







目录
残差网络(ResNet)
只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。
残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
残差块

残差映射在现实中往往更容易优化。在残差块中,输入可以通过跨层数据线路更块的向前传播。
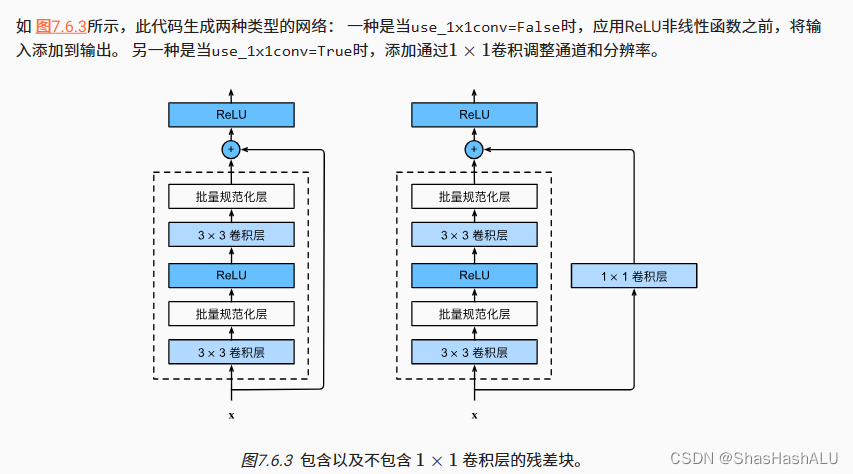
ResNet沿用了VGG完整的3x3卷积层设计,在残差块里现有两个有相同输出通道数的3x3卷积层。然后每个卷积层之后接着一个批量规范化层和ReLUctant激活函数。
我们可以通过跨层数据通道,跳过这两个卷积运算,将输入直接加在最后。可以用一个额外的1x1卷积层来将输入变换成需要的形状后再做相加运算。
残差块代码实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)ResNet模型
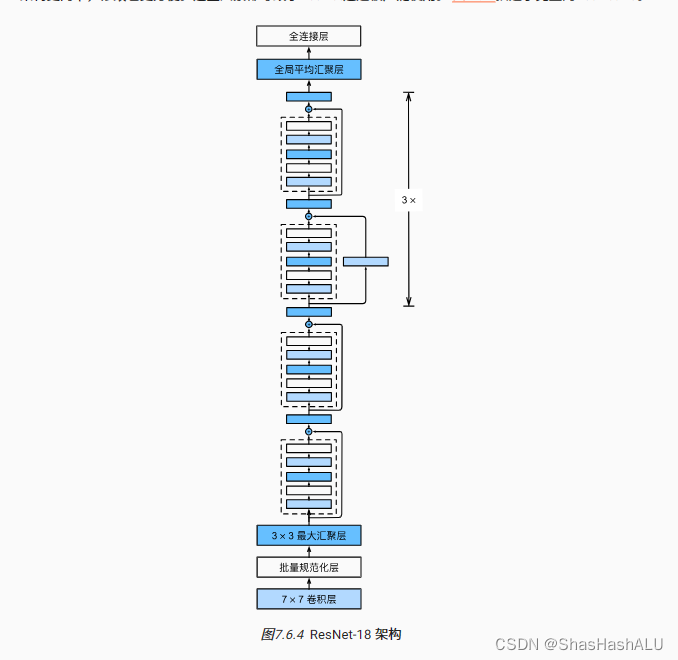
ResNet的前两层和GoogLeNet中的一样:在输出通道数为64、步幅为2的7x7卷积层后,接步幅为2的3x3最大汇聚层。不同之处就在于ResNet每个卷积层后增加了批量规范化层。
GoogLeNet在后面接了4个Inception块组成的模块,ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数和输入通道数一致。由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍并将高和宽减半。
最后和GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
(每个块不加上1x1卷积层,有四个卷积层,加上第一个7x7卷积层和最后一个全连接层,一共有18层,ResNet-18)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))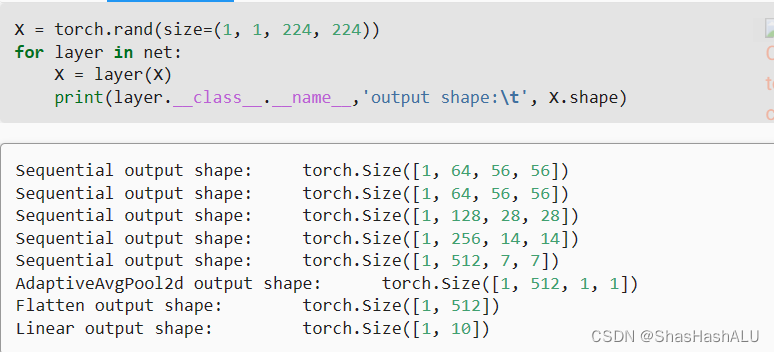
总结
残差映射可以更容易地学习同意函数,例如将权重层中的参数近似为0.
利用残差块可以训练出一个有效的深层神经网络:输入可以通过层间的参与连接更快的向前传播
稠密连接网络(DenseNet)
稠密连接网络在某种方面上来说是ResNet的逻辑扩展。

一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道。
然而,在前向传播中,我们将每个卷积块的输入和输出在通道维上连接。
import torch
from torch import nn
from d2l import torch as d2l
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输入和输出
X = torch.cat((X, Y), dim=1)
return X过渡层
每个稠密块会带来通道数的增加,过多就会导致过于复杂化模型。
过渡层可以用来控制模型复杂度,通过1x1卷积层来减小通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度。
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))DenseNet模型
DenseNet首先使用和ResNet一样的单卷积层和最大化汇聚层
然后使用4个稠密块。在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,DenseNet则使用过渡层来减半高和宽,并减半通道数。
与ResNet类似,最后接上全局汇聚层和全连接层来输出结果。
b1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# num_channels为当前的通道数
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
# 上一个稠密块的输出通道数
num_channels += num_convs * growth_rate
# 在稠密块之间添加一个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
net = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 10))总结
在跨层连接上,不同于ResNet中将输入与输出相加,稠密连接网络(DenseNet)在通道维上连结输入与输出。需要通过添加过渡层来控制网络的维数,从而再次减少通道的数量。
















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











