






现在的AI可谓是火的一塌糊涂, 看到使用LM Studio部署本地模型非常的方便, 于是我也想在自己的本地试试
LM Studio 简介
LM Studio 是一款专为本地运行大型语言模型(LLMs)设计的桌面应用程序,支持 Windows 和 macOS 系统。它允许用户在个人电脑上无需联网即可高效部署和交互开源大模型(如 LLaMA、Mistral、GPT-NeoX 等),兼顾隐私性与灵活性。
下载
LM Studio官网: https://lmstudio.ai/
进入到官网之后直接下载即可, 然后无脑安装, 这里就不多介绍了
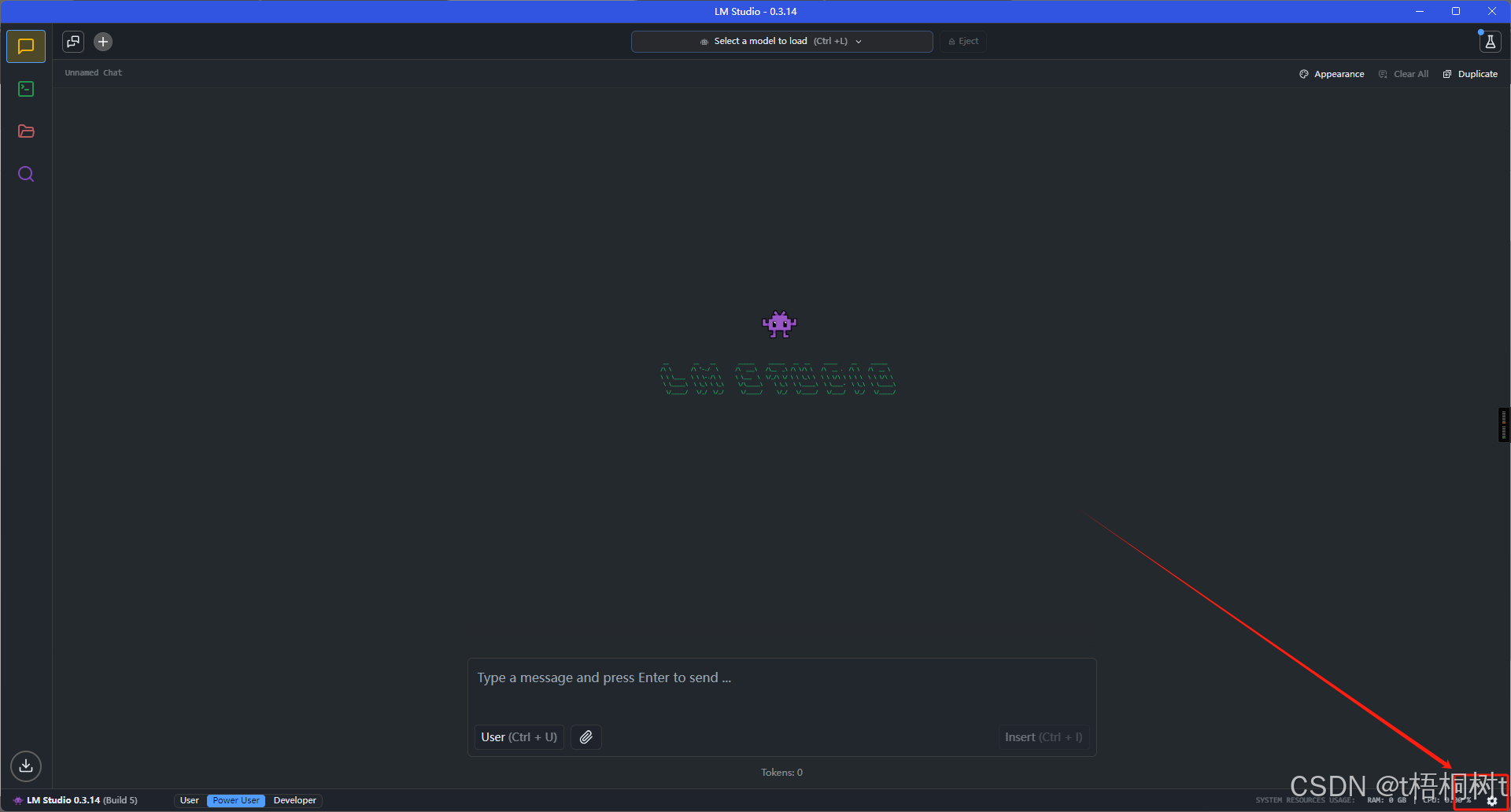
简单设置
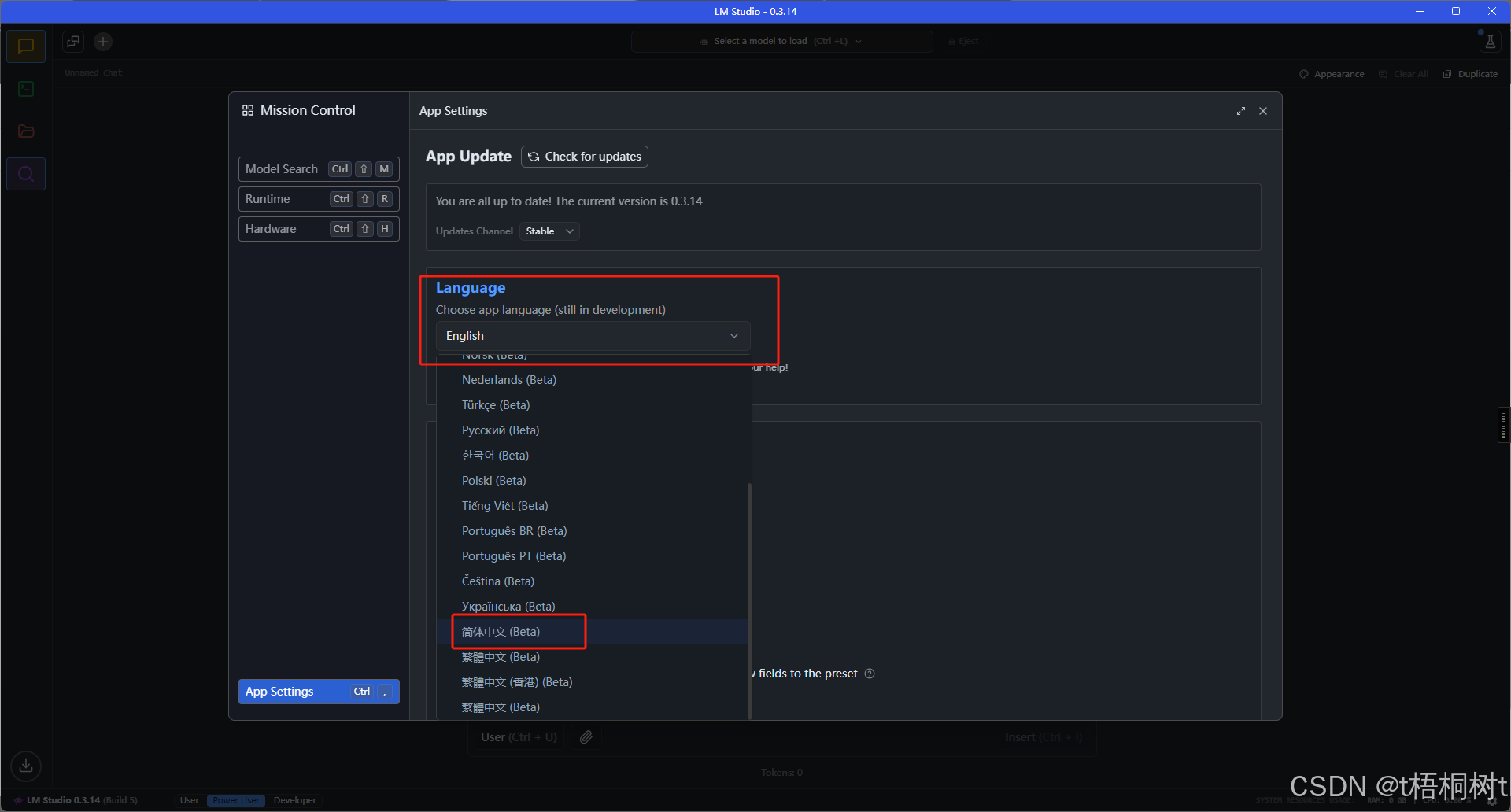
首次打开之后根据自己需要可以设置一下语言, 这里我们选择中文
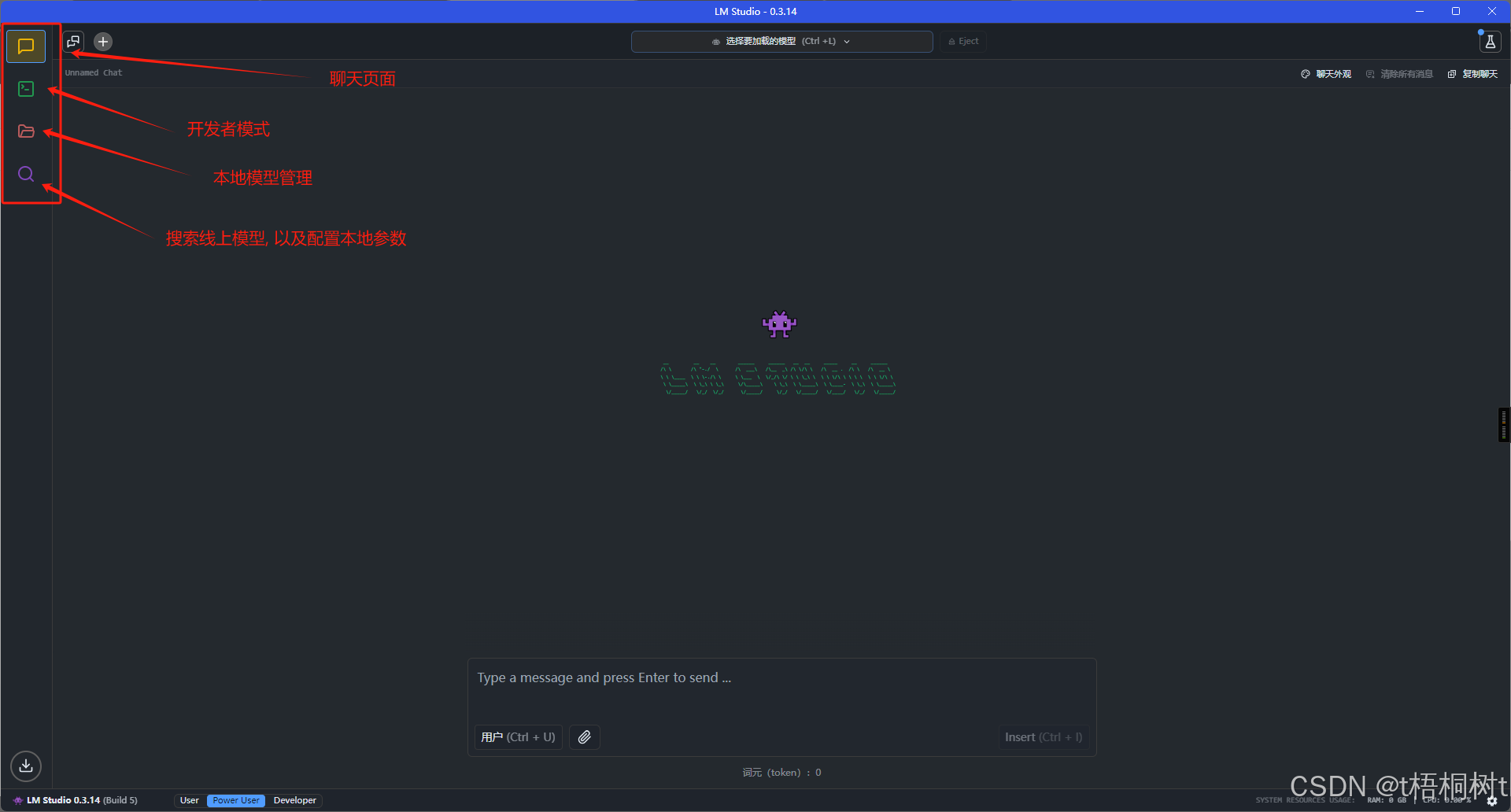
点击放大镜, 里面有三个选项
