







🤗 Transformers 笔记本
您可以在这里找到 Hugging Face 提供的官方笔记本列表。
此外,我们还想在这里列出社区创建的有趣内容。如果您编写了一些利用🤗 Transformers 的笔记本,并希望在此列出,请提交一个 Pull Request,以便将其包含在社区笔记本下。
Hugging Face 的笔记本 🤗
文档笔记
您可以在 Colab 中将文档的任何页面打开为笔记本(这些页面上直接有一个按钮),但如果您需要,它们也在这里列出:
| 笔记本 | 描述 | ||
|---|---|---|---|
| 库的快速浏览 | Transformers 中各种 API 的介绍 | [外链图片转存中…(img-4NJvKbOt-1719041577216)] |  |
| 任务摘要 | 如何逐个任务运行 Transformers 库的模型 |  |  |
| 数据预处理 | 如何使用分词器预处理数据 |  |  |
| 微调预训练模型 | 如何使用 Trainer 微调预训练模型 | [外链图片转存中…(img-jQ8Gp0yC-1719041577217)] |  |
| 分词器摘要 | 分词器算法之间的差异 |  |  |
| 多语言模型 | 如何使用库中的多语言模型 |  |  |
PyTorch 示例
自然语言处理
| 笔记本 | 描述 | ||
|---|---|---|---|
| 训练您的分词器 | 如何训练和使用您自己的分词器 | [外链图片转存中…(img-PGR9FrkQ-1719041577218)] |  |
| 训练您的语言模型 | 如何轻松开始使用 transformers |  |  |
| 如何在文本分类上微调模型 | 展示如何预处理数据并在任何 GLUE 任务上微调预训练模型。 |  |  |
| 如何在语言建模上微调模型 | 展示如何预处理数据并在因果或掩码 LM 任务上微调预训练模型。 | [外链图片转存中…(img-fPtRFnti-1719041577219)] |  |
| 如何在标记分类上微调模型 | 展示如何预处理数据并在标记分类任务(NER,PoS)上微调预训练模型。 |  |  |
| 如何在问答上微调模型 | 展示如何预处理数据并在 SQUAD 上微调预训练模型 |  |  |
| 如何在多项选择上微调模型 | 展示如何预处理数据并在 SWAG 上微调预训练模型 | [外链图片转存中…(img-eZyF1oqJ-1719041577220)] |  |
| 如何在翻译上微调模型 | 展示如何预处理数据并在 WMT 上微调预训练模型 |  |  |
| 如何在摘要上微调模型 | 展示如何预处理数据并在 XSUM 上微调预训练模型 |  |  |
| 如何从头开始训练语言模型 | 突出显示有效训练 Transformer 模型在自定义数据上的所有步骤 | [外链图片转存中…(img-wSBuQJdb-1719041577221)] |  |
| 如何生成文本 | 如何使用不同的解码方法为 transformers 进行语言生成 |  |  |
| 如何生成文本(带约束) | 如何通过用户提供的约束来引导语言生成 |  |  |
| Reformer | Reformer 如何推动语言建模的极限 | [外链图片转存中…(img-TrIBH6i3-1719041577222)] |  |
计算机视觉
| 笔记本 | 描述 | ||
|---|---|---|---|
| 如何在图像分类上微调模型(Torchvision) | 展示如何使用 Torchvision 预处理数据并在图像分类上微调任何预训练的视觉模型 |  |  |
| 如何在图像分类上微调模型(Albumentations) | 展示如何使用 Albumentations 预处理数据并在图像分类上微调任何预训练的视觉模型 |  |  |
| 如何在图像分类上微调模型(Kornia) | 展示如何使用 Kornia 预处理数据并在图像分类上微调任何预训练的视觉模型 | [外链图片转存中…(img-t1icrTSA-1719041577223)] |  |
| 如何使用 OWL-ViT 进行零样本目标检测 | 展示如何使用文本查询在图像上执行零样本目标检测 |  |  |
| 如何微调图像字幕模型 | 展示如何在自定义数据集上微调 BLIP 以进行图像字幕 |  |  |
| 如何使用 Transformers 构建图像相似性系统 | 展示如何构建图像相似性系统 | [外链图片转存中…(img-ZLMFzenK-1719041577224)] |  |
| 如何在语义分割上微调 SegFormer 模型 | 展示如何预处理数据并在语义分割上微调预训练的 SegFormer 模型 |  |  |
| 如何在视频分类上微调 VideoMAE 模型 | 展示如何预处理数据并在视频分类上微调预训练的 VideoMAE 模型 |  |  |
音频
| 笔记本 | 描述 | ||
|---|---|---|---|
| 如何在英语中微调语音识别模型 | 展示如何预处理数据并在 TIMIT 上微调预训练的语音模型 | [外链图片转存中…(img-eh87BakG-1719041577225)] |  |
| 如何在任何语言中微调语音识别模型 | 展示如何预处理数据并在 Common Voice 上微调多语言预训练语音模型 |  |  |
| 如何在音频分类上微调模型 | 展示如何预处理数据并在关键词检测上微调预训练的语音模型 |  |  |
生物序列
| 笔记本 | 描述 | ||
|---|---|---|---|
| 如何微调预训练蛋白质模型 | 查看如何对蛋白质进行标记化和微调大型预训练蛋白质“语言”模型 | [外链图片转存中…(img-aftSdtN9-1719041577225)] |  |
| 如何生成蛋白质折叠 | 查看如何从蛋白质序列到完整蛋白质模型和 PDB 文件 |  |  |
| 如何微调核苷酸 Transformer 模型 | 查看如何对 DNA 进行标记化和微调大型预训练 DNA“语言”模型 |  |  |
| 使用 LoRA 微调核苷酸 Transformer 模型 | 以内存高效的方式训练更大的 DNA 模型 | [外链图片转存中…(img-JH0jQRKl-1719041577226)] |  |
其他形式
| 笔记本 | 描述 | ||
|---|---|---|---|
| 概率时间序列预测 | 查看如何在自定义数据集上训练时间序列 Transformer |  |  |
实用笔记本
| 笔记本 | 描述 | ||
|---|---|---|---|
| 如何将模型导出到 ONNX | 突出显示如何通过 ONNX 导出和运行推理工作负载 | ||
| 如何使用基准测试 | 如何使用 transformers 基准测试模型 |  |  |
TensorFlow 示例
自然语言处理
| 笔记本 | 描述 | ||
|---|---|---|---|
| 训练您的分词器 | 如何训练和使用您自己的分词器 | [外链图片转存中…(img-4KVKdkoI-1719041577227)] |  |
| 训练您的语言模型 | 如何轻松开始使用 transformers |  |  |
| 如何在文本分类上微调模型 | 展示如何预处理数据并在任何 GLUE 任务上微调预训练模型。 |  |  |
| 如何在语言建模上微调模型 | 展示如何预处理数据并在因果或掩码 LM 任务上微调预训练模型。 | [外链图片转存中…(img-RP1NVKwi-1719041577228)] |  |
| 如何在标记分类上微调模型 | 展示如何预处理数据并在标记分类任务(NER,PoS)上微调预训练模型。 |  |  |
| 如何在问答上微调模型 | 展示如何预处理数据并在 SQUAD 上微调预训练模型。 |  |  |
| 如何在多项选择上微调模型 | 展示如何预处理数据并在 SWAG 上微调预训练模型 | [外链图片转存中…(img-R2TZq4Nd-1719041577229)] |  |
| 如何在翻译上微调模型 | 展示如何预处理数据并在 WMT 上微调预训练模型 |  |  |
| 如何在摘要上微调模型 | 展示如何预处理数据并在 XSUM 上微调预训练模型 |  |  |
计算机视觉
| 笔记本 | 描述 | ||
|---|---|---|---|
| 如何在图像分类上微调模型 | 展示如何预处理数据并在图像分类上微调任何预训练的视觉模型 | [外链图片转存中…(img-8hYEFhNZ-1719041577230)] |  |
| 如何在语义分割上微调 SegFormer 模型 | 展示如何预处理数据并在语义分割上微调预训练的 SegFormer 模型 |  |  |
生物序列
| 笔记本 | 描述 | ||
|---|---|---|---|
| 如何微调预训练的蛋白质模型 | 查看如何对蛋白质进行标记化,并微调一个大型预训练的蛋白质“语言”模型 |  |  |
实用笔记本
| 笔记本 | 描述 | ||
|---|---|---|---|
| 如何在 TPU 上训练 TF/Keras 模型 | 查看如何在 Google 的 TPU 硬件上以高速训练 | [外链图片转存中…(img-np9aJsmV-1719041577231)] |  |
Optimum 笔记本
🤗 Optimum 是 🤗 Transformers 的扩展,提供一组性能优化工具,实现在目标硬件上训练和运行模型的最大效率。
| 笔记本 | 描述 | ||
|---|---|---|---|
| 如何使用 ONNX Runtime 对文本分类模型进行量化 | 展示如何在任何 GLUE 任务中使用ONNX Runtime对模型应用静态和动态量化。 |  |  |
| 如何使用 Intel Neural Compressor 对文本分类模型进行量化 | 展示如何在任何 GLUE 任务中使用Intel Neural Compressor (INC)对模型应用静态、动态和感知训练量化。 |  |  |
| 如何使用 ONNX Runtime 在文本分类模型上进行微调 | 展示如何预处理数据并使用ONNX Runtime在任何 GLUE 任务上微调模型。 | [外链图片转存中…(img-EGNF96Lr-1719041577232)] |  |
| 如何使用 ONNX Runtime 在摘要上微调模型 | 展示如何预处理数据并使用ONNX Runtime在 XSUM 上微调模型。 |  |  |
社区笔记本:
社区开发的更多笔记本可在此处找到。
社区
此页面汇集了由社区开发的🤗 Transformers 周围的资源。
社区资源:
| 资源 | 描述 | 作者 |
|---|---|---|
| Hugging Face Transformers 词汇表闪卡 | 基于 Transformers Docs 词汇表的一套闪卡,已经制作成易于使用Anki学习/复习的形式,Anki 是一款专门设计用于长期知识保留的开源、跨平台应用程序。查看这个介绍性视频,了解如何使用闪卡。 | Darigov Research |
社区笔记本:
| 笔记本 | 描述 | 作者 | |
|---|---|---|---|
| 微调预训练的 Transformer 以生成歌词 | 如何通过微调 GPT-2 模型生成您最喜爱艺术家风格的歌词 | Aleksey Korshuk |  |
| 在 Tensorflow 2 中训练 T5 | 如何使用 Tensorflow 2 为任何任务训练 T5。这个笔记本演示了在 Tensorflow 2 中实现的一个问答任务,使用 SQUAD | Muhammad Harris |  |
| 在 TPU 上训练 T5 | 如何使用 Transformers 和 Nlp 在 SQUAD 上训练 T5 | Suraj Patil | [外链图片转存中…(img-TxlBdtkT-1719041577233)] |
| 为分类和多项选择微调 T5 | 如何使用 PyTorch Lightning 以文本-文本格式微调 T5 以进行分类和多项选择任务 | Suraj Patil |  |
| 在新数据集和语言上微调 DialoGPT | 如何在新数据集上微调 DialoGPT 模型,用于开放对话聊天机器人 | Nathan Cooper |  |
| 使用 Reformer 进行长序列建模 | 如何使用 Reformer 在长度为 500,000 个标记的序列上进行训练 | Patrick von Platen | [外链图片转存中…(img-iagYTroZ-1719041577234)] |
| 为摘要微调 BART | 如何使用 blurr 使用 fastai 微调 BART 进行摘要 | Wayde Gilliam |  |
| 为任何人的推文微调预训练 Transformer | 如何通过微调 GPT-2 模型生成您喜爱的 Twitter 账户风格的推文 | Boris Dayma |  |
| 使用 Weights&Biases 优化🤗Hugging Face 模型 | 一个完整的教程,展示了 W&B 与 Hugging Face 的集成 | Boris Dayma | [外链图片转存中…(img-ahYBLtR5-1719041577234)] |
| 预训练 Longformer | 如何构建现有预训练模型的“长”版本 | Iz Beltagy |  |
| 为 QA 微调 Longformer | 如何为 QA 任务微调 Longformer 模型 | Suraj Patil |  |
| 使用🤗nlp 评估模型 | 如何使用nlp在 TriviaQA 上评估 Longformer | Patrick von Platen | [外链图片转存中…(img-yk91EwE0-1719041577234)] |
| 为情感跨度提取微调 T5 | 如何使用 PyTorch Lightning 以文本到文本格式微调 T5 进行情感跨度提取 | Lorenzo Ampil |  |
| 为多类分类微调 DistilBert | 如何使用 PyTorch 微调 DistilBert 进行多类分类 | Abhishek Kumar Mishra |  |
| 微调 BERT 进行多标签分类 | 如何使用 PyTorch 微调 BERT 进行多标签分类 | Abhishek Kumar Mishra | [外链图片转存中…(img-9OM6oH4a-1719041577235)] |
| 微调 T5 进行摘要 | 如何在 PyTorch 中微调 T5 进行摘要,并使用 WandB 跟踪实验 | Abhishek Kumar Mishra |  |
| 使用动态填充/分桶加速 Transformer 中的微调 | 如何通过动态填充/分桶将微调加速 2 倍 | Michael Benesty |  |
| 为遮蔽语言建模预训练 Reformer | 如何训练具有双向自注意力层的 Reformer 模型 | Patrick von Platen | [外链图片转存中…(img-KJ1QPp74-1719041577235)] |
| 扩展和微调 Sci-BERT | 如何在 CORD 数据集上增加预训练的 SciBERT 模型的词汇量并进行流水线处理。 | Tanmay Thakur |  |
| 使用 Trainer API 微调 BlenderBotSmall 进行摘要 | 如何在自定义数据集上使用 Trainer API 微调 BlenderBotSmall 进行摘要 | Tanmay Thakur |  |
