







系列篇章💥
目录
前言
在人工智能大模型领域,多模态视觉语言模型(VLM)正成为研究和应用的热点。它能够处理文本和图像等多种模态的信息,为人工智能带来更丰富的交互能力和更广泛的应用场景。然而,大多数VLM模型规模庞大,训练成本高昂,对硬件资源要求苛刻,限制了其在更广泛场景下的应用和探索;今天介绍一个超小的多模态视觉语言模型(MiniMind-V)。
一、项目概述
MiniMind-V是由开发者jingyaogong开源的超小型多模态视觉语言模型(VLM),旨在以极低成本(仅需1.3元人民币和1小时)从零开始训练,支持图像识别、对话和多模态推理。其最小版本参数规模为26M,体积仅为GPT-3的1/7000,适合个人GPU快速训练和推理。

MiniMind-V 系列目前已完成了以下型号模型训练,最小仅需26M (0.026B),即可具备识图和对话的能力!
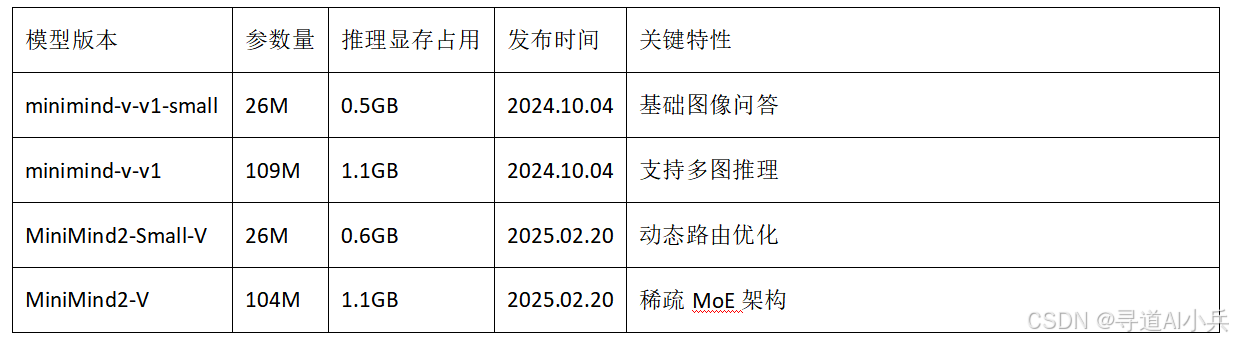
注:模型体积仅为GPT-3的1/7000,可在RTX 3090上完成全流程训练。
二、功能特点
-
低成本:MiniMind-V的训练成本极低,仅需1.3元的GPU服务器租用成本和1小时的训练时间,这种高效率的训练方式使得它在资源有限的环境下也能发挥出色的表现,大大降低了开发成本,使更多的开发者能够轻松上手。
-
小体积:MiniMind-V的最小版本仅26M参数,体积非常小巧。这意味着它可以在个人设备上轻松进行推理和训练,无需依赖高性能的硬件设施,进一步降低了硬件门槛,让普通用户也能体验到多模态AI的乐趣。
-
多模态处理:MiniMind-V具备强大的多模态处理能力,能够同时处理文本和图像等多种模态的信息。它不仅可以进行图像识别,还能与用户进行对话互动,为各种应用场景提供了更丰富的可能性,如智能助手、图像描述生成等。
-
代码完整:MiniMind-V项目提供了完整的代码框架,涵盖了VLM大模型的极简结构、数据集清洗、预训练、监督微调等全过程代码。这种全链路的开源复现,不仅降低了学习门槛,还为开发者提供了极大的便利,使他们能够快速理解和应用多模态AI技术,加速项目的开发和部署。
三、技术原理
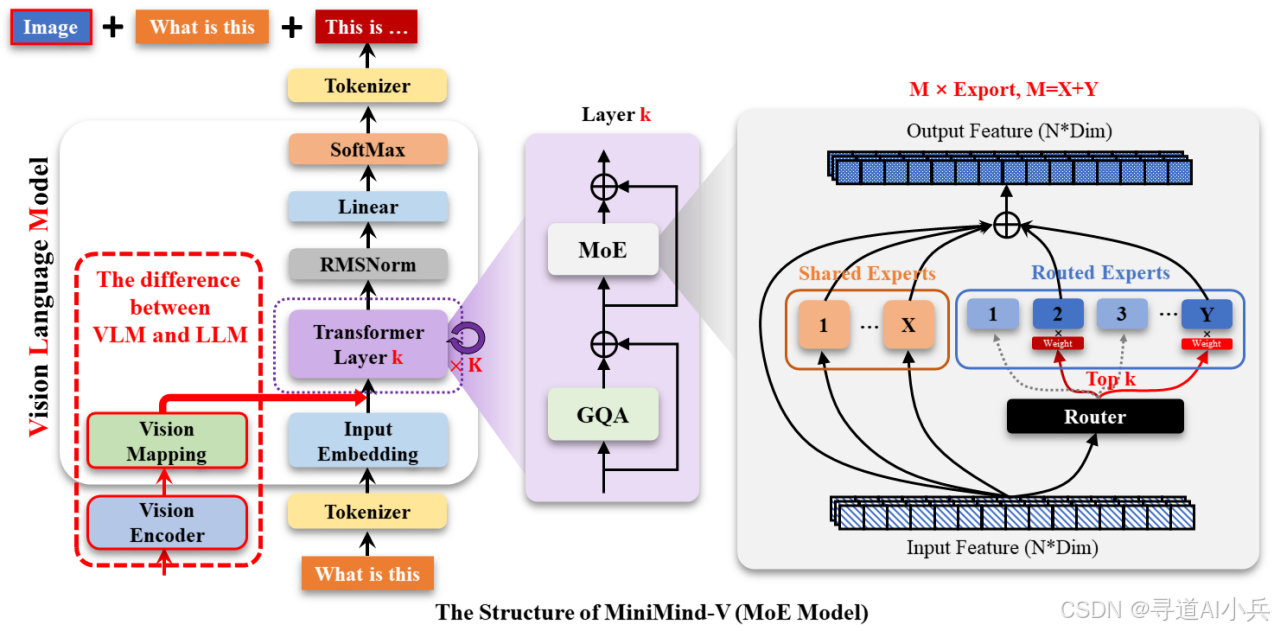
Transformer架构:MiniMind-V基于Transformer的Decoder-Only结构,类似于GPT系列。它采用预标准化(Pre-Norm)和RMSNorm归一化方法,提升模型性能。使用SwiGLU激活函数替代ReLU,提高训练效率。
