






各位同学大家好,欢迎来到动手学AI专栏。
本篇文章是第二部分第二节——主流卷积神经网络。
那由于主流的卷积神经网络呢实在是太多了,所以我打算也是分成了上下两节给大家去介绍。
干货满满,希望大家点赞关注一下呗~~~~
那我们正式开始
在当今的人工智能领域,卷积神经网络(Convolutional Neural Networks,CNN)无疑占据着举足轻重的地位。从图像识别到目标检测,从语音处理到自然语言处理的部分任务,CNN 都展现出了卓越的性能。随着技术的不断发展,现代卷积神经网络在架构设计、训练方法和应用范围上都有了极大的突破。
那么我们本篇文章,将会给大家详细介绍几种具有代表性的现代卷积神经网络,包括它们的原理、代码示例以及优缺点分析。
一、卷积神经网络基础回顾
在深入探讨现代卷积神经网络之前,让我们先简要回顾一下卷积神经网络的基本概念。卷积神经网络的核心在于卷积层,它通过卷积核在输入数据上滑动进行卷积操作,提取数据的局部特征。这种局部感知的特性使得 CNN 能够有效减少参数数量,降低计算复杂度,同时保留数据的空间结构信息。
例如,对于一张图像,卷积核可以捕捉到图像中的边缘、纹理等基本特征。池化层则通常紧随卷积层之后,它通过对局部区域进行下采样(如最大池化、平均池化),进一步减少数据的维度,同时增强特征的鲁棒性。全连接层则用于对提取到的特征进行分类或回归等任务。
OK,那我们接下来就为大家介绍几种常见的主流卷积神经网络。
二、AlexNet:开启现代卷积神经网络的大门
(一)原理
AlexNet 是 2012 年 ImageNet 图像识别大赛的冠军模型,它的出现彻底改变了深度学习的格局。AlexNet 由 5 个卷积层和 3 个全连接层组成。
网络结构如下图所示:
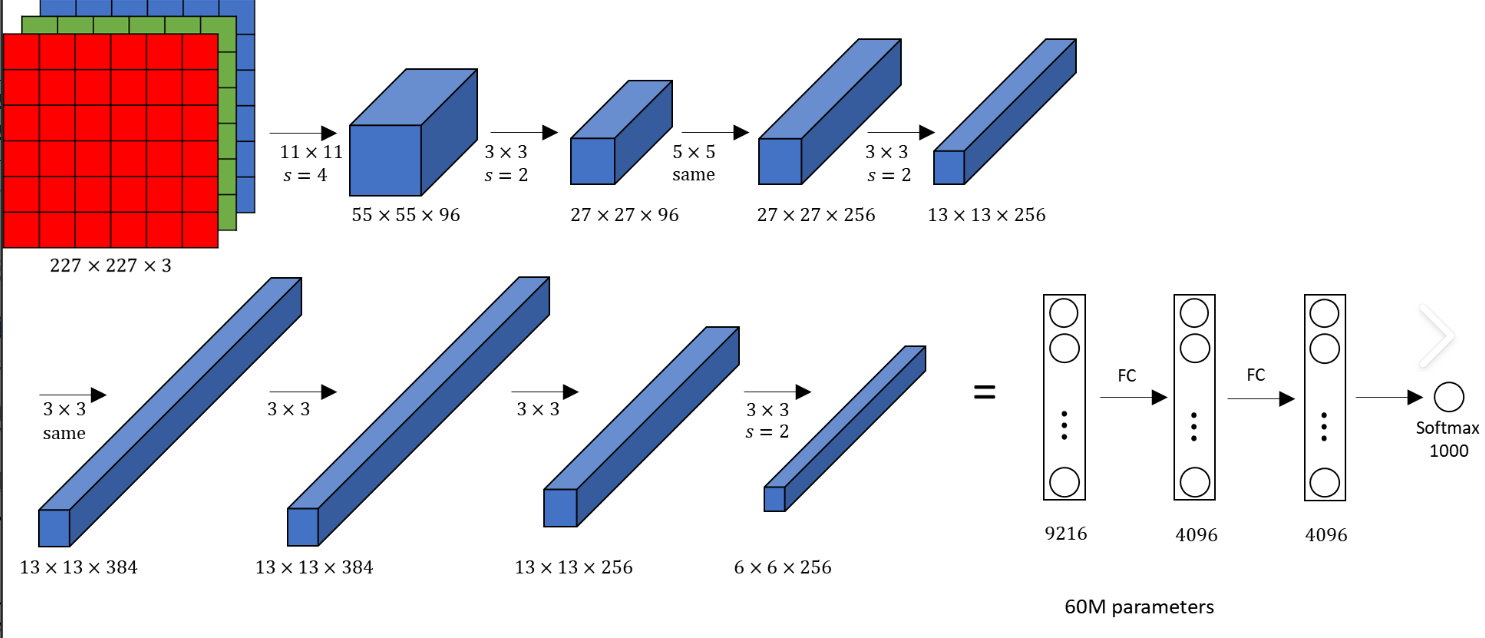
其主要创新点包括:
-
使用 ReLU 激活函数:传统的 sigmoid 或 tanh 激活函数在训练过程中容易出现梯度消失问题,而 ReLU(Rectified Linear Unit)函数 f(x)=max(0,x)f(x)=max(0,x) 能够有效解决这一问题,加快模型的收敛速度。
-
