



人类的大脑除了推理能力之外,还有另一个重要的能力,就是记忆。如果人们失去了记忆,推理能力也会大打折扣。如何提升AI 的记忆能力是一个非常重要的课题。我们要从生命科学中获得启发。本文是关于记忆的读书笔记。
人类记忆是智力的基础——它塑造我们的身份,指导决策,并使我们能够学习、适应和建立有意义的关系
为什么关注记忆
为什么对记忆感兴趣呢?在过去的一年里,我一直断断续续地做面向老年人的个人AI 助手工作,希望AI能够帮助老人,老年人记忆力逐渐衰退,帮助老人家记住事情就显得十分中,另一方面,了解老人的习惯,生活经历能够更好地与老年人交流。
我使用的方法大致如下;
- 直接使用langchain 的memory 方式
- 将对话存储在一个文件中,然后通过RAG ,增强检索内容
- 使用大语言模型提取对话中的信息,存储在图数据库中,通过图数据库检索
老实说,前一阶段的实验并不理想,分析其原因,可能有两点;
- 大模型的推理能力有限,使用ReAct Agent 等方法推理出错率高
- 记忆方式过于粗糙
一年多过去了,大模型的推理能力有了长足进步。我们有一次来试试,这一次我们从研究记忆出发。
什么是记忆?
记忆是回忆所学信息的过程。大脑的许多部分协同工作,收集并存储信息,以便你在需要时查找和访问。记忆有多种分类方法。
记忆是人类至关重要的生理过程。它用于解决问题,例如在考试中回答问题。它帮助你规划路线,并在熟悉和陌生的地方导航。它与你的语言发展息息相关(例如,记住某人的名字)。你的记忆也有助于推理,例如避免那些曾经伤害过你的事情。
随着年龄的增长,你的记忆力可能不如以前那么强。这是衰老的正常现象。但有时,潜在的疾病会影响大脑中负责记忆的部分的功能。如果你对记忆力有任何疑问,医疗保健提供者可以提供帮助。
记忆有哪些类型?
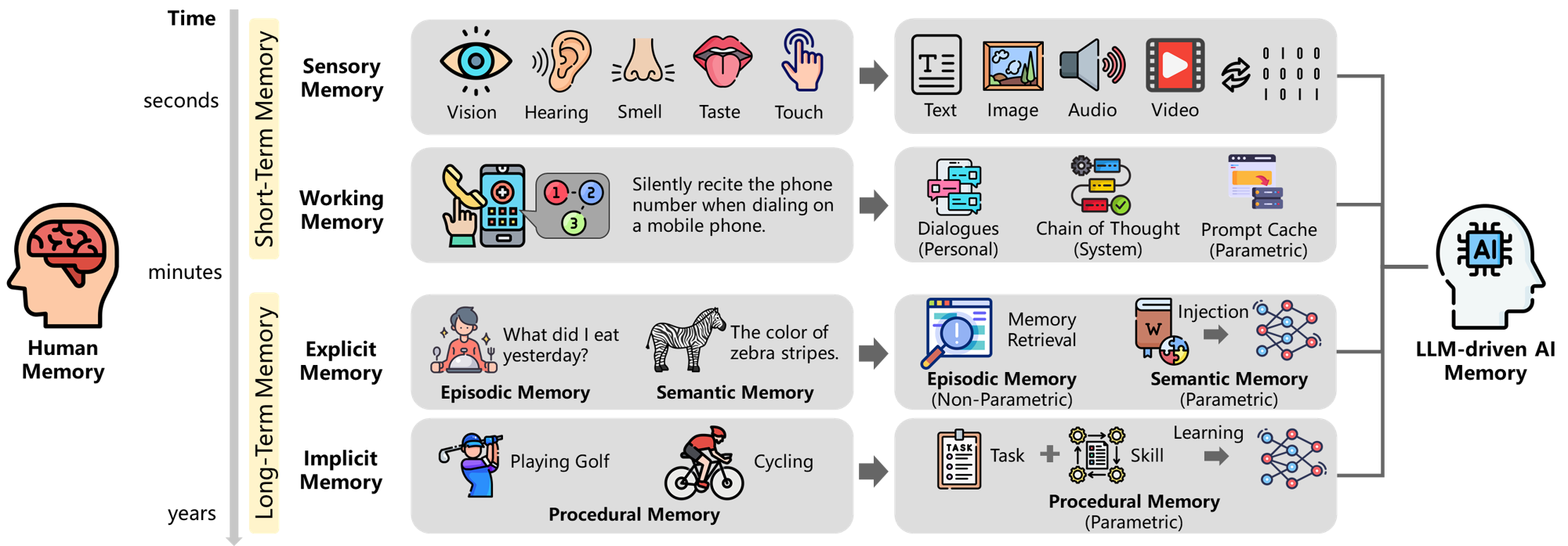
记忆主要有三种类型:
- 感觉记忆:这是从你的感官(听觉、触觉、嗅觉、味觉和视觉)收集的信息。你只会储存几秒钟。你无法有意识地控制这种记忆,但它非常详细。
- 短期记忆:这是一个临时的存储空间。它保存信息的时间从几秒到几分钟不等。它很容易被访问。
- 长期记忆:这是一个几乎永久的存储空间。你可以将信息保存在这里多年。存储信息量没有限制。
感觉记忆
感觉记忆通常只有1秒钟,感觉记忆类型代表你的每一种感觉:
- 回声记忆:听觉。
- 触觉记忆:触觉(体感)。
- 味觉记忆:味道。
- 标志性记忆:愿景。
- 嗅觉记忆:气味。
当特定的感官体验变得相关时,例如厨房里的某种东西的气味,它可能转换成其他类型的记忆。
感觉记忆非常短暂,人们很快就会忘记它们。例如,一个人不会回忆过去30秒,30分钟或者30天内听到的所有特定声音。除非有某些理由记住它们。
短期记忆
短期记忆通常为30秒钟。短期记忆的容量和持续时间有限。你可以把短期记忆想象成一个专属的VIP俱乐部。你只能在那里待一小会儿,然后就会有人把你带出去。
然而,你可以通过增加容量和持续时间来操纵你的短期记忆。有两种策略可以做到这一点:
- 分块:您可以将材料(信息)组织成组,以帮助您记住更多内容(将车牌号码回忆成两个部分而不是一个部分)。
- 排练:您可以不断重复信息以延长记忆时间(例如通过多次唱一首歌来记住歌词)。
由于您可以组织、处理和使用来自短期记忆的信息,研究人员创造了“工作记忆”或“短期工作记忆”这两个术语,并互换使用它们。
短期记忆并非只是短暂的记忆,而是一种只能保存少量信息的短暂存储,例如记住一串5~7个单词并重复
拿起笔记下电话号码
长期记忆
长期记忆主要有两种类型:
- 陈述性记忆或外显记忆:这是对事实、事件和地点的存储。你会不断地添加和回忆信息。
- 非陈述性记忆或内隐记忆(程序性记忆):这是对所学技能、习惯或人际关系的储存。你可以有意识或无意识地访问这些记忆。
外显长期记忆时对事件,事实或者一个人学到的知识的有意识的记忆
外显长期记忆的类型包括以下几种:
情景记忆
这些是对事实或者事实的记忆。情景记忆的例子包括记住选举,童年事件或者个人事实。例如某人是否已婚。
语义记忆
语义记忆是关于世界的常识。一个人可能会记住一些它们没有经历过的事实或事件,因为他们学习过或者研究过。例如,知道人类心脏的样子就是语义记忆的一个例子,然而,如果一个人记得在学校解剖过猪的心脏,那就属于情景记忆了。
记忆是如何运作的?