| 微调 Electra 并使用 Integrated Gradients 进行解释 | 如何微调 Electra 进行情感分析,并使用 Captum Integrated Gradients 解释预测 | Eliza Szczechla | [外链图片转存中…(img-ehrEtlhL-1719041577236)] |
| 使用 Trainer 类微调非英语 GPT-2 模型 | 如何使用 Trainer 类微调非英语 GPT-2 模型 | Philipp Schmid |  |
| 为多标签分类任务微调 DistilBERT 模型 | 如何为多标签分类任务微调 DistilBERT 模型 | Dhaval Taunk |  |
| 为句对分类微调 ALBERT | 如何为句对分类任务微调 ALBERT 模型或其他基于 BERT 的模型 | Nadir El Manouzi | [外链图片转存中…(img-e02hLMGK-1719041577236)] |
| Fine-tune Roberta for sentiment analysis | 如何为情感分析微调一个 Roberta 模型 | Dhaval Taunk |  |
| 评估问题生成模型 | 您的 seq2seq 变压器模型生成的问题的答案有多准确? | Pascal Zoleko |  |
| 使用 DistilBERT 和 Tensorflow 对文本进行分类 | 如何在 TensorFlow 中为文本分类微调 DistilBERT | Peter Bayerle | [外链图片转存中…(img-3kPl5SFi-1719041577238)] |
| 利用 BERT 进行 CNN/Dailymail 的编码器-解码器摘要 | 如何使用bert-base-uncased检查点对 CNN/Dailymail 的摘要进行热启动EncoderDecoderModel | Patrick von Platen |  |
| 利用 RoBERTa 进行 BBC XSum 的编码器-解码器摘要 | 如何使用roberta-base检查点对 BBC/XSum 的摘要进行热启动共享EncoderDecoderModel | Patrick von Platen |  |
| 在顺序问答(SQA)上微调 TAPAS | 如何在顺序问答(SQA)数据集上使用tapas-base检查点微调TapasForQuestionAnswering | Niels Rogge | [外链图片转存中…(img-ZZjM6DBf-1719041577238)] |
| 在 Table Fact Checking(TabFact)上评估 TAPAS | 如何使用🤗数据集和🤗transformers 库的组合评估经过微调的TapasForSequenceClassification,使用tapas-base-finetuned-tabfact检查点 | Niels Rogge |  |
| 为翻译微调 mBART | 如何使用 Seq2SeqTrainer 为印地语到英语翻译微调 mBART | Vasudev Gupta | [外链图片转存中…(img-W56h7Ga2-1719041577239)] |
| 在 FUNSD 上微调 LayoutLM(一种表单理解数据集) | 如何在 FUNSD 数据集上微调LayoutLMForTokenClassification,从扫描文档中提取信息 | Niels Rogge |  |
| 微调 DistilGPT2 并生成文本 | 如何微调 DistilGPT2 并生成文本 | Aakash Tripathi | [外链图片转存中…(img-X1QoQSy8-1719041577239)] |
| 在最多 8K 标记上微调 LED | 如何在 pubmed 上微调 LED 进行长距离摘要 | Patrick von Platen |  |
| 在 Arxiv 上评估 LED | 如何有效评估 LED 进行长距离摘要 | Patrick von Platen |  |
| 在 RVL-CDIP 上微调 LayoutLM(一种文档图像分类数据集) | 如何在 RVL-CDIP 数据集上微调LayoutLMForSequenceClassification,用于扫描文档分类 | Niels Rogge | [外链图片转存中…(img-21fAgEIN-1719041577240)] |
| - 使用 GPT2 调整进行 Wav2Vec2 CTC 解码 | 如何使用语言模型调整解码 CTC 序列 | Eric Lam |  |
| - 使用 Trainer 类在两种语言中对 BART 进行摘要微调 | 如何使用 Trainer 类在两种语言中对 BART 进行摘要微调 | Eliza Szczechla |  |
| - 在 Trivia QA 上评估 Big Bird | 如何在 Trivia QA 上评估 BigBird 在长文档问答上的表现 | Patrick von Platen |  |
| - 使用 Wav2Vec2 创建视频字幕 | 如何通过使用 Wav2Vec 转录音频来从任何视频创建 YouTube 字幕 | Niklas Muennighoff | [外链图片转存中…(img-zVoIo4FS-1719041577240)] |
| - 使用 PyTorch Lightning 在 CIFAR-10 上微调 Vision Transformer | 如何使用 HuggingFace Transformers、Datasets 和 PyTorch Lightning 在 CIFAR-10 上微调 Vision Transformer(ViT) | Niels Rogge |  |
| - 使用🤗 Trainer 在 CIFAR-10 上微调 Vision Transformer | 如何使用 HuggingFace Transformers、Datasets 和🤗 Trainer 在 CIFAR-10 上微调 Vision Transformer(ViT) | Niels Rogge |  |
| - 在 Open Entity 上评估 LUKE,一个实体类型数据集 | 如何在 Open Entity 数据集上评估LukeForEntityClassification | Ikuya Yamada | [外链图片转存中…(img-XzbCWkGz-1719041577241)] |
| - 在 TACRED 上评估 LUKE,一个关系抽取数据集 | 如何在 TACRED 数据集上评估LukeForEntityPairClassification | Ikuya Yamada |  |
| 在 CoNLL-2003 上评估 LUKE,一个重要的 NER 基准 | 如何在 CoNLL-2003 数据集上评估LukeForEntitySpanClassification | Ikuya Yamada |  |
| 在 PubMed 数据集上评估 BigBird-Pegasus | 如何在 PubMed 数据集上评估BigBirdPegasusForConditionalGeneration | Vasudev Gupta |  |
| 使用 Wav2Vec2 进行语音情感分类 | 如何利用预训练的 Wav2Vec2 模型对 MEGA 数据集进行情感分类 | Mehrdad Farahani | [外链图片转存中…(img-jCUvcCyy-1719041577241)] |
| 使用 DETR 在图像中检测对象 | 如何使用训练好的DetrForObjectDetection模型在图像中检测对象并可视化注意力 | Niels Rogge |  |
| 在自定义对象检测数据集上微调 DETR | 如何在自定义对象检测数据集上微调DetrForObjectDetection | Niels Rogge | [外链图片转存中…(img-ZJIBVTvt-1719041577241)].ipynb) |
| 为命名实体识别微调 T5 | 如何在命名实体识别任务上微调T5 | Ogundepo Odunayo |  |
自定义工具和提示
如果您不了解 transformers 上下文中的工具和代理是什么,我们建议您先阅读 Transformers Agents 页面。
Transformers Agents 是一个实验性 API,随时可能发生变化。代理返回的结果可能会有所不同,因为 API 或底层模型可能会发生变化。
创建和使用自定义工具和提示对于赋予代理能力并使其执行新任务至关重要。在本指南中,我们将看一下:
-
如何自定义提示
-
如何使用自定义工具
-
如何创建自定义工具
自定义提示
如 Transformers Agents 中所解释的,代理可以在 run()和 chat()模式下运行。run 和 chat 模式都基于相同的逻辑。驱动代理的语言模型是基于一个长提示进行条件化,并通过生成下一个标记来完成提示,直到达到停止标记。两种模式之间唯一的区别是,在 chat 模式期间,提示会扩展为先前用户输入和模型生成。这使得代理可以访问过去的交互,似乎给代理一定的记忆。
提示的结构
让我们更仔细地看一下提示的结构,以了解如何最好地定制它。提示大体上分为四个部分。
-
- 介绍:代理应该如何行为,工具概念的解释。
-
- 所有工具的描述。这由一个
<<all_tools>>标记定义,它在运行时动态替换为用户定义/选择的工具。
- 所有工具的描述。这由一个
-
- 一组任务及其解决方案的示例
-
- 当前示例和解决方案请求。
为了更好地理解每个部分,让我们看一下 run 提示的缩短版本可能是什么样子:
I will ask you to perform a task, your job is to come up with a series of simple commands in Python that will perform the task.
[...]
You can print intermediate results if it makes sense to do so.
Tools:
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
- image_captioner: This is a tool that generates a description of an image. It takes an input named `image` which should be the image to the caption and returns a text that contains the description in English.
[...]
Task: "Answer the question in the variable `question` about the image stored in the variable `image`. The question is in French."
I will use the following tools: `translator` to translate the question into English and then `image_qa` to answer the question on the input image.
Answer:
```py
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"翻译后的问题是 {translated_question}。")
answer = image_qa(image=image, question=translated_question)
print(f"答案是 {answer}")
```py
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
```py
answer = document_qa(document, question="最年长的人是谁?")
print(f"答案是 {answer}。")
image = image_generator("显示 " + answer + " 的横幅")
```py
[...]
Task: "Draw me a picture of rivers and lakes"
I will use the following
介绍(“工具:”之前的文本)精确解释了模型应该如何行为以及它应该做什么。这部分很可能不需要定制,因为代理应该始终以相同的方式行为。
第二部分(“工具”下面的项目符号)在调用 run 或 chat 时动态添加。agent.toolbox 中有多少工具,就有多少项目符号,每个项目符号包括工具的名称和描述:
- <tool.name>: <tool.description>
让我们通过加载 document_qa 工具并打印出名称和描述来快速验证这一点。
from transformers import load_tool
document_qa = load_tool("document-question-answering")
print(f"- {document_qa.name}: {document_qa.description}")
这给出了:
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
我们可以看到工具名称简短而准确。描述包括两部分,第一部分解释工具的功能,第二部分说明预期的输入参数和返回值。
一个好的工具名称和工具描述对于代理正确使用它非常重要。请注意,代理对于工具的唯一信息是其名称和描述,因此应确保两者都写得准确,并与工具箱中现有工具的风格匹配。特别要确保描述中提到所有预期的参数名称,以代码样式列出,以及预期的类型和它们的描述。
检查精心策划的 Transformers 工具的命名和描述,以更好地了解工具应该具有的名称和描述。您可以通过 Agent.toolbox 属性查看所有工具。
第三部分包括一组精心策划的示例,向代理展示它应该为何种用户请求生成什么样的代码。赋予代理力量的大型语言模型非常擅长识别提示中的模式,并使用新数据重复该模式。因此,非常重要的是示例以最大化代理生成正确可执行代码的可能性的方式编写。
让我们看一个例子:
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
```py
answer = document_qa(document, question="What is the oldest person?")
print(f"答案是 {answer}。")
image = image_generator("显示" + answer + "的横幅")
```py
模型被提示重复的模式有三部分:任务陈述,代理解释其打算做什么,最后是生成的代码。提示中的每个示例都具有这个确切的模式,从而确保代理在生成新标记时会重现完全相同的模式。
提示示例由 Transformers 团队精心策划,并在一组问题陈述上进行严格评估,以确保代理的提示尽可能好地解决代理的真实用例。
提示的最后部分对应于:
Task: "Draw me a picture of rivers and lakes"
I will use the following
是代理被要求完成的最终未完成示例。未完成的示例是根据实际用户输入动态创建的。对于上面的示例,用户运行了:
agent.run("Draw me a picture of rivers and lakes")
用户输入 - 即任务:“给我画一幅河流和湖泊的图片”被转换为提示模板:“任务: \n\n 我将使用以下内容”。这句话构成了代理所依赖的提示的最后几行,因此强烈影响代理完成示例的方式与之前的示例完全相同。
不要深入细节,聊天模板具有相同的提示结构,示例具有稍微不同的风格,例如:
[...]
