







 本文介绍了一种新的查询引擎SQLAutoVectorQueryEngine,它能利用SQL数据库和向量存储处理结构化和非结构化数据的复杂查询,展示了如何结合这两种技术来提供更全面的答案。实验结果显示了其在不同场景下的有效性和潜力。
本文介绍了一种新的查询引擎SQLAutoVectorQueryEngine,它能利用SQL数据库和向量存储处理结构化和非结构化数据的复杂查询,展示了如何结合这两种技术来提供更全面的答案。实验结果显示了其在不同场景下的有效性和潜力。
摘要
在本文中,我们展示了LlamaIndex中一个强大的新查询引擎(SQLAutoVectorQueryEngine),它可以利用SQL数据库和向量存储来满足对结构化和非结构化数据的复杂自然语言查询。该查询引擎可以利用SQL在结构化数据上的表达能力,并将其与向量数据库中的非结构化上下文进行连接。我们在几个示例中展示了这个查询引擎,并表明它可以处理同时使用结构化/非结构化数据或任一数据的查询。
在这里查看完整指南:https://gpt-index.readthedocs.io/en/latest/examples/query_engine/SQLAutoVectorQueryEngine.html。
背景
企业的数据湖通常包含结构化和非结构化数据。结构化数据通常以表格格式存储在SQL数据库中,以预定义的模式和实体之间的关系组织成表格。另一方面,数据湖中的非结构化数据缺乏预定义的结构,无法完全适应传统数据库。这种类型的数据包括文本文档,以及其他多模态格式,如音频记录,视频等。
大型语言模型(LLM)能够从结构化和非结构化数据中提取见解。已经出现了一些用于处理这两种类型数据的初始工具和堆栈:
-
**文本到SQL(结构化数据):**给定一组表格模式,我们将自然语言转换为可以针对数据库执行的SQL语句。
-
**带有向量数据库的语义搜索(非结构化数据):**将非结构化文档及其嵌入存储在向量数据库中(例如Pinecone,Chroma,Milvus,Weaviate等)。在查询时,通过嵌入相似性获取相关文档,然后将其放入LLM输入提示中以合成响应。
每个堆栈都解决了特定的用例。
结构化数据上的文本到SQL
在结构化环境中,SQL是一种非常表达能力强的操作表格数据的语言 - 在分析的情况下,您可以进行聚合,跨多个表格连接信息,按时间戳排序等操作。使用LLM将自然语言转换为SQL可以被视为程序合成的“作弊代码” - 只需让LLM编译成正确的SQL查询,然后让数据库上的SQL引擎处理剩下的工作!
**用例:**文本到SQL查询非常适合分析用例,其中答案可以通过执行SQL语句找到。但如果您需要比结构化表中找到的更多细节,或者如果您需要更复杂的确定与查询相关性的方式,那么它们就不适用。
适合文本到SQL的示例查询:
-
“北美洲城市的平均人口是多少?”
-
“每个大洲最大的城市和人口是什么?”
非结构化数据上的语义搜索
在非结构化环境中,检索增强生成系统的行为是首先执行检索,然后进行合成。在检索过程中,我们首先通过嵌入相似性查找与查询最相关的文档。一些向量存储支持处理检索的附加元数据过滤器。我们可以选择手动指定所需过滤器集,或者让LLM“推断”查询字符串和元数据过滤器应该是什么(请参阅我们在LlamaIndex中的自动检索模块或LangChain的自查询模块)。
**用例:**检索增强生成非常适合在非结构化文本数据的某些部分中获取答案的查询。大多数现有的向量存储(例如Pinecone,Chroma)不提供类似SQL的接口;因此,它们不太适合涉及聚合,连接,求和等操作的查询。
适合检索增强生成的示例查询
-
“告诉我关于柏林的历史博物馆”
-
“乔丹代表盖茨比向尼克提出了什么要求?”
