









给数据集做文本向量化Embeding
1. 加载数据集
本示例使用的数据集是来自亚马逊的精细食品评论。该数据集包含截至2012年10月,亚马逊用户留下的共568,454条食品评论。我们将使用该数据集的一个子集,包含最近的1,000条评论,以说明目的。这些评论是用英语编写的,倾向于是积极的或消极的。每个评论都有一个ProductId、UserId、Score、评论标题(Summary)和评论正文(Text)。
我们将把评论摘要和评论文本合并成一个单独的文本。模型将对这个合并的文本进行编码,并输出一个单一的向量嵌入。
要运行这个笔记本,您需要安装以下软件包:pandas、openai、transformers、plotly、matplotlib、scikit-learn、torch(transformer dep)、torchvision 和 scipy。
# 导入pandas和tiktoken模块
import pandas as pd
import tiktoken
# 导入自定义的get_embedding函数
from utils.embeddings_utils import get_embedding
# 定义嵌入模型参数
embedding_model = "text-embedding-ada-002"
# 定义嵌入编码方式
embedding_encoding = "cl100k_base" # 这是text-embedding-ada-002的编码方式
# 定义最大标记数
max_tokens = 8000 # text-embedding-ada-002的最大标记数为8191
# 加载和检查数据集
input_datapath = "data/fine_food_reviews_1k.csv" # 为了节省空间,我们提供了一个经过预过滤的数据集
df = pd.read_csv(input_datapath, index_col=0) # 使用pandas库的read_csv函数读取csv文件,并将第一列作为索引列
df = df[["Time", "ProductId", "UserId", "Score", "Summary", "Text"]] # 选择数据集中的指定列
df = df.dropna() # 删除包含缺失值的行
df["combined"] = ( # 创建一个新的列"combined",将"Summary"和"Text"两列的内容合并到一起
"Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip()
)
df.head(2) # 显示数据集的前两行数据
| Time | ProductId | UserId | Score | Summary | Text | combined | |
|---|---|---|---|---|---|---|---|
| 0 | 1351123200 | B003XPF9BO | A3R7JR3FMEBXQB | 5 | where does one start...and stop... with a tre... | Wanted to save some to bring to my Chicago fam... | Title: where does one start...and stop... wit... |
| 1 | 1351123200 | B003JK537S | A3JBPC3WFUT5ZP | 1 | Arrived in pieces | Not pleased at all. When I opened the box, mos... | Title: Arrived in pieces; Content: Not pleased... |
# subsample to 1k most recent reviews and remove samples that are too long
# 将数据集抽样为最近的1000个评论,并删除过长的样本
top_n = 1000
# 对数据集按照"Time"列进行排序,然后取最后的2k个样本
df = df.sort_values("Time").tail(top_n * 2) # first cut to first 2k entries, assuming less than half will be filtered out
# 删除"Time"列
df.drop("Time", axis=1, inplace=True)
# 使用tiktoken库的get_encoding方法获取嵌入编码
encoding = tiktoken.get_encoding(embedding_encoding)
# 对于每个评论,计算其编码后的token数量,并将结果保存在新的列"n_tokens"中
df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))
# 保留token数量不超过max_tokens的样本,并取最后的top_n个样本
df = df[df.n_tokens <= max_tokens].tail(top_n)
# 返回数据集df的长度
len(df)
1000
2. 获取嵌入并保存以备将来使用
# 确保您已按照README中的说明在环境中设置了API密钥:https://github.com/openai/openai-python#usage
# 这可能需要几分钟时间
# 将get_embedding函数应用于df的combined列,并将结果存储在df的embedding列中
df["embedding"] = df.combined.apply(lambda x: get_embedding(x, model=embedding_model))