下载模型
注意下载模型时尽量选择有绿色标识的模型进行下载, 这是LM Studio给我推荐安装的, 表示我们的GPU显存可以完全的运行该模型, 以保证模型的运行速度

运行环境
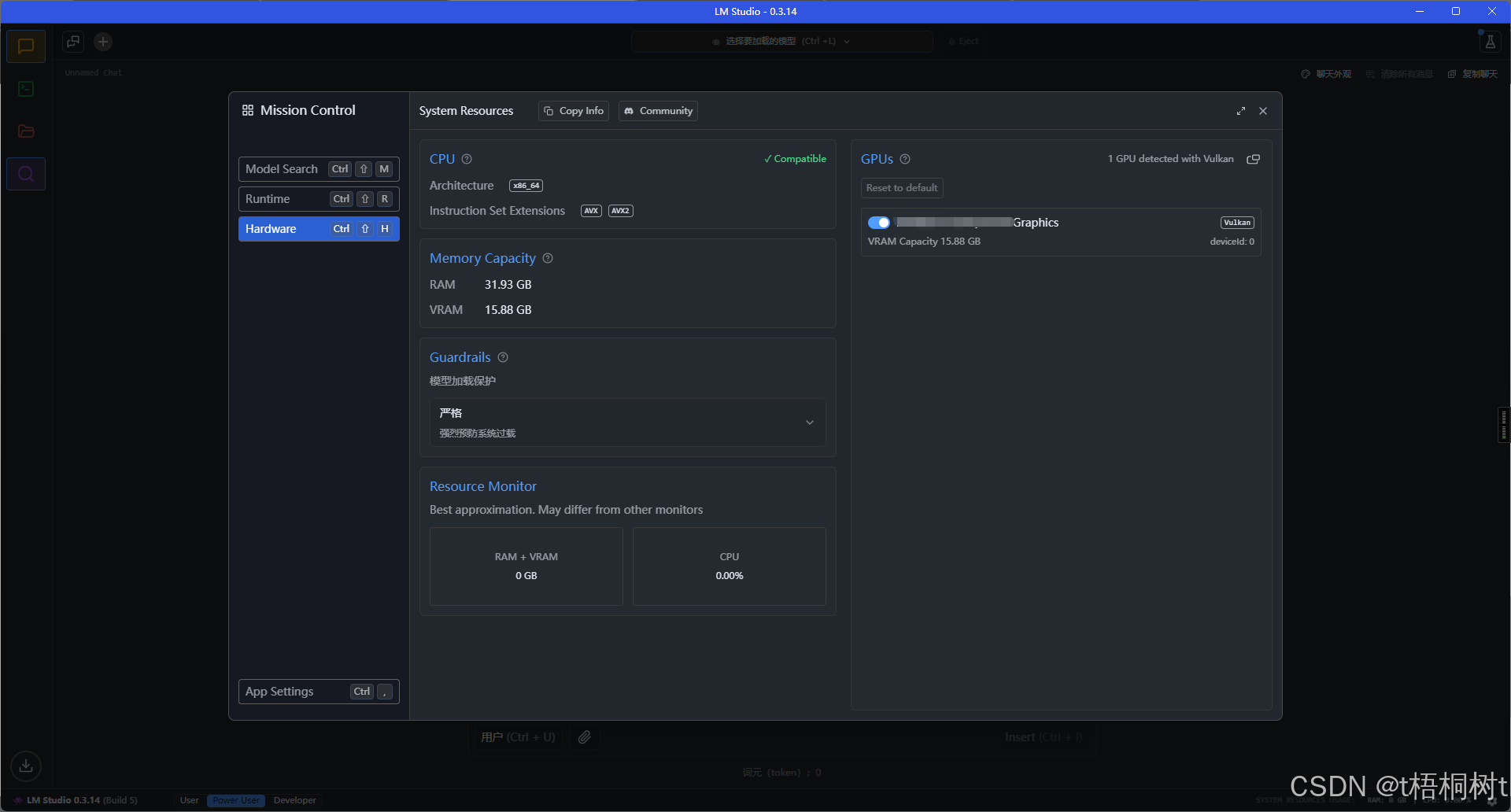
运行环境很重要, 这关系到我们的电脑到底能不能玩模型, 正常来讲肯定是NAIDIA显卡更合适一些, 但是很多人可能装的不是N卡,甚至没有独显, 也就不支持CUDA, 这让本地部署成了件麻烦事, 好在LM Studio帮我们解决了这些麻烦, 可以看到我的显卡并不支持CUDA, 但是支持Vulkan,虽说比不上CUDA但是总归是能吃上显卡的算力的, 就算是我们本地没有独显, LM Studio还支持纯CPU运行的, 只是体验不太好罢了, 这一点比ollama就要好上太多了
本地资源监视
这里就是本地资源的展示, 可以不用调整
启动模型
选择要启动的模型直接点击就可以运行
设置模型参数
