







生存分析导论:尼尔森-艾伦估计量

了解如何使用非参数方法来估计累积风险函数!
在之前的文章中,我已经描述了 Kaplan-Meier 估计量。简单回顾一下,这是一种逼近真实生存函数的非参数方法。这一次,我将重点关注可视化生存数据集的另一种方法——使用风险函数和 Nelson-Aalen 估计量。同样,我们将使用lifetimes库的便利来快速创建 Python 中的情节。
1.尼尔森-艾伦估计量
利用卡普兰-迈耶曲线,我们近似计算了生存函数,说明了在某个时间 t. 内不发生感兴趣事件(例如,死亡事件)的概率
另一种方法是使用风险函数来可视化来自以生存为中心的数据集的综合信息,风险函数可以被解释为受试者在一小段时间间隔内经历感兴趣事件的概率,假设受试者已经生存到所述间隔的开始。有关危险功能的更详细描述,请参见这篇文章。
不幸的是,我们不能将生存函数的 Kaplan-Meier 估计转换成风险函数。然而,我们可以使用累积风险函数的另一个非参数估计量——Nelson-Aalen 估计量。简而言之,它用于估计在一定时间内预期事件的累计数量。它之所以是累积的,是因为估计的和比逐点估计要稳定得多。
Nelson-Aalen 估计值可计算如下:

其中 d_i 代表在时间 t 的感兴趣事件的数量,而 n_i 是处于危险中的观察的数量。所有这些项自然与 Kaplan-Meier 估计公式中的项相似。
Nelson-Aalen 估计量,或者更一般地,将风险函数随时间可视化,并不是一种非常流行的生存分析方法。这是因为——与生存函数相比——对曲线的解释不那么简单和直观。然而,风险函数对于更高级的生存分析方法非常重要,例如 Cox 回归。这就是为什么理解这个概念很重要,我将试着提供一些关于它的见解。我们可以说累积风险函数:
- 衡量到某个时间点为止累积的风险总量 t.
- 如果事件是可重复的,则提供我们在数学上预期感兴趣的事件在某个时间段内发生的次数。这可能有点令人困惑,所以为了使陈述简单一点(但不太现实),你可以把累积风险函数想象成一个人到时间 *t,*为止的预期死亡次数,如果这个人可以在每次死亡后复活而不重置时间的话。正如我所说的,这不太现实,但这同样适用于机器故障等。
最后一个可能有助于获得累积风险函数直觉的概念是浴缸曲线,或者更确切地说是它的组成部分。这条曲线代表了许多电子消费产品的生命周期。浴盆曲线的风险率是通过结合以下因素得出的:
- 产品首次推出时的早期“婴儿死亡率”失败率,
- 在产品的设计寿命期间,具有恒定故障率的随机故障率,
- 产品超过预期寿命时的“磨损”故障率。

而上图代表的是危险率(不是累计的!),Nelson–Aalen 估计曲线的形状让我们了解了风险率如何随时间变化。
例如,累积风险函数的凹形表明我们正在处理一种“婴儿死亡率”事件(图中的红色虚线),其中失败率在早期最高,随着时间的推移而降低。另一方面,累积风险函数的凸形意味着我们正在处理“磨损”类事件(黄色虚线)。
我相信这些理论足以理解累积风险函数的 Nelson-Aalen 估计量。是时候编码了!
2.Python 中的示例
为了保持一致,我们继续使用上一篇文章中开始的流行的电信客户流失数据集。为了简洁起见,请参考文章中对数据集的描述以及对其应用转换的推理。首先,我们加载所需的库。
然后,我们加载数据:
lifelines使计算和绘制 Nelson-Aalen 估计量的过程非常简单,我们只需运行以下几行代码来绘制累积风险函数。
该代码生成以下图形:

我认为,基于 Nelson-Aalen 估计值的累积风险函数的形状可能表明,我们正在处理的风险函数类似于浴缸曲线。这是因为我们看到,在开始和接近结束时,变化率都较高,而在客户与公司的生命周期中间,变化率或多或少趋于平缓(稳定在一个恒定的水平)。
我们还可以通过使用拟合的NelsonAalenFitter对象的cumulative_hazard_方法来轻松访问累积风险函数。
该库提供的另一个有趣的功能是 events 表,它汇总了每个时间点发生的事情。我们可以通过运行naf.event_table来获得它,结果如下:

与 Kaplan-Meier 案例类似,我们也将绘制支付方式的每个变量的累积风险函数。由于lifelines提供了一种统一的方法来处理用于生存分析的不同工具,代码只需要少量的修改。
对于两种自动支付类别:银行转账和信用卡,累积风险函数的形状非常相似。

注:在理论介绍中,我们提到用累积风险函数代替风险函数的原因是前者的精度更高。然而,lifelines提供了一种通过应用核平滑器从累积函数中导出风险函数的方法。那么,问题出在哪里?为此,我们需要指定带宽参数,由此产生的风险函数的形状高度依赖于所选的值。我将引用作者对这种方法的评论:“*没有明显的方法来选择一个带宽,不同的带宽产生不同的推论,所以这里最好非常小心。我的建议是:坚持累积风险函数。”。*如果你仍然感兴趣,请查看文档。
3.结论
在这篇文章中,我试图提供一个估计累积风险函数的介绍和一些关于结果解释的直觉。虽然 Nelson-Aalen 估计值远不如 Kaplan-Meier 生存曲线流行,但在使用更高级的生存分析方法(如 Cox 回归)时,理解它可能会非常有帮助。
您可以在我的 GitHub 上找到本文使用的代码。一如既往,我们欢迎任何建设性的反馈。你可以在推特上或者评论里联系我。
如果您对这篇文章感兴趣,您可能也会喜欢本系列中的其他文章:
了解生存分析的基本概念,以及可以用来做什么任务!
towardsdatascience.com](/introduction-to-survival-analysis-6f7e19c31d96) [## 生存分析导论:卡普兰-迈耶估计量
了解用于生存分析的最流行的技术之一,以及如何用 Python 实现它!
towardsdatascience.com](/introduction-to-survival-analysis-the-kaplan-meier-estimator-94ec5812a97a) [## 用 Tableau 提升你的 Kaplan-Meier 曲线
方便访问整个公司的生存分析!
towardsdatascience.com](/level-up-your-kaplan-meier-curves-with-tableau-bc4a10ec6a15)
4.参考
[1]https://stats . stack exchange . com/questions/60238/直觉累积危险功能生存分析
技术指标介绍及其 Python 实现
建立你自己的技术指标图表,以创建和实施交易策略
技术指标是做什么的?
技术指标是从股票价格(高、低、开、闭)和交易量的运动模式中产生的信号。这些信号又被用来预测未来的价格走势。技术分析师在历史数据中寻找指标,用它们来寻找交易的进场点和出场点。技术分析师不同于基本面分析师,基本面分析师通过观察基本面和内在价值来评估股票的表现。

鸣谢:图片来自 Unsplash
技术指标大致分为两大类:
1.**叠加图:**它们使用与价格相同的标度,并被绘制在股价图上价格的上方。例子:移动平均线,布林线
2.**振荡指标:**这些技术指标在局部最大值和局部最小值之间振荡,绘制在价格图的上方或下方。例子:MACD
我们将涉及的技术指标的一些基本示例如下:
1.简单移动平均线
2.加权移动平均数(WMA)
3.指数移动平均线
4.移动平均收敛发散(MACD)
5.布林线
移动平均线:
均线是广泛使用的技术分析指标之一。这是一个在日常生活中听说过的概念,如果不是关于股票的话。移动平均通过过滤曲线中的各种噪声来平滑曲线。由于移动平均线是基于历史价格而不是实际价格,人们可能会观察到它相对于真实股价曲线的曲线滞后。常用的均线有 5、10、20、50、200 日均线。
在移动平均线中,进一步分类为简单移动平均线(SMA)、加权移动平均线(WMA)和指数移动平均线(EMA)。
简单移动平均线:
简单移动平均线(SMA)是所有股票价格的非常基本的平均值或算术平均值,这意味着所有股票价格的总和除以周期数。

简单移动平均线来源:维基百科
加权移动平均:
在加权移动平均线(WMA)中,每个价格点被赋予不同的权重。在将各种权重乘以各自的股票价格后,这些权重的总和除以总周期数。在简单移动平均线的情况下,股票价格被赋予相等的权重。

来源:Sap.com
指数移动平均:
指数移动平均线(EMA)是一个 3 步过程。为此,我们使用简单移动平均线计算第一根均线。其次,我们计算乘数的平滑因子。第三,我们把这个乘数应用到前一天的均线上。在这个过程中,我们会给最新的价格分配更高的权重。

来源:Investopedia
移动平均线收敛发散:
移动平均线收敛发散(MACD)是一个振荡的技术指标。它通过发现股票价格的两条移动平均线之间的关系来显示股票所遵循的动量。一般是用 12 期均线减去 26 期指数移动平均线(EMA)计算出来的。许多交易者用这个作为进场信号,并以某种方式解读,让他们洞察自己的交易决策。
MACD 线:MACD 的 9 日均线叫做信号线,它是在 MACD 线上运行均线得到的。现在这条线被绘制在 MACD 线的顶部,这有助于分析交叉、分叉和陡坡。通过这条线,分析师能够解读买入和卖出信号。如果 MACD 越过了它的信号线,交易者可能会买入股票,如果它越过了信号线,就会卖出。
布林线:
布林线的概念最初是由约翰·布林格提出的。这些波段由上下波段组成,位于均线上下两个标准差范围内。
分析的方法是首先假设它们是价格目标的上限和下限。如果股价跌破较低的价格带,这可能表明买入触发,反之亦然。
使用 Python 的技术指标:
我尝试过使用 python 来构建这些技术指标。我已经使用 IEX API 获得了“网飞”股票价格的收盘价,并将其直接加载到数据框架中进行进一步分析。请看下面的代码:
形状记忆合金分析:

10 天和 50 天的 SMA
上面的内容非常直观地向我们展示了价格走势和交叉的趋势。
均线分析:

10 天和 50 天的均线
当长期(50 天)均线穿过短期(10 天)均线时,我们可以推断价格已经正式开始下跌,这应该是卖出信号。同样,当短期移动平均线穿过长期移动平均线时,这是买入信号。
布林线分析:

20 天移动平均线的布林线
这里有更多的概念叫做挤压和突破。当带子靠得更近时,就会发生挤压。交易员认为这是一个波动性较低的时期,预计未来波动性将会增加。这又被认为是未来贸易机会的可能性。突破显示股价穿过布林线的点。
布林线帮助我们识别买入和卖出信号,这也可以从上面的图表中看出。只要股价突破波段,就可以推断出信号。如果股价低于较低的波段,就存在买入该股票的机会,同样,如果股价穿过较高的波段,现在就是卖出的时候
MACD 分析:

MACD vs 信号线
从第二张图中,我们可以观察到一些交叉的发生。当 MACD 线穿过信号线时,我们可以假设特定股票的价格上涨,反之亦然,当信号线穿过 MACD 线时
再者:
在这篇文章中,我提到了一些技术指标,初学者可以从这些指标开始,慢慢地探索各种复杂性和许多其他指标。如需进一步阅读,可以浏览下面这篇关于 Investopedia 的文章:
在统计学中,移动平均线是一种计算方法,用于通过创建一系列平均值来分析数据点
www.investopedia.com](https://www.investopedia.com/terms/m/movingaverage.asp)
来自《走向数据科学》编辑的提示: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们并不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者用语。
Python 文本分类简介