=====
Human: Answer the question in the variable `question` about the image stored in the variable `image`.
Assistant: I will use the tool `image_qa` to answer the question on the input image.
```py
answer = image_qa(text=question, image=image)
打印(f"答案是 {answer}")
```py
Human: I tried this code, it worked but didn't give me a good result. The question is in French
Assistant: In this case, the question needs to be translated first. I will use the tool `translator` to do this.
```py
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
打印(f"翻译后的问题是 {translated_question}。")
answer = image_qa(text=translated_question, image=image)
打印(f"答案是 {answer}")
```py
=====
[...]
与run提示的示例相反,每个chat提示示例都有一个或多个人类和助手之间的交流。每个交流的结构与run提示的示例类似。用户的输入附加在*人类:*后面,代理被提示首先生成需要完成的内容,然后再生成代码。一个交流可以基于先前的交流,因此允许用户参考先前的交流,就像用户上面的输入“我尝试这段代码”引用了代理先前生成的代码一样。
运行.chat后,用户的输入或任务被转换为一个未完成的示例,形式如下:
Human: <user-input>\n\nAssistant:
代理完成。与run命令相反,chat命令会将已完成的示例附加到提示中,从而为下一个chat轮提供更多上下文。
现在我们知道了提示的结构,让我们看看如何自定义它!
编写良好的用户输入
虽然大型语言模型在理解用户意图方面变得越来越好,但尽可能准确地帮助代理选择正确的任务会极大地有所帮助。什么是尽可能准确?
代理在其提示中看到一系列工具名称及其描述。添加的工具越多,代理选择正确工具的难度就越大,选择正确的工具运行的顺序也变得更加困难。让我们看一个常见的失败案例,这里我们只返回分析代码。
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.run("Show me a tree", return_code=True)
给出:
==Explanation from the agent==
I will use the following tool: `image_segmenter` to create a segmentation mask for the image.
==Code generated by the agent==
mask = image_segmenter(image, prompt="tree")
这可能不是我们想要的。相反,更有可能的是我们希望生成一棵树的图像。为了更多地引导代理程序使用特定工具,因此使用工具名称和描述中存在的重要关键词可能非常有帮助。让我们看一看。
agent.toolbox["image_generator"].description
'This is a tool that creates an image according to a prompt, which is a text description. It takes an input named `prompt` which contains the image description and outputs an image.
名称和描述使用了关键词“图像”、“提示”、“创建”和“生成”。在这里使用这些词可能会更有效。让我们稍微完善一下我们的提示。
agent.run("Create an image of a tree", return_code=True)
给出:
==Explanation from the agent==
I will use the following tool `image_generator` to generate an image of a tree.
==Code generated by the agent==
image = image_generator(prompt="tree")
好多了!这看起来更像我们想要的。简而言之,当您注意到代理程序在正确将您的任务映射到正确的工具时遇到困难时,请尝试查找工具名称和描述的最相关关键词,并尝试用它来完善您的任务请求。
自定义工具描述
正如我们之前所看到的,代理程序可以访问每个工具的名称和描述。基本工具应该具有非常精确的名称和描述,但是,您可能会发现,为了您的特定用例,更改工具的描述或名称可能会有所帮助。当您添加了多个非常相似的工具或者只想将代理程序用于特定领域时,这可能变得尤为重要,例如图像生成和转换。
一个常见问题是,当代理程序在图像生成任务中经常混淆图像生成和图像转换/修改时,例如
agent.run("Make an image of a house and a car", return_code=True)
返回
==Explanation from the agent==
I will use the following tools `image_generator` to generate an image of a house and `image_transformer` to transform the image of a car into the image of a house.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
house_car_image = image_transformer(image=car_image, prompt="A house")
这可能不是我们想要的。看起来代理程序很难理解image_generator和image_transformer之间的区别,并经常同时使用这两者。
我们可以通过更改image_transformer的工具名称和描述来帮助代理程序。我们可以将其称为modifier,以使其与“图像”和“提示”有些脱离关系:
agent.toolbox["modifier"] = agent.toolbox.pop("image_transformer")
agent.toolbox["modifier"].description = agent.toolbox["modifier"].description.replace(
"transforms an image according to a prompt", "modifies an image"
)
现在,“修改”是一个强烈的提示,可以使用新的图像处理器来帮助完成上述提示。让我们再次运行它。
agent.run("Make an image of a house and a car", return_code=True)
现在我们得到了:
==Explanation from the agent==
I will use the following tools: `image_generator` to generate an image of a house, then `image_generator` to generate an image of a car.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
这绝对更接近我们的想法!但是,我们希望在同一张图片中同时有房子和汽车。将任务更多地转向单张图片生成应该会有所帮助:
agent.run("Create image: 'A house and car'", return_code=True)
==Explanation from the agent==
I will use the following tool: `image_generator` to generate an image.
==Code generated by the agent==
image = image_generator(prompt="A house and car")
对于许多用例,代理程序仍然很脆弱,特别是在生成多个对象的图像等稍微复杂的用例中。代理程序本身和基础提示将在未来几个月进一步改进,以确保代理程序对各种用户输入更加稳健。
自定义整个提示
为了给用户最大的灵活性,整个提示模板如上所述可以被用户覆盖。在这种情况下,请确保您的自定义提示包括一个介绍部分、一个工具部分、一个示例部分和一个未完成示例部分。如果您想覆盖run提示模板,可以按照以下步骤操作:
template = """ [...] """
agent = HfAgent(your_endpoint, run_prompt_template=template)
请确保在template中的某处定义<<all_tools>>字符串和<<prompt>>,以便代理程序可以了解可用的工具,并正确插入用户的提示。
同样,用户可以覆盖chat提示模板。请注意,chat模式始终使用以下格式进行交流:
Human: <<task>>
Assistant:
因此,重要的是自定义chat提示模板的示例也要使用这种格式。您可以在实例化时覆盖chat模板,如下所示。
template = """ [...] """
agent = HfAgent(url_endpoint=your_endpoint, chat_prompt_template=template)
请确保在template中的某处定义<<all_tools>>字符串,以便代理程序可以了解可用的工具。
在这两种情况下,如果您想使用社区中某人托管的模板,可以传递一个存储库 ID 而不是提示模板。默认提示位于此存储库中作为示例。
要在 Hub 上上传您的自定义提示并与社区共享,请确保:
-
使用数据集存储库
-
将
run命令的提示模板放在名为run_prompt_template.txt的文件中 -
将
chat命令的提示模板放在名为chat_prompt_template.txt的文件中
使用自定义工具
在本节中,我们将利用两个现有的特定于图像生成的自定义工具:
-
我们用diffusers/controlnet-canny-tool替换huggingface-tools/image-transformation,以允许进行更多图像修改。
-
我们向默认工具箱添加一个新的图像升频工具:diffusers/latent-upscaler-tool替换现有的图像转换工具。
我们将通过方便的 load_tool()函数加载自定义工具:
from transformers import load_tool
controlnet_transformer = load_tool("diffusers/controlnet-canny-tool")
upscaler = load_tool("diffusers/latent-upscaler-tool")
在向代理添加自定义工具时,工具的描述和名称会自动包含在代理的提示中。因此,自定义工具必须有一个写得很好的描述和名称,以便代理了解如何使用它们。让我们看一下controlnet_transformer的描述和名称:
print(f"Description: '{controlnet_transformer.description}'")
print(f"Name: '{controlnet_transformer.name}'")
给出
Description: 'This is a tool that transforms an image with ControlNet according to a prompt.
It takes two inputs: `image`, which should be the image to transform, and `prompt`, which should be the prompt to use to change it. It returns the modified image.'
Name: 'image_transformer'
名称和描述准确,并符合精心策划的工具集的风格。接下来,让我们用controlnet_transformer和upscaler实例化一个代理:
tools = [controlnet_transformer, upscaler]
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=tools)
此命令应该给您以下信息:
image_transformer has been replaced by <transformers_modules.diffusers.controlnet-canny-tool.bd76182c7777eba9612fc03c0
8718a60c0aa6312.image_transformation.ControlNetTransformationTool object at 0x7f1d3bfa3a00> as provided in `additional_tools`
精心策划的工具集已经有一个image_transformer工具,现在用我们的自定义工具替换。
覆盖现有工具可以是有益的,如果我们想要为与现有工具完全相同的任务使用自定义工具,因为代理擅长使用特定任务。请注意,自定义工具在这种情况下应遵循与被覆盖工具完全相同的 API,或者您应该调整提示模板以确保使用该工具的所有示例都已更新。
升频工具被命名为image_upscaler,该工具尚未出现在默认工具箱中,因此只需将其添加到工具列表中。您可以随时查看代理当前可用的工具箱,通过agent.toolbox属性:
print("\n".join([f"- {a}" for a in agent.toolbox.keys()]))
- document_qa
- image_captioner
- image_qa
- image_segmenter
- transcriber
- summarizer
- text_classifier
- text_qa
- text_reader
- translator
- image_transformer
- text_downloader
- image_generator
- video_generator
- image_upscaler
请注意,image_upscaler现在是代理工具箱的一部分。
现在让我们尝试一下新工具!我们将重复使用我们在 Transformers Agents Quickstart 中生成的图像。
from diffusers.utils import load_image
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png"
)

让我们将图像转换为美丽的冬季风景:
image = agent.run("Transform the image: 'A frozen lake and snowy forest'", image=image)
==Explanation from the agent==
I will use the following tool: `image_transformer` to transform the image.
==Code generated by the agent==
image = image_transformer(image, prompt="A frozen lake and snowy forest")

新的图像处理工具基于 ControlNet,可以对图像进行非常强烈的修改。默认情况下,图像处理工具返回大小为 512x512 像素的图像。让我们看看是否可以将其升频。
image = agent.run("Upscale the image", image)
==Explanation from the agent==
I will use the following tool: `image_upscaler` to upscale the image.
==Code generated by the agent==
upscaled_image = image_upscaler(image)

代理根据升频工具的描述和名称自动将我们的提示“将图像升频”映射到刚刚添加的升频工具,并能够正确运行它。
接下来,让我们看看如何创建一个新的自定义工具。
添加新工具
在本节中,我们将展示如何创建一个可以添加到代理的新工具。
创建一个新工具
我们首先将通过创建一个工具来开始。我们将添加一个不太有用但有趣的任务,即获取 Hugging Face Hub 上针对给定任务下载量最高的模型。
我们可以使用以下代码来实现:
from huggingface_hub import list_models
task = "text-classification"
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
print(model.id)
对于任务text-classification,返回'facebook/bart-large-mnli',对于translation,返回`‘t5-base’。
我们如何将其转换为代理可以利用的工具?所有工具都依赖于保存主要属性的超类Tool。我们将创建一个继承自它的类:
from transformers import Tool
class HFModelDownloadsTool(Tool):
pass
这个类有一些需求:
-
一个
name属性,对应于工具本身的名称。为了与具有表现性名称的其他工具保持一致,我们将其命名为model_download_counter。 -
一个
description属性,将用于填充代理的提示。 -
inputs和outputs属性。定义这些属性将帮助 Python 解释器做出明智的选择,并允许在将工具推送到 Hub 时生成一个 gradio-demo。它们都是预期值的列表,可以是text、image或audio。 -
包含推理代码的
__call__方法。这就是我们上面玩耍的代码!
现在我们的类是这样的:
from transformers import Tool
from huggingface_hub import list_models
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = (
"This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub. "
"It takes the name of the category (such as text-classification, depth-estimation, etc), and "
"returns the name of the checkpoint."
