







【数据+代码】LightGBM+Optuna实现回归分析
01引言
本文涵盖主题:数据预处理、数据探索性分析、LightGBM+OPTUNA模型训练和结果分析四个方面。

本文数据集采用奥迪汽车数据,使用多种算法与LightGBM+OPTUNA回归模型进行对比。
该项目的结构如下:
-
数据清理
-
探索性数据分析
-
ML 建模的数据准备
-
机器学习建模:
-
- 线性回归模型
- LightGBM 与 OPTUNA
-
结果分析
本文主要结果汇总仪表板:
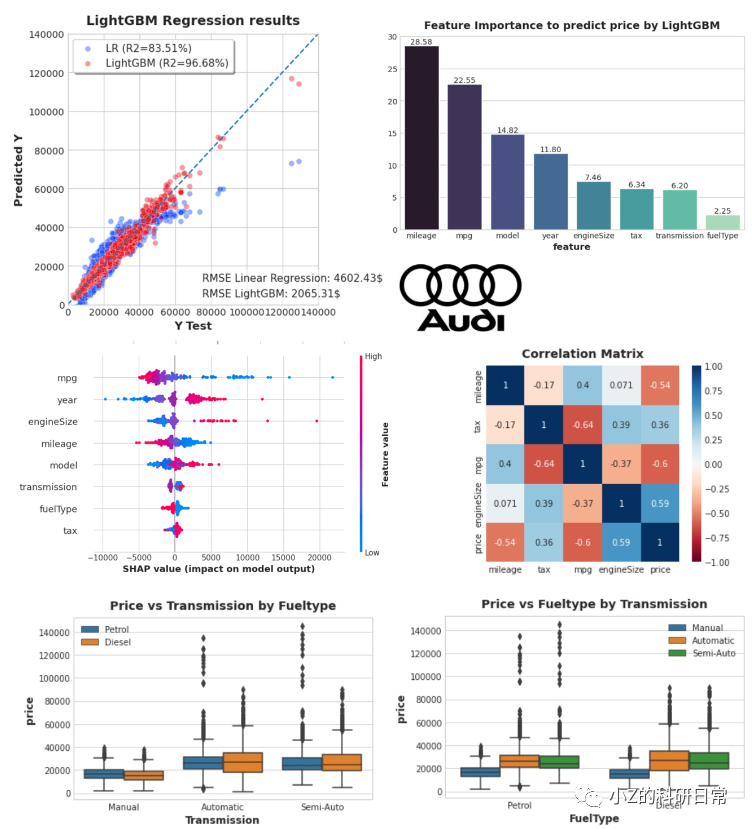
本期内容『数据+代码』已上传百度网盘。有需要的朋友可以关注公众号【小Z的科研日常】,后台回复关键词[LightGBM]获取。
02
╱数据预处理╱
首先将数据进行读取,同时在模型部署过程中,注意到模型列中的值前面有一个空白的空间。出于此原因,决定在读取数据过程中添加 “skipinitialspace=True”。并将重新排序,先将分类变量分组,再将数字变量分组。
df=pd.read_csv('audi.csv',skipinitialspace=True)
print(df.head())
缺失值
其次观察数据集中各列特征中是否存在缺失值,并将year转换为object类型。经输出数据分析,本数据集中并无缺失值。我们需要了解,除了"里程数"之外,其他特征是否能独特地识别一辆车。
df=df[['model','year','transmission','fuelType','mileage','tax','mpg','engineSize','price']]
print(df.head(10))
print(df.info())
df['year'] = df['year'].astype(object)
df_clean = df.copy()
df_models=df.drop(['price','mileage','tax'], axis=1).drop_duplicates().sort_values(by=['model','year','fuelType'])
print(df_models.head())
经观察,mpg和发动机尺寸不是由汽车型号、年份、变速器和燃料类型唯一识别的。
为了分析数据中的数值特征,我们将首先定义一个函数,绘制所有数字特征的分布直方图和箱线图。
def num_plots_all(df):
fig, ax = plt.subplots(2,5, figsize=(15,5), gridspec_kw={"height_ratios": (.2, .8)})
sns.boxplot(x='mileage', data=df, ax=ax[0,0])
ax[0,0].set_title('Mileage distribution')
ax[0,0].set(yticks=[], xticks=[])
ax[0,0].axis('off')
sns.boxplot(x='tax', data=df, ax=ax[0,1])
ax[0,1].set_title('Tax distribution')
ax[0,1].set(yticks=[], xticks=[])
ax[0,1].axis('off')
sns.boxplot(x='mpg', data=df, ax=ax[0,2])
ax[0,2].set_title('MPG distribution')
ax[0,2].set(yticks=[], xticks=[])
ax[0,2].axis('off')
sns.boxplot(x='engineSize', data=df, ax=ax[0,3])
ax[0,3].set_title('EngineSize distribution')
ax[0,3].set(yticks=[], xticks=[])
ax[0,3].axis('off')
sns.boxplot(x='price', data=df, ax=ax[0,4])
ax[0,4].set_title('Price distribution')
ax[0,4].set(yticks=[], xticks=[])
ax[0,4].axis('off')
sns.histplot(x='mileage', data=df, ax=ax[1,0])
sns.histplot(x='tax', data=df, ax=ax[1,1])
sns.histplot(x='mpg', data=df, ax=ax[1,2])
sns.histplot(x='engineSize', data=df, ax=ax[1,3])
sns.histplot(x='price', data=df, ax=ax[1,4])
plt.show()
num_plots_all(df)
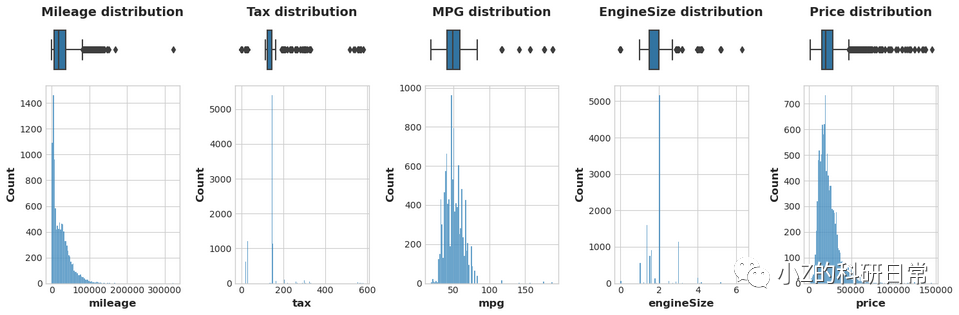
从这些图中我们可以看到,数值特征呈现出所谓的 "长尾 "分布,有一些异常值。
通过查看直方图、箱线图和汇总统计,我们可以对数字特征有一个初步的了解:
-
里程数:平均数约为2.5万,由于存在一个32.3万英里的异常值(这个数字太高了),我们将删除这个离群值,以获得一个更准确的数据表示。
-
税收:平均数约为126,与里程数类似,这是由于该特征存在一些非常高的数值。我们需要对这些数值进行处理,以获得一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1029
1029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









