









1 背景
在多智能体强化学习中有两个重要的问题,一是如何学习联合动作值函数,因为该函数的参数会随着智能体数量的增多而成指数增长;二就是学习到了联合动作值函数后,如何提取出一个合适的分布式的策略。这两个问题导致单智能体强化学习算法,如Q-learning,难以直接应用到多智能体系统中。Rashid提出了QMIX多智能体算法,基于Q-learning和VDN的启发,从上述两个问题角度提升marl算法的准确度。
论文原文:QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
2 模型结构
为了解决agent的状态动作空间随着agent数量指数爆炸的问题,QMIX模仿了VDN,用了一些数学手段让agents的状态动作空间随着agents数量线性增长,并且使得值函数的分解变得更加合理。QMIX依然采用集中式训练、分布式执行的架构,并且同VDN一样,也是所有agents共同维护一个奖励函数。
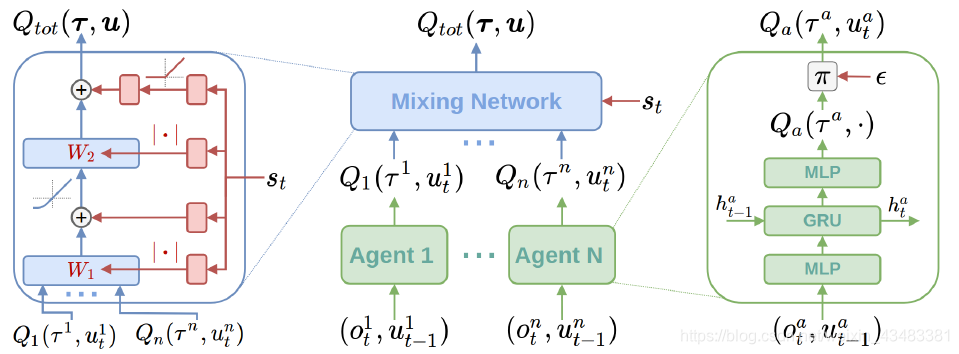
算法的架构如上图所示,从左到右分别成为a,b,c三图。
1、c图表示每一个智能体使用DRQN拟合Q,也意味着实际上每个agent之间都是相互连接的。
2、b图中的mixing network中所有的权值都是非负数,限制方法应该是直接通过代码方法。
3、全局状态St不是直接输入到Mixing network中的,而是中间通过了一个超网络,以St为输入,输出Mixing network的权值和偏移量,并且在超网络的最后用线性网络和绝对值激活函数保证输出的非负性。
4、混合网络最后一层的偏移量(bias)通过两层网络以及ReLU激活函数得到非线性映射网络。
5、超网络存在的意义是为了将St的信息完整的存储下来,因为mixing Network权重是全正的,如果直接将
S
t
S_t
St输入进去那么会降低其一半的信息。
6、Qix的更新方式与Qlearning是一致的,整个QMIX也都是基于值函数的marl算法,即deepmind流派的RL算法。
3 实验
文章给出了两个环境,一个用来单独说明QMIX相比于VDN的好处,另一个用常见的星际争霸二来更普遍地进行对比。
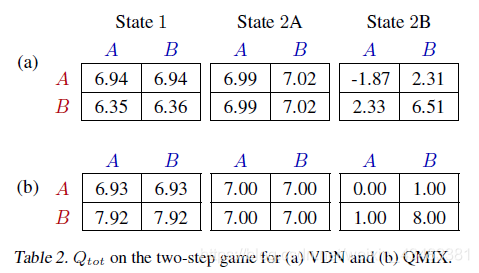
3.1 Two-Step Game
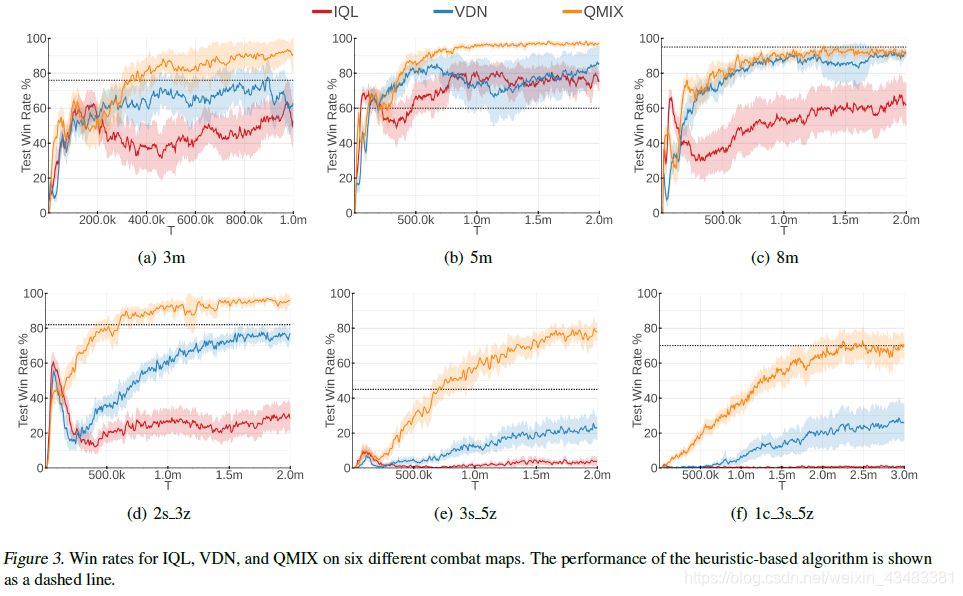
3.2 Decentralised StarCraft II Micromanagement
4 特点总结
相比于其他marl的论文,本文可以算是更加优秀的一篇,不仅有理论证明,还有巧妙的网络设计,总结如下:
1)本文提出的QMIX网络,采用固定混合网络权重为非负和加入全局状态作为集中式训练的方法,使得agents的动作状态空间随agents数量线性增长,从而提高了mas下强化学习算法的准确度。
2)QMIX可以看作是IQL+VDN的改进版本,实际上本文的实验对比也是基于这两种算法实现的。
3)文章作者具有很强的网络调参能力和模型设计能力,这是在理解了神经网络每一层的作用之后才能做到的这一点,可以看出作者团队都是具有丰富经验的机器学习工程师。
4)QMIX在应用效果上也具有很好的表现,但是其只能应用在完全合作的情况下,因为全局维护一个Qtotal值和共同的奖励函数。

















 6900
6900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









