







引言
自然语言处理中的Transformer模型真正改变了我们处理文本数据的方式。Transformer是最近自然语言处理发展的幕后推手,包括Google的BERT(Bidirectional Encoder Representations from Transformers),来自Transformer的双向编码器表示。
Transformer是为了解决序列传导问题或神经网络机器翻译而设计的,意味着任何需要将输入序列转换为输出序列的任务都可以用,包括语音识别和文本到语音转换等。

序列传导。绿色表示输入,蓝色表示模型,紫色表示输出。
本文主要是讲解对于Transformer的工作原理、它如何与语言建模、序列到序列建模相关
先看下面一个段落:

标注高亮的单词指的是同一个人:Griezmann,一名受欢迎的足球运动员。对我们而言,要弄清楚文本中这些词之间的关系并不难。但对一台机器来说,这可就是一项相当艰巨的任务了。
翻译这样的句子,模型需要找出句子之间的依赖和关联。循环神经网络 (RNNs)和卷积神经网络(CNNs)由于其特性已被使用来解决这个问题
长期依赖的问题——补充知识点
考虑一下这类模型,即使用之前看到的单词预测下一个单词。如果我们需要预测这句话“the clouds in the ___”的下一个单词,不需要额外的语境信息,很显然下个单词是“sky”。
这个例子里,相关信息和需预测单词的距离很近。循环神经网络可以学习前面的信息,并找出句中下一个单词。
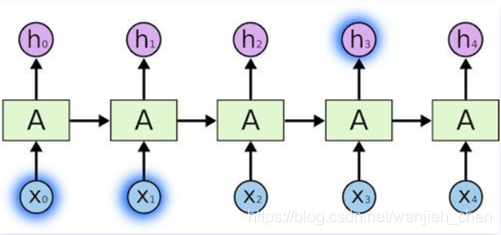
但有些情况我们需要更多语境信息。例如试图预测这句话的最后一个单词: “I grew up in France… I speak fluent ___”。 最靠近这个单词的信息建议这很有可能是一种语言,但当你想确定具体是哪种语言时,我们需要语境信息France,而这出现在较前面的文本中。
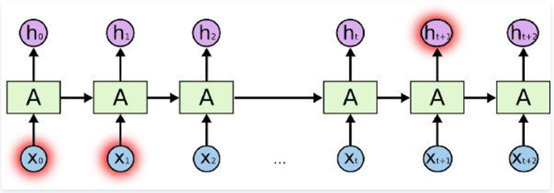
当相关信息和词语之间距离变得很大时,RNN变得非常低效。那是因为,需要翻译的信息经过运算中的每一步,传递链越长,信息就越可能在链中丢失。
理论上RNN可以学习这些长期依赖关系,不过实践表现不佳,学不到这些信息。因而出现了LSTM,一种特殊的RNN,试图解决这类问题
Long-Short Term Memory (LSTM)
我们平时安排日程时,通常会为不同的约会确定不同的优先级。如果有什么重要行程安排,我们通常会取消一些不那么重要的会议,去参加那些重要的。
RNN不会那么做。无论什么时候都会不断往后面加信息,它通过应用函数转换全部现有信息。在过程中所有信息都被修改了,它不去考虑哪些重要,哪些不重要。
LSTMs在此基础上利用乘法和加法做了一些小改进。在LSTMs里,信息流经一种机制称为细胞状态(cell state)。LSTM便可以选择性的记忆或遗忘那些重要或不重要的事情了。
LSTM内部结构:
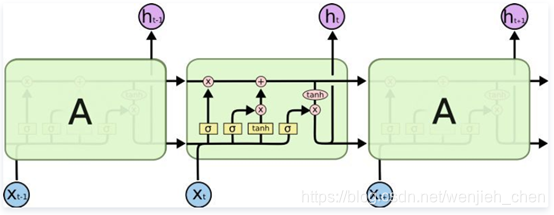
