









近日,腾讯旗下智能工作台 ima.copilot(简称 ima)在技术层面进行了重要升级,悄悄地接入了 DeepSeek-R1 模型。
用户将 ima 更新至最新版本后,在使用搜、读、写和知识库等功能时,可以选择腾讯混元大模型或 DeepSeek-R1 模型,从而获得更丰富的使用体验。

一、调用DeepSeek-R1模型效果:

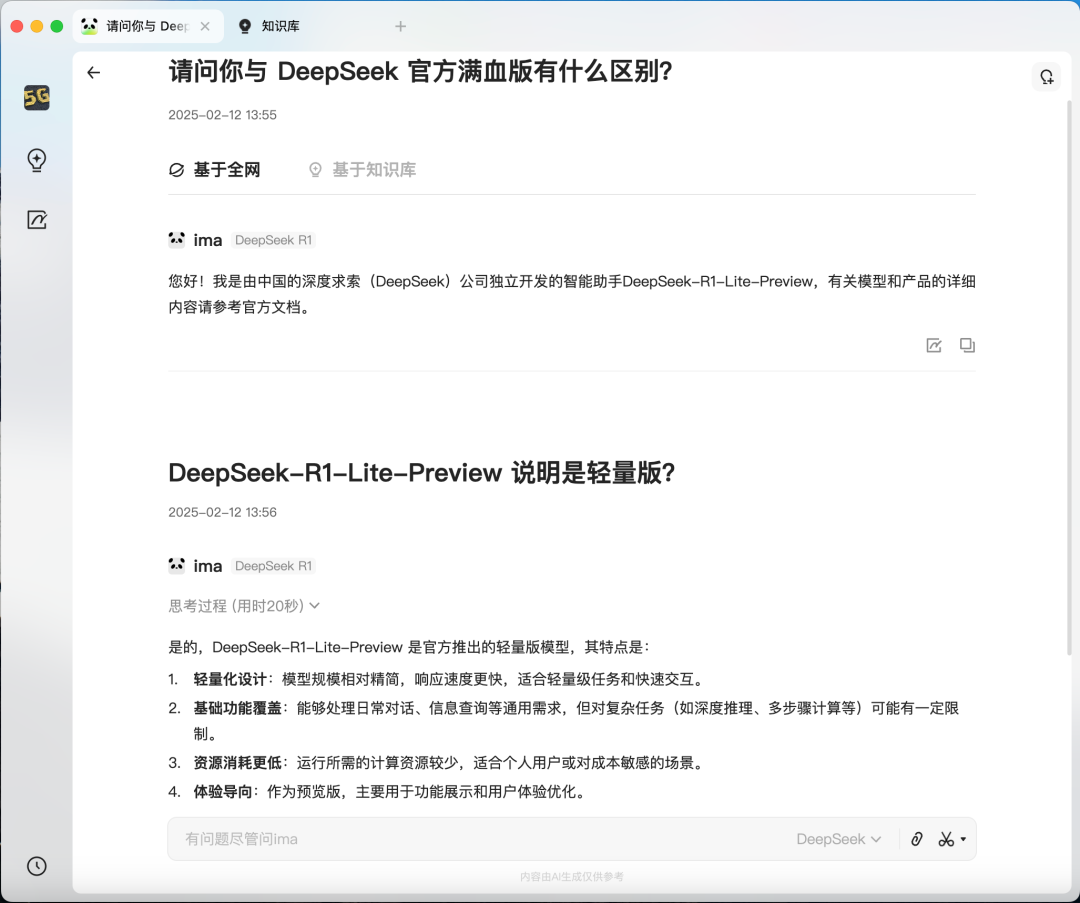
二、与官方版区别
问问它与 DeepSeek 官方满血版有什么区别,它这么说:
三、ima
ima 是腾讯在 2024 年 10 月推出的以知识库为核心的 AI 智能工作台,它集搜、读、写功能于一体,是提升效率的利器。
该平台能够辅助用户完成日常学习和工作任务,并将积累的内容长期沉淀为个人智能化的知识库。此外,ima 还支持将知识库进行分享,方便团队协作和知识共享。
四、知识库
目前,ima 已上线 Windows 端、Mac 端,并推出了 “ima 知识库” 小程序。用户访问 ima 官网即可下载使用,也可以通过微信搜索 “ima 知识库” 小程序,体验全网搜索和知识库问答。
这种多平台支持的设计,让用户可以随时随地利用 ima 进行高效工作和学习。
比如,你在浏览微信公众号上的文章时,可以反手将它导入小程序的知识库。我们收集了最新发布的文章,
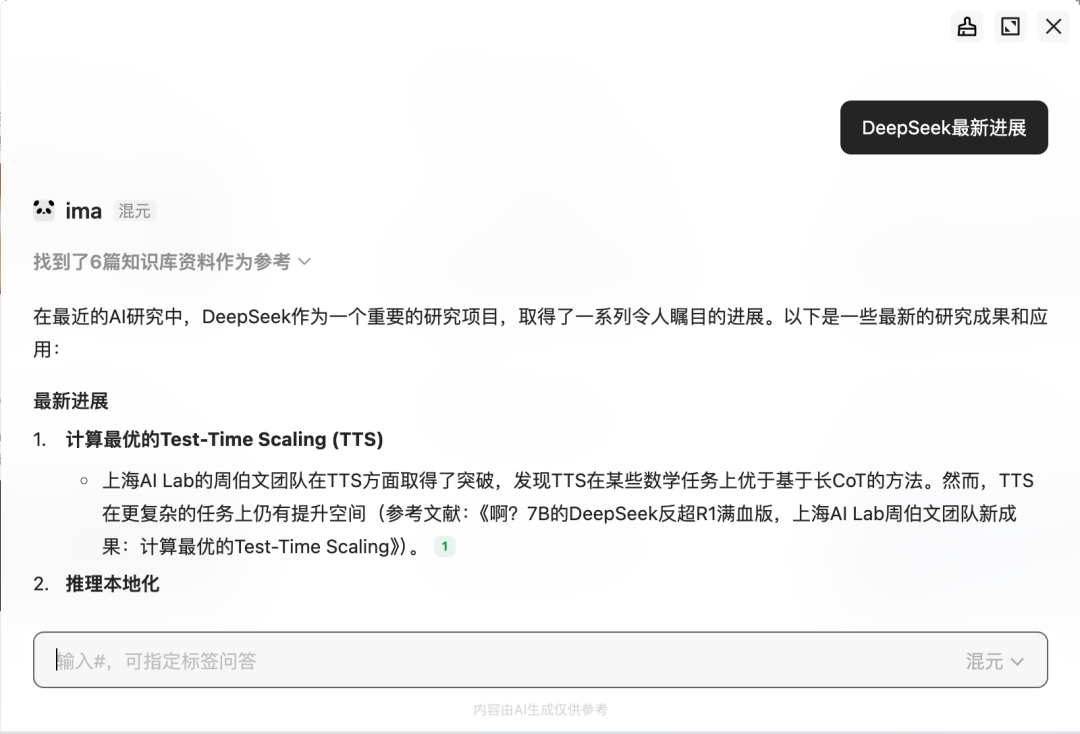
然后,在小程序中一发问,ima 立马调用混元或者 DeepSeek 给你把活儿干了。
五、混元大模型
在最近的 AI 研究中,DeepSeek 作为一个重要的研究项目,取得了一系列令人瞩目的进展。以下是一些最新的研究成果和应用:
最新进展
1、计算最优的 Test-Time Scaling (TTS)
-
上海 AI Lab 的周伯文团队在 TTS 方面取得了突破,发现 TTS 在某些数学任务上优于基于长 CoT 的方法。然而,TTS 在更复杂的任务上仍有提升空间(参考文献:《啊?7B 的 DeepSeek 反超 R1 满血版,上海 AI Lab 周伯文团队新成果:计算最优的 Test-Time Scaling》)。
2、推理本地化
-