# 将df保存为CSV文件,文件名为fine_food_reviews_with_embeddings_1k.csv
df.to_csv("data/fine_food_reviews_with_embeddings_1k.csv")
使用文本向量化Embeding进行分类
有许多方法可以对文本进行分类。本笔记本分享了使用嵌入进行文本分类的示例。对于许多文本分类任务,我们已经看到微调模型比嵌入效果更好。请参见微调分类.ipynb中分类的微调模型示例。我们还建议拥有比嵌入维度更多的示例,但我们在这里并没有完全实现。
在这个文本分类任务中,我们基于评论文本的嵌入预测食品评论的评分(1到5)。我们将数据集分为训练集和测试集,以便在未见数据上实际评估性能。数据集是在从数据集获取嵌入笔记本中创建的。
# 导入必要的库
import pandas as pd
import numpy as np
from ast import literal_eval
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.model_selection import train_test_split # 数据集划分函数
from sklearn.metrics import classification_report, accuracy_score # 分类报告和准确率评估
# 加载数据
datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv" # 数据文件路径
df = pd.read_csv(datafile_path) # 读取csv文件
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array) # 将嵌入向量从字符串转换为数组
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
list(df.embedding.values), df.Score, test_size=0.2, random_state=42
)
# 训练随机森林分类器
clf = RandomForestClassifier(n_estimators=100) # 创建随机森林分类器对象
clf.fit(X_train, y_train) # 在训练集上拟合分类器
preds = clf.predict(X_test) # 在测试集上进行预测
probas = clf.predict_proba(X_test) # 预测每个类别的概率
# 生成分类报告并输出准确率评估
report = classification_report(y_test, preds) # 生成分类报告
print(report) # 输出分类报告
precision recall f1-score support
1 0.89 0.40 0.55 20
2 1.00 0.38 0.55 8
3 1.00 0.18 0.31 11
4 1.00 0.26 0.41 27
5 0.75 1.00 0.86 134
accuracy 0.77 200
macro avg 0.93 0.44 0.53 200
weighted avg 0.82 0.77 0.72 200
我们可以看到模型已经学会了很好地区分不同的类别。五星级评论总体上表现最好,这并不太令人惊讶,因为它们在数据集中最为常见。
# 从utils.embeddings_utils模块中导入plot_multiclass_precision_recall函数
from utils.embeddings_utils import plot_multiclass_precision_recall
# 调用plot_multiclass_precision_recall函数,传入probas、y_test、[1, 2, 3, 4, 5]和clf四个参数
# probas:预测结果的概率值
# y_test:测试集的真实标签
# [1, 2, 3, 4, 5]:标签的取值范围
# clf:分类器
plot_multiclass_precision_recall(probas, y_test, [1, 2, 3, 4, 5], clf)
RandomForestClassifier() - Average precision score over all classes: 0.87
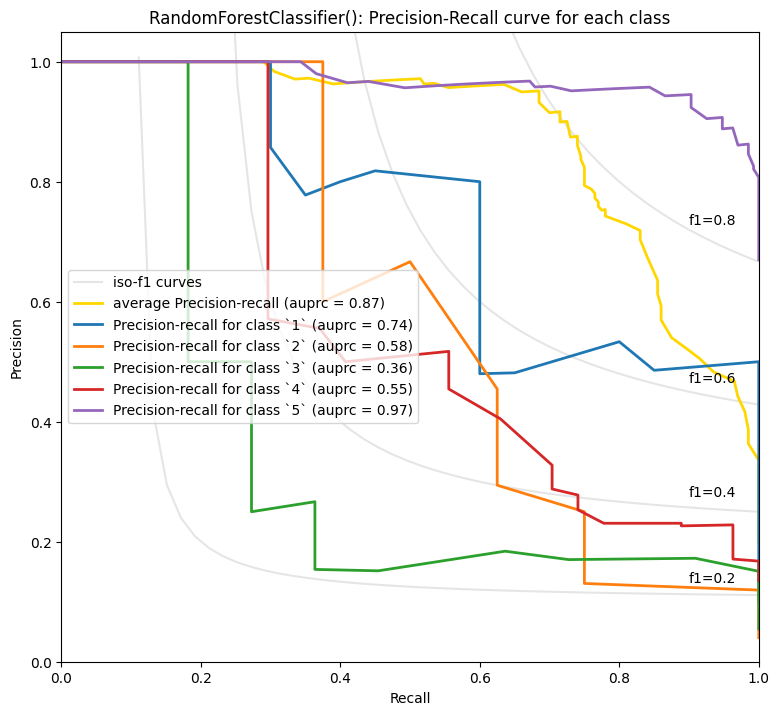
毫不意外,5星和1星的评论似乎更容易预测。也许有更多的数据,2-4星之间的细微差别可以更好地预测,但人们如何使用中间分数也可能更加主观。
使用文本向量进行零样本Zero Shot分类
在这个笔记本中,我们将使用嵌入和零标签数据来对评论的情感进行分类!数据集是在从数据集中获取嵌入笔记本中创建的。
我们将定义正面情感为4星和5星的评论,负面情感为1星和2星的评论。3星的评论被认为是中性的,我们不会在这个例子中使用它们。
我们将通过嵌入每个类别的描述,然后将新样本与这些类别的嵌入进行比较来进行零样本分类。
# 导入所需的库
import pandas as pd
import numpy as np
from ast import literal_eval
from sklearn.metrics import classification_report
# 设置参数,指定使用的文本嵌入模型
EMBEDDING_MODEL = "text-embedding-ada-002"
# 加载数据文件
datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