每个cell的输入为x_t (在句子到句子翻译这类应用中x_t是一个单词), 上一轮细胞状态以及上一轮的输出。模型基于这些输入计算改变其中信息,然后产生新的细胞状态和输出。本文不会详细讲每个细胞的实现机制。(关于LSTM详细的内容讲解、原理、推导……)
(推荐参考:https://zybuluo.com/hanbingtao/note/581764)
采用细胞状态(cell state)后,在翻译过程中,句子中对翻译单词重要的信息会被一轮一轮传递下去。
对机器理解自然语言来说,掌握句子中这些关系和单词序列至关重要。这就是 Transformer 概念发挥主要作用之处。
LSTM的问题
总体来说问题LSTM的问题与RNN一样,例如当句子过长LSTM也不能很好的工作。原因在于保持离当前单词较远的上下文的概率以距离的指数衰减。
那意味着当出现长句,模型通常会忘记序列中较远的内容。RNN与LSTM模型的另一个问题,由于不得不逐个单词处理,因此难以并行化处理句子。不仅如此,也没有长短范围依赖的模型。
总之,LSTM和RNN模型有三个问题:
- 顺序计算,不能有效并行化
- 没有显示的建模长短范围依赖
- 单词之间的距离是线性的
Attention
为了解决其中部分问题,研究者建立了一项能对特定单词产生注意力的技能。
当翻译一个句子,我会特别注意我当前正在翻译的单词。当我录制录音时,我会仔细聆听我正在写下的部分。如果你让我描述我所在的房间,当我这样做的时候,我会瞥一眼描述的物体。
神经网络用attention可以做到同样的效果,专注于给出信息的那部分。例如,RNN可注意另一RNN的输出。在每个时点它聚焦于其他RNN不同的位置。
为了解决这些问题,注意力(attention)是一种用于神经网络的技术。 对于RNN模型,与其只编码整个句子的隐状态,我们可以把每个单词的隐状态一起传给解码器阶段。在RNN的每个步骤使用隐藏状态进行解码。
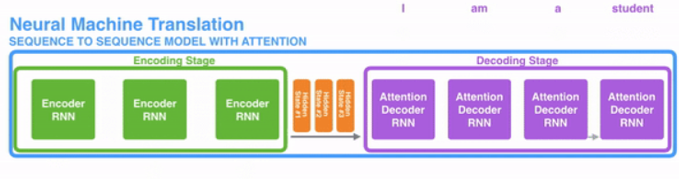
绿色步骤是编码阶段,紫色步骤是解码阶段
其背后的想法是句子每个单词都有相关信息。为了精确解码,需要用注意力机制考虑输入的每个单词。
对于要放入序列传导RNN模型的注意力,我们分成编码和解码两步。一步以绿色表示另一步以紫色表示。绿色步骤称为编码阶段紫色步骤称为解码阶段。
序列到序列模型(seq2seq model):背景
自然语言处理中的序列到序列模型(Sequence-to-sequence (seq2seq model))用于将A型序列转换为B型序列。例如,将英语句子翻译成德语句子就是一个序列到序列的任务。
自 2014 年推出以来,基于循环神经网络的序列到序列模型得到了很多人的关注。目前世界上的大多数数据都是以序列的形式存在的,它可以是数字序列、文本序列、视频帧序列或音频序列。
2015 年增加了注意力机制(Attention Mechanism),进一步提高了这些 seq2seq 模型的性能。
这些序列到序列模型用途非常广泛,可用于各种自然语言处理任务,例如:
机器翻译
文本摘要
语音识别
问答系统等等
基于循环神经网络的序列到序列模型
(RNN的基础知识补充,可以参考https://zybuluo.com/hanbingtao/note/541458)