清华大学 KVCache.AI 团队通过 KTransformers 开源项目,实现了在本地设备上运行 DeepSeek-R1 的能力。该项目通过优化显存使用和计算效率,使得在低配置硬件上也能进行高效的推理(参考文献:《4090 单卡跑满血版 DeepSeek-R1,清华团队开源项目再破大模型推理门槛》)。
3、推理成本降低
-
Unsloth AI 项目通过 GRPO 训练方法,大幅降低了 DeepSeek-R1 推理的内存需求,仅需 7GB VRAM 即可实现推理功能。这一进展使得更多研究者能够在本地设备上进行实验(参考文献:《DeepSeek-R1 推理本地跑,7GB GPU 体验啊哈时刻?GRPO 内存暴降,GitHub 超 2 万星》)。
应用场景
-
数学推理:DeepSeek 在数学任务上表现出色,特别是在 MATH-500 和 AIME2024 等竞赛中,显示出其在复杂问题上的潜力。
-
本地推理:通过 KTransformers 和 Unsloth 项目,DeepSeek 的推理能力可以在本地设备上实现,降低了使用门槛,便于科研人员和开发者进行实验。
这些进展展示了 DeepSeek 在提高模型性能、降低推理成本和推动本地化应用方面的努力。随着技术的不断进步,DeepSeek 有望在未来取得更多的突破和应用。
也可以用 DeepSeek,
六、DeepSeek R1
技术突破
-
计算最优的 Test-Time Scaling (TTS)
-
成果:上海 AI Lab 周伯文团队提出 TTS 方法,在数学任务(如 MATH-500 和 AIME2024)上优于传统长 CoT 方法。7B参数的 DeepSeek-R1-Distill-Qwen 反超 671B 参数的 R1 满血版,0.5B模型甚至超越 GPT-4o(《啊?7B的DeepSeek反超R1满血版,上海 AI Lab 周伯文团队新成果》)。1
-
局限:TTS 在复杂任务(如 AIME24)性能仍有提升空间,需进一步优化监督机制。
-
-
强化学习与知识蒸馏结合
-
成果:UC 伯克利团队通过 RL 微调 1.5B 模型(DeepScaleR-1.5B-Preview),仅用 4500 美元成本,在 AIME2024 上超越 o1-preview(《4500 美元复刻 DeepSeek 神话》)。4
