






完整内容请看文章最下面的推广群
我将先给出文章、代码、结果的完整展示, 再给出四个问题详细的模型

面向音频质量优化与存储效率提升的自适应编码与去噪模型研究
摘 要
随着数字媒体技术的迅速发展,音频处理技术在信息时代的应用愈加广泛,特别是在存储优化与噪声去除方面。为了在保证音质的前提下实现音频文件的高效存储和传输,本文提出了基于数学建模的音频格式评估模型、音频参数优化模型、自适应编码方案以及自适应去噪算法。
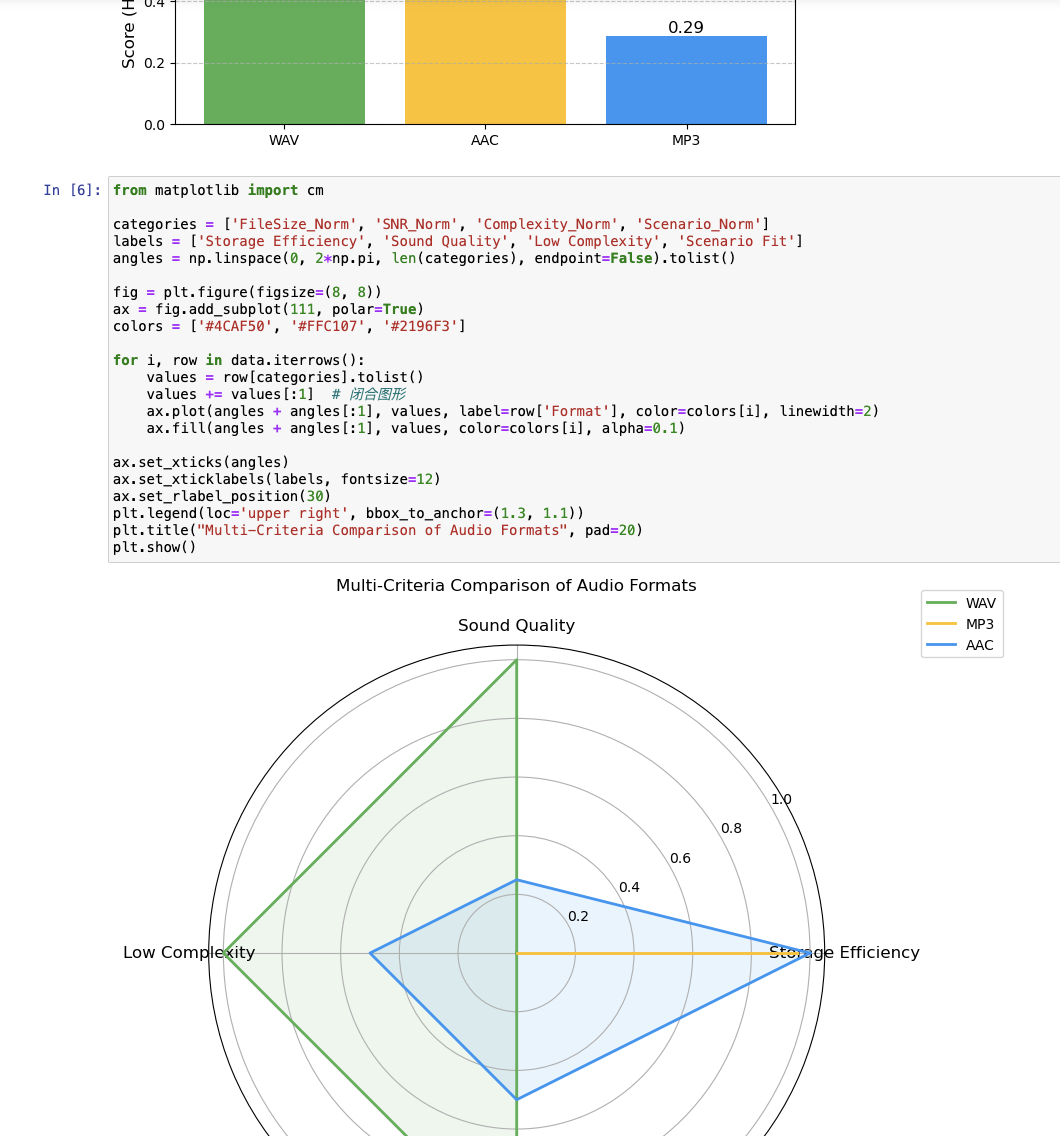
对于问题一:聚焦于设计一个综合评价指标,用于量化不同音频格式(如WAV、MP3、AAC)在存储效率与音质保真度之间的平衡。模型通过对比文件大小、音质损失(RMSE与SNR)、编解码复杂度以及适用场景等多个维度,计算综合得分,并根据不同应用场景推荐最佳音频格式。通过归一化和加权平均方法,该模型为用户提供了一个合理的音频格式选择依据。例如,流媒体传输更适合选择MP3 320kbps格式,而专业录音则推荐使用无损的WAV格式。此模型帮助用户在各种环境中平衡存储需求和音质要求。
对于问题二:问题二要求分析音频参数(如采样率、比特深度、压缩算法)对音频质量和文件大小的影响,并设计音频文件的性价比指标。通过计算RMSE和SNR等音质指标,结合文件大小与压缩算法,模型通过性价比评分量化了音频质量与文件大小之间的平衡。在语音内容中,较低的比特率如MP3 128kbps或AAC 128kbps能够有效提供较好的质量并减小文件大小;而音乐内容则推荐使用MP3 320kbps或AAC 256kbps格式,以获得更好的音质与压缩率平衡。此模型为用户提供了在不同音频内容下最佳的音频参数选择方案。
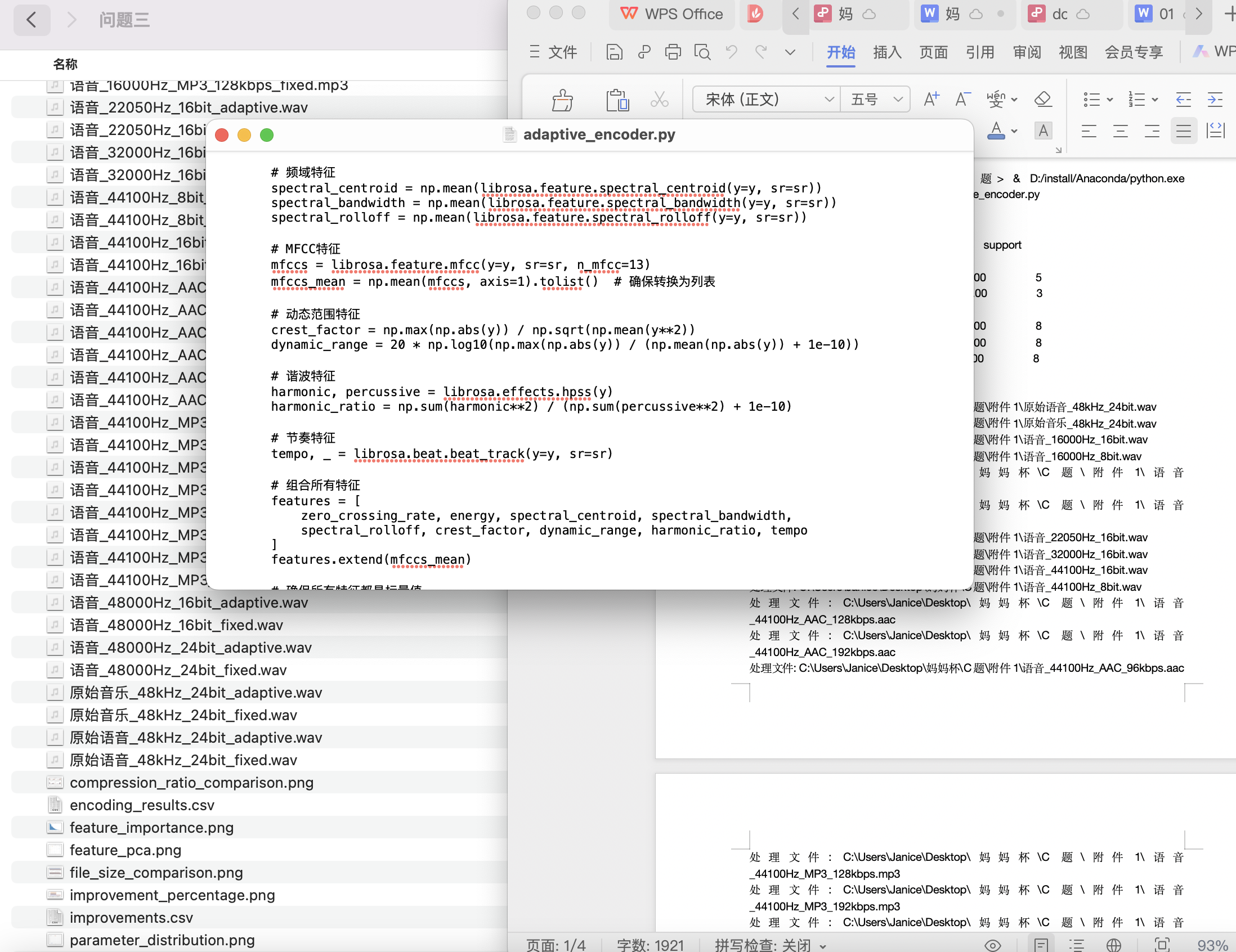