每段记忆都有四个部分:
- 收集:从周围环境中获取信息。
- 编码:您的大脑将信息转换为易于存储的格式。
- 存储:您的大脑会组织并保存翻译后的信息。
- 检索:选择并找到您想要记住的存储信息。
你的大脑有一套非常特殊的策略来收集、编码、存储和检索记忆。它需要神经元(神经细胞)、神经递质、突触和许多不同大脑区域的协调作用。
内隐记忆是影响一个人行为的记忆。然而,人们并没有意识到它们。
这种记忆的一些类型如下:
程序记忆
程序记忆帮助人们完成熟悉的任务。例如走路或开车。一开始,他们必须学会做这些事情并记住特定的技能。但最终,这些任务会成为程序记忆的自动组成部分。
启动
启动发送在经验影响一个人的行为。
例如,吸烟者可能在饭后渴望吸烟。经典条件反射和操作性条件反射都会促使人类或者动物根据特定的经历做出特定的行为。
大语言模型的记忆
记忆是创建引人入胜且不断发展的对话式人工智能系统(当然也包括人类)的基础。
会话记忆(Conversation)
大多数人在想象代理长期记忆时,记忆被存储为单独的文档或记录。对于每次新的对话,记忆系统可以决定将新的记忆插入到存储中。
记忆存储中的更改,删除非常的重要。
与人类不同,人类会动态地整合新信息并修改过时的信念,而 LLM一旦信息超出其上下文范围,就会有效地“重置”。
使用集合型记忆会增加更新记忆状态的复杂性。系统必须将新信息与先前的信念相协调,要么 删除/使其无效,要么更新/巩固现有记忆。如果系统过度提取,则可能导致代理在搜索记忆的准确率降低。
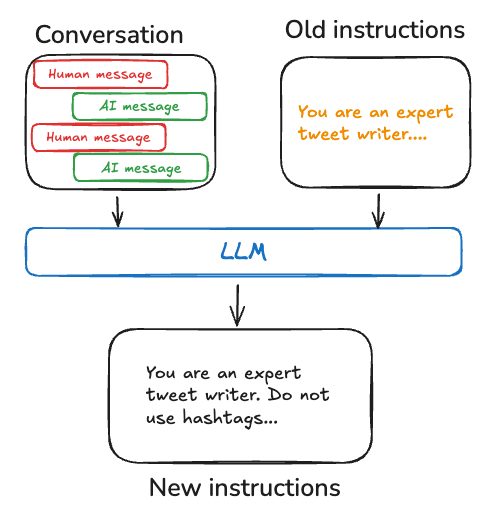
对于对话式人工智能系统,我们可以粗略地模拟人类的记忆:
- 场景感知——提供场景背景信息与感官输入非常相似,尽管它被视为文本。我们可以使用视觉模型、游戏引擎中的元数据等来提供 NPC 可以使用的物品、动作和事件的详细信息。
- 短期记忆 - 如果我们将上下文窗口中的最后 N 轮对话保持原样/不变,我们就会得到过去几分钟(或更长时间,取决于 N 的大小和对话速率)的逐字聊天记录。
- 中期记忆——一旦我们超过了指定的 N(短期记忆/信息保留),我们就可以将一段对话总结成记忆,捕捉有关讨论的主题、分享的个人详细信息、表达的情绪等信息。
- 长期记忆——当创建中期记忆时,我们首先检查是否存在高度相似的现有记忆,如果相似度在定义的阈值范围内,我们可以将这些记忆整合为一个长期记忆,通过增强回忆和解决冲突信息来提高性能。
- 工作记忆——NPC 使用的完整组合提示,包括背景故事、知识库中的信息以及之前定义的各个层次的“记忆”。
个人资料¶
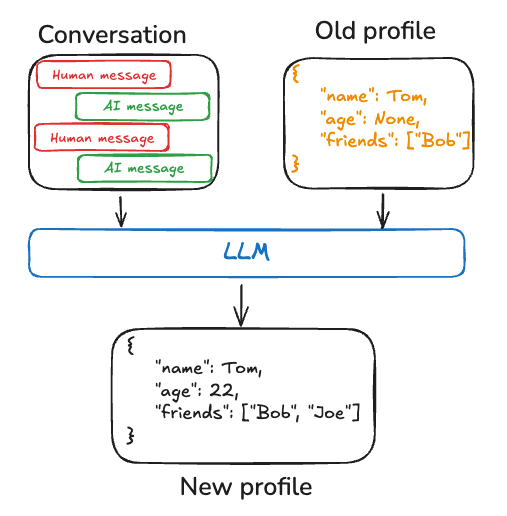
