







作者:李森茂 胡泰航(共同一作) 南开大学
内容简介
扩散模型的一个主要缺点是图像生成的推理时间慢。解决这个问题的最成功方法之一是蒸馏方法。然而,这些方法需要大量的计算资源。在本文中,我们采取了另一种方法来加速扩散模型。我们对UNet编码器进行了全面研究,并实证分析了编码器特征。这为我们提供了关于它们在推理过程中变化的见解。特别是,我们发现编码器特征变化很小,而解码器特征在不同时间步中表现出显著变化。这一见解激励我们在某些相邻时间步中省略编码器计算,并在多个时间步中将前一时间步的编码器特征作为输入重用到解码器。重要的是,这使我们能够并行执行解码器计算,进一步加速去噪过程。此外,我们引入了一种先验噪声注入方法来改善生成图像的纹理细节。除了标准的文本到图像任务,我们还在其他任务上验证了我们的方法:文本到视频、个性化生成和参考引导生成。不使用任何知识蒸馏技术,我们的方法分别加速了Stable Diffusion(SD)和DeepFloyd-IF模型采样41%和24%,以及DiT模型采样34%,同时保持了高质量的生成性能。
论文地址:https://arxiv.org/pdf/2312.09608
代码链接:https://sen-mao.github.io/FasterDiffusion
Background
在2022年,仍然是生成对抗网络(GAN)占据主导地位的时代。使用生成对抗网络生成一张高清图像通常只需要毫秒级的时间。然而,当时的扩散模型生成图像往往需要几十秒时间。这使得基于扩散模型的许多任务必须在离线环境中进行,从而大大限制了扩散模型的应用范围。

虽然到目前为止,基于生成对抗网络生成图像的一些工作已经取得了一定的进展,但这些工作往往没有开源代码或者模型。然而,基于扩散模型的工作则大多会开源他们的代码和模型。正是因为这些基于扩散模型的项目公开了代码和模型,学者们才能进一步探索和挖掘这些技术,开展科研工作和落地应用任务。
例如,基于潜在空间进行生成的稳定扩散(Stable Diffusion),及基于图像空间进行生成的DeeperFloyd-IF模型等。这些开源项目为研究人员和开发者提供了宝贵的资源,使得我们能够在此基础上进行创新和应用开发。

之所以扩散模型生成图像非常耗时,是因为在预训练模型以后,使用预训练的模型进行推理时,传统的扩散模型的推理过程由噪声逐渐迭代的生成一张清晰的图像,这个过程通常需要1000步,虽然可以采用最近提出的一些非马尔科夫采样策略,比如DDIM50步,但这个过程仍然非常耗时;推理速度相比于GAN的推理速度仍然让人无法接受;通过采样公式可以发现,每一个必须等待前一个的计算,而且主要的耗时来自于网络的计算,而公式中的都是预先定义好的。

