







 CodeLlama是一个基于LLAMA2的人工智能编码模型,以其精确度、效率和多语言支持改变了编码领域。文章详细介绍了模型的特点、设置和对开发者的益处,以及如何在HuggingFace平台上使用。未来,CodeLlama有望引入更多功能并扩展其影响力。
CodeLlama是一个基于LLAMA2的人工智能编码模型,以其精确度、效率和多语言支持改变了编码领域。文章详细介绍了模型的特点、设置和对开发者的益处,以及如何在HuggingFace平台上使用。未来,CodeLlama有望引入更多功能并扩展其影响力。
文章目录
一个全面指南,了解和利用基于LLAMA-2的编码模型“Code Llama”在编码世界中的力量

介绍:
在不断发展的技术领域中,总是有一些新的东西即将出现,承诺改变我们处理任务和挑战的方式。Code Llama就是这样一种开创性的人工智能工具,它将重新定义编码领域。但是,Code Llama到底是什么,为什么在技术界引起如此轰动呢?
让我解释一下为什么我认为它非常具有革命性。我在下面简短而简洁地解释了所有重要的要点。
在这份全面的指南中,我们将深入探讨Code Llama的世界,探索其特点、优势以及对编码未来的潜力。无论您是经验丰富的开发人员还是对人工智能最新进展感到好奇的人,本文将为您提供所有必要的信息。所以,让我们踏上这个旅程,发现Code Llama的魔力吧!
关键词:Code Llama,AI工具,编码领域,技术社区,开发人员,进展,AI,LLAMA 2
什么是Code Llama?
*Code Llama代表了人工智能驱动的编码辅助的巅峰。作为Meta创新团队的心血结晶,这个工具不仅仅是另一个编码助手;它是一次范式转变。Code Llama建立在Llama 2模型坚实的基础上,旨在以前所未有的精确度和效率理解、解释和生成代码。它的主要目标是弥合人类开发者与广阔的编码世界之间的鸿沟,使这个过程更加直观和节省时间。
来源 - 这里
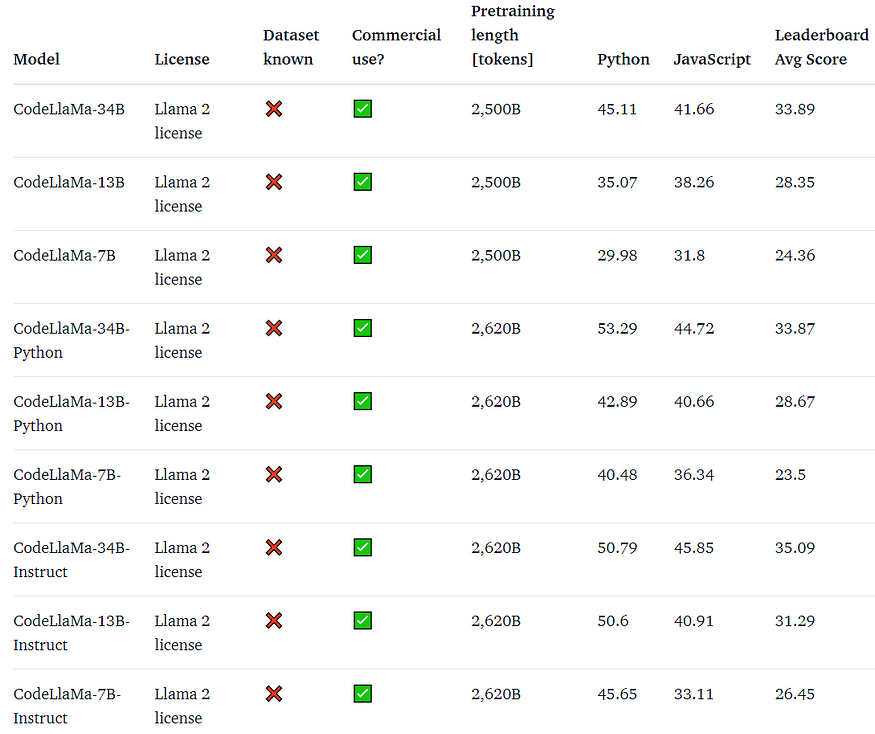
Code Llama不是一种一刀切的解决方案。它引入了一个多样化的模型系列,每个模型都针对特定需求进行了定制。开发人员可以选择拥有70亿、130亿和340亿参数的模型,确保他们有适合手头任务的正确工具。
Code LLAMA-70B:
Code Llama 70B与之前发布的Code Llama模型一样,有三个版本,都可以免费用于研究和商业用途:
1.)CodeLlama - 70B,基础代码模型;
2.)CodeLlama - 70B - Python,专门针对Python的70B模型;
3.)以及Code Llama - 70B - Instruct 70B,专门针对理解自然语言指令进行了微调。
