









论文:https://arxiv.org/abs/2010.11929
代码:GitHub - google-research/vision_transformer
ViT是transformer在CV领域的重要著作之一,将Transformer直接迁移到分类任务上,并且完全没有用到CNN,在分类任务中表现很好,尤其是大型训练集。下面聊聊ViT。
目录
一,选择怎样的Transformer网络及其变体作为ViT---(视觉分类任务)的初始结构?
整体结构
一,选择怎样的Transformer网络及其变体作为ViT---(视觉分类任务)的初始结构?
ViT希望把Transformer放到视觉分类上,但是用怎样的Transformer网络呢?
我们有必要先了解Transformer都有哪些经典变体。按照Transformer结构可以很直接的把这样的网络分为下面三大类:
1,第一类只有编码器,如大名鼎鼎的BERT。编码器网络就是堆叠若干层自注意力网络,所以适合于分类任务,比如nlp中的文本分类。
2,第二类只有解码器。解码器网络还是堆叠若干层自注意力网络(中间细节有不同),但是和编码器网络最大的不同是有mask,所以进行预测的词只能看到它前面的词,其他是看不到的, 所以适合于语言模型,即由前一个词生成后一个词。
3,第三类是编码器+解码器结构,如BART\switch transformer等。这就是Attention is all you need论文介绍的Transformer经典结构,在nlp中的主要应用是做机器翻译。

图片摘自:”A Tutorial of Transformers“ 邱锡鹏. 复旦大学
有了对Transformer变体的上述分析后直接就从应用属性可以套用了,视觉分类任务非常适合用”only编码器“这样的网络。
二,ViT的真实结构
1,从NLP用到的Transformer向CV迁移!
在nlp的Transformer中,输入是N x D,其中N是序列的长度,D是词/字的embedding。这个思想直接朝着2维图像迁移,那么N可以是图像块/像素的总个数,D可以是图像块/像素的embedding。
遵循上述思路,ViT将H x W x C的图像,变成一个flatten的2D pathches,可以看作是一系列展平的2D块序列,大小为,其中原始图像的大小是(H,W),通道是C。变化后的图像块个数为N,那么
。每个图像块的大小为(P,P), 通道还是C
关于ViT使用图像块而不是像素有两点原因:
1)图像块局部信息更丰富,无论是用CNN网络还是其他结构都可以从图像块中获取超越单个像素的信息
2) Transformer复杂度在第一节讲过,(其中self-attention结构的复杂度为O() 这也是 Transformer的一大应用缺陷,处理长序列复杂度太高。在CV中图像原始大小不变的情况下,用图像块比用像素N要小的多。
第一步:将H x W x C——>其中
代码是:

第二步,——>(N, D)
上面公式其实是完成了论文中的公式(1),公式中的E其实是完成了上面第二步的降维操作,
![]()
将维度转换为维度D可以直接使用全连接即可,具体的实现是:
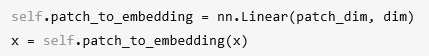
其中除了N是分块的总个数,公式1还加入了Xclass作为最终分类层需要使用的特征。公式1还加入了位置编码Epos,这里的位置编码不同于原始的Transformer不是固定的向量,是一个可学习的向量。此外,论文还对比了2D位置编码和1D的,差异不大。
2, ViT中的encoder前向
encoder的前向流程和Transformer中的encoder一模一样,

上述的公式1是刚才讲的第二步;
上述的公式2是multi-head self-attention + add and norm
上述的公式3是feed forward network + add and norm
相比原始的Transformer的encoder没有啥改动
注:需要说明的一点,不像CNN类的分类网络是在网络的最后层加一个全连接,得到输出的类别,在ViT中是将这个需要得到最终类别的特征从一开始就加了进去,就是下图Xclass
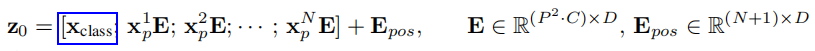
如上图所示,为什么要加在这里呢?我尝试解释下
1)完全参照CNN网络,干脆加在网络的最后输入是所有的encoder输出特征。这样做会有如下三个问题
问题1——维度高:那么这个输出特征的维度将会非常高!假设输入图像256x256,图像块16x16,那么N就是16,假设每个encoder输出维度是1000,那么concat起来就是16*1000。
问题2——不好迁移:N对于不同大小输入不同(参考后续”训练方式“预训练和微调的输入图像大小不同),那么这层weight完全没法用。
问题3——没有必要:CNN类的网络之所以要在后面加全连接是为了得到全局特征,流程是CNN-->pool-->fc,通过池化和fc才能将图像全局信息得到。但是~~~每个Transformer的自注意力就是为了得到全局特征,因此没有必要将每个小块的特征concat起来。
三,训练方法
先在大数据上预训练ViT模型,然后再在小的下游任务数据集上微调。大数据集上训练完成后移除MLP的预测head,换成一个全0初始化的DxK的前馈层,K是下游任务的类别数,D是encoder每层输出的特征维度大小,此外微调的时候使用大于预训练的图像分辨率效果更好,当图像分辨率更大的时候,使用相同的图像块大小,则序列的总长度更长,ViT可以处理任意长度的序列(上线是硬件的内存)但是预训练的位置编码也不再适用。因此对预训练得到的位置编码进行2D插值。
四,实验
几点实验结论。

1)预训练集越大模型效果越好,模型越大(层数越深,embeddIng维度越高)效果越好;

2)transformer对预训练集规模的苛刻程度:要想超过resnet50要30m量级的图像,要想超越resnet152需要100m量级的图像。

3)位置编码可以学到图像的位置信息,并且距离越近的图像块位置编码越接近

4)多头注意力部分head在网络浅层就可以学习到全局信息,并且随着网络加深 多头注意力都趋向于学习全局信息
















 8793
8793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











