







4.模型评估
4.1.模型区分能力评估
模型的风险区分能力在于它能够有效识别出好坏账户。具有最大区分能力的模型可以精确的预测出所有的坏账户。然而实际上这样的理性模型并不存在。一般称一个模型具有较高的风险区分能力是指评级分值较高的客户群在未来仅包含很低比例的坏客户和很高比例的好客户,较低的风险区分能力模型正好相反。模型区分能力一般的统计测度包括AR值、K-S变量。
4.1.1.Accuracy Ratios(AR)
累积准确曲线(CAP)及其主要指数准确性比率(AR)主要用来检验模型对客户进行正确排序的能力。CAP曲线及准确性比率/AR描绘了每个可能的点上累计违约排除百分比。为了画出CAP曲线,需要首先自高风险至低风险排列模型的分数,然后对于横坐标客户总数中特定的比例,CAP曲线的纵坐标描述风险评级分数小于或等于横坐标x中的违约个数百分比。一个有效的模型应当在样本客户处于同一排除率的情况下,排除更高百分比的坏客户。
下图为CAP曲线示意图:
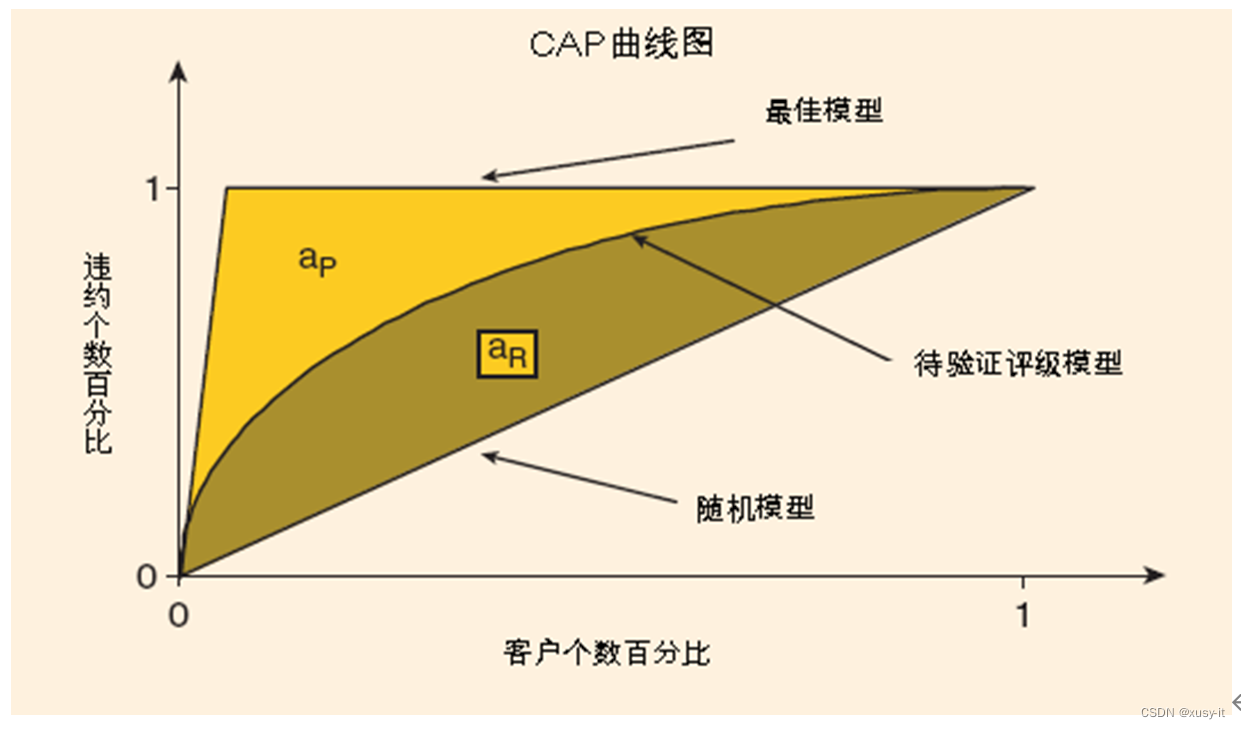 CAP曲线描述了各个评分结果下,累积违约客户比率和累积正常客户的关系。曲线上的点,例如(0.2,0.7),表示评级风险较高的20%的评级对象占违约客户的70%。在完美的模型下,CAP曲线开始阶段呈线性增长(斜率为1/违约率),然后稳定在1的水平上。反之,在完全没有区别能力下,模型的CAP曲线会是一条45度的直线。而AR(准确率,Gini系数)的定义为模型的CAP曲线和45度线间的区域面积,与介于45度线和完美模型的区域面积的比率,如下所示:
CAP曲线描述了各个评分结果下,累积违约客户比率和累积正常客户的关系。曲线上的点,例如(0.2,0.7),表示评级风险较高的20%的评级对象占违约客户的70%。在完美的模型下,CAP曲线开始阶段呈线性增长(斜率为1/违约率),然后稳定在1的水平上。反之,在完全没有区别能力下,模型的CAP曲线会是一条45度的直线。而AR(准确率,Gini系数)的定义为模型的CAP曲线和45度线间的区域面积,与介于45度线和完美模型的区域面积的比率,如下所示:
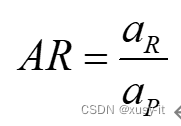
这个值越接近1,表示模型的效果越好。
下表为AR值对应的模型区分能力:
| AR值 |
模型表现 |
| <0.3 |
差 |
| 0.3-0.5 |
一般 |
| 0.5-0.6 |
好 |
| 0.6-0.7 |
很好 |
| 0.7-0.8 |
非常好 |
| 0.8-1 |
完美 |
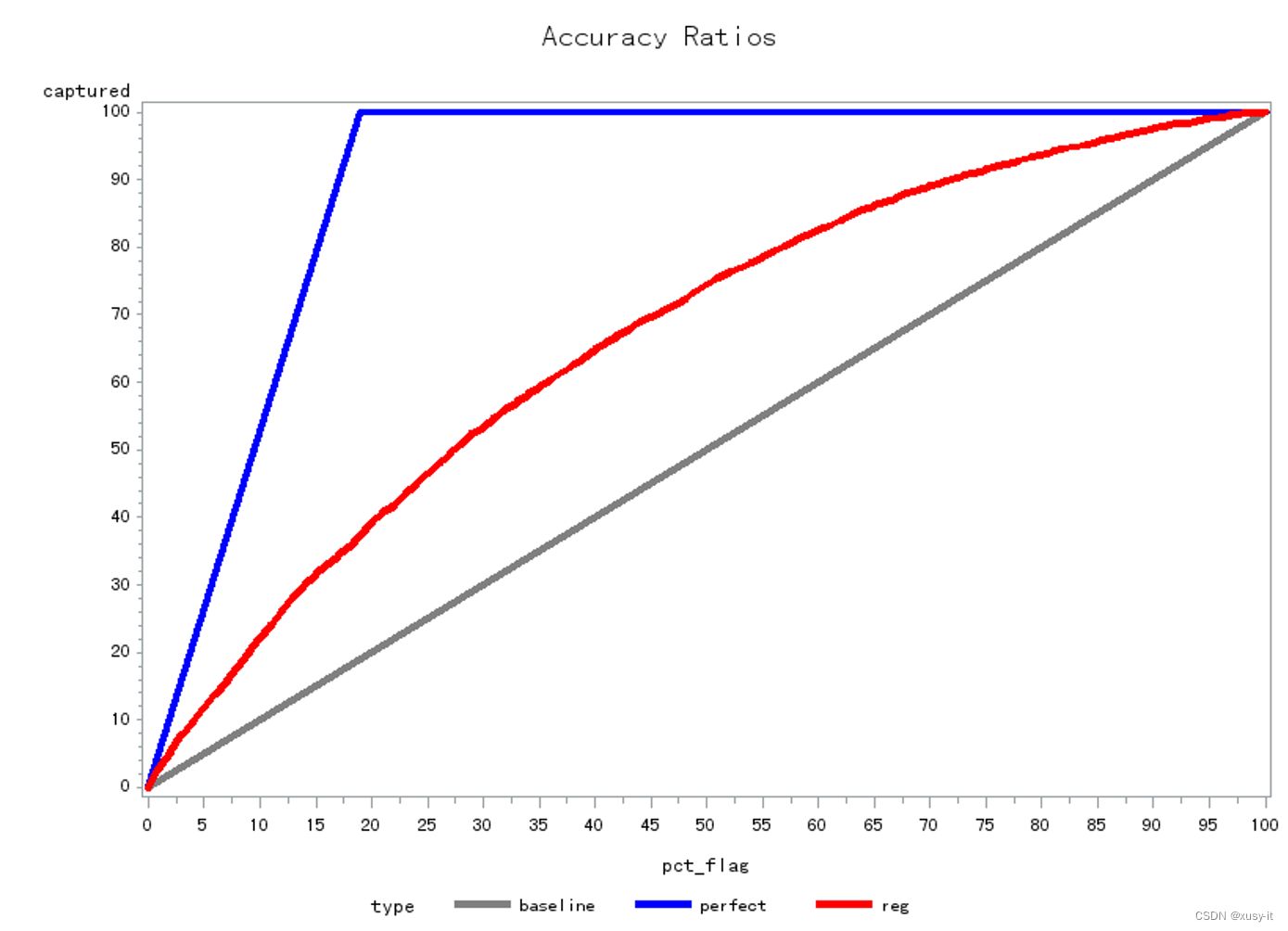
利用时间内验证样本和时间外验证样本对模型的区分能力进行检验,发现AR值在0.37到0.40之间,模型较稳定,且具有一定的区分能力,具体见下表:
| AR值 |
模型表现 |
|
| 开发样本 |
0.408373 |
|
| 验证样本 |
0.40081 |
|
| 时间外验证样本(2月) |
0.378526 |
|
| 时间外验证样本(3月) |
0.390023 |
|
| 剔除开发样本中重复的坏账户 |
时间外验证样本(3月) |
0.370199 |