模型大小
1.) 7B〜12.55GB
2.) 13B〜24GB
3.) 34B〜63GB
4.)70B〜131GB
设置
特点:
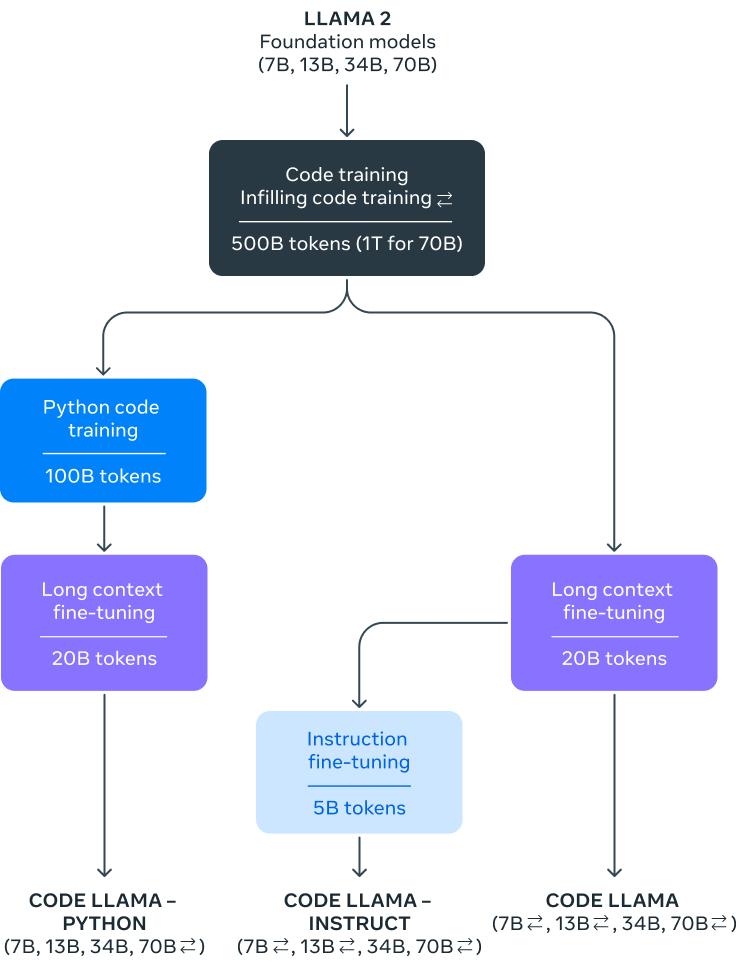
Code Llama的基础在于Llama 2模型。通过从Llama 2进行初始化,然后在5000亿个代码标记上进行训练,Code Llama继承了其前身的稳健性,同时引入了针对编码的专门能力。
i.) 精细调整的专业化:
为了满足开发者的多样化需求,Meta对基础模型进行了精细调整,创建了两个不同的版本:
-
Python 专家版: 在额外的1000亿个标记上进行训练,这个变体专为Python开发量身定制。
-
指令精细调整版本: 这个模型旨在理解自然语言指令,弥合人类语言和代码之间的差距。
ii.) 最先进的性能:
Code Llama不仅仅是关于庞大的参数,它还关注效率和效果。这些模型在多种编程语言中表现出顶级性能,包括Python、C++、Java、PHP、C#、TypeScript和Bash。这种多功能性确保了不同领域的开发者能够利用Code Llama的能力。
iii.) 填充能力:
7B和13B模型,包括基础模型和指令变体,都具有一个独特的功能:根据周围内容进行填充的能力。这使它们成为代码助手的完美选择,帮助开发者精确地完成代码段。
iv.) 上下文窗口:
Code Llama的一个突出特点是它的上下文窗口。虽然它是在一个16k的上下文窗口上进行训练的,但这些模型经过了额外的长上下文精细调整。这使它们能够处理长达100,000个标记的令人印象深刻的上下文窗口,确保它们可以处理大量的代码段而不会错过任何细节。
v.) RoPE缩放和位置嵌入:
从Llama 2的4k上下文窗口过渡到Code Llama的增强16k(有可能外推到100k)是RoPE缩放的进步的证明。社区发现Llama的位置嵌入可以在频域中进行线性插值或调整,这是关键。
这种调整通过精细调整便于过渡到更大的上下文窗口。具体来说,对于Code Llama,频域缩放包含一个松弛因子,确保精细调整长度仍然是缩放预训练长度的一部分。这种方法赋予了模型卓越的外推能力。
vi.) 最先进的性能:
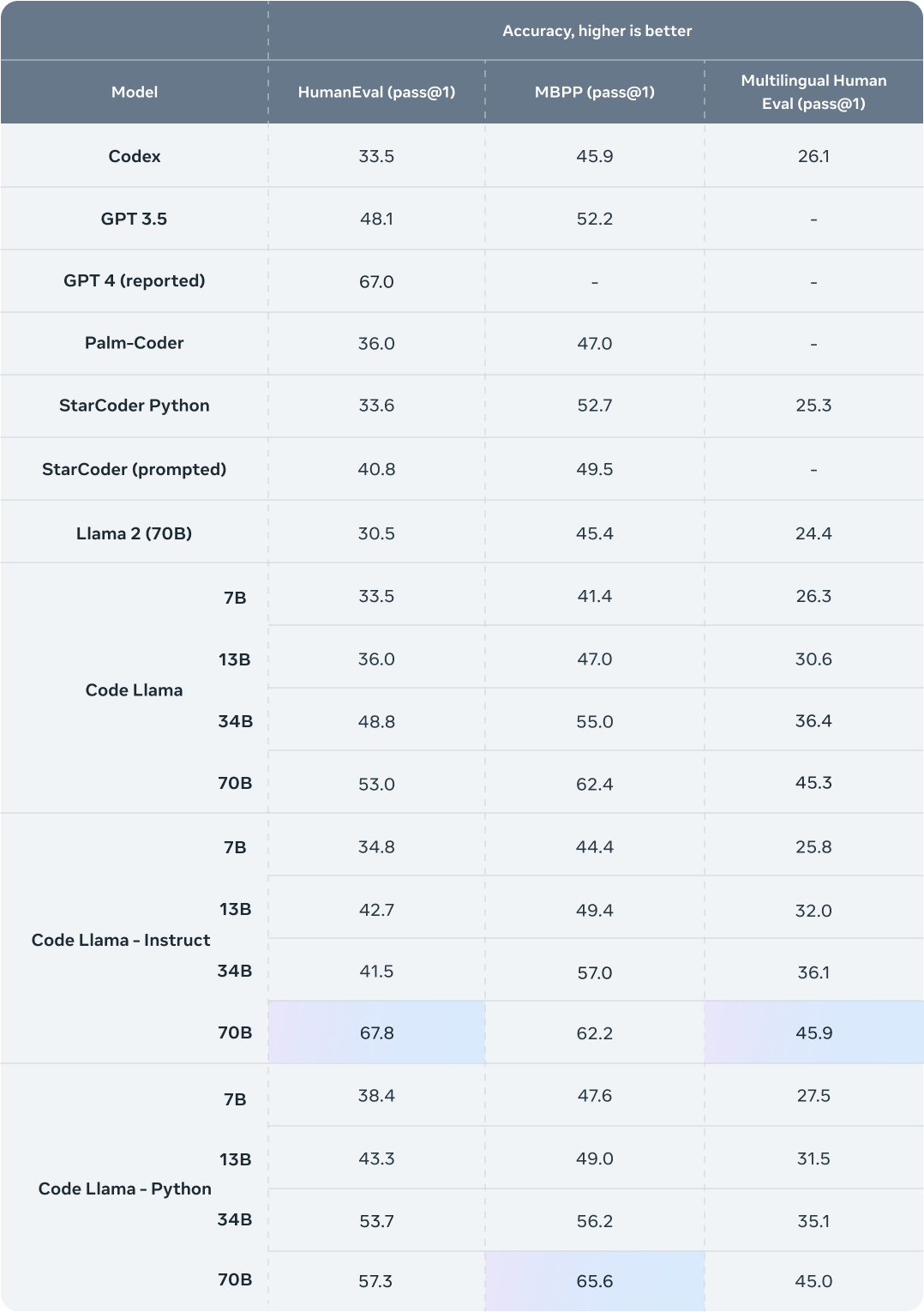
当我们谈论Code Llama的性能时,我们指的是它以闪电般的速度处理、理解和生成代码的能力。但这不仅仅是速度的问题,还关乎准确性。Code Llama经过大量数据集的训练,使其能够识别模式,预测开发者的需求,并提供高效和有效的解决方案。在与市场上其他工具进行对比时,Code Llama始终是领先者,为基于人工智能的编码工具设定了新的基准。