基于朴素贝叶斯模型的文本分类。
在过去的几年里,在线学习的影响力越来越大。使用它已经有很多应用,从市场营销、生物信息学、城市规划等等。机器学习是一种从数据中学习表示的方法,因此我们可以使用它来提取知识或基于它预测标签。这种方法的应用之一是文本分类。
文本分类是我们将文本分类到它们所属的类别的任务。在机器学习成为一种趋势之前,这项工作大多由几个标注者手工完成。这在未来会成为一个问题,因为数据变得越来越大,光是做这件事就要花很多时间。因此,我们应该使任务自动化,同时也获得更高的准确性。
在本文中,我将向您展示如何使用 Python 进行文本分类。对于数据集,我们将使用一个名为真实与否的 Kaggle 竞赛的数据集。灾难推文的 NLP。我还在 Google Colab 上做了这个笔记本,你可以在这里找到它。
概述
本文将分为几个部分:
- 清洗正文
- 用 TF-IDF 权重建立文档术语矩阵
- 朴素贝叶斯的概念
- 使用 Python 实现
该过程
清理文本
我们要做的第一步是准备和清理数据集。清理数据集是删除任何无意义的单词或无用的术语(如标签、提及、标点等等)的必要步骤。
为了清理文本,我们可以利用 re 之类的库来删除带有模式的术语,利用 NLTK 来删除单词,例如停用词。我还解释了如何使用 Python 一步一步地清理文本,您可以在这里看到,
你需要的只是 NLTK 和 re 库。
towardsdatascience.com](/cleaning-text-data-with-python-b69b47b97b76)
这是一些文本在预处理前的样子,
**Our Deeds are the Reason of this #earthquake May ALLAH Forgive us all****Forest fire near La Ronge Sask. Canada****All residents asked to 'shelter in place' are being notified by officers. No other evacuation or shelter in place orders are expected****13,000 people receive #wildfires evacuation orders in California** **Just got sent this photo from Ruby #Alaska as smoke from #wildfires pours into a school** **#RockyFire Update => California Hwy. 20 closed in both directions due to Lake County fire - #CAfire #wildfires****#flood #disaster Heavy rain causes flash flooding of streets in Manitou, Colorado Springs areas****I'm on top of the hill and I can see a fire in the woods...****There's an emergency evacuation happening now in the building across the street****I'm afraid that the tornado is coming to our area...**
执行该任务的代码如下所示,
**# # In case of import errors
# ! pip install nltk
# ! pip install textblob**import re
from textblob import TextBlob
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords**# # In case of any corpus are missing
# download all-nltk**
nltk.download()df = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')stop_words = stopwords.words("english")def text_preproc(x):
x = x.lower()
# x = ' '.join(wordnet.lemmatize(word, 'v') for word in x.split())
x = ' '.join([word for word in x.split(' ') if word not in stop_words])
x = x.encode('ascii', 'ignore').decode()
x = re.sub(r'https*\S+', ' ', x)
x = re.sub(r'@\S+', ' ', x)
x = re.sub(r'#\S+', ' ', x)
x = re.sub(r'\'\w+', '', x)
x = re.sub('[%s]' % re.escape(string.punctuation), ' ', x)
x = re.sub(r'\w*\d+\w*', '', x)
x = re.sub(r'\s{2,}', ' ', x)
return xdf['clean_text'] = df.text.apply(text_preproc)
test['clean_text'] = test.text.apply(text_preproc)
这是清洁步骤后的结果,
**deeds reason may allah forgive us****forest fire near la ronge sask canada****residents asked place notified officers evacuation shelter place orders expected****people receive evacuation orders california****got sent photo ruby smoke pours school****update california hwy closed directions due lake county fire****heavy rain causes flash flooding streets manitou colorado springs areas****i top hill see fire woods****there emergency evacuation happening building across street****i afraid tornado coming area**
还有,记笔记!确保从 NLTK 下载所有的包和语料库(基本上是单词的集合)。
使用 TF-IDF 权重构建术语-文档矩阵
在我们清理完数据之后,现在我们可以构建一个文本表示,这样计算机就可以轻松地读取数据。我们将使用术语-文档矩阵作为文本的表示。
术语-文档矩阵(TDM) 是一个矩阵,其中行代表每个文档,列代表每个术语(词),单元格用数字填充。
单元格由每个文档的字数组成。我们可以用来填充它的一种方法叫做词频——逆文档频(TF-IDF)。
词频—逆文档频率(TF-IDF) 是一个文档上的一个词的频率(词频)和一个词在所有文档上的逆频率(逆文档频率)的乘积。
词频(TF) 是计算文档中一个词的数量的公式。因为单词之间的数量不同,我们应用以 10 为底的对数来重新调整它。它看起来像这样,

逆文档频率(IDF) 是一个计算所有文档上单词稀有度的公式。如果数量很少,这个词就很常用。但如果大一点,这个词就不那么频繁了。这个公式将被用作 TF 的权重,它看起来像这样,

要创建术语-文档矩阵(TDM ),我们可以使用 sklearn 库中名为 TfidfVectorizer 的函数。代码看起来会像这样,
**vectorizer = TfidfVectorizer()****X = vectorizer.fit_transform(df['clean_text']).toarray()
df_new = pd.DataFrame(X, columns=vectorizer.get_feature_names())****X_test = vectorizer.transform(test['clean_text']).toarray()
test_new = pd.DataFrame(X_test, columns=vectorizer.get_feature_names())**
当您编写代码时,您必须非常小心对每个数据集使用哪个函数。对于训练数据,请确保使用 fit_transform 方法,因为它将根据训练数据中的项数进行拟合,并将其转换为矩阵。
同时,在测试数据上,确保您使用了 transform 方法,因为它会将文本转换为具有相同数量的训练数据列的矩阵。如果我们也对其使用 fit_transform,它将根据测试数据的项数创建一个矩阵。因此,它在列上不会有相同的维度,所以请确保检查您将使用的方法。
如果我们做对了,它会给出具有相同列维数的矩阵,以及一个类似这样的矩阵,

朴素贝叶斯的概念
有了矩阵后,现在我们可以将它应用到模型中。我们将使用的模型是朴素贝叶斯。
朴素贝叶斯是一种机器学习模型,通过计算数据属于某个类的概率来解决监督学习任务。
它基于贝叶斯原理,并假设文档中的每个术语都是相互独立的。计算这个的公式是这样的,

让我解释一下它的每一部分,
- P(c|d)代表文档属于一个类别的概率,
- 阿尔法符号对应于两边的比例,
- P©是通过计算一个类别的数量与文档总数的比例而得到的该类别的先验概率。公式看起来像这样,

其中 Nc 是数据集中相应类的数量,N 是数据集中文档的数量。
- P(t id | c)的乘积是文档(d)中属于类别©的每一项的概率结果的乘积。公式看起来像这样,

其中,T ct 对应于类别内的该项的数量,T CT’的总和对应于给定类别的项的总数,B 代表训练数据集上不同词汇的数量,1 代表模型的平滑以避免零。
P(t id | c)公式会根据我们对问题的表述而不同。前一个问题把它表述为一个多项式问题,我们计算一个类中有多少确切的项。我们有时称这个模型为多项式朴素贝叶斯。
还有一个模型叫做伯努利朴素贝叶斯,这里 P(t id | c)的计算是不同的。它将计算包含该术语的文档数量占所有文档总数的比例。公式看起来像这样,

其中 Nct 对应于包含该类别的术语的文档总数,Nc 对应于该类别的文档总数。
在我们计算每个概率后,我们将选择概率最高的最佳类。

使用 Python 的实现
在我向您解释了这些概念之后,让我们继续讨论实现。对于这一步,我将使用 scikit-learn 库来完成。
当我们建立模型时,要知道的重要方面是模型是否给出了很好的结果,尤其是在看不见的数据上,所以我们有信心使用它。我们可以通过一个叫做交叉验证的概念来做到这一点。代码看起来像这样,
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.model_selection import KFold
from sklearn.metrics import f1_scoreX = df_new.values
y = df.target.valueskfold = KFold(n_splits=10)**# Define the model**
nb_multinomial = MultinomialNB()
nb_bernoulli = BernoulliNB()**# As a storage of the model's performance**
def calculate_f1(model):
metrics = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
metrics.append(f1_score(y_test, y_pred))
**# Retrieve the mean of the result**
print("%.3f" % np.array(metrics).mean()) calculate_f1(nb_multinomial)
>>> 0.681calculate_f1(nb_bernoulli)
>>> 0.704
calculate_f1 函数是怎么回事?
- 首先,它将模型作为输入。
- 然后,它将在 k 次中进行交叉验证,在每次循环中,它将数据集分为训练和测试数据集,然后模型拟合训练数据并预测测试数据上的标签。
- 最后,我们计算每个交叉验证分数的平均值。
在此基础上,我们得出了伯努利朴素贝叶斯模型的得分(0.704)优于多项式朴素贝叶斯模型的得分(0.681)。
因此,我们将使用伯努利朴素贝叶斯作为我们的模型来预测真实的测试集数据。代码看起来像这样,
from sklearn.naive_bayes import BernoulliNBdef predict_to_csv(model, X, y):
model.fit(X, y)
X_test = test_new.values
y_pred = model.predict(X_test) **# Preparing submission**
submission = pd.DataFrame()
submission['id'] = test['id']
submission['target'] = y_pred
submission.to_csv('file_name.csv', index=False) **# Validate**
submission = pd.read_csv('file_name.csv')
print(submission.head()) nb_bernoulli = BernoulliNB()
X = df_new.values
y = df.target.valuespredict_to_csv(nb_bernoulli, X, y)
>>> id target
0 0 1
1 2 0
2 3 1
3 9 0
4 11 1
正如我们在上面看到的,我们用真实的训练数据拟合模型,并预测测试数据的标签。之后,我们创建一个数据框并将结果保存为 CSV 格式。最后你可以把那个提交给 Kaggle,你就知道结果好不好了。
最后的想法和建议
我想给你一些建议。对于这项任务,朴素贝叶斯是一个很好的机器学习模型,但还有很多空间来改进结果。您可以使用任何其他模型,如支持向量机、决策树、递归神经网络等等。
此外,您可以执行一些特征工程来移除数据上的无意义信息,或者您可以调整模型上的超参数。
终于,我们到了这篇文章的结尾。希望你从中有所收获,有想法可以在下面评论下来。此外,如果你对我的帖子感兴趣,你可以关注我的媒体来了解我的下一篇文章。
参考
[1] Pedregosa 等人,2011 年。sci kit-learn:Python 中的机器学习, JMLR 12,第 2825–2830 页。
[2]曼宁等,2011。信息检索导论。剑桥大学出版社,第 234–265 页。
【3】麦卡勒姆 a .和尼甘 K. 1998。朴素贝叶斯文本分类的事件模型比较。 Proc。AAAI/ICML-98 文本分类学习研讨会,第 41-48 页。
【4】哈立德,I. A. 2020。使用 Python 创建简单的搜索引擎。走向数据科学。https://towardsdatascience . com/create-a-simple-search-engine-using-python-412587619 ff 5
https://www.kaggle.com/c/nlp-getting-started
【6】https://en.wikipedia.org/wiki/Naive_Bayes_classifier
语言处理的文本表示介绍—第 1 部分

在 Unsplash 上由 Jaredd Craig 拍照
计算机是如何理解和解释语言的?
计算机在处理数字时很聪明。它们在计算和解码模式方面比人类快很多个数量级。但是如果数据不是数字呢?如果是语言呢?当数据是字符、单词和句子时会发生什么?我们如何让计算机处理我们的语言?Alexa、Google Home &很多其他智能助手是如何理解&回复我们的发言的?如果你正在寻找这些问题的答案,这篇文章将是你走向正确方向的垫脚石。
自然语言处理是人工智能的一个子领域,致力于使机器理解和处理人类语言。大多数自然语言处理(NLP)任务的最基本步骤是将单词转换成数字,以便机器理解和解码语言中的模式。我们称这一步为文本表示。这一步虽然是迭代的,但在决定机器学习模型/算法的特征方面起着重要作用。
文本表示可以大致分为两部分:
- 离散文本表示
- 分布式/连续文本表示
本文将关注离散文本表示&我们将深入研究一些基本 Sklearn 实现中常用的表示。
离散文本表示:
这些表示中,单词由它们在字典中的位置的对应索引来表示,该索引来自更大的语料库。
属于这一类别的著名代表有:
- 一键编码
- 词袋表示法(BOW)
- 基本 BOW 计数矢量器
- 先进弓-TF-IDF
一键编码:
这是一种将 0 赋给向量中所有元素的表示形式,只有一个元素的值为 1。该值表示元素的类别。
例如:
如果我有一个句子,“我爱我的狗”,句子中的每个单词将表示如下:
I → [1 0 0 0], love → [0 1 0 0], my → [0 0 1 0], dog → [0 0 0 1]
然后,整个句子表示为:
sentence = [ [1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1] ]
一键编码背后的直觉是每个比特代表一个可能的类别&如果一个特定的变量不能归入多个类别,那么一个比特就足以代表它
正如您可能已经理解的,单词数组的长度取决于词汇量。这对于可能包含多达 100,000 个唯一单词甚至更多的非常大的语料库来说是不可扩展的。
现在让我们使用 Sklearn 来实现它:
from sklearn.preprocessing import OneHotEncoder
import itertools# two example documents
docs = ["cat","dog","bat","ate"]# split documents to tokens
tokens_docs = [doc.split(" ") for doc in docs]# convert list of of token-lists to one flat list of tokens
# and then create a dictionary that maps word to id of word,
all_tokens = itertools.chain.from_iterable(tokens_docs)
word_to_id = {token: idx for idx, token in enumerate(set(all_tokens))}# convert token lists to token-id lists
token_ids = [[word_to_id[token] for token in tokens_doc] for tokens_doc in tokens_docs]# convert list of token-id lists to one-hot representation
vec = OneHotEncoder(categories="auto")
X = vec.fit_transform(token_ids)print(X.toarray())
输出:
[[0\. 0\. 1\. 0.]
[0\. 1\. 0\. 0.]
[0\. 0\. 0\. 1.]
[1\. 0\. 0\. 0.]]
Sklearn 文档:
[## sk learn . preprocessing . onehotencoder-sci kit-learn 0 . 23 . 1 文档
将分类特征编码为一个独热数值数组。这个转换器的输入应该是一个类似数组的…
scikit-learn.org](https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html)
一键编码的优势:
- 易于理解和实施
一键编码的缺点:
- 如果类别数量非常多,特征空间会爆炸
- 单词的矢量表示是正交的,并且不能确定或测量不同单词之间的关系
- 无法衡量一个单词在句子中的重要性,但可以理解一个单词在句子中是否存在
- 高维稀疏矩阵表示可能是存储器和计算昂贵的
词袋表示法
顾名思义,单词包表示法将单词放在一个“包”中,并计算每个单词的出现频率。它不考虑文本表示的词序或词汇信息
BOW 表示背后的直觉是,具有相似单词的文档是相似的,而不管单词的位置如何
基本 BOW 计数矢量器
CountVectorizer 计算一个单词在文档中出现的频率。它将多个句子的语料库(比如产品评论)转换成评论和单词的矩阵,并用每个单词在句子中的出现频率填充它
让我们看看如何使用 Sklearn 计数矢量器:
from sklearn.feature_extraction.text import CountVectorizertext = ["i love nlp. nlp is so cool"]vectorizer = CountVectorizer()# tokenize and build vocab
vectorizer.fit(text)
print(vectorizer.vocabulary_)
# Output: {'love': 2, 'nlp': 3, 'is': 1, 'so': 4, 'cool': 0}# encode document
vector = vectorizer.transform(text)# summarize encoded vector
print(vector.shape) # Output: (1, 5)
print(vector.toarray())
输出:
[[1 1 1 2 1]]
如你所见,单词“nlp”在句子中出现了两次&也在索引 3 中。我们可以将其视为最终打印语句的输出
一个词在句子中的“权重”是它的出现频率
作为 CountVectorizer 的一部分,可以调整各种参数来获得所需的结果,包括小写、strp_accents、预处理器等文本预处理参数
可以在下面的 Sklearn 文档中找到完整的参数列表:
[## sk learn . feature _ extraction . text . count vectorizer-sci kit-learn 0 . 23 . 1 文档
class sk learn . feature _ extraction . text . count vectorizer(*,input='content ',encoding='utf-8 ',decode_error=‘strict’…
scikit-learn.org](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html)
CountVectorizer 的优势:
- CountVectorizer 还能给出文本文档/句子中单词的频率,这是一键编码所不能提供的
- 编码向量的长度就是字典的长度
CountVectorizer 的缺点:
- 此方法忽略单词的位置信息。从这种表述中不可能领会一个词的意思
- 当遇到像“is,The,an,I”这样的停用词时&当语料库是特定于上下文的时,高频词更重要或提供关于句子的更多信息的直觉失效了。例如,在一个关于新冠肺炎的语料库中,冠状病毒这个词可能不会增加很多价值
高级弓
为了抑制非常高频率的单词&忽略低频率的单词,需要相应地标准化单词的“权重”
**TF-IDF 表示:**TF-IDF 的完整形式是术语频率-逆文档频率是 2 个因子的乘积