)
inputs = ["text"]
outputs = ["text"]
def __call__(self, task: str):
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
现在我们有了我们的工具。将其保存在一个文件中,并从您的主脚本中导入它。让我们将这个文件命名为 model_downloads.py,这样生成的导入代码看起来像这样:
from model_downloads import HFModelDownloadsTool
tool = HFModelDownloadsTool()
为了让其他人从中受益,并为了更简单的初始化,我们建议将其推送到 Hub 在您的命名空间下。要这样做,只需在 tool 变量上调用 push_to_hub:
tool.push_to_hub("hf-model-downloads")
现在您的代码已经在 Hub 上了!让我们看看最后一步,即让代理使用它。
让代理使用工具
现在我们有了我们的工具,它存放在 Hub 上,可以这样实例化(将用户名更改为您的工具):
from transformers import load_tool
tool = load_tool("lysandre/hf-model-downloads")
为了在代理中使用它,只需将其传递给代理初始化方法的 additional_tools 参数:
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run(
"Can you read out loud the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub?"
)
输出如下:
==Code generated by the agent==
model = model_download_counter(task="text-to-video")
print(f"The model with the most downloads is {model}.")
audio_model = text_reader(model)
==Result==
The model with the most downloads is damo-vilab/text-to-video-ms-1.7b.
并生成以下音频。
| 音频 |
|---|
|
https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/damo.wav
|
根据 LLM 的不同,有些可能非常脆弱,需要非常精确的提示才能很好地工作。拥有工具的明确定义的名称和描述对于代理能够利用它至关重要。
替换现有工具
通过将新项目分配给代理的工具箱,可以简单地替换现有工具。以下是如何操作的方法:
from transformers import HfAgent, load_tool
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.toolbox["image-transformation"] = load_tool("diffusers/controlnet-canny-tool")
替换工具时要小心!这也会调整代理的提示。如果您有一个更适合任务的更好提示,这可能是好事,但也可能导致您的工具被选中的次数远远超过其他工具,或者选择其他工具而不是您定义的工具。
利用 gradio-tools
gradio-tools 是一个强大的库,允许使用 Hugging Face Spaces 作为工具。它支持许多现有的 Spaces,以及可以使用它设计自定义 Spaces。
我们通过使用 Tool.from_gradio 方法为 gradio_tools 提供支持。例如,我们想利用 gradio-tools 工具包中提供的 StableDiffusionPromptGeneratorTool 工具来改进我们的提示并生成更好的图像。
我们首先从 gradio_tools 导入工具并实例化它:
from gradio_tools import StableDiffusionPromptGeneratorTool
gradio_tool = StableDiffusionPromptGeneratorTool()
我们将该实例传递给 Tool.from_gradio 方法:
from transformers import Tool
tool = Tool.from_gradio(gradio_tool)
现在我们可以像处理通常的自定义工具一样管理它。我们利用它来改进我们的提示 一只穿着太空服的兔子:
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run("Generate an image of the `prompt` after improving it.", prompt="A rabbit wearing a space suit")
模型充分利用了该工具:
==Explanation from the agent==
I will use the following tools: `StableDiffusionPromptGenerator` to improve the prompt, then `image_generator` to generate an image according to the improved prompt.
==Code generated by the agent==
improved_prompt = StableDiffusionPromptGenerator(prompt)
print(f"The improved prompt is {improved_prompt}.")
image = image_generator(improved_prompt)
最后生成图像之前:

gradio-tools 需要文本输入和输出,即使在处理不同的模态时也是如此。这个实现可以处理图像和音频对象。目前这两者是不兼容的,但随着我们努力改进支持,它们将迅速变得兼容。
未来与 Langchain 的兼容性
我们喜欢 Langchain,并认为它拥有一个非常引人注目的工具套件。为了处理这些工具,Langchain 需要文本输入和输出,即使在处理不同的模态时也是如此。这通常是对象的序列化版本(即保存到磁盘)。
这种差异意味着 transformers-agents 和 langchain 之间不能处理多模态。我们希望在未来版本中解决这个限制,并欢迎热衷于 langchain 的用户帮助我们实现这种兼容性。
我们希望能得到更好的支持。如果您愿意帮助,请提出问题,并分享您的想法。
故障排除
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/troubleshooting
有时会出现错误,但我们在这里帮助您!本指南涵盖了我们见过的一些最常见问题以及您可以如何解决它们。但是,本指南并不旨在成为每个🤗 Transformers 问题的全面集合。如需更多有关故障排除的帮助,请尝试:
www.youtube-nocookie.com/embed/S2EEG3JIt2A
- 在论坛上寻求帮助。您可以将问题发布到特定类别,如初学者或🤗 Transformers。请确保编写一个具有一些可重现代码的良好描述性论坛帖子,以最大程度地提高解决问题的可能性!
www.youtube-nocookie.com/embed/_PAli-V4wj0
-
如果是与库相关的错误,请在🤗 Transformers 存储库上创建一个Issue。尽量包含尽可能多描述错误的信息,以帮助我们更好地找出问题所在以及如何修复它。
-
如果您使用较旧版本的🤗 Transformers,请查看迁移指南,因为在版本之间引入了一些重要更改。
有关故障排除和获取帮助的更多详细信息,请查看 Hugging Face 课程的第八章。
防火墙环境
一些云端和内部设置的 GPU 实例被防火墙阻止对外部连接,导致连接错误。当您的脚本尝试下载模型权重或数据集时,下载将挂起,然后超时并显示以下消息:
ValueError: Connection error, and we cannot find the requested files in the cached path.
Please try again or make sure your Internet connection is on.
在这种情况下,您应该尝试在离线模式下运行🤗 Transformers 以避免连接错误。
CUDA 内存不足
在没有适当硬件的情况下训练拥有数百万参数的大型模型可能会很具挑战性。当 GPU 内存不足时,您可能会遇到的常见错误是:
CUDA out of memory. Tried to allocate 256.00 MiB (GPU 0; 11.17 GiB total capacity; 9.70 GiB already allocated; 179.81 MiB free; 9.85 GiB reserved in total by PyTorch)
以下是一些潜在的解决方案,您可以尝试减少内存使用:
-
减少 TrainingArguments 中的
per_device_train_batch_size值。 -
尝试在 TrainingArguments 中使用
gradient_accumulation_steps来有效增加总体批量大小。
有关节省内存技术的更多详细信息,请参考性能指南。
无法加载保存的 TensorFlow 模型
TensorFlow 的model.save方法将整个模型(架构、权重、训练配置)保存在单个文件中。然而,当您再次加载模型文件时,可能会遇到错误,因为🤗 Transformers 可能不会加载模型文件中的所有与 TensorFlow 相关的对象。为避免保存和加载 TensorFlow 模型时出现问题,我们建议您:
- 使用
model.save_weights将模型权重保存为h5文件扩展名,然后使用 from_pretrained()重新加载模型:
>>> from transformers import TFPreTrainedModel
>>> from tensorflow import keras
>>> model.save_weights("some_folder/tf_model.h5")
>>> model = TFPreTrainedModel.from_pretrained("some_folder")
- 使用
~TFPretrainedModel.save_pretrained保存模型,然后使用 from_pretrained()再次加载它:
>>> from transformers import TFPreTrainedModel
>>> model.save_pretrained("path_to/model")
>>> model = TFPreTrainedModel.from_pretrained("path_to/model")
ImportError
您可能会遇到另一种常见错误,特别是对于新发布的模型,即ImportError:
ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
对于这些错误类型,请确保您已安装了最新版本的🤗 Transformers 以访问最新的模型:
pip install transformers --upgrade
CUDA error: device-side assert triggered
有时您可能会遇到有关设备代码错误的通用 CUDA 错误。
RuntimeError: CUDA error: device-side assert triggered
您应该首先尝试在 CPU 上运行代码,以获得更详细的错误消息。将以下环境变量添加到您的代码开头以切换到 CPU:
>>> import os
>>> os.environ["CUDA_VISIBLE_DEVICES"] = ""
另一个选项是从 GPU 获取更好的回溯。将以下环境变量添加到您的代码开头,以使回溯指向错误源:
>>> import os
>>> os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
当填充标记未被屏蔽时输出不正确
在某些情况下,如果input_ids包含填充标记,则输出的hidden_state可能是不正确的。为了演示,加载一个模型和分词器。您可以访问模型的pad_token_id以查看其值。对于一些模型,pad_token_id可能为None,但您总是可以手动设置它。
>>> from transformers import AutoModelForSequenceClassification
>>> import torch
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
>>> model.config.pad_token_id
0
以下示例显示了不屏蔽填充标记时的输出:
>>> input_ids = torch.tensor([[7592, 2057, 2097, 2393, 9611, 2115], [7592, 0, 0, 0, 0, 0]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[ 0.1317, -0.1683]], grad_fn=<AddmmBackward0>)
以下是第二个序列的实际输出:
>>> input_ids = torch.tensor([[7592]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[-0.1008, -0.4061]], grad_fn=<AddmmBackward0>)
大多数情况下,您应该为您的模型提供一个attention_mask来忽略填充标记,以避免这种潜在错误。现在第二个序列的输出与其实际输出匹配:
默认情况下,分词器根据特定分词器的默认值为您创建attention_mask。
>>> attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0]])
>>> output = model(input_ids, attention_mask=attention_mask)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[-0.1008, -0.4061]], grad_fn=<AddmmBackward0>)
🤗 Transformers 不会自动创建attention_mask来屏蔽填充标记,如果提供了填充标记,因为:
-
一些模型没有填充标记。
-
对于某些用例,用户希望模型关注填充标记。
ValueError: Unrecognized configuration class XYZ for this kind of AutoModel
通常,我们建议使用 AutoModel 类来加载预训练模型的实例。这个类可以根据配置自动推断和加载给定检查点中的正确架构。如果在从检查点加载模型时看到ValueError,这意味着 Auto 类无法从给定检查点中的配置找到到您尝试加载的模型类型的映射。最常见的情况是,当检查点不支持给定任务时会发生这种情况。例如,在以下示例中,您将看到此错误,因为没有用于问答的 GPT2:
>>> from transformers import AutoProcessor, AutoModelForQuestionAnswering
>>> processor = AutoProcessor.from_pretrained("gpt2-medium")
>>> model = AutoModelForQuestionAnswering.from_pretrained("gpt2-medium")
ValueError: Unrecognized configuration class <class 'transformers.models.gpt2.configuration_gpt2.GPT2Config'> for this kind of AutoModel: AutoModelForQuestionAnswering.
Model type should be one of AlbertConfig, BartConfig, BertConfig, BigBirdConfig, BigBirdPegasusConfig, BloomConfig, ...