让我们以一个简单的序列到序列模型为例,请看以下如图所示
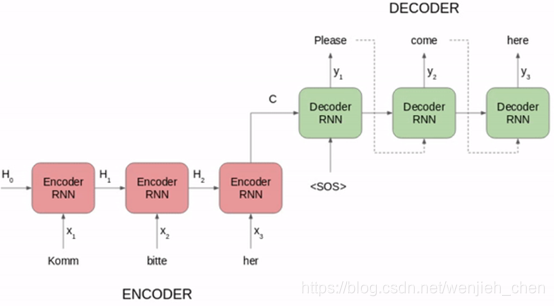
上图中的 seq2seq 模型将德语短语转换为英语短语。让我们把它分解一下:
编码器和解码器都是循环神经网络。
在编码器中的每个时间步骤,循环神经网络从输入序列获取词向量(xi),从前一个时间步骤中获取一个隐藏状态(Hi)。
隐藏状态在每个时间步骤中更新。
最后一个单元的隐藏状态称为语境矢量(context vector)。它包含有关输入序列的信息。
然后将该语境矢量传递给解码器,然后使用它生成目标序列(英文短语)。
如果我们使用注意力机制(Attention Mechanism),则隐藏状态的加权和将作为语境矢量传递给解码器。
挑战
尽管 seq2seq 模型非常出色,但也存在一定的局限性:
- 处理长期依赖仍然是一个挑战。
- 模型架构的顺序特性阻止了并行化。
这些挑战是通过 Google Brain 的 Transformer 概念得到解决的
Transformer 简介
自然语言处理中的 Transformer 是一种新颖的架构,旨在解决序列到序列的任务,同时轻松处理长期依赖(long-range dependencies)问题。Transformer 首次由论文(Attention Is All You Need)提出。下一篇博客将推出这篇论文的阅读总结。感兴趣的可以直接去阅读原文。
以下是论文引用:
“Transformer 是第一个完全依赖自注意力(self-attention)来计算输入和输出的表示,而不使用序列对齐的递归神经网络或卷积神经网络的转换模型。”
这里说的“转换”(transduction)是指将输入序列转换成输出序列。Transformer 背后的思想是使用注意力机制处理输入和输出之间的依赖关系,并且要完全递归。
让我们来看看 Transformer 的架构,它可能看上去令人生畏,但请别担心,我们会将其分解,一块块地来理解它。
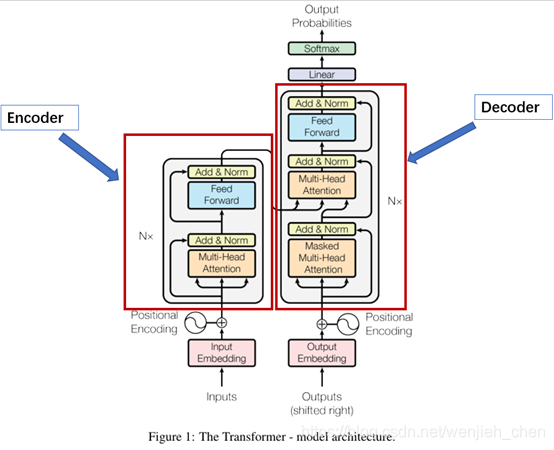
上图是Transformer的模型结构。首先,让我们只关注编码器和解码器的部分。现在,让我们观察下图。编码器块有一层 多头注意力(Multi-Head Attention),然后是另一层 前馈神经网络( Feed Forward Neural Network)。另一方面,解码器有一个额外的 掩模多头注意力(Masked Multi-Head Attention)。
编码器和解码器块实际上是相互堆叠在一起的多个相同的编码器和解码器。 编码器堆栈和解码器堆栈都具有相同数量的单元。编码器和解码器单元的数量是一个超参数。在本文中,我们使用了 6个编码器和解码器
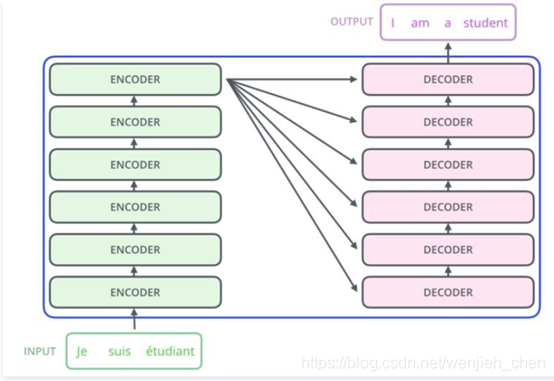
让我们看看编码器和解码器堆栈的设置是如何工作的:
将输入序列的词嵌入(word embeddings)传递给第一个编码器。
然后将它们进行转换并传播到下一个编码器。
编码器堆栈中最后一个编码器的输出将传递给解码器堆栈中所有的解码器,如下图所示:
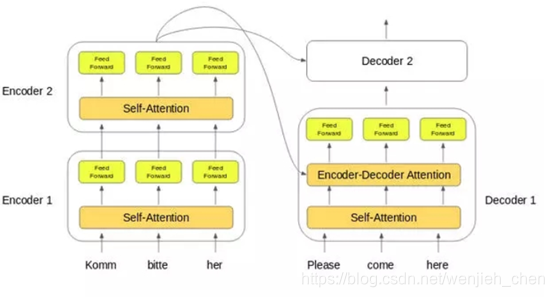