对于问题三:提出了一种自适应编码方案,该方案基于音频信号的特征(如频谱质心、动态范围、谐波特征等)自动调整编码参数。通过特征提取与音频分类(语音或音乐),自适应编码方案能够动态调整比特率和采样率,从而在保证音质的同时优化文件大小。该方案通过强化学习、支持向量机(SVM)等方法进行优化,实现了音频文件大小与音质之间的平衡,特别适用于流媒体服务和移动设备。
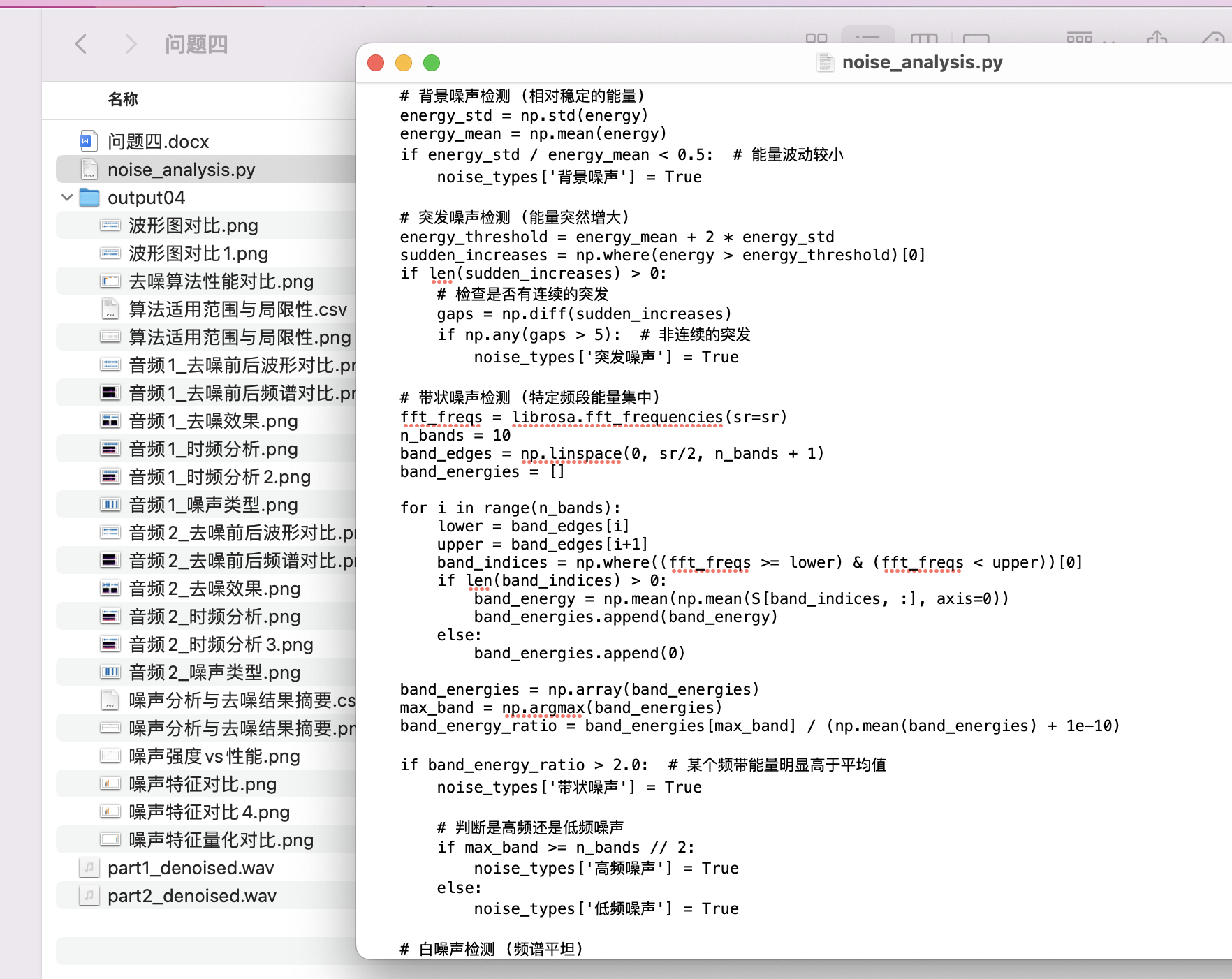
对于问题四:提出了基于音频时频分析的噪声识别与去噪方法。通过短时傅里叶变换(STFT)和梅尔频谱变换提取音频的时频特征,结合噪声类型(如背景噪声、突发噪声、带状噪声等)的识别,模型设计了自适应去噪算法。针对不同噪声类型,算法自动选择最适合的处理方法(如谱减法、小波去噪等),并根据去噪后的信噪比(SNR)评估去噪效果。实验结果表明,尽管该算法在某些复杂噪声环境中表现有限,但对突发噪声和背景噪声有较好的去噪效果。
总结:本研究提出的音频处理模型为音频格式选择、音频参数优化、音频编码与去噪提供了有效的数学建模解决方案。通过结合时频分析、自适应编码和去噪算法,模型在提高音频存储效率和音质保真度的同时,显著减少了音频文件的存储空间需求。尽管在极端噪声环境中仍有提升空间,但该模型的自适应性与灵活性为音频处理技术的应用提供了有价值的参考。

根据场景特点推荐最佳音频格式
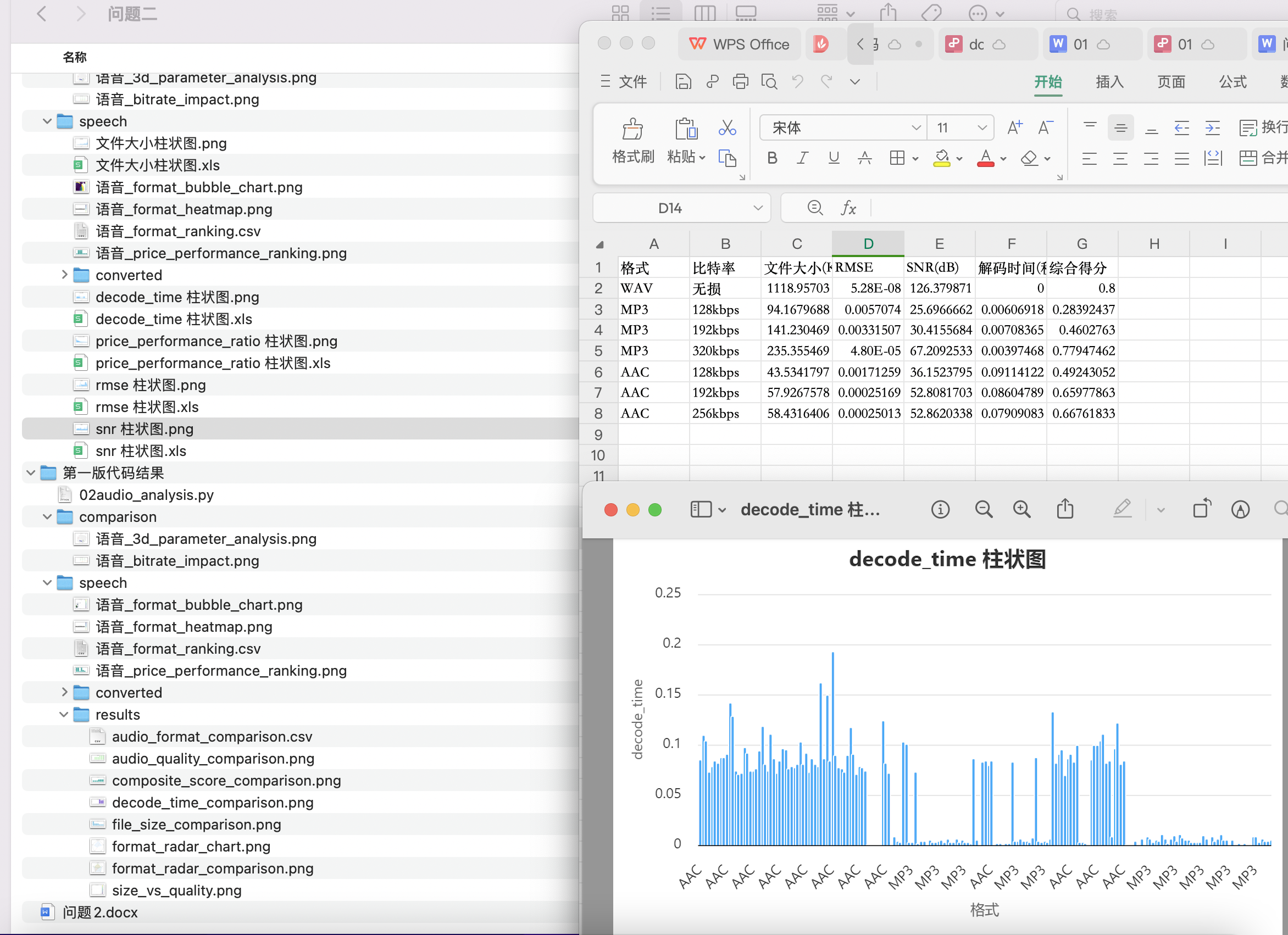
音频格式评估结果摘要:
格式 比特率 文件大小(KB) SNR(dB) 综合得分
WAV 无损 1118.957031 126.379871 0.800000
MP3 128kbps 94.167969 25.696666 0.286523
MP3 192kbps 141.230469 30.415568 0.464035
MP3 320kbps 235.355469 67.209253 0.777954