性能和可伸缩性
性能和可伸缩性
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/performance
训练大型 Transformer 模型并将其部署到生产环境中会带来各种挑战。
在训练过程中,模型可能需要比可用 GPU 内存更多的 GPU 内存,或者表现出训练速度较慢。在部署阶段,模型可能难以处理生产环境中所需的吞吐量。
本文档旨在帮助您克服这些挑战,并找到适合您用例的最佳设置。指南分为训练和推理部分,因为每个部分都有不同的挑战和解决方案。在每个部分中,您将找到针对不同硬件配置的单独指南,例如单个 GPU 与多个 GPU 进行训练,或 CPU 与 GPU 进行推理。
将本文档作为您进一步导航到与您的情况匹配的方法的起点。
训练
训练大型 Transformer 模型高效地需要像 GPU 或 TPU 这样的加速器。最常见的情况是你只有一块 GPU。您可以应用的方法来提高单个 GPU 上的训练效率也适用于其他设置,如多个 GPU。然而,也有一些特定于多 GPU 或 CPU 训练的技术。我们在单独的部分中进行介绍。
-
在单个 GPU 上进行高效训练的方法和工具:从这里开始学习可以帮助优化 GPU 内存利用率、加快训练速度或两者兼具的常见方法。
-
多 GPU 训练部分:探索本节,了解适用于多 GPU 设置的进一步优化方法,如数据、张量和管道并行。
-
CPU 训练部分:了解在 CPU 上进行混合精度训练。
-
在多个 CPU 上进行高效训练:了解分布式 CPU 训练。
-
使用 TensorFlow 在 TPU 上训练:如果您是 TPU 的新手,请参考本节,了解在 TPU 上训练和使用 XLA 的主观介绍。
-
用于训练的自定义硬件:在构建自己的深度学习装置时找到技巧和窍门。
-
使用 Trainer API 进行超参数搜索
推理
在生产环境中使用大型模型进行高效推理可能与训练它们一样具有挑战性。在接下来的部分中,我们将介绍在 CPU 和单/多 GPU 设置上运行推理的步骤。
-
在单个 CPU 上进行推理
-
在单个 GPU 上进行推理
-
多 GPU 推理
-
XLA 集成用于 TensorFlow 模型
训练和推理
在这里,您将找到适用于训练模型或使用模型进行推理的技术、提示和技巧。
-
实例化一个大模型
-
性能问题的故障排除
贡献
这份文档远未完整,还有很多需要添加的内容,所以如果您有补充或更正,请不要犹豫,打开一个 PR,或者如果您不确定,请开始一个 Issue,我们可以在那里讨论细节。
在提出 A 优于 B 的贡献时,请尽量包含可重现的基准测试和/或指向该信息来源的链接(除非信息直接来自您)。
量化
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/quantization
量化技术专注于用更少的信息表示数据,同时也试图不丢失太多准确性。这通常意味着将数据类型转换为用更少的位表示相同信息。例如,如果您的模型权重存储为 32 位浮点数,并且它们被量化为 16 位浮点数,这将使模型大小减半,使其更容易存储并减少内存使用。较低的精度也可以加快推理速度,因为使用更少的位进行计算需要更少的时间。
Transformers 支持几种量化方案,帮助您在大型语言模型(LLMs)上运行推理和在量化模型上微调适配器。本指南将向您展示如何使用激活感知权重量化(AWQ)、AutoGPTQ 和 bitsandbytes。
AWQ
尝试使用这个notebook进行 AWQ 量化!
激活感知权重量化(AWQ)不会量化模型中的所有权重,而是保留对 LLM 性能重要的一小部分权重。这显著减少了量化损失,使您可以在不经历任何性能降级的情况下以 4 位精度运行模型。
有几个库可用于使用 AWQ 算法量化模型,例如llm-awq、autoawq或optimum-intel。 Transformers 支持加载使用 llm-awq 和 autoawq 库量化的模型。本指南将向您展示如何加载使用 autoawq 量化的模型,但对于使用 llm-awq 量化的模型,过程类似。
确保您已安装 autoawq:
pip install autoawq
可以通过检查模型的config.json文件中的quantization_config属性来识别 AWQ 量化模型:
{
"_name_or_path": "/workspace/process/huggingfaceh4_zephyr-7b-alpha/source",
"architectures": [
"MistralForCausalLM"
],
...
...
...
"quantization_config": {
"quant_method": "awq",
"zero_point": true,
"group_size": 128,
"bits": 4,
"version": "gemm"
}
}
使用 from_pretrained()方法加载量化模型。如果您在 CPU 上加载了模型,请确保首先将其移动到 GPU 设备上。使用device_map参数指定模型放置的位置:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
加载 AWQ 量化模型会自动将其他权重默认设置为 fp16 以提高性能。如果您想以不同格式加载这些其他权重,请使用torch_dtype参数:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float32)
AWQ 量化也可以与 FlashAttention-2 结合,以进一步加速推理:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
融合模块
融合模块提供了改进的准确性和性能,并且对于Llama和Mistral架构的 AWQ 模块支持开箱即用,但您也可以为不支持的架构融合 AWQ 模块。
融合模块不能与 FlashAttention-2 等其他优化技术结合使用。
支持的架构不支持的架构
要为支持的架构启用融合模块,请创建一个 AwqConfig 并设置参数fuse_max_seq_len和do_fuse=True。fuse_max_seq_len参数是总序列长度,应包括上下文长度和预期生成长度。您可以将其设置为较大的值以确保安全。
例如,要融合TheBloke/Mistral-7B-OpenOrca-AWQ模型的 AWQ 模块。
import torch
from transformers import AwqConfig, AutoModelForCausalLM
model_id = "TheBloke/Mistral-7B-OpenOrca-AWQ"
quantization_config = AwqConfig(
bits=4,
fuse_max_seq_len=512,
do_fuse=True,
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config).to(0)
AutoGPTQ
在这个notebook中尝试使用 PEFT 进行 GPTQ 量化,并在这篇博客文章中了解更多细节!
AutoGPTQ库实现了 GPTQ 算法,这是一种后训练量化技术,其中权重矩阵的每一行都独立量化,以找到最小化误差的权重版本。这些权重被量化为 int4,但在推理过程中会动态恢复为 fp16。这可以通过 4 倍减少内存使用,因为 int4 权重在融合内核中而不是 GPU 的全局内存中被解量化,您还可以期望推理速度提升,因为使用较低的位宽需要更少的通信时间。
开始之前,请确保安装了以下库:
pip install auto-gptq
pip install git+https://github.com/huggingface/optimum.git
pip install git+https://github.com/huggingface/transformers.git
pip install --upgrade accelerate
要量化一个模型(目前仅支持文本模型),您需要创建一个 GPTQConfig 类,并设置要量化的位数、用于校准权重的数据集以及准备数据集的分词器。
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
gptq_config = GPTQConfig(bits=4, dataset="c4", tokenizer=tokenizer)
您还可以将自己的数据集作为字符串列表传递,但强烈建议使用 GPTQ 论文中相同的数据集。
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
gptq_config = GPTQConfig(bits=4, dataset=dataset, tokenizer=tokenizer)
加载一个要量化的模型,并将gptq_config传递给 from_pretrained()方法。设置device_map="auto"以自动将模型卸载到 CPU,以帮助将模型适配到内存中,并允许模型模块在 CPU 和 GPU 之间移动以进行量化。
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
如果由于数据集过大而导致内存不足,不支持磁盘卸载。如果是这种情况,请尝试传递max_memory参数来分配设备(GPU 和 CPU)上要使用的内存量:
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", max_memory={0: "30GiB", 1: "46GiB", "cpu": "30GiB"}, quantization_config=gptq_config)
根据您的硬件,从头开始量化一个模型可能需要一些时间。在免费的 Google Colab GPU 上,量化 faceboook/opt-350m 模型可能需要约 5 分钟,但在 NVIDIA A100 上,量化一个 175B 参数模型可能需要约 4 小时。在量化模型之前,最好先检查 Hub,看看模型的 GPTQ 量化版本是否已经存在。
一旦您的模型被量化,您可以将模型和分词器推送到 Hub,这样可以轻松共享和访问。使用 push_to_hub()方法保存 GPTQConfig:
quantized_model.push_to_hub("opt-125m-gptq")
tokenizer.push_to_hub("opt-125m-gptq")
您还可以使用 save_pretrained()方法将您的量化模型保存在本地。如果模型是使用device_map参数量化的,请确保在保存之前将整个模型移动到 GPU 或 CPU。例如,要在 CPU 上保存模型:
quantized_model.save_pretrained("opt-125m-gptq")
tokenizer.save_pretrained("opt-125m-gptq")
# if quantized with device_map set
quantized_model.to("cpu")
quantized_model.save_pretrained("opt-125m-gptq")
使用 from_pretrained()方法重新加载一个量化模型,并设置device_map="auto"以自动将模型分布在所有可用的 GPU 上,以便更快地加载模型而不使用比所需更多的内存。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
ExLlama
ExLlama是 Llama 模型的 Python/C++/CUDA 实现,旨在通过 4 位 GPTQ 权重实现更快的推理(查看这些基准测试)。当您创建一个 GPTQConfig 对象时,默认情况下会激活 ExLlama 内核。为了进一步提高推理速度,请配置exllama_config参数使用ExLlamaV2内核:
import torch
from transformers import AutoModelForCausalLM, GPTQConfig
gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)
仅支持 4 位模型,并且我们建议在对量化模型进行微调时停用 ExLlama 内核。
只有当整个模型在 GPU 上时才支持 ExLlama 内核。如果您在 CPU 上使用 AutoGPTQ(版本>0.4.2)进行推理,则需要禁用 ExLlama 内核。这将覆盖 config.json 文件中与 ExLlama 内核相关的属性。
import torch
from transformers import AutoModelForCausalLM, GPTQConfig
gptq_config = GPTQConfig(bits=4, use_exllama=False)
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="cpu", quantization_config=gptq_config)
bitsandbytes
bitsandbytes是将模型量化为 8 位和 4 位的最简单选择。8 位量化将 fp16 中的异常值与 int8 中的非异常值相乘,将非异常值转换回 fp16,然后将它们相加以返回 fp16 中的权重。这减少了异常值对模型性能的降级影响。4 位量化进一步压缩模型,通常与QLoRA一起用于微调量化的 LLM。
要使用 bitsandbytes,请确保已安装以下库:
8 位 4 位
pip install transformers accelerate bitsandbytes>0.37.0
现在您可以使用 from_pretrained()方法中的load_in_8bit或load_in_4bit参数来量化模型。只要模型支持使用 Accelerate 加载并包含torch.nn.Linear层,这对任何模态的模型都适用。
8 位 4 位
将模型量化为 8 位可以减半内存使用量,对于大型模型,设置device_map="auto"以有效地使用可用的 GPU:
from transformers import AutoModelForCausalLM
model_8bit = AutoModelForCausalLM.from_pretrained("bigscience/bloom-1b7", device_map="auto", load_in_8bit=True)
默认情况下,所有其他模块(如torch.nn.LayerNorm)都会转换为torch.float16。如果需要,您可以使用torch_dtype参数更改这些模块的数据类型:
import torch
from transformers import AutoModelForCausalLM
model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, torch_dtype=torch.float32)
model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
一旦模型被量化为 8 位,除非您使用最新版本的 Transformers 和 bitsandbytes,否则无法将量化的权重推送到 Hub。如果您有最新版本,则可以使用 push_to_hub()方法将 8 位模型推送到 Hub。首先推送量化的 config.json 文件,然后是量化的模型权重。
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m", device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
model.push_to_hub("bloom-560m-8bit")
仅支持使用 8 位和 4 位权重进行训练额外参数。
您可以使用get_memory_footprint方法检查内存占用情况:
print(model.get_memory_footprint())
可以从 from_pretrained()方法中加载量化模型,无需指定load_in_8bit或load_in_4bit参数:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
8 位
在这篇博客文章中了解更多关于 8 位量化的细节!