这里需要注意的一点是,除了自注意力和前馈层外,解码器还有一层解码器 - 解码器注意力层。这有助于解码器将注意力集中在输入序列的适当部分上。
你可能会想,这个“自注意力”层在 Transformer 中到底做了什么呢?问得好!这可以说是整个设置中最关键的部分,所以让我们来理解这个概念。
掌握自注意力的技巧
根据这篇论文所述:
“自注意力(self-attention),有时也称为内部注意力(intra-attention),是一种注意力机制,它将一个序列的不同位置联系起来,以计算出序列的表示形式。”

找出句中单词之间的关系并给出正确的注意力
请看上图。你能弄明白这句话中的“it”是指什么吗?
它指的是 street 还是 animal?这对我们来说是一个简单的问题,但对算法来说可不是这样的。当模型处理到“it”这个单词时,自注意力试图将“it”与同一句话中的“animal”联系起来。
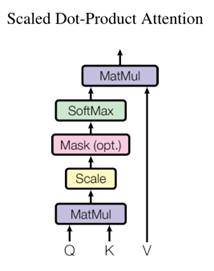
自注意力允许模型查看输入序列中的其他单词,以便更好地理解序列中的某个单词。现在,让我们看看如何计算自注意力。
计算自注意力(self-attention)
第一步:通过编码器的输入向量 (本例中是每个单词的词嵌入向量) 建立Query, Key和Value三个向量,我们通过输入的词嵌入向量乘以之前训练完成的三个矩阵(查询向量Wq、键向量Wk、值向量W^v)得到。
来看看这句话:“Action gets results”。为了计算第一个单词“Action”的自注意力,我们将计算短语中与“Action”相关的所有单词的得分。当我们在输入序列中编码某个单词时,该得分确定其他单词的重要性。
通过将查询向量(q1)的与所有单词的键向量(k1,k2,k3) 的点积来计算第一个单词的得分:
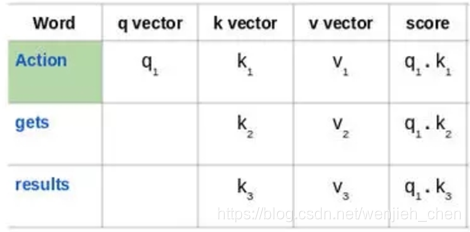
然后,将这些得分除以 8,也就是键向量维数的平方根:
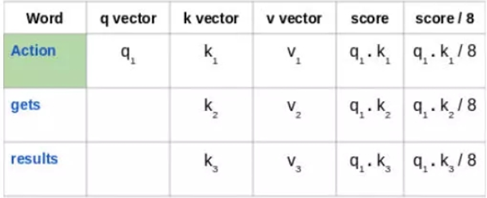
接下来,使用 softmax 激活函数对这些得分进行归一化:
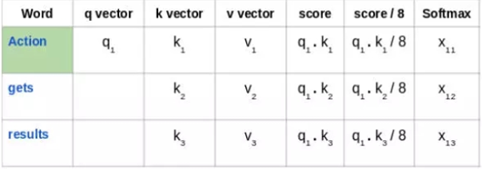
然后将这些经过归一化的得分乘以值向量(v1,v2,v3),并将得到的向量求和,得到最终向量(z1)。这是自注意力层的输出。然后将其作为输入传递给前馈网络:
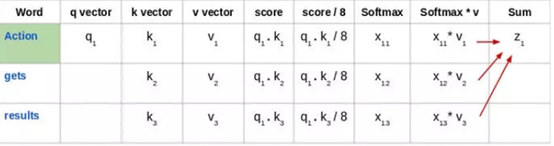
因此,z1 是输入序列“Action gets results”的第一个单词的自注意力向量。我们可以用同样的方式得到输入序列中其余单词的向量:
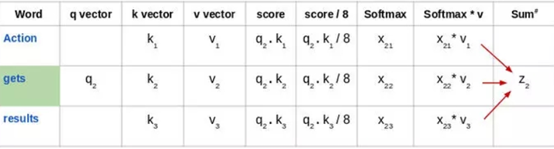
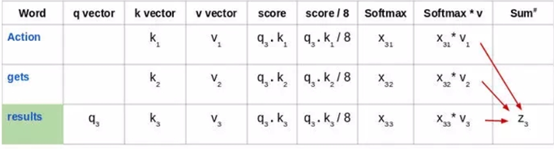
注意,这些新向量的长度小于词嵌入向量的长度。这里取64,而词嵌入向量及编码器的输入输出长度为512。这是一个架构性选择,向量长度不需要变得更小,使得多头注意力(multiheaded attention)计算基本稳定。
