






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
数据包含取自模拟流程示例的二维数据集。此数据用于训练和测试内核 PCA 以进行故障检测。训练后,针对输出数据空间中的每个位置计算广泛用于故障检测的T2和Q统计指标,从而生成等高线图。然后将 2% 显著性水平检测限叠加在地图上,作为数据空间的正常(绿色)和错误(洋红色)区域之间的边界。
使用等高线图,可以将各种核类型和参数选择对正常和错误过程状态之间的决策边界的影响可视化。
基于核主成分分析(KPCA)的故障检测方法是一种有效的非线性方法,可以处理复杂系统中的故障检测问题。KPCA通过将数据映射到高维特征空间,然后在高维空间中进行主成分分析,从而捕捉数据的非线性结构。在故障检测中,通常使用T²统计量和Q统计量(也称为SPE,Squared Prediction Error)来检测异常。下面是KPCA故障检测中T²和Q统计量的计算与可视化步骤。
1. KPCA的基本步骤
1. **数据预处理**:对输入数据进行标准化处理。
2. **核函数选择**:常用的核函数包括高斯核、多项式核等。
3. **计算核矩阵**:通过核函数计算数据之间的相似性。
4. **中心化核矩阵**:去除核矩阵中的均值。
5. **特征值分解**:对中心化后的核矩阵进行特征值分解。
6. **主成分选择**:选择前k个主成分构建低维子空间。
2. T²统计量和Q统计量的计算
**T²统计量**:
\[ T^2 = \sum_{i=1}^k \left(\frac{z_i}{\lambda_i}\right)^2 \]
其中,\(z_i\)为第i个主成分得分,\(\lambda_i\)为对应的特征值,k为所选主成分的数量。
**Q统计量**:
\[ Q = \sum_{i=k+1}^n z_i^2 \]
其中,n为所有特征值的数量。
### 3. 可视化T²统计量和Q统计量
为了便于故障检测,可以将T²统计量和Q统计量可视化。通常可以采用控制图的形式,分别绘制T²统计量和Q统计量随时间的变化,并设置控制限(阈值)来判断是否存在异常。下面是一个示例代码,演示如何计算和可视化T²和Q统计量:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import KernelPCA
from scipy.stats import chi2
# 生成示例数据
np.random.seed(42)
X = np.random.normal(size=(100, 5))
# 标准化数据
X_mean = np.mean(X, axis=0)
X_std = np.std(X, axis=0)