另一方面,个人资料则针对特定任务进行了明确的限定。个人资料是一个单一的文档,用于描述当前状态,例如用户使用应用的主要目标、他们偏好的姓名和回复方式等等。当新信息到达时,它会更新现有文档,而不是创建新文档。当您只关心最新状态并希望避免记住无关信息时,这种方法非常理想。
两种记忆系统介绍
在这里我们介绍两种记忆系统,分别是LangMem和Mem0.
LangMem
LangMem是 LangChain 推出的一款软件开发工具包 (SDK),旨在赋予 AI 代理长期记忆。它使代理能够从长期交互中学习和适应,存储对话中的重要信息,优化其提示/行为,并在会话之间维护知识。本质上,LangMem 帮助 AI 代理记住用户的偏好、事实和过去事件,以便即使经过多次交互,也能提供更连贯、个性化且情境感知的响应。
Memory Manager
Memory Manager 是一个利用LLM从对话中提取关键信息,并将其作为长期记忆进行管理的API。
提供以下功能:
- 添加新的记忆
- 更新现有记忆
- 删除不需要的记忆
以下代码是一个将用户的饮食偏好反映到长期记忆中的示例。
用户的饮食偏好
from pydantic import BaseModel, Field, conint
from langmem import create_memory_manager
from langchain_openai import ChatOpenAI
import os
os.environ['OPENAI_API_KEY'] ="sk-kenMaSeAT8WxxxxxxxLv4Y1V3fZiuoHKAl"
os.environ['OPENAI_BASE_URL'] ="https://api.chatanywhere.tech/v1"
llm = ChatOpenAI(model_name="gpt-4.1-2025-04-14",base_url="https://api.chatanywhere.tech/v1", temperature=0)
class UserFoodPreference(BaseModel):
"""用户饮食偏好的详细信息"""
food_name: str = Field(..., description="菜名")
cuisine: str | None = Field(
None, description="料理类型(和食、洋食、中餐等)"
)
preference: conint(ge=0, le=100) | None = Field(
None, description="喜好程度(以0~100的分数表示)")
description: str | None = Field(
None, description="其他补充说明(例如,特定的调味或配料等)"
)
# 生成 Memory Manager
manager = create_memory_manager(
llm, # 用于记忆提取和更新的模型
