






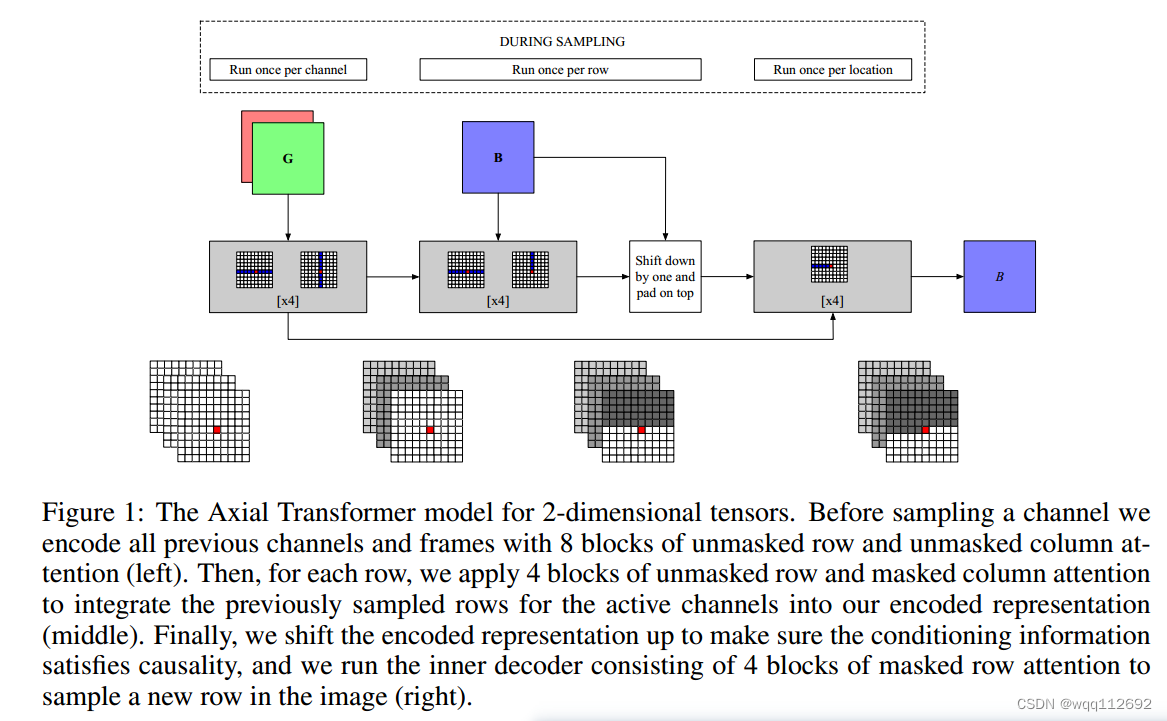
论文《Axial Attention in Multidimensional Transformers》中提出了一种基于Transformer自注意力机制的Axial Attention。Axial Attention轴向注意力将二维输入分解为其轴向的组件,例如行和列,然后在每一个组件中,独立地为每个轴应用注意力,比如在每一行上面执行自注意力机制然后再再每一列上执行自注意力机制。感受野是目标像素的同一行(或者同一列) 的W(或H)个像素, 只有将Row-Attention和Column-Attention组合使用, 才能实现全局注意力。
Row-Attention
#实现轴向注意力中的 row Attention
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
device = torch.device('cuda:0' )
class RowAttention(nn.Module):
def __init__(self, in_dim, q_k_dim, device):
'''
Parameters
----------
in_dim : int
channel of input img tensor
q_k_dim: int
channel of Q, K vector
device : torch.device
'''
super(RowAttention, self).__init__()
self.in_dim = in_dim
self.q_k_dim = q_k_dim
self.device = device
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.in_dim, kernel_size=1)
self.softmax = Softmax(dim=2)
self.gamma = nn.Parameter(torch.zeros(1)).to(self.device)
def forward(self, x):
'''
Parameters
----------
x : Tensor
4-D , (batch, in_dims, height, width) -- (b,c1,h,w)
'''
## c1 = in_dims; c2 = q_k_dim
b, _, h, w = x.size()
Q = self.query_conv(x) #size = (b,c2, h,w)
K = self.key_conv(x) #size = (b, c2, h, w)
V = self.value_conv(x) #size = (b, c1,h,w)
Q = Q.permute(0,2,1,3).contiguous().view(b*h, -1,w).permute(0,2,1) #size = (b*h,w,c2)
K = K.permute(0,2,1,3).contiguous().view(b*h, -1,w) #size = (b*h,c2,w)
V = V.permute(0,2,1,3).contiguous().view(b*h, -1,w) #size = (b*h, c1,w)
#size = (b*h,w,w) [:,i,j] 表示Q的所有h的第 Wi行位置上所有通道值与 K的所有h的第 Wj列位置上的所有通道值的乘积,
# 即(1,c2) * (c2,1) = (1,1)
row_attn = torch.bmm(Q,K)
########
#此时的 row_atten的[:,i,0:w] 表示Q的所有h的第 Wi行位置上所有通道值与 K的所有行的 所有列(0:w)的逐个位置上的所有通道值的乘积
#此操作即为 Q的某个(i,j)与 K的(i,0:w)逐个位置的值的乘积,得到行attn
########
#对row_attn进行softmax
row_attn = self.softmax(row_attn) #对列进行softmax,即[k,i,0:w] ,某一行的所有列加起来等于1,
#size = (b*h,c1,w) 这里先需要对row_atten进行 行列置换,使得某一列的所有行加起来等于1
#[:,i,j]即为V的所有行的某个通道上,所有列的值 与 row_attn的行的乘积,即求权重和
out = torch.bmm(V,row_attn.permute(0,2,1))
#size = (b,c1,h,2)
out = out.view(b,h,-1,w).permute(0,2,1,3)
out = self.gamma*out + x
return out
#实现轴向注意力中的 Row Attention
x = torch.randn(4, 8, 16, 20).to(device)
