







目录
9.8. 束搜索 — 动手学深度学习 2.0.0 documentation (d2l.ai)
门控循环单元(GRU)
门控循环单元支持隐状态的门控,意味着模型有专门的机制来确定应该何时更新隐状态,以及何时重置隐状态
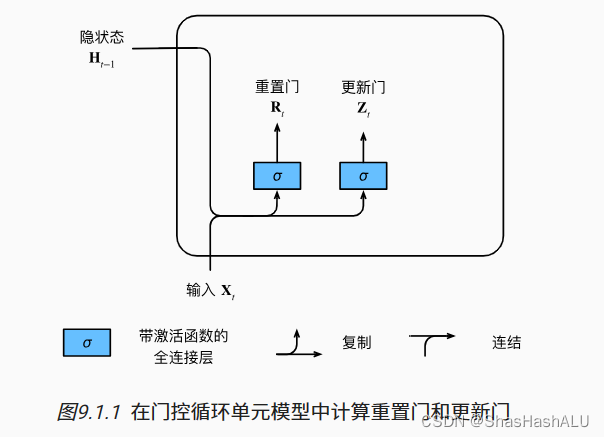
重置门和更新门
重置门可以控制什么时候进行重置,可以控制过去状态的数量
更新门可以控制我们的新状态中有多少个是旧状态的副本
输入是由当前时间步的输入和前一时间步的隐状态给出。 两个门的输出是由使用sigmoid激活函数的两个全连接层给出。
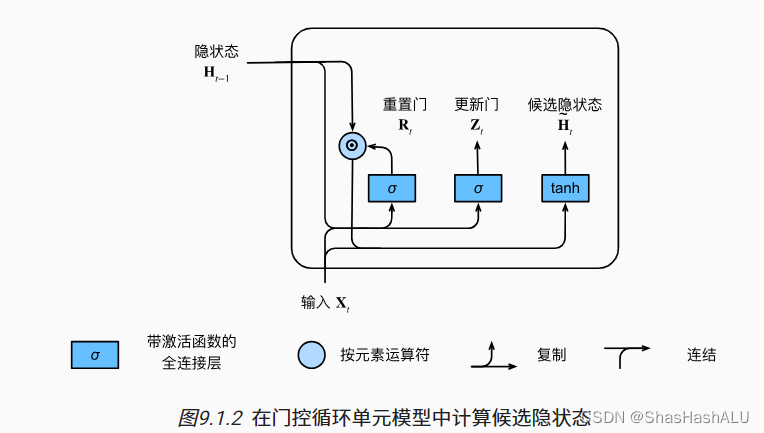
候选隐状态
重置门中的常规隐状态更新机制集成,得到在时间步t的候选隐状态
隐状态
更新门确定新的隐状态在多大程度上来自旧的状态Ht-1和新的候选状态Ht。