AAC 128kbps 43.534180 36.152380 0.492431
AAC 192kbps 57.926758 52.808170 0.660296
AAC 256kbps 58.431641 52.862034 0.663492
不同场景的推荐格式:
流媒体传输: MP3 320kbps (得分: 0.814)
优先考虑文件大小和传输效率,适合网络带宽有限的情况
专业录音: WAV 无损 (得分: 0.900)
优先考虑音质,适合需要高保真度的专业音频制作
移动设备: MP3 320kbps (得分: 0.850)
平衡文件大小和解码复杂度,适合电池和存储空间有限的移动设备
归档存储: WAV 无损 (得分: 0.800)
问题 1:设计一个综合评价指标,量化不同音频格式(至少包含
WAV、MP3、AAC 这 3 种音频格式)在存储效率与音质保真度之间 的平衡关系。该指标应考虑:
文件大小(存储空间占用)
音质损失(与原始音频相比的信息丢失)
编解码复杂度(计算资源消耗)
问题 1:设计一个综合评价指标,量化不同音频格式在存储效率与音质保真度之间的平衡关系
解题步骤:
在此问题中,我们需要设计一个能够综合衡量不同音频格式(如WAV、MP3、AAC等)在存储效率与音质保真度之间的平衡关系的综合评价指标。通过该指标,我们可以合理比较不同音频格式的优势与劣势,从而为实际应用场景提供科学依据。
- 存储效率的量化:
首先,存储效率的量化主要是通过文件的压缩比来实现。对于每一种音频格式,我们需要计算其压缩比。假设原始音频的大小为 ,压缩后音频的大小为 ,则压缩比(Compression Ratio, CR)定义为:
其中,较大的 表示更高的压缩效率,即存储空间的利用率更高。