schemas=[UserFoodPreference],
instructions="请详细提取用户的偏好。如果将偏好中的`preference`更新为0,则从记忆中删除(RemoveDoc)",
enable_inserts=True, # 添加记忆: 默认为True
enable_updates=True, # 更新记忆: 默认为True
enable_deletes=True, # 删除记忆: 默认为False
)
# 继续
def print_memory(num: int, memories: list):
"""输出长期记忆"""
print(f"### conversation:{num}")
for m in memories:
print(m)
# 添加
conversation = [
{"role": "user", "content": "我非常喜欢拉面!!"},
{"role": "user", "content": "我也喜欢意面"},
]
# 长期记忆反映
memories = manager.invoke({"messages": conversation})
print_memory(1, memories)
# Update or delete
conversation = [
{"role": "user", "content": "我喜欢味噌拉面"},
{"role": "user", "content": "我不喜欢意面"},
]
# 长期记忆反映(更新/删除现有长期记忆)
memories = manager.invoke({"messages": conversation, "existing": memories})
print_memory(2, memories)MEM0
研究人员认为,理想的人工智能记忆应该能够“选择性地存储重要信息,巩固相关概念,并在需要时检索相关细节——模拟人类的认知过程”。对于用户与人工智能代理之间较长时间(例如数月)的对话,其内存需求甚至会超过最宽松的上下文限制。即使上下文长度超过 10 万个标记,由于缺乏显著性、持久性和优先级,人工智能代理也无法接近通用智能。
Mem0 总部位于旧金山,提供一套开源记忆系统,通过高效存储和调用用户交互信息,应对无状态语言模型的挑战。Mem0 提供两种新颖的记忆架构 Mem0 和 Mem0g,能够动态地从对话中提取、整合和检索关键信息。Mem0 通过一个两阶段流程运行:提取阶段,从新的对话中识别出重要的信息;更新阶段,根据信息与现有记忆的相关性和一致性,评估是添加、修改还是丢弃这些信息。
通过模拟人类的选择性回忆,Mem0 使人工智能代理能够在较长的时间内保持连贯且具有情境感知能力的交互。
Memo 研发了两种算法,Mem0和Memo0g。
Mem0
