









Human4DiT,使用 4D Diffusion Transformer 生成自由视角人物视频。又一个根据一张图,生成人物动画视频的项目,效果如下视频所示。

给定参考图像、SMPL序列和摄像机参数,Human4DiT能够生成自由视图动态人体视频。

相关链接
项目地址:https://human4dit.github.io/
论文链接:https://arxiv.org/html/2405.17405v1
论文阅读

Human4DiT:使用 4D Diffusion Transformer 生成自由视角人物视频
摘要
我们提出了一种新的方法,用于从单个图像下在任意观点下产生高质量的时空连贯的人类视频。我们的框架结合了U-NET的优势,以进行准确的状态注入和扩散变压器,以捕获跨观点和时间的全局相关性。核心是级联的4D变压器体系结构,可将注意力跨越跨视图,时间和空间维度分配,从而可以对4D空间进行有效的建模。通过将人类身份,摄像机参数和时间信号注入相应的变压器来实现精确的调理。为了训练该模型,我们策划了一个跨越图像,视频,多视图数据和3D/4D扫描的多维数据集以及多维培训策略。我们的方法克服了基于基于GAN或基于UNET的扩散模型的先前方法的局限性,这些模型在复杂的动作和观点变化中挣扎。通过广泛的实验,我们证明了我们的方法能够综合现实,连贯和自由观看的人类视频,为在虚拟现实和动画等领域中的高级多媒体应用铺平了道路。
方法
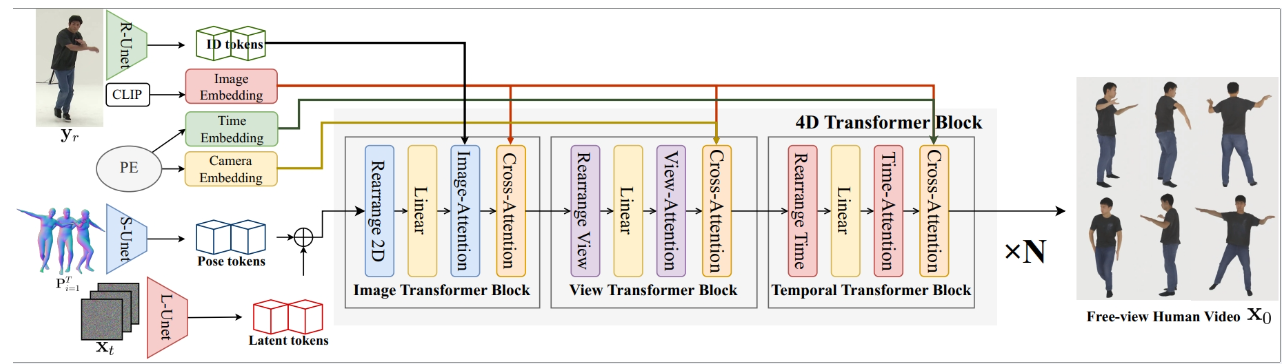
Human4DiT的pipeline。我们的框架基于四维扩散转换器,它采用由二维图像、视图转换器和时间块组成的级联结构。输入包含参考图像、动态SMPL序列和相机参数。

从生成的噪声潜在表示开始,我们然后用多个条件对其去噪。首先,设计二维图像变换块来捕获每帧内的空间自注意力。此外,还注入了从参考图像中提取的人的身份,以保证身份的一致性。其次,我们使用视图转换块来学习不同视点之间的对应关系。最后,我们采用时间转换器捕捉时间相关性与时间嵌入。
效果展示
单目视频