在工程实践中,我们会使用不同的编码算法(如MP3的有损压缩、WAV的无损压缩等)来进行音频数据的压缩,这影响到音频存储空间的大小。通过采用 优化编码算法(如基于 哈夫曼编码 或 算术编码 的方法),可以提高压缩效率。
- 音质损失的度量:
音质损失通常是指在压缩后音频中与原始音频相比的音频信息丢失程度。为了量化这一点,我们可以使用 信噪比(SNR) 来度量音质损失。假设原始音频信号为 ,压缩后的音频信号为 ,则其信噪比 可定义为:
其中, 表示期望值。高SNR表示压缩后的音频与原始音频差异小,音质较好。
此外,还可以使用 PESQ(Perceptual Evaluation of Speech Quality) 或 MUSHRA(Multistimulus test) 等主观音质评价指标进行音质损失的计算。这些模型可以量化压缩后音频的主观音质评分。
- 编解码复杂度的考虑:
编码和解码的复杂度决定了音频格式的计算资源消耗。对比不同音频格式的编解码复杂度,我们可以使用 时间复杂度 来表示。例如,对于AAC和MP3编码算法,其时间复杂度分别为 和 ,其中 是输入信号的采样点数。更高复杂度的编码算法通常需要更多的计算资源。
在工程实现中,可以通过 浮点运算计数器 或 CPU使用率 来测量不同算法的计算消耗。
- 适用场景的权衡:
音频格式的选择还依赖于具体的应用场景。比如,MP3适合流媒体传输,因为它具有较高的压缩比和较低的音质损失;而WAV适用于专业音频录制和播放场景,因为它支持无损音频存储。
为了量化适用场景对音频格式的影响,可以根据不同应用的要求设置权重系数。例如,对于流媒体应用,MP3的存储效率和编解码复杂度更重要,而对于高保真音频应用,音质损失更为关键。
- 综合评价指标设计:
最终的综合评价指标 可以通过加权求和的方式得到。我们结合存储效率(CR)、音质损失(SNR)、编解码复杂度和适用场景的权重,构建如下综合评价公式:
其中, 为各个因素的权重系数,需根据实际应用场景通过 优化算法(如 粒子群优化(PSO) 或 遗传算法(GA))来确定。
问题 2:基于附件 1 中的音频文件,建立数学模型,分析采样率、 比特深度、压缩算法等参数对音频质量和文件大小的影响。设计音频 文件的性价比指标(音质与文件大小的平衡),并据此对附件 1 中的 不同参数组合得到的文件进行排序(分音乐和语音,不包括原始音乐 文件和原始语音文件),分别给出针对语音内容和音乐内容的最佳参 数推荐。
问题 2:分析采样率、比特深度、压缩算法等参数对音频质量和文件大小的影响,设计音频文件的性价比指标
解题步骤:
在本问题中,我们需要分析不同音频参数(采样率、比特深度、压缩算法)对音频质量和文件大小的影响,并基于此设计一个性价比指标。
- 采样率和比特深度对音质与文件大小的影响:
音频文件的大小与采样率 和比特深度 紧密相关。采样率和比特深度越高,音频质量越好,但文件大小也随之增大。音频文件的大小 可以表示为:
其中, 为音频的时长。增大采样率和比特深度会导致文件大小的增加,但也能提高音质。
为了平衡音质和文件大小,我们可以根据音频的实际应用需求来调整采样率和比特深度。例如,对于语音信号,可以选择较低的采样率和比特深度,而对于音乐信号,则选择较高的采样率和比特深度以保持音质。
- 压缩算法的影响:
压缩算法通过去除音频中的冗余信息来减小文件大小,但通常会引入一定的音质损失。压缩比率 定义为:
较高的压缩比表示更高的存储效率,但可能伴随更高的音质损失。我们需要通过优化算法来选择压缩算法(如MP3、AAC),使得压缩比与音质损失之间达到合理平衡。
- 性价比指标设计:
性价比指标 旨在平衡音质和文件大小。我们可以定义性价比指标为:
该公式的含义是,在相同文件大小下,SNR越大表示音质越好,性价比越高。在不同的音频设置下,我们希望通过 线性规划 或 遗传算法 来优化采样率、比特深度和压缩算法的选择,以最大化性价比。