其中,TF(w,d)是单词“w”在文档“d”中的频率
IDF(w)可以进一步细分为:

其中,N 是文档总数,df(w)是包含单词“w”的文档的频率
TF-IDF 背后的直觉是,分配给每个单词的权重不仅取决于单词频率,还取决于特定单词在整个语料库中的出现频率
它采用上一节中讨论的 CountVectorizer 并将其乘以 IDF 分数。对于非常高频率的词(如停用词)和非常低频率的词(噪声项),从该过程得到的词的输出权重很低
现在让我们尝试使用 Sklearn 来实现这一点
from sklearn.feature_extraction.text import TfidfVectorizertext1 = ['i love nlp', 'nlp is so cool',
'nlp is all about helping machines process language',
'this tutorial is on baisc nlp technique']tf = TfidfVectorizer()
txt_fitted = tf.fit(text1)
txt_transformed = txt_fitted.transform(text1)
print ("The text: ", text1)# Output: The text: ['i love nlp', 'nlp is so cool',
# 'nlp is all about helping machines process language',
# 'this tutorial is on basic nlp technique']idf = tf.idf_
print(dict(zip(txt_fitted.get_feature_names(), idf)))
输出:
{'about': 1.916290731874155, 'all': 1.916290731874155,
'basic': 1.916290731874155, 'cool': 1.916290731874155,
'helping': 1.916290731874155, 'is': 1.2231435513142097,
'language': 1.916290731874155, 'love': 1.916290731874155,
'machines': 1.916290731874155, 'nlp': 1.0, 'on': 1.916290731874155,
'process': 1.916290731874155, 'so': 1.916290731874155,
'technique': 1.916290731874155, 'this': 1.916290731874155,
'tutorial': 1.916290731874155}
注意单词“nlp”的权重。因为它出现在所有的句子中,所以它被赋予 1.0 的低权重。同样,停用词“is”的权重也相对较低,为 1.22,因为它在给出的 4 个句子中有 3 个出现。
与 CountVectorizer 类似,可以调整各种参数来获得所需的结果。一些重要的参数(除了像小写、strip_accent、stop_words 等文本预处理参数。)是 max_df,min_df,norm,ngram_range & sublinear_tf。这些参数对输出权重的影响超出了本文的范围,将单独讨论。
您可以在下面找到 TF-IDF 矢量器的完整文档:
[## sk learn . feature _ extraction . text . tfidf vectorizer-sci kit-learn 0 . 23 . 1 文档
class sk learn . feature _ extraction . text . tfidf vectorizer(*,input='content ',encoding='utf-8 ',decode_error=‘strict’…
scikit-learn.org](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html)
TF-IDF 代表的优势:
- 简单、易于理解和解释的实施
- 构建 CountVectorizer 来惩罚语料库中的高频词和低频词。在某种程度上,IDF 降低了我们矩阵中的噪声。
TF-IDF 代表的缺点:
- 这个单词的位置信息仍然没有在这个表示中被捕获
- TF-IDF 高度依赖语料库。由板球数据生成的矩阵表示不能用于足球或排球。因此,需要有高质量的训练数据
让我们总结一下
离散表示是每个单词都被认为是唯一的&根据我们上面讨论的各种技术转换成数字。我们已经看到了各种离散表示的一些重叠的优点和缺点,让我们将其作为一个整体来总结
离散表示的优点:
- 易于理解、实施和解释的简单表示
- 像 TF-IDF 这样的算法可以用来过滤掉不常见和不相关的单词,从而帮助模型更快地训练和收敛
离散表示的缺点:
- 这种表现与词汇量成正比。词汇量大会导致记忆受限
- 它没有利用单词之间的共现统计。它假设所有的单词都是相互独立的
- 这导致具有很少非零值的高度稀疏的向量
- 它们没有抓住单词的上下文或语义。它不认为幽灵和恐怖是相似的,而是两个独立的术语,它们之间没有共性
离散表示广泛用于经典的机器学习和深度学习应用,以解决复杂的用例,如文档相似性、情感分类、垃圾邮件分类和主题建模等。
在下一部分中,我们将讨论文本的分布式或连续文本表示&它如何优于(或劣于)离散表示。
希望你喜欢这篇文章。回头见!
回购链接
[## SundareshPrasanna/自然语言处理的文本表示介绍
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/SundareshPrasanna/Introduction-to-text-representation-for-nlp/tree/master)
喜欢我的文章?给我买杯咖啡
[## sundaresh 正在创作与数据科学相关的文章,并且热爱教学
嘿👋我刚刚在这里创建了一个页面。你现在可以给我买杯咖啡了!
www.buymeacoffee.com](https://www.buymeacoffee.com/sundaresh)
语言处理的文本表示法介绍—第 2 部分

在 Unsplash 上由 Jaredd Craig 拍照
更好地表现文本和语言的高级技术
在之前的文章中,我们讨论了将文本输入机器学习或人工智能算法的离散文本表示。我们学习了一些技术,它们的工作原理,它们各自的优点和缺点。我们还讨论了离散文本表示的缺点&它如何忽略了单词的定位&没有试图解释单词的相似性或内在含义。
在本文中,我们将研究文本的分布式文本表示&它如何解决离散表示的一些缺点。
分布式文本表示:
分布式文本表示是指一个单词的表示与另一个单词不独立或不互斥,并且它们的配置通常表示数据中的各种度量和概念。所以关于一个单词的信息沿着它所代表的向量分布。这不同于离散表示,在离散表示中,每个单词都被认为是唯一的&彼此独立。
一些常用的分布式文本表示有:
- 共生矩阵
- Word2Vec
- 手套
共生矩阵:
同现矩阵,顾名思义,考虑的是彼此邻近的实体的同现。使用的实体可以是一个单词,可以是一个双字母组合,甚至是一个短语。主要地,单个字被用于计算矩阵。它帮助我们理解语料库中不同单词之间的关联。
让我们看一个使用前一篇文章中讨论的 CountVectorizer 的例子&将其转换为连续表示,
from sklearn.feature_extraction.text import CountVectorizerdocs = ['product_x is awesome',
'product_x is better than product_y',
'product_x is dissapointing','product_y beats product_x by miles',
'ill definitely recommend product_x over others']# Using in built english stop words to remove noise
count_vectorizer = CountVectorizer(stop_words = 'english')
vectorized_matrix = count_vectorizer.fit_transform(docs)# We can now simply do a matrix multiplication with the transposed image of the same matrix
co_occurrence_matrix = (vectorized_matrix.T * vectorized_matrix)
print(pd.DataFrame(co_occurrence_matrix.A,
columns=count_vectorizer.get_feature_names(),
index=count_vectorizer.get_feature_names()))
输出:
awesome beats better definitely dissapointing ill miles \\
awesome 1 0 0 0 0 0 0
beats 0 1 0 0 0 0 1
better 0 0 1 0 0 0 0
definitely 0 0 0 1 0 1 0
dissapointing 0 0 0 0 1 0 0
ill 0 0 0 1 0 1 0
miles 0 1 0 0 0 0 1
product_x 1 1 1 1 1 1 1
product_y 0 1 1 0 0 0 1
recommend 0 0 0 1 0 1 0 product_x product_y recommend
awesome 1 0 0
beats 1 1 0
better 1 1 0
definitely 1 0 1
dissapointing 1 0 0
ill 1 0 1
miles 1 1 0
product_x 5 2 1
product_y 2 2 0
recommend 1 0 1
每个单词的表示是它在共现矩阵中对应的行(或列)
如果我们想了解与 product_x 相关的单词,我们可以过滤该列,并分析正在与 product_y &进行比较的 product_x 与它相关的正面形容词比负面形容词多。
优势:
- 寻找单词关联的简单表示法
- 与离散技术不同,它考虑句子中单词的顺序
- 这种方法产生的表示是全局表示。也就是说,它使用整个语料库来生成表示
缺点:
- 类似于 CountVectorizer & TF-IDF 矩阵,这也是一个稀疏矩阵。这意味着它的存储效率不高&在上面运行计算效率很低
- 词汇表越大,矩阵越大(不可扩展到大词汇表)
- 使用这种技术并不能理解所有的单词联想。在上面的例子中,如果你查看 product_x 列,有一行名为 *beats。*在这种情况下,仅通过查看矩阵无法确定 beats 的上下文
Word2Vec
Word2Vec 是一个著名的表示单词嵌入的算法。它是由托马斯·米卡洛夫于 2013 年在研究论文《向量空间中单词表示的高效估计》中开发的
这是一种基于预测的单词表示方法,而不是基于计数的技术,如共生矩阵
单词嵌入是单词的向量表示。每个单词由固定的向量大小表示,同时捕捉其与其他单词的语义&句法关系
word2vec 的架构是一个浅层的单隐层网络。隐藏层的权重是单词的嵌入&我们通过损失函数(正常的反向投影)来调整它
这种架构类似于自动编码器,其中有一个编码器层和一个解码器层,中间部分是输入的压缩表示,可用于降维或异常检测用例。
word2vec 通过两种方法/技术构建矢量表示:
- CBOW —尝试在周围单词的上下文中预测中间的单词。因此,简单来说,它试图填补空白,即在给定的上下文/周围单词的情况下,什么单词更适合。数据集越小,效率越高。与 Skip-Gram 相比,训练时间更短
- Skip-Gram —尝试从目标单词预测周围的上下文单词(与 CBOW 相反)。倾向于在较大的数据集中表现得更好,但需要更长的训练时间
Word2vec 能够使用简单的矢量算法捕获单词之间的多种相似度。像“男人对女人就像国王对王后”这样的模式可以通过像“国王”这样的算术运算获得——“男人”+“女人”=“王后”,其中“王后”将是单词本身最接近的向量表示。它还能够处理句法关系,如现在时和过去时,以及语义关系,如国家与首都的关系
让我们看看使用 gensim 的 word2vec 实现
# pip install --upgrade gensim or conda install -c conda-forge gensim# Word2Vec expects list of list representation of words, the outer list represents
# the sentence, while the inner list represents the individual words in a sentence
# Ex: ["I love NLP", "NLP is awesome"] -> [["I", "love", "NLP"], ["NLP", "is", "awesome"]]import gensim
sentences = ["ML is awesome", "ML is a branch of AI", "ML and AI are used interchangably nowadays",
"nlp is a branch and AI", "AI has fastforwarded nlp",
"RL is also a branch of AI", "word2vec is a high dimensional vector space embedding",
"word2vec falls under text representation for nlp"]# Preprocessing sentence to convert to format expected by w2v
sentece_list=[]
for i in sentences:
li = list(i.split(" "))
sentece_list.append(li)print(sentece_list)# Training Word2Vec with Skip-Gram (sg=1), 100 dimensional vector representation,
# with 1 as min word count for dropping noise terms, 4 parallel workers to run on
# Window of 4 for computing the neighbours & 100 iterations for the model to converge
model = gensim.models.Word2Vec(Bigger_list, min_count=1,
workers=4, size = 100, iter=100, sg=1, window=4)model.wv['word2vec']model.wv.most_similar(positive=['word2vec'])
输出
# Sentence List
[['ML', 'is', 'awesome'],
['ML', 'is', 'a', 'branch', 'of', 'AI'],
['ML', 'and', 'AI', 'are', 'used', 'interchangably', 'nowadays'],
['nlp', 'is', 'a', 'branch', 'and', 'AI'],
['AI', 'has', 'fastforwarded', 'nlp'],
['RL', 'is', 'also', 'a', 'branch', 'of', 'AI'],
['word2vec',
'is',
'a',
'high',
'dimensional',
'vector',
'space',
'embedding'],
['word2vec', 'falls', 'under', 'text', 'representation', 'for', 'nlp']]# 100-dimensional vector representation of the word - "word2vec"
array([-2.3901083e-03, -1.9926417e-03, 1.9080448e-03, -3.1678095e-03,
-4.9522246e-04, -4.5374390e-03, 3.4716981e-03, 3.8659102e-03,
9.2548935e-04, 5.1823643e-04, 3.4266592e-03, 3.7806653e-04,
-2.6678396e-03, -3.2777642e-04, 1.3322923e-03, -3.0630219e-03,
3.1524736e-03, -8.5508014e-04, 2.0837481e-03, 5.2613947e-03,
3.7915679e-03, 5.4354439e-03, 1.6099468e-03, -4.0912461e-03,
4.8913858e-03, 1.7630701e-03, 3.1557647e-03, 3.5352646e-03,
1.8157288e-03, -4.0848055e-03, 6.5594626e-04, -2.7539986e-03,
1.5574660e-03, -5.1965546e-03, -8.8450959e-04, 1.6077182e-03,
1.5791818e-03, -6.2289328e-04, 4.5868102e-03, 2.6237629e-03,
-2.6883748e-03, 2.6881986e-03, 4.0420778e-03, 2.3544163e-03,
4.8873704e-03, 2.4868934e-03, 4.0510278e-03, -4.2424505e-03,
-3.7380056e-03, 2.5551897e-03, -5.0872993e-03, -3.3367933e-03,
1.9790635e-03, 5.7303126e-04, 3.9246562e-03, -2.4457059e-03,
4.2443913e-03, -4.9923239e-03, -2.8107907e-03, -3.8890676e-03,
1.5237951e-03, -1.4327581e-03, -8.9179957e-04, 3.8922462e-03,
3.5140023e-03, 8.2534424e-04, -3.7862784e-03, -2.2930673e-03,
-2.1645970e-05, 2.9765235e-04, -1.4117253e-03, 3.0826295e-03,
8.1492326e-04, 2.5406217e-03, 3.3184432e-03, -3.5381948e-03,
-3.1870278e-03, -2.7319558e-03, 3.0047926e-03, -3.9584241e-03,
1.6430502e-03, -3.2808927e-03, -2.8428673e-03, -3.1900958e-03,
-3.9418009e-03, -3.3188087e-03, -9.5077307e-04, -1.1602251e-03,
3.4587954e-03, 2.6288461e-03, 3.1395135e-03, 4.0585222e-03,
-3.5573558e-03, -1.9402980e-03, -8.6417084e-04, -4.5995312e-03,
4.7944607e-03, 1.1922724e-03, 6.6742860e-04, -1.1188064e-04],
dtype=float32)# Most similar terms according to the trained model to the word - "Word2Vec"
[('AI', 0.3094254434108734),
('fastforwarded', 0.17564082145690918),
('dimensional', 0.1452922821044922),
('under', 0.13094305992126465),
('for', 0.11973076313734055),
('of', 0.1085459440946579),
('embedding', 0.06551346182823181),
('are', 0.06285746395587921),
('also', 0.05645104497671127),
('nowadays', 0.0527990460395813)]
在几行代码中,我们不仅能够将单词训练和表示为向量,还可以使用一些内置的函数来使用向量运算来查找最相似的单词、最不相似的单词等。
有两种方法可以找到向量之间的相似性,这取决于它们是否被归一化:
- **如果归一化:**我们可以计算向量之间的简单点积,以确定它们有多相似
- **如果没有归一化:**我们可以使用下面的公式计算向量之间的余弦相似度

