






我们在进行写代码的时候,有时候会发现有的m = nn.Conv2d(16, 33, 3, stride=2,bias=False) ,bias是False,而默认的是True。为啥呢?是因为一般为False的时候,nn.Conv2d()后面通常接nn.BatchNorm2d(output)。
是因为BN里面有一个关键操作,
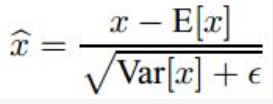
其中x1 = x0 * w0 + b0,而E[x1] = E[x0*w0] + b0, 所以对于分子而言,加没加偏置,没有影响;而对于下面分母而言,因为Var是方差操作,所以也没有影响(为什么没影响,回头问问你的数学老师就知道了)。所以,卷积之后,如果要接BN操作,最好是不设置偏置,因为不起作用,而且占显卡内存。
【PyTorch细节】卷积后的bias什么时候加,什么时候不加
最新推荐文章于 2025-04-01 20:54:59 发布



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