数据增强:通过对训练图像进行随机裁剪、翻转等操作,增加数据的多样性,防止模型过拟合。
-
Dropout 正则化:在全连接层中随机丢弃一部分神经元,减少神经元之间的共适应性,进一步防止过拟合。
-
可是使用多 GPU 训练:利用多个 GPU 并行计算,加速模型的训练过程。
(二)代码示例(使用 PyTorch)
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
(三)优缺点
- 优点
-
强大的特征提取能力:能够学习到图像中丰富的语义特征,在图像分类任务上取得了巨大的成功,显著超越了传统方法。
-
推动深度学习发展:为后续的卷积神经网络架构设计提供了重要的参考和启示,开启了深度学习在计算机视觉领域大规模应用的先河。
-
- 缺点
-
计算资源需求高:由于模型结构较大,在训练和推理过程中需要大量的计算资源,对硬件要求较高。
-
过拟合风险:尽管采用了数据增强和 Dropout 等技术,但在某些情况下仍可能出现过拟合现象,尤其是在训练数据量有限的情况下。
-
三、VGGNet:简洁而高效的网络架构
(一)原理
VGGNet 是 2014 年由牛津大学的视觉几何组(Visual Geometry Group)提出的。它的主要特点是采用了非常规整的网络结构,全部使用 3×33×3的小卷积核和 2×22×2 的最大池化层。通过堆叠多个这样的卷积层和池化层,VGGNet 构建了一个深度的网络。
模型结构示意图:
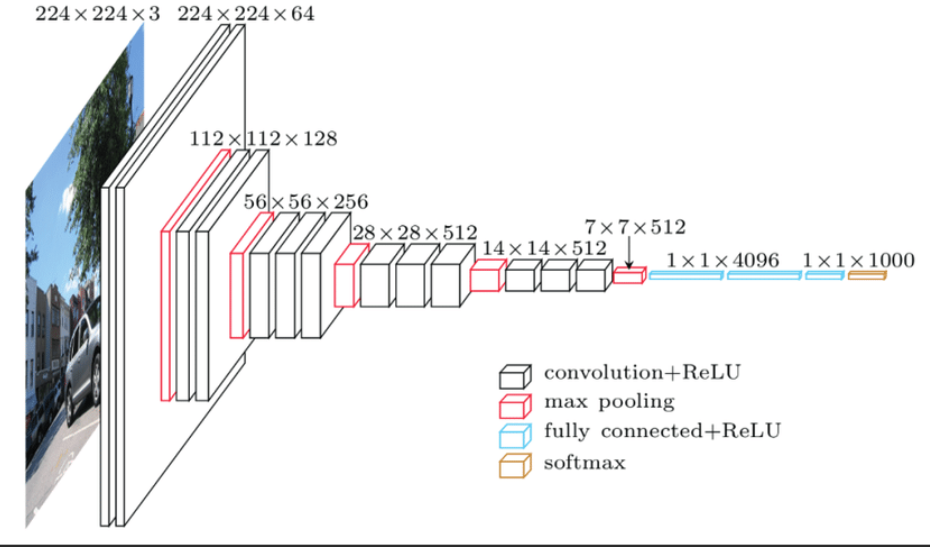
使用小卷积核的好处在于,多个 3×33×3的卷积核堆叠可以达到与大卷积核相同的感受野,同时减少了参数数量。例如,两个 3×33×3 的卷积核堆叠相当于一个 5×55×5 的卷积核的感受野,但参数数量从 5×5×Cin×Cout5×5×Cin×Cout 减少到 2×(3×3×Cin×Cout)2×(3×3×Cin×Cout) CinCin 和 CoutCout 分别是输入和输出通道数)。

















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