余弦相似度与余弦距离的关系
关于所有可能的参数和功能,您可以参考下面的 gensim 文档:
这个模块实现了 word2vec 系列算法,使用了高度优化的 C 例程、数据流和…
radimrehurek.com](https://radimrehurek.com/gensim/models/word2vec.html)
关于余弦相似性的更多细节,请参考下面的维基文章
[## 余弦相似性
余弦相似性是内积空间的两个非零向量之间的相似性的度量。它被定义为…
en.wikipedia.org](https://en.wikipedia.org/wiki/Cosine_similarity)
该架构的确切工作方式&训练算法&如何发现单词之间的关系超出了本文的范围&值得单独写一篇文章
原文可以在下面找到:
[## 向量空间中单词表示的有效估计
我们提出了两种新的模型架构,用于从非常大的数据中计算单词的连续向量表示…
arxiv.org](https://arxiv.org/abs/1301.3781)
优势:
- 能够捕捉不同单词之间的关系,包括它们的句法和语义关系
- 嵌入向量的大小很小&很灵活,不像前面讨论的所有算法,嵌入的大小与词汇量成比例
- 由于无人监管,标记数据的人工工作更少
缺点:
- Word2Vec 不能很好地处理词汇外的单词。它为 OOV 单词分配随机向量表示,这可能是次优的
- 它依赖于语言单词的局部信息。一个词的语义表示只依赖于它的邻居&可能被证明是次优的
- 新语言培训的参数不能共享。如果你想用一种新的语言训练 word2vec,你必须从头开始
- 需要相对较大的语料库来使网络收敛(特别是如果使用 skip-gram
手套
单词表示的全局向量是 NLP 中经常使用的另一种著名的嵌入技术。这是斯坦福大学的 Jeffery Pennington、Richard Socher 和 Christopher D Manning 在 2014 年发表的一篇论文的结果。
它试图克服上面提到的 word2vec 的第二个缺点,通过学习单词的局部和全局统计来表示它。也就是说,它试图包含基于计数的技术(共现矩阵)和基于预测的技术(Word2Vec)的精华,因此也被称为用于连续单词表示的混合技术
在手套中,我们试图加强下面的关系

其可以被重写为,


因此,本质上,我们正在构造忠实于 P(i|j)的词向量 Vi 和 Vj,P(I | j)是从共现矩阵全局计算的统计
GloVe 的棘手部分是目标函数的推导,这超出了本文的范围。但是我鼓励你阅读这篇论文,它包含了它的推导过程,以进一步理解它是如何被转化为一个优化问题的
[## [PDF] Glove:单词表示的全局向量|语义学者
最近的学习单词向量空间表示的方法已经成功地捕获了细粒度的语义和语义
www.semanticscholar.org](https://www.semanticscholar.org/paper/Glove%3A-Global-Vectors-for-Word-Representation-Pennington-Socher/f37e1b62a767a307c046404ca96bc140b3e68cb5)
为了改变,而不是从零开始构建手套向量,让我们了解如何利用在数十亿条记录上训练的令人敬畏的预训练模型
import gensim.downloader as api# Lets download a 25 dimensional GloVe representation of 2 Billion tweets
# Info on this & other embeddings : <https://nlp.stanford.edu/projects/glove/>
# Gensim provides an awesome interface to easily download pre-trained embeddings
# > 100MB to be downloaded
twitter_glove = api.load("glove-twitter-25")# To find most similar words
# Note : All outputs are lowercased. If you use upper case letters, it will throw out of vocab error
twitter_glove.most_similar("modi",topn=10)# To get the 25D vectors
twitter_glove['modi']twitter_glove.similarity("modi", "india")# This will throw an error
twitter_glove.similarity("modi", "India")
输出:
# twitter_glove.most_similar("modi",topn=10)
[('kejriwal', 0.9501368999481201),
('bjp', 0.9385530948638916),
('arvind', 0.9274109601974487),
('narendra', 0.9249324798583984),
('nawaz', 0.9142388105392456),
('pmln', 0.9120966792106628),
('rahul', 0.9069461226463318),
('congress', 0.904523491859436),
('zardari', 0.8963413238525391),
('gujarat', 0.8910366892814636)]# twitter_glove['modi']
array([-0.56174 , 0.69419 , 0.16733 , 0.055867, -0.26266 , -0.6303 ,
-0.28311 , -0.88244 , 0.57317 , -0.82376 , 0.46728 , 0.48607 ,
-2.1942 , -0.41972 , 0.31795 , -0.70063 , 0.060693, 0.45279 ,
0.6564 , 0.20738 , 0.84496 , -0.087537, -0.38856 , -0.97028 ,
-0.40427 ], dtype=float32)# twitter_glove.similarity("modi", "india")
0.73462856# twitter_glove.similarity("modi", "India")
KeyError: "word 'India' not in vocabulary"
优势
- 在类比任务中,它往往比 word2vec 表现得更好
- 它在构造向量时考虑词对到词对的关系&因此与从词-词关系构造的向量相比,倾向于向向量添加更多的含义
- 与 Word2Vec 相比,GloVe 更容易平行化,因此训练时间更短
不足之处
- 因为它使用了共现矩阵&全局信息,所以与 word2vec 相比,它的内存开销更小
- 类似于 word2vec,它没有解决多义词的问题,因为词和向量是一对一的关系
荣誉提名:
下面是一些高级语言模型,在掌握了上述表示法之后,应该对它们进行探索
工程与后勤管理局
从语言模型嵌入是 Matthew E. Peters 等人在 2018 年 3 月以深度语境化单词表示的名义发表的论文。
它试图通过在向量表示和它所表示的单词之间建立多对一的关系来解决 word2vec & GloVe 的缺点。也就是说,它结合了上下文并相应地改变了单词的向量表示。
它使用字符级 CNN 将单词转换为原始单词向量。这些进一步输入双向 LSTMs 进行训练。向前和向后迭代的组合创建了分别表示单词前后的上下文信息的中间单词向量。
原始单词向量和两个中间单词向量的加权和给出了最终的表示。
原始 ELMO 纸
[## 深层语境化的词汇表征
我们介绍了一种新的深度上下文化的单词表示,它模拟了(1)单词的复杂特征…
arxiv.org](https://arxiv.org/abs/1802.05365)
伯特
BERT 是谷歌 AI 团队以 BERT 的名义发表的一篇论文:2019 年 5 月出来的语言理解深度双向转换器的预训练。这是一种新的自我监督学习任务,用于预训练变压器,以便针对下游任务对其进行微调
BERT 使用语言模型的双向上下文,即它试图屏蔽从左到右和从右到左,以创建用于预测任务的中间标记,因此有术语双向。
BERT 模型的输入表示是标记嵌入、分段嵌入和位置嵌入的总和,遵循模型的掩蔽策略来预测上下文中的正确单词。

它使用一种转换网络和注意力机制,学习单词之间的上下文关系,并进行微调,以承担其他任务,如 NER 和问答配对等。
原文可以在下面找到:
[## BERT:用于语言理解的深度双向转换器的预训练
我们介绍了一种新的语言表示模型,称为 BERT,代表双向编码器表示…
arxiv.org](https://arxiv.org/abs/1810.04805)
摘要
分布式文本表示是能够处理 NLP 中复杂问题陈述的强大算法。
单独地,它们可以用于理解和探索语料库,例如,探索语料库中的单词&它们如何彼此关联。但是,当与用于解决问题陈述的监督学习模型结合时,它们的优势和重要性才真正显现出来,例如问答、文档分类、聊天机器人、命名实体识别等等。
如今,它们在猜想中被频繁地使用 CNNs & LSTMs 来求解&是许多最新成果的一部分。
希望你喜欢这个系列!
回购链接:
[## SundareshPrasanna/自然语言处理的文本表示介绍
为 SundareshPrasanna/Introduction-to-text-re presentation-for-NLP 开发创建一个帐户…
github.com](https://github.com/SundareshPrasanna/Introduction-to-text-representation-for-nlp/tree/master)
喜欢我的文章?给我买杯咖啡
[## sundaresh 正在创作与数据科学相关的文章,并且热爱教学
嘿👋我刚刚在这里创建了一个页面。你现在可以给我买杯咖啡了!
www.buymeacoffee.com](https://www.buymeacoffee.com/sundaresh)
介绍强化学习的致命问题

作者图片
当我了解深度强化学习时,我阅读了致命三合问题,但找不到任何令人满意的简单解释(除了科学论文)。因此,我写了两篇文章用直觉(因此很少用数学)解释它是什么,然后是如何处理的。
这个问题表明,当一个人试图结合TD-学习(或引导)、偏离策略学习和函数逼近(如深度神经网络)时,可能会出现不稳定和发散。
强化学习问题
我认为你熟悉强化学习问题的典型表述。如果没有,请查看以下一个(或多个)来源:
强化学习被定义为一种机器学习方法,它关注的是软件代理应该如何采取…
www.guru99.com](https://www.guru99.com/reinforcement-learning-tutorial.html)
Arxiv Insights 的视频,非常清晰完整
大卫·西尔弗的精彩讲座(每次 1.5 小时)
我将使用通常的符号。
学习价值函数
我们想要解决 RL 问题的方法是学习价值函数。特别是,我们对 Q 值函数感兴趣,对于我们所处的任何状态,以及我们选择的任何行动,都会给我们带来回报(行动有多好)。
Q 值函数给出的不是执行这个动作后获得的奖励,而是执行这个动作后,如果你遵循你的策略,你将获得的所有奖励的总和(潜在折扣),称为回报:

回报方程
使用随机ε-贪婪策略
如果代理人想知道一个动作有多好,他首先要尝试一下。这将把他带到另一个状态,在那里他可以在不同的行动之间再次选择。这个想法是:
- 探索:尝试许多动作
- 利用:更多地使用积极的高回报行为,以获得最佳策略。
因此,一个经典的方法是首先尝试完全随机的行动,这样你就可以了解每个状态下哪个行动是好的,哪个是坏的,并逐步优先考虑给你最积极回报的行动。
因此,策略在这里(在强化学习的大部分时间里)随机,这意味着它随机地行动。
注意不要将其与一致随机混淆,我这里不是说代理完全随机地选择动作,它试图以更高的概率选择好的动作而不是坏的动作,但是它必须探索、测试它不知道结果的动作,因此不能有完全确定的策略。
基于贝尔曼方程,有不同的方法来学习该函数,例如动态编程、蒙特卡罗方法和自举。
动态规划
如果你有一个精确的环境模型(例如,在一个特定的状态下执行一个特定的动作,你将获得什么样的回报和状态),你可以使用动态编程来计算你的状态和动作的值。
然而,对于有许多状态和动作的环境,或者随机的环境,获得环境的模型是非常昂贵的。因此,人们更喜欢使用蒙特卡罗技术(比如 AlphaGo 的 Deepmind)。
蒙特卡洛
使用蒙特卡罗,代理通过选择它来更新他所考虑的动作的值,然后遵循他的策略直到情节终止(它到达最终状态)。然后,它可以汇总他通过这一集获得的所有回报,并获得回报的近似值。重复这个过程足够多次将最终收敛到状态动作的真实 Q 值。
如果你有很长的一集,这也是非常昂贵的,因为你必须等待一集结束才能获得回报。
时差学习
为了找到正确的 Q 值,我们可以观察到,对于每个状态/动作对的**,它应该收敛于回报(奖励的贴现总和)。状态动作/对的回报是:**
- 这次行动获得的报酬®
- 下一个状态/动作的返回,在下一个状态中选择下一个动作后获得,由其 Q 值近似

为什么经纪人要等剧集结束?他可以做以下事情:
- 从状态 S,根据 Q 值(以ε-贪婪的方式)选择一个动作( a
- 观察奖励( R )和新状态(S’)
- 再次选择一个动作( a’ ),观察它的 Q 值
- 使用这个新状态和动作的 Q 值作为剩余回报的近似**😗*

这里,出于稳定性原因,该值用α因子逐步更新。
这是对 SARSA 算法的描述。它使用自举技术,该技术在于使用下一个值的估计来估计该值(而不是等待整个剧集)。
下图说明了这三种技术是如何工作:

大卫·西尔弗的 RL 课程 第四讲 :“无模型预测”
TD-learning 和 Monte Carlo 混合存在,它们被归入 TD( λ) 族。
q 学习
SARSA 是一种基于策略的学习技术,这意味着它遵循自己的策略来学习价值函数。另一个想法是直接使用 next 的 Q 值的最大值来计算回报。
这被称为 Q-Learning,具体如下:
- 从状态 S,根据 Q 值(以ε-贪婪的方式)选择一个动作( a )
- 观察奖励( R )和新状态(S’)
- 使用下一状态的最大 Q 值来更新当前 Q 值:

因此,代理使用了最佳的可能 Q 值,即使他没有采取相应的行动。这是连贯的,因为他总是选择最佳行动来结束。因此,这有助于加快学习过程。
这被称为偏离策略学习,因为你不再使用当前遵循的策略来更新你的 Q 值函数(而是一个贪婪的策略)。
政策外学习有优点也有缺点,你可以在这里查阅。
函数逼近(神经网络)
当状态和动作的数量过多时,或者当在连续的环境中进化时(这意味着在计算机上是相同的),人们不能为每个可能的状态或状态-动作对创建一个价值函数。
因此,这个想法是使用函数逼近,如神经网络。然后将状态输入神经网络,并获得每个动作的 Q 值作为输出。因此,这是容易处理的,然后我们可以使用梯度上升技术将这个神经网络变成一个良好的 Q 值函数近似值,告诉我们为每张图像按下哪个按钮(或按钮组合)。

作者图片
使用近似法的一个明显的优点是,你可以得到相似状态的相似值(这似乎是一致的和有用的),但是我们将在下一篇文章中看到这一点。
致命的黑社会问题
致命的三位一体问题是这样一个事实,即自举、偏离策略学习和函数逼近的结合最终会导致很多不稳定,或者没有收敛。在下一篇文章中,我会解释为什么会发生这种情况以及如何处理。
描述统计学导论

约翰尼·麦克朗在 Unsplash 上的照片
对最基本和广泛使用的描述性统计方法有清晰和详细的理解
描述性统计对数据进行总结、展示和分析,使其更容易理解。如果数据集很大,从原始数据中很难看出任何意义。使用描述性统计技术,数据可以变得更加清晰,模式可能出现,一些结论可能是显而易见的。
但是描述性统计不允许我们得出超出分析部分的任何结论。它没有证实我们所做的任何假设。为此你需要学习推理统计学。我在这一页的末尾添加了一些研究推断统计学的链接。
有几种通用类型的统计方法来描述数据:
- 集中趋势的度量:平均值、中间值、众数
- 变异的度量:范围、标准偏差和四分位数范围
- 五个数摘要:第一个四分位数,第二个四分位数,第三个四分位数,最小值和最大值
- 数据的形状:对称、左偏和右偏。
在本文中,我将解释所有四种统计方法及其属性。
集中趋势测量
有三种常用的方法来表示数据集的中心。这些被称为集中趋势的度量。
它们是:
平均
中位数
方式
的意思是
这是最基本的。可能你们大多数人已经知道了。
我们计算平均值的方法是将所有值相加,然后除以值的个数。以下是一个数据集示例:
12, 18, 20, 16
平均值为= (12 + 18 +20 + 16)/4 = 16.5
数据集的平均值对极值敏感。例如,在上面的数据集中,如果还有一个这样的值:
12, 18, 20, 16, 150
平均值变为:
(12 + 18 +20 + 16 + 150)/5 = 43.2
因为一个值,平均值发生了剧烈变化。平均值变得比数据集的其余值大得多,除了 150。它并不代表整个数据集。
当数据集中存在极值时,平均值不能很好地代表整个数据集。
修整数据集的平均值将代表整个数据集。如果我们只是从上面的数据集中修剪极值数据 150,平均值将再次变为 16.5,并且它将再次表示数据集中的大部分数据。
修整极值是统计学和数据科学中的常用技术。
中值
在一组数值数据中,中位数是介于前 50%数据和后 50%数据之间的数据点。这是一个数据集,例如:
13, 19, 12, 21, 9, 15, 24, 11, 14
在找到中位数之前,我们需要对数据进行排序。对数据排序后,它变成:
9, 11, 12, 13, 14, 15, 19, 21, 24
中位数是中间点。在这个数据集中,它是 14。
如果我们还有一个数据,并且数据的数量和这个一样,那会怎么样呢?
9, 11, 12, 13, 14, 15, 19, 21, 24, 28
在这种情况下,中位数是两个中间值的平均值。
媒体是= (14 + 15)/2 = 14.5
让我们给这个数据集添加一个极值:
9, 11, 12, 13, 14, 15, 19, 21, 24, 28, 278
这个更新数据集的中位数是 15。
所以,中值对极值不敏感。
模式
众数是数据集中出现频率最高的值。
这是一个数据集示例:
23, 45, 34, 32, 45, 12, 23, 37, 45
这里 45 出现了 3 次,23 出现了 2 次,其余值出现了 1 次。所以,数据集的众数是 45。
如果所有数据在数据中只出现一次,则没有模式。
如果有更多的数字出现相同的次数,他们都是模式。如果上面的数据集被修改为:
23, 45, 34, 32, 45, 12, 23, 37, 45, 23
这里 45 和 23 都出现了 3 次。因此,23 和 45 都是数据集的模式。
如果所有数据在数据中只出现一次,则没有模式。
变化的度量
上面讨论的中心测量并不总是描述数据集和得出结论的最佳方式。比如说。这里有两个数据集:
数据 1:74,75,78,78,80
数据 2: 69,74,78,78,86
这些数据集的均值、中值和众数完全相同。请自己检查一下。
三种最常用的变化测量方法是:
范围
标准偏差
四分位间距
范围
数据集的范围是数据集的最大值和最小值之差。上面提到的数据 1 的范围是 6,数据 2 的范围是 17。所以,这给了我们更多关于数据集分布的视角。
标准差
标准差代表数据集与数据平均值的偏差。
计算这个要比前几个复杂一点。计算标准差的步骤如下:
第一步:计算平均值
第二步:取平均值的差值
第三步:取这些差值的平方并相加
第四步:将结果除以值的总数。这个数字被称为方差
第五步:求方差的平方根
标准偏差的公式如下:

让我们来算一个例子:
使用上面的数据 1:
数据 1:74,75,78,78,80
第一步:平均值= 77
**第二步和第三步:**我从平均值中取每个值的差,然后平方它们

计算后得出 24。
**第四步:**用这个数除以数据集中值的个数,得到方差。我们有五种价值观。所以,方差= 24/5 = 4.8。
**第五步:**取方差的平方根,得出标准差为 2.19。
如果对上面的 data 2(data 2:69,74,78,78,86)进行同样的处理,将得到 5.6。请随意自己尝试。
你可以看到标准差给出了数值分布的概念。换句话说,这些值是如何相互变化的。
数据集中的值变化越大,标准差就越大。
以下是一些与标准差相关的趋势:
- 对于钟形分布,99.7%的数据位于平均值两侧的 3 个标准偏差内
- 大约 95%的数据应该在平均值的 2 个标准偏差之内。
- 大约 68%的数据位于数据的一个标准偏差内。
请看这张来自维基百科的图片:

来源:维基百科
四分位数范围将在下面的“五个数摘要”部分解释,因为它与这五个数有关。
五个数摘要
这五个数字是:
第一个四分位数
将数据中最底层的 25%和最顶层的 75%分开。看看下面的例子。在下图中,Q1 是第一个四分位数。
第二个四分位数
第二个四分位数实际上是将数据中前 50%和后 50%分开的中间值。在下图中,Q2 代表第二个四分位数。
第三个四分位数
将后 75%的数据与前 25%的数据相除。Q3 代表下图中的第三个四分位数。
让我们看看这个例子。这是一个经过排序的数据集 d:
d = 33,36,38,40,41,44,49,53,56,61,66,71
这里有 12 个值。第一、第二和第三四分位数的位置如下:

让我们来计算一下。
第一个四分位数:(38 + 40)/2 = 38
第二个四分位数是:(44 + 49)/2 = 46.5
第三个四分位数是:(56 + 61)/2 = 58.5
你可能会想,我们这里有三个度量:第一、第二和第三四分位数。怎么是五数总结!
另外两个度量是最大值和最小值。
它们不言自明。我相信你知道它们是什么。
但是我们需要理解它们的含义。在此之前,我们需要了解一个更重要的术语。
即***【IQR】***。
IQR 是第三个四分位数(Q3)和第一个四分位数(Q1)之间的差值。所以,IQR 代表了中间 50%数据的变化。上述数据集的 IQR 为 58.5–38 = 20.5。
IQR 在确定极值或异常值时非常有用,我们在计算均值和中值时讨论过。
数据集的合理下限是
Q1-1.5 * IQR
数据集的合理上限是
Q3 + 1.5 * IQR
上述数据集 d 的下限是:
38–1.5 * 20.5 = 7.25
数据集 d 的上限是:
58.5 + 1.5* 20.5 = 89.25
如果您注意到,数据集中的所有值都在下限和上限的计算范围之间。因此,该数据集中没有异常值或极值。
数据的形状
数据的形状表示数据在整个范围内的分布。在统计学中有三种主要的分布类型。
对称
当低于平均值的值与高于平均值的值以相同的方式分布时,该分布称为对称分布。

这条曲线也就是我之前提到的钟形曲线。
对于对称形状的数据,平均值和中值是相同的
左倾
当大部分数据位于分布的上部时,数据集的形状是左偏的。
以下是 left_skewed 数据集的属性:
a.最小值和中值之差大于最大值和中值之差。
b.最小值和第一个四分位数之间的差值大于最大值和第三个四分位数之间的差值。
c.第一个四分位数和中位数之间的差异大于第三个四分位数和中位数之间的差异。

在左斜的形状中,尾巴位于左侧。
右倾
当大部分数据位于分布的较低部分时,该曲线是右偏曲线。
这些是右偏数据集的属性:
a.最小值和中值之差小于最大值和中值之差。
b.最小值和第一个四分位数之间的差值小于第三个四分位数和最大值之间的差值。
c.第一个四分位数和中位数之间的差值小于第三个四分位数和中位数之间的差值。