混合专家(MoE)技术:在前馈网络(FFN)中引入混合专家模块,将计算资源动态分配给不同的“专家”,通过共享和隔离技术提升小模型的学习能力和效率。
多模态处理:MiniMind-V通过视觉编码器(如CLIP模型)将图像转化为特征向量,与文本Token结合,实现对图像和文本的多模态处理。
轻量化的训练流程:支持多种训练技术,包括预训练、监督微调、LoRA微调、直接偏好优化(DPO)和模型蒸馏
四、应用场景
(一)图像识别与描述
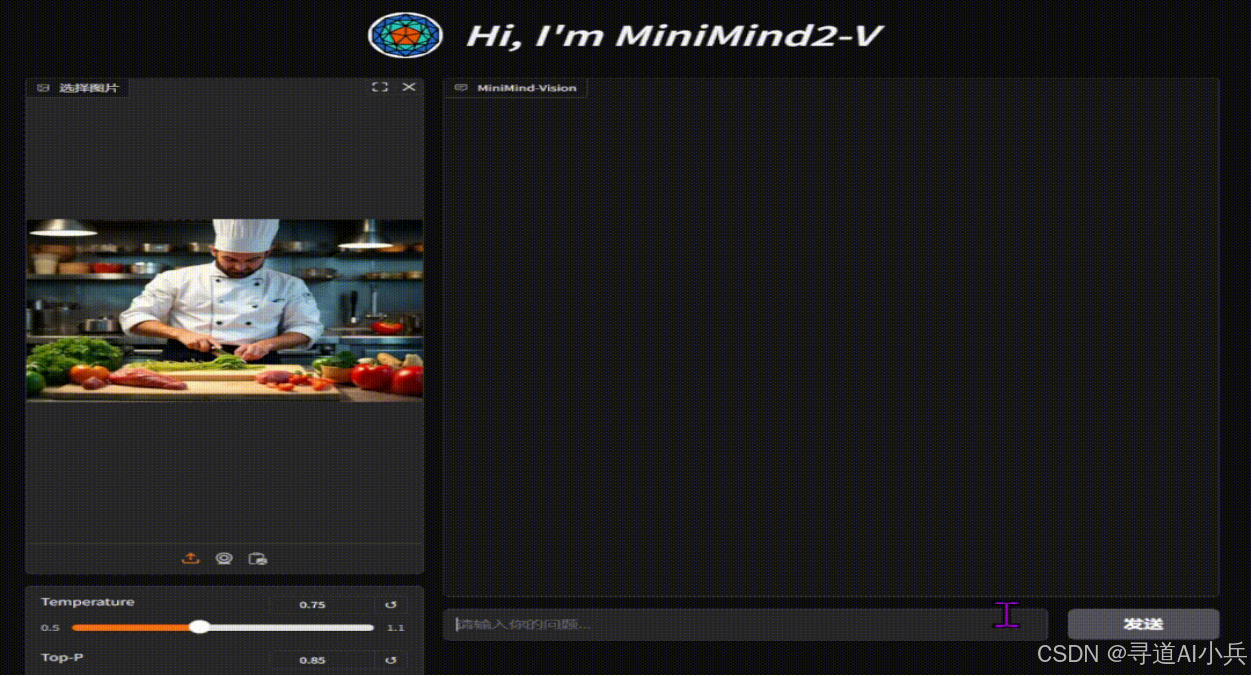
MiniMind-V可以用于图像识别和描述任务,用户上传一张图片,模型会对图片中的物体、场景等进行详细描述。这在智能相册、图像搜索等领域有广泛的应用前景。例如,在智能相册中,模型可以自动为图片添加描述信息,方便用户快速查找和管理图片。
(二)视觉问答系统
基于MiniMind-V的多模态交互能力,可以构建视觉问答系统。用户可以上传图片并提出相关问题,模型会根据图片内容进行回答。这种系统可以应用于教育、娱乐等领域,例如在教育领域,学生可以上传科学实验图片并询问相关问题,模型可以提供详细的解答。
(三)智能客服
在电商、旅游等行业,智能客服是一个重要的应用场景。MiniMind-V可以集成到智能客服系统中,处理包含图片的客户咨询。例如,客户上传商品图片并询问商品的特点、价格等信息,模型可以根据图片内容和预设的知识进行回答,提高客服的效率和服务质量。
(四)视频理解
虽然MiniMind-V主要是为图像和文本处理设计的,但通过扩展可以实现视频理解能力。可以参考MiniCPM-V 2.6的方法,从视频中提取关键帧,然后进行多图像推理。这在视频监控、视频内容分析等领域有潜在的应用价值。
五、快速使用
在开始使用 MiniMind-V 之前,需要准备好相应的软硬件环境。
(一)环境准备
1. 硬件配置
以下是参考的硬件配置:
CPU:Intel® Core™ i9 - 10980XE CPU @ 3.00GHz
RAM:128 GB
GPU:NVIDIA GeForce RTX 3090(24GB) * 8
操作系统:Ubuntu20.04
CUDA:CUDA12.2
Python:Python==3.10.16
2. 安装依赖
# 克隆代码仓库
git clone https://github.com/jingyaogong/minimind-v
cd minimind-v
