






YOLOv5分布式训练与混合精度训练实战指南
在深度学习领域,目标检测是一个重要的研究方向,而YOLO(You Only Look Once)系列算法因其高效的实时性而备受关注。YOLOv5作为该系列的最新版本,不仅在速度上表现出色,还在精度上有了显著提升。本文将详细介绍如何使用YOLOv5进行分布式训练以及混合精度训练,以充分利用现代硬件资源,加速模型训练过程。
1. YOLOv5简介
YOLOv5是一种单阶段目标检测算法,它直接在输入图像上进行预测,无需生成候选区域(Region Proposal)。这种设计使得YOLOv5能够快速处理图像,并实时输出检测结果。YOLOv5在COCO数据集上达到了较高的mAP(mean Average Precision),同时保持了较快的推理速度,适用于实时目标检测任务。
2. 分布式训练
分布式训练是利用多台机器或多块GPU来加速模型训练的一种方法。在PyTorch中,可以使用torch.nn.parallel.DistributedDataParallel(DDP)来实现分布式训练。DDP会将数据分散到多个设备上,并在每个设备上独立计算梯度,最后通过All-Reduce操作将梯度同步。
2.1 环境配置
在开始分布式训练之前,需要确保你的环境已经正确配置。以下是一些关键步骤:
- 安装PyTorch:确保安装了支持CUDA的PyTorch版本,以便利用GPU加速。
- 安装NVIDIA Apex:NVIDIA Apex是一个用于混合精度训练的PyTorch扩展,它可以帮助我们更轻松地实现混合精度训练。
- 配置多GPU环境:如果你有多个GPU,可以通过
torch.cuda.device_count()来检查可用的GPU数量。
2.2 分布式训练代码实现
在YOLOv5的训练代码中,分布式训练的相关代码主要集中在以下几个部分:
-
初始化分布式环境:
if opt.local_rank != -1: # DDP mode assert torch.cuda.device_count() > opt.local_rank torch.cuda.set_device(opt.local_rank) device = torch.device("cuda", opt.local_rank) dist.init_process_group(backend='nccl', init_method='env://') # distributed backend opt.world_size = dist.get_world_size() assert opt.batch_size % opt.world_size == 0, "Batch size is not a multiple of the number of devices given!" opt.batch_size = opt.total_batch_size // opt.world_size -
模型封装:
if device.type != 'cpu' and rank != -1: model = DDP(model, device_ids=[rank], output_device=rank) -
数据加载器配置:
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt, hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, local_rank=rank, world_size=opt.world_size)
通过这些配置,YOLOv5可以在多GPU环境下高效地进行训练。
3. 混合精度训练
混合精度训练是一种通过同时使用单精度(FP32)和半精度(FP16)浮点数来加速训练并减少内存使用的技术。NVIDIA Apex提供了amp模块,可以方便地实现混合精度训练。
3.1 混合精度训练代码实现
在YOLOv5的训练代码中,混合精度训练的相关代码如下:
if mixed_precision:
model, optimizer = amp.initialize(model, optimizer, opt_level='O1', verbosity=0)