在右斜的形状中,尾巴位于右侧
结论
这些是描述性统计中最基本和最主要的度量类型。没有人再手工计算它们了。数据科学家或分析师使用 python 或 R 之类的编程语言来推导它们。这些参数每天都在研究、统计和数据科学中使用。所以,清楚地理解它们对理解数据是很重要的。
欢迎在推特上关注我,喜欢我的脸书页面。
更多阅读:
对统计学中一个非常流行的参数——置信区间及其计算的深入理解
towardsdatascience.com](/a-complete-guide-to-confidence-interval-and-examples-in-python-ff417c5cb593) [## 数据科学家使用 Python 进行假设检验的完整指南
用样本研究问题、解决步骤和完整代码清楚地解释
towardsdatascience.com](/a-complete-guide-to-hypothesis-testing-for-data-scientists-using-python-69f670e6779e) [## 使用直方图和箱线图理解数据,并举例说明
了解如何从直方图和箱线图中提取最多的信息。
towardsdatascience.com](/understanding-the-data-using-histogram-and-boxplot-with-example-425a52b5b8a6) [## 熊猫数据可视化的终极备忘单
熊猫的所有基本视觉类型和一些非常高级的视觉…
towardsdatascience.com](/an-ultimate-cheat-sheet-for-data-visualization-in-pandas-4010e1b16b5c) [## 想在 12 周内成为数据科学家?
花钱前再想一想
towardsdatascience.com](/want-to-become-a-data-scientist-in-12-weeks-3926d8eacee2) [## 成为数据科学家的一系列免费课程
链接到知名大学的高质量课程,可以免费学习。循序渐进地学习这些课程,以…
towardsdatascience.com](/series-of-free-courses-to-become-a-data-scientist-3cb9fd591739)
不变矩及其在特征提取中的应用
通过真实代码理解概念

雅各布·欧文斯在 Unsplash 上的照片
介绍
首先要明白什么是不变量,什么是矩分别?在图像处理中,不变量(I)是图像的一个属性(在这种情况下是一个函数),如果我们对图像进行变换(旋转、缩放、模糊等),这个属性不会改变或者只改变一点点。
如果 D 是退化算子(图像的变换函数),f(x,y)是原始图像(其中 x 和 y 是图像的像素坐标,f 的输出是像素的强度),则

(1)
通常,不变量被写成一个向量

(2)
其中 n 是我们应用于图像的变换次数。在理想条件下,给定(1 ),那么如果我们映射来自图像数据集的所有不变向量,我们将发现不同对象的不同群集,因为不同对象具有显著不同的 I 值。
不变量有很多种,每一种都有一组不同转换函数。我们都知道图像最基本的变换是旋转、缩放、平移等。不变矩是不变方法之一。它利用了某种特殊的瞬间功能。
矩(m)是函数(图像,f(x,y))到多项式基或多项式形式的投影。

(3)
其中 X 和 Y 是图像在 X 轴和 Y 轴上的总像素。力矩®的阶数定义为

(4)
I 和 j 的一些组合具有直观的意义,例如
- m0,0 是图像的质量。

(5)
**它只是所有像素强度的总和。**如果图像只是一个纯黑色(这里我们认为完美的黑色像素= 0,白色= 1),那么质量为 0。
- m1,0/m0,0 和 m0,1/m0,0 是图像的重心。

(6)

(7)
比如一张大小为 20x20 的纯白图像,图像的重心在哪里?让我们编写代码来解决这个问题,因为图像是一个普通图像,图像的形状是正方形,那么 m1,0/m0,0 和 m0,1/m0,0 是相同的。
而的结果是 10.5 所以重心在(10.5,10.5) 。这是有道理的,一个扁平的矩形物体应该有一个重心在中间。
还有很多。中心力矩(μ)定义为

(8)
其中 x '和 y '是图像在 x 轴(m1,0/m0,0)和 y 轴(m0,1/m0,0)上的重心。所以很明显

(9)
然后归一化中心矩(η)定义为

(10)
其中λ是

(11)
不变矩有 7 个矩(ɸ),它们是使用归一化中心矩定义的,例如

(12)

(13)

(14)

(15)

(16)

(17)

(18)
我们可以将这 7 个矩(12–18)视为不变矩的 7 个特征。
特征抽出
让我们用(12–18)公式来测试等式(1)。例如,我们有这个手写的数字 2(来自 MNIST 数据集)。

angka.png
我们旋转了图片所以我们会得到

angka_rotated.png

angka_rotated2.png

angka_rotated3.png
在这种情况下,旋转图片是一个退化操作符(D) 。让我们用(12-18)来计算它们的不变矩。这是代码
对所有图像(原始图像和所有旋转后的图像)运行此代码,结果是

让我们计算原始图像angka.png与所有其他图像之间的欧几里德距离(d)。欧几里德距离的值越小,根据不变矩值物体与原始物体越相似。如果数据有 N 维(在这种情况下,我们有 7 个矩,所以有 7 维),那么

(19)
其中p bar(本例中为angka.png)为参考点,p为点。结果是

看起来最接近原始图像的值是我们将它旋转 180 度时的版本。
我们仍然不知道在这个实验背景下“相似的”ɸ有多大。我们需要比较值。让我们检查另一个数字。我们要试试 6 码的。

6.png
这个对比是

如果你注意,它看着 phi 5 到 phi 7 它的值总是相似的(接近 0)。甚至不同的数字6.png也有相似的值。
他们的欧几里德距离是

在上表中,您可以看到6.png 与原始图像相比具有明显的不变矩值,并且它是旋转变量。
让我们在数据集中选取另一个数字 2。

2.png
它的不变矩值是

从这个比较中,我们得到angka.png和2.png之间的d的值是0.080392465667106。它仍然比6.png小,这证明了**2.png** 比 **6.png** 与原始图像更相似。在这种情况下,不变矩成功地区分了基于(1)中的定义给出的样本图像。
关闭
这就是我们如何利用不变矩从图像中提取特征。下一篇文章也许我会试着用不变矩来分类一张图片。另一篇文章再见。
参考
马,岳超&李,思宁&陆,魏。(2018).基于支持向量机的部分扫描低空风切变识别。机械工程进展。10.168781401775415.10.1177/1687814017754151.
http://zoi.utia.cas.cz/files/chapter_moments_color1.pdf 于 2020 年 7 月 23 日进入
R 时间序列分析导论

克里斯·利维拉尼在 Unsplash 上的照片
从探索,到预测。使用印度尼西亚 2002 年 12 月至 2020 年 4 月的消费者价格指数(CPI)数据
时间序列数据是以固定的时间间隔观察到的数据,可以每天、每月、每年等进行测量。时间序列有很多应用,特别是在金融和天气预报方面。在本文中,我将向您介绍如何使用 r 分析和预测时间序列数据。对于数据本身,我将为您提供一个来自印度尼西亚银行 2002 年 12 月至 2020 年 4 月的消费者价格指数(CPI)数据的示例。
行动(或活动、袭击)计划
在我们开始分析之前,我会告诉你我们必须做的步骤。步骤是这样的,
- 首先,我们必须收集和预处理数据,并且,我们应该知道我们使用的数据的领域知识,
- 然后,我们对时间序列进行可视化和统计分析,
- 然后,我们基于其自相关性识别完美模型,
- 然后,我们诊断模型是否满足独立性假设,最后,
- 我们可以用这个模型来做预测
预处理数据
如前所述,我们将对印度尼西亚 2002 年 12 月至 2020 年 4 月的 CPI 数据进行时间序列分析。我们可以从印尼银行得到数据。不幸的是,我们必须首先将数据从网站复制到电子表格中,然后从中生成一个. csv 数据。数据在我们导入后是这样的,
library(tidyverse)
data <- read.csv("data.csv")
colnames(data) <- c("Time", "InflationRate")
head(data)

在进行分析之前,我们必须先对其进行预处理。尤其是在“InflationRate”列中,我们必须删除“%”符号并将其转换为数字类型,如下所示,
**# Pre-process the data**
data$InflationRate <- gsub(" %$", "", data$InflationRate)
data$InflationRate <- as.numeric(data$InflationRate)
data <- data[order(nrow(data):1), ]
tail(data)
然后,我们得到的数据会像这样,

这样,我们可以使用 ts 函数从“InflationRate”列创建一个时序对象
cpi <- ts(data$InflationRate, frequency = 12, start = c(2002, 12))
有了 cpi 变量,我们可以进行时间序列分析。
分析
首先,我们来介绍一下居民消费价格指数(CPI)。CPI 是衡量消费品在其基年的某一时刻的价格变化的指数。公式看起来像这样,

公式
每个月都会测量每个 CPI 值。这是代码和代码结果的图表,
library(ggplot2)**# Make the DataFrame**
tidy_data <- data.frame(
date = seq(as.Date("2002-12-01"), as.Date("2020-04-01"), by = "month"),
cpi = cpi
)
tidy_data**# Make the plot**
p <- ggplot(tidy_data, aes(x=date, y=cpi)) +
geom_line(color="red", size=1.1) +
theme_minimal() +
xlab("") +
ylab("Consumer Price Index") +
ggtitle("Indonesia's Consumer Price Index", subtitle = "From December 2002 Until April 2020")
p**# Get the statistical summary
# Returns data frame and sort based on the CPI** tidy_data %>%
arrange(desc(cpi))
tidy_data %>%
arrange(cpi)

根据图表,我们看不到任何趋势或季节性模式。尽管它看起来是季节性的,但每年的高峰期不在同一个月,所以它不是季节性的。然后,这个图也没有增加或减少的趋势。因此,此图是静态的,因为数据的统计属性(如均值和方差)不会因时间而产生任何影响。
除了图表之外,我们还可以从数据中测量统计摘要。我们可以看到最大的通货膨胀发生在 2005 年 11 月,CPI 为 18.38。然后,最小通货膨胀发生在 2009 年 11 月,CPI 为 2.41。有了这些信息,我们可以得出结论,这些数据没有季节性模式。
模型识别
在我们分析了数据之后,我们就可以根据数据进行建模。在这种情况下,我们将考虑两种模型,即自回归(AR)模型和移动平均(MA)模型。在使用模型之前,我们必须根据数据的自相关性确定哪个模型最适合数据,哪个滞后适合模型。为了识别这一点,我们将制作自相关函数(ACF)图和部分自相关函数(PACF)图,如下图所示,这是代码。
acf(cpi, plot = T, main = "ACF Plot of CPI", xaxt="n")
pacf(cpi, plot = T, main = "ACF Plot of CPI", xaxt="n")


左:ACF 图,右:PACF 图
根据上面的图,我们如何为这些数据选择完美的模型。要在 AR 和 MA 模型之间进行选择,我们可以看到下面的总结:

情节解读
该总结指出,如果 ACF 曲线在滞后 p 之后变窄,PACF 曲线截止到接近 0,则 AR§将符合模型。然后,如果 ACF 曲线在滞后 Q 之后截止到接近 0,并且 PACF 曲线变窄,则 MA(q)模型将符合模型。如果两个图都是拖尾,那么我们可以用 ARMA(p,q)模型来拟合。对于那些仍然对 tail off 和 cut off 感到困惑的人来说,tail off 意味着值逐渐减小,而不是下降到接近 0。那么截止意味着自相关在前一个滞后之后降低到接近 0。
基于该信息,我们可以看到 ACF 图逐渐减小(变小),并且 PACF 图在滞后-1 之后减小到接近 0。因此,对于这个模型,我们将在下一步使用 AR(1)模型。
模型诊断
为了确保该模型可以用于预测和其他测量,我们必须使用 Ljung 盒测试来测试该模型。下面是实现这一点的代码,
library(FitAR)
acf(ar1$residuals)
res <- LjungBoxTest(ar1$residuals, k=2, StartLag=1)
plot(res[,3],main= "Ljung-Box Q Test", ylab= "P-values", xlab= "Lag")
qqnorm(ar1$residuals)
qqline(ar1$residuals)



左:Q 测试图,中:残差自相关,右:QQ 图
根据这些图,我们可以看到 Q-test 图的 p 值高于 0.05,ACF 图显示另一个滞后之间没有显著性,最后,我们可以看到 QQ 图几乎符合直线,因此我们可以假设这已经是正常的。因此,我们可以用模型来做预测。
预测
在我们建立模型并进行测试之后,现在我们可以使用下面的代码进行预测,
library(forecast)
futurVal <- forecast(ar1, h=10, level=c(99.5))
plot(futurVal)
这是结果,

结论
预测是我能给你看的最后一部作品。我希望,通过这个时间序列分析的学习案例,你可以根据你的问题进行时间序列分析。这篇文章只是展示了如何进行分析的基本原理,而不是解决使用 ARIMA 模型和我使用的静态数据的问题。我希望我能在以后与你分享如何分析非平稳时间序列数据。
参考文献
[1]查特吉,s .,时间序列分析使用 ARIMA 模型在 R (2018),datascienceplus.com。
【2】hynd man,r . j .&Athanasopoulos,G. (2018) 预测:原理与实践 ,第二版,OTexts。
感谢您阅读我的文章,您也可以在下面查看我以前的文章:
我们可以定量地衡量机器学习模型的性能,但不仅仅是准确性,还有很多…
towardsdatascience.com](/greater-accuracy-does-not-mean-greater-machine-learning-model-performance-771222345e61) [## 如果我有自己的时间,我会这样学习数据科学
感觉不知所措和筋疲力尽让我在释放数据科学技能方面表现不佳。这个…
towardsdatascience.com](/this-is-how-i-will-learn-data-science-if-i-got-back-my-own-time-e9148c909ce9) [## 用 R 整理数据
为什么你应该在它上面投资更多,为什么这使你的分析变得容易得多
towardsdatascience.com](/tidy-data-with-r-f3d078853fc6)
时间序列预测简介
介绍时间序列,以及与时间序列分析和预测相关的基本概念和建模技术。

