







 本文讨论了将异常作为业务逻辑处理可能导致的性能问题,并介绍了为何应避免这种做法。通过对比异常处理与tryxxx方法的性能差异,强调了异常处理的高昂开销,包括从用户态到内核态的切换和堆栈跟踪的获取。文章还深入探讨了StackTrace的生成时机,并在CLR中寻找答案。
本文讨论了将异常作为业务逻辑处理可能导致的性能问题,并介绍了为何应避免这种做法。通过对比异常处理与tryxxx方法的性能差异,强调了异常处理的高昂开销,包括从用户态到内核态的切换和堆栈跟踪的获取。文章还深入探讨了StackTrace的生成时机,并在CLR中寻找答案。
一:背景
在项目应该或多或少的见过有人把异常当做业务逻辑处理的情况(┬_┬),比如说判断一个数字是否为整数,就想当然的用try catch包起来,再进行 int.Parse,如果抛异常就说明不是整数,简单粗暴,也不需要写正则或者其他逻辑,再比如一个字符串强制转化为Enum,直接用Enum.Parse,可能是因为对异常的开销不是特别了解,这种不好的使用习惯也许被官方发现了,后续给我们补了很多的Try前缀的方法,比如:int.TryParse , Enum.TryParse, dict.TryGetValue ,用代码展示如下:
//原始写法
var num = int.Parse("1");
//使用try方式
var result = 0;
var b = int.TryParse("1", out result);
用Try系列方法没毛病,但这写法让人吐槽,还要单独定义result变量,没撤,官方还得靠我们这些开发者给他们发扬光大😄😄😄,终于在C# 7.0 中新增了一个 out variables 语法糖。
//try out 变量模式
var c = int.TryParse("1", out int result2);
这种 out 变量 模式就🐮👃了,一个方法获取两个值,还没有抛异常的风险。
二:为什么要用tryxxx方法
有了tryxxx方法之后,你就应该明白微软已经在提醒我们开发人员不要滥用异常,尤其在可预知可预见的场景下,毕竟他们知道异常的开销真的是太大了,不知者不怪哈。
1. 肉眼看得见的低性能
为了让大家肉眼能看见,我们就用异常方法和tryxxx方法做一个性能比较,迭代50w次,看看各自的性能如何?
for (int i = 0; i < 3; i++)
{
var watch = Stopwatch.StartNew();
for (int k = 0; k < 50000; k++)
{
try
{
var num = int.Parse("xxx");
}
catch (Exception ex) { }
}
watch.Stop();
Console.WriteLine($"i={i + 1},耗费:{watch.ElapsedMilliseconds}");
}
Console.WriteLine("---------------------------------------------");
for (int i = 0; i < 3; i++)
{
var watch = Stopwatch.StartNew();
for (int k = 0; k < 50000; k++)
{
var num = int.TryParse("xxx", out int reuslt);
}
watch.Stop();
Console.WriteLine($"i={i + 1},耗费:{watch.ElapsedMilliseconds}");
}
Console.ReadLine();
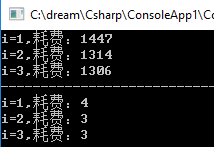
看结果还挺吓人的,相差480倍, 好熟悉的一个数字。。。 南朝四百八十寺,多少楼台烟雨中 😄😄😄
三: 异常的超强开销
为什么异常有那么大的开销? 只有知己知彼才能心中有数,看过我多线程视频的朋友应该知道,线程的创建和销毁代价都是非常大的,其中有一项就是需要代码从用户态切换到了内核态,毕竟线程是操作系统层面的事情,和你CLR无关,CLR只是做了一层系统包装而已,其实很多人都想不到,我们用的 try catch finally 底层也是封装了操作系统层面的(Windows 结构化异常处理),也叫做SEH,什么意思? 就是当你throw之后,代码需要从用户态切换到内核态,这个开销是不会小的,还有一个开销来自于Exception中的StackTrace,这里面的值需要从当前异常的线程栈中去抓取调用堆栈,栈越深,开销就越大。
1. 从用户态到内核态
大家肯定会说,甭那么玄乎,凡事都要讲个证据, Do more,Talk less, 这里我准备分两种情况讲解。
<1> 有catch情况
准备在catch的时候阻塞住,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