X_scaled = (X - X_mean) / X_std
# KPCA分析
kpca = KernelPCA(kernel='rbf', gamma=15, fit_inverse_transform=True)
X_kpca = kpca.fit_transform(X_scaled)
# 计算T²统计量
lambdas = np.var(X_kpca, axis=0)
T2 = np.sum((X_kpca / lambdas)**2, axis=1)
# 计算Q统计量
X_reconstructed = kpca.inverse_transform(X_kpca)
Q = np.sum((X_scaled - X_reconstructed)**2, axis=1)
# 设置控制限
alpha = 0.99 # 置信水平
T2_limit = chi2.ppf(alpha, df=len(lambdas))
Q_limit = np.percentile(Q, 100 * alpha)
# 可视化
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(T2, label='T² Statistic')
plt.axhline(y=T2_limit, color='r', linestyle='--', label='Control Limit')
plt.title('T² Statistic Control Chart')
plt.xlabel('Sample Index')
plt.ylabel('T²')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(Q, label='Q Statistic')
plt.axhline(y=Q_limit, color='r', linestyle='--', label='Control Limit')
plt.title('Q Statistic Control Chart')
plt.xlabel('Sample Index')
plt.ylabel('Q')
plt.legend()
plt.tight_layout()
plt.show()4. 结果分析
通过上述代码,可以得到T²统计量和Q统计量的控制图。如果某个样本点的T²或Q值超过了对应的控制限,则可以认为该样本点可能存在故障或异常情况。
总结
基于KPCA的故障检测方法通过捕捉数据的非线性结构,可以有效地检测复杂系统中的故障。通过T²统计量和Q统计量的可视化,可以直观地识别异常数据点,从而实现故障检测。
📚2 运行结果
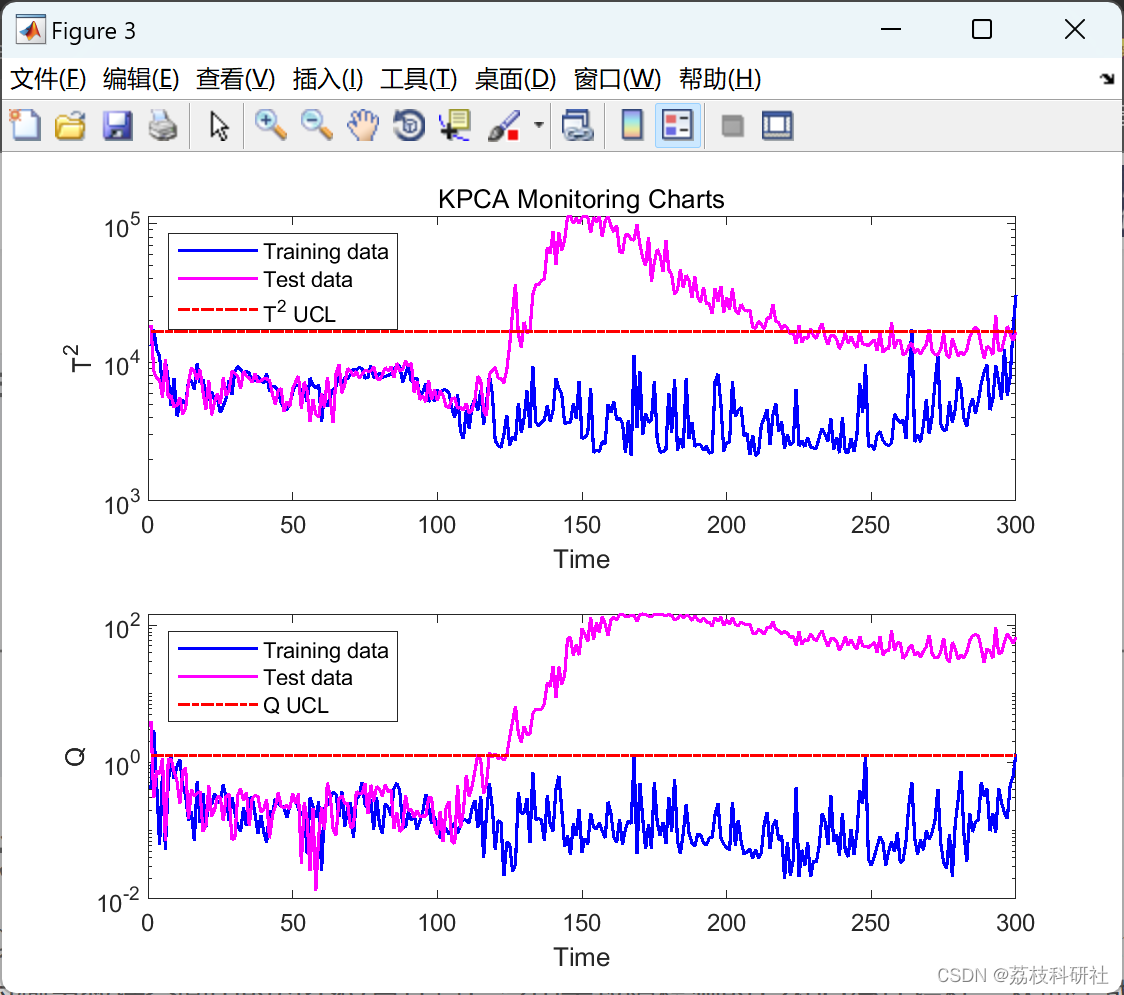