多视角视频

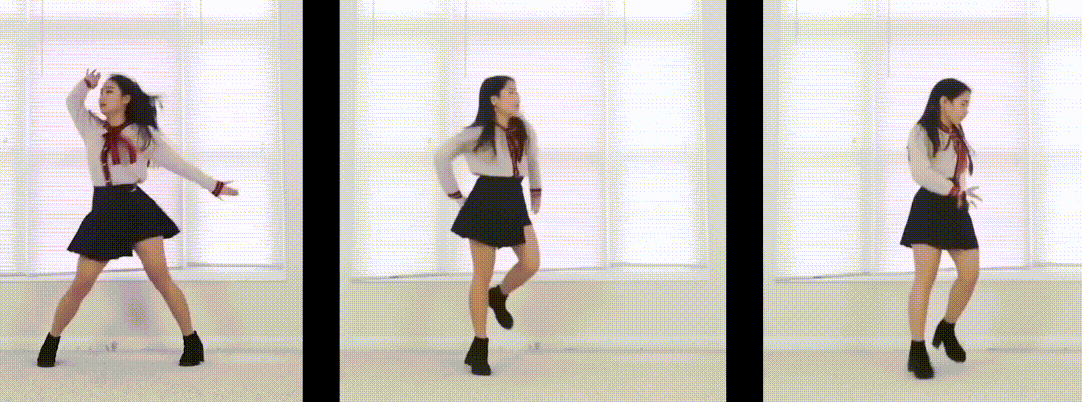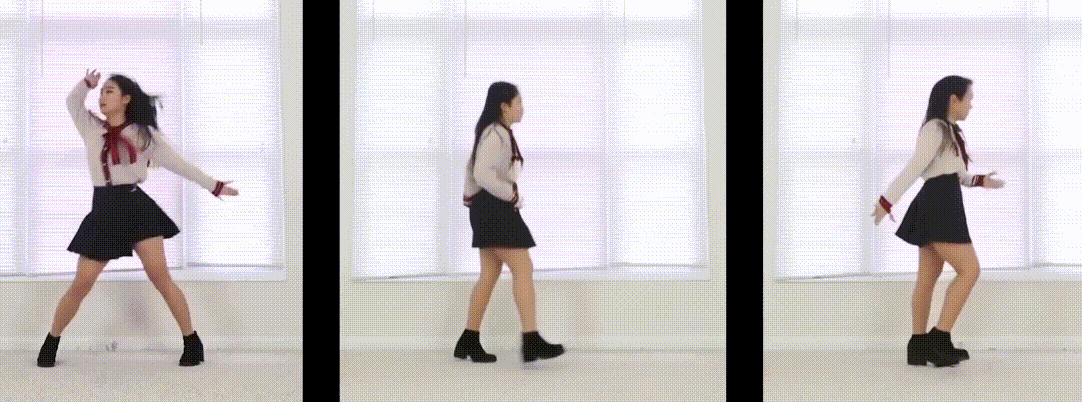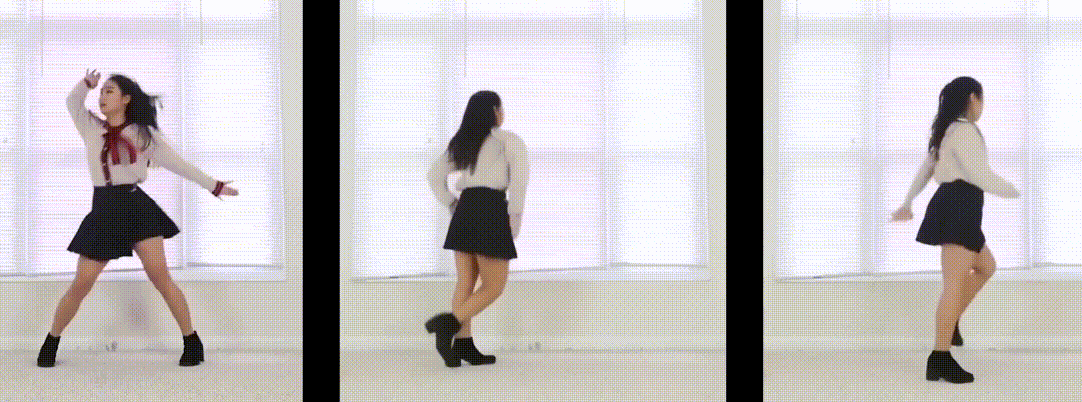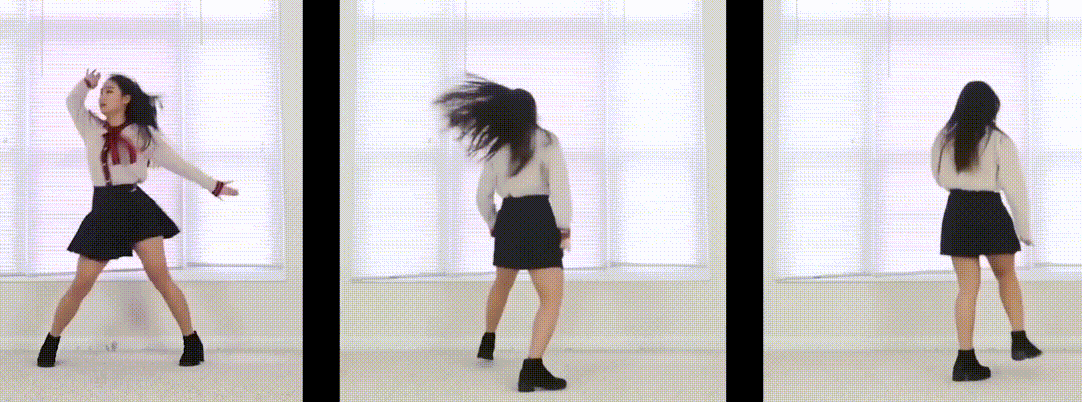
静态3D视频

结论
我们已经提出了一种新的人类视频生成方法,该方法仅作为输入,并在自由视点下生成动态人类运动的时空连贯视频。我们的方法采用高效的4D变压器体系结构来建模多个域之间的相关性,包括视图,时间和姿势。与UNET相结合以进行准确的状态注入,我们的模型可以在跨越图像,视频,多视图数据和4D扫描的多维数据集上进行培训。经过训练,我们的方法可以从自由角度综合现实,连贯的人类运动视频,我们相信我们的贡献将激发未来的工作对4D内容的生成。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