设置模型参数有两种方式, 一种是临时的, 一种是永久保存的, 在这里设置的参数, 在通过接口访问本地模型时也是生效的, 相当于不用我们在调用接口时再去手写这些配置, 很是方便
临时设置参数
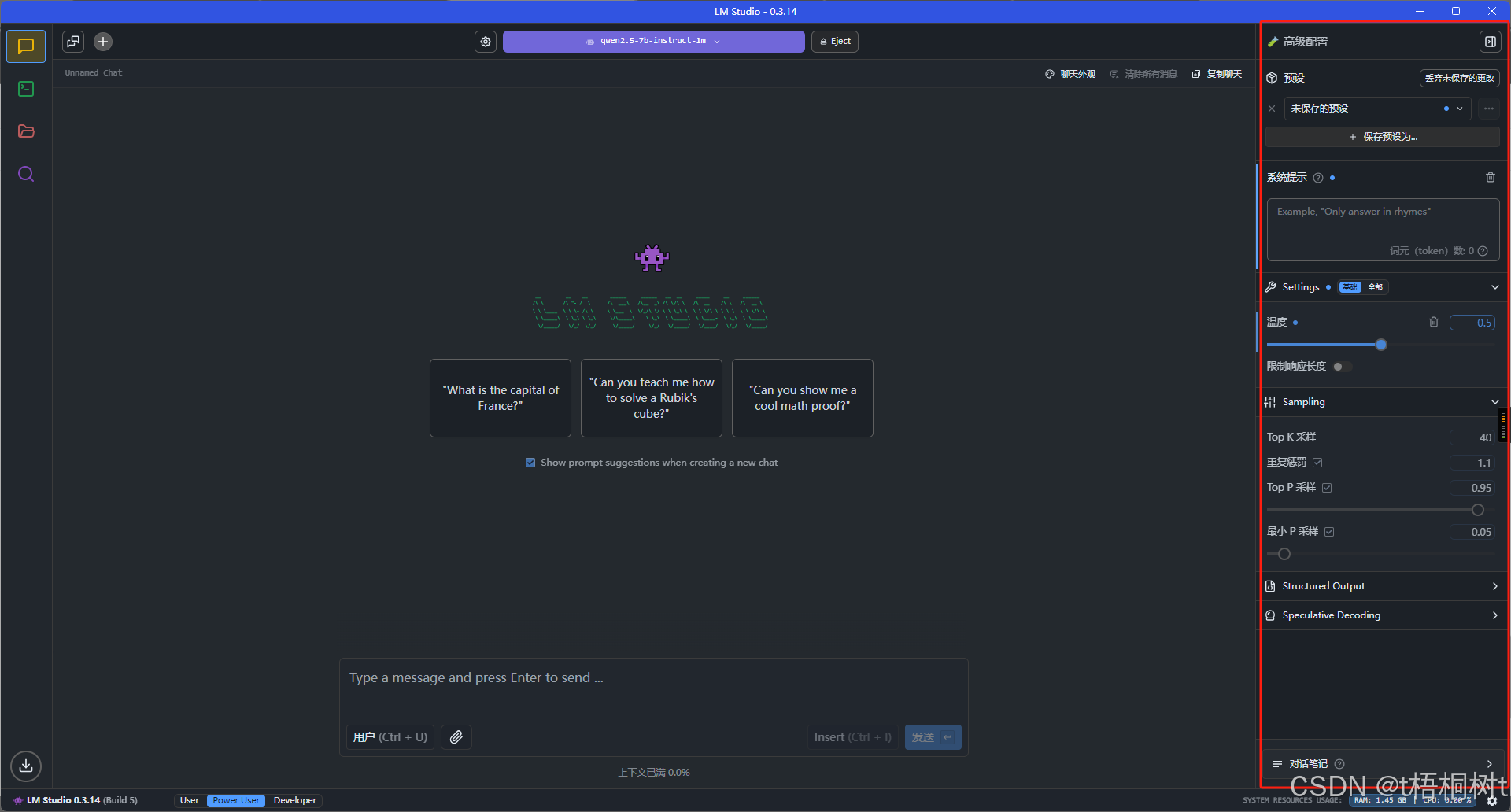
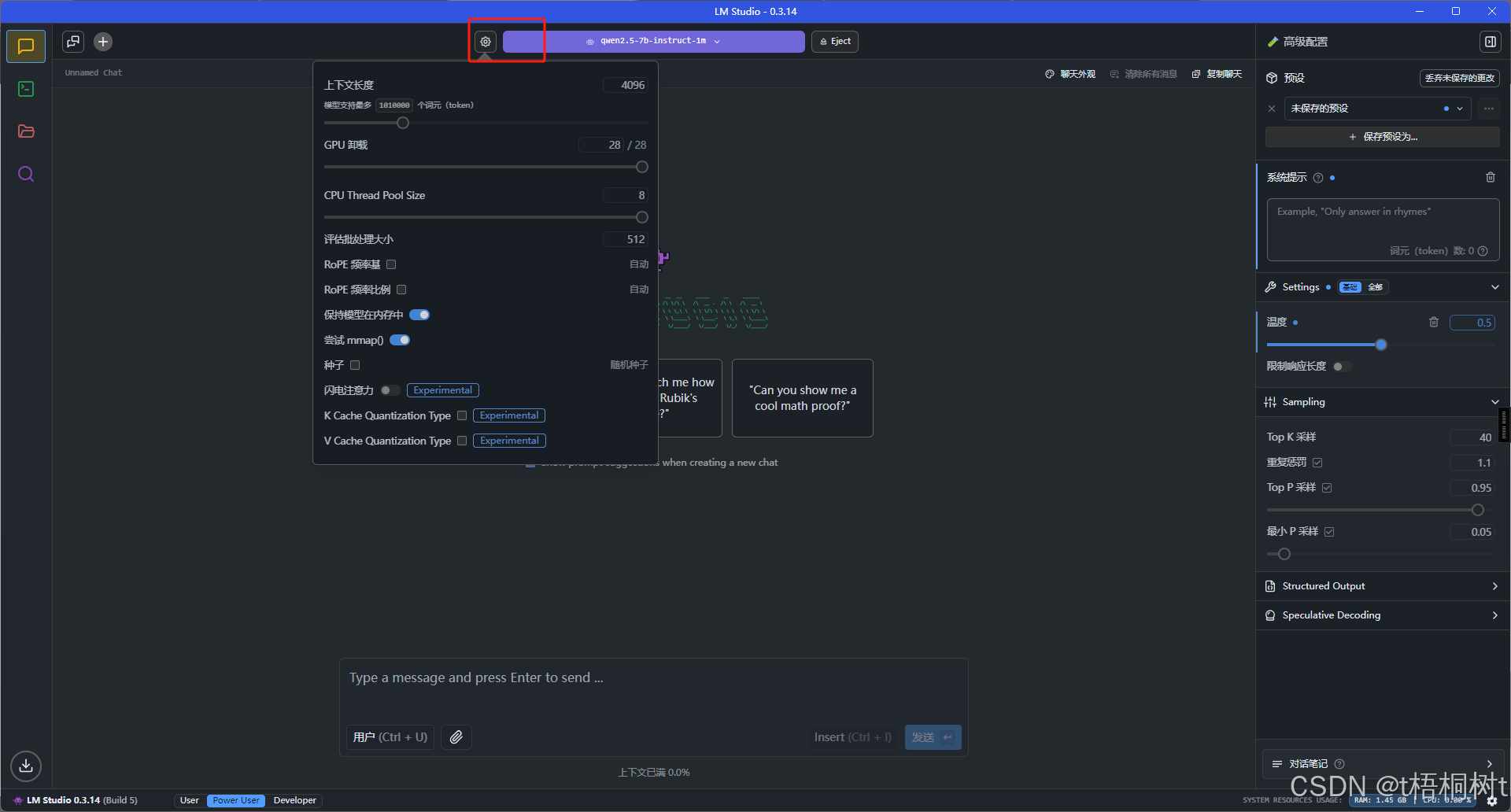
永久设置参数
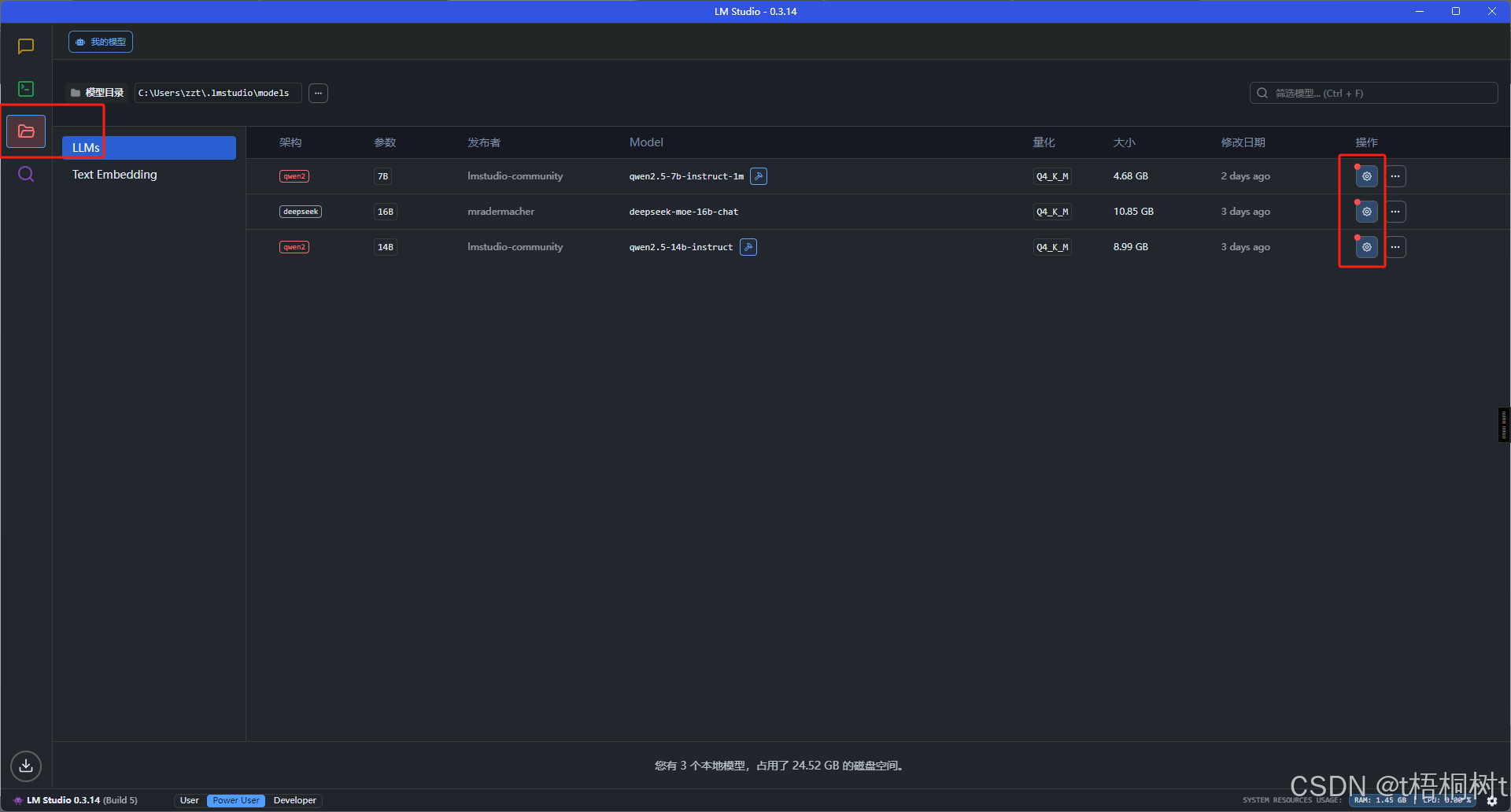
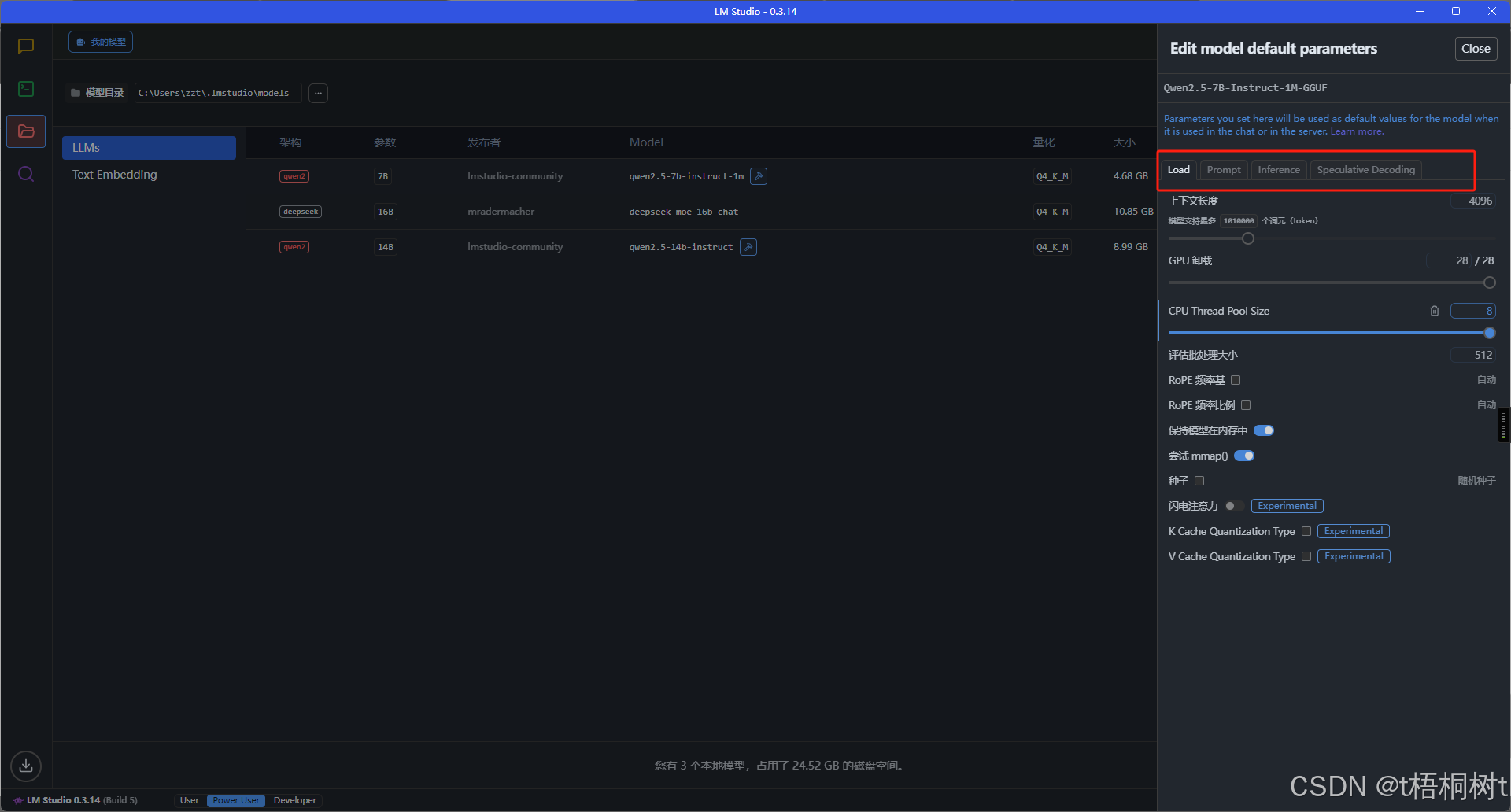
聊天窗口对话
这里截图不完整, 我问了它一个简单问题, 让它使用java写一个简单的冒泡排序算法, 可见它生成的速度还是蛮快的, 这说明它却是吃上了显卡的算力
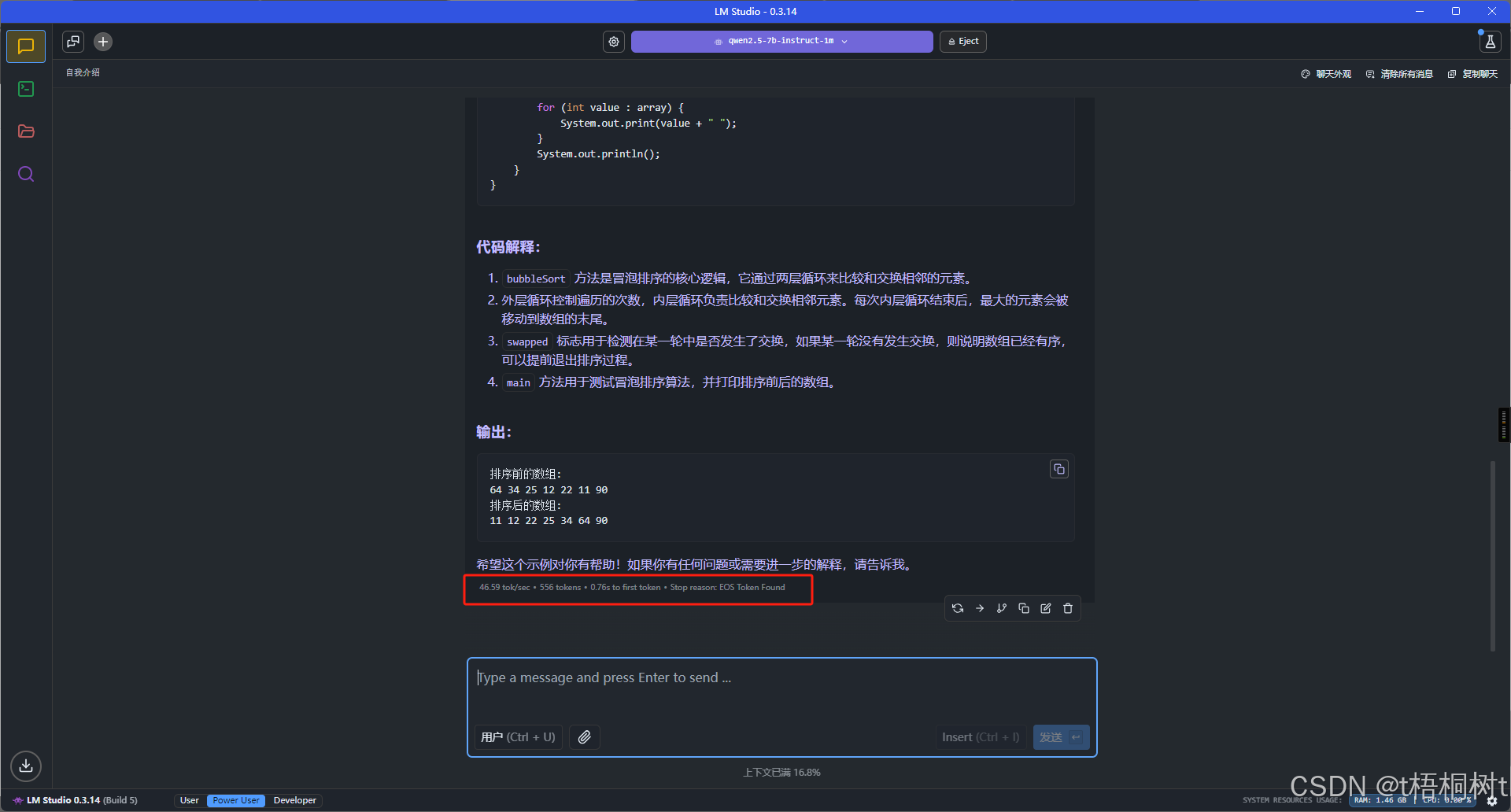
开发者
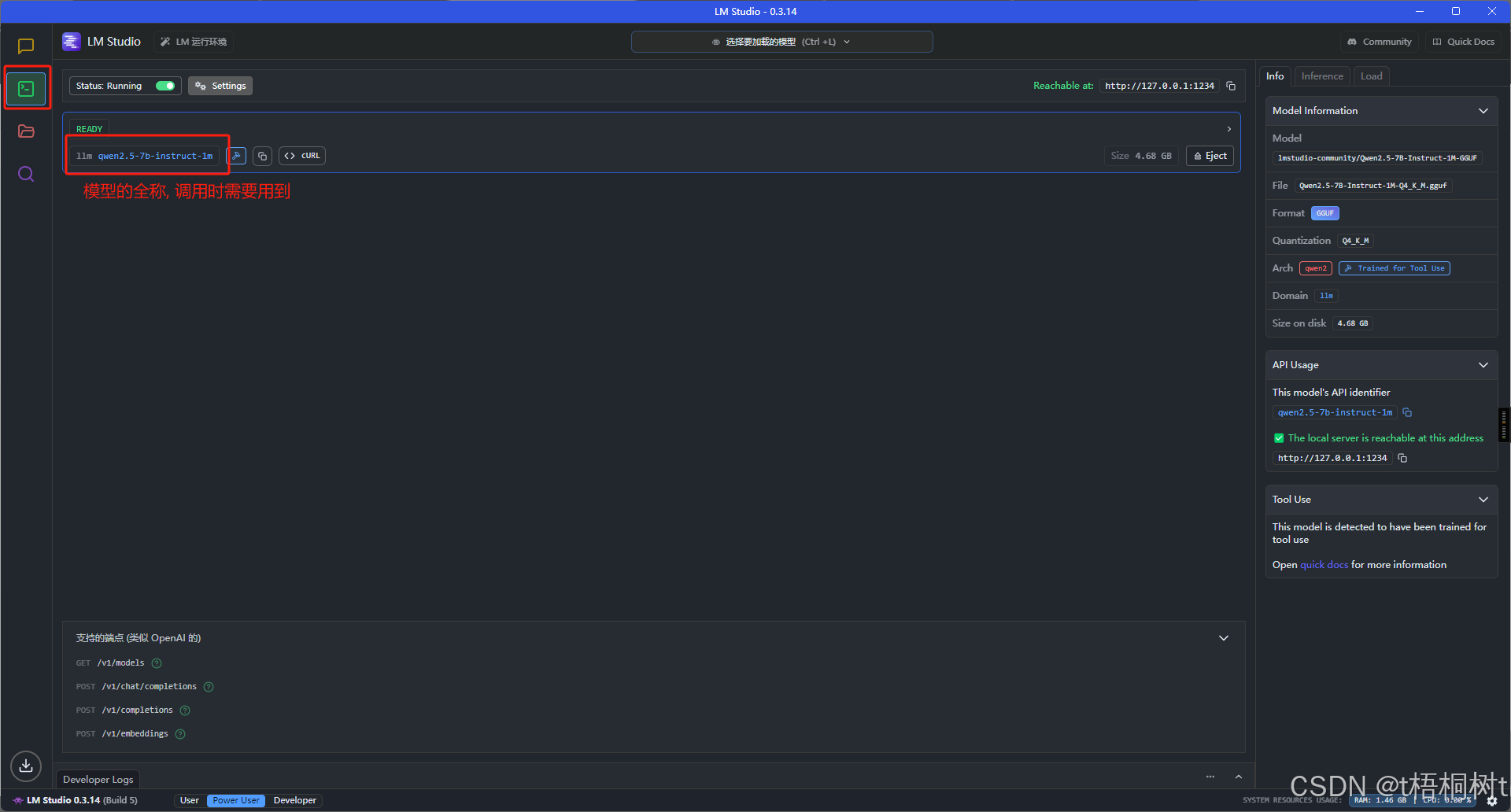
本地调用模型
这里我使用python写了一个简单调用大模型的脚本
import requests