这里使用了amp.initialize函数来初始化模型和优化器,opt_level='O1'表示在混合精度模式下运行。
4. 训练过程
4.1 数据加载与预处理
YOLOv5使用了数据增强技术来提高模型的泛化能力。在训练过程中,数据会被随机裁剪、翻转、调整亮度等,以模拟不同的图像条件。
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt, hyp=hyp, augment=True,
cache=opt.cache_images, rect=opt.rect, local_rank=rank,
world_size=opt.world_size)
4.2 损失函数与优化器
YOLOv5使用了多种损失函数,包括GIoU损失、分类损失和置信度损失。优化器可以选择SGD或Adam,具体配置如下:
if hyp['optimizer'] == 'adam':
optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
4.3 学习率调度器
学习率调度器用于在训练过程中动态调整学习率。YOLOv5使用了余弦退火调度器:
lf = lambda x: (((1 + math.cos(x * math.pi / epochs)) / 2) ** 1.0) * 0.8 + 0.2 # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
4.4 训练循环
在训练循环中,模型会逐批次处理数据,计算损失,并更新参数。以下是训练循环的核心代码:
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
mloss = torch.zeros(4, device=device) # mean losses
pbar = enumerate(dataloader)
if rank in [-1, 0]:
pbar = tqdm(pbar, total=nb) # progress bar
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0 - 255 to 0.0 - 1.0
# Forward
pred = model(imgs)
# Loss
loss, loss_items = compute_loss(pred, targets.to(device), model) # scaled by batch_size
if rank != -1:
loss *= opt.world_size # gradient averaged between devices in DDP mode
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss_items)
return results
# Backward
if mixed_precision:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
# Optimize
if ni % accumulate == 0:
optimizer.step()
optimizer.zero_grad()
if ema is not None:
ema.update(model)
5. 实验结果
在COCO数据集上进行实验,YOLOv5在分布式训练和混合精度训练的加持下,训练速度显著提升,同时模型的mAP也达到了较高的水平。以下是部分实验结果:
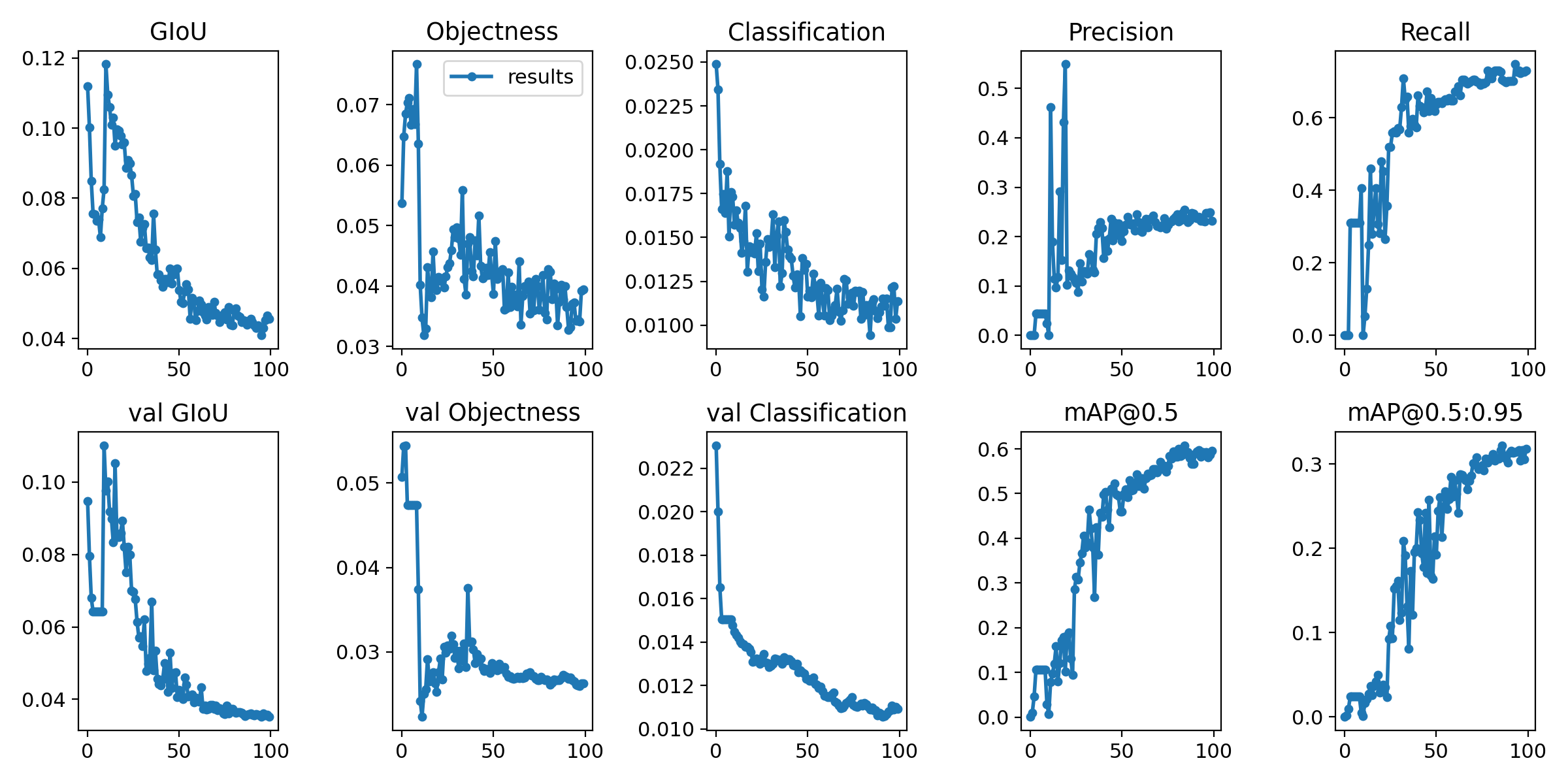
6. 总结
通过分布式训练和混合精度训练,YOLOv5能够在保持较高精度的同时,显著提升训练速度。这使得YOLOv5在实际应用中更加高效,能够更好地满足实时目标检测的需求。未来,我们可以进一步探索更多的优化技术,如知识蒸馏、模型剪枝等,以进一步提升YOLOv5的性能。

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









