







原文:
zh.annas-archive.org/md5/2e3ab9ce96c35c507253e57a41b1a6f1译者:飞龙
第六章:开发软件
加入我们在 Discord 上的书籍社区
packt.link/EarlyAccessCommunity

尽管这本书讨论整合生成式人工智能,特别是大型语言模型(LLMs)到软件应用程序中,但在本章中,我们将讨论如何利用 LLMs 来帮助软件开发。这是一个重要的话题,软件开发被几家咨询公司(如毕马威和麦肯锡)的报告强调为受生成式人工智能影响最大的领域之一。我们将首先讨论 LLMs 如何帮助编码任务,并概述我们在自动化软件工程师方面取得的进展。我们还将讨论许多最新的进展和新模型。然后,我们将测试一些模型,定性地评估生成的代码。接下来,我们将实现一个完全自动化的软件开发代理。我们将讨论设计选择,并展示我们通过 LangChain 仅使用几行 Python 代码在代理实现中得到的结果。这种方法有许多可能的扩展,我们也会详细介绍。在整个章节中,我们将探讨软件开发的不同方法,您可以在 Github 存储库中的software_development目录中找到书籍的链接:github.com/benman1/generative_ai_with_langchain主要包括以下几个部分:
-
软件开发和人工智能
-
使用 LLMs 编写代码
-
自动化软件开发
我们将以对使用人工智能进行软件开发的最新技术做一个广泛概述作为这一章的开端。
软件开发和人工智能
强大的人工智能系统如 ChatGPT 的出现引发了将 AI 作为辅助软件开发的工具的极大兴趣。卡特彼马集团(KPMG)在 2023 年 6 月的一份报告估计,约有 25%的软件开发任务可以自动化完成。这个月的麦肯锡报告强调了软件开发作为一个功能,其中生成 AI 可以在成本降低和效率提高方面产生显著影响。利用人工智能辅助编程的想法并不是新鲜事物,但随着计算和 AI 的进步,这两个领域已迅速发展。正如我们将看到的那样,这两个领域是相互交织的。20 世纪 50 年代和 60 年代早期的语言和编译器设计早期努力旨在使编写软件变得更容易。数据处理语言像FLOW-MATIC(也称为:商业语言版本 0),由 Grace Hopper 于 1955 年在 Remington Rand 设计,可以从类似于英语的语句中生成代码。同样,编程语言如 Dartmouth College 在 1963 年创建的BASIC(初学者通用符号指令代码)旨在使在解释环境中编写软件更容易。其他努力进一步简化和规范化编程语法和接口。 流程驱动编程(FBP)范例,由 J. Paul Morrison 在 20 世纪 70 年代早期发明,允许将应用程序定义为连接的黑盒进程,其通过消息传递交换数据。可视化的低代码或无代码平台遵循相同的模式,其中一些流行的支持者包括 LabVIEW,广泛用于电子工程中的系统设计,以及 KNIME 数据科学中的提取、转换、加载工具。通过 AI 自动编码本身的最早的一些努力是专家系统,它们出现在 20 世纪 80 年代。作为狭义 AI 的一种形式,它们专注于编码领域知识和规则以提供指导。这些规则将以非常特殊的语法公式化,并在规则引擎中执行。这些编码了编程任务的最佳实践,如调试,但它们的有用性受到了需要精细的基于规则的编程的限制。对于软件开发,从命令行编辑器如 ed(1969),到 vim 和 emacs(1970 年代),再到今天的集成开发环境(IDEs),如 Visual Studio(1997 年首次发布)和 PyCharm(自 2010 年以来),这些工具帮助开发人员编写代码,导航在复杂的项目中,重构,获得高亮和设置和运行测试。IDE 也集成并提供来自代码验证工具的反馈,其中一些工具已经存在自 20 世纪 70 年代以来。其中,贝尔实验室 1978 年由 Stephen Curtis Johnson 编写的 Lint 可以标记错误,风格上的错误和可疑的结构。许多工具应用正式方法; 然而,机器学习至少 20 年来已经应用,包括遗传编程和基于神经网络的方法。在本章中,我们将看到使用深度神经网络,特别是Transformers来分析代码的进展。这带我们来到了现在,已经训练出模型根据自然语言描述(在编码助手或
现在的一天
DeepMind 的研究人员分别在《自然》和《科学》期刊上发表了两篇论文,这代表了使用 AI 改变基础计算的重要里程碑,特别是使用强化学习来发现优化算法。2022 年 10 月,他们发布了由他们的模型AlphaTensor发现的用于矩阵乘法问题的算法,这可以加速深度学习模型需要的这种重要计算,也适用于许多其他应用。AlphaDev发现了集成到广泛使用的 C++库中的新型排序算法,提高了数百万开发人员的性能。它还推广了它的能力,发现了一个比目前每天数十亿次使用的速度快 30%的哈希算法。这些发现证明了 AlphaDev 的能力超越了人工精细调整的算法,并解锁了在较高编程级别难以进行的优化。他们的模型AlphaCode,在 2022 年 2 月作为一篇论文发表,展示了一个由人工智能驱动的编码引擎,其创建计算机程序的速度可与普通程序员相媲美。他们报告了不同数据集上的结果,包括 HumanEval 等,我们将在下一节讨论。DeepMind 的研究人员强调了大规模采样算法候选池和从中选择的过滤步骤。该模型被誉为突破性成就;然而,他们的方法的实用性和可扩展性尚不清楚。如今,像 ChatGPT 和微软的 Copilot 这样的新代码 LLM 已经成为备受欢迎的生成式 AI 模型,拥有数百万用户和显著的提高生产力的能力。LLM 可以处理与编程相关的不同任务,比如:
-
代码补全:这项任务涉及基于周围代码预测下一个代码元素。它通常用于集成开发环境(IDE)中,以帮助开发人员编写代码。
-
代码摘要/文档:这项任务旨在为给定的源代码块生成自然语言摘要或文档。这个摘要帮助开发人员理解代码的目的和功能,而不必阅读实际的代码。
-
代码搜索:代码搜索的目标是根据给定的自然语言查询找到最相关的代码片段。这项任务涉及学习查询和代码片段的联合嵌入,以返回预期的代码片段排名顺序。在文本中提到的实验,神经代码搜索专门侧重于这一点。
-
Bug 查找/修复:AI 系统可以减少手动调试工作量,增强软件的可靠性和安全性。对于程序员来说,许多错误和漏洞很难找到,尽管存在用于代码验证的典型模式。作为替代方案,LLM 可以发现代码中的问题,并在提示时进行修正。因此,这些系统可以减少手动调试工作量,并有助于提高软件的可靠性和安全性。
-
测试生成:类似于代码补全,LLM(大型语言模型)可以生成单元测试(参见 Bei Chen 等人,2022 年)和增强代码库可维护性的其他类型的测试。
AI 编程助手结合了早期系统的互动性和前沿的自然语言处理。开发人员可以用简单的英语查询 bug 或描述所需的功能,接收生成的代码或调试提示。然而,围绕代码质量、安全性和过度依赖仍存在风险。在保持人类监督的同时实现正确的计算机增强的平衡是一个持续的挑战。让我们来看看目前用于编码的 AI 系统的性能,特别是代码 LLMs。
代码 LLMs
出现了相当多的 AI 模型,每个模型都有其优点和缺点,并不断竞争以改进并提供更好的结果。这个比较应该概述一些最大和最流行的模型:
| 模型 | 读取文件 | 运行代码 | 标记 |
|---|---|---|---|
| ChatGPT;GPT 3.5/4 | 否 | 否 | 最多 32k |
| ChatGPT:代码解释器 | 是 | 是 | 最多 32k |
| Claude 2 | 是 | 否 | 100k |
| Bard | 否 | 是 | 1k |
| 必应 | 是 | 否 | 32k |
图 6.1:软件开发的公共聊天界面。
虽然这种竞争为用户提供了更广泛的选择,但这也意味着仅仅依赖 ChatGPT 可能不再是最佳选择。用户现在面临选择为每个特定任务选择最合适的模型的决策。最新的浪潮利用机器学习和神经网络实现了更灵活的智能。强大的预训练模型如 GPT-3 使得上下文感知、对话支持成为可能。深度学习方法还赋予了 Bug 检测、修复建议、自动化测试工具和代码搜索更强大的能力。微软的 GitHub Copilot 基于 OpenAI 的 Codex,利用开源代码实时建议完整的代码块。根据 2023 年 6 月的 GitHub 报告,开发人员大约 30%的时间接受了 AI 助手的建议,这表明该工具可以提供有用的建议,而经验不足的开发人员受益最多。
Codex 是由 OpenAI 开发的一个模型。它能够解析自然语言并生成代码,为 GitHub Copilot 提供动力。作为 GPT-3 模型的后裔,它已经在 GitHub 上公开可用的代码上进行了微调,包括来自 5400 万 GitHub 仓库的 159 千兆字节的 Python 代码,用于编程应用。
为了说明在创建软件方面取得的进展,让我们看一下基准中的定量结果:HumanEval 数据集,由 Codex 论文介绍(“评估基于代码的大型语言模型的性能”,2021 年),旨在测试大型语言模型根据其签名和文档字符串完成函数的能力。它评估了从文档字符串合成程序的功能正确性。数据集包括 164 个编程问题,涵盖了语言理解、算法和简单数学等各个方面。其中一些问题类似于简单的软件面试问题。在 HumanEval 上的一个常见指标是 pass@k(pass@1)-这是指在每个问题生成 k 个代码样本时的正确样本的分数。这张表总结了 AI 模型在 HumanEval 任务上的进展(来源:Suriya Gunasekar 等人,“仅需教科书”,2023 年;arxiv.org/pdf/2306.11644.pdf):
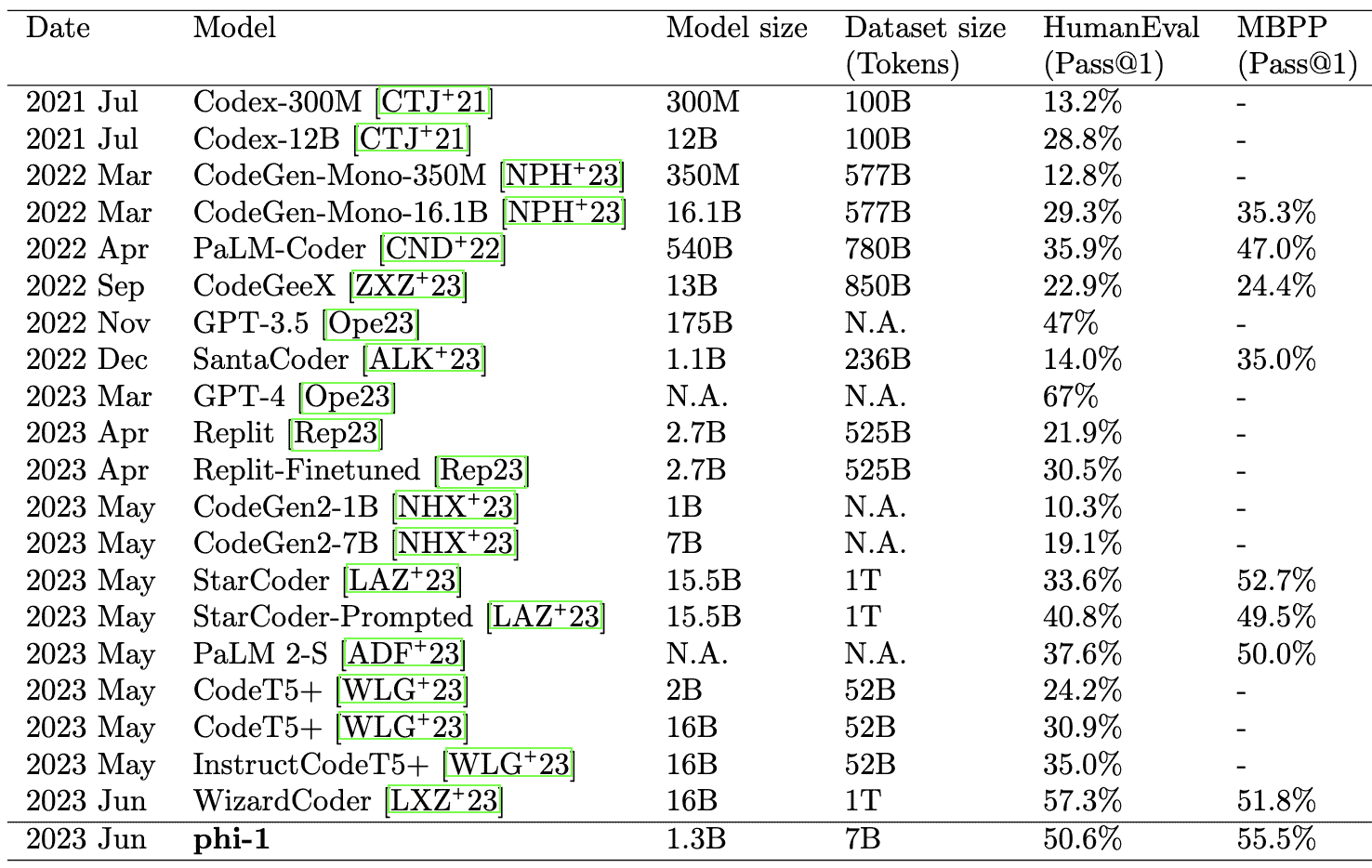
图 6.2:编码任务基准上的模型比较(HumanEval 和 MBPP)。性能指标是自报的。这张表只包括模型,而不是其他方法,例如推理策略。Llama2 在 HumanEval 上的自报性能为 29.9%。
请注意,训练大多数 LLM 模型的数据中包含一定数量的源代码。例如,由 EleutherAI 的 GPT-Neo 等人策划的 Pile 数据集,用于训练 GPT 模型的开源替代品,其中至少包含来自 Github 的约 11% 代码(102.18GB)。Pile 被用于 Meta 的 Llama、Yandex 的 YaLM 100B 等的训练。尽管 HumanEval 已广泛用作代码 LLM 的基准,但有多种编程基准可供选择。以下是一个示例问题以及给 Codex 的一个高级计算机科学测试的响应:

图 6.3:CS2 考试中的一个问题(左)和 Codex 的响应(来源:“我的 AI 想知道这会不会出现在考试中:测试 OpenAI 的 Codex 对 CS2 编程练习” James Finnie-Ansley 等人,2023 年)。
有许多有趣的研究揭示了 AI 帮助软件开发人员的能力,或者扩展了该能力,如在这个表格中总结的那样:
| 作者 | 出版日期 | 结论 | 任务 | 分析的模型/策略 |
|---|---|---|---|---|
| Abdullah Al Ishtiaq 等人 | 2021 年 4 月 | 类似 BERT 的预训练语言模型可以通过改进语义理解来增强代码搜索。 | 代码搜索 | BERT |
| Mark Chen 等人(OpenAI) | 2021 年 7 月 | 对 Codex 进行代码生成评估,显示提升程序合成的潜力 | 代码生成 | Codex |
| Ankita Sontakke 等人 | 2022 年 3 月 | 即使是最先进的模型也会产生质量低劣的代码摘要,表明它们可能不理解代码。 | 代码摘要 | Transformer 模型 |
| Bei Chen 等人(微软) | 2022 年 7 月 | CODE-T 利用 LLM 自动生成测试用例,减少人力成本并提高代码评估。它达到了 65.8% 的 HumanEval pass@1。 | 代码生成、测试 | CODET |
| Eric Zelikman 等人(斯坦福大学) | 2022 年 12 月 | Parsel 框架使 LLM 能够分解问题并利用其优势,在层次化推理方面提高性能 | 程序合成、规划 | Codex |
| James Finnie-Ansley 等人 | 2023 年 1 月 | Codex 在高级 CS2 编程考试中表现优于大多数学生。 | CS2 编程 | Codex |
| 刘越 等人 | 2023 年 2 月 | 现有的自动化代码生成在鲁棒性和可靠性方面存在限制。 | 代码生成 | 5 个 NMT 模型 |
| 耿明扬 等人 | 2023 年 2 月 | 两阶段方法显著增加了代码摘要的有效性。 | 代码摘要 | LLM + 强化学习 |
| Noah Shinn 等人 | 2023 年 3 月 | 通过口头反思,Reflexion 实现了试错学习,达到了 91% 的 HumanEval pass@1 | 编码、推理 | Reflexion |
| 田昊烨 等人 | 2023 年 4 月 | ChatGPT 在编程辅助方面表现出潜力,但在鲁棒性、泛化性和注意力跨度方面存在限制。 | 代码生成、程序修复、代码摘要 | ChatGPT |
| 耿初琴 等人 | 2023 年 4 月 | ChatGPT 在初级编程教育中展现出令人印象深刻的能力,但作为学生只能获得 B- 的成绩。 | 初级函数式编程课程 | ChatGPT |
| 陈欣云 等人 | 2023 年 4 月 | 自调试技术使语言模型能够识别和纠正生成代码中的错误。 | 代码生成 | Self-Debugging |
| Masum Hasan 等人 | 2023 年 4 月 | 将文本转换为中间形式语言可从描述中更高效地生成应用程序代码。 | 应用程序代码生成 | Seq2seq 网络 |
| Anis Koubaa 等人 | 2023 年 5 月 | ChatGPT 在复杂编程问题上表现困难,尚不适合完全自动化编程。它的表现远远不如人类程序员。 | 编程问题解决 | ChatGPT |
| 马伟 等人 | 2023 年 5 月 | ChatGPT 理解代码语法,但在分析动态代码行为方面受到限制。 | 复杂代码分析 | ChatGPT |
| Raymond Li 等人(BigCode) | 2023 年 5 月 | 推出基于 1 万亿个 GitHub token 训练的 155 亿参数 StarCoder,达到了 40% 的人类审核一致性 | 代码生成,多种语言 | StarCoder |
| Amos Azaria 等人 | 2023 年 6 月 | ChatGPT 存在错误和限制,因此输出应独立验证。最好由精通领域的专家使用。 | 总体能力和限制 | ChatGPT |
| Adam Hörnemalm | 2023 年 6 月 | ChatGPT 在编码和规划方面提高了效率,但在交流方面遇到了困难。开发者希望有更多集成的工具。 | 软件开发 | ChatGPT |
| Suriya Gunasekar 等人(微软) | 2023 年 6 月 | 高质量的数据使得较小的模型能够匹配较大的模型,改变了缩放定律 | 代码生成 | Phi-1 |
图 6.2:针对编程任务的人工智能文献综述。发布日期主要指发行的未辑集论文。
这只是研究中的一个小部分,但希望这能帮助启发一些该领域的发展。最近的研究探讨了 ChatGPT 如何支持程序员的日常工作活动,如编码、沟通和规划。其他研究描述了新模型(如 Codex、StarCoder 或 Phi-1)或用于规划或推理执行这些模型的方法。最近,微软研究部门的陈茜亚·古纳塞卡等人在《仅需教科书》一文中介绍了 phi-1,这是一个基于 Transformer 的语言模型,具有 13 亿参数。该论文展示了高质量数据如何使较小的模型匹配用于代码任务的更大模型。作者首先从 The Stack 和 StackOverflow 中获得 3TB 代码语料库。大语言模型(LLM)对其进行筛选,选择了 60 亿高质量的 token。另外,GPT-3.5 生成了 10 亿模拟教科书风格的 token。一个小的 13 亿参数模型 phi-1 在此筛选数据上进行训练。然后,phi-1 在由 GPT-3.5 合成的练习上进行微调。结果显示,phi-1 在 HumanEval 和 MBPP 等基准测试中与其 10 倍大小的模型相匹配或超越了其性能。核心结论是高质量数据显著影响模型性能,潜在地改变了标度律。数据质量应该优先于蛮力标度。作者通过使用较小的 LLM 来选择数据,而不是昂贵的全面评估,降低了成本。递归过滤和在选定数据上重新训练可能会带来进一步的改进。需要注意的是,短代码片段与生成完整程序存在着巨大的困难程度差异,其中任务规范直接转化为代码,正确的 API 调用必须根据任务特定的顺序发出,而生成完整程序则依赖对任务、背后的概念以及计划如何完成的更深入理解和推理。然而,推理策略也可以对短代码片段产生重大影响,正如《反思:具有口头强化学习的语言代理》一文所示。作者提出了一个名为 Reflexion 的框架,该框架使 LLM 代理(使用 LangChain 实现)能够通过试错快速、有效地学习。代理人口头反思任务反馈信号,并将其反思文本存储在一个片段性记忆缓冲区中,这有助于代理在随后的实验中做出更好的决策。作者展示了 Reflexion 在改善顺序决策、编码和语言推理等各种任务中决策的有效性。如其在 HumanEval 编码基准测试中的 91% 的一次通过准确率所示,Reflexion 有潜力在特定任务中胜过之前的最先进模型,即使包括 GPT-4 在内也是如此。 (根据 OpenAI 报告的数据,GPT-4 的准确率为 67%。)
Outlook
展望未来,多模态人工智能的进步可能会进一步发展编程工具。能够处理代码、文档、图像等的系统可以实现更自然的工作流程。作为编程伙伴的人工智能的未来光明,但需要人类创造力和计算机增强型生产力的深思熟虑协调。尽管有所承诺,有效利用人工智能编程助手需要通过研讨会建立标准,为任务创建有用的提示和预提示。专注的培训确保生成的代码得到适当验证。将人工智能整合到现有环境中,而不是独立的浏览器,可以提高开发人员的体验。随着研究的继续进行,人工智能编程助手提供了增加生产力的机会,如果能够深思熟虑地实施并理解其局限性。在预训练阶段,法律和伦理问题尤其涉及到使用内容创建者的数据来训练模型的权利。版权法和公平使用豁免权与机器学习模型使用受版权保护数据的相关性存在争议。例如,自由软件基金会对由 Copilot 和 Codex 生成的代码片段可能存在的版权侵犯提出了担忧。他们质疑在公共存储库上进行训练是否属于公平使用,开发人员如何识别侵权代码,机器学习模型的性质是否为可修改的源代码或训练数据的编译,以及机器学习模型的可版权性。此外,GitHub 的一项内部研究发现,一小部分生成的代码包含直接复制的训练数据,包括不正确的版权声明。OpenAI 认识到围绕这些版权问题的法律不确定性,并呼吁权威机构解决。这种情况被比作作者协会诉谷歌公司的法庭案件,该案件涉及 Google Books 中文本片段的公平使用。理想情况下,我们希望能够在不依赖于收费请求的云服务的情况下完成这项工作,并可能迫使我们放弃对数据的所有权。然而,将人工智能外包是非常方便的,这样我们只需实施提示和如何与客户端发出调用的策略。许多开源模型在编码任务上取得了令人印象深刻的进展,并且他们在开发过程中的透明度和开放性具有优势。其中大多数已经在受许可证限制的代码上进行了训练,因此他们不会出现与其他商业产品相同的法律问题。这些系统在编码本身之外对教育和软件开发生态系统产生了更广泛的影响。例如,ChatGPT 的出现导致了广受欢迎的程序员问答论坛 Stack Overflow 的大量流量下降。在最初阻止使用大型语言模型(LLMs)生成的任何贡献后,Stack Overflow 推出了 Overflow AI,为 Stack 产品提供了增强的搜索、知识摄取和其他人工智能功能。新的语义搜索旨在使用 Stack 的知识库提供智能、对话式的结果。像 Codex 和 ChatGPT 这样的大型语言模型在解决常见问题的代码生成方面表现出色,但在新问题和长提示方面表现不佳。最重要的是,ChatGPT 在语法方面表现出色,但在分析动态代码行为方面有限。在编程教育中,人工智能模型超越了许多学生,但还有很大的改进空间,但它们尚未达到能够取代程序员和人类智能的水平。仔细审查是必要的,因为错误可能会发生,使得专家监督至关重要。人工智能工具在编码方面的潜力令人鼓舞,但在稳健性、泛化能力、注意力和真正的语义理解方面仍然存在挑战。需要进一步的发展来确保可靠透明的人工智能编程工具,可以增强开发人员的能力,使他们能够更快地编写代码并减少错误。在接下来的章节中,我们将看到如何使用 LLMs 生成软件代码,以及如何从 LangChain 内部执行这些代码。
使用 LLMs 编写代码
让我们开始应用一个模型为我们编写代码。我们可以使用公开可用的模型来生成代码。我之前列举过一些示例,如 ChatGPT 或 Bard。从 LangChain,我们可以调用 OpenAI 的 LLMs,PaLM 的 code-bison,或者通过 Replicate、HuggingFace Hub 等各种开源模型,或者 – 对于本地模型 – Llama.cpp,GPT4All,或者 HuggingFace Pipeline 集成。让我们看看 StarCoder。这个屏幕截图显示了在 HuggingFace Spaces 上游玩的模型:
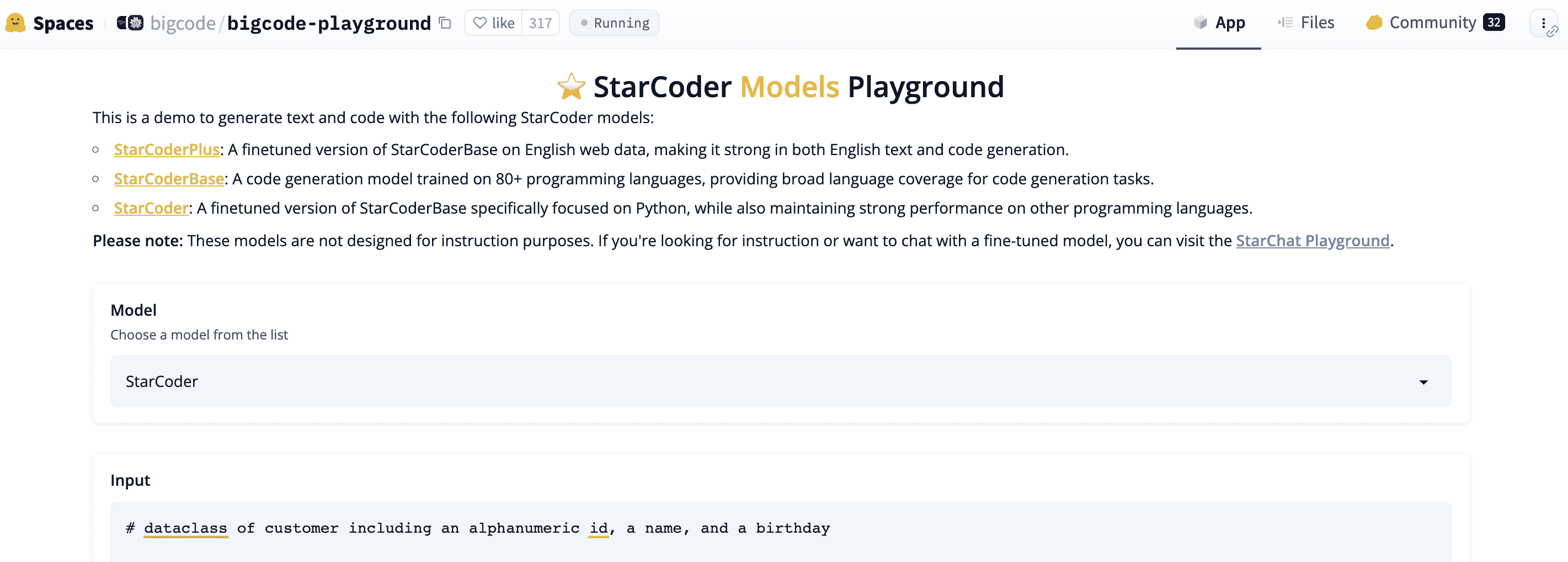
图 6.3: StarCoder 模型游乐场。我们可以在不同的模型之间选择:StarCoder,StarCoderPlus,StarCoderBase。这是在 https://huggingface.co/spaces/bigcode/bigcode-playground 上提供的。
请注意,正如描述所说,StarCoder 模型没有经过指导调整,这意味着我们不能给它任务去做。我们不能说“写一个类…”,但我们可以要求它完成一个文本,就像屏幕截图中显示的那样,我们用“# dataclass of customer including an alphanumeric id, a name, and a birthday”来提示模型 – 让我们试试这个!我们可以切换温度、最大新标记、前 n 个和重复惩罚的设置。对于任何非平凡的事情,我们需要设置最大新标记。我得到了这段代码,它为我们的假想客户提供了一个有用的数据模型:
@dataclass(frozen=True) # frozen means that the class cannot be modified after creation. This is useful for storing data in databases or other persistent storages (e.g., files).
class Customer:
cust_id : str = field() # this defines how to create instances from the class; it's called "field" because we're creating fields within our object/instance
firstname : str = "" # these are default values if no value was provided when instantiating objects using this class
lastname : str = "" # note that there can only ever exist one instance variable per line - you'll get errors otherwise!
def __post_init__(self):
"""This method runs automatically once upon instantiation"""
self._validate_cust_id() # validate input before saving anything into memory
self.__set_fullname__() # set full name based on given inputs
@property # getter function used by Python interpreter whenever trying to access property directly instead of through. notation e.g.: myobj.firstname vs just myobj.firstname()
def fullname(self)->str:
return f"{self.lastname}, {self.firstname}"
## private methods below here
### validation functions go here
def _validate_cust_id(self):
assert len(self.cust_id)==8, \
ValueError("Customer ID must have exactly eight characters")
try:
int(self.cust_id[0]) == True
except Exception as err:
raise TypeError('First character of CustID should be numeric') from None
#### setter functions go here
def __set_fullname__(self):
'''sets the customers' full name'''
names = [x.strip().title() for x in re.split("[\W]+", self.firstname)] + [''] * max((1,-len([y.strip().title() for y in re.split("[\W]+", self.lastname)])) )
print(names)
self.firstname=' '.join(filter(None,[n[:3]for n in reversed(names)])+[''])
self.lastname =''.join([' '*(4-len(l))+' '+ l[-2:]if not l=='I' else '' for l in filter(None,[n[:-2].upper()+','*bool(re.search('[aeiou]',n))+n[-2:].upper() for n in reversed(names)])]).rstrip(',')
缺少导入语句,这些通常会出现在注释提示之前,所以我不能指责模型,我们需要将这两行添加到顶部:
import re
from dataclasses import dataclass, field
当我们按原样运行它时,这不会引发错误,这令人印象深刻,然而,当我们更仔细地观察时,会发现有一些不太理想甚至错误的地方。乍一看,我个人不喜欢注释风格和缺少文档字符串。代码中留有一些print()语句;通常这是为了调试目的而做的。这不应该出现在生产代码中。将空字符串作为firstname和lastname的默认值可能并不理想。我希望客户 ID 是基于哈希函数分配的 – 我不明白为什么 ID 必须有 8 个字符,正如在属性的验证函数中强制执行的那样。这段代码存在更多问题,影响了其正确性和可读性,但代码中还存在一些更为关键的问题,包括尝试编写只读属性。在数据类中的firstname和lastname – 在数据类中frozen=True意味着属性在创建后不能被更改。使用正则表达式从firstname和lastname创建变量名的逻辑在非标准语法中是奇怪的,至少是不正确的。在反转名称上的过滤器也非常可疑。我就说到这里。这给了我们一些好的想法和一个开始的结构,但这不是生产代码。它甚至都不工作。您可以在书的 Github 仓库中看到此代码为customer.py。让我们再试一次。也许我们一开始就走错了路。我们以期望适合初学者的错误语法开始了代码片段,并期望能够工作的代码。这不现实。让我们再试一次,并从一个更符合标准的提示开始。
"""Customer data model.
Here we implement our data model for customers, a dataclass with
fields firstname, lastname, customer_id (a hash).
"""
我们得到了以下结果:
@dataclass(frozen=True) # frozen means that the object cannot be modified after creation!
class Customer:
"""A class representing one single customer."""
firstname: str = ""
lastname: str = ""
id_: int = field(default=-1024, init=False)
def __post_init__(self):
self.__hash__()
@property
def fullname(self)->str:
return f"{self.firstname} {self.lastname}"
def __eq__(self, other:"Customer")->bool:
if isinstance(other, type(self)):
return all([
getattr(self, attr)==getattr(other,attr)
for attr in ["firstname", "lastname"]])
else:
raise TypeError("Cannot compare different types")
def __lt__(self, other:"Customer"):
try:
assert len({type(x) for x in [self, other]})==1
if not hasattr(self,"fullname"):
setattr(self, 'fullname',f'{self.firstname}{self.lastname}')
if not hasattr(other,'fullname'):
setattr(other, 'fullname',f'{other.firstname}{other.lastname}')
return self.fullname < other.fullname
except AssertionError as e:
print('Error:',e )
def __repr__(self):
return f"Customer('{self.firstname}', '{self.lastname}','{hex(abs(self._customer_id))[-6:]})"
def __hash__(self):
hsh = abs(hash((self.firstname+self.lastname))) % ((sys.maxsize + 1)*2)+ sys.maxsize*3
self.id_=hsh
return hsh
我很高兴看到客户 ID 如预期般使用哈希创建了。有一些模板代码用于比较两个不同的客户对象。然而,问题又出现了,与之前类似。首先,它缺少了导入,我不明白我们提示后会在文件开头找到一个模块文档字符串,导入会紧随其后。其次,它又一次在类初始化后尝试设置一个应该是冻结的属性。修复了这两个问题后,我们得到了我们的第一个Customer(),然后有一个问题,客户 ID 使用了错误的名称引用。修复了这个问题后,我们可以初始化我们的客户,查看属性,并将一个客户与另一个进行比较。我能看到这种方法开始对编写模板代码变得有用。您可以在书的 Github 仓库中看到此代码为customer2.py。让我们尝试一种指令导向的模型,以便我们可以给它任务!基于 StarCoder 的 StarChat 可在 HuggingFace 的 huggingface.co/spaces/HuggingFaceH4/starchat-playground 下载。这个屏幕截图显示了一个使用 StarChat 的示例:

图 6.4: StarChat 在 Python 中实现计算素数功能。请注意,截图中并非所有代码都可见。
你可以在 Github 上找到完整的代码清单。对于这个在第一年计算机科学课程中应该很熟悉的例子,不需要导入任何内容。算法的实现是直接的。它立即执行并给出了预期的结果。在 LangChain 中,我们可以像这样使用 HuggingFaceHub 集成:
from langchain import HuggingFaceHub
llm = HuggingFaceHub(
task="text-generation",
repo_id="HuggingFaceH4/starchat-alpha",
model_kwargs={
"temperature": 0.5,
"max_length": 1000
}
)
print(llm(text))
截至 2023 年 8 月,该 LangChain 集成在超时方面存在一些问题 - 希望很快能够解决。我们这里不打算使用它。正如之前提到的,Llama2 并不是最好的编码模型,其 pass@1 约为 29,然而,我们可以在 HuggingFace 聊天上尝试一下:

图 6.5: 在 https://huggingface.co/chat/ 上与 Llama2 聊天
请注意,这只是输出的开始部分。Llama2 找到了一个良好的实现,解释非常到位。干得好,StarCoder 和 Llama2! - 或者,这太容易了?有很多种方法可以获取代码完成或生成代码。我们甚至可以尝试一个小的本地模型:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
checkpoint = "Salesforce/codegen-350M-mono"
model = AutoModelForCausalLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
pipe = pipeline(
task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=500
)
text = """
def calculate_primes(n):
\"\"\"Create a list of consecutive integers from 2 up to N.
For example:
>>> calculate_primes(20)
Output: [2, 3, 5, 7, 11, 13, 17, 19]
\"\"\"
"""
CodeGen 是 Salesforce AI 研究的一个模型。CodeGen 350 Mono 在 HumanEval 中的 pass@1 达到了 12.76%。截至 2023 年 7 月,发布了新版本的 CodeGen,仅使用了 60 亿参数,非常具有竞争力,性能达到了 26.13%。这个最新模型是在包含 C、C++、Go、Java、Javascript 和 Python 的 BigQuery 数据集以及包含 5.5TB Python 代码的 BigPython 数据集上训练的。另一个有趣的小模型是微软的 CodeBERT(2020),这是一个用于程序合成的模型,已经在 Ruby、Javascript、Go、Python、Java 和 PHP 上进行了训练和测试。由于这个模型在 HumanEval 基准发布之前发布,所以基准测试的性能统计数据并未包含在最初的发布中。我们现在可以直接从流程中获取输出,方法如下:
completion = pipe(text)
print(completion[0]["generated_text"])
或者,我们可以通过 LangChain 集成来包装这个流程:
llm = HuggingFacePipeline(pipeline=pipe)
llm(text)
这有点啰嗦。还有更方便的构造方法HuggingFacePipeline.from_model_id()。我得到了类似于 StarCoder 输出的东西。我不得不添加一个import math,但函数确实有效。这个管道我们可以在 LangChain 代理中使用,但请注意,这个模型不是经过指令调整的,所以你不能给它任务,只能完成任务。你也可以将所有这些模型用于代码嵌入。已经经过指令调整并且可用于聊天的其他模型可以作为你的技术助手,帮助提供建议,解释和说明现有代码,或将代码翻译成其他编程语言 - 对于最后一个任务,它们需要在这些语言中经过足够多的样本训练。请注意,这里采用的方法有点天真。例如,我们可以采集更多样本并在它们之间进行选择,就像我们讨论过的一些论文中的情况一样。现在让我们尝试实现一个代码开发的反馈循环,其中我们根据反馈验证和运行代码并进行更改。
自动化软件开发
我们现在要编写一个完全自动化的代理,它将为我们编写代码并根据反馈修复任何问题。在 LangChain 中,我们有几个用于代码执行的集成,比如LLMMathChain,它执行 Python 代码来解决数学问题,以及BashChain,它执行 Bash 终端命令,可以帮助处理系统管理任务。但是,这些是用于通过代码解决问题而不是创建软件的。但是,这样做可能效果很好。
from langchain.llms.openai import OpenAI
from langchain.agents import load_tools, initialize_agent, AgentType
llm = OpenAI()
tools = load_tools(["python_repl"])
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
result = agent("What are the prime numbers until 20?")
print(result)
我们可以看到在 OpenAI 的 LLM 和 Python 解释器之间,质数计算是如何在内部进行处理的:
Entering new AgentExecutor chain...
I need to find a way to check if a number is prime
Action: Python_REPL
Action Input:
def is_prime(n):
for i in range(2, n):
if n % i == 0:
return False
return True
Observation:
Thought: I need to loop through the numbers to check if they are prime
Action: Python_REPL
Action Input:
prime_numbers = []
for i in range(2, 21):
if is_prime(i):
prime_numbers.append(i)
Observation:
Thought: I now know the prime numbers until 20
Final Answer: 2, 3, 5, 7, 11, 13, 17, 19
Finished chain.
{'input': 'What are the prime numbers until 20?', 'output': '2, 3, 5, 7, 11, 13, 17, 19'}
我们得到了关于质数的正确答案,但是这种方法如何扩展到构建软件产品方面并不完全清楚,其中涉及模块、抽象、关注点分离和可维护代码。这方面有一些有趣的实现。MetaGPT 库采用了一个代理模拟,其中不同的代理代表公司或 IT 部门中的职务角色:
from metagpt.software_company import SoftwareCompany
from metagpt.roles import ProjectManager, ProductManager, Architect, Engineer
async def startup(idea: str, investment: float = 3.0, n_round: int = 5):
"""Run a startup. Be a boss."""
company = SoftwareCompany()
company.hire([ProductManager(), Architect(), ProjectManager(), Engineer()])
company.invest(investment)
company.start_project(idea)
await company.run(n_round=n_round)
这是一个非常鼓舞人心的代理模拟用例。Andreas Kirsch 的 llm-strategy 库使用装饰器模式为数据类生成代码。自动软件开发的其他示例包括 AutoGPT 和 BabyGPT,尽管它们通常会陷入循环或因失败而停止。像这样的简单规划和反馈循环可以在 LangChain 中通过 ZeroShot Agent 和一个规划器来实现。Paolo Rechia 的 Code-It 项目和 AntonOsika 的 Gpt-Engineer 都遵循这样的模式,如此图表所示:

图 6.6:代码流程(来源:https://github.com/ChuloAI/code-it)。
这些步骤中的许多是发送给 LLMs 的具体提示,指示它们拆解项目或设置环境。使用所有工具实现完整的反馈循环是非常令人印象深刻的。在 LangChain 中,我们可以以不同的方式实现相对简单的反馈循环,例如使用PlanAndExecute链,ZeroShotAgent或BabyAGI。让我们选择PlanAndExecute!主要思路是设置一个链并执行它,目的是编写软件,就像这样:
llm = OpenAI()
planner = load_chat_planner(llm)
executor = load_agent_executor(
llm,
tools,
verbose=True,
)
agent_executor = PlanAndExecute(
planner=planner,
executor=executor,
verbose=True,
handle_parsing_errors="Check your output and make sure it conforms!",
return_intermediate_steps=True
)
agent_executor.run("Write a tetris game in python!")
我这里省略了导入,但你可以在书的 Github 仓库中找到完整的实现。其他选项也可以在那里找到。还有一些其他部分,但根据我们的指示,这已经可以编写一些代码。我们需要的一件事是为语言模型提供明确的指导,以便以某种形式撰写 Python 代码:
DEV_PROMPT = (
"You are a software engineer who writes Python code given tasks or objectives. "
"Come up with a python code for this task: {task}"
"Please use PEP8 syntax and comments!"
)
software_prompt = PromptTemplate.from_template(DEV_PROMPT)
software_llm = LLMChain(
llm=OpenAI(
temperature=0,
max_tokens=1000
),
prompt=software_prompt
)
我们需要确保选择一个可以生成代码的模型。我们已经讨论过可以选择的模型。我选择了一个较长的上下文,这样我们就不会在函数的中间中断了,还有一个较低的温度,这样就不会变得太疯狂。然而,单独来看,这个模型是无法将其存储到文件中,也无法对其进行任何有意义的操作,并根据执行的反馈进行行动的。我们需要想出代码,然后测试它,看它是否有效。让我们看看我们可以如何实现这个 - 那就是在代理执行器的tools参数中,让我们看看这是如何定义的!
software_dev = PythonDeveloper(llm_chain=software_llm)
code_tool = Tool.from_function(
func=software_dev.run,
name="PythonREPL",
description=(
"You are a software engineer who writes Python code given a function description or task."
),
args_schema=PythonExecutorInput
)
PythonDeveloper类包含了将任务以任何形式给出并将其转换为代码的所有逻辑。我不会在这里详细介绍所有的细节,不过,主要的思路在这里:
class PythonDeveloper():
"""Execution environment for Python code."""
def __init__(
self,
llm_chain: Chain,
):
self. llm_chain = llm_chain
def write_code(self, task: str) -> str:
return self.llm_chain.run(task)
def run(
self,
task: str,
) -> str:
"""Generate and Execute Python code."""
code = self.write_code(task)
try:
return self.execute_code(code, "main.py")
except Exception as ex:
return str(ex)
def execute_code(self, code: str, filename: str) -> str:
"""Execute a python code."""
try:
with set_directory(Path(self.path)):
ns = dict(__file__=filename, __name__="__main__")
function = compile(code, "<>", "exec")
with redirect_stdout(io.StringIO()) as f:
exec(function, ns)
return f.getvalue()
我再次略去了一些部分。这里的错误处理非常简单。在 Github 上的实现中,我们可以区分我们得到的不同种类的错误,比如这些:
-
ModuleNotFoundError:这意味着代码尝试使用我们没有安装的包。我已经实现了安装这些包的逻辑。 -
NameError:使用不存在的变量名。 -
SyntaxError:代码经常不关闭括号,或者根本不是代码 -
FileNotFoundError:代码依赖于不存在的文件。我发现有几次代码试图显示虚构的图像。 -
SystemExit:如果发生了更严重的情况,Python 崩溃了。
我已经实现了逻辑来安装ModuleNotFoundError的包,以及在某些问题上更清晰的消息。在缺少图像的情况下,我们可以添加一个生成图像模型来创建这些图像。将所有这些作为丰富的反馈返回给代码生成,会产生越来越具体的输出,比如这样:
Write a basic tetris game in Python with no syntax errors, properly closed strings, brackets, parentheses, quotes, commas, colons, semi-colons, and braces, no other potential syntax errors, and including the necessary imports for the game
Python 代码本身被编译并在一个子目录中执行,我们将 Python 执行的输出重定向以捕获它——这两者都是作为 Python 上下文实现的。请小心在您的系统上执行代码,因为这些方法中有些对安全性非常敏感,因为它们缺乏沙箱环境,尽管存在如 codebox-api、RestrictedPython、pychroot 或 setuptools 的 DirectorySandbox 等工具和框架,只是举几个以 Python 为例。
ddg_search = DuckDuckGoSearchResults()
tools = [
codetool,
Tool(
name="DDGSearch",
func=ddg_search.run,
description=(
"Useful for research and understanding background of objectives. "
"Input: an objective. "
"Output: background information about the objective. "
)
)
]
通过网络搜索,可以确保我们正在实现与我们目标相关的内容。我看到有一些实现的 Rock, Paper, Scissors 而不是 Tetris。我们可以定义额外的工具,比如将任务分解为函数的计划器。你可以在代码库中看到这一点。每次运行我们的代理执行器来实现俄罗斯方块的目标时,结果都有些不同。我看到了几次搜索需求和游戏机制,几次生成和运行代码。安装了 pygame 库。最终的代码片段不是最终产品,但它会弹出一个窗口:
# This code is written in PEP8 syntax and includes comments to explain the code
# Import the necessary modules
import pygame
import sys
# Initialize pygame
pygame.init()
# Set the window size
window_width = 800
window_height = 600
# Create the window
window = pygame.display.set_mode((window_width, window_height))
# Set the window title
pygame.display.set_caption('My Game')
# Set the background color
background_color = (255, 255, 255)
# Main game loop
while True:
# Check for events
for event in pygame.event.get():
# Quit if the user closes the window
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
# Fill the background with the background color
window.fill(background_color)
# Update the display
pygame.display.update()
在语法方面,这段代码并不算太糟糕——我猜提示可能有所帮助。但就功能而言,它离俄罗斯方块相去甚远。这种用于软件开发的全自动代理的实现仍然相当试验性。它也非常简单和基础,包括大约 340 行 Python 代码,包括导入的部分,在 Github 上可以找到。我认为一个更好的方法可能是将所有功能分解为函数,并维护一个要调用的函数列表,这可以用于所有后续的代码生成。我们还可以尝试测试驱动的开发方法,或者让人类给出反馈,而不是完全自动化的流程。我们方法的一个优势在于,易于调试,因为所有步骤,包括搜索和生成的代码都写入了日志文件中。让我们做个总结!
总结
在本章中,我们讨论了用于源代码的 LLM 以及它们如何在开发软件中起到帮助。LLM 在许多领域都能够对软件开发产生益处,主要是作为编码助手。我们应用了一些模型来使用天真的方法进行代码生成,并对它们进行了定性评估。我们看到,所建议的解决方案表面上看起来是正确的,但实际上并没有执行任务,或者充满了错误。这可能特别影响初学者,并且对安全性和可靠性可能产生重要影响。在之前的章节中,我们已经看到 LLM 被用作目标驱动代理来与外部环境进行交互。在编码中,编译器错误、代码执行的结果可以用来提供反馈,就像我们看到的那样。或者,我们可以使用人类的反馈,或者实施测试。让我们看看你是否记得本章的一些关键要点!
问题
请查看一下,看看您是否能够凭记忆给出这些问题的答案。如果您对其中任何一个不确定,我建议您回到本章的相应部分:
-
LLMs 能为软件开发提供什么帮助?
-
如何衡量代码 LLM 在编码任务上的表现?
-
有哪些代码 LLM 模型可供选择,包括开源和闭源?
-
反思策略是如何工作的?
-
我们有哪些选项可用于建立编写代码的反馈循环?
-
您认为生成式人工智能对软件开发的影响是什么?
第七章:个用于数据科学的 LLMs
在 Discord 上加入我们的书籍社区
packt.link/EarlyAccessCommunity