作者图片
时间序列预测是机器学习的重要领域之一。当涉及到时间成分的预测问题时,这是非常重要的。
这些天我在做基于时间序列分析和预测的项目任务。所以,我在这个领域做了一些研究,认为这将对我和那些开始时间序列预测的人有益,以一些记录的方式做出那些发现。
本文的目的是介绍时间序列,以及与时间序列分析和预测相关的基本概念和建模技术。
什么是时间序列?
时间序列可以被定义为在规则的时间间隔内记录的一系列指标。根据频率的不同,时间序列可以是每年、每季度、每月等。
时间序列与常规回归问题有两点不同。第一个是时间相关的。在线性回归模型中,观察值是独立的,但是在这种情况下,观察值依赖于时间。还有**季节性趋势,**特定于特定时间范围的变化。
时间序列预测有两种方法。
- 单变量时间序列预测:只有两个变量,一个是时间,一个是预测的领域。
- **多元时间序列预测:**包含多个变量,其中一个变量为时间,其他变量为多个参数。
在进行时间序列分析时,需要考虑一些特殊的特征。他们是,
1。趋势
趋势显示数据随时间增加或减少的总体趋势。
2.季节性
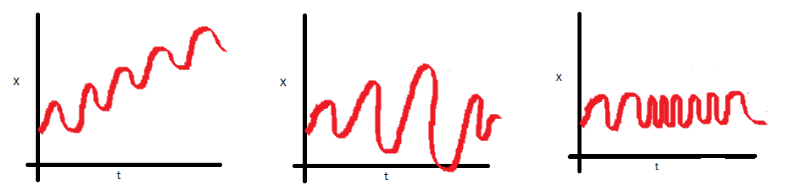
时间序列中的季节性是在 S 个时间段内重复的规则变化模式,其中 S 定义了该模式重复之前的时间段数。
举个例子,我们想想几年后的冰淇淋销量,会出现夏季销量高,冬季销量低的情况。因此,这种模式会在特定的年份重复出现。所以 S 应该是 12。

图片鸣谢:https://I2 . WP . com/radacad . com/WP-content/uploads/2017/07/trend seasonal . png
3.静止的
平稳性是指时间序列的统计特性,即均值、方差和协方差不随时间变化。

图片鸣谢:https://cdn . analyticsvidhya . com/WP-content/uploads/2018/09/ns5-e 1536673990684 . png
- 在第一个图中,平均值随时间变化(增加),导致上升趋势。
- 在第二个图中,序列中没有趋势,但是序列的方差是随时间变化的。
- 在第三个图中,随着时间的增加,分布变得更接近,这意味着协方差随时间而变化。

图片鸣谢:https://cdn . analyticsvidhya . com/WP-content/uploads/2018/09/ns6-e 1536674898419 . png
在该图中,所有三个属性都是随时间恒定的,就像平稳时间序列一样。
我们可以用几种方法来识别时间序列是否平稳。
- 视觉测试,简单地通过查看每个情节来识别系列。
- ADF (Augmented Dickey-Fuller)测试,用于确定数列中单位根的存在。
- **KPSS(科维亚特科夫斯基-菲利普斯-施密特-申)**测验
通过差分使时间序列平稳
为了使用时间序列预测模型,首先,我们需要将任何非平稳序列转换为平稳序列。一种方法是使用差分法。简单地执行差分来去除变化的平均值。
在这种方法中,当前值减去前一个值。时间序列的复杂性导致需要进行多次差分来消除季节性。
季节差异是一个值和一个滞后值之间的差异,滞后值是 S 的倍数。
差分的正确顺序是获得近似平稳序列所需的最小差分,该序列大致具有恒定的平均值。并且 ACF 图尽可能快地达到零。
4.白噪声

简单地说,“白色”意味着所有频率都被同等地表示,“噪声”是因为没有模式,只是随机变化。
如果一个时间序列的均值为零,方差不变,滞后之间的相关性为零,那么它就是一个白噪声。高斯白噪声、二进制白噪声和正弦白噪声是白噪声的例子。
接下来,让我们看看什么是 ACF 和 PACF 图。
自相关函数

作者图片
这概括了两个变量之间关系的强度。为此,我们可以使用皮尔逊相关系数。
皮尔逊相关系数是介于-1 和 1 之间的数字,分别表示负相关或正相关。
我们可以计算时间序列观测值与先前时间步长的相关性,称为滞后。因为相关性是用以前同一系列的值计算的,所以这被称为序列相关或自相关。
滞后时间序列的自相关图称为相关图或自相关图。
部分自相关函数

作者图片
PACF 描述了一个观察和它的滞后之间的直接关系。它通过去除中间观测值之间的关系来总结时间序列中的观测值与先前时间步的观测值之间的关系。
观测值和前一时间步观测值的自相关由直接相关和间接相关组成。这些间接相关性由在中间时间步长的观测相关性的线性函数组成。部分自相关函数消除了这些间接相关性。
现在,让我们讨论一些用于时间序列预测的模型。
AR 模型
自回归(仅 AR)模型是一种仅依赖于自身滞后的模型。

图片鸣谢:https://www . machine learning plus . com/WP-content/uploads/2019/02/Equation-1-min . png
马模型
移动平均模型是一种仅依赖于滞后预测误差的模型,即各滞后的 AR 模型的误差。

ARMA 模型
自回归-移动平均过程是分析平稳时间序列的基本模型。ARMA 模型是关于 AR 和 MA 模型的融合。
AR 模型解释了动量效应和均值回复效应,MA 模型捕捉了白噪声条件下观察到的冲击效应。这些冲击效应可以被认为是影响观察过程的意外事件,如意外收入、战争、攻击等。
ARIMA 模型
A uto- R 过度IintegratedMovingAverage 又名 ARIMA 是一类基于其自身滞后和滞后预测误差的模型。任何显示模式且不是随机白噪声的非季节性时间序列都可以用 ARIMA 模型建模。
ARIMA 模型有三个特征:
- p 是 AR 项的阶数,其中 Y 的滞后数用作预测值
- q 是 MA 项的顺序,滞后预测误差的数量应达到该顺序。
- d 是使数列平稳所需的最小差分数。

萨里玛模型
在季节性 ARIMA 模型中,季节性 AR 和 MA 项使用数据值和误差进行预测,滞后时间是 m(季节性跨度)的倍数。

图片来源:https://miro.medium.com/max/875/0*7QNGRNyQreHmHkQp.png
非季节性术语(p,d,q) :可以用 ACF 和 PACF 图来表示。通过检查早期滞后的尖峰,ACF 指示 MA 项(q)。同样,PACF 表示 AR 项§。
季节术语(P、D、Q 和 m) :针对这种需要,检验滞后为 m 倍数的模式。大多数情况下,前两三个季节倍数就足够了。以同样的方式使用 ACF 和 PACF。
除了上面讨论的模型,还有一些模型,如向量自回归(VAR),ARCH/GARCH 模型,LSTMs 等。
结论
时间序列分析最重要的用途是它帮助我们根据过去预测一个变量的未来行为。所以,希望你对什么是时间序列,以及时间序列分析的基本概念有一个基本的了解。以及 AR、MA、ARIMA 和萨里玛模型的直觉。
感谢您的阅读!
参考
[1] N. Tyagi,I 时间序列分析导论:时间序列预测机器学习方法&模型 (2020),Analyticssteps.com
[2] S. Prabhakaran,machinelearningplus.com ARIMA 模型——用 Python 编写的时间序列预测完全指南
[3] J. Brownlee 、、自相关和偏相关的温和介绍 (2017),机器学习掌握
[4] J. Brownlee,白噪声时间序列与 Python (2017),机器学习掌握
[5] J. Brownlee,如何用 Python 创建时间序列预测的 ARIMA 模型 (2017),机器学习掌握
[6]奥泉,金融数据时间序列分析四 — ARMA 模型(2017),medium.com/auquan
迁移学习简介
从零开始学习迁移的综合指南

介绍
我们人类有能力将在一项任务中获得的知识转移到另一项任务中,任务越简单,利用知识就越容易。一些简单的例子是:
- 懂数学统计→学机器学习
- 知道如何骑自行车→学习如何骑摩托车
到目前为止,大多数机器学习和深度学习算法都是为了解决特定的任务而设计的。如果任何分布发生变化,这些算法都要重新构建,并且很难重新构建和重新训练,因为这需要计算能力和大量时间。
迁移学习是关于如何使用一个预先训练好的网络,并将其应用到我们的定制任务中,将它从以前的任务中学到的东西进行迁移。
迁移学习是我们采用 VGG 16 和 ResNet 等架构的地方,这些架构是许多架构和大量超参数调整的结果,基于他们已经了解的内容,我们将这些知识应用于新的任务/模型,而不是从零开始,这称为迁移学习。
一些迁移学习模型包括:
- 例外
- VGG16
- VGG19
- Resnet,ResnetV2
- InceptionV3
- MobileNet
利用迁移学习实现医学应用
在这个应用程序中,我们将检测这个人是否患有肺炎。我们使用 Kaggle 数据集进行分类。下面给出了数据集和代码的链接。
数据集链接:
5,863 张图片,2 个类别
www.kaggle.com](https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia)
代码链接:
permalink dissolve GitHub 是超过 5000 万开发人员的家园,他们一起工作来托管和审查代码,管理…
github.com](https://github.com/ajaymuktha/DeepLearning/blob/master/TransferLearning/transfer-learning.ipynb)
数据集由训练集和测试集组成,子文件夹为 normal 和 pneumonia。肺炎文件夹包含患有肺炎的人的胸部 x 光图像,而正常文件夹包含正常人的图像,即没有肺部疾病。
安装 Tensorflow
如果你的 PC 或笔记本电脑没有 GPU,你可以使用 Google Colab,或者使用 Jupyter Notebook。如果您使用您的系统,请升级 pip,然后安装 TensorFlow,如下所示

tensorflow.org
导入库
调整图像大小
在这里,我们将所有的图像调整到 224224,因为我们使用 VGG16 模型,它接受 224224 大小的图像。
训练和测试路径
我们将为培训指定培训和测试路径。
导入 VGG16
这里,我们将为我们的应用程序导入 VGG16 模型权重。我们应该为模型声明一个图像大小,我们已经在上一步中完成了,参数 3 表示图像将接受 RGB 图像,即彩色图像。为了训练我们的模型,我们使用 imagenet 权重和 include_top = False 意味着它将从模型中移除最后几层。
训练层
像 VGG16、VGG19、Resnet 和其他模型已经在成千上万的图像上被训练,并且这些权重用于分类成千上万的类,所以我们使用这些模型权重来分类我们的模型,所以我们不需要再次训练模型。
班级数量
我们使用 glob 来找出我们模型中的类的数量。train 文件夹中的子文件夹数量代表了模型中的类数量。
变平
无论我们从 VGG16 得到什么输出,我们都要将其展平,我们从 VGG16 中移除了最后的层,以便我们可以保留自己的输出层。我们用问题陈述中的类别数替换最后一层。我们认为 softmax 是我们的激活函数,我们把它附加到 x 上。
模型
我们将它包装成一个模型,其中输入指的是我们从 VGG16 获得的内容,输出指的是我们在上一步中创建的输出层。
模型摘要

上图是我们模型的总结,在密集层中,我们有两个节点,因为我们有两个不同的类别肺炎和正常。

Justino Neto 在 Unsplash 上拍摄的照片
编制
我们使用类别交叉熵作为损失,adam 优化器和准确性作为度量来编译我们的模型。如果你不知道这些术语的意思,我会在文章的最后提到我博客的链接,在那里我会清楚地解释所有这些术语。
预处理
我们将在训练图像上应用一些变换以避免过度拟合,如果我们不执行,我们将在训练集和测试集的准确性之间得到很大的差异。
我们执行一些几何变换,如水平翻转图像,垂直翻转,放大,缩小和许多其他可以执行的操作,我们应用它,这样我们的模型就不会过度学习我们的训练图像。我们使用 ImageDataGenerator 类执行上述方法。
我们不为测试集应用变换,因为我们只使用它们来评估,对我们的测试集做的唯一任务是重新缩放图像,因为在训练部分,我们定义了可以馈入网络的图像的目标大小。
flow_from_directory 将把图像增强过程连接到我们的训练集。我们需要提到我们的训练集的路径。目标尺寸是应该输入神经网络的图像尺寸。批次大小被定义为一个批次中图像的数量,类别模式是明确的,因为我们只有两个输出。
现在我们定义从目录中导入测试图像的测试集。我们定义的批量大小、目标大小和班级模式与训练集中提到的相同。
符合模型
我们将拟合我们的模型,并将时期的数量声明为 5,每个时期的步骤将是训练集的长度,验证步骤将是测试集的长度。