本节探讨了 8 位模型的一些特定功能,如转移、异常值阈值、跳过模块转换和微调。
转移
8 位模型可以在 CPU 和 GPU 之间转移权重,以支持将非常大的模型适配到内存中。发送到 CPU 的权重实际上是以float32存储的,并且不会转换为 8 位。例如,要为bigscience/bloom-1b7模型启用转移,请首先创建一个 BitsAndBytesConfig:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
设计一个自定义设备映射,将所有内容都适配到 GPU 上,除了lm_head,这部分将发送到 CPU:
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": 0,
"lm_head": "cpu",
"transformer.h": 0,
"transformer.ln_f": 0,
}
现在使用自定义的device_map和quantization_config加载您的模型:
model_8bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
device_map=device_map,
quantization_config=quantization_config,
)
异常值阈值
“异常值”是大于某个阈值的隐藏状态值,这些值是在 fp16 中计算的。虽然这些值通常是正态分布的([-3.5, 3.5]),但对于大型模型([-60, 6]或[6, 60]),这种分布可能会有很大不同。8 位量化适用于值约为 5,但超过这个值,会有显著的性能损失。一个很好的默认阈值是 6,但对于更不稳定的模型(小模型或微调),可能需要更低的阈值。
为了找到您的模型的最佳阈值,我们建议尝试在 BitsAndBytesConfig 中使用llm_int8_threshold参数进行实验:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_threshold=10,
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
跳过模块转换
对于一些模型,如 Jukebox,您不需要将每个模块量化为 8 位,这实际上可能会导致不稳定性。对于 Jukebox,有几个lm_head模块应该使用 BitsAndBytesConfig 中的llm_int8_skip_modules参数跳过:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_skip_modules=["lm_head"],
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
quantization_config=quantization_config,
)
微调
使用PEFT库,您可以使用 8 位量化微调大型模型,如flan-t5-large和facebook/opt-6.7b。在训练时不需要传递device_map参数,因为它会自动将您的模型加载到 GPU 上。但是,如果您想要,仍然可以使用device_map参数自定义设备映射(device_map="auto"仅应用于推断)。
4 位
在这个notebook中尝试 4 位量化,并在这篇博客文章中了解更多细节。
本节探讨了 4 位模型的一些特定功能,如更改计算数据类型、使用 Normal Float 4 (NF4)数据类型和使用嵌套量化。
计算数据类型
为了加速计算,您可以将数据类型从 float32(默认值)更改为 bf16,使用 BitsAndBytesConfig 中的bnb_4bit_compute_dtype参数:
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
Normal Float 4 (NF4)
NF4 是来自QLoRA论文的 4 位数据类型,适用于从正态分布初始化的权重。您应该使用 NF4 来训练 4 位基础模型。这可以通过 BitsAndBytesConfig 中的bnb_4bit_quant_type参数进行配置:
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
对于推断,bnb_4bit_quant_type对性能没有太大影响。但是,为了保持与模型权重一致,您应该使用bnb_4bit_compute_dtype和torch_dtype值。
嵌套量化
嵌套量化是一种技术,可以在不增加性能成本的情况下节省额外的内存。此功能对已经量化的权重执行第二次量化,以节省额外的 0.4 位/参数。例如,使用嵌套量化,您可以在 16GB 的 NVIDIA T4 GPU 上微调Llama-13b模型,序列长度为 1024,批量大小为 1,并启用梯度累积 4 步。
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b", quantization_config=double_quant_config)
Optimum
Optimum库支持 Intel、Furiosa、ONNX Runtime、GPTQ 和较低级别的 PyTorch 量化功能。如果您正在使用像 Intel CPU、Furiosa NPU 或像 ONNX Runtime 这样的模型加速器这样的特定和优化的硬件,请考虑使用 Optimum 进行量化。
基准测试
要比较每种量化方案的速度、吞吐量和延迟,请查看从optimum-benchmark库获得的以下基准测试。该基准测试在 NVIDIA A1000 上运行,用于TheBloke/Mistral-7B-v0.1-AWQ和TheBloke/Mistral-7B-v0.1-GPTQ模型。这些还与 bitsandbytes 量化方法以及本机 fp16 模型进行了测试。
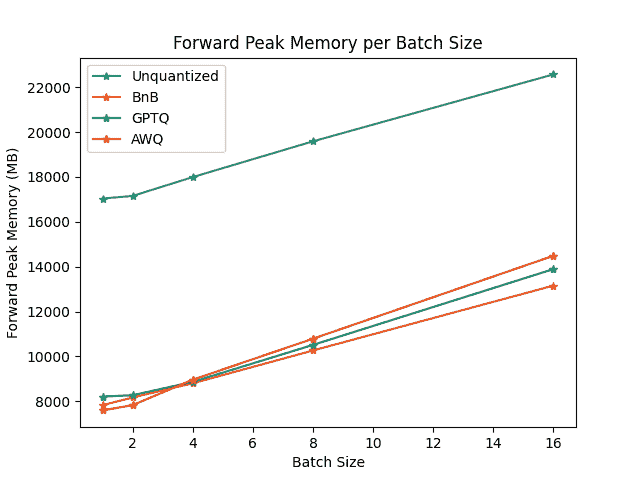
前向峰值内存/批处理大小
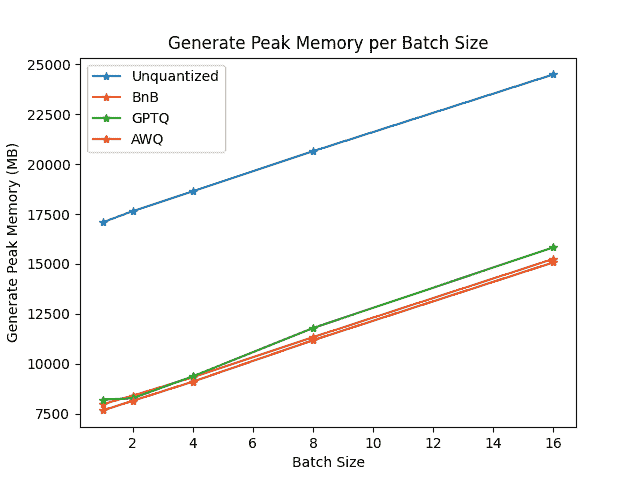
每批生成峰值内存/批处理大小
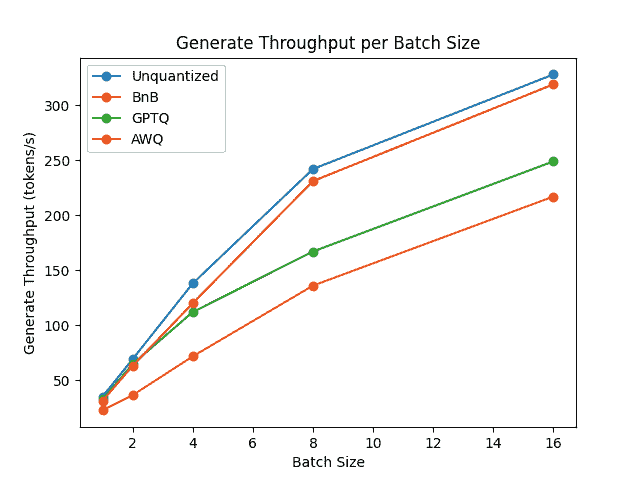
每批生成吞吐量/批处理大小
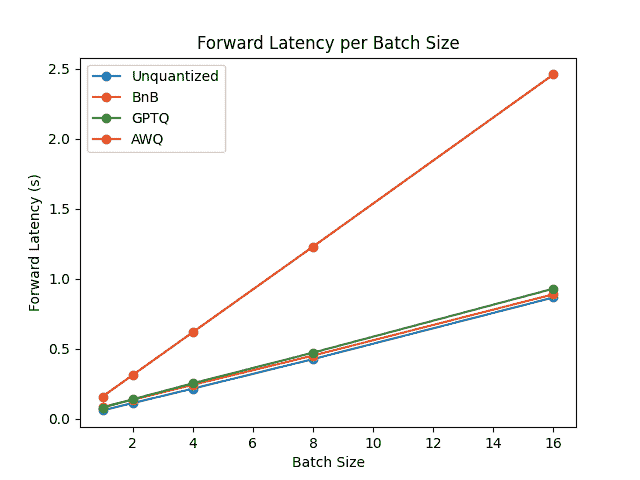
前向延迟/批处理大小
基准测试表明,AWQ 量化在推理、文本生成方面是最快的,并且在文本生成方面具有最低的峰值内存。然而,AWQ 在每个批处理大小上具有最大的前向延迟。要了解每种量化方法的优缺点的更详细讨论,请阅读🤗 Transformers 中本地支持的量化方案概述博客文章。
融合 AWQ 模块
TheBloke/Mistral-7B-OpenOrca-AWQ模型在batch_size=1下进行了基准测试,有无融合模块。
未融合模块
| 批处理大小 | 预填充长度 | 解码长度 | 预填充标记/秒 | 解码标记/秒 | 内存(VRAM) |
|---|---|---|---|---|---|
| 1 | 32 | 32 | 60.0984 | 38.4537 | 4.50 GB (5.68%) |
| 1 | 64 | 64 | 1333.67 | 31.6604 | 4.50 GB (5.68%) |
| 1 | 128 | 128 | 2434.06 | 31.6272 | 4.50 GB (5.68%) |
| 1 | 256 | 256 | 3072.26 | 38.1731 | 4.50 GB (5.68%) |
| 1 | 512 | 512 | 3184.74 | 31.6819 | 4.59 GB (5.80%) |
| 1 | 1024 | 1024 | 3148.18 | 36.8031 | 4.81 GB (6.07%) |
| 1 | 2048 | 2048 | 2927.33 | 35.2676 | 5.73 GB (7.23%) |
融合模块
| 批处理大小 | 预填充长度 | 解码长度 | 预填充标记/秒 | 解码标记/秒 | 内存(VRAM) |
|---|---|---|---|---|---|
| 1 | 32 | 32 | 81.4899 | 80.2569 | 4.00 GB (5.05%) |
| 1 | 64 | 64 | 1756.1 | 106.26 | 4.00 GB (5.05%) |
| 1 | 128 | 128 | 2479.32 | 105.631 | 4.00 GB (5.06%) |
| 1 | 256 | 256 | 1813.6 | 85.7485 | 4.01 GB (5.06%) |
| 1 | 512 | 512 | 2848.9 | 97.701 | 4.11 GB (5.19%) |
| 1 | 1024 | 1024 | 3044.35 | 87.7323 | 4.41 GB (5.57%) |
| 1 | 2048 | 2048 | 2715.11 | 89.4709 | 5.57 GB (7.04%) |
融合和未融合模块的速度和吞吐量也经过了optimum-benchmark库的测试。
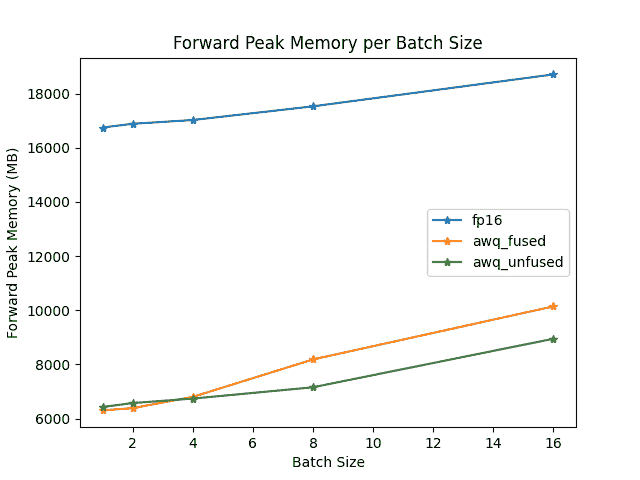
前向峰值内存/批处理大小
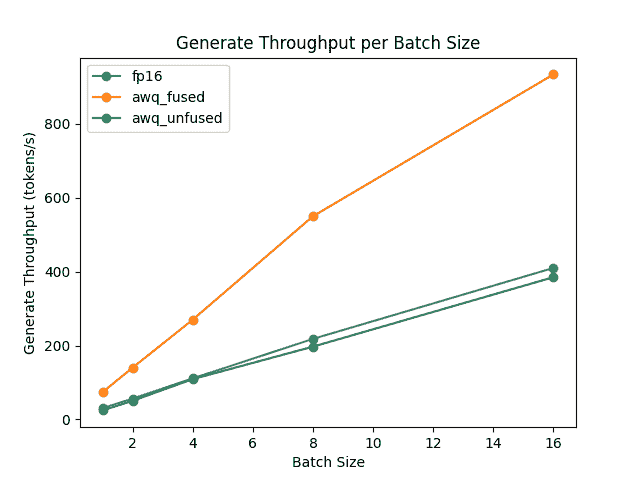
每批生成吞吐量/批处理大小
高效的训练技巧
在单个 GPU 上进行高效训练的方法和工具
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/perf_train_gpu_one
本指南演示了您可以使用的实用技术,通过优化内存利用率、加快训练速度或两者兼而有之来提高模型训练的效率。如果您想了解 GPU 在训练过程中的使用情况,请先参考模型训练解剖概念指南。本指南侧重于实用技术。
如果您可以访问具有多个 GPU 的计算机,这些方法仍然有效,此外,您还可以利用多 GPU 部分中概述的其他方法。
在训练大型模型时,应同时考虑两个方面:
-
数据吞吐量/训练时间
-
模型性能
最大化吞吐量(样本/秒)可以降低训练成本。通常通过尽可能充分利用 GPU 并将 GPU 内存填满来实现这一目标。如果所需的批处理大小超出了 GPU 内存的限制,可以使用内存优化技术,如梯度累积,来帮助。
然而,如果首选的批处理大小适合内存,就没有理由应用内存优化技术,因为它们可能会减慢训练速度。仅仅因为可以使用大批处理大小,并不一定意味着应该这样做。作为超参数调整的一部分,您应该确定哪种批处理大小产生最佳结果,然后相应地优化资源。
本指南涵盖的方法和工具可以根据它们对训练过程的影响进行分类:
| 方法/工具 | 提高训练速度 | 优化内存利用率 |
|---|---|---|
| 批处理大小选择 | 是 | 是 |
| 梯度累积 | 否 | 是 |
| 梯度检查点 | 否 | 是 |
| 混合精度训练 | 是 | (否) |
| 优化器选择 | 是 | 是 |
| 数据预加载 | 是 | 否 |
| DeepSpeed Zero | 否 | 是 |
| torch.compile | 是 | 否 |
| 参数高效微调(PEFT) | 否 | 是 |
注意:当使用混合精度与小模型和大批处理大小时,会有一些内存节省,但对于大模型和小批处理大小,内存使用量会更大。
您可以结合上述方法以获得累积效果。这些技术对您都是可用的,无论您是使用 Trainer 训练模型,还是编写纯 PyTorch 循环,在这种情况下,您可以通过使用🤗 Accelerate 配置这些优化。
如果这些方法没有带来足够的收益,您可以探索以下选项:
-
考虑构建自己的自定义 Docker 容器,其中包含高效的软件预构建
-
考虑使用专家混合(MoE)的模型
-
将您的模型转换为 BetterTransformer 以利用 PyTorch 原生注意力
最后,如果即使切换到像 A100 这样的服务器级 GPU 后仍然不够,考虑切换到多 GPU 设置。所有这些方法在多 GPU 设置中仍然有效,此外,您还可以利用多 GPU 部分中概述的其他并行技术。
批处理大小选择
为了实现最佳性能,首先要确定适当的批处理大小。建议使用大小为 2^N 的批处理大小和输入/输出神经元计数。通常是 8 的倍数,但可以更高,具体取决于所使用的硬件和模型的数据类型。
有关参考,请查看 NVIDIA 关于全连接层(涉及 GEMMs(通用矩阵乘法))的输入/输出神经元计数和批次大小的建议。
Tensor Core 要求根据数据类型和硬件定义乘数。例如,对于 fp16 数据类型,推荐使用 8 的倍数,除非是 A100 GPU,此时使用 64 的倍数。
