










MuVi旨在解决视频到音乐生成(V2M)中的语义对齐和节奏同步问题。 MuVi通过专门设计的视觉适配器分析视频内容,以提取上下文 和时间相关的特征,这些特征用于生成与视频的情感、主题及其节奏和节拍相匹配的音乐。MuVi在音频质量和时间同步方面表现优于现有基线方法,并展示了其在风格和流派控制方面的潜力。
浙大&阿里提出视频到音乐生成模型MuVi
相关链接
http://arxiv.org/abs/2410.12957v1 https://muvi-v2m.github.io
论文阅读

MuVi:具有语义对齐和节奏同步的视频音乐生成
摘要
生成与视频视觉内容相一致的音乐一直是一项具有挑战性的任务,因为它需要对视觉语义的深入理解,并涉及生成旋律、节奏和动态与视觉叙事相协调的音乐。本文提出了 MuVi,这是一种新颖的框架,可以有效解决这些挑战,从而增强视听内容的凝聚力和沉浸式体验。
MuVi 通过专门设计的视觉适配器分析视频内容,以提取上下文和时间相关的特征。这些功能用于生成音乐,不仅与视频的情绪和主题相匹配,而且还与视频的节奏和节奏相匹配。我们还引入了一种对比音乐视觉预训练方案,以确保基于音乐短语的周期性的同步。此外,我们证明了基于流程匹配的音乐生成器具有上下文学习能力,使我们能够控制生成的音乐的风格和流派。实验结果表明,MuVi 在音频质量和时间同步方面都表现出了优越的性能。
方法
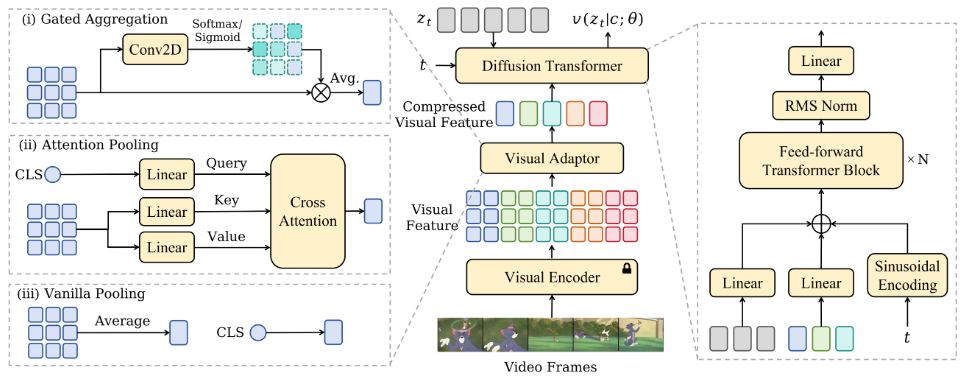
MuVi的pipeline。主模型和输入/输出在中间说明,其中视觉编码器在训练阶段被冻结。可视压缩策略列在左侧,其中“CLS”表示某些可视编码器(如CLIP)的CLS令牌。扩散变压器的结构如图所示。
实验
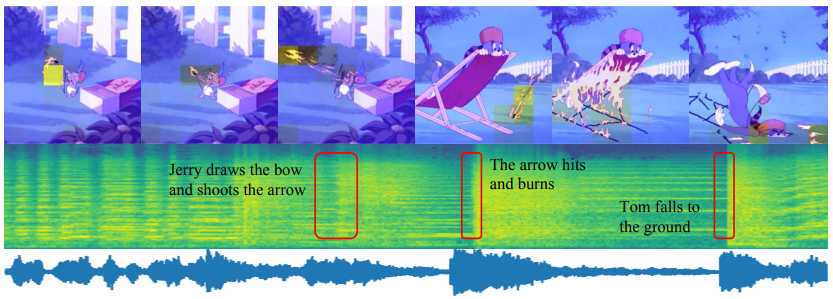
Softmax聚合的注意力分布可视化。斑块越黄,表示它与生成的音乐关系越密切。我们用平均注意力分数掩盖视频帧。我们在应用Softmax后将权重对应的patch变换成蒙版,然后相应调整蒙版的颜色。权值越小(接近0.0),掩模越蓝;相反(接近1.0),它看起来更黄。这反映了适配器的注意力分布。
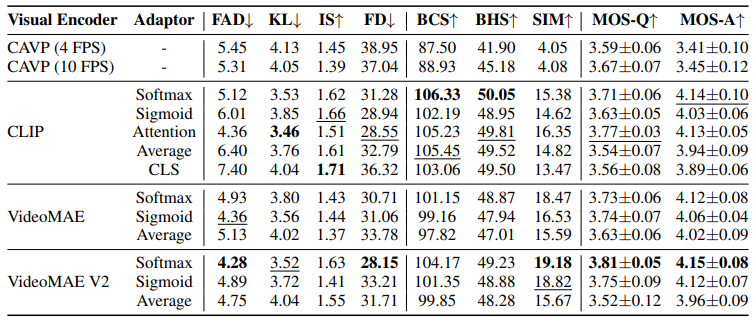
不同视觉编码器和适配器的结果。粗体数字代表该列的最佳结果,下划线数字代表第二好的结果。“Softmax”和“Sigmoid”表示Softmax和Sigmoid聚合策略,“Attention”表示注意力池策略,“Average”和“CLS”表示使用CLS令牌进行平均池化和池化
结论
本文介绍了一种新的V2M方法MuVi,它可以生成具有语义对齐和节奏同步的音乐原声带。该方法利用了一个简单的非自回归的基于ode的音乐生成器,结合了一个有效的视觉适配器,压缩视觉信息并确保长度对齐。提出了一种创新的对比音乐-视觉预训练方案,通过解决节拍的周期性来强调时间同步。实验结果表明,该方法在V2M任务中取得了满意的效果,并对不同设计的有效性进行了研究。


















 1362
1362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