# 将embedding列中的字符串转换为numpy数组
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)
# 将5星评分转换为二元情感标签
df = df[df.Score != 3] # 去除评分为3的数据
df["sentiment"] = df.Score.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"}) # 将1和2评分标记为negative,将4和5评分标记为positive
为了进行零样本分类,我们希望在没有任何训练的情况下为样本预测标签。为此,我们可以简单地嵌入每个标签的简短描述,例如正面和负面,然后比较样本和标签描述之间的余弦距离。
与样本输入最相似的标签是预测标签。我们还可以定义一个预测分数,即到正面和负面标签的余弦距离之间的差异。可以使用此分数绘制精确度-召回率曲线,通过选择不同的阈值选择不同的精确度和召回率之间的权衡。
# 导入所需的函数和类
from utils.embeddings_utils import cosine_similarity, get_embedding
from sklearn.metrics import PrecisionRecallDisplay
# 定义评估嵌入方法的函数
def evaluate_embeddings_approach(
labels = ['negative', 'positive'], # 定义标签列表,用于计算标签的嵌入向量
model = EMBEDDING_MODEL, # 定义嵌入模型
):
# 获取标签的嵌入向量
label_embeddings = [get_embedding(label, model=model) for label in labels]
# 定义计算评分的函数,用于计算嵌入向量与标签嵌入向量之间的余弦相似度
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
# 计算每个评论的评分,并将评分转换为预测标签
probas = df["embedding"].apply(lambda x: label_score(x, label_embeddings))
preds = probas.apply(lambda x: 'positive' if x>0 else 'negative')
# 生成分类报告
report = classification_report(df.sentiment, preds)
print(report)
# 生成精度-召回率曲线
display = PrecisionRecallDisplay.from_predictions(df.sentiment, probas, pos_label='positive')
_ = display.ax_.set_title("2-class Precision-Recall curve")
# 调用评估嵌入方法的函数,并传入标签和嵌入模型
evaluate_embeddings_approach(labels=['negative', 'positive'], model=EMBEDDING_MODEL)
precision recall f1-score support
negative 0.61 0.88 0.72 136
positive 0.98 0.90 0.94 789
accuracy 0.90 925
macro avg 0.79 0.89 0.83 925
weighted avg 0.92 0.90 0.91 925
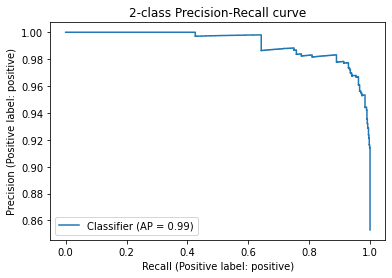
我们可以看到,这个分类器已经表现得非常好了。我们使用了相似性嵌入和最简单的标签名称。让我们尝试通过使用更具描述性的标签名称和搜索嵌入来改进它。
evaluate_embeddings_approach(labels=['An Amazon review with a negative sentiment.', 'An Amazon review with a positive sentiment.'])
precision recall f1-score support
negative 0.98 0.73 0.84 136
positive 0.96 1.00 0.98 789
accuracy 0.96 925
macro avg 0.97 0.86 0.91 925
weighted avg 0.96 0.96 0.96 925
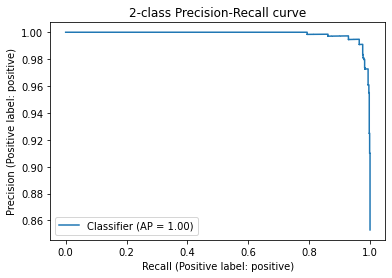
使用搜索嵌入和描述性名称可以进一步提高性能。
evaluate_embeddings_approach(labels=['An Amazon review with a negative sentiment.', 'An Amazon review with a positive sentiment.'])
precision recall f1-score support
negative 0.98 0.73 0.84 136
positive 0.96 1.00 0.98 789
accuracy 0.96 925
macro avg 0.97 0.86 0.91 925
weighted avg 0.96 0.96 0.96 925

如上所示,使用嵌入进行零样本分类可以获得很好的结果,特别是当标签比简单的单词更具描述性时。


















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











