







【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
论文1:[PreWorld] Semi-Supervised Vision-Centric 3D Occupancy World Model for Autonomous Driving.
https://arxiv.org/pdf/2502.07309
- 任务:4D占用预测(根据历史帧Occ预测未来帧Occ)
- 以前的方法:输入图像给3D占用模型获得历史Occ → 预测模块预测未来Occ
【问题:重复的编码和解码过程会造成信息丢失】 - 改进点:
- 直接实现图像到未来Occ预测【避免了信息丢失,同时优化占用网络和预测模块】
- 用2D标签进行自监督预训练 + Occ 全监督微调【更好地利用2D标签】
- 方法 & 训练范式:
- 阶段一【自监督预训练】:用图像自监督训练Occupancy Network(Occ网络)
- 阶段二【全监督微调】:用4D Occ全监督训练Forecasting Module(预测模块)

- 状态条件预测模块 State-Conditioned Forecasting Module
- 实现:从多帧历史图像中提取Volume体素特征 → 预测未来的体积特征 → 转换为未来Occ
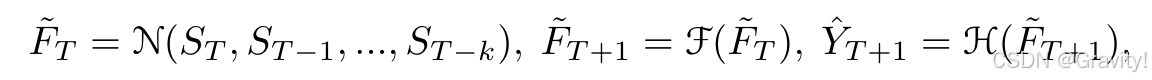
- 预测模块:两个多层MLP【简单的模型也可以实现好的预测效果】