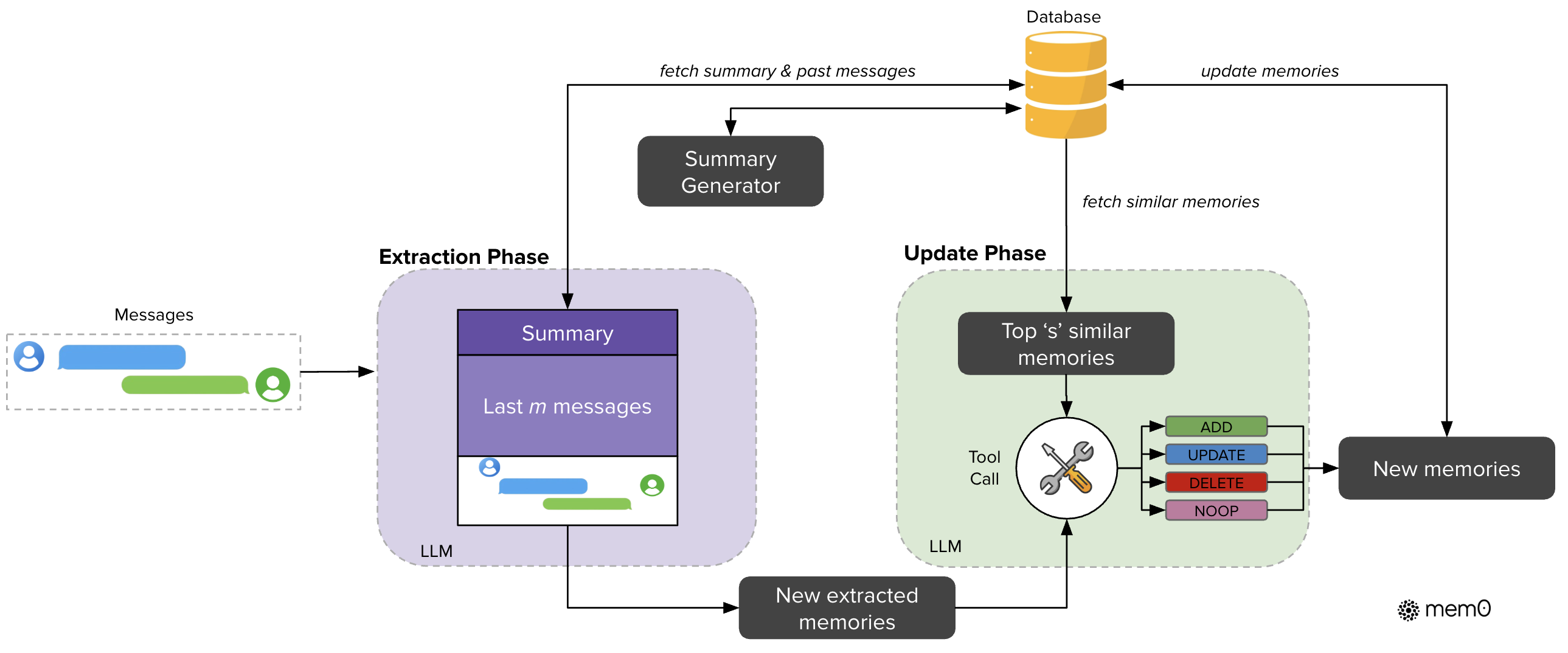
Mem0系统分为提取和更新两个阶段。提取阶段处理消息和历史上下文以创建新的记忆。更新阶段将提取的记忆与类似的现有记忆进行比较,并通过工具调用机制应用适当的操作。数据库充当中央存储库,为处理和存储更新的记忆提供上下文。
提取
当有新的对话消息进入系统时,Mem0 会从数据库中取出本次对话的 会话摘要(S),帮助系统理解整个对话的全局上下文。 此外,Mem0 还会使用一个 最近消息窗口,即最近的若干条消息(由超参数 m 控制),以便提取出更多的细节上下文信息。
Mem0 会将 会话摘要 和 最近消息 结合起来(很常见的全局和局部信息结合的思想),与当前的新消息(用户和助手的最新一轮对话)一起,生成一个 综合提示(P)。这个提示会被送入一个提取函数,通过大语言模型(LLM)来处理和提取出一组 候选记忆(Ω)。这些候选记忆是与当前对话相关的关键信息,用于后续更新知识库中的记忆。
记忆提取后,Mem0 会进入 记忆更新 阶段。在这个阶段,系统会将刚提取的候选记忆组与现有记忆进行对比,确保它们的一致性并避免冗余。为此,Mem0 首先会检索出与候选记忆语义最相似的若干个现有记忆(向量数据库向量检索)。然后通过function call的形式调用记忆更新工具来更新记忆。工具有4个:
- 添加(ADD):当没有语义相似的记忆时,将新记忆添加到知识库。
- 更新(UPDATE):当现有记忆与新记忆有部分重叠时,更新现有记忆,以纳入新信息。
- 删除(DELETE):当现有记忆与新记忆存在冲突时,删除旧记忆。
- 无操作(NOOP):当新记忆与现有记忆一致时,保持现有记忆不变。
当现有记忆与新提取的候选记忆存在冲突时,Mem0 会决定是否删除、更新或添加新记忆。
Mem0g
Mem0g 是基于图数据库的方式,首先要从对话中提取实体(Entity)和关系(relation) 然后存储在图数据库中,之前我们也做过这样的存储算法,发现的主要问题是大模型提取Entity 和Relation 一致性差,造成同样的实体或者关系有许多,影响查询。不知道Mem0g 使用gpt-4o-mini 是否有改善。
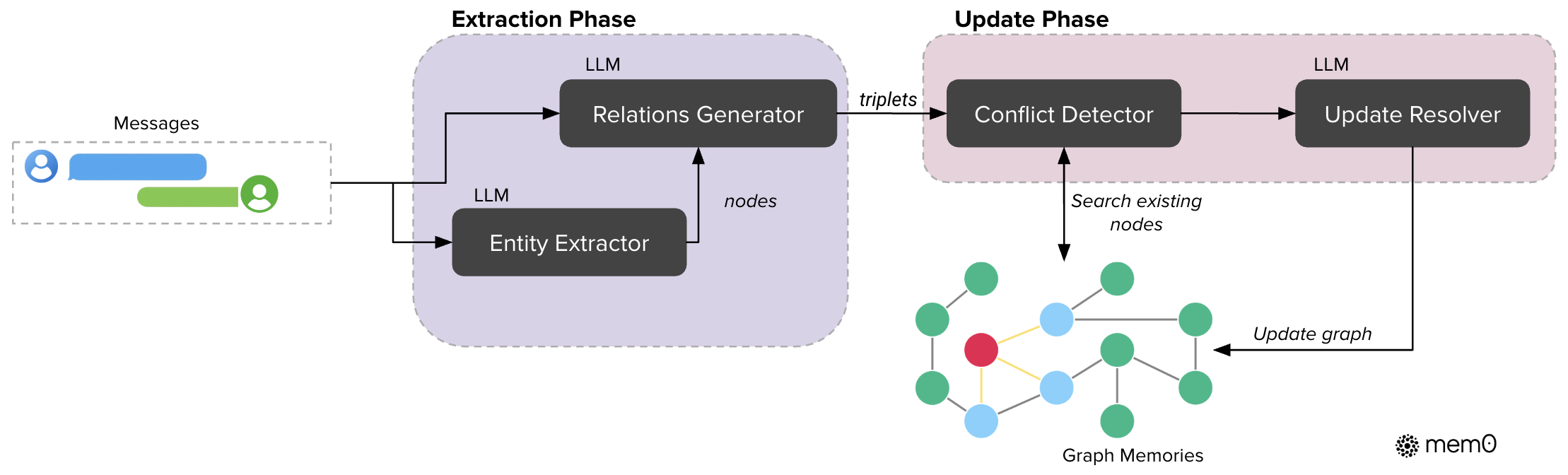
提取过程采用两阶段流水线,利用 LLM 将非结构化文本转换为结构化图表征。首先,实体提取器模块处理输入文本,以识别一组实体及其对应的类型。在我们的框架中,实体代表对话中的关键信息元素,包括人物、地点、物体、概念、事件以及值得在记忆图中表示的属性。实体提取器通过分析对话中元素的语义重要性、唯一性和持久性来识别这些不同的信息单元。例如,在关于旅行计划的对话中,实体可能包括目的地(城市、国家)、交通方式、日期、活动和参与者偏好——本质上是任何可能与未来参考或推理相关的离散信息。
