






在OrangePi 5 Pro上访问NPU需要安装最新版Ubuntu的定制版本,还需要安装特殊软件,让你能在NPU 而不是CPU上运行专门转换的LLM。整个过程肯定要比运行Ollama 复杂得多,但如果你愿意迎接挑战,就能获得不菲的收益。所以,如果你感兴趣,就让我们深入了解一下吧!

安装操作系统
首先要安装合适的操作系统。我推荐 GitHub 用户Joshua Riek 专门为 Rockchip SoC 定制的 Ubuntu。你需要的是 24.04 版本,因为它拥有运行 LLM 所需的最新版 NPU 驱动程序。为 OrangePi在SD卡上刷新操作系统的方法与 Raspberry Pi 基本相同,以下是简要介绍:
1.将操作系统镜像下载到你选择的电脑上。
2.打开一个可以帮助闪存 SD 卡的程序。在本指南中,我们将使用 balenaEtcher。
3.选择 “从文件闪存”,然后选择之前下载的操作系统映像文件。
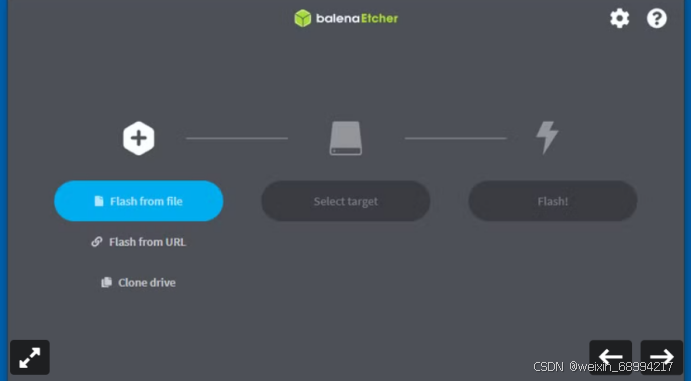
4.确保已插入 SD 卡,然后单击 “选择目标”。
5.从列表中选择 SD 卡,然后单击 “选择”。
6.选择 Flash!
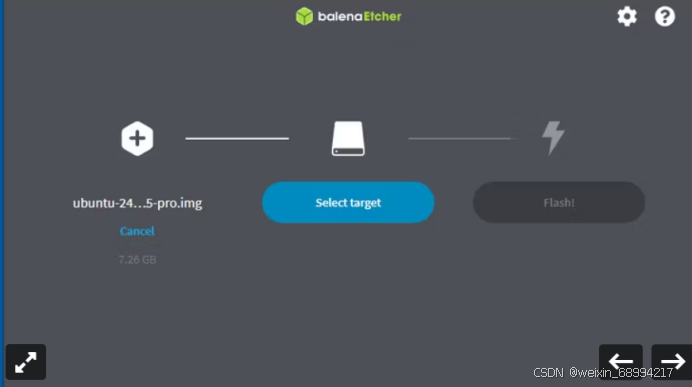
这个过程可能需要 10 分钟才能完成,所以在程序运行时请耐心等待。
成功闪存操作系统后,将 SD卡传输到你的 OrangePi 中,然后打开电源。确保你手边有键盘和显示器,因为我们需要直接访问我们的 SBC,至少需要足够长的时间来安装 SSH。
安装 SSH
在 OPi 上完成初始操作系统设置后,按 Ctrl + Alt + T 键打开终端,在终端中输入 sudo apt install openssh-server。这将允许你从另一台电脑访问你的 OrangePi。我们之所以要这么麻烦,是因为运行 LLM 的程序在桌面上无法运行,但在 SSH 终端上可以运行。

