







论文: QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
背景
同VDN
4. QMIX
假设 Qtot 与 Qi 有如(4)式的关系.
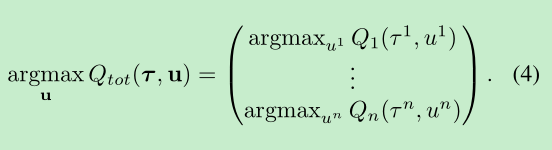
(4)式可以通过(5)式实现.

(5)式可以通过如下Fig2的QMIX网络架构实现

- agent networks: 进行local决策
- 即DRQN, Qi
- mixing network: 实现线性并保证单调(式(5))
- 保证单调的方法
- 网络权重W均为正 (bias无所谓)
- (非线性的)激活函数单调递增
- 保证单调的方法
- hypernetworks: 融入state信息
- state为何不直接与Qi 一同作为输入?
- 因为 Qtot 和 st 之间没有单调关系
- 实现灵活输入以方便 mix net 评估 joint action-value
- 由state经过NN生成mix net的weight 和 bias
- 为什么最后的bias用了两层Linear?
- state为何不直接与Qi 一同作为输入?
7.2. Ablation Results
both central state information and non-linear value function factorisation is required to achieve good performance.
A.1. Representational Complexity
- Three Keys:
The value function class representable with QMIX includes any value function that can be factored into a non-linear monotonic combination of the agents’ individual value functions in the fully observable setting.- non-linear: 比VDN更expressive
- monotonic (对于单个agent来说) : 单个agent的最优action与其他agent无关
- fully observable: observartion != state
In a Dec-POMDP, QMIX cannot necessarily represent the value function. For example, if
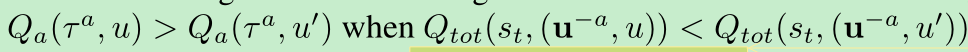















 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