接下来,关系生成器组件会导出这些实体之间的有意义连接,从而建立一组关系三元组,以捕捉信息的语义结构。这个基于 LLM 的模块会分析提取出的实体及其在对话中的上下文,以识别具有语义意义的连接。它通过检查语言模式、语境线索和领域知识来确定实体之间的关系。对于每个潜在的实体对,生成器会评估是否存在有意义的关系,如果存在,则使用适当的标签(例如,“住在哪里”、“喜欢”、“拥有”、“发生在”等)对该关系进行分类。该模块采用即时工程技术,引导 LLM 对对话中的显式语句和隐式信息进行推理,从而生成关系三元组,这些关系三元组构成了我们记忆图中的边,并支持跨互连信息进行复杂的推理。
在整合新信息时,Mem0g 采用复杂的存储和更新策略。对于每个新的关系三元组,我们计算源实体和目标实体的嵌入,然后搜索语义相似度高于定义阈值的现有节点。吨'。根据节点的存在情况,系统可能会同时创建两个节点、仅创建一个节点,或者在使用适当元数据建立关系之前使用现有节点。
为了维护一致的知识图谱,我们实现了冲突检测机制,该机制可在新信息到达时识别出可能存在冲突的现有关系。基于 LLM 的更新解析器会确定某些关系是否应该过时,并将其标记为无效,而不是物理地将其删除以启用时间推理。
在 Mem0 的基础上,Mem0g 引入了传统知识图谱的思想来增强其对复杂关系的处理能力。与 Mem0 主要通过文本和摘要来管理记忆不同,Mem0g 通过三元组方式将记忆存储为头节点、尾节点和关系边的图,这种结构能更好地捕捉了不同实体之间的关系。同样是两个阶段(提取和更新)。
Mem0g 采用了图结构来表示和处理实体和关系。Mem0g 首先通过一个实体提取模块从对话中识别出所有相关的实体(例如人物、地点、事件等)及实体类别。随后,系统会通过关系生成模块根据对话上下文建立实体之间的关系,形成一组三元组(如实体 A 、实体 B及关系 R)。这些三元组也就组成了一个记忆知识图谱。这里Mem0g在抽取实体和关系的时候就是用大模型+prompt完成,没有用传统nlp中实体识别或者关系抽取的方法。并且,它是采用两阶段完成,即先实体抽取,再关系生成。传统nlp时代(也称BERT时代)也有很多一步同时生成实体和关系的方法。
记忆检索功能Mem0g 实施双重方法策略,以实现最佳信息访问。以实体为中心的方法首先识别查询中的关键实体,然后利用语义相似度在知识图谱中定位相应的节点。它系统地探索来自这些锚节点的传入和传出关系,构建一个全面的子图来捕获相关的上下文信息。作为补充,语义三元组方法通过将整个查询编码为密集的嵌入向量,采取更全面的视角。然后,将此查询表示与知识图谱中每个关系三元组的文本编码进行匹配。系统计算查询与所有可用三元组之间的细粒度相似度得分,仅返回那些超过可配置相关性阈值的三元组,并按相似度递减的顺序排列。这种双重检索机制能够内存0克 以同样的效率处理有针对性的实体问题和更广泛的概念查询。