对开发者社区的影响:
开发者社区对于承诺革新编码的工具和平台并不陌生。然而,Code Llama的推出引起了激动和乐观的涟漪。
它的速度、准确性和适应性的结合意味着开发者可以专注于编码的创造性方面,将重复和耗时的任务交给Code Llama。这个工具减少了开发时间,加上它的精确性,意味着更少的错误、更快的项目完成和更多的创新时间。开发者社区对Code Llama的广泛赞誉反映了它的变革潜力。
代码补全技术
为了有效利用这一功能,对于这个特定任务,对模型的训练格式要非常细致,因为它依赖于不同分隔符来区分提示的各个部分。幸运的是,transformers中的CodeLlamaTokenizer简化了这个过程,如下所示:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
# 指定模型ID
model_id = "codellama/CodeLlama-70b-hf"
# 根据模型ID加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 根据模型ID加载模型,并将模型转移到GPU上
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
# 定义输入的提示文本
prompt = '''def remove_non_ascii(s: str) -> str:
""" <FILL_ME>
return result
'''
# 使用tokenizer对输入进行编码,并将编码后的输入转移到GPU上
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
# 使用模型生成文本
output = model.generate(
input_ids,
max_new_tokens=200,
)
# 将生成的文本转移到CPU上
output = output[0].to("cpu")
# 解码生成的文本,并去除特殊标记
filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True)
# 打印最终的结果
print(prompt.replace("<FILL_ME>", filling))
4位量化技术
通过Code Llama与Transformers库的集成,用户可以立即获得先进功能,例如4位量化。这个功能使您能够在标准消费级GPU上运行庞大的32B参数模型,例如Nvidia 3090显卡!
要执行基于4位模式的推理,请按照以下步骤进行:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