以开源的Stable Diffusion为例,主要的组成部分是UNet,并且以时间步和文本提示作为条件输入,本文依据UNet中block的尺度(或者分辨率)将其划分为Encoder,Bottleneck和Decoder;
通过之前的一些工作,作者发现Unet中的解码器对生成中过程中相比于编码器更重要,比如条件生成的工作ControlNet中将特征注入到解码器中;图像编辑的工作PnP使用解码器中的特征进行图像编辑;特征点匹配的工作DIFT利用解码器中的特征进行图像中的特征匹配;
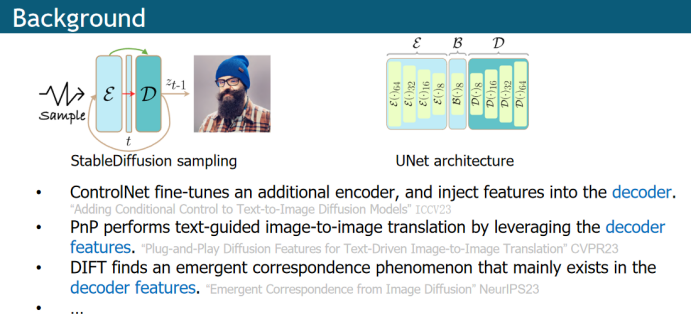
Analysis
基于这些工作的启发,本文首次对UNet中编码器和解码器的特征在时间步维度进行了全面的分析;
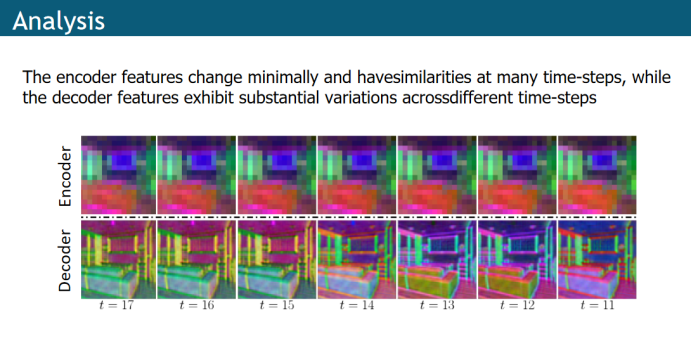
首先作者对推理过程中的编码器和解码器的特征进行PCA降维并进行可视化,从可视化结果来看,在相邻时间步之间,编码器的特征变化是连续的,解码器的变化比较明显;
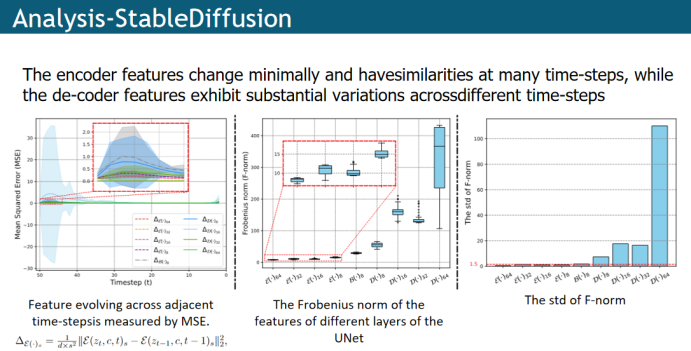
作者也对相邻时间步的特征进行了一些定量的分析,(a)左边这个图,计算相邻时间步的误差,从统计结果中同样可以发现编码器在相邻时间步下的变化比较缓慢,也就是这些暖色的曲线,而解码器的变化比较明显,用冷色的曲线表示,尤其是解码器中尺度为16的模块,特征之间变化的方差很大,甚至与编码器相比相差两个数量级;(b)在中间的这个图中,作者计算了不同模块的特征在时间步下的F-norm均值,来观察模块包含的信息量,发现编码器的F-norm相比于解码器小的多,相差一个数量级,© 右图,作者发现F-norm的标准差也表现出同样的特性;
Method
在 Stable Diffusion 的采样过程中,以时间步 t t t 时刻的采样为例,在时间步 t t t 时,就已经得到了当前时间步的图像 z t z_t zt ,要预测下一个时间步的图像 z t − 1 z_{t-1} zt−1 时,需要给模型输入当前步的图像 z t z_t zt ,时间步 t t t ,和文本提示 c c c 。然后模型会预测当前时间步的噪声,通过公式 1 就能得到 z t − 1 z_{t-1} zt−1 。同样的,可以基于 z t − 1 z_{t-1} zt−1 得到 z t − 2 z_{t-2} zt−2 。这个过程是迭代式的,当前时间步的计算必须等待上一个时间步的计算完成。
基于以上发现与分析,在时间步
t
−
1
t-1
t−1 时,使用时间步
t
t
t 共享的编码器的特征,而跳过当前时间步的编码器,进行 Encoder propagation,这样就能获得加速采样的效果。文中将计算编码器的时间步定义为关键 key timestep,将跳过编码器计算的时间步定义为非关键时间步 non-key timestep。所以,时间步
t
t
t 就是关键时间步,时间步
t
−
1
t-1
t−1 就是非关键时间步;

这样的话,在整个推理阶段,在特征相似的时间步中只需要选择一个时间步作为关键时间步 key timestep,其余都作为非关键时间步 non-key timestep;例如,对于 DDIM50 步采样,我们只选取 9 个时间步作为关键时间步;推理时间减少了
24
%
24 \%
24% ;
通过进一步分析发现,在非关键时间步预测噪声时,并不需要上一个时间步的结果 z t − 1 z_{t-1} zt−1 ,而只需要接受上一个时间步的编码器的跳转连接就行;所以当关键时间步的编码器计算完成后,相邻的非关键时间步的解码器可以并行计算,这样就可以进一步加速采样;推理时间减少了 41 % 41 \% 41% ;