- 发现:仅在训练期间优化预测模块的做法 不如 同时优化占用网络和预测模块
- 实现:从多帧历史图像中提取Volume体素特征 → 预测未来的体积特征 → 转换为未来Occ
- 时序2D渲染自监督 Temporal 2D Rendering Self-supervision
- 实现:属性投影 → 射线生成 → 体积渲染 → 自监督训练
- 属性投影(类似Renderocc做法):将3D体积特征转换为时序属性场(如密度、语义和RGB场)
- 射线生成:从多视角图像中提取3D射线,用自车姿态转换到当前帧,来捕捉多视角信息
- 体积渲染:在射线上采样多个点,分配权重,预测属性
- 自监督训练:Loss为2D渲染预测与2D标签之间深度、语义和RGB这些属性的差异
- 实验:
- 4D Occ预测,都为多视图输入
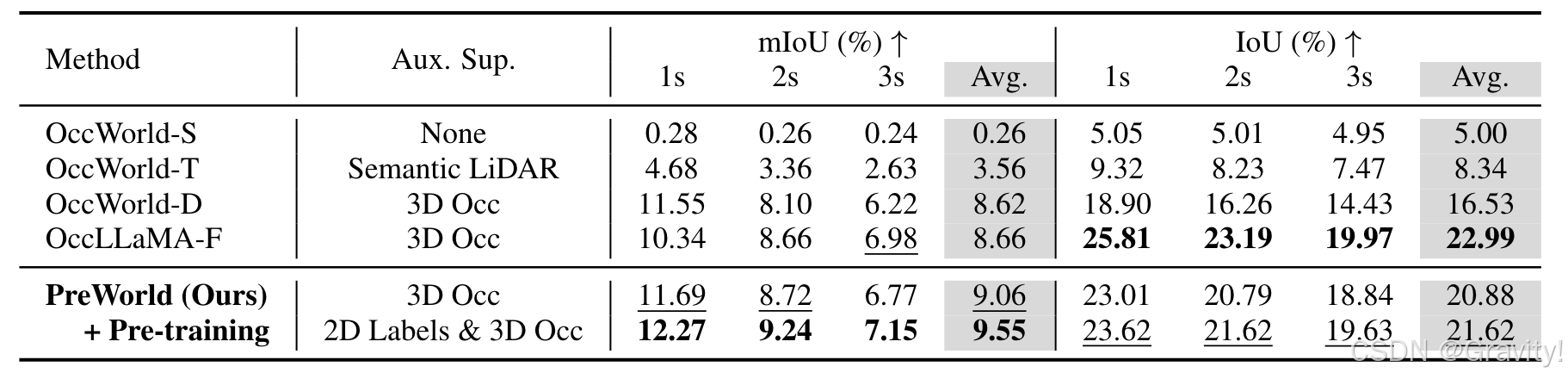
- 4D Occ预测,都为多视图输入
论文2:DynamicCity: Large-Scale Lidar Generation from Dynamic Scenes
https://arxiv.org/pdf/2410.18084
- 任务:4D LiDAR 场景生成
- 贡献点:
- 高效表示学习:基于VAE,把4D LiDAR特征压缩为六个2D特征图(HexPlane)
- 扩散模型生成:利用DiT生成HexPlane
- 多样化的下游应用:如轨迹引导生成、命令驱动生成、场景修复(inpainting)和布局条件生成
- HexPlane:编码时空特征【降低计算复杂度,更灵活】