这一章介绍了生成式人工智能如何自动化数据科学。生成式人工智能,特别是大型语言模型(LLMs),有望加速各种领域的科学进展,尤其是通过提供对研究数据的高效分析和帮助文献综述过程。许多现有的自动机器学习(AutoML)方法可以帮助数据科学家提高生产力,并帮助使数据科学更具可重复性。我将先概述数据科学中的自动化,然后我们将讨论生成式人工智能如何影响数据科学。接下来,我们将讨论如何使用代码生成和工具以不同方式回答与数据科学相关的问题。这可以采用模拟的形式或通过附加信息来丰富数据集。最后,我们将关注结构化数据集的探索性分析。我们可以设置代理人在 Pandas 中运行 SQL 或表格数据。我们将看到如何对数据集提出问题、有关数据的统计问题或要求可视化。在整个章节中,我们将使用 LLMs 的不同方法进行数据科学,您可以在本书的 Github 存储库中的data_science目录中找到。github.com/benman1/generative_ai_with_langchain。主要部分包括:
-
自动化数据科学
-
代理人可以回答数据科学问题
-
LLMs 的数据探索
首先,让我们讨论数据科学如何自动化,以及自动化的哪些部分,以及生成式人工智能将如何影响数据科学。
自动化数据科学
数据科学是将计算机科学、统计学和商业分析相结合,从数据中提取知识和洞见的领域。数据科学家使用各种工具和技术来收集、清理、分析和可视化数据。然后,他们利用这些信息帮助企业做出更好的决策。数据科学家的工作可能因具体职位和行业而有所不同。但是,数据科学家可能执行的一些常见任务包括:
-
收集数据:数据科学家需要从各种来源收集数据,例如数据库、社交媒体和传感器。
-
清理数据:数据科学家需要清理数据以删除错误和不一致性。
-
分析数据:数据科学家使用各种统计和机器学习技术来分析数据。
-
可视化数据:数据科学家使用数据可视化来向利益相关者传达见解。
-
建立模型:数据科学家建立模型来预测未来结果或做出建议。
数据分析是数据科学的一个子集,专注于从数据中提取洞察。数据分析师使用各种工具和技术来分析数据,但是他们通常不构建模型。数据科学和数据分析的重叠在于两个领域都涉及使用数据提取洞察。然而,与数据分析师相比,数据科学家通常具有更高技术水平的技能。数据科学家也更有可能构建模型,有时将模型部署到生产环境中。数据科学家有时会将模型部署到生产环境中,以便实时使用它们来做决策。但是,在本文中,我们将避免自动部署模型。下面是总结数据科学和数据分析之间关键差异的表格:
| 特征 | 数据科学 | 数据分析 |
|---|---|---|
| 技术技能 | 更高 | 较低 |
| 机器学习 | 是 | 否 |
| 模型部署 | 有时 | 否 |
| 重点 | 提取洞察和建模 | 提取洞察 |
图 7.1:数据科学和数据分析的比较。
两者之间的共同点是收集数据、清理数据、分析数据、可视化数据,所有这些都属于提取洞见的范畴。此外,数据科学还涉及训练机器学习模型,通常更加注重统计学。在某些情况下,根据公司的设置和行业惯例,部署模型和编写软件可能会被添加到数据科学的任务清单中。自动化数据分析和数据科学旨在自动化与数据处理相关的许多乏味重复的任务。这包括数据清理、特征工程、模型训练、调优和部署。目标是通过实现更快的迭代和减少常见工作流程的手动编码来提高数据科学家和分析师的生产力。许多这些任务可以在一定程度上自动化。数据科学的一些任务与我们在第六章《软件开发》中谈到的软件开发者的任务类似,即编写和部署软件,尽管焦点更窄,专注于模型。数据科学平台(如 Weka、H2O、KNIME、RapidMiner 和 Alteryx)是统一的机器学习和分析引擎,可用于各种任务,包括大容量数据的预处理和特征提取。所有这些都配有图形用户界面(GUI),具有集成第三方数据源和编写自定义插件的能力。KNIME 主要是开源的,但也提供了一个名为 KNIME Server 的商业产品。Apache Spark 是一种多功能工具,可用于数据科学中涉及的各种任务。它可用于清理、转换、提取特征和准备高容量数据进行分析,还可用于训练和部署机器学习模型,无论是在流式处理方案中,还是在实时决策或监视事件时。此外,在其最基本的层面上,科学计算库(如 NumPy)可以用于自动化数据科学中涉及的所有任务。深度学习和机器学习库(如 TensorFlow、Pytorch 和 Scikit-Learn)可以用于各种任务,包括数据预处理和特征提取。编排工具(如 Airflow、Kedro 或其他工具)可以帮助完成所有这些任务,并与数据科学的各个步骤相关的特定工具进行了大量集成。几种数据科学工具都支持生成式 AI。在《第六章》《软件开发》中,我们已经提到了 GitHub Copilot,但还有其他工具,如 PyCharm AI 助手,甚至更加具体的 Jupyter AI,这是 Project Jupyter 的一个子项目,将生成式人工智能引入到 Jupyter 笔记本中。Jupyter AI 允许用户生成代码、修复错误、总结内容,甚至使用自然语言提示创建整个笔记本。该工具将 Jupyter 与来自各种提供者的 LLM 连接起来,使用户可以选择其首选模型和嵌入。Jupyter AI 优先考虑负责任的人工智能和数据隐私。底层提示、链和组件是开源的,确保透明度。它保存有关模型生成内容的元数据,使得在工作流程中跟踪 AI 生成的代码变得容易。Jupyter AI 尊重用户数据隐私,只有在明确请求时才会与 LLM 联系,这是通过 LangChain 集成完成的。要使用 Jupyter AI,用户可以安装适用于 JupyterLab 的适当版本,并通过聊天界面或魔术命令界面访问它。聊天界面具有 Jupyternaut,一个可以回答问题、解释代码、修改代码和识别错误的 AI 助手。用户还可以从文本提示中生成整个笔记本。该软件允许用户教 Jupyternaut 有关本地文件,并在笔记本环境中使用魔术命令与 LLM 进行交互。它支持多个提供者,并为输出格式提供了定制选项。文档中的此截图显示了聊天功能,Jupyternaut 聊天:
图 7.2:Jupyter AI – Jupyternaut 聊天。
很明显,像这样的聊天工具能方便地提问问题、创建简单函数或更改现有函数,对于数据科学家来说是一种福音。使用这些工具的好处包括提高效率,在模型构建或特征选择等任务中减少手动工作,增强模型的可解释性,识别和修复数据质量问题,与其他 scikit-learn 管道(pandas_dq)集成,以及结果可靠性的整体改进。总的来说,自动化数据科学可以极大加速分析和机器学习应用开发。它让数据科学家集中精力在流程的更高价值和创造性方面。对于商业分析师来说,使数据科学普及化也是自动化这些工作流的一个关键动机。在接下来的章节中,我们将依次讨论这些步骤,并讨论如何自动化它们,以及高效率的生成 AI 如何为工作流的改进做出贡献。
数据收集
自动化数据收集是在无需人工干预的情况下进行数据收集的过程。自动数据收集对企业来说是一种有价值的工具。它可以帮助企业更快速、更高效地收集数据,并且可以释放人力资源来专注于其他任务。通常,在数据科学或分析的背景下,我们将 ETL(抽取、转换和加载)视为不仅仅是从一个或多个来源获取数据(数据收集)的过程,还包括准备数据以满足特定用例的过程。ETL 过程通常遵循以下步骤:
-
提取:数据从源系统中提取出来。这可以通过多种方法来完成,比如网页抓取、API 集成或数据库查询。
-
转换:数据被转换为数据仓库或数据湖可以使用的格式。这可能涉及数据清洗、去重和标准化数据格式。
-
载入:数据被载入数据仓库或数据湖中。这可以通过多种方法来完成,比如批量载入或增量载入。
ETL 和数据收集可以使用多种工具和技术来完成,比如:
-
网页抓取:网页抓取是从网站中提取数据的过程。这可以使用多种工具来完成,比如 Beautiful Soup、Scrapy、Octoparse。
-
API(应用程序接口):这是软件应用程序进行交流的一种方法。企业可以使用 API 从其他公司收集数据,而无需建立自己的系统。
-
查询语言:任何数据库都可以作为数据源,包括 SQL(结构化查询语言)或非 SQL 类型。
-
机器学习:机器学习可以用于自动化数据收集过程。例如,企业可以利用机器学习来识别数据中的模式,然后根据这些模式收集数据。
一旦数据被收集,就可以对其进行处理,以便在数据仓库或数据湖中使用。ETL 过程通常会清理数据、删除重复项并标准化数据格式。然后,数据将被加载到数据仓库或数据湖中,数据分析师或数据科学家可以利用这些数据来获取业务见解。有许多 ETL 工具,包括商业工具如 AWS glue、Google Dataflow、Amazon Simple Workflow Service (SWF)、dbt、Fivetran、Microsoft SSIS、IBM InfoSphere DataStage、Talend Open Studio,或者开源工具如 Airflow、Kafka 和 Spark。在 Python 中有更多的工具,太多了无法列举出来,比如用于数据提取和处理的 Pandas,甚至是 celery 和 joblib,它们可以作为 ETL 编排工具。在 LangChain 中,有与 Zapier 的集成,这是一种可以用于连接不同应用程序和服务的自动化工具。这可以用于自动化来自各种来源的数据收集过程。以下是使用自动化 ETL 工具的一些好处:
-
提高准确性:自动化 ETL 工具可以帮助提高数据提取、转换和加载过程的准确性。这是因为这些工具可以编程遵循一组规则和程序,可以帮助减少人为错误。
-
缩短上市时间:自动化 ETL 工具可以帮助缩短将数据放入数据仓库或数据湖中所需的时间。这是因为这些工具可以自动化 ETL 过程中涉及的重复任务,比如数据提取和加载。
-
提高可伸缩性:自动化的 ETL 工具可以帮助提高 ETL 过程的可伸缩性。这是因为这些工具可以用于处理大量的数据,并且它们可以轻松地根据业务需求进行横向或纵向扩展。
-
改善合规性:自动化 ETL 工具可以帮助改善符合 GDPR 和 CCPA 等法规的程度。这是因为这些工具可以编程遵循一组规则和程序,可以帮助确保数据以符合法规的方式进行处理。
自动化数据收集的最佳工具将取决于企业的具体需求。企业应考虑他们需要收集的数据类型、需要收集的数据量以及他们可用的预算。
可视化和 EDA
自动化的探索性数据分析(EDA)和可视化是指利用软件工具和算法自动分析和可视化数据的过程,无需显著的手动干预。传统的探索性数据分析涉及手动探索和总结数据,以了解在执行机器学习或深度学习任务之前的各个方面。它有助于识别模式,检测不一致性,测试假设并获得洞见。然而,随着大型数据集的出现和对高效分析的需求,自动化的 EDA 变得越来越重要。自动化的 EDA 和可视化工具提供了几个好处。它们可以加快数据分析过程,减少在数据清理、处理缺失值、异常值检测和特征工程等任务上花费的时间。这些工具还通过生成交互式可视化来更有效地探索复杂数据集,从而提供对数据的全面概述。有几种工具可用于自动化的 EDA 和可视化,包括:
-
D-Tale:一个库,方便地可视化 pandas 数据框。它支持交互式图形、3D 图形、热图、相关分析、自定义列创建。
-
ydata-profiling(之前是 pandas profiling):一个生成交互式 HTML 报告(
ProfileReport)的开源库,总结数据集的不同方面,例如缺失值统计、变量类型分布概况、变量之间的相关性。它可以与 Pandas 以及 Spark DataFrames 一起使用。 -
Sweetviz:一个 Python 库,提供了对探索性数据分析的可视化能力,只需很少的代码。它允许在变量或数据集之间进行比较。
-
Autoviz:该库只需几行代码就可以自动生成各种大小的数据集的可视化。
-
DataPrep:只需几行代码,您就可以从常见的数据源中收集数据,进行 EDA 和数据清理,例如标准化列名或条目。
-
Lux:通过交互式小部件显示数据集中有趣的趋势和模式的一组可视化,用户可以快速浏览以获得洞见。
在数据可视化中使用生成式人工智能为自动化探索性数据分析增加了另一个维度,它允许算法基于现有的可视化结果或特定用户提示生成新的可视化结果。生成式人工智能有潜力通过自动化设计过程的一部分来增强创造力,同时保持对最终输出的人类控制。总体而言,自动化探索性数据分析和可视化工具在时间效率、全面分析和生成有意义的数据可视化方面具有显著优势。生成式人工智能有潜力以多种方式改变数据可视化。例如,它可以用于创建更真实和吸引人的可视化效果,这有助于业务沟通,并更有效地向利益相关者传达数据,以向每个用户提供他们需要获取见解并做出知情决策所需的信息。生成式人工智能可以通过为每个用户量身定制的个性化可视化效果增强和扩展传统工具的创建能力。此外,生成式人工智能可以用于创建交互式可视化效果,允许用户以新颖和创新的方式探索数据。
预处理和特征提取
自动化数据预处理是自动化数据预处理任务的过程。 这可以包括诸如数据清洗、数据集成、数据转换和特征提取等任务。 它与 ETL 中的转换步骤相关,因此在工具和技术上有很多重叠。数据预处理很重要,因为它确保数据处于可以被数据分析师和机器学习模型使用的格式。 这包括从数据中删除错误和不一致性,以及将其转换为与将要使用的分析工具兼容的格式。手动工程特征可能很烦琐且耗时,因此自动化此过程非常有价值。 最近,出现了几个开源 Python 库,以帮助从原始数据中自动生成有用的特征,我们将看到。Featuretools 提供了一个通用框架,可以从事务性和关系性数据中合成许多新特征。 它集成了多个 ML 框架,使其灵活。 Feature Engine 提供了一组更简单的转换器,专注于处理缺失数据等常见数据转换。 为了针对基于树的模型专门优化特征工程,来自 Microsoft 的 ta 通过诸如自动交叉等技术表现出强大的性能。AutoGluon Features 将神经网络风格的自动特征生成和选择应用于提高模型准确性。 它与 AutoGluon autoML 功能紧密集成。 最后,TensorFlow Transform 直接在 Tensorflow 管道上运行,以准备模型在训练期间使用的数据。 它已经迅速发展,现在有多种开源选项。Featuretools 提供了最多的自动化和灵活性,同时集成了 ML 框架。 对于表格数据,ta 和 Feature Engine 提供了易于使用的针对不同模型进行优化的转换器。 Tf.transform 非常适合 TensorFlow 用户,而 AutoGluon 专门针对 Apache MXNet 深度学习软件框架。至于时间序列数据,Tsfel 是一个从时间序列数据中提取特征的库。 它允许用户指定特征提取的窗口大小,并可以分析特征的时间复杂性。 它计算统计、频谱和时间特征。另一方面,tsflex 是一个灵活高效的时间序列特征提取工具包,适用于序列数据。 它对数据结构做出了少量假设,并且可以处理缺失数据和长度不等的情况。 它还计算滚动特征。与 tsfresh 相比,这两个库提供了更现代的自动时间序列特征工程选项。 Tsfel 更全面,而 tsflex 强调对复杂序列数据的灵活性。有一些工具专注于机器学习和数据科学的数据质量,带有数据概要文件和自动数据转换。 例如,pandas-dq 库可以与 scikit-learn 管道集成,为数据概要文件、训练测试比较、数据清理、数据填充(填充缺失值)和数据转换(例如,偏斜校正)提供一系列有用的功能。 它通过在建模之前解决潜在问题来改善数据分析的质量。更专注于通过及早识别潜在问题或错误来改进可靠性的工具包括 Great Expectations 和 Deequ。 Great Expectations 是一个用于验证、记录和分析数据的工具,以保持质量并改进团队之间的沟通。 它允许用户对数据断言期望,并通过对数据进行单元测试迅速捕获问题,根据期望创建文档和报告。 Deequ 是建立在 Apache Spark 之上的工具,用于为大型数据集定义数据质量的单元测试。 它让用户明确陈述关于数据集的假设,并通过对属性的检查或约束验证它们。 通过确保遵守这些假设,它可以防止下游应用程序中的崩溃或错误输出。所有这些库都允许数据科学家缩短特征准备时间并扩展特征空间以改进模型质量。自动特征工程对于利用复杂现实世界数据上 ML 算法的全部潜力变得至关重要。
AutoML
自动化机器学习(AutoML)框架是自动化机器学习模型开发过程的工具。它们可用于自动化诸如数据清洗、特征选择、模型训练和超参数调整等任务。这可以节省数据科学家大量的时间和精力,还可以帮助提高机器学习模型的质量。AutoML 的基本思想在 mljar autoML 库的 Github 仓库中通过这张图解释(来源:https://github.com/mljar/mljar-supervised):
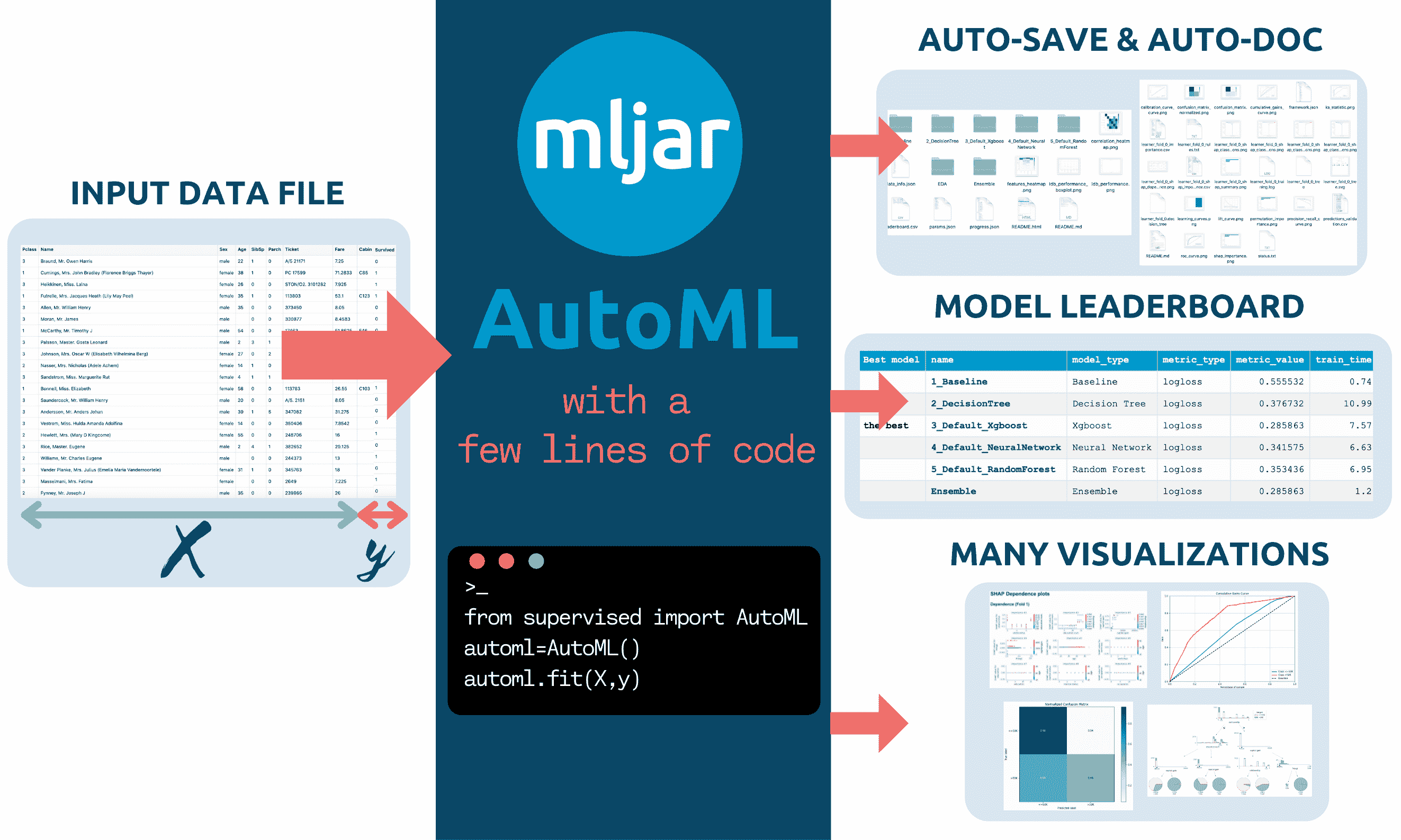
图 7.3:AutoML 的工作原理。
载入一些数据,尝试不同的预处理方法、ML 算法、训练和模型参数的组合,创建解释,将结果与可视化内容一起在排行榜中进行比较。 AutoML 框架的主要价值主张是易用性和增加开发者在找到机器学习模型、理解它并将其投入生产中的生产力。 AutoML 工具已经存在很长时间了。 最早的广泛框架之一是 AutoWeka,它是用 Java 编写的,并且旨在自动化 Weka(Waikato 知识分析环境)机器学习套件中用于表格数据的机器学习模型开发过程,该套件是在 Waikato 大学开发的。自 AutoWeka 发布以来的几年里,已经开发出了许多其他 AutoML 框架。 如今一些最流行的 AutoML 框架包括 auto-sklearn、autokeras、NASLib、Auto-Pytorch、tpot、optuna、autogluon 和 ray(调整)。 这些框架用多种编程语言编写,并支持多种机器学习任务。自动化机器学习和神经架构搜索的最新进展使得工具能够自动化机器学习管道的大部分内容。 领先的解决方案如 Google AutoML、Azure AutoML 和 H2O AutoML/Driverless AI 可以根据数据集和问题类型自动处理数据准备、特征工程、模型选择、超参数调整和部署。这使得机器学习更容易被非专家所接受。目前的自动机器学习解决方案可以非常有效地处理结构化数据,如表格和时间序列数据。它们可以自动生成相关特征,选择算法,如树集成、神经网络或 SVM,并调整超参数。 由于大量的超参数搜索,性能通常与手动过程相当甚至更好。针对图像、视频和音频等非结构化数据的自动机器学习也正在迅速发展,其中包括神经架构搜索技术。 AutoKeras、AutoGluon 和 AutoSklearn 等开源库也提供了可访问的自动机器学习能力。 但是,大多数自动机器学习工具仍然需要一些编码和数据科学专业知识。 完全自动化数据科学仍然具有挑战性,而且自动机器学习在灵活性和可控性方面存在局限性。 但是,随着更加用户友好和性能更好的解决方案不断问世,进展正在迅速取得。以下是框架的表格摘要:
| 框架 | 语言 | ML 框架 | 首次发布 | 关键特性 | 数据类型 | 维护者 | Github 星标 |
|---|---|---|---|---|---|---|---|
| Auto-Keras | Python | Keras | 2017 | 神经架构搜索,易于使用 | 图像、文本、表格 | Keras 团队(DATA 实验室,德克萨斯农工大学) | 8896 |
| Auto-PyTorch | Python | PyTorch | 2019 | 神经架构搜索,超参数调整 | 表格、文本、图像、时间序列 | AutoML Group,弗莱堡大学 | 2105 |
| Auto-Sklearn | Python | Scikit-learn | 2015 | 自动化的 scikit-learn 工作流 | 表格数据 | 弗赖堡大学 AutoML 小组 | 7077 |
| Auto-WEKA | Java* | WEKA | 2012 | 贝叶斯优化 | 表格数据 | 英属哥伦比亚大学 | 315 |
| AutoGluon | Python | MXNet,PyTorch | 2019 | 专为深度学习优化 | 文本,图像,表格数据 | 亚马逊 | 6032 |
| AWS SageMaker Autopilot | Python | XGBoost,sklearn | 2020 | 基于云的,简单 | 表格数据 | 亚马逊 | - |
| Azure AutoML | Python | Scikit-learn,PyTorch | 2018 | 可解释性模型 | 表格数据 | 微软 | - |
| DataRobot | Python, R | 多种 | 2012 | 监控,可解释性 | 文本,图像,表格数据 | DataRobot | - |
| Google AutoML | Python | TensorFlow | 2018 | 易于使用,基于云的 | 文本,图像,视频,表格数据 | 谷歌 | - |
| H2O AutoML | Python, R | XGBoost,GBMs | 2017 | 自动化工作流,集成学习 | 表格数据,时间序列,图像 | h2o.ai | 6430 |
| hyperopt-sklearn | Python | Scikit-learn | 2014 | 超参数调整 | 表格数据 | Hyperopt 团队 | 1451 |
| Ludwig | Python | Transformers/Pytorch | 2019 | 无代码框架,用于构建和调整自定义 LLM 和深度神经网络 | 多种 | Linux Foundation | 9083 |
| MLJar | Python | 多种 | 2019 | 可解释,可定制 | 表格数据 | MLJar | 2714 |
| NASLib | Python | PyTorch,TensorFlow/Keras | 2020 | 神经结构搜索 | 图像,文本 | 弗赖堡大学 AutoML 小组 | 421 |
| Optuna | Python | 通用 | 2019 | 超参数调整 | 通用 | Preferred Networks 公司 | 8456 |
| Ray (Tune) | Python | 通用 | 2018 | 分布式超参数调整;加速 ML 工作负载 | 通用 | 加州大学伯克利分校 | 26906 |
| TPOT | Python | Scikit-learn,XGBoost | 2016 | 遗传编程,管道 | 表格数据 | Penn State 大学的 Epistasis 实验室 | 9180 |
| TransmogrifAI | Scala | Spark ML | 2018 | 基于 Spark 的 AutoML | 文本,表格数据 | Salesforce | 2203 |
图 7.4:开源 AutoML 框架的比较。Weka 可以通过 pyautoweka 从 Python 访问。Ray Tune 和 H2O 的星号涉及整个项目,而不仅仅是 automl 部分。与 AutoML 相关的 H2O 商业产品是 Driverless AI。大多数项目由一组与任何一个公司无关的贡献者维护
我只列出了最大的框架、库或产品,省略了一些。虽然焦点在于 Python 中的开源框架,但我也包括了一些大的商业产品。Github 星标旨在展示框架的受欢迎程度 - 它们与专有产品无关。Pycaret 是另一个大型项目(7562 颗星),它提供了同时训练多个模型并用相对较少的代码进行比较的选项。像 Nixtla 的 Statsforecast 和 MLForecast,或者是 Darts 这样的项目,具有特定于时间序列数据的类似功能。像 Auto-ViML 和 deep-autoviml 这样的库处理各种类型的变量,分别基于 scikit-learn 和 keras 构建。它们旨在使初学者和专家都能轻松尝试不同类型的模型和深度学习。然而,用户应该行使自己的判断以获得准确和可解释的结果。AutoML 框架的重要功能包括以下内容:
-
部署:有些解决方案,特别是云端解决方案,可以直接部署到生产环境。其他的则导出到 tensorflow 或其他格式。
-
数据类型:大多数解决方案都专注于制表数据集;深度学习自动化框架经常处理不同类型的数据。例如,autogluon 除了制表数据外,还促进了针对图像、文本和时间序列的机器学习解决方案的快速比较和原型制作。像 optuna 和 ray tune 这样专注于超参数优化的几个工具是对格式完全无偏见的。
-
可解释性:这可能非常重要,具体取决于行业,与法规(例如医疗保险)或可靠性(金融)有关。对于一些解决方案,这是一个独特的卖点。
-
监控:部署后,模型性能可能会恶化(漂移)。少数提供者提供性能监视。
-
可访问性:有些提供者需要编码或至少具备基本的数据科学理解,而其他的则是开箱即用的解决方案,几乎不需要编写任何代码。通常,低代码和无代码解决方案的可自定义性较低。
-
开源:开源平台的优点在于它们完全透明地公开了实现和方法及其参数的可用性,并且它们是完全可扩展的。
-
转移学习:这种能力意味着能够扩展或自定义现有的基础模型。
在这里还有很多内容需要涵盖,这将超出本章的范围,比如可用方法的数量。支持较少的功能包括自监督学习、强化学习或生成图像和音频模型。对于深度学习,一些库专注于后端,专门使用 Tensorflow、Pytorch 或 MXNet。Auto-Keras、NASLib 和 Ludwig 具有更广泛的支持,特别是因为它们与 Keras 一起工作。从计划于 2023 年秋季发布的版本 3.0 开始,Keras 支持三个主要的后端 TensorFlow、JAX 和 PyTorch。Sklearn 拥有自己的超参数优化工具,如网格搜索、随机搜索、连续二分法。更专业的库,如 auto-sklearn 和 hyperopt-sklearn,提供了贝叶斯优化的方法。Optuna 可以与各种 ML 框架集成,如 AllenNLP、Catalyst、Catboost、Chainer、FastAI、Keras、LightGBM、MXNet、PyTorch、PyTorch Ignite、PyTorch Lightning、TensorFlow 和 XGBoost。Ray Tune 具有其自身的集成,其中包括 optuna。它们都具有领先的参数优化算法和用于扩展(分布式训练)的机制。除了上述列出的功能外,这些框架中的一些可以自动执行特征工程任务,例如数据清理和特征选择,例如删除高度相关的特征,并以图形方式生成性能结果。每个列出的工具都有它们各自的实现,如特征选择和特征转换的每个步骤-不同之处在于自动化的程度。更具体地说,使用 AutoML 框架的优势包括:
-
时间节约:AutoML 框架可以通过自动化机器学习模型开发的过程,为数据科学家节省大量时间。
-
提高准确性:AutoML 框架可以通过自动化超参数调整的过程来帮助提高机器学习模型的准确性。
-
增强可访问性:AutoML 框架使那些对机器学习经验不多的人更容易接触机器学习。
但是,使用 AutoML 框架也存在一些缺点:
-
黑盒子:AutoML 框架可以是“黑盒子”,这意味着它的工作原理可能难以理解。这可能会使得调试 AutoML 模型的问题变得困难。
-
有限的灵活性:AutoML 框架在能够自动化的机器学习任务类型方面可能会有所限制。
上述工具中有很多都至少具有某种自动特征工程或预处理功能,但是也有一些更专业化的工具可以实现这一点。
生成模型的影响
生成式人工智能和像 GPT-3 这样的 LLMs 已经给数据科学和分析领域带来了重大变革。这些模型,特别是 LLMs,有潜力以多种方式彻底改变数据科学的所有步骤,为研究人员和分析师提供令人兴奋的机会。生成式人工智能模型,比如 ChatGPT,能够理解和生成类似人类的回应,成为增强研究生产力的有价值工具。生成式人工智能在分析和解释研究数据方面起着关键作用。这些模型可以协助进行数据探索,发现隐藏的模式或相关性,并提供通过传统方法可能不明显的见解。通过自动化数据分析的某些方面,生成式人工智能节省了时间和资源,使研究人员能够专注于更高级别的任务。生成式人工智能可以在帮助研究人员进行文献综述和识别研究空白方面起到关键作用。ChatGPT 和类似模型可以总结学术论文或文章中的大量信息,提供现有知识的简洁概述。这有助于研究人员更有效地识别文献中的空白并指导他们自己的调查。我们在第四章 问题回答中研究了使用生成式人工智能模型的这一方面。生成式人工智能的其他用例可能包括:
-
自动产生合成数据:生成式人工智能可用于自动生成合成数据,可用于训练机器学习模型。这对于没有大量真实世界数据的企业非常有帮助。
-
识别数据中的模式:生成式人工智能可以用于识别人类分析员无法看到的数据中的模式。这对于希望从数据中获得新见解的企业非常有帮助。
-
从现有数据中创建新特征:生成式人工智能可以用于从现有数据中创建新特征。这对于希望改善他们的机器学习模型准确性的企业非常有帮助。
根据像麦肯锡和毕马威这样的最近报告所述,人工智能的后果涉及数据科学家将工作的内容,他们如何工作以及谁能完成数据科学任务。主要影响包括:
-
人工智能的民主化:生成式模型让更多人通过简单提示生成文本、代码和数据来利用人工智能。这将人工智能的使用扩展到数据科学家以外的范围。
-
提高生产力:通过自动生成代码、数据和文本,生成式人工智能可以加速开发和分析工作流程。这使数据科学家和分析师能够专注于更高价值的任务。
-
数据科学的创新:生成式人工智能正在带来更创新的方式来探索数据,并生成以传统方法不可能的新假设和见解
-
行业的颠覆:生成式人工智能的新应用可能通过自动化任务或增强产品和服务来颠覆行业。数据团队将需要确定高影响力的用例。
-
仍然存在限制:当前模型仍然存在准确性限制、偏见问题和缺乏可控性。需要数据专家监督负责的发展。
-
治理的重要性:对生成式人工智能模型的发展和道德使用进行严格的治理将对维护利益相关者的信任至关重要。
-
合作伙伴关系的需求 - 公司将需要与合作伙伴、社区和平台提供商建立生态系统,以有效利用生成式人工智能的能力。
-
数据科学技能的变化 - 需求可能从编码专业知识转向数据治理、伦理、将业务问题转化为语言以及监督人工智能系统等能力。
关于数据科学的民主化和创新,更具体地说,生成式人工智能也正在影响数据可视化的方式。过去,数据可视化通常是静态的和二维的。然而,生成式人工智能可以用于创建交互式和三维的可视化,这有助于使数据更易于访问和理解。这使得人们更容易理解和解释数据,从而促进更好的决策。同样,生成式人工智能带来的最大变化之一是数据科学的民主化。过去,数据科学是一个非常专业化的领域,需要对统计学和机器学习有深入的理解。然而,生成式人工智能使得不具备较高技术专业知识的人们能够创建和使用数据模型。这使得数据科学领域对更广泛的人群开放。LLMs 和生成式人工智能可以在自动化数据科学中发挥关键作用,提供几个优势:
-
自然语言交互:LLMs 允许进行自然语言交互,使用户能够使用普通英语或其他语言与模型进行交流。这使得非技术用户可以使用日常语言与数据进行交互和探索,而无需具备编码或数据分析方面的专业知识。
-
代码生成:生成式人工智能可以自动生成代码片段,以执行探索性数据分析期间的特定分析任务。例如,它可以生成检索数据的代码(例如,SQL)、清理数据、处理缺失值或创建可视化(例如,在 Python 中)。此功能节省时间,减少了手动编码的需求。
-
自动报告生成:LLM(大型语言模型)可以生成自动化报告,总结探索性数据分析的关键发现。这些报告提供了关于数据集各个方面的见解,例如统计摘要、相关性分析、特征重要性等,使用户更容易理解和展示他们的发现。
-
数据探索和可视化:生成式人工智能算法可以全面地探索大型数据集,并自动生成可视化图表,揭示数据中的基本模式、变量之间的关系、离群值或异常值。这有助于用户全面理解数据集,而无需手动创建每个可视化图表。
此外,我们可以认为生成式 AI 算法应该能够从用户交互中学习,根据个人偏好或过去行为调整推荐内容。它们通过持续自适应学习和用户反馈而不断优化,为自动化 EDA 提供更加个性化和有用的见解。最后,生成式 AI 模型可以通过从现有数据集中学习模式(智能错误识别)在 EDA 过程中识别数据中的错误或异常。它们能够快速准确地检测不一致性并突出潜在问题。总的来说,LLM 和生成式 AI 可以通过简化用户互动、生成代码片段、高效识别错误/异常、自动化报告生成、实现全面数据探索和可视化建设以及适应用户偏好来增强自动化 EDA,以便更有效地分析大型和复杂数据集。然而,虽然这些模型可以极大地增强研究和文献综述过程,但它们不应被视为绝对可靠的来源。如前所述,LLM 是通过类比工作的,在推理和数学方面会遇到困难。它们的优势在于创造力,而不是准确性,因此研究人员必须运用批判性思维,并确保这些模型生成的输出准确、公正并符合严格的科学标准。其中一个著名的例子是微软的 Fabric,它包含由生成式 AI 驱动的聊天界面,使用户能够使用自然语言提出数据相关问题,并在无需等待数据请求队列的情况下立即获得答案。通过利用像 OpenAI 模型这样的 LLM,Fabric 实现了对有价值的见解的实时访问。Fabric 在其他分析产品中脱颖而出,因为它采用全面的方法。它解决了组织在分析过程中各个方面的需求,并为参与分析过程的不同团队(如数据工程师、数据仓库专业人员、科学家、分析人员和业务用户)提供角色专用的体验。借助每个层面的 Azure OpenAI 服务的集成,Fabric 利用生成式 AI 的能力来发掘数据的全部潜力。类似 Microsoft Fabric 中的 Copilot 等特性提供了对话式语言体验,使用户能够创建数据流、生成代码或整个函数、构建机器学习模型、可视化结果,甚至开发自定义的对话式语言体验。有趣的是,ChatGPT(以及它的扩展 Fabric)经常会产生不正确的 SQL 查询。虽然对于可以检查输出有效性的分析人员来说这没问题,但对于非技术业务用户而言,这是一场灾难性的自助式分析工具。因此,在使用 Fabric 进行分析时,组织必须确保有可靠的数据管道,并采取数据质量管理实践。虽然生成式 AI 在数据分析中的潜力很大,但仍需要谨慎。必须通过第一原理推理和严格的分析来验证 LLM 的可靠性和准确性。尽管这些模型在临时分析、研究中的思想生成和复杂分析的概括方面表现出了其潜力,但由于需要领域专家的验证,它
代理人可以回答数据科学问题
正如我们在 Jupyter AI(Jupyternaut chat)中所看到的 - 还有第六章的开发软件 - 通过生成式 AI(代码 LLMs)来增加创建和编写软件的效率有很大的潜力。这是我们研究数据科学中使用生成式 AI 的实际部分的很好的起点。我们之前已经看到不同的带有工具的代理人。例如,LLMMathChain 可以执行 Python 来回答数学问题,就像这里所示:
from langchain import OpenAI, LLMMathChain
llm = OpenAI(temperature=0)
llm_math = LLMMathChain.from_llm(llm, verbose=True)
llm_math.run("What is 2 raised to the 10th power?")
尽管这对于提取信息并将其反馈是有用的,但如何将其插入传统的 EDA 过程中却不太明显。同样,CPAL(CPALChain)和 PAL(PALChain)链可以回答更复杂的推理问题,同时保持幻觉受控,但很难想出它们的真实用例。通过PythonREPLTool,我们可以使用玩具数据创建简单的可视化,或者用合成数据进行训练,这对说明或启动项目可能很好。这是 LangChain 文档中的一个例子:
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.llms.openai import OpenAI
from langchain.agents.agent_types import AgentType
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=1000),
tool=PythonREPLTool(),
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
agent_executor.run(
"""Understand, write a single neuron neural network in PyTorch.
Take synthetic data for y=2x. Train for 1000 epochs and print every 100 epochs.
Return prediction for x = 5"""
)
请注意,这应谨慎执行,因为 Python 代码直接在机器上执行而且没有任何防护措施。实际上这是有效的,可以创建数据集,训练模型,然后得到预测结果:
Entering new AgentExecutor chain...
I need to write a neural network in PyTorch and train it on the given data
Action: Python_REPL
Action Input:
import torch
model = torch.nn.Sequential(
torch.nn.Linear(1, 1)
)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Define the data
x_data = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0], [8.0]])
for epoch in range(1000): # Train the model
y_pred = model(x_data)
loss = loss_fn(y_pred, y_data)
if (epoch+1) % 100 == 0:
print(f'Epoch {epoch+1}: {loss.item():.4f}')
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Make a prediction
x_pred = torch.tensor([[5.0]])
y_pred = model(x_pred)
Observation: Epoch 100: 0.0043
Epoch 200: 0.0023
Epoch 300: 0.0013
Epoch 400: 0.0007
Epoch 500: 0.0004
Epoch 600: 0.0002
Epoch 700: 0.0001
Epoch 800: 0.0001
Epoch 900: 0.0000
Epoch 1000: 0.0000
Thought: I now know the final answer
Final Answer: The prediction for x = 5 is y = 10.00.
再次,这非常酷,但很难看出如何在没有更严谨的工程的情况下扩展。如果我们想要丰富我们的数据以获取类别或地理信息,LLMs 和工具会很有用。例如,如果我们的公司从东京提供航班,而我们想要知道我们的客户距离东京的距离,我们可以使用 Wolfram Alpha 作为一个工具。这是一个简单的例子:
from langchain.agents import load_tools, initialize_agent
from langchain.llms import OpenAI
from langchain.chains.conversation.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
tools = load_tools(['wolfram-alpha'])
memory = ConversationBufferMemory(memory_key="chat_history")
agent = initialize_agent(tools, llm, agent="conversational-react-description", memory=memory, verbose=True)
agent.run(
"""How far are these cities to Tokyo?
* New York City
* Madrid, Spain
* Berlin
""")
请确保您已经设置了 OPENAI_API_KEY 和 WOLFRAM_ALPHA_APPID 环境变量,正如在第三章开始使用 LangChain中所讨论的那样。这是输出结果:
> Entering new AgentExecutor chain...
AI: The distance from New York City to Tokyo is 6760 miles. The distance from Madrid, Spain to Tokyo is 8,845 miles. The distance from Berlin, Germany to Tokyo is 6,845 miles.
> Finished chain.
'
The distance from New York City to Tokyo is 6760 miles. The distance from Madrid, Spain to Tokyo is 8,845 miles. The distance from Berlin, Germany to Tokyo is 6,845 miles.
现在,很多这些问题都非常简单。然而,我们可以给予代理人数据集进行处理,这就是当我们连接更多工具时,它变得非常强大的地方。让我们开始问答关于结构化数据集的问题吧!
使用 LLMs 进行数据探索
数据探索是数据分析中至关重要且基础的步骤,使研究人员能够全面了解其数据集并发现重要信息。随着类似 ChatGPT 这样的 LLM 的出现,研究人员可以利用自然语言处理的能力促进数据探索。正如我们之前提到的生成式 AI 模型如 ChatGPT 具有理解和生成类人回答的能力,使它们成为增强研究生产力的有价值的工具。以自然语言提出问题并获得易消化的响应可以极大地促进分析。LLM 不仅可用于探索文本数据,还可用于探索其他形式的数据,如数字数据集或多媒体内容。研究人员可以利用 ChatGPT 的能力,询问数值数据集中的统计趋势或查询图像分类任务的可视化。让我们加载一个数据集并进行处理。我们可以从 scikit-learn 快速获取一个数据集:
from sklearn.datasets import load_iris
df = load_iris(as_frame=True)["data"]
Iris 数据集是众所周知的-它是玩具数据集,但它将帮助我们说明使用生成式 AI 进行数据探索的能力。我们将在接下来使用 DataFrame。我们现在可以创建一个 Pandas dataframe 代理,看看如何轻松地完成一些简单的事情!
from langchain.agents import create_pandas_dataframe_agent
from langchain import PromptTemplate
from langchain.llms.openai import OpenAI
PROMPT = (
"If you do not know the answer, say you don't know.\n"
"Think step by step.\n"
"\n"
"Below is the query.\n"
"Query: {query}\n"
)
prompt = PromptTemplate(template=PROMPT, input_variables=["query"])
llm = OpenAI()
agent = create_pandas_dataframe_agent(llm, df, verbose=True)
我已经为模型制定了当怀疑时告诉它自己不知道以及逐步思考的指示,这两者都可以减少产生幻觉的可能性。现在我们可以针对 DataFrame 查询我们的代理:
agent.run(prompt.format(query="What's this dataset about?"))
我们得到了答案 “这个数据集是关于某种类型的花的测量”,是正确的。让我们展示如何获得一个可视化:
agent.run(prompt.format(query="Plot each column as a barplot!"))
它并不完美,但我们得到了一个好看的图表:

图 7.5: Iris 数据集的条形图。
我们也可以请求以可视化方式查看列的分布,从而获得这个整洁的图表:

图 7.6: Iris 数据集箱线图。
我们可以请求图表使用其他绘图后端,例如 seaborn,但请注意,这些必须安装。我们还可以询问关于数据集的更多问题,比如哪一行在花瓣长度和花瓣宽度之间有最大差异。我们得到了具有中间步骤的答案(缩短后)。
df['difference'] = df['petal length (cm)'] - df['petal width (cm)']
df.loc[df['difference'].idxmax()]
Observation: sepal length (cm) 7.7
sepal width (cm) 2.8
petal length (cm) 6.7
petal width (cm) 2.0
difference 4.7
Name: 122, dtype: float64
Thought: I now know the final answer
Final Answer: Row 122 has the biggest difference between petal length and petal width.
我认为这值得称赞,LLM!下一步可能是给提示添加更多关于绘图的指示,例如绘图大小等。在 Streamlit 应用程序中实现相同的绘图逻辑有点困难,因为我们需要使用适当的 Streamlit 函数的绘图功能,例如st.bar_chart(),但是这也可以完成。您可以在 Streamlit 博客上找到有关此内容的解释(“使用 ChatGPT 构建 Streamlit 和 scikit-learn 应用程序”)。那么统计测试呢?
agent.run(prompt.format(query="Validate the following hypothesis statistically: petal width and petal length come from the same distribution."))
我们得到了这个回答:
Thought: I should use a statistical test to answer this question.
Action: python_repl_ast
Action Input: from scipy.stats import ks_2samp
Observation:
Thought: I now have the necessary tools to answer this question.
Action: python_repl_ast
Action Input: ks_2samp(df['petal width (cm)'], df['petal length (cm)'])
Observation: KstestResult(statistic=0.6666666666666666, pvalue=6.639808432803654e-32, statistic_location=2.5, statistic_sign=1)
Thought: I now know the final answer
Final Answer: The p-value of 6.639808432803654e-32 indicates that the two variables come from different distributions.
'6.639808432803654e-32 的 p 值表明两个变量来自不同的分布。'这是统计检验!很酷。我们可以用简单的提示用普通英语询问关于数据集的相当复杂的问题。还有 pandas-ai 库,它在内部使用 LangChain 并提供类似的功能。以下是文档中的一个例子,案例数据集:
import pandas as pd
from pandasai import PandasAI
df = pd.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"gdp": [19294482071552, 2891615567872, 2411255037952, 3435817336832, 1745433788416, 1181205135360, 1607402389504, 1490967855104, 4380756541440, 14631844184064],
"happiness_index": [6.94, 7.16, 6.66, 7.07, 6.38, 6.4, 7.23, 7.22, 5.87, 5.12]
})
from pandasai.llm.openai import OpenAI
llm = OpenAI(api_token="YOUR_API_TOKEN")
pandas_ai = PandasAI(llm)
pandas_ai(df, prompt='Which are the 5 happiest countries?')
当我们直接使用 LangChain 时,这将给我们提供所请求的结果。请注意,pandas-ai 并不是本书的设置的一部分,所以如果你想使用它,你需要单独安装它。对于 SQL 数据库中的数据,我们可以使用SQLDatabaseChain进行连接。LangChain 的文档展示了这个例子:
from langchain.llms import OpenAI
from langchain.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain
db = SQLDatabase.from_uri("sqlite:///../../../../notebooks/Chinook.db")
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
db_chain.run("How many employees are there?")
我们首先连接到数据库。然后我们可以用自然语言提出关于数据的问题。这也可以非常强大。LLM 将为我们创建查询。我期望当我们不了解数据库模式时,这将特别有用。SQLDatabaseChain还可以在use_query_checker选项设置时检查查询并自动更正它们。让我们做个总结!
摘要
在本章中,我们探讨了自动化数据分析和数据科学的最新技术。有很多领域,LLM 可以使数据科学受益,主要是作为编码助手或数据探索。我们从概述了覆盖数据科学流程中每个步骤的框架开始,比如 AutoML 方法,然后讨论了 LLM 如何帮助我们进一步提高生产力,使数据科学和数据分析更加容易访问,无论是对利益相关者还是对开发人员或用户。我们随后研究了代码生成和类似代码 LLM 第六章 软件开发中的工具如何在数据科学任务中帮助我们通过创建我们可以查询的函数或模型,或者如何利用 LLM 或第三方工具如沃尔夫拉姆阿尔法来丰富数据。然后,我们关注了在数据探索中使用 LLM。在第四章 问答中,我们研究了摄取大量文本数据以进行分析。在本章中,我们聚焦于 SQL 或表格形式的结构化数据集的探索性分析。总之,人工智能技术有潜力彻底改变我们分析数据的方式,ChatGPT 插件或微软 Fabric 就是例子。然而,在当前的状况下,人工智能不能取代数据科学家,只能帮助他们。让我们看看你是否记住了本章的一些关键要点!
问题
请看看你是否能够凭记忆回答这些问题。如果对任何问题不确定,我建议您回到本章的相应部分查看:
-
数据科学和数据分析之间有什么区别?
-
数据科学涉及哪些步骤?
-
为什么我们想要自动化数据科学/分析?
-
存在用于自动化数据科学任务的框架以及它们能做什么?
-
生成式人工智能如何帮助数据科学家?
-
我们可以使用什么样的代理和工具来回答简单的问题?
-
如何让 LLM 处理数据?
第八章:自定义 LLMs 及其输出
在 Discord 上加入我们的书籍社区
packt.link/EarlyAccessCommunity