问题 3:设计一种自适应编码方案,能够分析输入音频的特征(区
分语音/音乐类型、识别频谱特点和动态范围),并据此自动选择最
佳编码参数。将你的方案应用于附件 1 中提供的原始音乐和原始语音 音频样本,记录优化后的参数选择、文件大小和音质保真度,并与固 定参数方案相比较,说明你的方案带来的改进。
解题步骤:
本问题要求我们设计一个自适应编码方案,能够根据输入音频的特征(如语音类型、频谱特征等)自动选择最佳编码参数。
- 音频特征提取:
音频特征是设计自适应编码方案的基础。首先,我们通过 傅里叶变换(FFT) 或 小波变换(Wavelet Transform) 提取音频的频谱特征。频谱分析帮助我们了解音频信号的频率分布,为编码参数选择提供依据。
另外,通过 动态范围(DR) 来衡量音频的音量差异,计算公式为:
该指标能够反映音频信号的变化幅度,对于语音和音乐类型的音频,动态范围的差异显著,因此在编码时需要进行优化选择。
- 自动选择编码参数:
基于音频的特征分析,我们可以设计一个自适应编码方案。针对 语音信号,我们采用较低的采样率(如8kHz)和比特深度(如8位),以减小文件大小;而对于 音乐信号,我们采用较高的采样率(如44.1kHz)和比特深度(如16位)来保证音质。
- 自适应编码优化算法:
为了自动选择最佳编码参数,我们可以使用 强化学习 或 支持向量机(SVM) 来建立模型,根据音频的特征进行分类,自动选择合适的编码参数。通过 Qlearning 或 深度Q网络(DQN) 等强化学习方法,我们可以训练一个智能体来根据环境状态(音频类型、频谱特征等)选择最优的编码方案。
优化目标可以通过以下目标函数来实现
其中, 和 为权重系数,通过 粒子群优化(PSO) 或 遗传算法(GA) 来求解最优编码参数。