多头注意力(Multi-head attention)
在 Transformer 的架构中,自注意力并不是计算一次,而是进行多次计算,并且是并行且独立进行的。因此,它被称为 多头注意力。输出经过串联并进行线性转换,如下图所示。
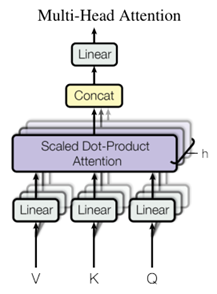
根据论文 Attention Is All You Need:
“多头注意力允许模型共同注意来自不同位置的不同表示子空间的信息。”
位置编码(Positional Encoding):
Transfomer的另一个重要步骤是为每个词增加了位置编码。由于每个单词的位置与翻译相关,所以编码每个单词的位置是有用的。
Transformer 的局限性
Transformer 无疑是对基于递归神经网络的 seq2seq 模型的巨大改进。
但它也有自身的局限性:
注意力只能处理固定长度的文本字符串。在输入系统之前,文本必须被分割成一定数量的段或块。
这种文本块会导致 上下文碎片化。例如,如果一个句子从中间分隔,那么大量的上下文就会丢失。换言之,在不考虑句子或任何其他语义边界的情况下对文本进行分隔。
那么,我们如何处理这些非常重要的问题呢?这就是使用过 Transformer 的人们提出的问题。由此催生了 Transformer-XL。
注明:本文假设读者对一些深度学习概念有基本的了解。
-
《深度学习要领:带注意力的序列到序列建模》(Essentials of Deep Learning – Sequence to Sequence modeling with Attention)
-
《深度学习基础:递归神经网络导论》(Fundamentals of Deep Learning – Introduction to Recurrent Neural Networks)
-
《Python 中使用深度学习的文本摘要综合指南》
-
(Comprehensive Guide to Text Summarization using Deep Learning in Python)
参考文献以及网页链接:
[1]. Vaswani A, Shazeer N, Parmar N, et al. Attention is All you Need[C]. neural information processing systems, 2017: 5998-6008.
[2]. 一文理解 Transformer 的工作原理
http://www.uml.org.cn/ai/201910314.asp
[3]. 多图带你读懂 Transformers 的工作原理
https://cloud.tencent.com/developer/article/1422884
[4]. Attention Is All You Need(Transformer)算法原理解析
https://www.cnblogs.com/huangyc/p/9813907.html














 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