结合这两个系统
对于某些查询,我们可能希望利用结构化表格以及向量数据库/文档存储中的知识,以便为查询提供最佳答案。理想情况下,这可以给我们带来最佳的两个世界:在结构化数据上的分析能力和在非结构化数据上的语义理解。
以下是一个示例用例:
-
您可以访问存储在向量数据库中的有关不同城市的文章集合
-
您还可以访问包含每个城市统计数据的结构化表格。
在给定这个数据集合的情况下,让我们来看一个示例查询:“告诉我人口最多的城市的艺术和文化。”
回答这个问题的“正确”方法大致如下:
- 查询结构化表格以获取人口最多的城市。
-- 从city_stats表中选择city和population两列的数据
SELECT city, population FROM city_stats
-- 按照population降序排序
ORDER BY population DESC
-- 只返回一条数据
LIMIT 1
-
将原始问题转化为更详细的问题:“告诉我关于东京的艺术和文化。”
-
在向量数据库上提出新问题。
-
使用原始问题+中间查询/响应到SQL数据库和向量数据库来合成答案。
让我们思考一下这个序列的一些高级影响:
-
我们不想使用嵌入式搜索(以及可选的元数据过滤器)来检索相关上下文,而是希望以某种方式将SQL查询作为第一个“检索”步骤。
-
我们希望确保我们可以以某种方式将SQL查询的结果与向量数据库中存储的上下文“连接”起来。目前没有现有的语言可以在SQL和向量数据库之间“连接”信息。我们将不得不自己实现这种行为。
-
两个数据源都无法单独回答这个问题。结构化表只包含人口信息。向量数据库包含城市信息,但没有简单的方法来查询具有最大人口的城市。
一个结合结构化分析和语义搜索的查询引擎
我们创建了一个全新的查询引擎(SQLAutoVectorQueryEngine),可以查询、连接、排序和组合来自SQL数据库的结构化数据和来自向量数据库的非结构化数据,以合成最终答案。
通过传入一个SQL查询引擎(GPTNLStructStoreQueryEngine)以及一个使用我们的向量存储自动检索模块(VectorIndexAutoRetriever)的查询引擎,可以初始化SQLAutoVectorQueryEngine。SQL查询引擎和向量查询引擎都被包装为包含name和description字段的“Tool”对象。
提醒:
VectorIndexAutoRetriever接受自然语言查询作为输入。在对向量数据库的元数据模式有一定了解的情况下,自动检索器首先推断出其他必要的查询参数(例如,top-k值和元数据过滤器),并使用所有查询参数对向量数据库执行查询。
SQLAutoVectorQueryEngine流程图
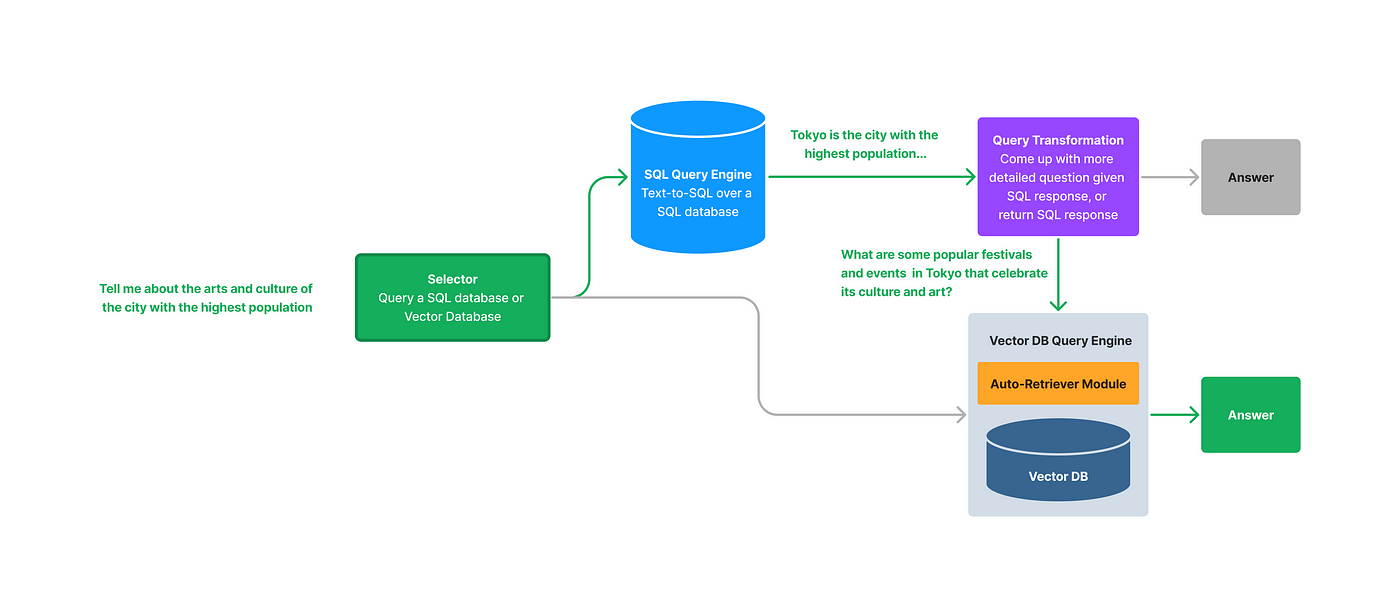
在查询时,我们执行以下步骤:
-
选择器提示(类似于我们的
RouterQueryEngine中使用的方式,参见指南)首先选择我们是应该查询SQL数据库还是向量数据库。如果选择使用向量查询引擎,则其余的函数执行与使用RetrieverQueryEngine和VectorIndexAutoRetriever查询相同。 -
如果选择查询SQL数据库,则会对数据库执行文本到SQL查询操作,并(可选地)合成自然语言输出。
-
运行查询转换,将原始问题转换为更详细的问题,根据SQL查询的结果。例如,如果原始问题是“告诉我关于人口最多的城市的艺术和文化。”,而SQL查询返回东京作为人口最多的城市,则新查询是“告诉我关于东京的艺术和文化。”唯一的例外是如果SQL查询本身足以回答原始问题;如果是,则函数执行返回SQL查询作为响应。
-
然后,将新查询通过向量存储查询引擎运行,该引擎从向量存储中进行检索,然后进行LLM响应合成。我们强制使用