# 指定模型ID
model_id = "codellama/CodeLlama-70b-hf"
# 配置量化参数
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # 使用4位量化
bnb_4bit_compute_dtype=torch.float16 # 使用半精度浮点数进行计算
)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config, # 使用量化配置
device_map="auto", # 自动选择设备
)
# 设置输入的提示文本
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
# 对提示文本进行分词和编码
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
# 生成代码
output = model.generate(
inputs["input_ids"],
max_new_tokens=200, # 生成的最大代码长度
do_sample=True, # 使用采样方式生成代码
top_p=0.9, # 采样时的概率阈值
temperature=0.1, # 采样时的温度参数
)
# 将生成的代码转移到CPU上
output = output[0].to("cpu")
# 解码生成的代码并打印
print(tokenizer.decode(output))
Hugging Face 上可用的模型:
-
Code-LLAMA - 一个在 GitHub 代码库上训练的大规模语言模型。
https://huggingface.co/models?pipeline_tag=text2code&sort=downloads
-
GGUF - 一个可以针对各种任务进行微调的生成模型。
-
https://huggingface.co/models?pipeline_tag=text2code&sort=downloads
Code Llama的未来:
科技领域不断发展,每天都会出现新的挑战和机遇。像Code Llama这样的工具不仅跟上了步伐,而且正在引领方向。随着人工智能研究的进展和我们对编码挑战的理解加深,我们可以期待Code Llama的发展,它将融入更先进的功能,并扩展其能力范围。Code Llama的路线图充满了希望——从处理更多编程语言到与其他开发工具和平台的集成。旅程才刚刚开始,未来充满了无限的可能性。


















 169
169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