总结
重置门有助于捕获序列中的短期依赖关系
更新门有助于捕获序列中的长期依赖关系
长短期记忆网络(LSTM)
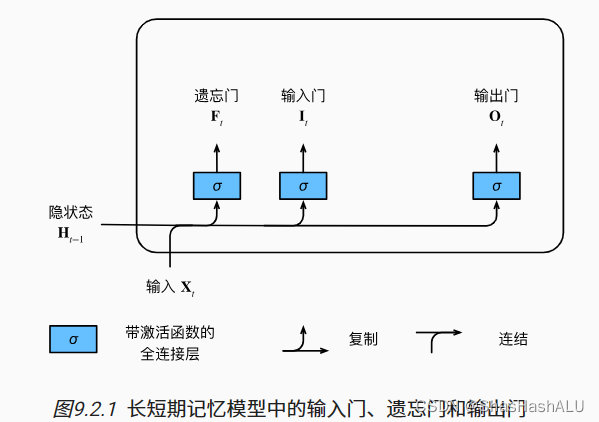
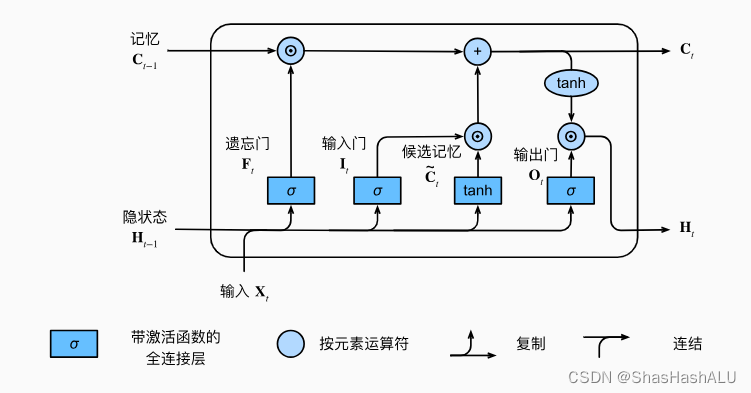
如同在门控循环单元一样,当前时间步的输入和前一个时间步的隐状态 作为数据输入长短期记忆网络的门中,它们由三个具有sigmoid 激活函数的全连接层处理,用来计算输入门、遗忘门、输出门的值。
记忆元
输入门控制采用多少来自记忆元的新数据,遗忘门控制保留多少记忆元的内容
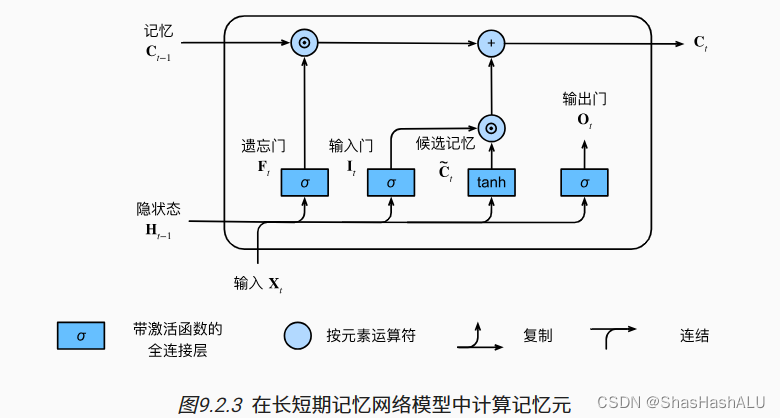
隐状态
隐状态在LSTM当中仅仅是记忆元的tanh的门控版本
只要输出门接近1,我们就可以有效的将所有记忆信息传递给预测部分,而对于输出门接近0,我们只保留记忆元内的所有信息而不需要更新隐状态Ht
代码实现
加载数据集
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)初始化模型参数
按照标准差0.01的高斯分布初始化权重,并将偏置项设置为0.
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params定义模型
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)代码简洁实现
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)总结
长短期记忆网络的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
长短期记忆网络可以缓解梯度消失和梯度爆炸。
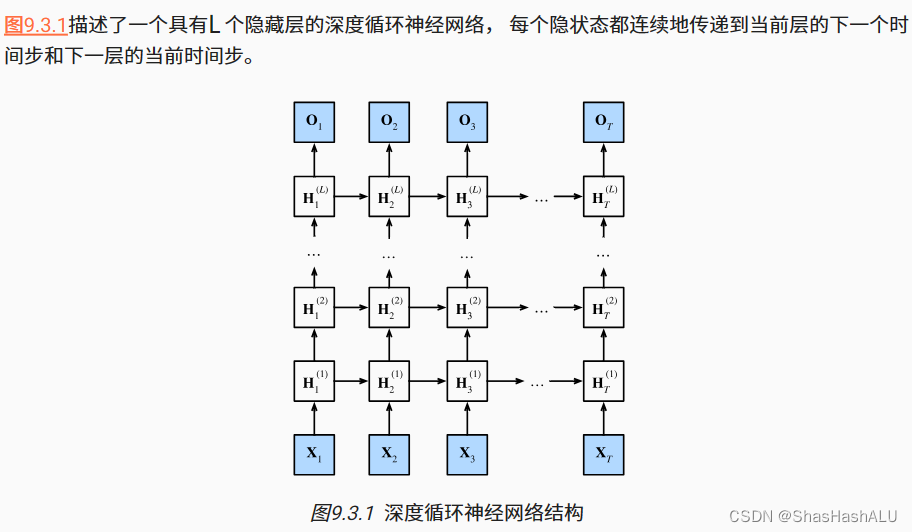
深度循环神经网络
将多层循环神经网络堆叠在一起,通过 对几个简单层的组合,产生一个灵活的机制。
代码的简洁实现
加载数据集
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)设置参数
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)总结
在深度循环神经网络中,隐状态的信息被传递到当前层的下一时间步和下一层的当前时间步。
深度循环神经网络需要大量的调参(学习率和修剪)来确保合适的收敛。
双向循环神经网络
双向循环神经网络的一个关键特性:使用来自序列两端的信息来估计输出。也就是说我们使用来自过去和未来的观测信息来预测当前的观测。
但是双向循环神经网络的计算速度非常的慢,其主要原因就是网络的前向传播需要在双向层中进行前向和后向递归,并且网络的反向传播还依赖于前向传播的结果。因此梯度求解将有一个非常长的链。

总结
在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
主要用于序列编码和给定双向上下文的观测估计。
序列到序列学习
循环神经网络编码器使用长度可变的序列作为输入,将其转换为股东形状的隐状态。
也就是说,输入的序列信息被编码到循环神经网络编码器的隐状态中,为了连续生成输出序列的词元,独立的循环神经网络解码器是基于输入序列的编码信息和输出序列已经看见的或者生成的词元来预测下一个词元。
编码器
编码器将长度可以变的输入序列转换成 形状固定的上下文变量C,并且将输入序列的信息在该上下文中进行编码。
目前为止,使用的是一个单向循环神经网络来设计编码器,其中隐状态只依赖于输入子序列
也可以使用双向循环神经网络构造编码器, 其中隐状态依赖于两个输入子序列,因此隐状态对整个序列的信息都进行了编码。
解码器
解码器输出y的概率取决于先前的输出子序列和编码器输出的上下文变量C。
在获得解码器的隐状态之后, 我们可以使用输出层和softmax操作 来计算在时间步t时输出y的条件概率分布

















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