import json
# 配置 LM Studio 的 API 地址(默认端口 1234)
LM_STUDIO_API_URL = "http://localhost:1234/v1/chat/completions"
def query_qwen_model(
prompt: str,
model_name: str = "qwen2.5-7b-instruct-1m", # 需与 LM Studio 加载的模型名称完全一致
max_tokens: int = 1000, # 生成的最大 token 数(7B 模型建议 500 以内)
temperature: float = 0.7, # 控制随机性(0.1-1.0)
top_p: float = 0.9, # 核采样概率(0-1,与 temperature 配合)
stream: bool = False # 是否流式输出
) -> str:
"""
调用 LM Studio 部署的 Qwen2.5 7B 模型
:param prompt: 用户输入的提示文本
:param model_name: 模型名称(需与 LM Studio 中加载的名称一致)
:param max_tokens: 生成内容的最大长度
:param temperature: 值越低输出越确定,越高越随机
:param top_p: 核采样阈值(通常 0.8-0.95)
:param stream: 是否启用流式输出(逐字显示)
:return: 模型生成的回复内容
"""
# 请求头(必须为 JSON 类型)
headers = {
"Content-Type": "application/json"
}
# 请求体(OpenAI 兼容格式)
data = {
"model": model_name,
"messages": [
{"role": "user", "content": prompt}
],
"temperature": temperature,
"max_tokens": max_tokens,
"top_p": top_p,
