







虽然国外模型的能力目前还领先4个月左右,但考虑安全性与响应速度等因素,在国内最好还是选择国内的模型。
不过,面对众多的大模型 : 如文心、豆包、通义等,市面上已经有好几百个国产大模型,如何挑选合适自己的模型就成为了一大难题。
同时,目前市场上关于大模型能力的排行榜种类繁多,不光有国外的各种模型评测,还有国内大学也都纷纷提出了自己的模型评测 ,但要找到一个准确且有区分度模型排名并不容易。
本文就是我调研的结果,本文主要回答两个问题:
1)国内大模型哪些比较好?
2)这些排名,是什么原理?哪个最值得参考
目录
2)有一些模型没有在国际竞技场,不过在国内的平替,思南 竞技场 上有PK记录:
结论先行,国内大模型在第一梯队的有:
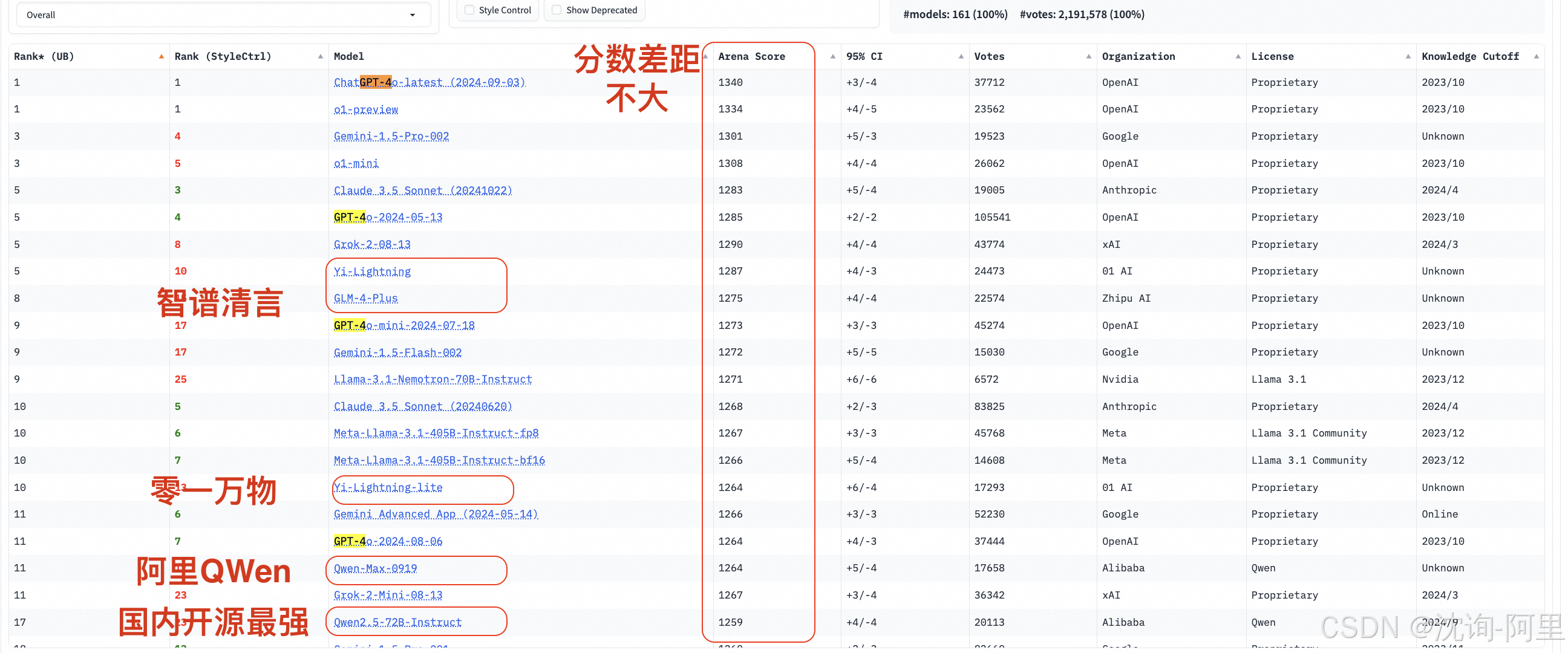
前三强:零一、智谱、通义千问
通义千问Qwen系列:由阿里巴巴云打造的一系列人工智能模型,最近刚刚开源了QWen 2.5版本。这一系列开源了从70亿到1100亿参数规模的全尺寸模型,并且也开源了专门支持文本、视觉等多模态信息处理的模型 。阿里云通过全面开放的方式,不仅为开发者提供了强大的技术支持,还极大地促进了AI技术在各个领域的应用和发展。

YI系列:模型由李开复领导的团队 零一万物 研发,主要做闭源的大模型,目前整体排名在国内第一 。不过,与市场上其他竞品相比,yi系列显得较为封闭,只开源了一款名为Yi-9B的小型开源模型,除了这一个版本外没有更多的公开资源可供使用或研究。虽然对于某些特定场景下的需求可能有所助益,但由于其相对较小的规模限制了其实用性和灵活性。