本章主要讨论改进大型语言模型(LLMs)在复杂推理和问题解决任务等特定情况下的可靠性和性能的技术和最佳实践。一般来说,使模型适应特定任务或确保模型输出与我们期望的一致的过程称为条件。在本章中,我们将讨论微调和提示作为条件的方法。微调涉及在特定任务或与所需应用相关的数据集上训练预训练基础模型。这个过程允许模型适应并在预期用例中变得更准确和上下文对齐。同样,通过在推断时提供额外的输入或上下文,大型语言模型(LLMs)可以生成适合特定任务或风格的文本。提示设计对于释放 LLM 的推理能力,模型和提示技术未来进展的潜力非常重要,这些原则和技术构成了研究人员和从业者使用大型语言模型的宝贵工具包。了解 LLMs 如何逐个标记地生成文本有助于创建更好的推理提示。提示仍然是一个经验性的艺术——通常需要尝试各种变化来看看什么有效。但一些提示工程的见解可以在模型和任务之间转移。我们将讨论 LangChain 中的工具,以实现高级提示工程策略,如少样本学习、动态示例选择和链式推理。在本章的整个过程中,我们将使用 LLMs 进行微调和提示,您可以在书的 Github 存储库的notebooks目录中找到,网址是github.com/benman1/generative_ai_with_langchain主要章节包括:
-
条件和对齐
-
微调
-
提示工程
让我们首先讨论条件和对齐,为什么重要,以及如何实现它。
条件和对齐
在生成式人工智能模型的背景下,“alignment” 意味着确保这些模型的输出与人类的价值观、意图或期望结果一致。它涉及指导模型的行为与在特定上下文中被认为道德、适当或相关的内容保持一致。“alignment” 概念对于避免生成可能存在偏见、有害或偏离预期目的的输出至关重要。解决"alignment" 问题需要注意训练数据中存在的偏见,涉及人类审阅者的反馈循环,在训练/微调阶段改进客观函数,利用用户反馈,并在部署过程中持续监测以确保持续对齐。一个可能想对大型语言模型进行条件的原因有几个。第一个是控制输出的内容和风格。例如,根据某些关键词或属性如正式程度进行条件,可以产生更相关和高质量的文本。条件还包括安全措施,以防止生成恶意或有害内容。例如,避免生成误导性信息、不当建议或潜在危险指示,或者更一般地对齐模型与某些价值观。对大型语言模型进行条件的潜在好处很多。通过提供更具体和相关的输入,我们可以得到符合我们需求的输出。例如,在客服聊天机器人中,对模型进行条件,允许它生成准确解决用户问题的回应。条件还有助于通过限制模型创造性在特定边界内来控制有偏见或不当的输出。此外,通过对大型语言模型进行条件,我们可以使它们更可控和适应性更强。我们可以根据我们的需求对其进行微调和塑造行为,并创建在特定领域如法律建议或技术写作中可靠的人工智能系统。然而,也有潜在的不利因素需要考虑。过于强烈地对模型进行条件可能导致过拟合,导致模型过分依赖特定输入,在不同环境中难以产生创造性或多样化的输出。此外,应该有责任地利用条件,因为大型语言模型有放大训练数据中存在偏见的倾向。在对这些模型进行条件时,必须小心不要加剧与偏见或有争议话题相关的问题。
对齐的好处 包括:
-
增强用户体验:对齐的模型生成与用户查询或提示相关的输出。
-
建立信任:确保道德行为有助于在用户/客户之间建立信任。
-
品牌声誉:通过与关于品牌一致性和期望的语气/风格指南的业务目标保持一致。
-
缓解有害影响:与安全、保密和隐私考虑的对齐有助于防止生成有害或恶意内容。
潜在的缺点包括:
-
平衡挑战:在极端对齐(过于保守)和创造性自由(过于宽松)之间取得平衡可能很困难。
-
自动度量标准的限制:定量评估指标可能无法完全捕捉对齐的微妙差异。
-
主观性:对齐判断往往是主观的,需要对所需价值观和指导方针进行认真考虑和共识建立。
预训练大型模型以学习模式和语言理解会导致一个基础模型,该模型具有对各种主题的广泛理解,但缺乏特定上下文的特定性或对齐性。尽管像 GPT-4 这样的基础模型能够在各种主题上生成令人印象深刻的文本,但通过对它们进行调节可以增强它们在任务相关性、特定性和连贯性方面的能力,并使它们的输出更相关和贴切。没有条件的话,这些模型往往会生成与所需上下文不完全一致的文本。通过对其进行调节,我们可以引导语言模型生成更与给定输入或指令相关的输出。调节的主要优势在于它允许在不进行大量重新训练的情况下引导模型。它还可以实现交互式控制和在不同模式之间切换。调节可以在模型开发周期的不同阶段进行——从微调到在各种上下文中生成输出。有几种实现大型语言模型对齐的选择。一种方法是在微调过程中进行条件化,通过对模型进行反映所需输出的数据集进行训练。这样可以使模型专业化,但需要访问相关的训练数据。另一种选择是在推理时动态地对模型进行条件化,通过提供条件输入和主提示。这样更灵活,但在部署过程中引入了一些复杂性。在下一节中,我将总结关键的对齐方法,如微调和提示工程,讨论其原理,并分析它们的相对优缺点。
对齐方法
随着像 GPT-3 这样的大型预训练语言模型的出现,人们对调整这些模型以适应下游任务的技术越来越感兴趣。这个过程被称为微调。微调允许预训练模型在利用预训练期间获得的广泛语言知识的同时,为特定应用定制。在 2010 年代初,调整预训练神经网络的想法起源于计算机视觉研究。在自然语言处理领域,Howard 和 Ruder(2018)展示了微调预训练上下文表示(如 ELMo 和 ULMFit)在下游任务上的有效性。开创性的 BERT 模型(Devlin 等人,2019)将微调预训练 transformer 确立为自然语言处理中的事实标准。微调的需求产生的原因是预训练语言模型旨在建模一般语言知识,而不是特定的下游任务。只有当适应特定应用程序时,它们的能力才会显现出来。微调允许更新预训练权重以适应目标数据集和目标。这样可以在定制化专业任务的同时从一般模型中转移知识。已经提出了几种用于对齐的方法,其中在效果和效率方面存在权衡,值得深入研究每种对齐方法的细节。完全微调涉及在微调期间更新预训练语言模型的所有参数。该模型在下游任务上端到端地进行训练,允许全局更新权重以最大化目标性能。FFT 在各个任务上一直表现出色,但需要大量的计算资源和大型数据集来避免过拟合或遗忘。在适配器调整中,额外的可训练适配器层被插入到预训练模型中,通常是瓶颈层,同时保持原始权重冻结。只有新增的适配器层在下游任务上进行训练。这使得调整参数效率高,因为只有一小部分权重被更新。然而,由于预训练权重保持不变,适配器调整有着低配合任务的风险。适配器的插入点和容量会影响整体的有效性。前缀调整:这种方法将可训练向量预置到 LM 的每一层中,在微调期间优化这些向量,而基本权重保持冻结。前缀允许向模型注入归纳偏见。与适配器相比,前缀调整的内存占用较小,但效果没有被发现那么有效。前缀的长度和初始化会影响效果。在提示调整中,输入文本附加了可训练提示标记,这些标记提供了对 LM 所需行为的软提示。例如,任务描述可以作为提示提供给模型。只有新增的提示标记在训练期间进行更新,而预训练权重被冻结。性能受提示工程的影响很大。自动提示方法正在被探索。低秩调整(LoRA)将一对低秩可训练权重矩阵添加到冻结的 LM 权重中。例如,对于每个权重 W,添加低秩矩阵 B 和 A,使得前向传播使用 W + BA。只有 B 和 A 被训练,基本的 W 保持冻结。LoRA 实现了合理的有效性,而且参数效率比全面调整更高。秩 r 的选择会影响权衡。LoRA 可以在有限的硬件上调整巨大的 LM。确保生成的输出正确对齐的另一种方法是通过人工监督方法,例如人机协同系统。这些系统涉及人类审阅员提供反馈,并在必要时进行更正。人的参与有助于使生成的输出与人类设定的期望值或指南相一致。下表总结了不同的技术用于引导生成式 AI 输出:
| 阶段 | 技术 | 示例 |
|---|---|---|
| 训练 | 预训练 | 在多样化数据上进行训练 |
| 目标函数 | 训练目标的谨慎设计 | |
| 架构和训练过程 | 优化模型结构和训练 | |
| 微调 | 专业化 | 在特定数据集/任务上进行训练 |
| 推断时间调整 | 动态输入 | 前缀、控制代码、上下文示例 |
| 人类监督 | 人机协同 | 人工审查和反馈 |
图 8.1:引导生成型 AI 输出。
结合这些技术可以为生成型 AI 系统的行为和输出提供更多的控制。最终目标是确保人类价值观在所有阶段,从训练到部署,都得到了体现,以创建负责任和对齐的 AI 系统。此外,在预训练目标函数中进行谨慎设计选择也会影响语言模型最初学习的行为和模式。通过将伦理考量纳入这些目标函数中,开发者可以影响大型语言模型的初始学习过程。我们还可以区分微调的几种方法,例如在线和离线。InstructGPT 被认为是一个改变游戏规则的因素,因为它展示了通过将来自人类反馈的强化学习(RLHF)纳入到语言模型(如 GPT-3)中,可以显著改进语言模型的潜力。让我们谈谈 InstructGPT 为什么会产生如此革命性的影响的原因。
利用人类反馈进行强化学习
在他们 2022 年 3 月的论文中,来自 OpenAI 的欧阳等人展示了使用来自人类反馈的强化学习(RLHF)和近端策略优化(PPO)来调整大型语言模型(如 GPT-3)与人类偏好一致。从人类反馈中进行强化学习(RLHF)是一种在线方法,它使用人类偏好对语言模型进行微调。它有三个主要步骤:
-
监督预训练:首先通过标准的监督学习在人类示范中对语言模型进行训练。
-
奖励模型训练:一个奖励模型根据语言模型输出的人类评分进行训练,以估计奖励。
-
RL 微调:通过强化学习对语言模型进行微调,以最大化奖励模型的预期奖励,使用像 PPO 这样的算法。
主要变化 RLHF,通过学习的奖励模型将细微的人类判断纳入语言模型的训练中。因此,人类反馈可以引导和改进语言模型的能力,超越标准的监督微调。这种新模型可以用于遵循用自然语言给出的指示,并且可以回答问题的准确性和相关性比 GPT-3 更高。尽管参数少了 100 倍,但 InstructGPT 在用户偏好、真实性和减少伤害方面都优于 GPT-3。从 2022 年 3 月开始,OpenAI 开始发布 GPT-3.5 系列模型,这些模型是 GPT-3 的升级版本,包括与 RLHF 微调。这些模型的用户立即发现了微调的三个优势:
-
Steerability: 模型遵循指示的能力(指令调整)
-
可靠的输出格式:这对于 API 调用/函数调用变得重要。
-
自定义语气:这使得可以根据任务和受众的需求调整输出风格。
InstructGPT 通过将人类反馈的强化学习方法纳入传统微调方法之外,开辟了改进语言模型的新途径。尽管强化学习训练可能不稳定且计算成本高昂,但其成功激发了进一步研究,以改进强化学习人机反馈技术,减少对齐的数据需求,以及为各种应用开发更强大和更易于访问的模型。
离线方法
离线方法通过直接利用人类反馈来绕过在线强化学习的复杂性。我们可以区分基于排名和基于语言的方法:
-
基于排名的:人类对语言模型输出进行排名,用于定义微调的优化目标,完全避免了强化学习。这包括 Preference Ranking Optimization (PRO; Song 等人,2023)和 Direct Preference Optimization (DPO; Rafailov 等人,2023)等方法。
-
基于语言:人类通过自然语言提供反馈,并通过标准监督学习利用。例如,Chain of Hindsight (CoH; Liu 等人,2023)将所有类型的反馈转换为句子,并用它们微调模型,利用语言模型的语言理解能力。
直接优化偏好(DPO)是一种简单有效的方法,用于训练语言模型以符合人类偏好,无需显式学习奖励模型或使用强化学习。虽然它优化与现有 RLHF 方法相同的目标,但它实现起来要简单得多,更稳定,并且具有强大的经验性能。Meta 的研究人员在论文“LIMA:对齐的少即多”中,通过在对 LLaMa 模型进行精细训练时仅在 1000 个精心策划的提示上最小化监督损失来简化对齐。通过将它们的输出与 DaVinci003(GPT-3.5)进行比较时所得到的有利人类偏好,他们得出结论,精细训练仅具有极小的重要性。他们将这称为表面对齐假设。离线方法提供了更稳定和高效的调整。然而,它们受限于静态人类反馈。最近的方法尝试将离线和在线学习相结合。尽管 DPO 和带有 PPO 的 RLHF 都旨在将 LLMs 与人类偏好对齐,但它们在复杂性、数据需求和实现细节方面存在差异。DPO 提供了简单性,但通过直接优化概率比率实现了强大的性能。另一方面,带有 PPO 的 RLHF 在 InstructGPT 中引入了更多复杂性,但允许通过奖励建模和强化学习优化进行细微的对齐。
低秩适应
LLM(大型语言模型)在自然语言处理方面取得了令人印象深刻的成果,现在也被应用于计算机视觉和音频等其他领域。然而,随着这些模型变得越来越庞大,用消费者硬件训练它们变得困难,并且为每个特定任务部署它们变得昂贵。有几种方法可以减少计算、内存和存储成本,同时提高在低数据和领域外场景下的性能。低秩适应(LoRA)冻结预训练模型的权重,并在 Transformer 架构的每一层中引入可训练的秩分解矩阵,以减少可训练参数的数量。LoRA 在各种语言模型(RoBERTa、DeBERTa、GPT-2 和 GPT-3)上与微调相比,实现了可比较或更好的模型质量,同时具有更少的可训练参数和更高的训练吞吐量。QLORA 方法是 LoRA 的扩展,通过将梯度通过冻结的 4 位量化模型传播到可学习的低秩适配器,实现了对大型模型的有效微调,从而使得在单个 GPU 上对 650 亿参数模型进行微调成为可能。QLORA 模型在 Vicuna 上实现了与 ChatGPT 性能 99%相当的性能,采用了新的数据类型和优化器等创新。特别是,QLORA 将对 650 亿参数模型进行微调的内存需求从大于 780GB 降低到小于 48GB,而不影响运行时或预测性能。
量化指的是降低神经网络中权重和激活的数值精度的技术,例如大型语言模型(LLMs)。量化的主要目的是减少大型模型的内存占用和计算需求。
关于 LLM 量化的一些关键点:
-
它涉及使用比标准单精度浮点(FP32)更少的比特来表示权重和激活。例如,权重可以量化为 8 位整数。
-
这可以通过将可训练向量前置到 LLM 层来缩小模型大小最多 4 倍,并提高专用硬件的吞吐量。
-
量化通常对模型准确度影响不大,尤其是在重新训练时。
-
常见的量化方法包括标量、向量和乘积量化,这些方法将权重分别或分组量化。
-
通过估计激活的分布并适当分组,激活也可以进行量化。
-
量化感知训练在训练过程中调整权重以最小化量化损失。
-
像 BERT 和 GPT-3 之类的 LLM 已经通过微调展示了对 4-8 位量化的良好适应性。
参数高效微调(PEFT)方法使得可以为每个任务使用小检查点,使得模型更具可移植性。这些小训练权重可以添加到 LLM 之上,允许同一模型用于多个任务而无需替换整个模型。在下一节中,我们将讨论在推理时如何为大型语言模型(LLMs)进行条件化的方法。
推理时条件化
一个常用的方法是在推理时进行条件化(输出生成阶段),在这个过程中动态提供特定的输入或条件以引导输出生成过程。在某些场景中,LLM 微调并不总是可行或有益的:
-
有限的微调服务:一些模型只能通过缺乏或具有受限微调能力的 API 访问。
-
数据不足:在特定下游任务或相关应用领域缺乏微调所需的数据的情况下。
-
动态数据:像新闻相关平台这样频繁更改数据的应用可能难以频繁微调模型,导致潜在的缺点。
-
上下文敏感应用:像个性化聊天机器人这样的动态和特定上下文的应用无法根据个人用户数据执行微调。
在推理阶段进行条件化时,最常见的做法是在文本生成过程开始时提供文本提示或指令。这个提示可以是几句话甚至是一个单词,作为所需输出的明确指示。一些常见的动态推理时条件化技术包括:
-
提示调整:为预期行为提供自然语言指导。对提示设计敏感。
-
前缀调整:在 LLM 层前面添加可训练向量。
-
限制令牌:强制包含/排除某些单词
-
元数据:提供类似类型、目标受众等高层次信息。
提示可以促进生成符合特定主题、风格甚至模仿特定作者写作风格的文本。这些技术涉及在推理时提供上下文信息,比如针对上下文学习或检索增强。一个提示调整的例子是在提示前添加前缀,比如“写一个适合儿童的故事…”,这些指示会被添加到提示的前面。例如,在聊天机器人应用中,用用户消息来调整模型有助于生成与正在进行的对话相关且个性化的回复。更进一步的例子包括在提示之前添加相关文档,以帮助语言模型完成写作任务(如新闻报道、维基百科页面、公司文件),或者在提示 LLM 之前检索并添加用户特定数据(财务记录、健康数据、电子邮件)以确保个性化回答。通过在运行时将 LLM 输出与上下文信息相结合,这些方法可以引导模型而不依赖于传统的微调过程。通常演示是推理任务说明的一部分,其中提供少量示例来诱导期望的行为。强大的 LLM,如 GPT-3,可以通过提示技术解决问题而无需进一步的训练。在这种方法中,要解决的问题被呈现给模型作为文本提示,可能包括一些类似问题及其解决方案的文本示例。模型必须通过推理提供提示的完成。零次提示不包含已解决的示例,而少量提示包括一小部分类似(问题、解决方案)对的示例。已经表明提示可以轻松控制像 GPT-3 这样的大型冻结模型,并且可以在不需要大量微调的情况下引导模型行为。提示使模型可以在新知识上进行调整,而开销较低,但是需要谨慎地进行提示工程以获得最佳结果。这将作为本章的一部分进行讨论。在前缀调整中,连续的任务特定向量在推理时被训练并提供给模型。类似的想法也被提出用于适配器方法,例如参数高效的迁移学习(PELT)或梯子侧调整(LST)。在推理时的调整也可以发生在采样过程中,比如基于语法的采样,其中输出可以受到某些定义良好模式的约束,比如编程语言语法。
结论
全面的微调一贯取得强大的结果,但往往需要大量资源,效率与功效之间存在着权衡。像适配器、提示和 LoRA 这样的方法通过稀疏化或冻结减轻了这一负担,但可能效果较差。最佳方法取决于约束条件和目标。未来改进的技术针对大型语言模型定制可能会推动功效和效率的边界。最近的工作将离线和在线学习相结合,以提高稳定性。整合世界知识和可控生成仍是开放挑战。基于提示的技术允许对大型语言模型进行灵活的调节,以引导所需行为而无需进行密集训练。精心设计、优化和评估提示是有效控制大型语言模型的关键。基于提示的技术可通过灵活、低资源的方式对语言模型进行特定行为或知识的调节。
评估
对齐在类似 HUMAN 的对齐基准和 FLAN 等泛化测试上进行评估。有一些核心基准可以准确评估模型的优势和劣势,例如:
-
英文知识:MMLU
-
中文知识:C-Eval
-
推理:GSM8k / BBH(算法)
-
编码:HumanEval / MBPP
在平衡了这些方向之后,可以追求像 MATH(高难度推理)和 Dialog 等额外的基准。尤其有趣的评估在数学或推理方面,人们预期泛化能力会非常强大。MATH 基准展示了高级别的难度,而 GPT-4 根据提示方法的不同实现了不同的分数。结果从通过少量样本评估的朴素提示到 PPO + 基于过程的奖励建模都有。如果微调只涉及对话数据,可能会对现有的能力产生负面影响,例如 MMLU 或 BBH。提示工程至关重要,因为偏见和查询难度会影响评估。还有一些定量指标,如困惑度(衡量模型预测数据的能力)或 BLEU 分数(捕捉生成文本与参考文本之间的相似性)。这些指标提供了粗略的估计,但可能无法完全捕捉语义含义或与更高级别目标的一致性。其他指标包括通过人类评估的用户偏好评分,成对偏好,利用预训练奖励模型进行在线小/中型模型的评估或自动化 LLM 评估(例如 GPT-4)。人类评估有时可能存在问题,因为人类可能会受到主观标准的影响,例如回答中的权威语气而不是实际的准确性。进行评估时,用户根据事先设置的特定标准来评估生成文本的质量、相关性和适当性,可以提供更加细致入微的洞见。微调的目的不仅仅是为了改善对给定提示集的用户偏好。其主要目的是通过减少不良输出(如非法、有害、滥用、虚假或欺骗性内容)来解决 AI 安全问题。关注减轻风险行为对于确保 AI 系统的安全性和可靠性至关重要。仅基于用户偏好评估和比较模型,而不考虑它们可能导致的潜在危害,可能会产生误导,并将次优模型优先于更安全的替代方案。总之,评估 LLM 的一致性需要仔细选择基准、考虑可区分性,并结合自动评估方法和人类判断。注意提示工程和特定评估方面对于确保准确评估模型性能至关重要。在下一节中,我们将使用 PEFT 和量化微调一个小型开源 LLM(OpenLLaMa)以进行问答,并将其部署在 HuggingFace 上。
微调
正如我们在本章第一节中讨论的那样,对 LLM 进行模型微调的目标是优化模型,使其生成的输出比原始基础模型更具体于任务和上下文。在我们可能想要应用这种方法的众多任务和场景中,包括以下几种:
-
软件开发
-
文档分类
-
问答系统
-
信息检索
-
客户支持
在本节中,我们将微调一个用于问答的模型。这个步骤不专门针对 LangChain,但我们将指出一些自定义内容,其中 LangChain 可能会起作用。出于性能原因,我们将在谷歌 Colab 上运行,而不是通常的本地环境。
谷歌 Colab 是一个计算环境,提供了不同的硬件加速计算任务的手段,如张量处理单元(TPUs)和图形处理单元(GPUs)。这些在免费和专业版中都可用。对于本节中的任务目的,免费版完全足够。您可以在此网址登录到 Colab 环境:
colab.research.google.com/
请确保您在顶部菜单中将您的谷歌 Colab 机器设置为 TPU 或 GPU,以确保您有足够的资源运行此操作并且训练不会太长时间。我们将在谷歌 Colab 环境中安装所有必需的库 - 我正在添加这些库的版本,以便我们的微调是可重复的:
-
peft: Parameter-Efficient Fine-Tuning(PEFT;版本 0.5.0)
-
trl: Proximal Policy Optimization (0.6.0)
-
bitsandbytes: k 位优化器和矩阵乘法例程,用于量化 (0.41.1)
-
accelerate: 使用多 GPU、TPU、混合精度训练和使用 PyTorch 模型 (0.22.0)
-
transformers: HuggingFace transformers library with backends in JAX, PyTorch and TensorFlow (4.32.0)
-
datasets: 社区驱动的开源数据集库 (2.14.4)
-
sentencepiece: 快速标记化的 Python 包装器 (0.1.99)
-
wandb: 用于监视 Weights and Biases(W&B)训练进度的工具 (0.15.8)
-
langchain 用于在训练后将模型加载回 langchain llm (0.0.273)
我们可以从 Colab 笔记本中安装这些库,如下所示:
!pip install -U accelerate bitsandbytes datasets transformers peft trl sentencepiece wandb langchain
为了从 HuggingFace 下载和训练模型,我们需要在该平台上进行身份验证。请注意,如果您稍后想要将模型推送到 HuggingFace,则需要在 HuggingFace 上生成一个具有写入权限的新 API 令牌:huggingface.co/settings/tokens
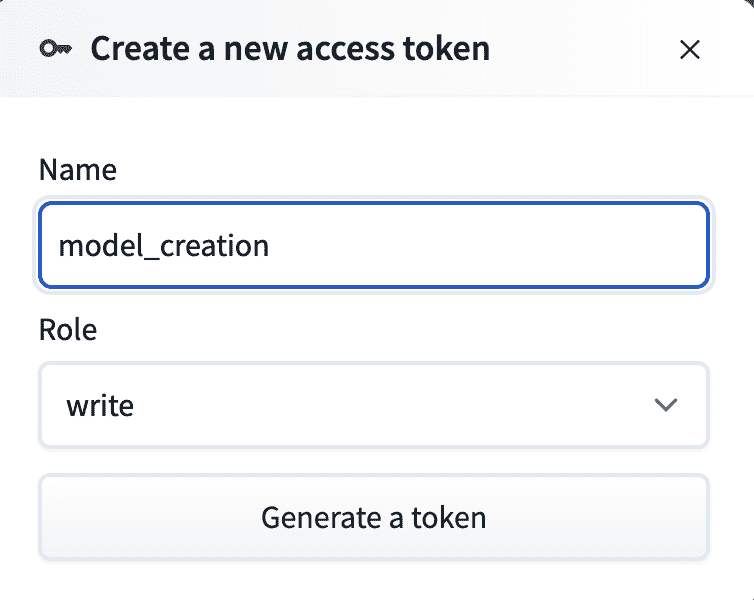
图 8.3:在 HuggingFace 上创建新的 API 令牌并授予写入权限。
我们可以像这样从笔记本进行身份验证:
import notebook_login
notebook_login()
当提示时,请粘贴您的 HuggingFace 访问令牌。
在开始之前,我们需要注意一点:在执行代码时,您需要登录到不同的服务中,所以在运行笔记本时请注意!
Weights and Biases(W&B)是一个 MLOps 平台,可以帮助开发人员从头到尾地监视和记录 ML 训练工作流程。正如前面提到的,我们将使用 W&B 来了解训练的情况,特别是模型是否随时间改进。对于 W&B,我们需要为项目命名;或者,我们可以使用 wandb 的 init() 方法:
import os
os.environ["WANDB_PROJECT"] = "finetuning"
为了用 W&B 进行身份验证,您需要在他们这里创建一个免费账户:www.wandb.ai您可以在“授权”页面找到您的 API 密钥:wandb.ai/authorize再次,我们需要粘贴我们的 API 令牌。如果之前的训练仍然处于活动状态——如果您第二次运行笔记本可能是因为之前的执行——让我们确保开始一个新的!这将确保我们在 W&B 上获得新的报告和仪表板:
if wandb.run is not None:
wandb.finish()
接下来,我们需要选择一个数据集进行优化。我们可以使用许多不同的数据集,这些数据集适用于编码、叙述、工具使用、SQL 生成、小学数学问题(GSM8k)或许多其他任务。HuggingFace 提供了丰富的数据集,可以在此网址查看:huggingface.co/datasets,这些数据集涵盖了许多不同,甚至是最小众的任务。我们也可以定制自己的数据集。例如,我们可以使用 langchain 来设置训练数据。有许多可用的过滤方法可以帮助减少数据集中的冗余。本章原本很想展示数据收集作为一个实用的配方。但是,因为复杂性的原因,我决定不在本书范围内讨论这个问题。过滤网络数据的质量可能更难一些,但有很多可能性。对于代码模型,我们可以应用代码验证技术来将部分代码分数化为质量过滤器。如果代码来自 Github,我们可以按星和存储库所有者筛选。对于自然语言的文本,质量过滤并不容易。搜索引擎排名可以作为受欢迎程度的过滤器,因为它通常基于用户对内容的参与度。此外,知识蒸馏技术可以通过事实的密度和准确性调整为一个过滤器。在这个配方中,我们在 Squad V2 数据集上进行了问答性能微调。您可以在 HuggingFace 上查看详细的数据集描述:huggingface.co/spaces/evaluate-metric/squad_v2
from datasets import load_dataset
dataset_name = "squad_v2"
dataset = load_dataset(dataset_name, split="train")
eval_dataset = load_dataset(dataset_name, split="validation")
我们正在采用训练和验证集。Squad V2 数据集有一个部分应该在训练中使用,另一个部分应该在验证中使用,正如我们可以在load_dataset(dataset_name)的输出中看到的:
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 130319
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 11873
})
})
我们将使用验证集进行提前停止。当验证错误开始恶化时,提前停止将允许我们停止训练。Squad V2 数据集由各种特征组成,我们可以在这里看到:
{'id': Value(dtype='string', id=None),
'title': Value(dtype='string', id=None),
'context': Value(dtype='string', id=None),
'question': Value(dtype='string', id=None),
'answers': Sequence(feature={'text': Value(dtype='string', id=None),
'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None)}
在训练中的基本思想是用一个问题提示模型,并将答案与数据集进行比较。我们需要一个可以在本地以不错的令牌速率运行的小型模型。LLaMa-2 模型需要您使用您的电子邮件地址签署许可协议并获得确认(公平地说,这可能非常快),因为它受到商业使用限制。LLaMa 衍生产品,如 OpenLLaMa,在 HF 排行榜上表现得相当不错:huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard。OpenLLaMa 版本 1 不能用于编码任务,因为分词器的原因。因此,让我们使用 v2!我们将使用一个 30 亿参数的模型,即使在旧硬件上也能使用:
model_id = "openlm-research/open_llama_3b_v2"
new_model_name = f"openllama-3b-peft-{dataset_name}"
我们甚至可以使用更小的模型,比如 EleutherAI/gpt-neo-125m,它也可以在资源使用和性能之间达到很好的折衷。让我们加载模型:
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
device_map="auto"
base_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
base_model.config.use_cache = False
使用 Bits and Bytes 配置,我们可以将模型量化为 8、4、3 甚至 2 位,具有更快的推断速度和更低的内存占用,而不会在性能方面产生大的代价。我们将在 Google Drive 上存储模型检查点;您需要确认您的 Google 账号登录:
from google.colab import drive
drive.mount('/content/gdrive')
我们需要通过 Google 进行身份验证才能让它起作用。我们可以将模型检查点和日志的输出目录设置为我们的 Google Drive:
output_dir = "/content/gdrive/My Drive/results"
如果您不想使用 Google Drive,只需将其设置为计算机上的目录。对于训练,我们需要设置一个分词器:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
现在我们将定义我们的训练配置。我们将设置 LORA 和其他训练参数:
from transformers import TrainingArguments, EarlyStoppingCallback
from peft import LoraConfig
# More info: https://github.com/huggingface/transformers/pull/24906
base_model.config.pretraining_tp = 1
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
training_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=10,
max_steps=2000,
num_train_epochs=100,
evaluation_strategy="steps",
eval_steps=5,
save_total_limit=5
push_to_hub=False,
load_best_model_at_end=True,
report_to="wandb"
)
有一些注释来解释其中一些参数是有必要的。push_to_hub 参数意味着我们可以在训练期间定期将模型检查点推送到 HuggingSpace Hub。为此,您需要设置 HuggingSpace 认证(如前所述,具有写权限)。如果我们选择这样做,作为 output_dir 我们可以使用 new_model_name。这将是模型在 HuggingFace 上可用的仓库名称:huggingface.co/models 或者,如我在这里所做的,我们可以将模型保存在本地或云端,例如将其保存到 Google Drive 上的一个目录。我将 max_steps 和 num_train_epochs 设置得非常高,因为我注意到训练仍然可以在许多步骤之后进行改进。我们使用提前停止与最大训练步数的高数量来使模型收敛到更高的性能。对于提前停止,我们需要将 evaluation_strategy 设置为 "steps" 并将 load_best_model_at_end=True。eval_steps 是两次评估之间的更新步数。save_total_limit=5 意味着只保存最后 5 个模型。最后,report_to="wandb" 意味着我们将向 W&B 发送训练统计信息、一些模型元数据和硬件信息,我们可以在那里查看每次运行的图形和仪表板。然后,训练可以使用我们的配置:
from trl import SFTTrainer
trainer = SFTTrainer(
model=base_model,
train_dataset=dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
dataset_text_field="question", # this depends on the dataset!
max_seq_length=512,
tokenizer=tokenizer,
args=training_args,
callbacks=[EarlyStoppingCallback(early_stopping_patience=200)]
)
trainer.train()
训练可能需要相当长的时间,即使在 TPU 设备上运行也是如此。评估和提前停止会大大减慢训练速度。如果禁用提前停止,您可以加快训练速度。随着训练的进行,我们应该看到一些统计数据,但是通过 W&B,将性能图形化展示更好:
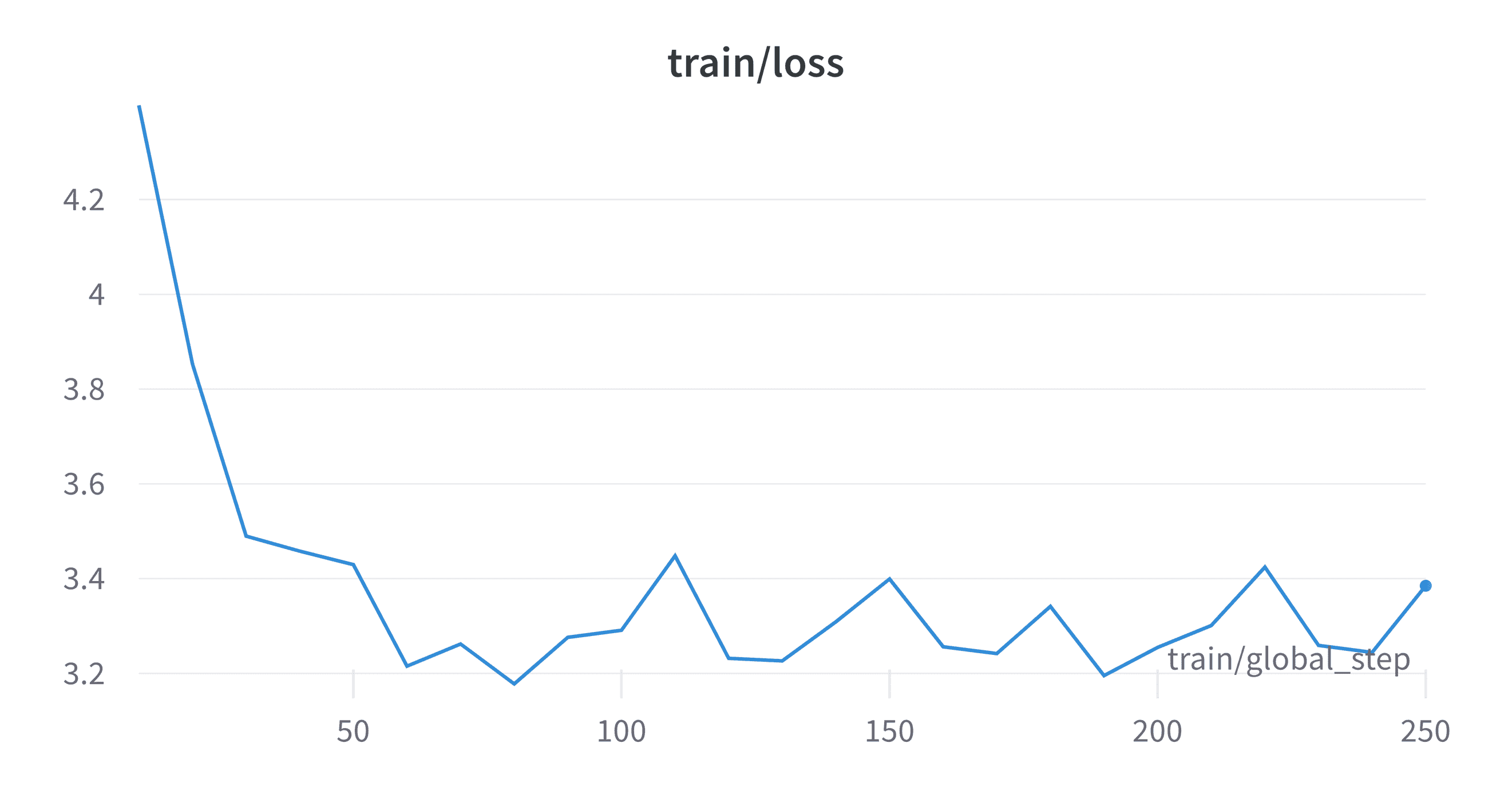
图 8.4:时间(步骤)上的微调训练损失。
训练完成后,我们可以将最终的检查点保存在磁盘上以便重新加载:
trainer.model.save_pretrained(
os.path.join(output_dir, "final_checkpoint"),
)
现在我们可以将最终模型与朋友共享,以炫耀我们通过手动推送到 HuggingFace 所实现的性能:
trainer.model.push_to_hub(
repo_id=new_model_name
)
现在,我们可以使用我们的 HuggingFace 用户名和仓库名称(新模型名称)的组合来加载模型。让我们快速展示如何在 LangChain 中使用这个模型。通常情况下,peft 模型被存储为适配器,而不是完整模型,因此加载方式略有不同:
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from langchain.llms import HuggingFacePipeline
model_id = 'openlm-research/open_llama_3b_v2'
config = PeftConfig.from_pretrained("benji1a/openllama-3b-peft-squad_v2")
model = AutoModelForCausalLM.from_pretrained(model_id)
model = PeftModel.from_pretrained(model, "benji1a/openllama-3b-peft-squad_v2")
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=256
)
llm = HuggingFacePipeline(pipeline=pipe)
到目前为止,我们一直在 Google Colab 上完成所有操作,但我们同样可以在本地执行这些操作,只需注意您需要安装 HuggingFace peft 库!到目前为止,我们已经展示了如何微调和部署开源 LLM。一些商业模型也可以根据自定义数据进行微调。例如,OpenAI 的 GPT-3.5 和 Google 的 PaLM 模型都具备这个功能。这已经集成到了一些 Python 库中。使用 Scikit-LLM 库,在任何情况下,这都只是几行代码:像这样对 PaLM 模型进行文本分类的微调:
from skllm.models.palm import PaLMClassifier
clf = PaLMClassifier(n_update_steps=100)
clf.fit(X_train, y_train) # y_train is a list of labels
labels = clf.predict(X_test)
类似地,您可以这样微调 GPT-3.5 模型进行文本分类:
from skllm.models.gpt import GPTClassifier
clf = GPTClassifier(
base_model = "gpt-3.5-turbo-0613",
n_epochs = None, # int or None. When None, will be determined automatically by OpenAI
default_label = "Random", # optional
)
clf.fit(X_train, y_train) # y_train is a list of labels
labels = clf.predict(X_test)
有趣的是,在 OpenAI 提供的微调中,所有输入都要通过一套审查系统,以确保输入符合安全标准。这样完成了微调。而在极端情况下,LLMs 可以在没有任何任务特定调整的情况下部署和查询。通过提示,我们可以实现少样本学习甚至零样本学习,这将在下一节讨论。
提示工程
提示对于引导大型语言模型(LLMs)的行为很重要,因为它们可以在不需要昂贵的重新训练的情况下,将模型的输出与人类意图对齐。精心设计的提示可以使 LLMs 适用于各种超出其原始训练范围的任务。提示充当指示,向 LLM 展示所需的输入-输出映射。下面的图片展示了为不同语言模型提供提示的几个示例(来源:“预训练、提示和预测-自然语言处理中提示方法的系统调查”作者刘和同事,2021 年):