VectorIndexAutoRetriever模块。这使我们能够根据SQL查询的结果自动推断出正确的查询参数(查询字符串、前k个、元数据过滤器)。例如,对于上面的例子,我们可以推断查询为类似于query_str="arts and culture"和filters={"title": "Tokyo"}的内容。 -
将原始问题、SQL查询、SQL响应、向量存储查询和向量存储响应合并成提示,以合成最终答案。
回顾一下,以下是关于这种方法的一些一般性评论:
-
使用我们的自动检索模块是我们模拟SQL数据库和向量数据库之间的连接的方式。我们有效地使用我们的SQL查询结果来确定查询向量数据库的参数。
-
这也意味着SQL数据库中的项目与向量数据库中的元数据之间不需要有显式的映射,因为我们可以依靠LLM能够为不同项目提出正确的查询。不过,对于结构化表和文档存储元数据之间的显式关系进行建模将是有趣的;这样我们就不需要在自动检索步骤中花费额外的LLM调用来推断正确的元数据过滤器。
实验
那么这个方法效果如何?它在广泛的查询范围内表现出色,从可以利用结构化数据和非结构化数据的查询到特定于结构化数据集合或非结构化数据集合的查询。
设置
我们的实验设置非常简单。我们有一个名为city_stats的SQL表,其中包含三个不同城市(多伦多、东京和柏林)的城市、人口和国家信息。
我们还使用Pinecone索引存储与这三个城市对应的维基百科文章。每篇文章都被分块并存储为单独的“Node”对象;每个块还包含一个包含城市名称的title元数据属性。
然后,我们从Pinecone向量索引中派生出VectorIndexAutoRetriever和RetrieverQueryEngine。
from llama_index.indices.vector_store.retrievers import VectorIndexAutoRetriever
from llama_index.vector_stores.types import MetadataInfo, VectorStoreInfo
from llama_index.query_engine.retriever_query_engine import RetrieverQueryEngine
# 定义向量存储的信息
vector_store_info = VectorStoreInfo(
content_info='articles about different cities', # 存储的内容信息
metadata_info=[
MetadataInfo(
name='city', # 元数据的名称
type='str', # 元数据的类型
description='The name of the city' # 元数据的描述
),
]
)
# 创建向量自动检索器
vector_auto_retriever = VectorIndexAutoRetriever(vector_index, vector_store_info=vector_store_info)
# 创建检索器查询引擎
retriever_query_engine = RetrieverQueryEngine.from_args(
vector_auto_retriever, service_context=service_context
)
您还可以按照以下方式获取SQL查询引擎
# 将sql_index转换为查询引擎
sql_query_engine = sql_index.as_query_engine()
两个SQL查询引擎和向量查询引擎都可以封装为QueryEngineTool对象。
# 创建一个QueryEngineTool对象,使用默认设置
sql_tool = QueryEngineTool.from_defaults(
query_engine=sql_query_engine,