从实现角度来看,该系统使用 Neo4j 1作为底层图数据库。基于 LLM 的提取器和更新模块利用GPT-4o-mini 的函数调用功能,可以从非结构化文本中结构化地提取信息。通过将基于图的表示与语义嵌入和基于 LLM 的信息提取相结合,Mem0g 既实现了复杂推理所需的结构丰富性,又实现了自然语言理解所需的语义灵活性。
Mem0 的使用方法
安装
pip install mem0ai
pip install "mem0ai[graph]"后面一种是安装mem0g
mem0g 的使用
Mem0g 的优雅之处是可以使用自然语言访问图数据库了
以下是如何使用 Mem0 的图形操作的示例:
- 首先,我们将为名为 Alice 的用户添加一些回忆。
- 然后,我们将直观地看到随着添加更多记忆,图表是如何演变的。
- 您将看到实体和关系如何在图表中自动提取和连接。
添加记忆“我喜欢去远足”
m.add("I like going to hikes", user_id="alice123")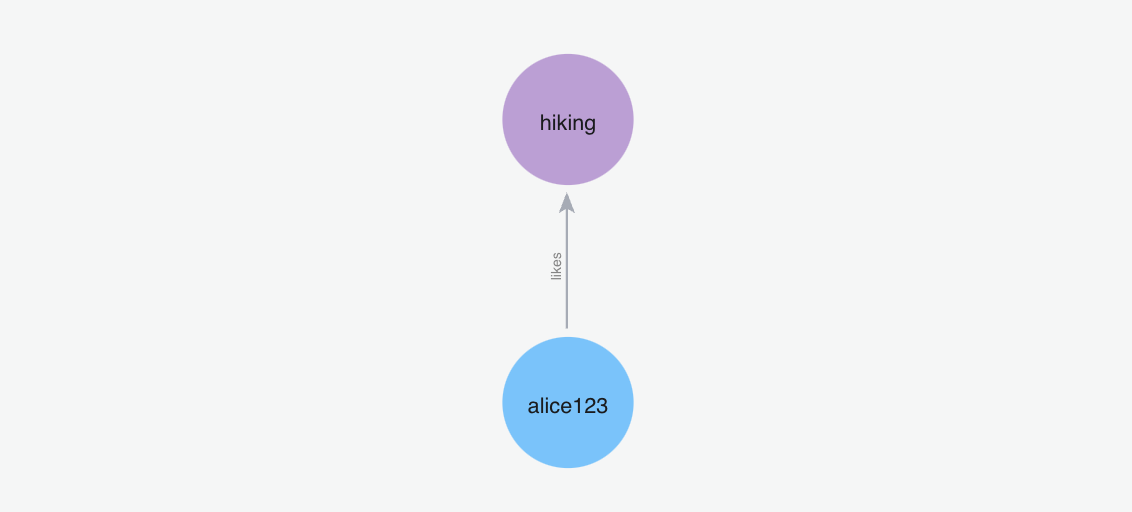
添加记忆“我喜欢打羽毛球”
m.add("I love to play badminton", user_id="alice123")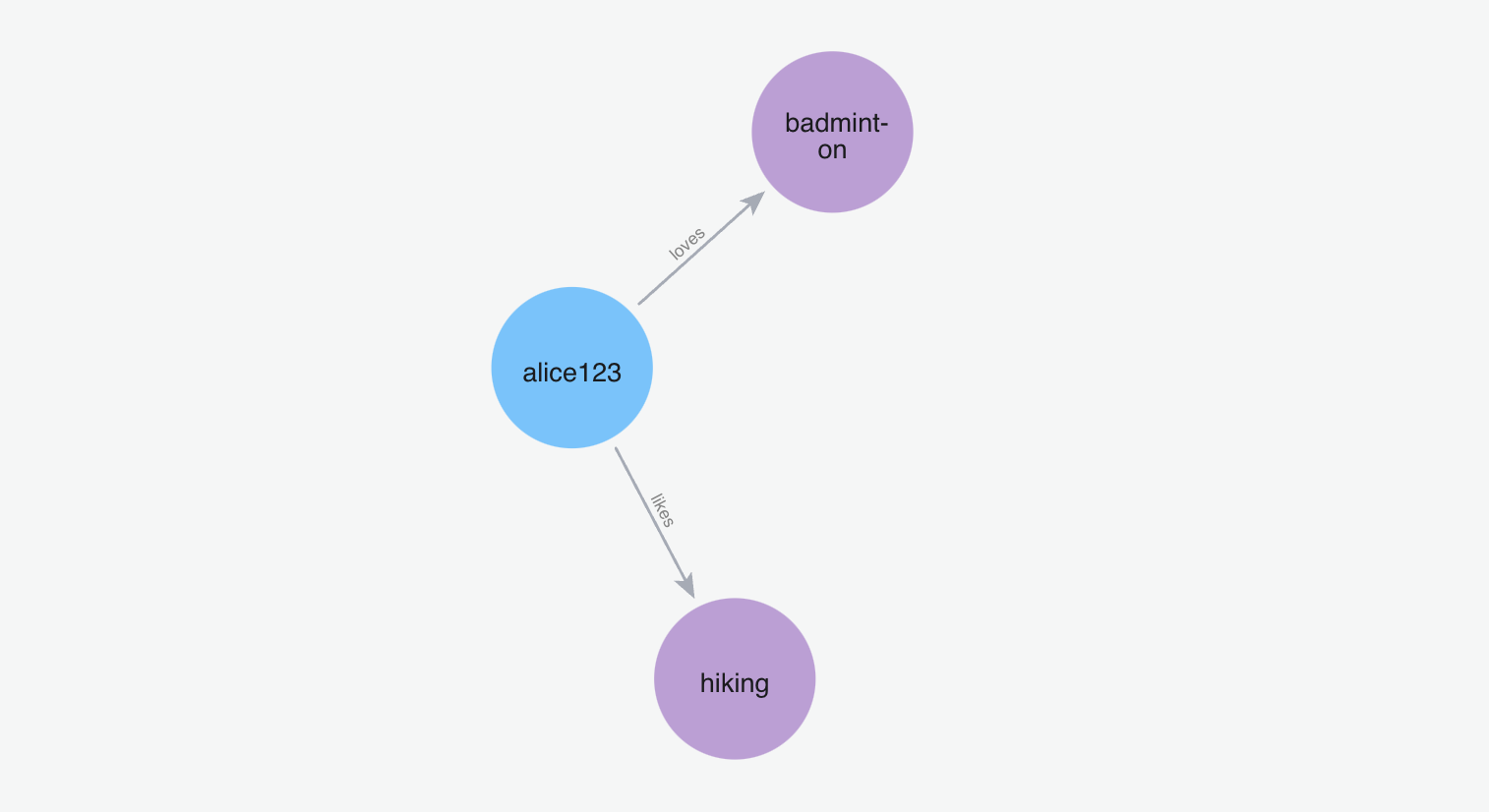
添加记忆“我讨厌打羽毛球”
m.add("I hate playing badminton", user_id="alice123")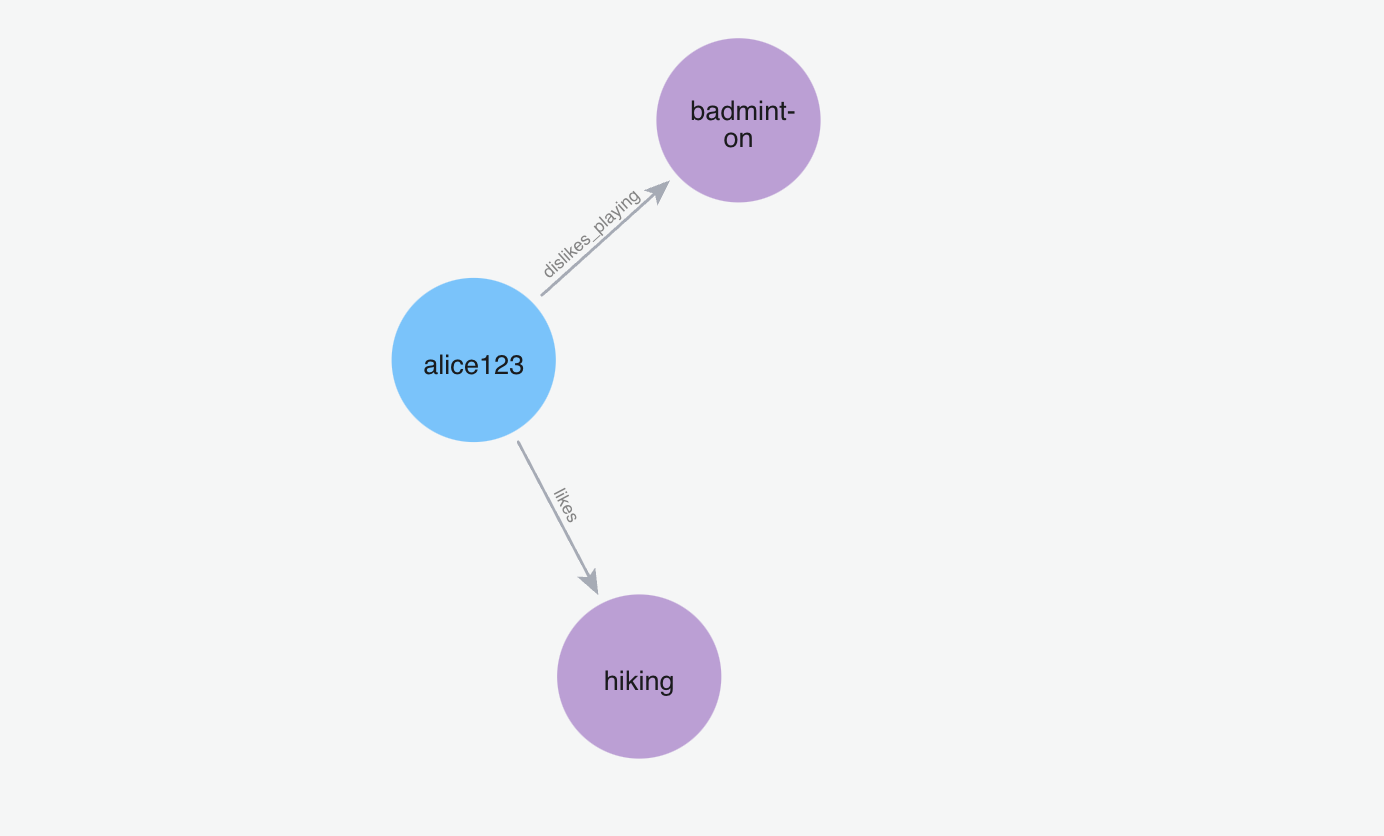
添加记忆“我的朋友叫约翰,约翰有一只名叫汤米的狗”
m.add("My friend name is john and john has a dog named tommy", user_id="alice123") 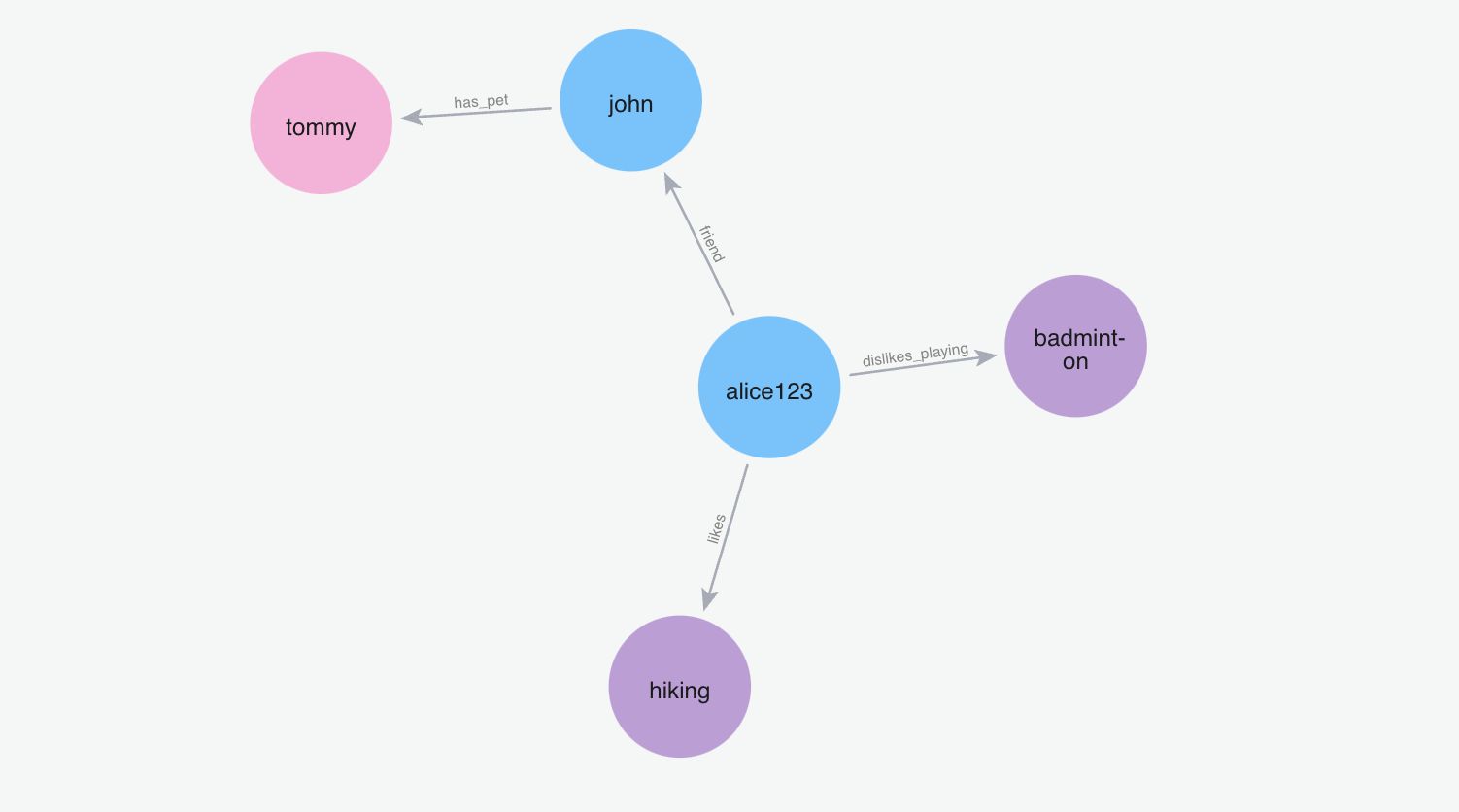
添加记忆“我的名字是爱丽丝”
m.add("My name is Alice", user_id="alice123") 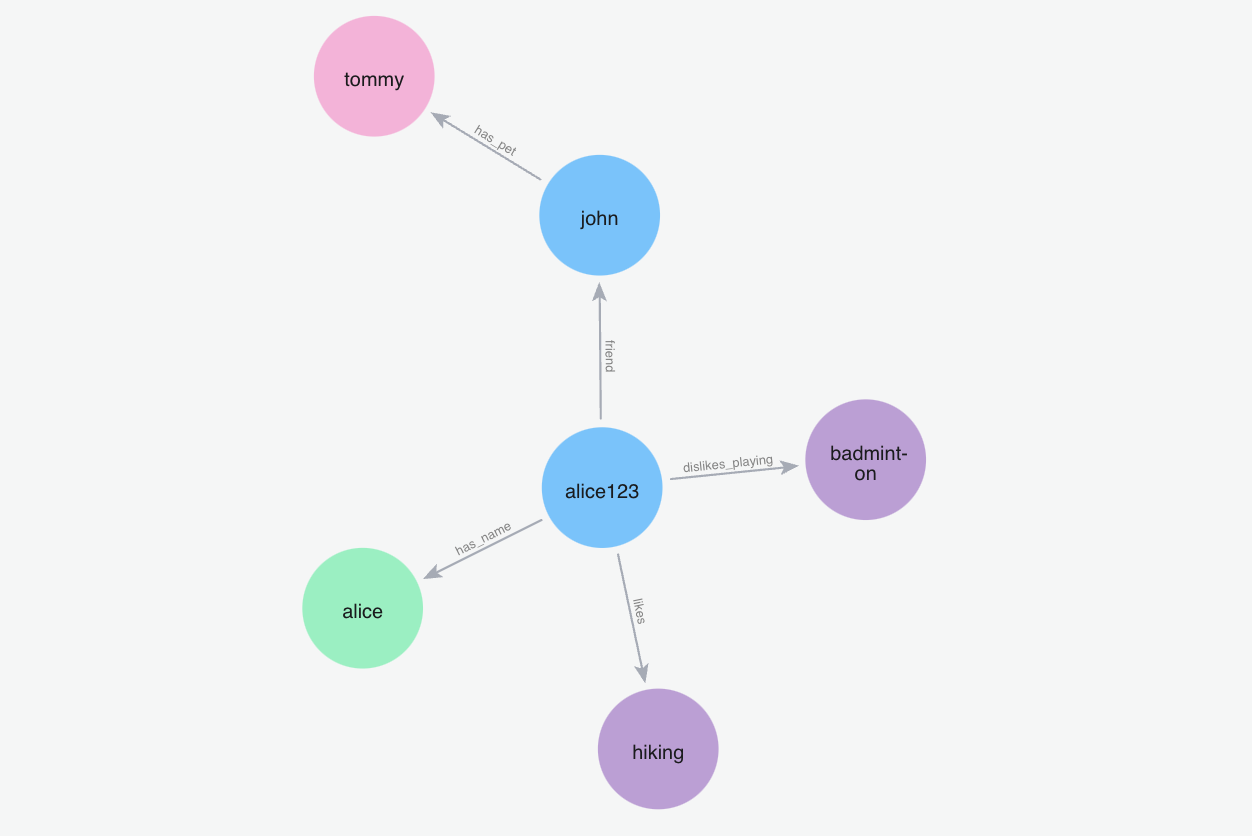
添加记忆“约翰喜欢徒步旅行,哈利也喜欢徒步旅行”
m.add("John loves to hike and Harry loves to hike as well", user_id="alice123")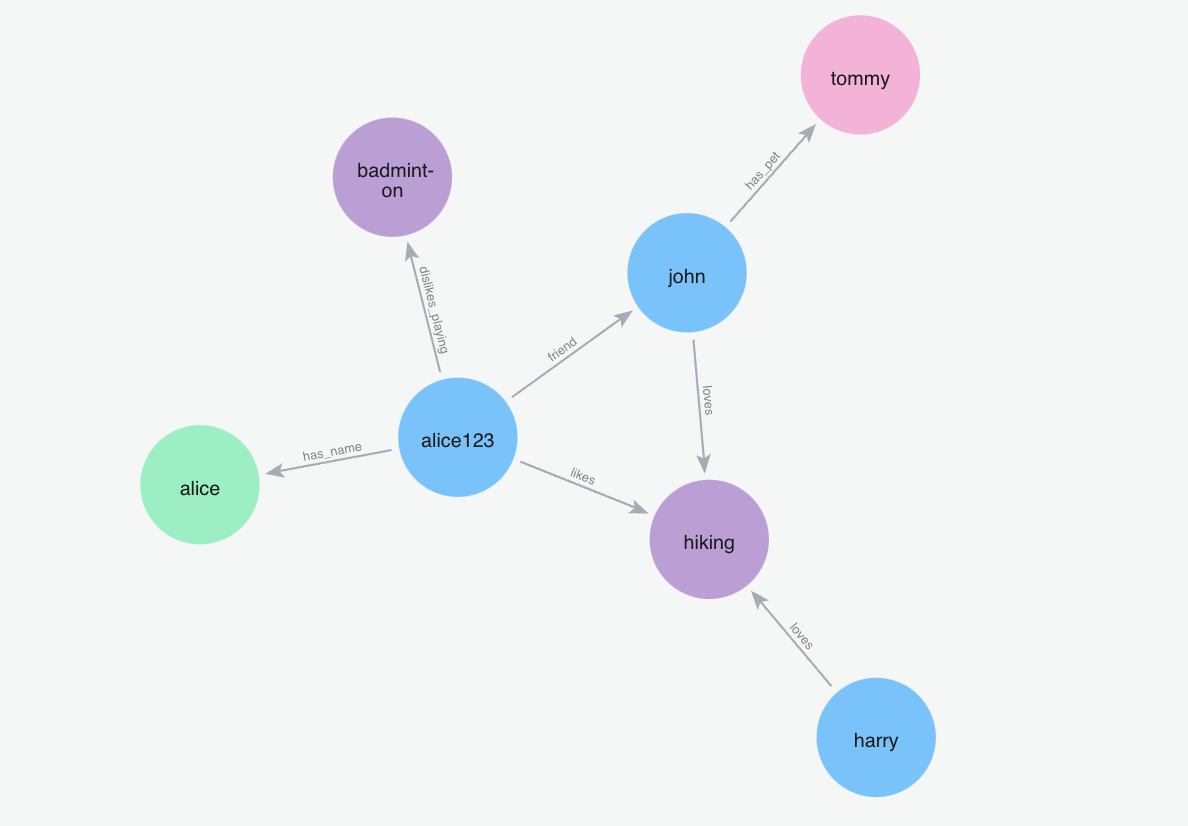
添加记忆“我的朋友彼得是蜘蛛侠”
m.add("My friend peter is the spiderman", user_id="alice123")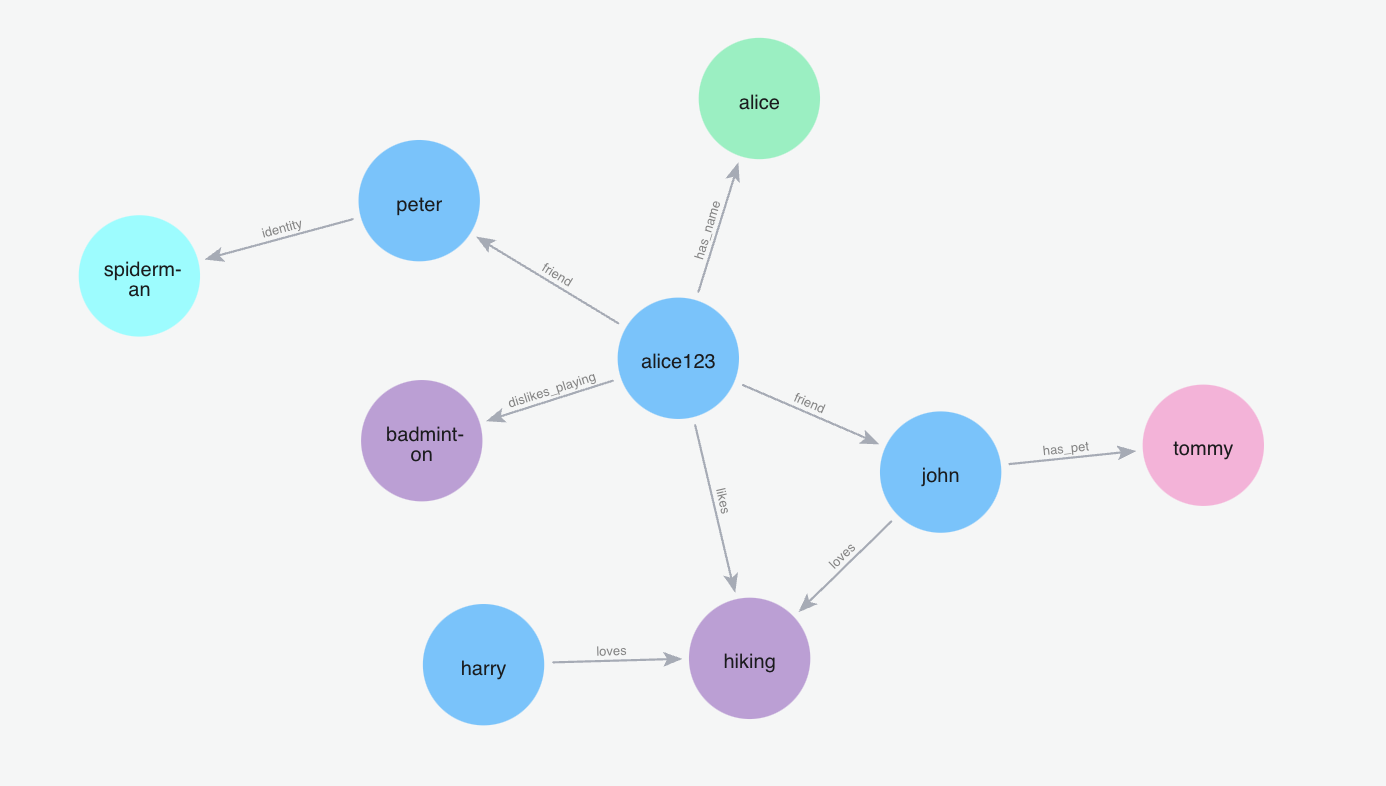