对于较小的参数,还要考虑维度量化效应。这是瓦片化发生的地方,正确的乘数可以显著加快速度。
梯度累积
梯度累积方法旨在以较小的增量计算梯度,而不是一次为整个批次计算梯度。这种方法涉及通过模型执行前向和反向传递,并在过程中累积梯度来迭代计算较小批次的梯度。一旦积累了足够数量的梯度,就会执行模型的优化步骤。通过使用梯度累积,可以将有效批次大小增加到 GPU 内存容量所施加的限制之外。然而,需要注意的是,梯度累积引入的额外前向和反向传递可能会减慢训练过程。
您可以通过向 TrainingArguments 添加gradient_accumulation_steps参数来启用梯度累积:
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
在上述示例中,您的有效批次大小变为 4。
或者,使用🤗 Accelerate 来完全控制训练循环。在本指南的后面找到🤗 Accelerate 示例。
尽可能地最大化 GPU 使用率是建议的,但是高数量的梯度累积步骤可能会导致训练减速更加明显。考虑以下示例。假设per_device_train_batch_size=4,没有梯度累积达到了 GPU 的极限。如果您想要使用大小为 64 的批次进行训练,请不要将per_device_train_batch_size设置为 1,并将gradient_accumulation_steps设置为 64。相反,保持per_device_train_batch_size=4,并设置gradient_accumulation_steps=16。这样可以实现相同的有效批次大小,同时更好地利用可用的 GPU 资源。
有关更多信息,请参考RTX-3090和A100的批次大小和梯度累积基准。
梯度检查点
即使将批次大小设置为 1 并使用梯度累积,一些大型模型仍可能面临内存问题。这是因为还有其他组件也需要内存存储。
保存前向传递中的所有激活以便在反向传递期间计算梯度可能会导致显着的内存开销。另一种方法是在反向传递期间丢弃激活并在需要时重新计算它们,这将引入相当大的计算开销并减慢训练过程。
梯度检查点提供了这两种方法之间的折衷方案,并在计算图中保存了策略性选择的激活,因此只需重新计算一小部分激活以获得梯度。有关梯度检查点的深入解释,请参阅这篇很棒的文章。
要在 Trainer 中启用梯度检查点,请将相应的标志传递给 TrainingArguments:
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
或者,使用🤗 Accelerate-在本指南中找到🤗 Accelerate 示例(#使用加速)。
虽然梯度检查点可能提高内存效率,但会使训练速度减慢约 20%。
混合精度训练
混合精度训练是一种旨在通过利用较低精度数值格式来处理某些变量来优化训练模型的计算效率的技术。传统上,大多数模型使用 32 位浮点精度(fp32 或 float32)来表示和处理变量。然而,并非所有变量都需要这种高精度级别才能获得准确的结果。通过将某些变量的精度降低到较低的数值格式,如 16 位浮点(fp16 或 float16),我们可以加快计算速度。因为在这种方法中,一些计算是以半精度进行的,而一些仍然是以全精度进行的,所以这种方法被称为混合精度训练。
最常见的混合精度训练是通过使用 fp16(float16)数据类型来实现的,但是一些 GPU 架构(例如 Ampere 架构)提供了 bf16 和 tf32(CUDA 内部数据类型)数据类型。查看NVIDIA 博客以了解这些数据类型之间的区别。
fp16
混合精度训练的主要优势来自于将激活保存在半精度(fp16)中。尽管梯度也是以半精度计算的,但它们在优化步骤中被转换回全精度,因此在这里没有节省内存。虽然混合精度训练可以加快计算速度,但也可能导致更多的 GPU 内存被利用,特别是对于小批量大小。这是因为模型现在以 16 位和 32 位精度(GPU 上原始模型的 1.5 倍)存在于 GPU 上。
要启用混合精度训练,请将fp16标志设置为True:
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
如果您更喜欢使用🤗 Accelerate,请在本指南中找到🤗 Accelerate 示例(#使用加速)。
BF16
如果您可以访问 Ampere 或更新的硬件,您可以使用 bf16 进行混合精度训练和评估。虽然 bf16 的精度比 fp16 差,但它具有更大的动态范围。在 fp16 中,您可以拥有的最大数字是65535,任何超过这个数字的数字都会导致溢出。bf16 的数字可以达到3.39e+38(!),这大约与 fp32 相同-因为两者都使用了 8 位用于数值范围。
您可以在🤗 Trainer 中启用 BF16:
training_args = TrainingArguments(bf16=True, **default_args)
TF32
Ampere 硬件使用一种名为 tf32 的神奇数据类型。它具有与 fp32 相同的数值范围(8 位),但是精度只有 10 位(与 fp16 相同),总共只使用了 19 位。它在这种意义上是“神奇的”,即您可以使用正常的 fp32 训练和/或推理代码,并通过启用 tf32 支持,您可以获得高达 3 倍的吞吐量改进。您只需要将以下内容添加到您的代码中:
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
CUDA 将在可能的情况下自动切换到使用 tf32 而不是 fp32,假设所使用的 GPU 来自 Ampere 系列。
根据NVIDIA 研究,大多数机器学习训练工作负载显示出与 fp32 相同的困惑度和收敛性。如果您已经在使用 fp16 或 bf16 混合精度,这也可能有助于提高吞吐量。
您可以在🤗 Trainer 中启用此模式:
TrainingArguments(tf32=True, **default_args)
tf32 无法通过tensor.to(dtype=torch.tf32)直接访问,因为它是内部 CUDA 数据类型。您需要torch>=1.7才能使用 tf32 数据类型。
有关 tf32 与其他精度的更多信息,请参考以下基准测试:RTX-3090和A100。
Flash Attention 2
您可以通过在 transformers 中使用 Flash Attention 2 集成来加快训练吞吐量。查看单 GPU 部分中的适当部分,了解如何加载带有 Flash Attention 2 模块的模型的更多信息。
优化器选择
用于训练变压器模型的最常用优化器是 Adam 或 AdamW(带有权重衰减的 Adam)。Adam 通过存储先前梯度的滚动平均值实现良好的收敛;然而,它会增加与模型参数数量相同数量级的额外内存占用。为了解决这个问题,您可以使用另一种优化器。例如,如果您在 NVIDIA GPU 上安装了NVIDIA/apex,或者在 AMD GPU 上安装了ROCmSoftwarePlatform/apex,adamw_apex_fused将为您提供所有支持的 AdamW 优化器中最快的训练体验。
Trainer 集成了各种可立即使用的优化器:adamw_hf、adamw_torch、adamw_torch_fused、adamw_apex_fused、adamw_anyprecision、adafactor或adamw_bnb_8bit。更多优化器可以通过第三方实现插入。
让我们更仔细地看看两种替代 AdamW 优化器:
-
adafactor可在 Trainer 中使用 -
adamw_bnb_8bit也可在 Trainer 中使用,但以下提供了第三方集成以供演示。
以 3B 参数模型“t5-3b”为例进行比较:
-
标准的 AdamW 优化器将需要 24GB 的 GPU 内存,因为它为每个参数使用 8 字节(8*3 => 24GB)
-
Adafactor 优化器将需要超过 12GB。它为每个参数使用略多于 4 字节,因此 4*3,然后再加一些。
-
8 位 BNB 量化优化器将仅使用(2*3)6GB,如果所有优化器状态都被量化。
Adafactor
Adafactor 不会为权重矩阵中的每个元素存储滚动平均值。相反,它保留聚合信息(按行和列的滚动平均和),显著减少了内存占用。然而,与 Adam 相比,Adafactor 在某些情况下可能收敛较慢。
您可以通过在 TrainingArguments 中设置optim="adafactor"来切换到 Adafactor:
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
结合其他方法(梯度累积、梯度检查点和混合精度训练),您可以在保持吞吐量的同时实现高达 3 倍的改进!然而,如前所述,Adafactor 的收敛性可能比 Adam 更差。
8 位 Adam
与 Adafactor 等聚合优化器状态不同,8 位 Adam 保留完整状态并对其进行量化。量化意味着以较低精度存储状态,并仅在优化时对其进行反量化。这类似于混合精度训练的思想。
要使用adamw_bnb_8bit,您只需在 TrainingArguments 中设置optim="adamw_bnb_8bit":
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
然而,我们也可以使用第三方实现的 8 位优化器进行演示,以了解如何集成。
首先,按照 GitHub repo中的安装指南安装实现 8 位 Adam 优化器的bitsandbytes库。
接下来需要初始化优化器。这涉及两个步骤:
-
首先,将模型的参数分为两组 - 一组应用权重衰减,另一组不应用。通常,偏置和层归一化参数不会被权重衰减。
-
然后进行一些参数整理,以使用与先前使用的 AdamW 优化器相同的参数。
import bitsandbytes as bnb
from torch import nn
from transformers.trainer_pt_utils import get_parameter_names
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
decay_parameters = [name for name in decay_parameters if "bias" not in name]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
"weight_decay": training_args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
"weight_decay": 0.0,
},
]
optimizer_kwargs = {
"betas": (training_args.adam_beta1, training_args.adam_beta2),
"eps": training_args.adam_epsilon,
}
optimizer_kwargs["lr"] = training_args.learning_rate
adam_bnb_optim = bnb.optim.Adam8bit(
optimizer_grouped_parameters,
betas=(training_args.adam_beta1, training_args.adam_beta2),
eps=training_args.adam_epsilon,
lr=training_args.learning_rate,
)
最后,将自定义优化器作为参数传递给Trainer:
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
结合其他方法(梯度累积、梯度检查点和混合精度训练),您可以期望获得大约 3 倍的内存改进,甚至比使用 Adafactor 时的吞吐量稍高。
multi_tensor
pytorch-nightly 引入了torch.optim._multi_tensor,应该显着加快具有大量小特征张量的优化器的速度。最终应该成为默认设置,但如果您想更早尝试它,请查看这个 GitHub 问题。
数据预加载
达到良好训练速度的一个重要要求是能够以 GPU 能够处理的最大速度提供数据。默认情况下,所有操作都在主进程中进行,可能无法快速从磁盘读取数据,从而导致瓶颈,导致 GPU 利用率不足。配置以下参数以减少瓶颈:
-
DataLoader(pin_memory=True, ...)- 确保数据预加载到 CPU 上的固定内存中,通常会导致从 CPU 到 GPU 内存的传输速度更快。 -