| 时间外验证样本(4月) |
0.376906 |
|
CAP曲线图:
4.1.2.K-S值
K-S检验主要是验证模型对违约对象的区分能力,通常是在模型预测全体样本的信用评分后,将全体样本按违约与非违约分为两部分,然后用KS统计量来检验这两组样本信用评分的分布是否有显著差异。
运用KS检验来验证模型能否区别出违约户与正常户,当两组样本的累积相对次数分配非常接近,且差异为随机时,则两组样本的评级分配应为一致;反之当两组样本的评级分配并不一致时,样本累积相对次数分配的差异会很明显,如下图所示:
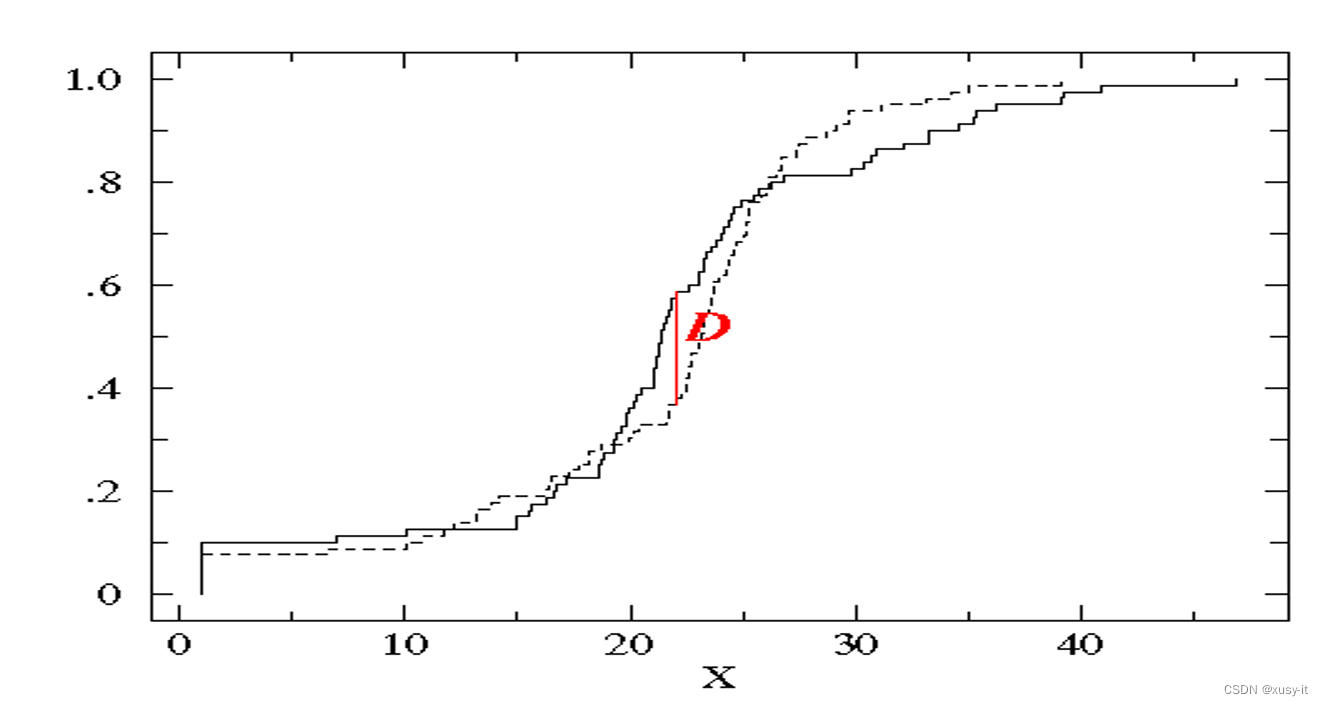
KS的检验步骤为:
· 计算正常户和违约户在各评分阶段下的累积比率
· 计算各阶段累积比率之差
· 找出最大的累积比率之差,即为KS
另外,下表为KS值对应的模型区分能力(作为参考,不能作为严格的判别标准):
| KS值 |
模型表现 |
| 20以下 |
不建议采用 |
| 20-40 |
中等 |
| 40-50 |
好 |
| 50-60 |
很强 |
| 60-75 |
非常强 |
| 75以上 |
能力高但疑似有误 |
模型开发样本KS值达到30,时间内验证及时间外验证的KS值在27到31之间,模型稳定且具有一定的预测能力。具体指标见下表:
| KS值 |
模型表现 |
|
| 开发样本 |
30.32194 |
|
| 验证样本 |
31.63423 |
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