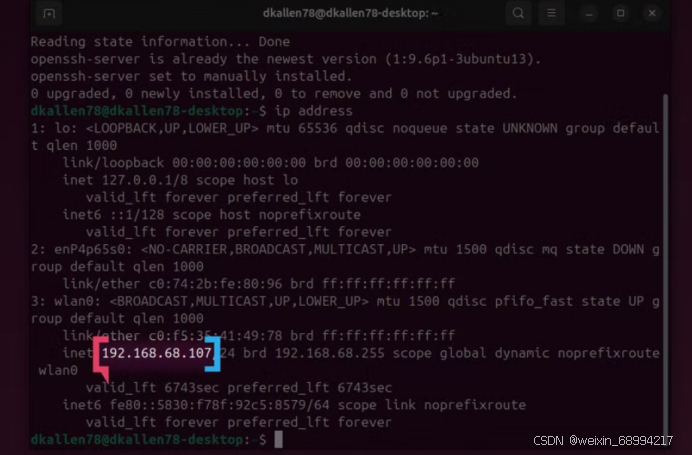
在离开你的 OrangePi 之前,记下它的 IP 地址,然后通过 SSH 登录。如果你不喜欢 SSH,也可以在你的设备上按照本指南操作,但你必须按 Ctrl + Alt + F5 退出桌面,只在 shell 中工作。
安装 RKNN LLM 和 RKNN 工具包 2
现在,我们可以开始安装运行 LLM 的软件了。RKNN LLM 是在我们的机器上运行 LLM 的程序。RKNN Toolkit 2 是让其他软件与 NPU 通信的软件。我们将使用 GitHub 用户 Pelochus 提供的脚本一次性安装这两个软件。在终端中输入:
sudo curl https://raw.githubusercontent.com/Pelochus/ezrknpu/main/install.sh | sudo bash
运行需要 5 到 10 分钟,请耐心等待。
安装 LLM
安装完 RKNN LLM 和 RKNN Toolkit 2 后,就可以安装模型了(这还需要 5 到 10 分钟)。为了让 LLM利用OrangePi 上Rockchip RK3588S SoC 的 NPU,需要使用 RKNN Toolkit 2 对其进行转换(这远远超出了本指南的范围)。
幸运的是,Pelochus 维护着一个可与 RK3588S 配合使用的 LLM 的 Hugging Face 资源库。遗憾的是,并非所有这些模型都与我们刚刚下载的软件兼容。您需要寻找已使用 RKLLM runtime 1.0.1 转换的模型。我们要安装的是微软的 Phi-3 Mini 型号,参数为 3.8B。在终端中输入以下命令:
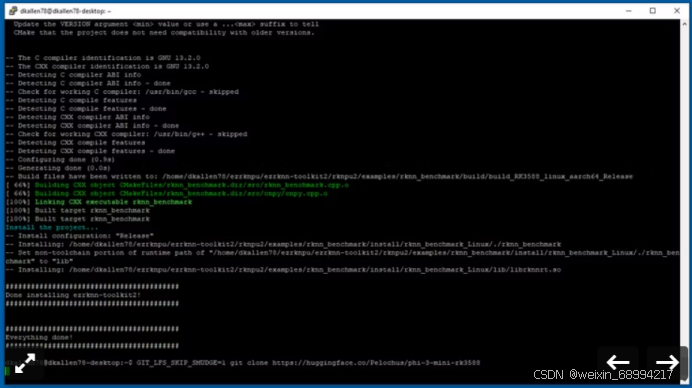
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Pelochus/phi-3-mini-rk3588
命令第一部分的大写字母将确保我们只先克隆较小的文件。如果我们试图一次性克隆整个版本库,可能会出现一些错误。接下来,导航到我们刚刚创建的新目录(cd ~/phi-3-mini-rk3588),然后运行 git lfs pull 命令。这将下载数千兆字节的大型模型文件。
在 OrangePi 5 Pro NPU 上运行 LLM
如果一切按计划进行,你就可以启动 LLM 了。在终端中输入 rkllm phi-3-mini-4k-rk3588.rkllm 即可。
运行情况如何?它比我们在超频的 Raspberry Pi 5 上通过 Ollama 运行的 Phi-3 要快得多。它的输出似乎也有硬性限制,如果达到极限,就会中途自断。
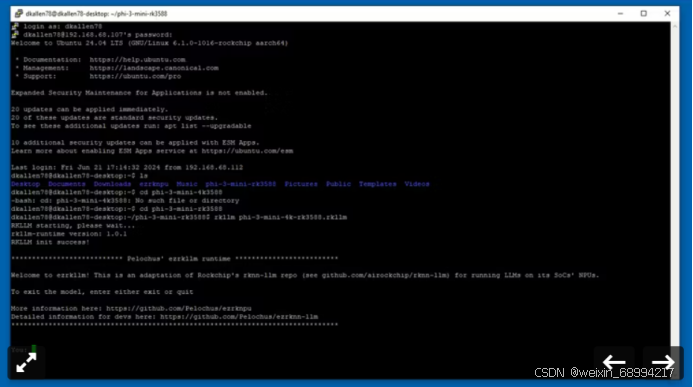
OrangePi上的NPU 驱动 LLM 在很大程度上仍处于试验阶段,但没想到响应速度是如此之快。在树莓派上运行的 Phi-3 平均响应时间为 27 秒,中位数为 5 秒(范围为 3-295 秒)。在OrangePi 5 Pro 的 NPU上运行的 Phi-3 均响应时间约为 1 秒,中位数在 1-2 秒之间。
如果你有一台配备 RK3588或RK3588S SoC的OrangePi 5,如果你喜欢尝试使用 LLM,那么这个项目绝对值得你花时间去做,哪怕只是为了大幅提高 LLM 的响应时间。支持 OrangePi 上 LLM 的社区规模虽小,但非常活跃,我期待看到更多型号不断涌现。

















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