- 对时空中的任意点
,在六个平面中提取相应特征
- 对时空中的任意点
- 方法:
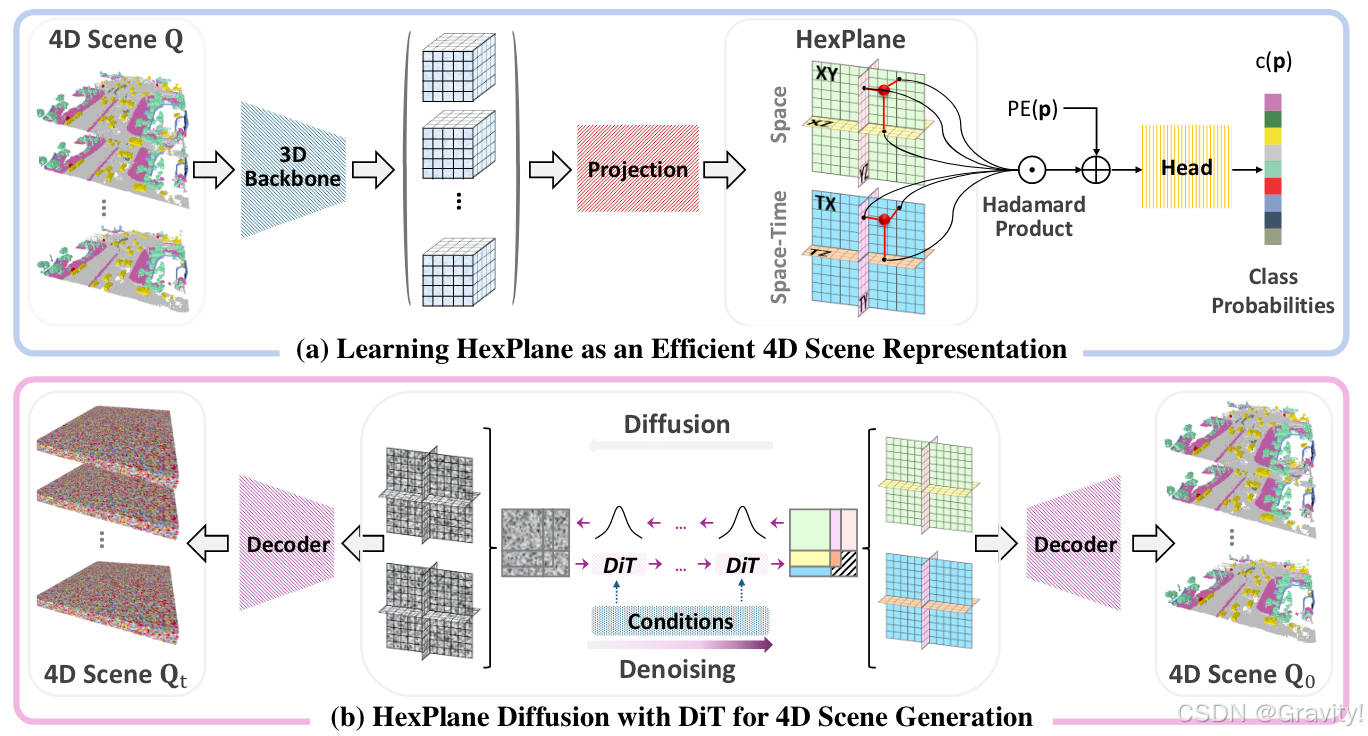
- 阶段一:VAE学习4D表征
- 编码HexPlane【3D CNN提取特征、降采样】→ Projection Module【将4D特征投影到六张2D特征图】→ 解码HexPlane【并行解码六张特征图来重建特征体积序列,卷积上采样得语义预测】
- 阶段二:扩撒模型生成 Diffusion Transformer(DiT) for HexPlane
- Padded Rollout Operation (PRO) 【高效建模特征序列中的空间和时间关系】
- 动机:HexPlane的六个特征平面共享空间或时间维度,直接展平无法有效建模关系
- 方法:将六个特征平面重新排列为一个正方形特征图,然后将特征图的patch转化为序列
- 条件生成:Classifier-Free Guidance,训练时同时学习条件生成和无条件生成
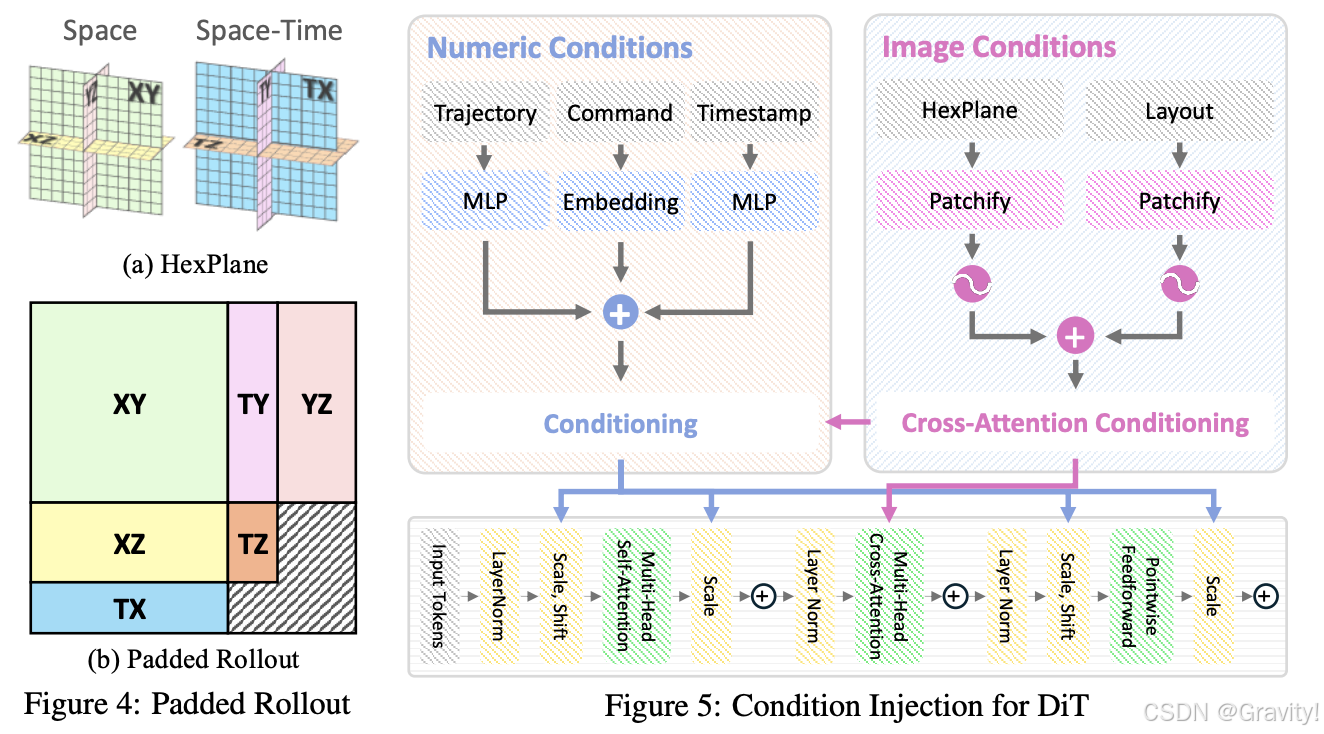
- Padded Rollout Operation (PRO) 【高效建模特征序列中的空间和时间关系】
- 阶段一:VAE学习4D表征
- 实验(和OccSora比较):


















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









