53
"""感知机模型代码实现"""
from sklearn import datasets
import pandas as pd
import numpy as np
import matplotlib as plot
mydata = datasets.load_iris() # 加载鸢尾花数据集
df = pd.DataFrame(mydata.data, columns=mydata.feature_names) # 利用pandas构建数据集
df['label'] = mydata.target # 添加标签列
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
# print(df)
data = np.array(df.iloc[:100, [2, 3, -1]]) # 取100个样本,后两个特征值训练
# print(data)
x = data[:, :-1] # 取出特征值
y = data[:, -1] # 取出标签
y = np.array([1 if i == 1 else -1 for i in y])
for i in range(len(x)):
print(x[i], y[i])
class PerceptronModel(object):
def __init__(self):
self.w = np.ones(len(data[0]) - 1, dtype=np.float32) # 参数w有2个特征值,而data[0]中有3列,其中一列是标签,所以减1
self.b = 0 # 偏执
self.lrate = 0.1 # 梯度下降用的学习率
def sign(self, x, w, b):
"""sign函数,即 f(x) = wx + b"""
y = np.dot(x, w) + b # np.dot是求内积的意思
return y
def gradient_descent(self, x_train, y_label):
"""梯度下降法"""
flag = False # 模型是否全部预测正确
while not flag:
wrong_num = 0 # 计算预测错误的样本数
for i in range(len(x_train)):
x = x_train[i] # 取出样本点的特征值
y = y_label[i] # 取出样本点对应的标签
# 如果判断错误(文章中提到了判断的式子)就进行梯度更新
if -y * self.sign(x, self.w, self.b) > 0:
self.w = self.w + self.lrate * np.dot(y, x) # 更新w
self.b = self.b + self.lrate * y # 更新b
print(f"参数w:{self.w}, 参数b:{self.b}")
wrong_num += 1 # 误分类数加1
# 预测错误数为0,说明模型全部预测正确,结束梯度更新
if wrong_num == 0:
flag = True
return self.w, self.b # 返回参数和偏置
perceptron = PerceptronModel()
perceptron.gradient_descent(x, y)📝5 总结
感知机通过构造超平面的形式划分不同形式的点(二分类)
感知机属于线性判别模型
函数间隔与几何间隔的区别(感知机是误分类驱动,所以两者都可以用)
💗6 写在最后
初学一门知识的时候,心中总会产生许多的疑惑的。我们往往会因此而陷进去,去思考这个问题是否可以用那个方法解决,是不是有更好的思路。但其实,这都是因为我们书读的太少而想得太多。我们对于这个领域知之甚少,很多的问题其实别人已经思考过、解决过了。所以,对于一个小白来说,最重要的不是钻牛角尖,死扣,而是要广泛的阅读,无论是博客还是论文、视频讲解也好,都可以。尽可能的充实自己,以前的困惑自然就会消失了。















 1545
1545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