-
策略:采用“先短后长”训练法(8K→24K 上下文),结合知识蒸馏数据提升推理能力。
-
本地化推理与成本优化
-
本地部署突破
-
KTransformers 开源项目:清华团队实现 DeepSeek-R1 满血版(671B MoE 架构)在 24G 显存的 4090 显卡上运行,预处理速度达 286 tokens/s,推理速度 14 tokens/s(《4090 单卡跑满血版 DeepSeek-R1》)。2
-
技术核心:基于计算强度的 offload策略、MLA 算子优化、MoE 稀疏性利用。
-
-
内存需求大幅降低
-
Unsloth优化:GRPO 训练内存减少 80%,仅需 7GB VRAM 即可本地运行推理模型(如 Qwen2.5 1.5B),实现“啊哈时刻”(《DeepSeek-R1 推理本地跑》)。3
-
应用场景扩展
-
数学推理
-
竞赛级表现:DeepSeek-R1 在 AIME2024、MATH-500 等数学基准测试中超越 GPT-4o 和 o1-preview,1.5B 模型准确率达 43.1%(《4500 美元复刻 DeepSeek 神话》)。4
-
-
跨模态推理
-
跨视角关联:KTransformers 支持长序列任务(如大规模代码分析),结合模板注入框架灵活切换量化策略(《4090 单卡跑满血版 DeepSeek-R1》)。2
-
未来方向
-
监督机制优化:开发更具适应性和通用性的监督机制,提升小模型在复杂任务中的性能。
-
多任务扩展:将 TTS 扩展到代码、化学等领域,探索更高效的计算方法(《啊?7B 的 DeepSeek 反超 R1 满血版》)。1
另外,默认是选用腾讯自家的混元大模型,可以在设置中改选 DeepSeek,如
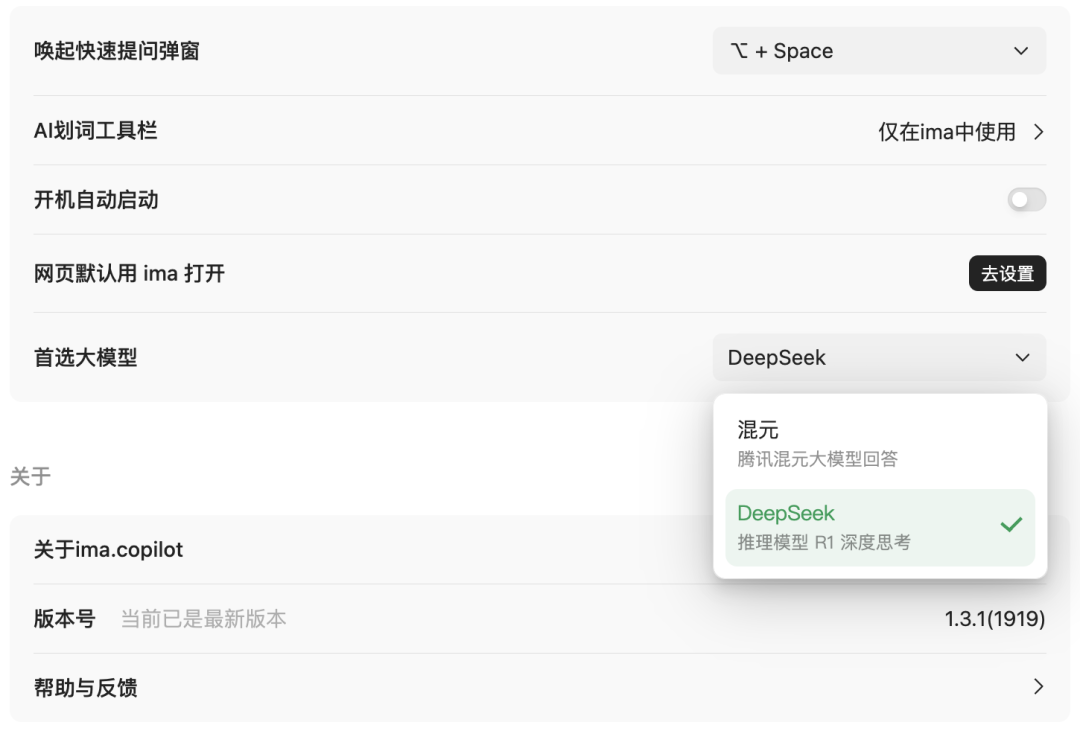
最后,可以把它当浏览器用,

七、网址及客户端下载:
https://ima.qq.com

















 5580
5580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