description=(
'Useful for translating a natural language query into a SQL query over a table containing: '
'city_stats, containing the population/country of each city'
)
)
# 创建一个QueryEngineTool对象,使用默认设置
vector_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
description=f'Useful for answering semantic questions about different cities',
)
最后,我们可以定义我们的SQLAutoVectorQueryEngine
# 创建一个SQLAutoVectorQueryEngine对象,用于执行SQL查询和向量化操作
query_engine = SQLAutoVectorQueryEngine(
sql_tool, # SQL工具,用于执行SQL查询
vector_tool, # 向量化工具,用于将文本转换为向量表示
service_context=service_context # 服务上下文,用于存储一些全局信息
)
结果
我们运行了一些示例查询。
查询1
# 调用query_engine模块中的query函数,传入一个字符串参数
# 查询关于人口最多的城市的艺术和文化信息
result = query_engine.query(
'Tell me about the arts and culture of the city with the highest population'
)
# 打印查询结果
print(result)
结果:
{
"query": "Tell me about the arts and culture of the city with the highest population",
"result": "The city with the highest population is New York City. It is known for its vibrant arts and culture scene, with numerous museums, theaters, galleries, and cultural events. Some famous cultural landmarks include the Metropolitan Museum of Art, Broadway, and the Lincoln Center for the Performing Arts."
}
中间步骤:
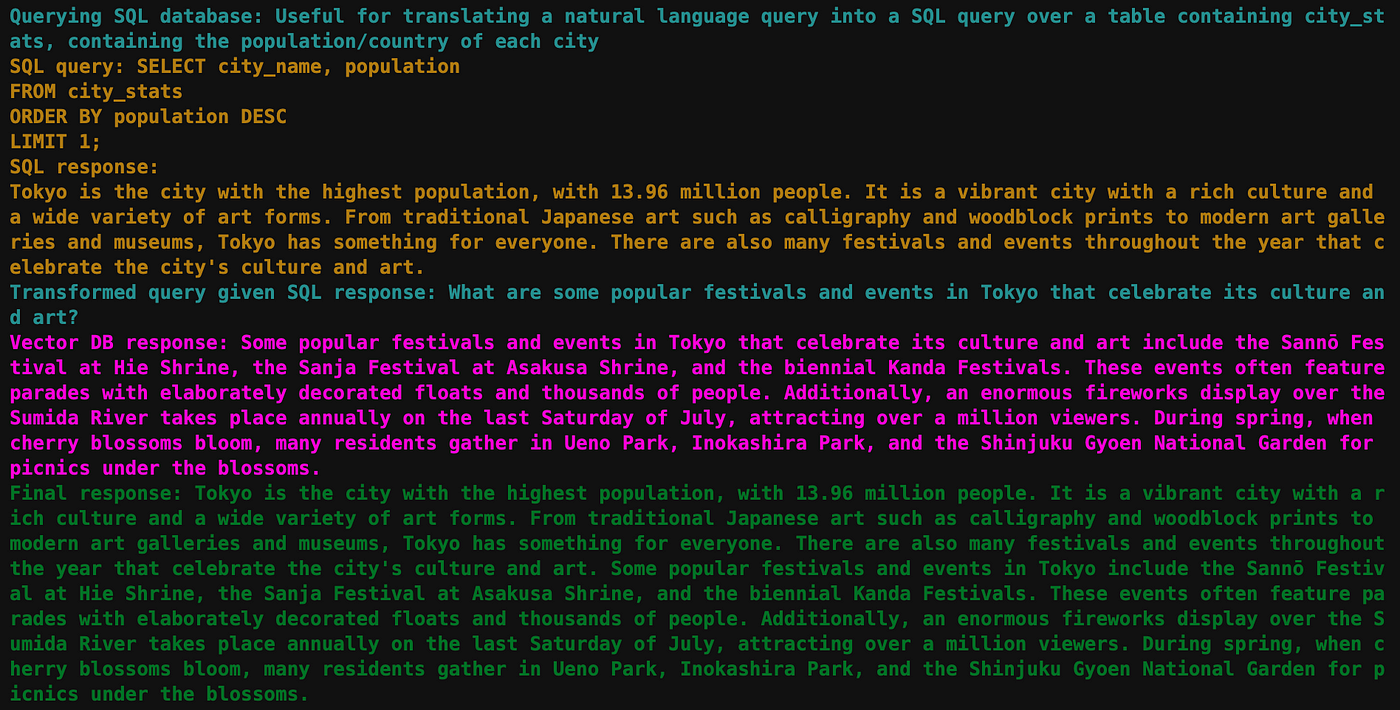
最终回应:
东京是人口最多的城市,有1396万人口。它是一个充满活力的城市,拥有丰富的文化和各种艺术形式。从传统的日本艺术,如书法和木版画,到现代艺术馆和博物馆,东京应有尽有。每年都有许多庆祝城市文化和艺术的节日和活动。东京的一些热门节日和活动包括日枝神社的山王祭、浅草神社的三社祭和两年一度的神田祭。这些活动通常都有装饰精美的花车游行和成千上万的人参加。此外,每年7月的最后一个星期六,在隅田川上空举行一场规模庞大的烟花表演,吸引了超过一百万的观众。在春天樱花盛开时,许多居民会聚集在上野公园、井之头公园和新宿御苑,享受樱花下的野餐。
这个查询通过SQLAutoVectorQueryEngine的完整流程运行。首先查询SQL数据库中人口最多的城市(“东京”),然后使用新查询查询向量数据库。结果被合并成最终的响应。
查询2