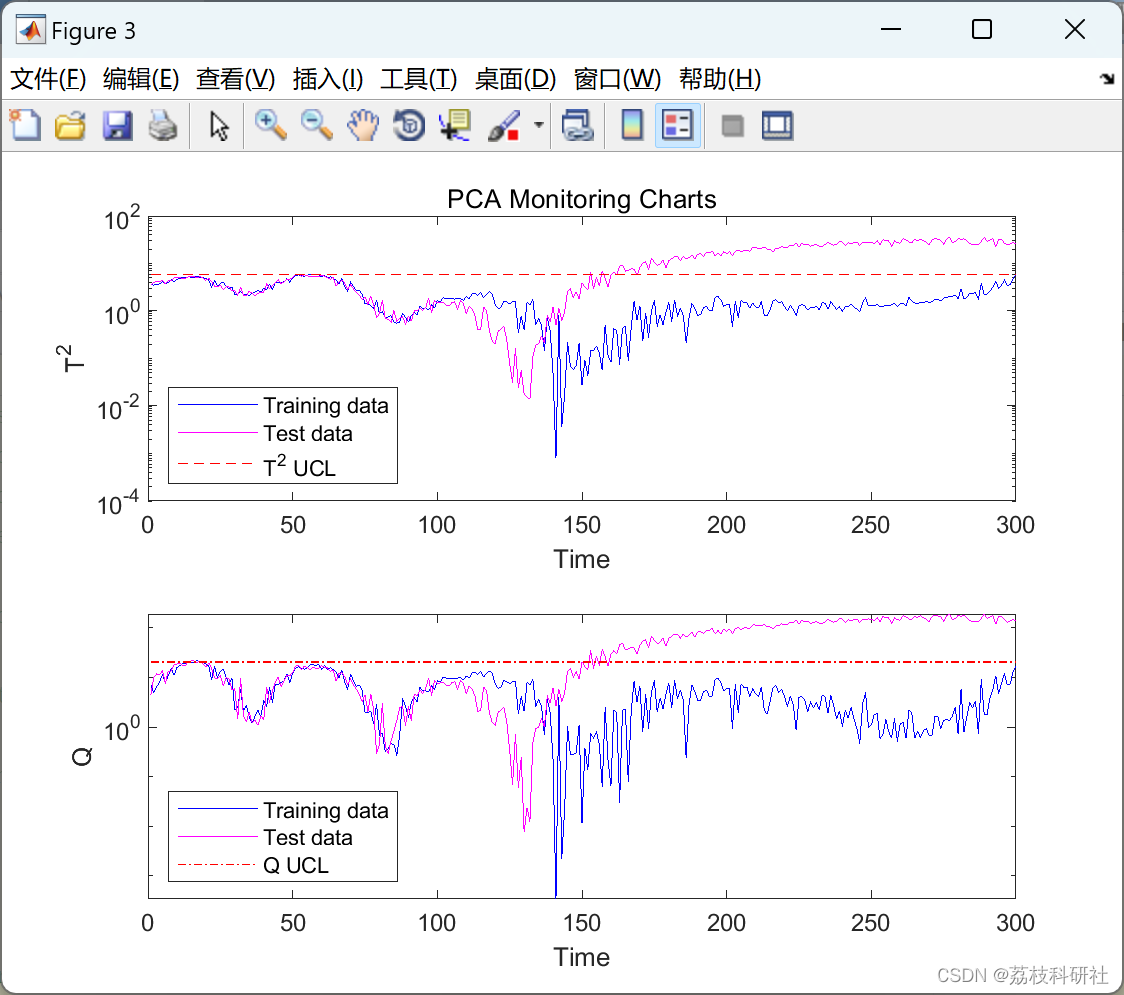

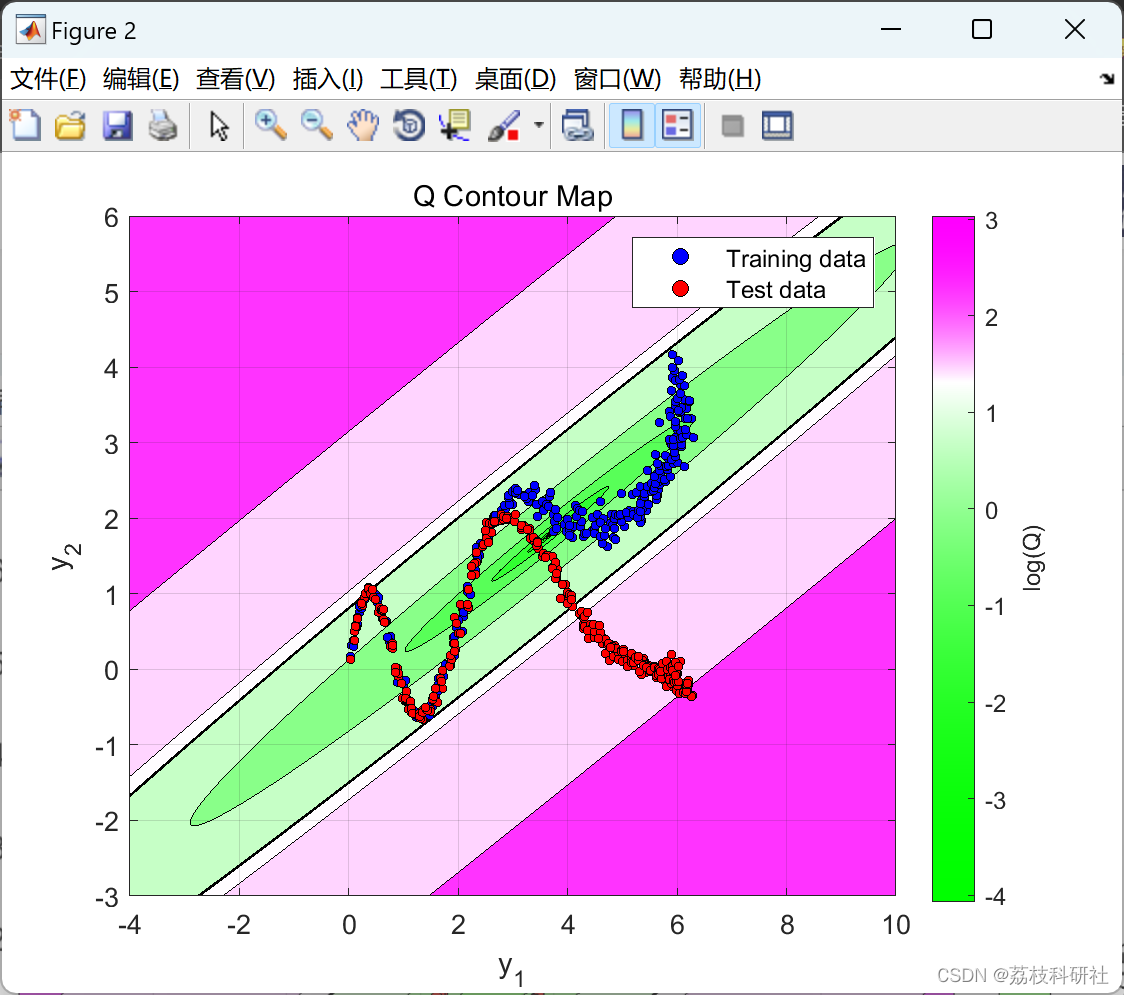
部分代码:
%% Get 2D data
close all; clc; tic;
if nargin == 0
load dataset.mat p;
train = p{1}; test = p{2};
% Kernel types and parameters:
ktype = 'rbf'; kpar = 1; % RBF kernel
%ktype = 'rbf'; kpar = 10; % RBF kernel
%ktype = 'rbf'; kpar = 0.9; % RBF kernel
%ktype = 'rbfpoly'; kpar = [1 1 0.65]; % mixed kernel
%ktype = 'poly'; kpar = 2; % polynomial kernel
%ktype = 'imquad'; kpar = 10; % inverse multiquadric kernel
%ktype = 'cauchy'; kpar = 5; % Cauchy kernel
end
%lax = [-15 15 -15 15];
lax = [-4 10 -3 6]; % Axes limits
N = length(train); M = length(test);
z0T = train; z1T = test; % Training and Test data
[xx,yy] = meshgrid(lax(1):0.05:lax(2),... % Meshgrid for contours
lax(3):0.05:lax(4));
z2T = [xx(:) yy(:)]; L = length(z2T); % Vectorize meshgrid points
K.type = ktype; K.p = kpar; % Kernel type and parameters
set(0,'defaultfigurecolor',[1 1 1]); % Set fig color to w
conf = 0.99; % Significance level (*100%)
% Normalize 2D Data
zm = mean(z0T); zs = std(z0T);
z0 = (z0T - zm(ones(N,1),:))./zs(ones(N,1),:); % Normalize training z
z1 = (z1T - zm(ones(N,1),:))./zs(ones(M,1),:); % Normalize test z