GLM系列:出自智谱清言团队之手,该团队拥有深厚的清华大学学术背景。他们曾经对外发布了开源版本的glm-4模型,但这并非是该系列中最先进的成果。尽管如此,基于其坚实的理论基础和实践经验,glm系列依然在自然语言处理领域占据了一席之地。

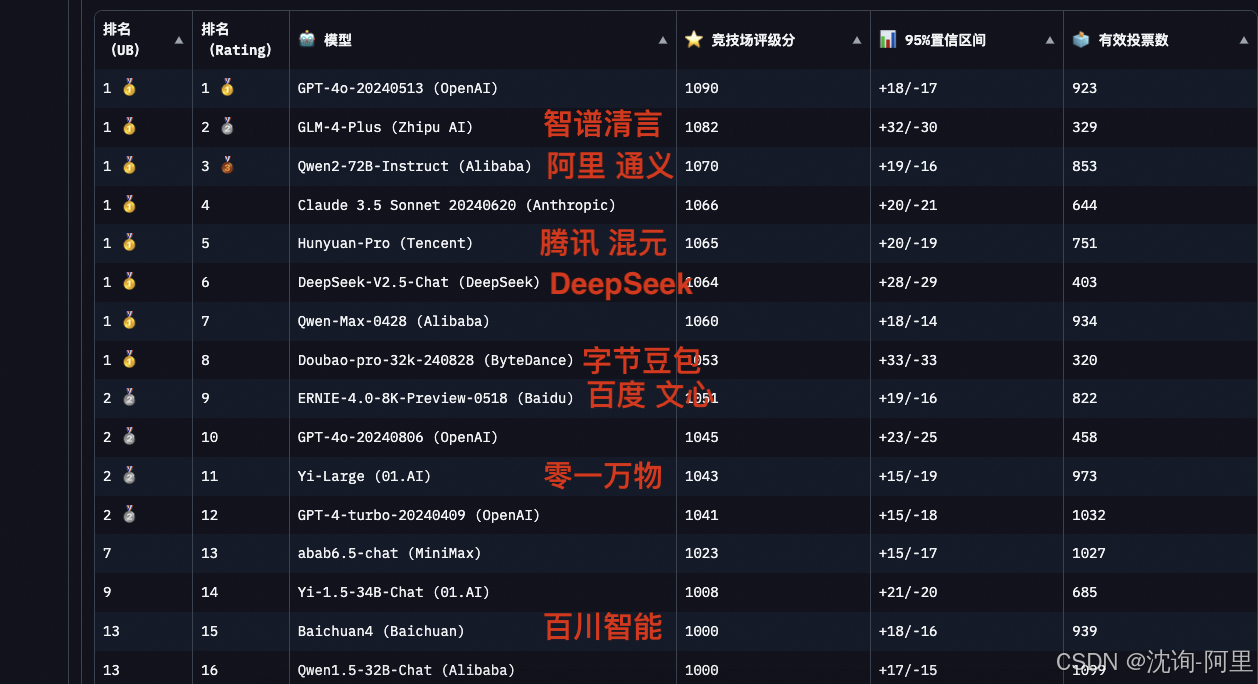
也不错的:豆包、文心、腾讯混元
豆包系列:是由字节跳动研发的人工智能解决方案之一,尤其擅长C端用户的语音识别服务。虽然相较于行业内其他领先者,在综合能力上可能存在一定的差距,但它凭借着优秀的用户体验以及针对特定应用场景的高度优化,仍然赢得了众多用户的好评。
文心系列:是百度公司推出的又一力作,在功能实现和技术水平方面被认为与字节跳动的产品相当。凭借百度多年来积累的强大数据资源和技术实力,文心能够提供高质量的语言理解及生成服务,满足不同行业客户多样化的需求。
腾讯混元系列:隶属于腾讯集团,它在性能表现上被认为与百度文心处于同一档次。依托于腾讯广泛的服务生态体系,混元不仅能为企业级用户提供定制化的智能解决方案,同时也致力于推动整个社会向更加智能化的方向发展。
这些是在目前最公允的排行榜上的系列,整体来看,这些模型有大厂的,也有创新性企业的,为我们国产模型能够与美国能作为世界两级做竞争而开心!