# 调用query_engine模块中的query函数,传入参数"Tell me about the history of Berlin"
query_engine.query("Tell me about the history of Berlin")
注释:
- 导入query_engine模块
- 调用query_engine模块中的query函数,传入参数"Tell me about the history of Berlin"
中间步骤:

最终回应:
柏林的历史可以追溯到13世纪初,当时它作为一个小定居点建立起来。1618年,勃兰登堡边疆伯国与普鲁士公国结成个人联盟,1701年,他们与柏林为首的普鲁士王国合并。在18世纪,柏林在弗里德里希大帝的统治下成为启蒙运动的中心,并与周边城市合并。
19世纪的工业革命改变了柏林,扩大了其经济、人口和基础设施。1871年,它成为新成立的德意志帝国的首都。20世纪初,柏林成为德国表现主义运动的中心和一个以其对科学、技术、艺术和其他领域的贡献而闻名的世界主要城市。
1933年,阿道夫·希特勒和纳粹党上台,导致柏林的犹太社区衰落以及该市参与第二次世界大战。战后,柏林被分为东柏林和西柏林,前者在苏联控制下,后者在美国、英国和法国的控制下。柏林墙于1961年建成,物理上和意识形态上分割了这座城市,直到1989年才倒塌。1990年德国重新统一后,柏林再次成为统一德国的首都,并继续作为一个重要的全球城市不断发展壮大。
这个查询只需要向量数据库,而不需要SQL数据库。初始选择器正确地确定我们只需要查询向量数据库并返回结果。
查询3
# 调用query_engine模块中的query函数,并传入参数'Can you give me the country corresponding to each city?'
query_engine.query('Can you give me the country corresponding to each city?')
中间步骤

最终回应
# 给定的语料是一个包含三个城市和它们所在国家的句子
# 定义一个字符串变量,存储给定的语料
corpus = "Toronto is in Canada, Tokyo is in Japan, and Berlin is in Germany."
# 使用split()方法将语料分割成单词列表
words = corpus.split()
# 创建一个空字典,用于存储城市和国家的对应关系
city_country = {}
# 遍历单词列表
for i in range(len(words)):
# 如果当前单词是城市名
if words[i] == "Toronto" or words[i] == "Tokyo" or words[i] == "Berlin":
# 将城市名作为键,下一个单词(国家名)作为值,添加到字典中
city_country[words[i]] = words[i+2]
# 打印城市和国家的对应关系
print(city_country)
结论
到目前为止,围绕LLMs +非结构化数据和LLMs +结构化数据的堆栈在很大程度上是分开的。我们对将LLMs与结构化和非结构化数据相结合以新颖和有趣的方式解锁新的检索/查询能力感到兴奋!
我们希望您尝试使用SQLAutoVectorQueryEngine并告诉我们您的想法。
完整的笔记本演示可以在[此指南中找到。
代码:https://github.com/jerryjliu/llama_index/blob/main/docs/examples/query_engine/SQLAutoVectorQueryEngine.ipynb


















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