z2 = (z2T - zm(ones(L,1),:))./zs(ones(L,1),:); % Normalize surf z
%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% KERNEL PRINCIPAL COMPONENTS ANALYSIS %
[K0c,K0,U0] = kerneltrain(z0,K); % Populate kernel matrix
K1c = kerneltest(z1,z0,K0,U0,K); % Project test data to RKHS
K2c = kerneltest(z2,z0,K0,U0,K); % Project surf data to RKHS
[V,D] = eig(K0c/N); % Eigenvalue decomposition
[S,sj] = sort(diag(D),'descend'); % Sort eigenvalues
V = V(:,sj); S = S'; % Re-arrange eigenvectors
S(S < 1e-7) = []; % Remove eigenvalues <= 0
P = V(:,1:length(S))*diag(S.^-0.5); % Projection matrix
if ~isreal(S)
disp('Complex eigenvalues detected.'); % Warn about complex eigs
end
%% Perform KPCA Monitoring
CS = cumsum(S)/sum(S)*100;
RP = find(CS >= 99.9,1); % Get eigenvalues by %CPV
disp([num2str(RP) ' principal'...
' components chosen.']);
t0 = K0c*P(:,1:RP); % Kernel subspace (train)
t1 = K1c*P(:,1:RP); % Kernel subspace (test)
t2 = K2c*P(:,1:RP); % Kernel subspace (surf)
T2 = sum((t0.^2)./S(ones(N,1),1:RP),2); % T2 statistics (train)
t0n = K0c*P; % Full kernel space
Q = abs(sum(t0n.^2,2) - sum(t0.^2,2)); % Q statistics (train)
if strcmp(ktype,'rbf') == 1
fprintf('\n At infinite fault magnitude:\n');