图 8.5:提示示例,特别是使用填空形式的知识调查和摘要。
提示工程,也被称为上下文学习,指的是通过精心设计的提示技术来引导大型语言模型(LLM)的行为,而无需改变模型权重。其目标是使模型输出与给定任务的人类意图一致。通过设计良好的提示模板,模型可以取得良好的结果,有时可以与微调相媲美。但良好的提示是什么样子呢?
提示的结构
提示由三个主要组成部分组成:
-
描述任务要求、目标和输入/输出格式的指示
-
展示所需的输入-输出对的例子
-
模型必须作用于以生成输出的输入
说明清楚地向模型解释任务。示例提供了不同输入应该如何映射到输出的多样化演示。输入是模型必须进行泛化的内容。基本提示方法包括零样本提示,仅使用输入文本,以及少样本提示,其中有几个演示示例显示所需的输入输出对。研究人员已经确定了诸如多数标签偏差和最近偏差等偏见,这些偏见导致少样本性能的可变性。通过示例选择、排序和格式化等仔细的提示设计可以帮助减轻这些问题。更高级的提示技术包括指令提示,其中任务要求明确描述而不仅仅是演示。自洽性抽样生成多个输出,并选择与示例最匹配的输出。思维链(CoT)提示生成导致最终输出的明确推理步骤。这对于复杂的推理任务特别有益。思维链提示可以通过手动编写或通过增广-修剪-选择等方法自动生成。这个表格简要概述了几种提示方法与微调的比较:
| 技术 | 方法 | 关键想法 | 结果 |
|---|---|---|---|
| 微调 | 在通过提示生成的解释数据集上进行微调 | 提高模型的推理能力 | 在常识问答数据集上的准确率为 73% |
| 零样本提示 | 简单地将任务文本提供给模型并要求结果。 | 文本:“我打赌视频游戏比电影更有趣。” - 情感: | |
| 思维链(CoT) | 在响应前加上"让我们一步一步地思考" | 给模型提供推理空间以在回答之前推理 | 在数学数据集上的准确率增加了四倍 |
| 少样本提示 | 提供由输入和期望输出组成的少量演示来帮助模型理解 | 显示所需的推理格式 | 在小学数学上的准确率提高了两倍 |
| 由浅入深提示 | 逐步提示模型解决较简单的子任务。“要解决{问题},我们首先需要解决:” | 将问题分解为较小的部分 | 在某些任务中的准确度从 16%提高到 99.7% |
| 选择推理提示 | 交替选择和推理提示 | 引导模型通过推理步骤 | 提高了长推理任务的性能 |
| 自洽性抽样 | 从多个样本中选择最频繁的答案 | 增加冗余性 | 在各项基准测试中提升了 1-24 个百分点 |
| 核查器 | 训练独立模型评估响应 | 过滤出错误响应 | 提高了小学数学准确度约 20 个百分点 |
图 8.6:LLMs 的提示技术。
一些提示技术包括获取外部信息来提供缺失的上下文给 LLM,然后在生成输出之前。对于开放领域的问答,可以通过搜索引擎检索相关段落并纳入提示。对于闭卷问答,拥有证据-问题-答案格式的少样本示例比问题-答案格式更有效。对于复杂推理任务,有不同的技术来提高大型语言模型(LLMs)的可靠性:
-
提问和解释:在回答之前,通过提示模型一步一步解释其推理过程,例如使用"让我们一步一步思考"(如在 CoT 中),可以显著提高推理任务的准确性。
-
提供少样本推理链的例子有助于展示所需的格式,并指导 LLM 生成连贯的解释。
-
交替选择和推理提示:利用专门的选择提示(缩小答案空间)和推理提示(生成最终响应)的组合,与仅使用通用推理提示相比,会得到更好的结果。
-
问题分解:使用逐步提示的方法,将复杂问题分解为较小的子任务或组件,有助于提高可靠性,因为这样可以进行更有结构化和可管理的问题解决过程。
-
多次响应采样:在生成过程中从 LLMs 中采样多个响应,并选择最常见的答案,可以增加一致性,减少对单一输出的依赖。特别是,训练单独的验证模型来评估 LLMs 生成的候选响应有助于过滤出不正确或不可靠的答案,提高总体可靠性。
最后,通过提示在解释数据集上进行 LLMs 的微调,增强其在推理任务中的表现和可靠性。
少样本学习向 LLM 提供与任务相关的仅有少量输入-输出示例,而不包含明确的说明。这使得模型能够纯粹从示范中推断出意图和目标。精心选择、排序和格式化的示例可以极大地提高模型的推理能力。然而,少样本学习可能容易受到偏见和试验间的变异影响。添加明确的说明可以使模型更透明地了解意图并提高鲁棒性。总的来说,提示结合了说明和示例的优势,以最大程度地引导 LLM 完成手头的任务。
与手工设计提示不同,诸如自动提示调整之类的方法通过直接优化嵌入空间上的前缀标记来学习最佳提示。其目标是增加在给定输入情况下所需输出的可能性。总的来说,提示工程是一个积极研究的领域,用于将大型预训练的 LLM 与各种任务的人类意图保持一致。仔细设计提示可以在不昂贵的重新训练的情况下引导模型。在本节中,我们将讨论之前提到的一些(但不是所有)技术。让我们讨论 LangChain 提供的用于在 Python 中创建提示模板的工具!
模板化
提示是我们向语言模型提供的指令和示例,以引导其行为。提示模板化是指创建可重用的提示模板,可以使用不同的参数进行配置。LangChain 提供了用于在 Python 中创建提示模板的工具。模板允许使用变量输入动态生成提示。我们可以像这样创建一个基本提示模板:
from langchain import PromptTemplate
prompt = PromptTemplate("Tell me a {adjective} joke about {topic}")
此模板有两个输入变量 - {adjective} 和 {topic}。我们可以使用值格式化这些变量:
prompt.format(adjective="funny", topic="chickens")
# Output: "Tell me a funny joke about chickens"
模板格式默认为 Python f-strings,但也支持 Jinja2。提示模板可以组合成管道,其中一个模板的输出作为下一个模板的输入传递。这允许模块化重用。
聊天提示模板
对于会话代理,我们需要聊天提示模板:
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("human", "Hello, how are you?"),
("ai", "I am doing great, thanks!"),
("human", "{user_input}"),
])
template.format_messages(user_input="What is your name?")
这会格式化聊天消息列表而不是字符串。这对考虑对话历史可能会有所帮助。我们在第五章已经研究了不同的记忆方法。在此上下文中,这些方法同样相关,以确保模型输出相关且准确。提示模板化可以实现可重用的、可配置的提示。LangChain 提供了一个 Python API,方便地创建模板并动态格式化它们。模板可以组合成管道以实现模块化。高级提示工程可以进一步优化提示。
高级提示工程
LangChain 提供了一些工具,以实现高级提示工程策略,如少样本学习、动态示例选择和链式推理。
少样本学习
FewShotPromptTemplate 允许仅向模型展示任务的几个演示示例以引导它,而无需明确的说明。例如:
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate("{input} -> {output}")
examples = [
{"input": "2+2", "output": "4"},
{"input": "3+3", "output": "6"}
]
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt
)
模型必须仅通过示例推断出要做什么。
动态示例选择
要选择适合每个输入的示例,FewShotPromptTemplate 可以接受一个 ExampleSelector 而不是硬编码的示例:
from langchain.prompts import SemanticSimilarityExampleSelector
selector = SemanticSimilarityExampleSelector(...)
prompt = FewShotPromptTemplate(
example_selector=selector,
example_prompt=example_prompt
)
ExampleSelector 的实现,如 SemanticSimilarityExampleSelector,会自动为每个输入找到最相关的示例。
链式推理
在要求 LLM 推理问题时,让其在陈述最终答案之前解释其推理通常更有效。例如:
from langchain.prompts import PromptTemplate
reasoning_prompt = "Explain your reasoning step-by-step. Finally, state the answer: {question}"
prompt = PromptTemplate(
reasoning_prompt=reasoning_prompt,
input_variables=["questions"]
)
这鼓励 LLM 首先通过逻辑来思考问题,而不是只是猜测答案,然后试图在之后证明它。这被称为零射链思维。要求 LLM 解释其思维过程与其核心能力很好地吻合。少射链思维提示是少射提示,其中推理被解释为示例解决方案的一部分,旨在鼓励 LLM 在做出决定之前解释其推理。已经证明这种提示可以导致更准确的结果,但是,发现这种性能提升与模型大小成正比,而且在较小的模型中改进似乎是微不足道甚至是负面的。在**Tree of Thoughts (ToT)**提示中,我们正在为给定提示生成多个解决步骤或方法,然后使用 AI 模型对这些步骤进行批判。评价将基于模型对解决方案是否适用于问题的判断。让我们通过使用 LangChain 来实现 ToT 的更详细示例。首先,我们将使用PromptTemplates定义我们的 4 个链组件。我们需要一个解决方案模板、一个评估模板、一个推理模板和一个排名模板。让我们首先生成解决方案:
solutions_template = """
Generate {num_solutions} distinct solutions for {problem}. Consider factors like {factors}.
Solutions:
"""
solutions_prompt = PromptTemplate(
template=solutions_template,
input_variables=["problem", "factors", "num_solutions"]
)
让我们让 LLM 评估这些解决方案:
evaluation_template = """
Evaluate each solution in {solutions} by analyzing pros, cons, feasibility, and probability of success.
Evaluations:
"""
evaluation_prompt = PromptTemplate(
template=evaluation_template,
input_variables=["solutions"]
)
现在我们将更多地推理一下它们:
reasoning_template = """
For the most promising solutions in {evaluations}, explain scenarios, implementation strategies, partnerships needed, and handling potential obstacles.
Enhanced Reasoning:
"""
reasoning_prompt = PromptTemplate(
template=reasoning_template,
input_variables=["evaluations"]
)
最后,根据我们迄今为止的推理,我们可以对这些解决方案进行排名:
ranking_template = """
Based on the evaluations and reasoning, rank the solutions in {enhanced_reasoning} from most to least promising.
Ranked Solutions:
"""
ranking_prompt = PromptTemplate(
template=ranking_template,
input_variables=["enhanced_reasoning"]
)
接下来,我们从这些模板创建链,然后我们将所有内容放在一起:
chain1 = LLMChain(
llm=SomeLLM(),
prompt=solutions_prompt,
output_key="solutions"
)
chain2 = LLMChain(
llm=SomeLLM(),
prompt=evaluation_prompt,
output_key="evaluations"
)
最后,我们将这些链连接成一个SequentialChain:
tot_chain = SequentialChain(
chains=[chain1, chain2, chain3, chain4],
input_variables=["problem", "factors", "num_solutions"],
output_variables=["ranked_solutions"]
)
tot_chain.run(
problem="Prompt engineering",
factors="Requirements for high task performance, low token use, and few calls to the LLM",
num_solutions=3
)
这使我们能够在推理过程的每个阶段利用 LLM。 ToT 方法有助于通过促进探索来避免死胡同。这些技术共同增强了大型语言模型在复杂任务上推理能力的准确性、一致性和可靠性,方法包括提供更清晰的指导、使用定向数据进行微调、采用问题分解策略、结合多样化的抽样方法、整合验证机制,以及采用概率建模框架。Prompt 设计对于释放 LLM 的推理能力、模型和 Prompt 技术未来发展的潜力以及这些原则和技术对于与大型语言模型一起工作的研究人员和从业者都具有重要意义。让我们总结一下!
总结
在第一章中,我们讨论了生成模型的基本原理,特别是 LLMs(大型语言模型)及其训练。我们主要关注的是预训练阶段,通常是调整模型以符合单词和文本更广泛段落之间的相关性。对齐(alignment)是对模型输出进行评估,确保输出符合预期,而条件化(conditioning)是确保输出符合预期的过程。条件化可以引导生成式人工智能以提高安全性和质量,但它并不是一个完整的解决方案。本章重点介绍了条件化,特别是通过微调和提示进行。在微调中,语言模型通过许多以自然语言指令形式表述的任务示例以及相应的回答进行训练。通常情况下,这是通过强化学习和人类反馈(RLHF)来完成的,这涉及对人类生成的(提示,回答)对数据集进行训练,然后通过人类反馈进行强化学习,然而,已经开发出其他技术,证明其能够以更低的资源占用量产生具有竞争力的结果。在本章的第一个配方中,我们实现了一个小型开源模型用于问答的微调。有许多技术可以提高 LLMs 在复杂推理任务中的可靠性,包括分步提示,备选选择和推理提示,问题分解,抽样多个响应以及使用单独的验证模型。这些方法已被证明可以提高推理任务中的准确性和一致性。我们已经讨论并比较了几种技术。LangChain 提供了解锁高级提示策略的构建模块,例如少样本学习,动态示例选择和链式推理分解,正如我们在示例中所展示的。仔细的提示工程是对齐语言模型与复杂目标的关键。通过分解问题和添加冗余可以提高推理的可靠性。本章讨论的原则和技术为与 LLMs 一起工作的专家提供了工具包。我们可以期待模型训练和提示技术的未来发展。随着这些方法和 LLMs 的持续发展,它们可能会变得更加有效,并且对更广泛的应用范围更加有用。让我们看看你是否记得本章的一些关键点!
问题
请看一下,看看你是否能够凭记忆回答这些问题。如果你对其中任何一个不确定,我建议你回到本章的相应部分去查看一下:
-
LLM(语言模型)的背景下,什么是对齐(alignment)?
-
有哪些不同的条件化方法,我们如何区分它们?
-
调节(moderation)与条件化有何关联?
-
什么是指令调整(instruction tuning),以及它的重要性是什么?
-
量化是什么?
-
有哪些微调的方法?
-
什么是少样本学习(few-shot learning)?
-
什么是思维链提示(Chain of Thought prompting)?
-
解释一下思维树提示(Tree of Thought prompting)!
第九章:生成 AI 在生产中
在 Discord 上加入我们的书籍社区
packt.link/EarlyAccessCommunity