在世界级的比赛竞技场上,有零一万物、智谱、阿里通义千问Qwen三个模型与世界上最强的openai,claude等做竞争,而且不落下风。
1) https://lmarena.ai 竞技场的结果:
2)有一些模型没有在国际竞技场,不过在国内的平替,思南 竞技场 上有PK记录:
为什么这个竞技场模式是最值得借鉴的? 请看后文的模型能力评估部分。
大模型能力评估的主要方法和思路介绍:
大模型本身的能力横评主要通过“基准测试”和“人类评估”两种方式进行。
“基准测试”或“考试模式”的核心思路是通过一系列预设的、标准化的问题来评估模型在特定任务上的表现。简单来说,就是一大堆的QA对,用Q去问模型,然后跟标准的A做对照。 就像我们上学时候的模拟考试。 常见的基准测试包括GSM-8K(侧重于数学问题解决能力)、MMLU(多语言理解,考察跨学科知识掌握情况)、TheoremQA(针对逻辑推理与证明能力)以及GPQA(广义问题回答,检验模型综合信息处理能力)。
而“人类评估”或“竞技场模式”则是让两个或多个模型对同一开放性问题给出答案,然后由人类评判员选择哪个答案更优。这种方法由于问题更加灵活且贴近实际使用场景,能够更好地反映模型在真实世界中的应用效果。尽管基准测试存在题目固定易被优化的问题,但其结果仍具有参考价值;而竞技场模式则因其高度的人类参与度而显得更为直观可信。两者结合使用时,往往能提供关于大模型性能更为全面客观的评价。
从原理来说,最可信的测试,就是人类评估竞技场模式,这个模式可以非常客观的体现机器回答对人类的帮助,而且难以作弊,非常客观。
基准测试:
可以参考huggingface的 : https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard 。
人类评估竞技场模式:
可以参考国外 : https://lmarena.ai (评价人最多,不过以英文评测为主)
或者咱们国内的平替 思南平台 : CompassArena(目前评价人不够,但能以中文为主,也包含中文模型)
也欢迎大家参与这些评测,点点鼠标就行,给这些模型做更多的评测打分,让大家看到更客观的复合人类需要的模型涌现出来!
如何选择适合自己业务场景的大模型?
在选择大模型时,可以从以下几个维度综合考量:
首先,参考榜单排名。通常情况下,建议从当前市场认可度较高的前20个模型中进行挑选,特别是那些在特定领域如代码生成或图像识别方面表现优异的细分领域冠军。这些模型往往经过大量相关数据训练,在专门任务上的性能更加出色。
其次,考虑到实际应用环境和法律法规要求,对于国内用户来说,选择国产的大模型更为合适。相较于国外模型,国产模型不仅能够更好地满足本地化需求,在数据隐私保护与合规性方面也更符合中国市场的规定。
此外,还需关注所选模型是否支持私有化部署。虽然很多服务提供了便捷的云端API调用方式,但如果您的业务场景需要将模型运行于封闭网络环境中,则必须确保该模型能够在不影响其功能的前提下顺利完成本地部署。
最后但同样重要的是成本问题。
对于采用 API 云服务形式提供的模型而言,各大厂商的价格相对透明且容易比较,目前国内的大厂的模型API调用是白菜价,羊毛薅起来!
而对于需要自建基础设施的情况,则需权衡模型规模与硬件投入之间的关系——一般来说,较小的模型意味着较低的成本。综上所述,根据自身业务特点及具体需求,仔细评估上述各方面因素后作出合理选择是关键。
整体而言,我目前更倾向于通义Qwen是当前最值得推荐的
因为
1) 通义Qwen是目前最为开放的大模型之一。它提供了全尺寸的多模态大模型全部开源版本非常有利于做私有化部署。 这就比只做一两个小模型开源的零一万物和GLM要强很多,这个毕竟也跟阿里主要是卖计算资源,而零一和GLM则主要是卖大模型本身有关。这就直接决定了阿里在大模型上更为开放的态度。
2)能力较强,在MMLU、TheoremQA、GPQA等基准评测中表现优异,超越了Llama 3 70B,在Hugging Face 开源大模型排行榜Open LLM Leaderboard上位居首位。在国内市场中,通义的能力处于绝对的第一梯队。
3)价格不贵,现在还有100万免费token可供使用,又提供了开源选择,无论是通过API调用还是自行构建应用,成本都非常低。
特别推荐关注Qwen和Qwen VL这两个模态的模型,它们在国内开源榜单上均位列第一。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