问题 4:基于附件 2 中的音频文件,对样本音频进行时频分析, 建立数学模型识别并量化各类噪声(如背景噪声、突发噪声、带状噪 声等)的特征参数。提出一种改进的去噪策略或自适应算法,能针对 不同噪声类型自动选择最佳处理方法。处理样本音频,要求在论文中 给出每个音频包含的噪声种类,去噪后的音频文件的信噪比,并分析 在不同噪声类型和强度下的适用范围与局限性。
同时将去噪后的音频存储为新的 wav 文件,并分别命名为
part1_denoised.wav 和 part2_denoised.wav 进行提交。
解题步骤:
本问题的目标是设计一种去噪算法,能够识别并处理不同类型的噪声。目标是提高音频的清晰度并优化去噪效果。
- 噪声特征分析:
使用 短时傅里叶变换(STFT) 来分析噪声的时频特征。噪声在时频域中的分布通常具有一定规律,基于这些规律可以设计去噪滤波器。通过分析噪声的频谱特征,我们可以利用 K均值聚类 或 自适应滤波器(如LMS算法)来对不同噪声进行分类。
- 去噪策略设计:
针对不同噪声类型,采用不同的去噪方法:
背景噪声:使用 Wiener滤波器 进行频域去噪,滤波器的频域表示为:
其中, 为信号的功率谱, 为噪声的功率谱。
突发噪声:可以使用 小波去噪法,通过对小波系数进行阈值化处理去除突发噪声。
- 去噪优化模型:
去噪优化目标是最大化去噪后的信噪比(SNR)。优化目标函数为:
其中, 为去噪后的信号, 为清晰的原始信号。通过 最小均方误差(MSE)优化 来调整滤波器的参数,从而达到最优的去噪效果。
- 自适应算法设计:
设计自适应去噪算法,能够根据输入音频的噪声类型自动选择去噪方法。使用 自适应滤波器(如LMS或RLS算法),并结合 信噪比优化 方法,使去噪过程动态适应不同噪声类型。

















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