到目前为止,我们在本书中已经讨论了模型、代理和 LLM 应用程序以及不同的用例,但是当需要确保性能和监管要求时,模型和应用程序需要大规模部署,并且最终需要进行监视,许多问题就变得重要起来。在本章中,我们将讨论评估和可观察性,总结涵盖运行中的 AI 和决策模型的治理和生命周期管理的广泛主题,包括生成 AI 模型。虽然离线评估在受控环境中提供了对模型能力的初步理解,但是在生产中的可观察性提供了对其在实时环境中性能的持续洞察。两者在模型生命周期的不同阶段都至关重要,并相互补充,以确保大型语言模型的最佳运行和结果。我们将讨论一些用于这两种情况的工具,并举例说明。我们还将讨论围绕 LLMs 构建的模型和应用程序的部署,概述可用工具和使用 Fast API 和 Ray Serve 进行部署的示例。在整个章节中,我们将使用…与 LLMs 进行合作,您可以在书的 GitHub 存储库中找到它们:github.com/benman1/generative_ai_with_langchain本章的主要内容包括:
-
介绍
-
如何评估您的 LLM 应用程序?
-
如何部署您的 LLM 应用程序?
-
如何观察您的 LLM 应用程序?
让我们从介绍 MLOps 对 LLMs 和其他生成模型开始,了解它的含义和包含内容。
介绍
正如我们在本书中所讨论的,LLMs 近年来因其生成类似人类文本的能力而受到了重视。从创意写作到对话式聊天机器人,这些生成 AI 模型在各个行业都有着多样化的应用。然而,将这些复杂的神经网络系统从研究转化为实际部署到现实世界中会面临重大挑战。本章探讨了负责任地将生成 AI 技术投入生产的实际考虑和最佳实践。我们讨论了推理和服务的计算需求、优化技术以及围绕数据质量、偏见和透明度的关键问题。当规模扩大到数千用户时,架构和基础设施决策可能成败。与此同时,保持严格的测试、审计和道德保障对于可信赖的部署至关重要。将由模型和代理及其工具组成的应用程序部署到生产环境中涉及几个关键挑战,需要解决以确保其有效且安全的使用:
-
数据质量和偏见:训练数据可能引入偏见,反映在模型输出中。谨慎的数据策划和监控模型输出至关重要。
-
道德/合规考虑:LLMs 可能生成有害、偏见或误导性的内容。必须建立审查流程和安全准则,以防止滥用。遵守针对特定行业如医疗保健的 HIPAA 等法规。
-
资源需求:LLMs 需要大量计算资源进行训练和服务。高效基础设施对成本效益的大规模部署至关重要。
-
漂移或性能下降:模型需要持续监控,以便检测数据漂移或随时间的性能下降等问题。
-
可解释性不足:LLMs 通常是黑匣子,使其行为和决策不透明。解释性工具对于透明度至关重要。
将经过培训的 LLM 从研究转化为真实世界的生产,需要解决诸多复杂挑战,涉及可扩展性、监控和意外行为等方面。负责地部署功能强大但不可靠的模型需要认真规划可扩展性、可解释性、测试和监控等方面。精细调整、安全干预和防御性设计等技术,能够开发出有益、无害和诚实的应用程序。通过细心和准备,生成式 AI 在医学到教育等行业中具有巨大潜力。以下几个关键模式可以帮助解决上述挑战:
-
评估:可靠的基准数据集和指标对于衡量模型能力、回归和与目标的一致性至关重要。应根据任务仔细选择指标。
-
检索增强:检索外部知识可提供有用的上下文,以减少幻觉,并在预训练数据之外添加最新信息。
-
精细调整:在任务特定数据上进一步调整 LLMs,可以提高目标使用案例的性能。类似适配器模块的技术可以减少开销。
-
缓存:存储模型输出可以显著减少重复查询的延迟和成本。但缓存有效性需要仔细考虑。
-
防护栏:在句法和语义上验证模型输出,以确保可靠性。指导技术直接塑造输出结构。
-
防御性用户体验:设计时要预见到不准确性,例如在限制、属性和收集丰富的用户反馈等方面进行免责声明。
-
监控:持续追踪指标、模型行为和用户满意度,可以洞察模型问题和业务影响。
在第五章中,我们已经介绍了诸如宪法 AI 之类的与安全对齐的技术,用于减轻生成有害输出的风险。此外,LLM 具有生成有害或误导性内容的潜力。建立伦理指南和审查流程以防止误导信息、仇恨言论或任何其他有害输出的传播至关重要。人类审阅员在评估和过滤生成的内容以确保符合伦理标准方面发挥着至关重要的作用。我们不仅需要不断评估模型性能和输出以便检测数据漂移或能力丧失等问题,而且还需要为了维护性能。我们将讨论解释模型行为和决策的技术。改进高风险领域的透明度。由于 LLM 或生成性 AI 模型的规模和复杂性,部署需要大量的计算资源。这包括高性能硬件,如 GPU 或 TPU,用于处理涉及的大量计算。由于其资源密集的特性,扩展大型语言模型或生成性 AI 模型可能具有一定的挑战性。随着模型规模的增加,训练和推断的计算要求也将呈指数级增加。通常使用分布式技术,如数据并行性或模型并行性,来在多台机器或 GPU 上分发工作负载。这可以加快训练和推断时间。扩展还涉及管理与这些模型相关的大量数据的存储和检索。需要高效的数据存储和检索系统来处理庞大的模型规模。部署还涉及优化推断速度和延迟的考虑。可以采用模型压缩、量化或硬件特定优化等技术,以确保高效的部署。我们在第八章中已经讨论了一些这方面的内容。LLM 或生成性 AI 模型通常被视为黑匣子,这意味着很难理解它们是如何做出决定或生成输出的。解释性技术旨在提供对这些模型内部运作的洞察。这可能涉及方法如注意力可视化、特征重要性分析,或为模型输出生成解释。在健康、金融或法律系统等领域,解释性至关重要,因此透明度和问责制是重要的。正如我们在第八章中讨论的那样,可以对大型语言模型进行特定任务或领域的微调,以提高其在特定用例中的性能。迁移学习允许模型利用预训练知识并将其适应新任务。迁移学习和对领域特定数据的微调在需要额外的审慎的同时,也打开了新的用例。通过深思熟虑的规划和准备,生成性 AI 承诺将从创意写作到客户服务等领域中改变行业。然而,在这些系统继续渗透各种领域的同时,深思熟虑地应对这些系统的复杂性仍然至关重要。本章旨在为团队提供一种实用指南,以构建具有影响力和负责任的生成性 AI 应用。我们提到了有关数据筛选、模型开发、基础设施、监控和透明度的策略。在我们继续讨论之前,对术语的一些解释是必要的。
术语
MLOps 是一种范式,专注于可靠高效地在生产环境中部署和维护机器学习模型。它将 DevOps 的实践与机器学习结合起来,将算法从实验性系统过渡到生产系统。MLOps 旨在增加自动化,提高生产模型的质量,并解决业务和监管要求。LLMOps 是 MLOps 的一种专业子类别。它指的是作为产品的一部分对大型语言模型进行微调和运行的操作能力和基础设施。虽然它可能与 MLOps 的概念没有显著不同,但区别在于与处理、精炼和部署像 GPT-3 这样的庞大语言模型相关的具体要求。术语LMOps比 LLMOps 更具包容性,因为它涵盖了各种类型的语言模型,包括大型语言模型和较小的生成模型。该术语承认了语言模型的不断扩展的景观以及它们在操作环境中的相关性。FOMO(基础模型编排)专门解决了在使用基础模型时面临的挑战。它强调了管理多步骤流程、与外部资源集成以及协调涉及这些模型的工作流程的需求。术语ModelOps专注于部署的 AI 和决策模型的治理和生命周期管理。更广泛地说,AgentOps涉及 LLMs 和其他 AI 代理的运行管理,确保它们的适当行为,管理它们的环境和资源访问,并促进代理之间的互动,同时解决与意外结果和不兼容目标相关的问题。虽然 FOMO 强调了专门与基础模型合作时面临的独特挑战,但 LMOps 提供了对除基础模型之外更广泛范围的语言模型的更具包容性和全面的覆盖。LMOps 承认了语言模型在各种操作用例中的多功能性和日益重要性,同时仍然属于更广泛的 MLOps 的范畴。最后,AgentOps 明确强调了由带有某些启发式操作的生成模型组成的代理的互动性质,并包括工具。所有这些非常专业的术语的出现都突显了该领域的快速发展;然而,它们的长期普及尚不清楚。MLOps 是一个在业界广泛使用的已建立的术语,得到了很大的认可和采用。因此,在本章的其余部分我们将坚持使用 MLOps。在将任何代理或模型投入生产之前,我们应该首先评估其输出,因此我们应该从这开始。我们将重点关注 LangChain 提供的评估方法。
如何评估你的 LLM 应用程序?
对 LLMs 进行评估,无论是作为独立实体还是与代理链结合使用,都是确保它们正确运行并产生可靠结果的关键,并且是机器学习生命周期的组成部分。评估过程确定了模型在有效性、可靠性和效率方面的性能。评估大型语言模型的目标是了解它们的优点和缺点,提高准确性和效率,减少错误,从而最大限度地提高它们在解决实际问题中的用途。这个评估过程通常在开发阶段离线进行。离线评估在受控测试条件下提供了模型性能的初步见解,并包括超参数调整、与同行模型或已建立标准的基准比较等方面。它们提供了在部署之前对模型进行改进的必要第一步。评估提供了关于 LLM 能否生成相关、准确和有用输出的见解。在 LangChain 中,有多种评估 LLMs 输出的方法,包括比较链输出、两两字符串比较、字符串距离和嵌入距离。评估结果可用于根据输出的比较确定首选模型。还可以计算置信区间和 p 值以评估评估结果的可靠性。LangChain 提供了几种工具来评估大型语言模型的输出。一个常见的方法是使用PairwiseStringEvaluator比较不同模型或提示的输出。这提示评估模型在相同输入上选择两个模型输出,并汇总结果以确定整体首选模型。其他评估器允许根据特定标准(如正确性、相关性和简洁性)评估模型输出。CriteriaEvalChain可以根据自定义或预定义的原则对输出进行评分,而无需参考标签。还可以通过指定不同的聊天模型(如 ChatGPT)来配置评估模型。让我们使用PairwiseStringEvaluator比较不同提示或 LLMs 的输出,该评估器提示 LLM 根据特定输入选择首选输出。
比较两个输出
此评估需要一个评估器、一个输入数据集以及两个或更多的 LLMs、链或代理来比较。评估将汇总结果以确定首选模型。评估过程涉及多个步骤:
-
创建评估器:使用
load_evaluator()函数加载评估器,指定评估器的类型(在本例中为pairwise_string)。 -
选择数据集:使用
load_dataset()函数加载输入数据集。 -
定义要比较的模型:使用必要的配置初始化要比较的 LLMs、Chains 或 Agents。这涉及初始化语言模型以及任何额外所需的工具或代理。
-
生成响应:为每个模型生成输出,然后再进行评估。通常会批量处理以提高效率。
-
评估成对:通过比较每个输入的不同模型的输出来评估结果。经常使用随机选择顺序来减少位置偏差。
这里有一个来自成对字符串比较文档的示例:
from langchain.evaluation import load_evaluator
evaluator = load_evaluator("labeled_pairwise_string")
evaluator.evaluate_string_pairs(
prediction="there are three dogs",
prediction_b="4",
input="how many dogs are in the park?",
reference="four",
)
评估器的输出应如下所示:
{'reasoning': 'Both responses are relevant to the question asked, as they both provide a numerical answer to the question about the number of dogs in the park. However, Response A is incorrect according to the reference answer, which states that there are four dogs. Response B, on the other hand, is correct as it matches the reference answer. Neither response demonstrates depth of thought, as they both simply provide a numerical answer without any additional information or context. \n\nBased on these criteria, Response B is the better response.\n',
'value': 'B',
'score': 0}
评估结果包括一个介于 0 和 1 之间的分数,表示代理的有效性,有时还包括概述评估过程并证明分数的推理。在这个反对参考资料的例子中,基于输入,两个结果事实上都是不正确的。我们可以移除参考资料,让一个 LLM 来评判输出,但是这样做可能是危险的,因为指定的也可能是不正确的。
根据标准比较
LangChain 为不同的评估标准提供了几个预定义的评估器。这些评估器可用于根据特定的评分标准或标准集合评估输出。一些常见的标准包括简洁性、相关性、正确性、连贯性、帮助性和争议性。CriteriaEvalChain允许您根据自定义或预定义标准评估模型输出。它提供了一种验证 LLM 或 Chain 的输出是否符合一组定义的标准的方法。您可以使用此评估器评估正确性、相关性、简洁性和生成的输出的其他方面。CriteriaEvalChain可以配置为使用或不使用参考标签。没有参考标签,评估器依赖于 LLM 的预测答案,并根据指定的标准对其进行评分。有了参考标签,评估器将预测的答案与参考标签进行比较,并确定其是否符合标准。LangChain 中默认使用的评估 LLM 是 GPT-4。但是,您可以通过指定其他聊天模型(例如 ChatAnthropic 或 ChatOpenAI)和所需的设置(例如温度)来配置评估 LLM。通过将 LLM 对象作为参数传递给load_evaluator()函数,可以使用自定义 LLM 加载评估器。LangChain 支持自定义标准和预定义原则进行评估。可以使用criterion_name: criterion_description对的字典定义自定义标准。这些标准可以根据特定要求或标准来评估输出。这里有一个简单的示例:
custom_criteria = {
"simplicity": "Is the language straightforward and unpretentious?",
"clarity": "Are the sentences clear and easy to understand?",
"precision": "Is the writing precise, with no unnecessary words or details?",
"truthfulness": "Does the writing feel honest and sincere?",
"subtext": "Does the writing suggest deeper meanings or themes?",
}
evaluator = load_evaluator("pairwise_string", criteria=custom_criteria)
evaluator.evaluate_string_pairs(
prediction="Every cheerful household shares a similar rhythm of joy; but sorrow, in each household, plays a unique, haunting melody.",
prediction_b="Where one finds a symphony of joy, every domicile of happiness resounds in harmonious,"
" identical notes; yet, every abode of despair conducts a dissonant orchestra, each"
" playing an elegy of grief that is peculiar and profound to its own existence.",
input="Write some prose about families.",
)
我们可以得到这两个输出的非常微妙的比较,如下结果所示:
{'reasoning': 'Response A is simple, clear, and precise. It uses straightforward language to convey a deep and sincere message about families. The metaphor of music is used effectively to suggest deeper meanings about the shared joys and unique sorrows of families.\n\nResponse B, on the other hand, is less simple and clear. The language is more complex and pretentious, with phrases like "domicile of happiness" and "abode of despair" instead of the simpler "household" used in Response A. The message is similar to that of Response A, but it is less effectively conveyed due to the unnecessary complexity of the language.\n\nTherefore, based on the criteria of simplicity, clarity, precision, truthfulness, and subtext, Response A is the better response.\n\n[[A]]', 'value': 'A', 'score': 1}
或者,您可以使用 LangChain 中提供的预定义原则,比如来自宪法人工智能的原则。这些原则旨在评估输出的道德、有害和敏感方面。在评估中使用原则可以更专注地评估生成的文本。
字符串和语义比较
LangChain 支持字符串比较和距离度量来评估 LLM 输出。像 Levenshtein 和 Jaro 这样的字符串距离度量提供了一个量化的相似度衡量标准,用于在预测和参考字符串之间的相似性。使用像 SentenceTransformers 这样的模型计算语义相似性的嵌入距离,计算生成和期望文本之间的语义相似性。嵌入距离评估器可以使用嵌入模型,如基于 GPT-4 或 Hugging Face 嵌入的模型,来计算预测字符串和参考字符串之间的向量距离。这可以衡量两个字符串之间的语义相似性,并提供有关生成文本质量的见解。以下是文档中的一个快速示例:
from langchain.evaluation import load_evaluator
evaluator = load_evaluator("embedding_distance")
evaluator.evaluate_strings(prediction="I shall go", reference="I shan't go")
评估器返回得分 0.0966466944859925。您可以通过load_evaluator()调用中的embeddings参数更改所使用的嵌入。这通常比旧的字符串距离度量方法效果更好,但这些方法也可用,从而可以进行简单的单元测试和准确性评估。字符串比较评估器将预测的字符串与参考字符串或输入进行比较。字符串距离评估器使用诸如 Levenshtein 或 Jaro 距离之类的距离度量来衡量预测和参考字符串之间的相似性或不相似性。这提供了预测字符串与参考字符串的相似性的定量衡量。最后,还有一个 agent 轨迹评估器,其中使用evaluate_agent_trajectory()方法来评估输入、预测和 agent 轨迹。我们还可以使用 LangSmith 与数据集比较我们的性能。我们将在关于可观测性部分更多地讨论 LangChain 的伴侣项目 LangSmith。
基准数据集
使用 LangSmith,我们可以评估模型在数据集上的性能。让我们通过一个示例来了解。首先,请确保您在此处创建 LangSmith 账户:smith.langchain.com/ 您可以获取 API 密钥,并将其设置为环境中的LANGCHAIN_API_KEY。我们还可以设置项目 ID 和跟踪的环境变量:
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "My Project"
这将配置 LangChain 记录跟踪。如果我们不告诉 LangChain 项目 ID,它将对default项目进行记录。设置完成后,当我们运行 LangChain agent 或 chain 时,我们将能够在 LangSmith 上看到跟踪。让我们记录一次运行吧!
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
llm.predict("Hello, world!")
我们将在 LangSmith 上看到如下内容:LangSmith 允许我们在 LangSmith 项目页面上列出到目前为止所有的运行:smith.langchain.com/projects
from langsmith import Client
client = Client()
runs = client.list_runs()
print(runs)
我们可以按照特定项目或run_type列出运行,例如"chain"。每个运行都有输入和输出,就像我们在这里看到的那样:
print(f"inputs: {runs[0].inputs}")
print(f"outputs: {runs[0]. outputs}")
我们可以使用create_example_from_run()函数从现有的 agent 运行中创建数据集,或者从其他任何东西创建数据集。以下是如何使用一组问题创建数据集的方法:
questions = [
"A ship's parts are replaced over time until no original parts remain. Is it still the same ship? Why or why not?", # The Ship of Theseus Paradox
"If someone lived their whole life chained in a cave seeing only shadows, how would they react if freed and shown the real world?", # Plato's Allegory of the Cave
"Is something good because it is natural, or bad because it is unnatural? Why can this be a faulty argument?", # Appeal to Nature Fallacy
"If a coin is flipped 8 times and lands on heads each time, what are the odds it will be tails next flip? Explain your reasoning.", # Gambler's Fallacy
"Present two choices as the only options when others exist. Is the statement \"You're either with us or against us\" an example of false dilemma? Why?", # False Dilemma
"Do people tend to develop a preference for things simply because they are familiar with them? Does this impact reasoning?", # Mere Exposure Effect
"Is it surprising that the universe is suitable for intelligent life since if it weren't, no one would be around to observe it?", # Anthropic Principle
"If Theseus' ship is restored by replacing each plank, is it still the same ship? What is identity based on?", # Theseus' Paradox
"Does doing one thing really mean that a chain of increasingly negative events will follow? Why is this a problematic argument?", # Slippery Slope Fallacy
"Is a claim true because it hasn't been proven false? Why could this impede reasoning?", # Appeal to Ignorance
]
shared_dataset_name = "Reasoning and Bias"
ds = client.create_dataset(
dataset_name=shared_dataset_name, description="A few reasoning and cognitive bias questions",
)
for q in questions:
client.create_example(inputs={"input": q}, dataset_id=ds.id)
然后我们可以以这样的方式在数据集上运行 LLM agent 或 chain:
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
llm = ChatOpenAI(model="gpt-4", temperature=0.0)
def construct_chain():
return LLMChain.from_string(
llm,
template="Help out as best you can.\nQuestion: {input}\nResponse: ",
)
我们使用构造函数来为每个输入进行初始化。为了评估模型在该数据集上的性能,我们需要定义一个评估器,正如我们在前一节中所见。
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig
evaluation_config = RunEvalConfig(
evaluators=[
# Arbitrary criterion as a key: value pair in the criteria dict:
RunEvalConfig.Criteria({"helpfulness": "Is the response helpful?"}),
RunEvalConfig.Criteria({"insightful": "Is the response carefully thought out?"})
]
)
我们将一个数据集和评估器传递给run_on_dataset()来生成指标和反馈:
from langchain.smith import run_on_dataset
results = run_on_dataset(
client=client,
dataset=dataset,
llm_factory=lambda: my_agent,
evaluation=evaluation_config
)
同样地,我们可以传递一个数据集和评估器给run_on_dataset()来异步生成指标和反馈。我们可以在 LangSmith UI 中查看评估器反馈,以确定改进的方向。

图 9.1:LangSmith 中的评估器。
我们可以单击其中任何一个评估器来查看一些细节,例如,对于仔细思考的评估器,我们得到了这个包含了由 LLM 提供的原始答案的提示:
You are assessing a submitted answer on a given task or input based on a set of criteria. Here is the data:
[BEGIN DATA]
***
[Input]: Is something good because it is natural, or bad because it is unnatural? Why can this be a faulty argument?
***
[Submission]: The argument that something is good because it is natural, or bad because it is unnatural, is often referred to as the "appeal to nature" fallacy. This argument is faulty because it assumes that what is natural is automatically good or beneficial, and what is unnatural is automatically bad or harmful. However, this is not always the case. For example, many natural substances can be harmful or deadly, such as certain plants or animals. Conversely, many unnatural things, such as modern medicine or technology, can greatly benefit our lives. Therefore, whether something is natural or unnatural is not a reliable indicator of its value or harm.
***
[Criteria]: insightful: Is the response carefully thought out?
***
[END DATA]
Does the submission meet the Criteria? First, write out in a step by step manner your reasoning about each criterion to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer of whether the submission meets all criteria. At the end, repeat just the letter again by itself on a new line.
我们得到了这个评估:
The criterion is whether the response is insightful and carefully thought out.
The submission provides a clear and concise explanation of the "appeal to nature" fallacy, demonstrating an understanding of the concept. It also provides examples to illustrate why this argument can be faulty, showing that the respondent has thought about the question in depth. The response is not just a simple yes or no, but a detailed explanation that shows careful consideration of the question.
Therefore, the submission does meet the criterion of being insightful and carefully thought out.
Y
Y
提高一些类型问题的性能的一种方式是进行少量提示。LangSmith 也可以帮助我们。您可以在 LangSmith 文档中找到更多此类示例。这就结束了评估。现在我们已经评估了我们的代理,假设我们对性能感到满意,我们就部署它!
如何部署您的大型语言模型应用?
鉴于大型语言模型在各个领域的广泛使用,了解如何有效地将模型和应用程序部署到生产环境中是至关重要的。部署服务和框架可以帮助解决技术障碍。有很多不同的方法可以将大型语言模型应用或具有生成能力的应用程序投入生产。生产部署需要对生成式人工智能生态系统进行研究和了解,这包括不同方面,包括:
-
模型和语言模型即服务:LLMs 和其他模型可以直接运行,也可以作为 API 提供在供应商提供的基础设施上。
-
推理启发式:检索增强生成(RAG),思维之树等等。
-
向量数据库:用于检索上下文相关信息以供提示使用。
-
提示工程工具:这些工具可以在不需要昂贵的微调或敏感数据的情况下进行上下文学习。
-
预训练和微调:适用于专门用于特定任务或领域的模型。
-
提示日志,测试和分析:一种新兴的领域,灵感来自于对大型语言模型性能的理解和改进的愿望。
-
自定义的语言模型堆栈:一组用于塑造和部署在开源模型上构建解决方案的工具。
我们在第一章和第三章讨论了模型,第 4-7 章的推理启发式,第五章的向量数据库以及第八章的提示和微调。在本章中,我们将重点关注部署的日志记录、监控和自定义工具。LLM 通常使用外部 LLM 提供商或自托管模型来利用。对于外部提供商,计算负担由类似于 OpenAI 或 Anthropic 的公司承载,而 LangChain 则促进业务逻辑实现。然而,自托管开源 LLM 可以显着降低成本、延迟和隐私问题。一些拥有基础设施的工具提供完整的包。例如,您可以使用 Chainlit 部署 LangChain 代理,并创建带有 Chainlit 的 ChatGPT UI。一些关键特点包括中间步骤可视化、元素管理和显示(图像、文本、走马灯等)以及云部署。BentoML 是一个框架,可以将机器学习应用程序容器化,以便于使用它们作为独立运行和扩展的微服务,自动生成 OpenAPI 和 gRPC 端点。您还可以将 LangChain 部署到不同的云服务节点,例如 Azure Machine Learning Online Endpoint。使用 Steamship,LangChain 开发人员可以快速部署其应用程序,其中包括:生产就绪的端点、依赖项的水平扩展、应用程序状态的持久性存储、多租户支持等。下表总结了部署大型语言模型应用程序的服务和框架:
| 名称 | 描述 | 类型 |
|---|---|---|
| Streamlit | 用于构建和部署 Web 应用程序的开源 Python 框架 | 框架 |
| Gradio | 允许您在 Hugging Face 上封装模型并进行托管的框架 | 框架 |
| Chainlit | 构建和部署对话式 ChatGPT 应用程序 | 框架 |
| Apache Beam | 用于定义和编排数据处理工作流程的工具 | 框架 |
| Vercel | 用于部署和扩展 Web 应用程序的平台 | 云服务 |
| FastAPI | 用于构建 API 的 Python Web 框架 | 框架 |
| Fly.io | 具有自动缩放和全球 CDN 的应用程序托管平台 | 云服务 |
| DigitalOcean 应用程序平台 | 构建、部署和扩展应用程序的平台 | 云服务 |
| Google Cloud | 提供像 Cloud Run 这样的服务,可托管和扩展容器化的应用程序 | 云服务 |
| Steamship | 用于部署和扩展模型的 ML 基础设施平台 | 云服务 |
| Langchain-serve | 用于将 LangChain 代理作为 Web API 提供的工具 | 框架 |
| BentoML | 模型服务、打包和部署的框架 | 框架 |
| OpenLLM | 提供商业 LLM 的开放 API | 云服务 |
| Databutton | 无代码平台,用于构建和部署模型工作流程 | 框架 |
| Azure ML | Azure 上的托管 ML 操作服务,用于模型 | 云服务 |
图 9.2:部署大型语言模型应用程序的服务和框架。
所有这些都有不同的用例很好地记录,通常直接引用 LLM。我们已经展示了使用 Streamlit 和 Gradio 的示例,并讨论了如何以 HuggingFace Hub 为例部署它们。运行 LLM 应用程序有几个主要要求:
-
可扩展的基础设施,以处理计算密集型模型和潜在的流量激增。
-
实时为模型输出提供服务的低延迟
-
用于管理长对话和应用程序状态的持久存储
-
用于集成到最终用户应用程序的 API
-
监控和日志记录以跟踪指标和模型行为
维持成本效益在大量用户交互和与 LLM 服务相关的高成本的情况下可能具有挑战性。管理效率的策略包括自托管模型、根据流量自动调整资源分配、使用抢占式实例、独立扩展和批处理请求以更好地利用 GPU 资源。工具和基础设施的选择决定了这些需求之间的权衡。灵活性和便利性非常重要,因为我们希望能够快速迭代,这对于 ML 和 LLM 领域的动态性是至关重要的。避免被绑定在一个解决方案上是至关重要的。一个灵活的、可扩展的服务层对各种模型都很关键。模型组合和云提供商的选择构成了这种灵活性方程的一部分。对于最大的灵活性,Infrastructure as Code(IaC)工具如 Terraform、CloudFormation 或 Kubernetes YAML 文件可以可靠且快速地重新创建您的基础设施。此外,持续集成和持续交付(CI/CD)流水线可以自动化测试和部署过程,以减少错误并促进更快的反馈和迭代。设计健壮的 LLM 应用服务可能是一个复杂的任务,需要在评估服务框架时了解权衡和关键考虑因素。利用这些解决方案之一进行部署使开发人员能够专注于开发有影响力的 AI 应用,而不是基础设施。如前所述,LangChain 与几个开源项目和框架(如 Ray Serve、BentoML、OpenLLM、Modal 和 Jina)很好地配合。在下一节中,我们将基于 FastAPI 部署一个聊天服务 Web 服务器。
Fast API Web 服务器
FastAPI 是部署 Web 服务器非常受欢迎的选择。设计快速、易于使用和高效,它是一个用 Python 构建 API 的现代高性能 Web 框架。Lanarky 是一个小型的开源库,用于部署 LLM 应用程序,它提供了方便的封装,使您能够同时获得 REST API 端点和浏览器中的可视化,而且您只需要几行代码。
REST API(表征状态传输应用程序编程接口)是一组规则和协议,允许不同的软件应用程序通过互联网相互通信。它遵循 REST 的原则,这是一种用于设计网络应用程序的体系结构风格。REST API 使用 HTTP 方法(例如 GET、POST、PUT、DELETE)对资源执行操作,通常以标准化格式(例如 JSON 或 XML)发送和接收数据。
在库文档中,有几个示例,包括具有源链的检索 QA、会话检索应用程序和零射击代理。跟随另一个示例,我们将使用 Lanarky 实现一个带有聊天机器人的 Web 服务器。我们将使用 Lanarky 设置一个与 Gradio 集成的 Web 服务器,创建一个带有 LLM 模型和设置的 ConversationChain 实例,并定义用于处理 HTTP 请求的路由。首先,我们将导入必要的依赖项,包括用于创建 Web 服务器的 FastAPI,用于与 Gradio 集成的 mount_gradio_app,用于处理 LLM 对话的 ConversationChain 和 ChatOpenAI,以及其他所需模块:
from fastapi import FastAPI
from lanarky.testing import mount_gradio_app
from langchain import ConversationChain
from langchain.chat_models import ChatOpenAI
from lanarky import LangchainRouter
from starlette.requests import Request
from starlette.templating import Jinja2Templates
请注意,您需要根据第三章的说明设置环境变量。定义了一个create_chain()函数来创建ConversationChain的一个实例,指定了 LLM 模型及其设置:
def create_chain():
return ConversationChain(
llm=ChatOpenAI(
temperature=0,
streaming=True,
),
verbose=True,
)
我们将链设置为ConversationChain。
chain = create_chain()
将变量app分配给mount_gradio_app,它创建一个名为ConversationChainDemo的FastAPI实例,并将其与 Gradio 集成:
app = mount_gradio_app(FastAPI(title="ConversationChainDemo"))
变量模板被设置为Jinja2Templates类,指定了用于渲染模板的目录。这指定了网页将如何显示,允许各种自定义:
templates = Jinja2Templates(directory="webserver/templates")
使用 FastAPI 装饰器@app.get定义了用于处理根路径(/)的 HTTP GET 请求的端点。与此端点关联的函数返回一个模板响应,用于渲染 index.xhtml 模板:
@app.get("/")
async def get(request: Request):
return templates.TemplateResponse("index.xhtml", {"request": request})
创建了一个LangchainRouter类的路由器对象。该对象负责定义和管理与ConversationChain实例相关联的路由。我们可以向路由器添加其他路由,用于处理基于 JSON 的聊天,甚至可以处理 WebSocket 请求:
langchain_router = LangchainRouter(
langchain_url="/chat", langchain_object=chain, streaming_mode=1
)
langchain_router.add_langchain_api_route(
"/chat_json", langchain_object=chain, streaming_mode=2
)
langchain_router.add_langchain_api_websocket_route("/ws", langchain_object=chain)
app.include_router(langchain_router)
现在我们的应用程序知道如何处理请求,这些请求是针对路由器中定义的指定路由发出的,并将它们定向到适当的函数或处理程序进行处理。我们将使用 Uvicorn 来运行我们的应用程序。Uvicorn 擅长支持高性能、异步框架,如 FastAPI 和 Starlette。由于其异步特性,它能够处理大量的并发连接,并在负载较重时表现良好。我们可以像这样从终端运行 Web 服务器:
uvicorn webserver.chat:app –reload
这个命令启动了一个 Web 服务器,在本地地址 127.0.0.1:8000 可以在浏览器中查看。--reload 开关特别方便,因为这意味着一旦你做出任何更改,服务器将自动重新启动。以下是我们刚刚部署的聊天机器人应用的快照:

图 9.3: Flask/Lanarky 中的聊天机器人
我认为我们的工作量相当小,这看起来相当不错。它还拥有一些很棒的功能,比如 REST API,Web UI 和 WebSocket 接口。虽然 Uvicorn 本身并不提供内置的负载平衡功能,但它可以与其他工具或技术(如 Nginx 或 HAProxy)一起工作,以在部署设置中实现负载平衡,从而将传入的客户端请求分发给多个工作进程或实例。Uvicorn 与负载平衡器的使用可以实现横向扩展,处理大量流量,为客户端提供改进的响应时间,增强容错能力。在下一节,我们将看到如何使用 Ray 构建稳健且经济高效的生成式 AI 应用。我们将使用 LangChain 进行文本处理,并使用 Ray 进行索引和服务方面的扩展,构建一个简单的搜索引擎。
Ray
Ray 提供了一个灵活的框架,以满足在生产环境中扩展复杂神经网络的基础设施挑战,通过在集群中扩展生成式 AI 工作负载。Ray 通过在低延迟服务、分布式训练和大规模批量推断等方面帮助解决常见的部署需求。Ray 还能够轻松地按需启动微调或将现有工作负载从一台机器扩展到多台机器。具体的功能包括:
-
使用 Ray Train 在 GPU 集群上调度分布式训练任务
-
使用 Ray Serve 在规模上部署预训练模型,以实现低延迟服务
-
使用 Ray Data 在 CPU 和 GPU 上并行运行大批推断
-
编排端到端的生成式 AI 工作流,包括训练、部署和批处理
我们将使用 LangChain 和 Ray 来构建一个简单的搜索引擎,以此跟随 Waleed Kadous 在 anyscale 博客和 Github 上的 langchain-ray 仓库实现的示例。你可以把这看作是 Channel 5 中实现的一个扩展。你可以在这里看到这个示例的完整代码:github.com/benman1/generative_ai_with_langchain 你也可以看到如何将其作为 FastAPI 服务器运行。首先,我们将摄取并索引 Ray 文档,以便能够快速找到搜索查询的相关段落:
# Load the Ray docs using the LangChain loader
loader = RecursiveUrlLoader("docs.ray.io/en/master/")
docs = loader.load()
# Split docs into sentences using LangChain splitter
chunks = text_splitter.create_documents(
[doc.page_content for doc in docs],
metadatas=[doc.metadata for doc in docs])
# Embed sentences into vectors using transformers
embeddings = LocalHuggingFaceEmbeddings('multi-qa-mpnet-base-dot-v1')
# Index vectors using FAISS via LangChain
db = FAISS.from_documents(chunks, embeddings)
通过摄取文档、拆分成句子、将句子嵌入和索引向量来构建我们的搜索索引。另外,我们也可以通过并行化嵌入步骤来加速索引:
# Define shard processing task
@ray.remote(num_gpus=1)
def process_shard(shard):
embeddings = LocalHuggingFaceEmbeddings('multi-qa-mpnet-base-dot-v1')
return FAISS.from_documents(shard, embeddings)
# Split chunks into 8 shards
shards = np.array_split(chunks, 8)
# Process shards in parallel
futures = [process_shard.remote(shard) for shard in shards]
results = ray.get(futures)
# Merge index shards
db = results[0]
for result in results[1:]:
db.merge_from(result)
通过在每个分片中并行运行嵌入,我们可以显著减少索引时间。然后将数据库索引保存到磁盘:
db.save_local(FAISS_INDEX_PATH)
FAISS_INDEX_PATH 是一个任意的文件名。我已将其设置为 faiss_index.db。接下来,我们将看到如何使用 Ray Serve 提供搜索查询服务。
# Load index and embedding
db = FAISS.load_local(FAISS_INDEX_PATH)
embedding = LocalHuggingFaceEmbeddings('multi-qa-mpnet-base-dot-v1')
@serve.deployment
class SearchDeployment:
def __init__(self):
self.db = db
self.embedding = embedding
def __call__(self, request):
query_embed = self.embedding(request.query_params["query"])
results = self.db.max_marginal_relevance_search(query_embed)
return format_results(results)
deployment = SearchDeployment.bind()
# Start service
serve.run(deployment)
这让我们可以将搜索查询作为 Web 端点提供!运行后,我得到了这个输出:
Started a local Ray instance.
View the dashboard at 127.0.0.1:8265
我们现在可以从 Python 进行查询:
import requests
query = "What are the different components of Ray"
" and how can they help with large language models (LLMs)?”
response = requests.post("http://localhost:8000/", params={"query": query})
print(response.text)
对我而言,服务器在https://docs.ray.io/en/latest/ray-overview/use-cases.xhtml获取了 Ray 的用例页面。我真的很喜欢 Ray 仪表板上的监控,它看起来像这样:
图 9.4:Ray 仪表板。
这个仪表板非常强大,因为它可以为您提供大量的指标和其他信息。收集指标真的很容易,因为您所需做的就是设置和更新部署对象或者 actor 类型的变量,例如 Counter、Gauge、Histogram 或其他类型。对于时序图表,您应该安装 Prometheus 或 Grafana 服务器。正如您在 Github 上的完整实现中所看到的,我们也可以将其作为 FastAPI 服务器运行。这结束了我们带有 LangChain 和 Ray 的简单语义搜索引擎。随着模型和 LLM 应用程序变得越来越复杂,并与业务应用程序的结构密切交织,生产中的可观察性和监控变得必不可少,以确保它们的准确性、效率和可靠性。接下来的部分将重点放在监视 LLM 的重要性,并突出了全面监控策略中要跟踪的关键指标。
如何观察 LLM 应用程序?
现实世界运营的动态性意味着离线评估中评估的条件几乎不可能涵盖 LLM 在生产系统中可能遇到的所有潜在场景。因此,生产中需要可观察性 - 更持续的、实时的观察,以捕捉离线测试无法预料的异常情况。可观察性允许监视模型与实际输入数据和用户在生产中交互时的行为和结果。它包括日志记录、跟踪、追踪和警报机制,以确保系统功能良好、优化性能,并及早发现诸如模型漂移之类的问题。正如所讨论的,LLM 已成为医疗、电子商务和教育等许多行业应用程序中越来越重要的组成部分。
跟踪、追踪和监控是软件运行和管理领域的三个重要概念。虽然都与理解和改进系统性能有关,但它们各自扮演着不同的角色。跟踪和追踪都是为了保持详细的历史记录以进行分析和调试,而监控旨在实时观察和及时发现问题,以确保系统功能始终处于最佳状态。这三个概念都属于可观察性的范畴。
监控是持续监视系统或应用程序性能的过程。这可能涉及持续收集和分析与系统健康相关的指标,如内存使用、CPU 利用率、网络延迟以及整体应用程序/服务性能(如响应时间)。有效的监控包括设置异常或意外行为的警报系统 - 在超出某些阈值时发送通知。虽然跟踪和追踪是关于保留详细的历史记录以进行分析和调试,但监控旨在实时观察和立即意识到问题,以确保系统功能始终处于最佳状态。
监控和可观测性的主要目标是通过实时数据提供对模型性能和行为的洞察。这有助于:
-
预防模型漂移:模型可能随着时间的推移而因输入数据或用户行为特征的变化而恶化。定期监控可以早期识别这种情况并采取纠正措施。
-
性能优化:通过跟踪推理时间、资源使用情况和吞吐量等指标,您可以调整以提高 LLM 在生产中的效率和效果。
-
A/B 测试:它有助于比较模型中轻微差异可能导致不同结果的情况,从而有助于决策改进模型。
-
调试问题:监控有助于识别运行时可能发生的未预料问题,从而快速解决。
考虑监控策略时,有几点需要考虑:
-
监控的指标:根据所需的模型性能,定义关键的感兴趣的指标,如预测准确性、延迟、吞吐量等。
-
监控频率:应根据模型对操作的关键程度来确定频率 - 高度关键的模型可能需要近实时监控。
-
日志记录:日志应提供关于 LLM 执行的每个相关操作的详细信息,以便分析人员可以追踪任何异常情况。
-
警报机制:如果检测到异常行为或性能急剧下降,系统应该提出警报。
通过验证、阴影启动和解释以及可靠的离线评估等方式持续评估 LLM 的行为和性能,组织可以识别和消除潜在风险,保持用户信任,并提供最佳体验。以下是相关指标的列表:
-
推断延迟:衡量 LLM 处理请求并生成响应所需的时间。较低的延迟确保了更快和更具响应性的用户体验。
-
每秒查询(QPS):计算 LLM 可以在给定时间内处理的查询或请求数量。监控 QPS 有助于评估可伸缩性和容量规划。
-
每秒标记数(TPS):跟踪 LLM 生成标记的速率。TPS 指标对于估计计算资源需求和了解模型效率很有用。
-
标记使用:标记数量与资源使用(如硬件利用、延迟和成本)相关。
-
错误率:监控 LLM 响应中错误或失败的发生,确保错误率保持在可接受的范围内,以保持输出的质量。
-
资源利用:测量计算资源(如 CPU、内存和 GPU)的消耗,以优化资源分配并避免瓶颈。
-
模型漂移:通过将其输出与基线或基本事实进行比较,以检测 LLM 行为随时间的变化,确保模型保持准确性并符合预期结果。
-
超出分布范围的输入:识别落在 LLM 训练数据意图分布范围之外的输入或查询,这可能导致意外或不可靠的响应。
-
用户反馈指标:监控用户反馈渠道,获取关于用户满意度的见解,找到改进的领域,并验证 LLM 的有效性。
数据科学家和机器学习工程师应该使用如 LIME 和 SHAP 这样的模型解释工具检查数据的陈旧性、错误学习和偏见。最具预测性的特征突然变化可能表明数据泄漏。离线指标如 AUC 并不总是与在线转化率的影响相关,因此找到可信赖的离线指标非常重要,这些指标可以转化为业务上的在线收益,最好是系统直接影响的点击和购买等直接指标。有效的监控可以实现 LLM 的成功部署和利用,增强对它们能力的信心,建立用户信任。不过,当依赖云服务平台时,应当注意研究隐私和数据保护政策。在接下来的部分,我们将来看看一个代理的轨迹监控。
跟踪和追踪
跟踪 通常指的是记录和管理应用程序或系统中特定操作或一系列操作的信息的过程。例如,在机器学习应用程序或项目中,跟踪可能涉及在不同实验或运行中记录参数、超参数、度量标准、结果等。这提供了一种记录进展和随时间变化的方式。
**追踪(Tracing)**是跟踪的一种更专业的形式。它涉及通过软件/系统记录执行流程。特别是在单个交易可能涉及多个服务的分布式系统中,追踪有助于保持审计或面包屑路径,详细信息包括请求路径通过系统的详细信息。这种细粒度的视图使开发人员能够理解各种微服务之间的交互,并通过确定它们在事务路径中发生的确切位置来解决延迟或故障等问题。
跟踪代理的轨迹可能具有挑战性,因为它们广泛的行动范围和生成能力。LangChain 提供了用于轨迹跟踪和评估的功能。实际上,看到代理的迹象非常容易!你只需在初始化代理或 LLM 时将 return_intermediate_steps参数设置为True。让我们快速看一下这个。我会跳过导入和设置环境。您可以在 github 上找到完整的列表,在此地址下的监控:github.com/benman1/generative_ai_with_langchain/我们将定义一个工具。使用@tool装饰器非常方便,它将使用函数文档字符串作为工具的描述。第一个工具向网站地址发送一个 ping,并返回有关传输包和延迟的信息,或者(在出现错误的情况下)返回错误消息:
@tool
def ping(url: HttpUrl, return_error: bool) -> str:
"""Ping the fully specified url. Must include https:// in the url."""
hostname = urlparse(str(url)).netloc
completed_process = subprocess.run(
["ping", "-c", "1", hostname], capture_output=True, text=True
)
output = completed_process.stdout
if return_error and completed_process.returncode != 0:
return completed_process.stderr
return output]
现在我们设置了一个代理,使用这个工具和 LLM 来调用给定的提示:
llm = ChatOpenAI(model="gpt-3.5-turbo-0613", temperature=0)
agent = initialize_agent(
llm=llm,
tools=[ping],
agent=AgentType.OPENAI_MULTI_FUNCTIONS,
return_intermediate_steps=True, # IMPORTANT!
)
result = agent("What's the latency like for https://langchain.com?")
代理报告如下:
The latency for https://langchain.com is 13.773 ms
在results[“intermediate_steps”]中,我们可以看到有关代理动作的大量信息:
[(_FunctionsAgentAction(tool='ping', tool_input={'url': 'https://langchain.com', 'return_error': False}, log="\nInvoking: `ping` with `{'url': 'https://langchain.com', 'return_error': False}`\n\n\n", message_log=[AIMessage(content='', additional_kwargs={'function_call': {'name': 'tool_selection', 'arguments': '{\n "actions": [\n {\n "action_name": "ping",\n "action": {\n "url": "https://langchain.com",\n "return_error": false\n }\n }\n ]\n}'}}, example=False)]), 'PING langchain.com (35.71.142.77): 56 data bytes\n64 bytes from 35.71.142.77: icmp_seq=0 ttl=249 time=13.773 ms\n\n--- langchain.com ping statistics ---\n1 packets transmitted, 1 packets received, 0.0% packet loss\nround-trip min/avg/max/stddev = 13.773/13.773/13.773/0.000 ms\n')]
通过提供对系统的可见性,并协助问题识别和优化工作,这种跟踪和评估可以非常有帮助。LangChain 文档演示了如何使用轨迹评估器来检查它们生成的完整动作和响应序列,并对 OpenAI 函数代理进行评分。让我们超越 LangChain,看看观测能提供什么!
观测工具
LangChain 中或通过回调可用的集成工具有相当多:
-
Argilla:Argilla 是一个开源数据整理平台,可以将用户反馈(人在回路工作流程)与提示和响应集成,以整理数据集进行精细调整。
-
Portkey:Portkey 将基本的 MLOps 功能添加到 LangChain 中,例如监视详细指标、追踪链、缓存和通过自动重试确保可靠性。
-
Comet.ml:Comet 为跟踪实验、比较模型和优化 AI 项目提供了强大的 MLOps 能力。
-
LLMonitor:跟踪大量指标,包括成本和使用情况分析(用户跟踪)、追踪和评估工具(开源)。
-
DeepEval:记录默认指标,如相关性、偏见和毒性。还可以帮助测试和监视模型漂移或退化。
-
Aim:一个用于 ML 模型的开源可视化和调试平台。它记录输入、输出和组件的序列化状态,可以对单个 LangChain 执行进行视觉检查,并将多个执行进行比较。
-
Argilla:一个用于跟踪训练数据、验证准确性、参数等的开源平台,可跨机器学习实验进行。
-
Splunk:Splunk 的机器学习工具包可以提供对生产中机器学习模型的可观察性。
-
ClearML:一个用于自动化训练流水线的开源工具,可无缝地从研究转向生产。
-
IBM Watson OpenScale:提供对 AI 健康状况的洞察,快速识别和解决问题,以帮助减轻风险的平台。
-
DataRobot MLOps:监控和管理模型,以在影响性能之前检测问题。
-
Datadog APM Integration:此集成允许您捕获 LangChain 请求、参数、提示完成,并可视化 LangChain 操作。您还可以捕获指标,如请求延迟、错误和令牌/成本使用。
-
权重和偏差(W&B)跟踪:我们已经展示了使用(W&B)监控微调收敛的示例,但它还可以承担跟踪其他指标、记录和比较提示的作用。
-
Langfuse:使用这个开源工具,我们可以方便地监视关于我们的 LangChain 代理和工具的跟踪的详细信息,如延迟、成本和分数。
这些集成大多很容易集成到 LLM 流水线中。例如,对于 W&B,您可以通过将LANGCHAIN_WANDB_TRACING环境变量设置为True来启用跟踪。或者,您可以使用wandb_tracing_enabled()上下文管理器来跟踪特定的代码块。使用 Langfuse,我们可以将langfuse.callback.CallbackHandler()作为参数传递给chain.run()调用。这些工具中的一些是开源的,而这些平台的优点在于它允许完全定制和本地部署,适用于隐私重要的用例。例如,Langfuse 是开源的,并提供自托管选项。选择最适合您需求的选项,并按照 LangChain 文档中提供的说明启用代理的跟踪。虽然该平台只是最近发布的,但我相信它还有更多的功能,但已经很棒了,可以看到代理执行的迹象,检测到循环和延迟问题。它允许与合作者共享跟踪和统计数据,以讨论改进。
LangSmith
LangSmith 是由 LangChain AI 开发和维护的用于调试、测试、评估和监控 LLM 应用程序的框架。LangSmith 通过提供覆盖 MLOps 过程多个方面的特性,成为 LLM 的 MLOps 的有效工具。它可以通过提供调试、监控和优化功能,帮助开发人员将 LLM 应用程序从原型制作阶段推进到生产。LangSmith 旨在为没有软件背景的人提供简单直观的用户界面,降低进入门槛。LangSmith 是构建在 LangChain 上的大型语言模型(LLMs)的调试、测试和监控平台。它允许你:
-
记录你的 LangChain 代理、链和其他组件的运行日志
-
创建数据集以对模型表现进行基准测试
-
配置 AI 辅助评估器来为你的模型评分
-
查看指标、可视化和反馈,迭代和改进你的 LLM 应用
LangSmith 通过提供可用于调试、测试、评估、监控和优化语言模型应用程序的功能和能力,满足代理的 MLOps 要求。其在 LangChain 框架中的集成增强了整个开发体验,并促进了语言模型应用程序的全部潜力。通过同时使用两个平台,开发人员可以将 LLM 应用程序从原型制作阶段推进到生产阶段,并优化延迟、硬件效率和成本。我们可以获得一系列重要统计数据的大量图表,如下所示:
图 9.5:LangSmith 中的评估器指标
监控仪表板包括以下图表,可以按不同时间间隔进行分解:
| 统计数据 | 类别 |
|---|---|
| 溯源计数、LLM 调用计数、溯源成功率、LLM 调用成功率 | 体积 |
| 溯源延迟(秒)、LLM 延迟(秒)、每个溯源的 LLM 调用次数、每秒令牌数 | 延迟 |
| 总令牌数、每个溯源的令牌数、每个 LLM 调用的令牌数 | 令牌 |
| % 具有流处理的溯源、% 具有流处理的 LLM 调用,溯源第一个令牌时间(毫秒)、LLM 第一个令牌时间(毫秒) | 流处理 |
图 9.6:LangSmith 中的统计数据
这是一个示例,展示了在评估章节中看到的基准数据集运行的 LangSmith 跟踪:

图 9.7:LangSmith 中的跟踪
该平台本身并非开源,但是 LangSmith 和 LangChain 背后的公司 LangChain AI 为有隐私顾虑的组织提供了一些自托管支持。不过,有几个 LangSmith 的替代方案,例如 Langfuse、Weights and Biases、Datadog APM、Portkey 和 PromptWatch,它们的功能有一些重叠。我们将在这里重点关注 LangSmith,因为它具有用于评估和监控的大量功能,并且可以与 LangChain 集成。在接下来的章节中,我们将演示在生产环境中使用 PromptWatch.io 进行 LLM 的提示跟踪。
PromptWatch
PromptWatch 记录了此交互过程中关于提示和生成输出的信息。让我们先把输入搞定。
from langchain import LLMChain, OpenAI, PromptTemplate
from promptwatch import PromptWatch
from config import set_environment
set_environment()
正如第三章中所述,我已将所有 API 密钥设置在 set_environment() 函数中的环境中。
prompt_template = PromptTemplate.from_template("Finish this sentence {input}")
my_chain = LLMChain(llm=OpenAI(), prompt=prompt_template)
使用 PromptTemplate 类,将提示模板设置为一个变量 input,指示用户输入应放置在提示中的位置。在 PromptWatch 块内,使用一个输入提示作为模型生成响应的示例来调用 LLMChain。
with PromptWatch() as pw:
my_chain("The quick brown fox jumped over")
图 9.8:在 PromptWatch.io 上的提示跟踪。
这似乎非常有用。通过利用 PromptWatch.io,开发人员和数据科学家可以在实际场景中有效地监视和分析 LLMs 的提示、输出和成本。PromptWatch.io 提供了全面的链式执行跟踪和监控功能。通过 PromptWatch.io,您可以跟踪 LLM 链、操作、检索文档、输入、输出、执行时间、工具详情等方面的所有内容,以完全了解您的系统。该平台通过提供用户友好的可视化界面,使用户能够识别问题的根本原因并优化提示模板,实现了深入分析和故障排除。PromptWatch.io 还可以帮助进行单元测试和提示模板的版本管理。让我们总结一下本章!
总结
成功在生产环境中部署 LLMs 和其他生成式 AI 模型是一个复杂但可控的任务,需要仔细考虑许多因素。它需要解决与数据质量、偏见、伦理、法规合规性、解释性、资源需求以及持续监控和维护等挑战相关的问题。LLMs 的评估是评估它们的性能和质量的重要步骤。LangChain 支持模型之间的比较评估,通过对输出进行标准检查、简单的字符串匹配和语义相似性度量。这些提供了不同的模型质量、准确性和适当生成的见解。系统化的评估是确保大型语言模型产生有用、相关和合理输出的关键。监控 LLMs 是部署和维护这些复杂系统的重要方面。随着 LLMs 在各种应用中的不断采用,确保它们的性能、有效性和可靠性至关重要。我们已经讨论了监视 LLMs 的重要性,重点介绍了全面监控策略所需追踪的关键指标,并举例说明了如何在实践中追踪指标。LangSmith 提供了强大的能力,可以跟踪、基准测试和优化使用 LangChain 构建的大型语言模型。它的自动评估器、指标和可视化帮助加速 LLM 的开发和验证。让我们看看你是否记得本章的重点!
问题
请看看你能否从中得出这些问题的答案。如果你对其中任何一个不确定,你可能需要参考本章对应的部分:
-
在你看来,描述语言模型、LLM 应用程序或一般依赖于生成模型的应用程序的运行化最佳术语是什么?
-
我们如何评估 LLMs 应用程序?
-
有哪些工具可以帮助评估 LLM 应用程序?
-
代理的生产部署需要考虑哪些因素?
-
说出几个部署工具的名字?
-
监控 LLMs 在生产环境中的重要指标是什么?
-
我们如何监视这些模型?
-
什么是 LangSmith?

















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