从可视化的定性结果来看,FasterDiffusion能够保持原始StableDiffusion的生成效果,推理时间减少了41%。

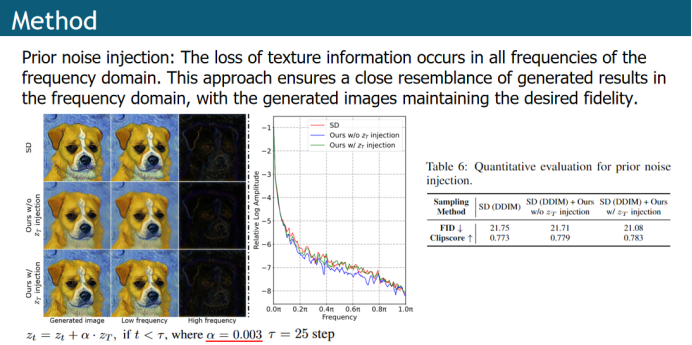
作者发现使用编码器传播会轻微的丢失纹理信息,包括在低频和高频中,但高频信息丢失的更多一些,可以从可视化的结果(第一行和第二行的比较看到),和从频率域的红色和蓝色曲线观察到。作者分析这可能是由于编码器传播过程中,共享的之前时间步的特征去噪能力较强,除了噪声还会去除纹理信息。所以我们给补充轻微的噪声,防止将纹理信息denoise掉。进行噪声注入以后,高频和低频都有恢复,红色曲线和绿色曲线也就很相似了。从指标上也能看到提升。
Analysis-DiT
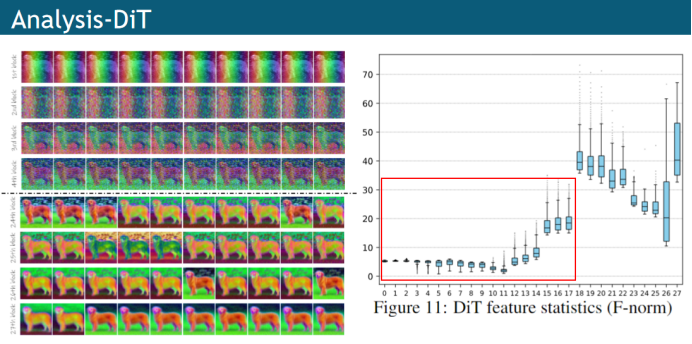
除了对Stable Diffusion这种具有UNet结构的扩散模型进行分析以外,文章还对DiT架构的扩散模型进行了分析,DiT本身没有以不同尺度来区分的编码器和解码器,所以作者首先对DiT中的每个模块的特征进行了分析,发现前半部分模块变化是连续的,而后半部分模块变化比较剧烈,这一现象可以从特征的可视化结果和F-norm的统计可以观察到。基于这一观察,就可以人为的将DiT的前半部分和后半部分的模块分别划分为编码器和解码器,这样的话就能进行FasterDiffusion的编码器传播策略,从而实现加速采样;
Experiments
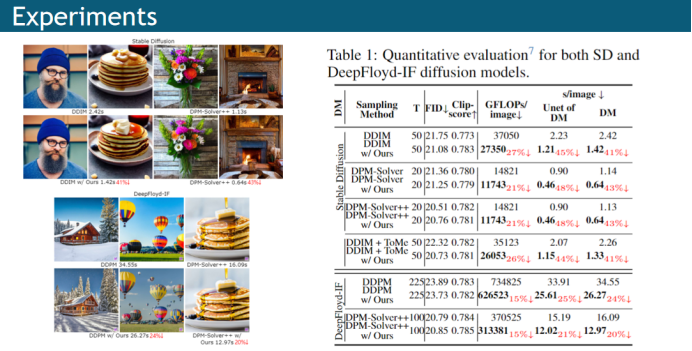
文章在latent space和image space的text2image的扩散模型上对所提方法做了验证;对于latent space,结合稳定扩散的不同采样方法,包括DDIM,DPM-Solver,以及像TokenMerge这样的加速方法;对于image space,结合了基于DeepFloy-IF的不同采样方法,包括DDPM和DPM-Solver。从定性和定量结果来看,文章在结合这些方法进行加速采样的同时,都能保持图像质量;
文章同样对一些扩散模型的下游任务进行结合,比如视频生成和条件生成的;定性和定量结果也都显示了所提方法的有效性;

按照文章对DiT中模块的划分,与UNet结构的扩散模型一样,就可以使DiT结合编码器传播,同样可以进行采样的加速,同时保持采样质量;可以从图片中的定性和定量结果上看到这一点。

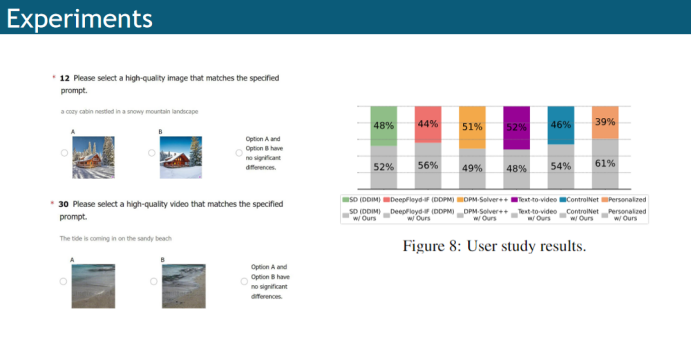
作者还进行了用户的评价,左边是一些用户评测的例子,分别展示原始模型的生成结果和结合FasterDiffusion的结果;右边的用户调查结果显示,所提方法和原始方法的生成效果,在用户角度看来是基本一致的;
当与ControlNet结合时,FasterDiffusion和DeepCache在视觉效果上与Stable Diffusion都很接近,加速方面FasterDiffusion实现更快加速;
由于FasterDiffusion的非关键时间步的计算都是独立且并行的,所以将非关键时间步的计算放到多个GPU上,可以实现真正的物理上的并行,这样的话,与DDIM结合时,采样时间减少77%,而DeepCache只能减少44%;

Take Aways
本文通过分析,发现在多步扩散模型中,编码器的特征变化比较连续,而解码器的变化比较剧烈;
基于这一发现,作者提出了编码器传播来实现高效采样;并且,该方法可以扩展到任何基于扩散模型的任务上。


















 137
137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