太棒了,我们达到了大约 97.7%的准确率和 91.5%的验证准确率,这就是迁移学习的力量。希望你喜欢这篇关于迁移学习的教程。如果你想知道人工神经网络和卷积神经网络如何与应用一起工作,请查看我下面的博客:
你深度学习的第一步
towardsdatascience.com](/introduction-to-artificial-neural-networks-ac338f4154e5) [## 用 Tensorflow 构建人工神经网络
如何使用 TensorFlow 构建神经网络的分步教程
towardsdatascience.com](/building-an-ann-with-tensorflow-ec9652a7ddd4) [## 卷积神经网络简介
关于卷积神经网络如何工作的直觉
medium.com](https://medium.com/dataseries/introduction-to-convolutional-neural-networks-5a227f61dd50) [## 使用张量流的图像分类器
如何创建图像分类器的分步指南
towardsdatascience.com](/image-classifier-using-tensorflow-a8506dc21d04)
Python 中趋势过滤及其应用简介
从嘈杂的时间序列数据中揭示潜在趋势
内容
- 趋势过滤简介
- 趋势滤波背后的最小化问题
惠普之间的区别& L1 趋势滤波 - Python 中新加坡 COE 保费的应用趋势过滤
简介
最近,我一直在做一个项目,涉及一些量化投资策略的时间序列建模。具体而言,该战略的一个关键组成部分涉及为不同的制度制定不同的投资方法。这种识别是有用的,因为当金融市场的基本动态发生变化时,在一种制度下行之有效的策略可能在另一种制度下也行不通。
举个简单的例子,众所周知,当市场陷入困境时,资产类别相关性往往会显著增加。因此,在资产配置中考虑协方差的模型将不得不相应地改变它们的假设,这必然会影响最优的投资组合配置。为了制定差异化战略,人们可以简单地识别金融市场中的两种不同机制:扩张和收缩。
为了使这种方法有用,基于制度的投资策略,尤其是中长期投资策略,需要解决两个问题:
- 需要考虑哪些相关制度?
- 我们如何根据这些制度划分不同的时间段?
一个简单而有效的制度分类是将一个时间序列分成上升期和下降期。事实上,Mulvey&Han*(2016)*在他们的论文 识别经济体制:降低大学捐赠基金的下行风险&基金会 *中应用了这一方法。*通过进行蒙特卡罗模拟并在季度基础上确定“增长”和“收缩”制度,他们能够证明根据制度类型调整支出规则的改进的最优性,这主要通过对下行风险的积极和动态管理来实现。
然而,金融时间序列往往非常嘈杂,为了实现稳健的季度到季度制度识别,平滑是必要的。这就是趋势过滤的用武之地。
趋势过滤
趋势过滤的目标是通过过滤掉“噪音”来平滑时间序列。趋势过滤算法面临两个目标之间的权衡。首先,它希望最小化实际序列和平滑序列之间的残留“噪声”。把这想象成算法想要尽可能真实地保持原始序列。第二,它希望最大化过滤序列的平滑度,这往往与第一个目标相矛盾。
在数学上,我们的目标是最小化以下目标函数:

H-P 滤波目标函数
y 是实际时间序列,而 x 是估计的滤波时间序列。损失函数的第一部分代表最小化实际序列和拟合序列之间残差平方和的目标。损失函数的第二部分表示对平滑度的要求。Dx 捕捉每组三个点之间的平滑度。

平滑度惩罚的三维矩阵
最后,𝜆是正则化参数。可以把它看作是在我们最小化残差和最大化平滑度这两个目标之间进行权衡。我们将在后面看到𝜆如何影响过滤趋势的例子。
到目前为止展示的模型描述了趋势过滤的 Hodrick-Prescott (H-P) 版本。或者,我们可以采用 L1 趋势滤波。关键的区别是平滑的惩罚,这是从 L2 改为 L1 规范。对于那些熟悉回归的人来说,这类似于正则化套索和岭回归之间的区别。像 H-P 滤波一样,L1 滤波也有助于平滑时间序列。结果的关键区别在于,L1 滤波产生了对潜在趋势的分段线性估计。当我们稍后看应用的例子时,这将变得清楚。
数学上,目标函数现在变成:

L1 滤波目标函数
正如 L1 趋势过滤的作者解释的那样:
估计趋势斜率的扭结、打结或变化可被解释为时间序列潜在动态的突变或事件。
Mulvey & Han 实际上应用了 L1 趋势滤波算法来平滑他们的财务时间序列,这可以说更适合于季度之间的体制识别和体制变化的情况。
一个应用实例:新加坡 COE 保险费
为了说明趋势过滤的实际作用,并理解 L1 趋势过滤和惠普趋势过滤之间的区别,让我们考虑一下新加坡 COE 保费的时间序列。我正在进行的一个项目是使用多变量 LSTMs 来了解新加坡 COE 保费的动态,因此我认为使用这个时间序列来提供趋势过滤的简单介绍会很有趣。
对于下面的例子,我把保费记录作为基本的时间序列。
Python 实现
import pandas as pd
import numpy as np
import cvxpy
import scipy
import cvxopt
import matplotlib.pyplot as plty = pd.read_csv('coe_premium.csv')
y = y['premium'].to_numpy()
y = np.log(y)n = y.size
ones_row = np.ones((1, n))
D = scipy.sparse.spdiags(np.vstack((ones_row, -2*ones_row, ones_row)), range(3), n-2, n)
对于那些不熟悉 spdiags 的人,请参考文档 这里 了解更多细节。
在上面的代码中,我已经导入了底层的时间序列并转换为日志。然后,我定义了作为构建损失函数/目标函数的一部分的 D 矩阵。
如果您想要一份’ coe_premium.csv '文件的副本来亲自尝试,请随时与我联系以获取副本,因为它实际上是我用于训练神经网络的公共数据的工程和插值版本。
我定义了一个𝜆列表进行实验,这样我们可以看到参数对估计的过滤趋势的影响。
lambda_list =
[0, 0.1, 0.5, 1, 2, 5, 10, 50, 200, 500, 1000, 2000, 5000, 10000, 100000]
最后,我遍历𝜆的列表,首先估计过滤后的趋势,并并排绘制结果,以查看改变𝜆:的影响
solver = cvxpy.CVXOPT
reg_norm = 2fig, ax = plt.subplots(len(lambda_list)//3, 3, figsize=(20,20))
ax = ax.ravel()ii = 0for lambda_value in lambda_list: x = cvxpy.Variable(shape=n) # x is the filtered trend that we initialize objective = cvxpy.Minimize(0.5 * cvxpy.sum_squares(y-x)
+ lambda_value * cvxpy.norm(D@x, reg_norm)) # Note: D@x is syntax for matrix multiplication problem = cvxpy.Problem(objective)
problem.solve(solver=solver, verbose=False) ax[ii].plot(np.arange(1, n+1), y, , linewidth=1.0, c='b')
ax[ii].plot(np.arange(1, n+1), np.array(x.value), 'b-', linewidth=1.0, c='r')
ax[ii].set_xlabel('Time')
ax[ii].set_ylabel('Log Premium')
ax[ii].set_title('Lambda: {}\nSolver: {}\nObjective Value: {}'.format(lambda_value, prob.status, round(obj.value, 3))) ii+=1
plt.tight_layout()
plt.savefig('results/trend_filtering_L{}.png'.format(reg_norm))
plt.show()
就是这样!cvxpy 库为你做了大部分的优化工作,所以你所需要的只是这几行代码。
也就是说,选择正确的参数更像是一门艺术,而不是一门科学,这真的取决于你试图解决什么问题。因此,搜索不同的参数以了解模型输出如何相应地变化,并选择最适合您的项目目的的正则化通常很有用。
这些是惠普趋势过滤的可视化:

惠普趋势过滤结果
从上面的可视化中,我们可以看到,随着参数𝜆从 0 增加到 100,000,算法的优先级从很好地拟合原始时间序列转移到获得趋势的更平滑版本。当𝜆处于其最大值时,该算法主要集中在平滑序列上,它只是为整个序列估计一条直线(最平滑的)。另一方面,当𝜆 = 0 时,该算法完全忽略平滑,并给我们原始时间序列以最小化残差。
要获得上述过程的 L1 版本,我们只需更改以下内容:
solver = cvxpy.ECOS
reg_norm = 1
由于超出本文范围的原因,优化器(变量解算器)必须改变,因为不同的优化器处理不同类型的优化问题。
这些是 L1 趋势过滤的结果:

L1 趋势过滤结果
当我们比较 L1 趋势滤波和 H-P 趋势滤波的结果时,我们注意到三个关键结果。首先,就像在 H-P 趋势滤波中一样,增加𝜆增加了估计趋势的平滑度。第二,与 H-P 趋势滤波器不同,在估计的时间序列中有更明显的扭结,或突然更剧烈的变化。如前所述,这是因为我们改变了平滑的惩罚。这一结果背后的数学原理超出了本次讨论的范围,但对于感兴趣的人,可以在 L1 趋势过滤中找到。第三,我们注意到,当我们增加𝜆.值时,该算法比 H-P 趋势滤波更快地达到“直线”估计趋势
我希望这份关于趋势过滤的温和实用的介绍对那些对时间序列分析和预测感兴趣的人有用!
数据科学线性代数 Ep1 使用 Python 的向量和矩阵简介
数据科学线性代数的主要组成部分入门

现在,我们已经为学习数据科学的数学奠定了基础,是时候开始学习系列的第一个主题线性代数了。这篇文章是线性代数系列的第一篇,在这篇文章中,我介绍了我们将来会用到的代数的基本组成部分。它短小精悍,重点突出。
您也可以在此按部就班地关注我:
我们将在本帖中讨论的主题:
- 标量、向量、矩阵和张量的重要定义和符号。
- 使用NumPy创建矢量和矩阵。
- 转置一个矩阵(2D 阵列)并对它们进行编码。
- 使用 NumPy 在矩阵中加法和广播
那么,让我们开始吧…
重要的定义和符号

来自 L-R:标量、向量、矩阵和张量
**标量:**任何单个数值都是标量,如上图所示。它只是用小写和斜体表示。例如:*n*
**向量:**数字(数据)数组是一个向量。您可以假设数据集中的一列是一个特征向量。

特征向量 x
向量通常用小写、斜体和粗体类型的变量(特征)名称来表示。比如:***x***
**矩阵:**矩阵是一个形状为 (m×n) 的二维数组,有 m 行 n 列。

m 行 n 列的矩阵
每个元素都可以通过它的行和列到达,并用下标表示。例如,A₁,₁返回第一行第一列的元素。
矩阵用大写、斜体和粗体的变量名表示。比如:***A***
**张量:**一般来说,一个 n 维数组,其中 n > 2 称为张量。但是矩阵或向量也是有效的张量。
使用 NumPy 创建向量和矩阵
现在我们知道了它们是如何定义的,让我们看看我们将如何使用 NumPy 来查看我们的数学运算。如果你想知道为什么是 NumPy 或者你需要一个关于 NumPy 的复习,请查看下面的链接:
帮助您掌握正确的 Numpy 主题以开始数据科学的参考指南
towardsdatascience.com](/numpy-essentials-for-data-science-25dc39fae39)
因为 vector 是一个数组,NumPy 有各种创建数组的方法。首先,安装 NumPy 并将其导入您的工作区/环境:
import numpy as np
然后创建一个数组需要你从库中使用array()方法:

然后,您可以使用shape属性检查数组的形状:

创建一个矩阵也很简单,你只需要将一个 2D 列表传递给数组方法:

转置一个矩阵(2D 阵列)并对它们进行编码
转置一个矩阵成为一个非常重要的话题,因为它进一步有助于计算矩阵的逆矩阵和其他数据操作,其中你想要镜像你的数据帧的轴。
转置矩阵会将行向量转换为列向量,反之亦然,这由上标 T 表示:


下面是一个正方形矩阵(行数和列数相同)在轴互换后的样子:

方阵转置
如果矩阵不是正方形,这是矩阵形状的变化:

非方阵转置
换位的后续代码:
有两种转置矩阵的方法,你可以使用 T 属性或者简单地使用转置方法:

使用 T 属性

使用transpose方法
我们还可以检查矩阵(2D 阵列)的形状变化:

矩阵中的加法和广播

2 个矩阵的加法
加法只是您希望在众多操作中执行的另一个简单操作。
我们可以添加相同形状的矩阵:
A + B = C
矩阵 A 中的每个单元都与矩阵 B 中的相应元素相加,总和存储在结果矩阵 C 中的相应位置,如左图所示。
现在,你可能会问,如果我们必须将两个不同形状的矩阵相加,或者将一个标量添加到一个矩阵中,会怎么样?NumPy 已经用广播解决了这个问题:
广播

向矩阵添加标量
广播是一种通过将自身扩展到矩阵的所有元素来将标量或不同形状的向量添加到矩阵的技术。标量被添加到矩阵的每个元素中,这就是它被称为“广播”的原因。
假设我们有两个不同形状的矩阵,如下图所示:

在这种情况下,矩阵 B(较小的矩阵)会自我扩展以匹配矩阵 A(较大的矩阵)的形状,如下所示:

您可以使用这个 Google Colab 笔记本来检查其他组合并试验代码:
标量、向量、矩阵和张量介绍。
colab.research.google.com](https://colab.research.google.com/drive/1-amF1d2wOoVxOXQRf5wKZ4yNfctyBF20?usp=sharing)
本系列的下一篇文章是关于矩阵和向量的乘法,将于下周初发表。在此之前,敬请关注 Harshit,继续学习数据科学。
Harshit 的数据科学
通过这个渠道,我计划推出几个覆盖整个数据科学领域的系列。以下是你应该订阅频道的原因:
- 该系列将涵盖每个主题和子主题的所有必需/要求的高质量教程,如 Python 数据科学基础。
- 解释了为什么我们在 ML 和深度学习中做这些事情的数学和推导。
- 与谷歌、微软、亚马逊等公司的数据科学家和工程师以及大数据驱动型公司的首席执行官的播客。
- 项目和说明实施到目前为止所学的主题。

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
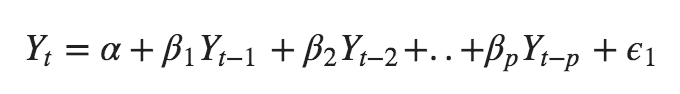{kind=link}
{kind=link}
{kind=link}
{kind=link}