U1 = ones(1,N)/N;
tt = U1*K0*(U0 - eye(N))*P(:,1:RP);
fprintf(' T2 limit: %.2f\n',...
sum((tt.^2)./S(1:RP),2)); % Limit of T2 for RBF
tu = U1*K0*(U0 - eye(N))*P;
fprintf(' Q limit: %.2f\n\n',...
abs(sum(tu.^2,2) - sum(tt.^2,2))); % Limit of Q for RBF
end
T2t = sum((t1.^2)./S(ones(M,1),1:RP),2); % T2 statistics (test)
T2u = sum((t2.^2)./S(ones(L,1),1:RP),2); % T2 statistics (surf)
t1n = K1c*P; t2n = K2c*P;
Qt = abs(sum(t1n.^2,2) - sum(t1.^2,2)); % Q statistics (test)
Qu = abs(sum(t2n.^2,2) - sum(t2.^2,2)); % Q statistics (surf)
%% Plot monitoring charts
figure(3); subplot(211);
semilogy(1:N,T2,'b',1:M,T2t,'m','linewidth',1.2); % T2 monitoring chart
xlabel('Time'); ylabel('T^2'); subplot(212);
semilogy(1:N,Q,'b',1:M,Qt,'m','linewidth',1.2); % Q monitoring chart
xlabel('Time'); ylabel('Q');
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1] K.E.S. Pilario, Y. Cao, and M. Shafiee. Mixed Kernel Canonical Variate Dissimilarity Analysis for Incipient Fault Monitoring in Nonlinear Dynamic Processes. Comput. and Chem. Eng., 123, 143-154. 2019. doi: 10.1016/j.compchemeng.2018.12.027















 4013
4013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