DataLoader(num_workers=4, ...)- 生成几个工作进程以更快地预加载数据。在训练过程中,观察 GPU 利用率统计数据;如果远离 100%,尝试增加工作进程的数量。当然,问题可能出在其他地方,因此许多工作进程不一定会导致更好的性能。
在使用 Trainer 时,相应的 TrainingArguments 是:dataloader_pin_memory(默认为True),和dataloader_num_workers(默认为0)。
DeepSpeed ZeRO
DeepSpeed 是一个开源的深度学习优化库,与🤗 Transformers 和🤗 Accelerate 集成。它提供了各种功能和优化,旨在提高大规模深度学习训练的效率和可扩展性。
如果您的模型适合单个 GPU 并且有足够的空间来容纳小批量大小,则不需要使用 DeepSpeed,因为它只会减慢速度。但是,如果模型无法适应单个 GPU 或无法容纳小批量,则可以利用 DeepSpeed ZeRO + CPU Offload,或 NVMe Offload 来处理更大的模型。在这种情况下,您需要单独安装该库,然后按照指南之一创建配置文件并启动 DeepSpeed:
-
有关 DeepSpeed 与 Trainer 集成的详细指南,请查看相应文档,特别是单个 GPU 部署部分。在笔记本中使用 DeepSpeed 需要进行一些调整;请查看相应指南。
-
如果您更喜欢使用🤗 Accelerate,请参考🤗 Accelerate DeepSpeed 指南。
使用 torch.compile
PyTorch 2.0 引入了一个新的编译函数,不需要对现有的 PyTorch 代码进行任何修改,只需添加一行代码即可优化您的代码:model = torch.compile(model)。
如果使用 Trainer,您只需要在 TrainingArguments 中传递torch_compile选项:
training_args = TrainingArguments(torch_compile=True, **default_args)
torch.compile使用 Python 的帧评估 API 自动从现有的 PyTorch 程序创建图。在捕获图之后,可以部署不同的后端以将图降低到优化引擎。您可以在PyTorch 文档中找到更多详细信息和基准测试。
torch.compile有一个不断增长的后端列表,可以通过调用torchdynamo.list_backends()找到,每个后端都有其可选依赖项。
通过在 TrainingArguments 中指定torch_compile_backend来选择要使用的后端。一些最常用的后端包括:
调试后端:
-
dynamo.optimize("eager")- 使用 PyTorch 运行提取的 GraphModule。这在调试 TorchDynamo 问题时非常有用。 -
dynamo.optimize("aot_eager")- 使用 AotAutograd 而不使用编译器,即仅使用 PyTorch eager 进行 AotAutograd 的提取前向和反向图。这对调试很有用,但不太可能提供加速。
训练和推理后端:
-
dynamo.optimize("inductor")- 使用 TorchInductor 后端,通过利用 codegened Triton 内核实现 AotAutograd 和 cudagraphs。阅读更多 -
dynamo.optimize("nvfuser")- nvFuser 与 TorchScript。阅读更多 -
dynamo.optimize("aot_nvfuser")- nvFuser 与 AotAutograd。阅读更多 -
dynamo.optimize("aot_cudagraphs")- 使用 AotAutograd 的 cudagraphs。阅读更多
仅推理后端:
-
dynamo.optimize("ofi")- 使用 Torchscript 的 optimize_for_inference。阅读更多 -
dynamo.optimize("fx2trt")- 使用 NVIDIA TensorRT 进行推理优化。阅读更多 -
dynamo.optimize("onnxrt")- 使用 ONNXRT 进行 CPU/GPU 推理。阅读更多 -
dynamo.optimize("ipex")- 使用 IPEX 进行 CPU 推理。阅读更多
使用torch.compile与🤗 Transformers 的示例,请查看这篇博文,介绍如何使用最新的 PyTorch 2.0 功能微调 BERT 模型进行文本分类
使用🤗 PEFT
参数高效微调(PEFT)方法在微调期间冻结预训练模型参数,并在其上添加少量可训练参数(适配器)。
因此,与优化器状态和梯度相关的内存大大减少。
例如,对于普通的 AdamW,优化器状态的内存需求将是:
-
fp32 参数的副本:4 字节/参数
-
动量:4 字节/参数
-
方差:4 字节/参数
假设一个具有 70 亿参数和 2 亿参数注入低秩适配器的模型。
普通模型的优化器状态的内存需求将为 12 * 7 = 84 GB(假设有 7B 可训练参数)。
添加 Lora 会略微增加与模型权重相关的内存,并大幅减少优化器状态的内存需求至 12 * 0.2 = 2.4GB。
在PEFT 文档或PEFT 存储库中详细了解 PEFT 及其详细用法。
使用🤗 Accelerate
使用🤗 Accelerate可以在完全控制训练循环的同时使用上述方法,并且基本上可以使用纯 PyTorch 编写循环并进行一些微小修改。
假设您已将 TrainingArguments 中的方法组合如下:
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
使用🤗 Accelerate 的完整示例训练循环只有几行代码:
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
首先,我们将数据集包装在DataLoader中。然后,我们可以通过调用模型的 gradient_checkpointing_enable()方法启用梯度检查点。当我们初始化Accelerator时,我们可以指定是否要使用混合精度训练,并且它将在prepare调用中为我们处理。在prepare调用期间,如果我们使用多个 GPU,数据加载器也将分布在工作进程之间。我们使用与之前示例相同的 8 位优化器。
最后,我们可以添加主要的训练循环。请注意,backward调用由🤗 Accelerate 处理。我们还可以看到梯度累积的工作原理:我们规范化损失,因此在累积结束时获得平均值,一旦我们有足够的步骤,我们就运行优化。
使用🤗 Accelerate 实现这些优化技术只需要几行代码,并且在训练循环中具有更大的灵活性。要查看所有功能的完整文档,请查看Accelerate 文档。
高效的软件预构建
PyTorch 的pip 和 conda 构建预先构建了 cuda 工具包,足以运行 PyTorch,但如果需要构建 cuda 扩展,则不足。
有时,可能需要额外的努力来预构建一些组件。例如,如果您使用的是未经预编译的库,如apex。在其他情况下,弄清楚如何在系统范围内安装正确的 cuda 工具包可能会很复杂。为了解决这些情况,PyTorch 和 NVIDIA 发布了一个新版本的 NGC docker 容器,其中已经预先构建了一切。您只需在其中安装您的程序,它就可以立即运行。
这种方法在您想要调整 pytorch 源代码和/或制作新的定制构建时也很有用。要找到您想要的 docker 镜像版本,请从PyTorch 发布说明开始,选择最新的一个月发布之一。进入所需发布的发布说明,检查环境的组件是否符合您的需求(包括 NVIDIA 驱动程序要求!),然后在该文档的顶部转到相应的 NGC 页面。如果由于某种原因您迷失了方向,这里是所有 PyTorch NGC 镜像的索引。
接下来按照说明下载和部署 docker 镜像。
专家混合
一些最近的论文报告了 4-5 倍的训练加速和将 Mixture of Experts(MoE)集成到 Transformer 模型中以实现更快的推理。
由于发现更多的参数会导致更好的性能,这种技术允许将参数数量增加一个数量级,而不增加训练成本。
在这种方法中,每个其他的 FFN 层都被一个 MoE 层替换,该层由许多专家组成,具有一个门控函数,根据输入令牌在序列中的位置平衡地训练每个专家。
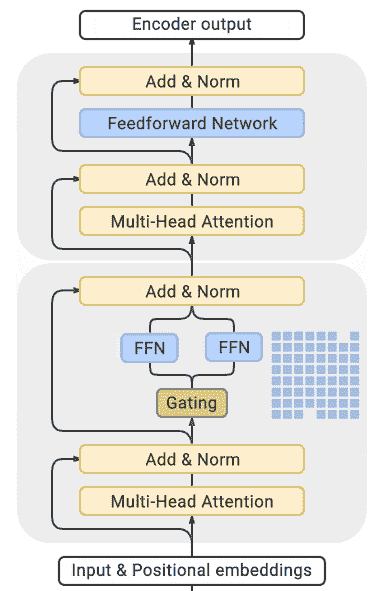
(来源:GLAM)
您可以在本节末尾列出的论文中找到详尽的细节和比较表。
这种方法的主要缺点是它需要大量的 GPU 内存 - 几乎比其密集等价物大一个数量级。提出了各种蒸馏和方法,以克服更高的内存需求。
然而,存在直接的权衡,您可以使用少量专家和 2-3 倍较小的基础模型,而不是数十或数百个专家,从而导致 5 倍较小的模型,因此适度增加训练速度,同时适度增加内存需求。
大多数相关论文和实现都是围绕 Tensorflow/TPUs 构建的:
对于 Pytorch,DeepSpeed 也构建了一个:DeepSpeed-MoE: 推进混合专家推理和训练以支持下一代 AI 规模,Mixture of Experts - 博文:1,2以及大型基于 Transformer 的自然语言生成模型的特定部署:博文,Megatron-Deepspeed 分支。
使用 PyTorch 原生注意力和 Flash Attention
PyTorch 2.0 发布了一个原生的torch.nn.functional.scaled_dot_product_attention(SDPA),允许使用融合的 GPU 内核,如内存高效注意力和闪存注意力。
安装optimum包后,可以替换相关的内部模块以使用 PyTorch 的原生注意力,方法如下:
model = model.to_bettertransformer()
转换后,像往常一样训练模型。
PyTorch 原生的scaled_dot_product_attention操作符只有在没有提供attention_mask时才能分派到 Flash Attention。
默认情况下,在训练模式下,BetterTransformer 集成取消了掩码支持,只能用于不需要填充掩码的批量训练。例如,在掩码语言建模或因果语言建模期间。BetterTransformer 不适用于需要填充掩码的任务的微调模型。
查看这篇博文,了解有关 SDPA 加速和节省内存的更多信息。
-in-context-learning-with.html))
您可以在本节末尾列出的论文中找到详尽的细节和比较表。
这种方法的主要缺点是它需要大量的 GPU 内存 - 几乎比其密集等价物大一个数量级。提出了各种蒸馏和方法,以克服更高的内存需求。
然而,存在直接的权衡,您可以使用少量专家和 2-3 倍较小的基础模型,而不是数十或数百个专家,从而导致 5 倍较小的模型,因此适度增加训练速度,同时适度增加内存需求。
大多数相关论文和实现都是围绕 Tensorflow/TPUs 构建的:
对于 Pytorch,DeepSpeed 也构建了一个:DeepSpeed-MoE: 推进混合专家推理和训练以支持下一代 AI 规模,Mixture of Experts - 博文:1,2以及大型基于 Transformer 的自然语言生成模型的特定部署:博文,Megatron-Deepspeed 分支。
使用 PyTorch 原生注意力和 Flash Attention
PyTorch 2.0 发布了一个原生的torch.nn.functional.scaled_dot_product_attention(SDPA),允许使用融合的 GPU 内核,如内存高效注意力和闪存注意力。
安装optimum包后,可以替换相关的内部模块以使用 PyTorch 的原生注意力,方法如下:
model = model.to_bettertransformer()
转换后,像往常一样训练模型。
PyTorch 原生的scaled_dot_product_attention操作符只有在没有提供attention_mask时才能分派到 Flash Attention。
默认情况下,在训练模式下,BetterTransformer 集成取消了掩码支持,只能用于不需要填充掩码的批量训练。例如,在掩码语言建模或因果语言建模期间。BetterTransformer 不适用于需要填充掩码的任务的微调模型。
查看这篇博文,了解有关 SDPA 加速和节省内存的更多信息。

















 5383
5383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