# 安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
3. 下载 Visual Encoder 模型
# 下载 clip-vit-base-patch16 模型
git clone https://huggingface.co/openai/clip-vit-base-patch16 ./model/vision_model
(二)测试已有模型效果
1. 下载预训练模型
git clone https://huggingface.co/jingyaogong/MiniMind2-V
2. 命令行问答
# 测试模型效果,load=1 表示加载 Hugging Face 模型
python eval_vlm.py --load 1
3. 启动 WebUI(可选)
python web_demo_vlm.py
(三)从零开始训练模型
1. 下载数据集
从 ModelScope 或 Hugging Face 下载数据集。
数据集包括 *.jsonl 格式的问答数据和配套的图片数据。
解压数据集到 ./dataset 目录。
2. 预训练(学习图像描述)
python train_pretrain_vlm.py --epochs 4
预训练完成后,模型权重将保存到 ./out/pretrain_vlm_*.pth。
3. 监督微调(学习看图对话方式)
python train_sft_vlm.py --epochs 4
微调完成后,模型权重将保存到 ./out/sft_vlm_*.pth。
4. 测试训练后的模型效果
python eval_vlm.py --model_mode 1
--model_mode 1 表示测试监督微调后的模型效果。
结语
MiniMind-V项目为多模态视觉语言模型的开发和应用提供了一个低成本、轻量级的解决方案。它以其独特的技术原理、丰富的功能特点、广泛的应用场景和良好的性能表现,吸引了众多开发者和研究者的关注。如果你也对它在各方面的应用感兴趣,不妨尝试使用体验一下。
GitHub地址:https://github.com/jingyaogong/minimind-v

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!


















 2402
2402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