搜索记忆
m.search("What is my name?", user_id="alice123")下面的图形可视化显示了从图形中获取的用于所提供查询的节点和关系。
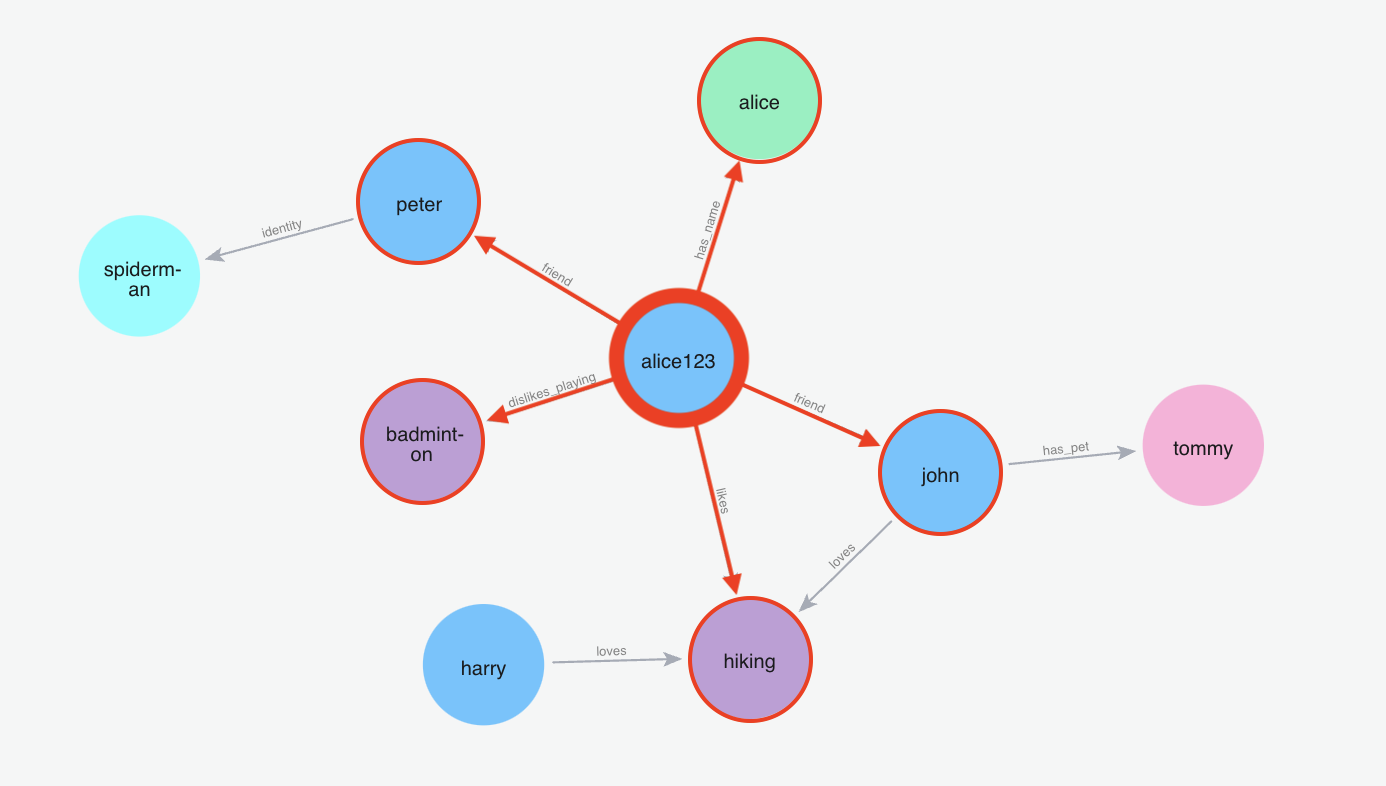
m.search("Who is spiderman?", user_id="alice123")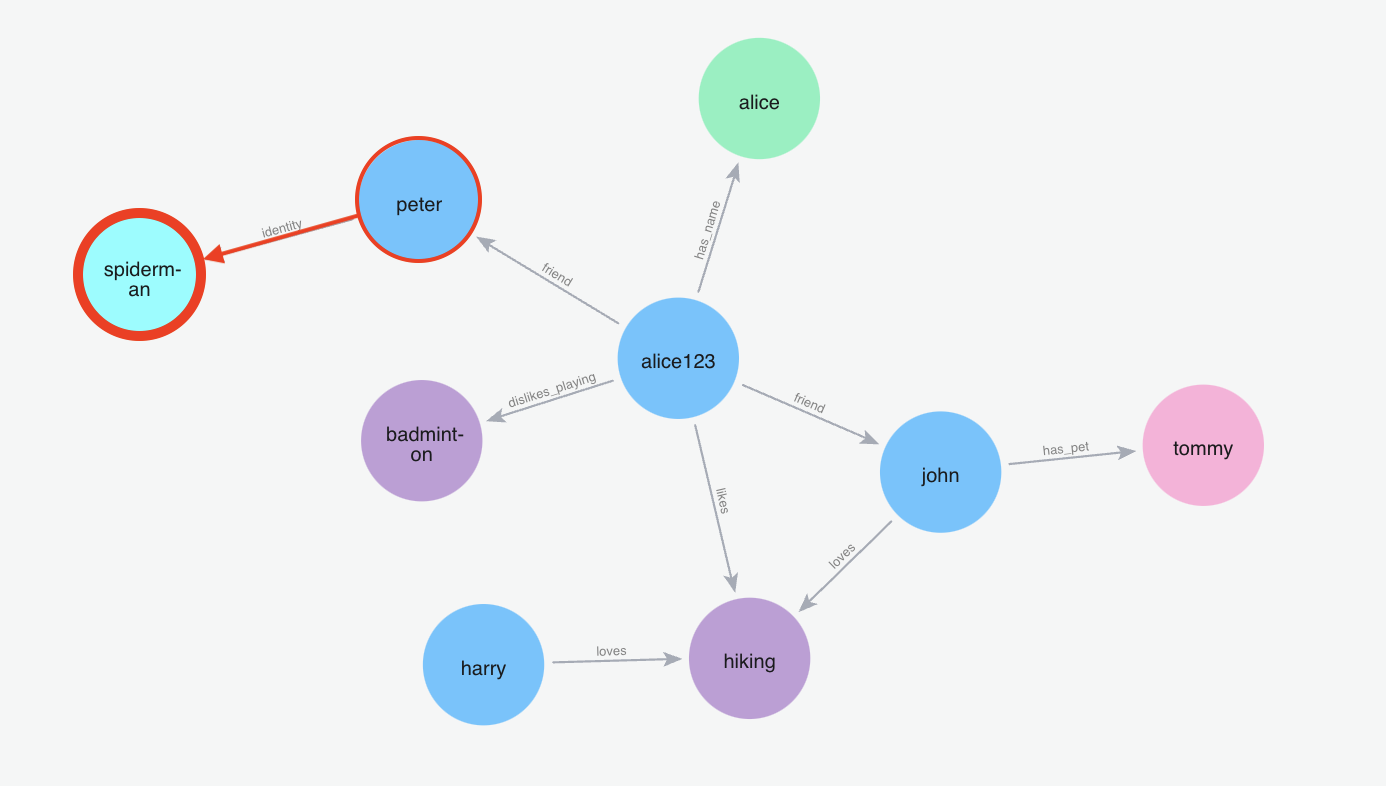
评估结果与效率
评估使用了 LOCOMO 数据集,该数据集包含 10 个扩展对话,每个对话包含约 600 个对话和 26,000 个标记,涵盖多个会话,平均每个对话包含 200 个问题。评估将 Mem0 和 Mem0g 与多个基准系统进行了比较,包括记忆增强方法(LoCoMo、ReadAgent、MemoryBank、MemGPT、A-Mem)、RAG(一种全上下文方法)、开源记忆解决方案(LangMem)、专有系统(OpenAI)以及专用记忆管理平台 Zep。
在性能方面,Mem0 在单跳问题上的表现优于其他系统。Mem0g 的性能略有下降,这表明基于图的内存结构对于更简单的单轮查询而言,其优势有限。在多跳问题上,Mem0 也表现出色,但 Mem0g 并未表现出显著的提升,这表明在需要跨多个会话整合信息的任务中使用图内存效率较低。在开放域问题中,Zep 基线得分最高,但 Mem0g 的表现与之相当。在时间推理任务中,Mem0g 表现出色,这证实了关系结构对于需要对事件序列进行建模的任务非常有用。
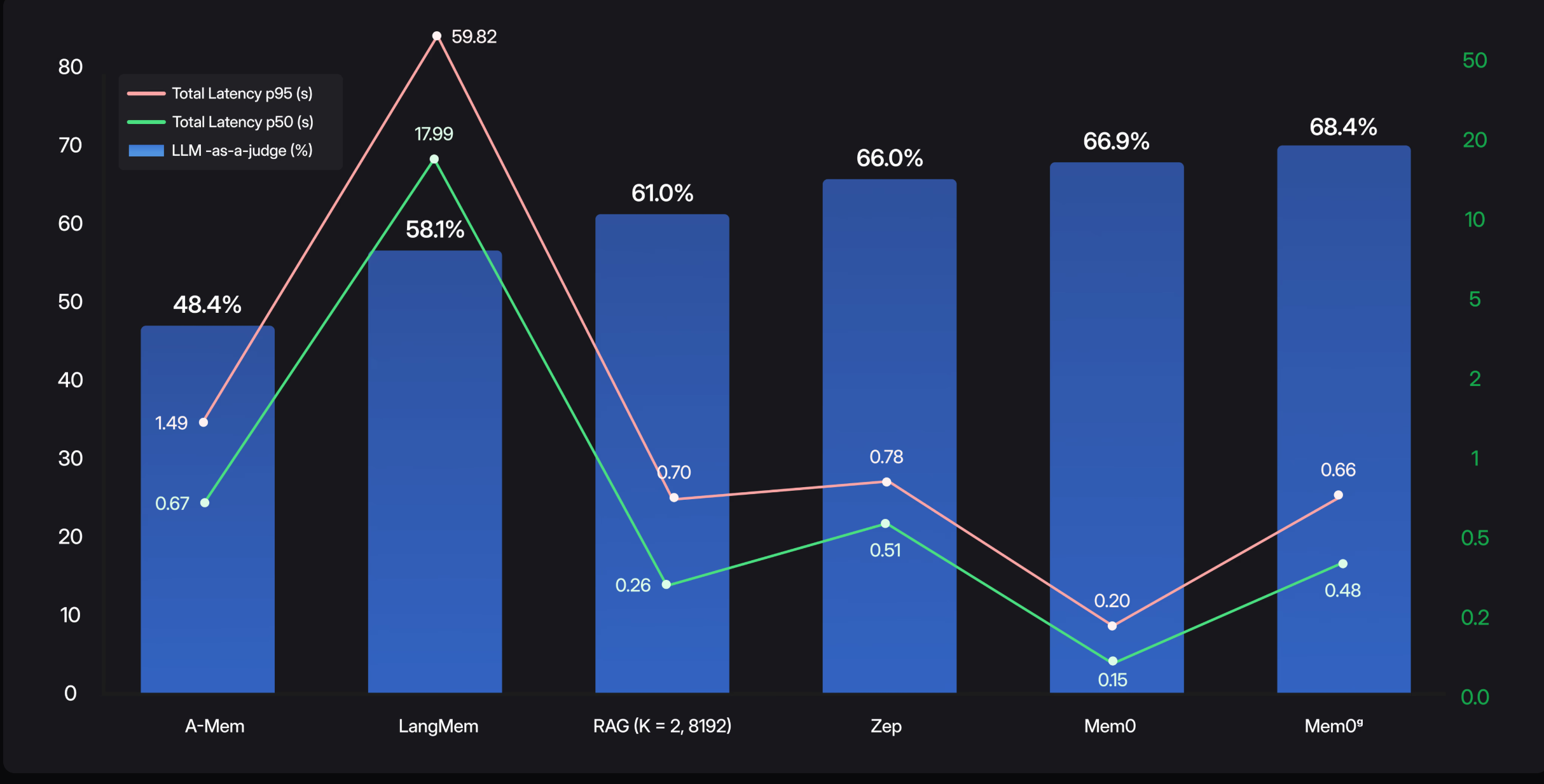
在计算效率方面,全上下文方法准确率最高,但响应速度较慢,大约需要 17 秒。Mem0 减少了令牌使用量,响应速度更快,延迟仅为 1.44 秒,提升了 92%。Mem0g 的延迟略高,为 2.6 秒,但仍提升了 85%,同时在记忆增强系统中实现了最佳准确率。
随着对话长度的增加,Mem0 和 Mem0g 保持了稳定的性能,而全上下文方法则面临着计算开销不断增加的问题。Mem0 每次对话仅使用 7k 个令牌,而 Mem0g(采用图内存)则需要 14k 个令牌。相比之下,Zep 消耗了超过 600k 个令牌,主要是因为在每个节点上缓存了完整的抽象摘要。
结束语
人类记忆是智力的基础 ,同样地,一个好的记忆系统是AI 智能体的基础,而出色的记忆体是借助于LLM 实现的,它能够使用自然语言对记忆的信息进行更新,删除,检索。这要比基于矢量数据库的RAG 更有效。作为一个AI 重要的基础设施,记忆系统值得进一步地研究。

















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