row_attn = RowAttention(in_dim = 8, q_k_dim = 4,device = device).to(device)
print(row_attn(x).size())Column-Attention
#实现轴向注意力中的 column Attention
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
device = torch.device('cuda:0')
class ColAttention(nn.Module):
def __init__(self, in_dim, q_k_dim, device):
'''
Parameters
----------
in_dim : int
channel of input img tensor
q_k_dim: int
channel of Q, K vector
device : torch.device
'''
super(ColAttention, self).__init__()
self.in_dim = in_dim
self.q_k_dim = q_k_dim
self.device = device
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.in_dim, kernel_size=1)
self.softmax = Softmax(dim=2)
self.gamma = nn.Parameter(torch.zeros(1)).to(self.device)
def forward(self, x):
'''
Parameters
----------
x : Tensor
4-D , (batch, in_dims, height, width) -- (b,c1,h,w)
'''
## c1 = in_dims; c2 = q_k_dim
b, _, h, w = x.size()
Q = self.query_conv(x) #size = (b,c2, h,w)
K = self.key_conv(x) #size = (b, c2, h, w)
V = self.value_conv(x) #size = (b, c1,h,w)
Q = Q.permute(0,3,1,2).contiguous().view(b*w, -1,h).permute(0,2,1) #size = (b*w,h,c2)
K = K.permute(0,3,1,2).contiguous().view(b*w, -1,h) #size = (b*w,c2,h)
V = V.permute(0,3,1,2).contiguous().view(b*w, -1,h) #size = (b*w,c1,h)
#size = (b*w,h,h) [:,i,j] 表示Q的所有W的第 Hi行位置上所有通道值与 K的所有W的第 Hj列位置上的所有通道值的乘积,
# 即(1,c2) * (c2,1) = (1,1)
col_attn = torch.bmm(Q,K)
########
#此时的 col_atten的[:,i,0:w] 表示Q的所有W的第 Hi行位置上所有通道值与 K的所有W的 所有列(0:h)的逐个位置上的所有通道值的乘积
#此操作即为 Q的某个(i,j)与 K的(i,0:h)逐个位置的值的乘积,得到列attn
########
#对row_attn进行softmax
col_attn = self.softmax(col_attn) #对列进行softmax,即[k,i,0:w] ,某一行的所有列加起来等于1,
#size = (b*w,c1,h) 这里先需要对col_atten进行 行列置换,使得某一列的所有行加起来等于1
#[:,i,j]即为V的所有行的某个通道上,所有列的值 与 col_attn的行的乘积,即求权重和
out = torch.bmm(V,col_attn.permute(0,2,1))
#size = (b,c1,h,w)
out = out.view(b,w,-1,h).permute(0,2,3,1)
out = self.gamma*out + x
return out
#实现轴向注意力中的 cols Attention
x = torch.randn(4, 8, 16, 20).to(device)
col_attn = ColAttention(in_dim = 8, q_k_dim = 4, device = device).to(device)
print(col_attn(x).size())













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