"stream": stream
}
try:
# 发送 POST 请求到 LM Studio API
response = requests.post(
LM_STUDIO_API_URL,
headers=headers,
data=json.dumps(data), # 将字典转换为 JSON 字符串
stream=stream # 如果是流式请求,需启用 stream=True
)
response.raise_for_status() # 检查 HTTP 错误(如 404, 500)
# 解析响应内容
if not stream:
result = response.json()
return result["choices"][0]["message"]["content"]
else:
# 流式输出处理
full_response = ""
for chunk in response.iter_lines():
if chunk:
decoded = chunk.decode("utf-8").strip()
if decoded.startswith("data:"):
chunk_data = json.loads(decoded[5:]) # 去掉 "data: " 前缀
if "content" in chunk_data["choices"][0]["delta"]:
content = chunk_data["choices"][0]["delta"]["content"]
print(content, end="", flush=True) # 逐字打印
full_response += content
return full_response
except requests.exceptions.RequestException as e:
return f"请求失败: {str(e)}"
except json.JSONDecodeError as e:
return f"JSON 解析错误: {str(e)}"
except KeyError as e:
return f"响应格式异常: {str(e)}"
# 示例调用
if __name__ == "__main__":
# 非流式调用
prompt = "你好,请介绍一下 Qwen2.5 7B 模型的特点。"
response = query_qwen_model(prompt)
print("\n模型回复(非流式):", response)
# # 流式调用(逐字显示)
# print("\n流式输出演示:")
# stream_response = query_qwen_model(
# "用 Python 写一个快速排序算法",
# stream=True
# )
调用返回(流式输出)
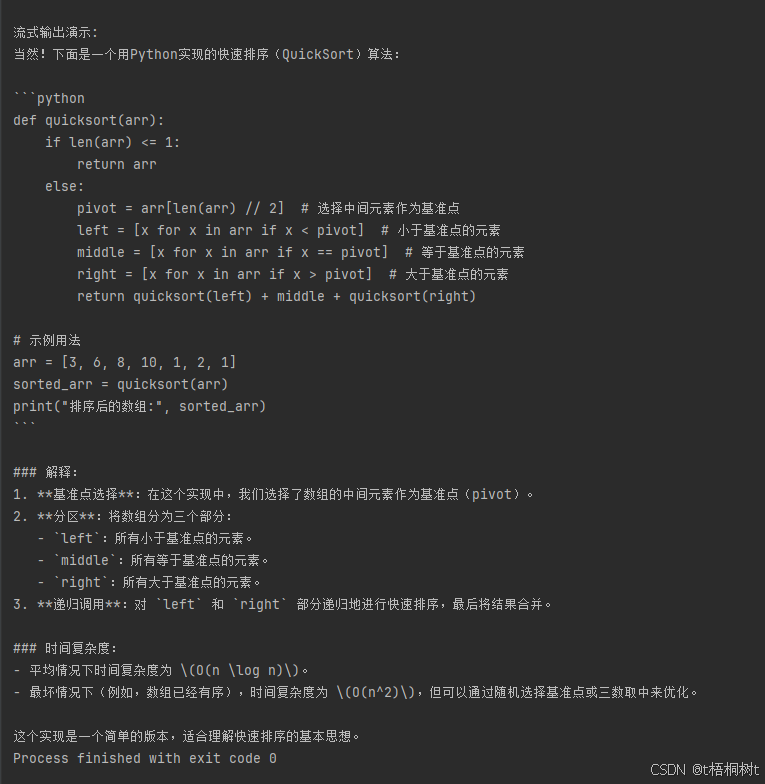

















 2348
2348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









